
Перевод How AI can learn to generate pictures of cats.
Опубликованная в 2014-м исследовательская работа Generative Adversarial Nets (GAN) стала прорывом в сфере генеративных моделей. Ведущий исследователь Янн Лекун назвал состязательные сети (adversarial nets) «лучшей идеей в машинном обучении за последние двадцать лет». Сегодня благодаря этой архитектуре мы можем создать ИИ, который генерирует реалистичные изображения кошек. Круто же!

DCGAN в ходе обучения
Весь работающий код лежит в Github-репозитории. Он будет вам полезен, если у вас есть какой-то опыт программирования на Python, глубокого обучения, работы с Tensorflow и свёрточными нейросетями.
А если вы новичок в глубоком обучении, рекомендую ознакомиться с прекрасной серией статей Machine Learning is Fun!
Что такое DCGAN?
Свёрточные генеративные состязательные сети глубокого обучения (Deep Convolutional Generative Adverserial Networks, DCGAN) — это архитектура глубокого обучения, генерирующая данные, аналогичные данным из обучающей выборки.
Эта модель заменяет свёрточными слоями полностью соединённые слои генеративной состязательной сети. Чтобы понять, как работает DCGAN, воспользуемся метафорой противостояния эксперта-искусствоведа и фальсификатора.
Фальсификатор («генератор») пытается создать фальшивую картину Ван Гога и выдать за настоящую.
Искусствовед («дискриминатор») старается уличить фальсификатора, используя свои знания о настоящих полотнах Ван Гога.
Со временем искусствовед всё лучше определяет фальшивки, а фальсификатор делает их всё совершеннее.
Как видите, DCGAN’ы скомпонованы из двух отдельных нейросетей глубокого обучения, соревнующихся друг с другом.
- Генератор пытается создать данные, выглядящие правдоподобно. Он не знает, что собой представляют настоящие данные, но учится на ответах нейросети-противника, с каждой итерацией изменяя результаты своей работы.
- Дискриминатор старается определить фальшивые данные (сравнивая с настоящими), по мере возможности избегая ложных срабатываний применительно к настоящим данным. Результат работы этой модели является обратной связью для генератора.
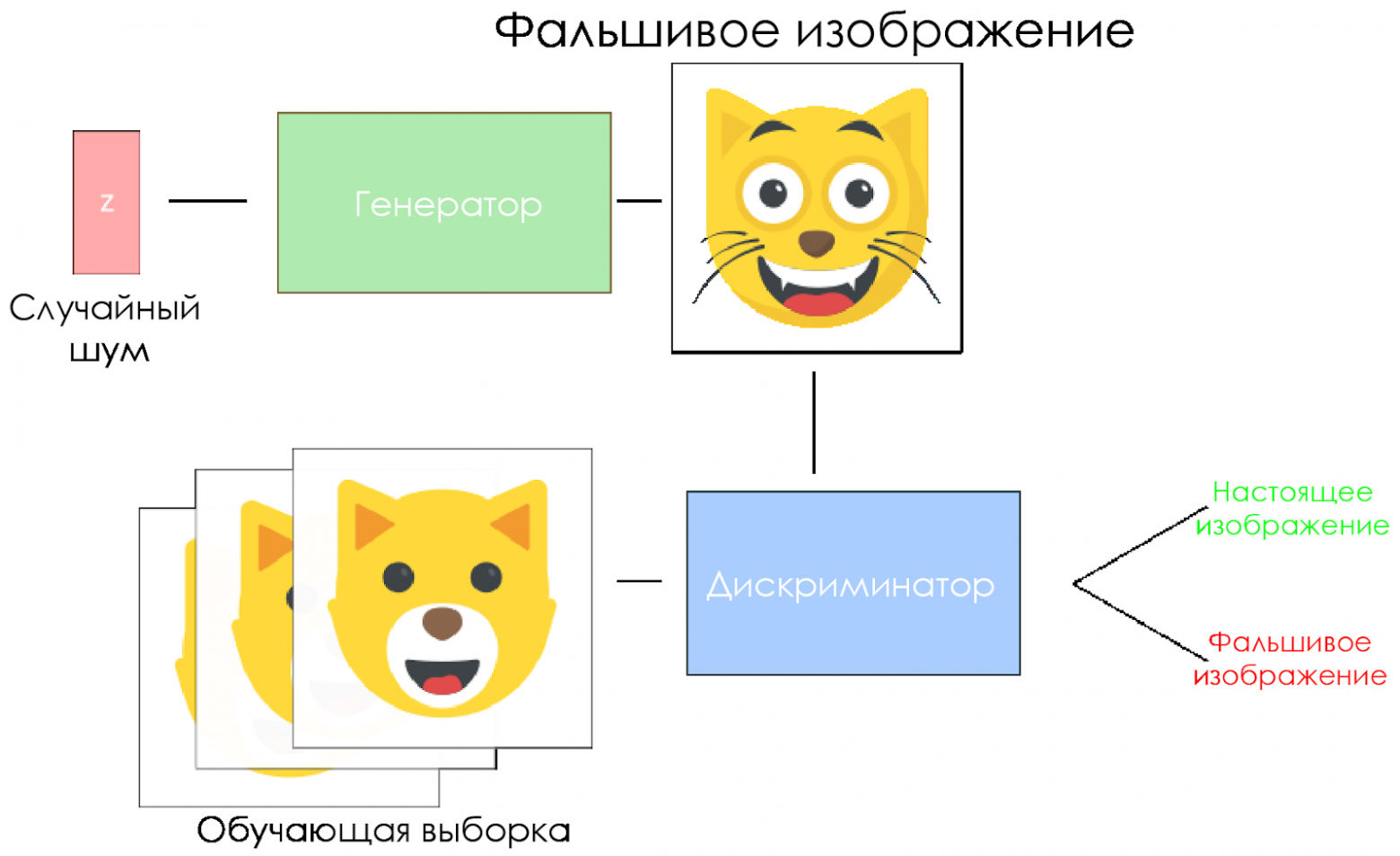
Схема DCGAN.
- Генератор берёт вектор случайного шума и генерирует изображение.
- Картинка отдаётся дискриминатору, тот сравнивает её с обучающей выборкой.
- Дискриминатор возвращает число — 0 (фальшивка) или 1 (настоящее изображение).
Давайте создадим DCGAN!
Теперь мы готовы создать свой ИИ.
В этой части мы сосредоточимся на основных компонентах нашей модели. Если хотите посмотреть весь код, заходите сюда.
Входные данные
Создадим заглушки для входных данных:
inputs_real для дискриминатора и inputs_z для генератора. Обратите внимание, что у нас будет две скорости обучения (learning rates), отдельно для генератора и дискриминатора.DCGAN’ы очень чувствительны к гиперпараметрам, поэтому очень важно тонко их настроить.
def model_inputs(real_dim, z_dim):""" Create the model inputs :param real_dim: tuple containing width, height and channels :param z_dim: The dimension of Z :return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D) """ # inputs_real for Discriminator inputs_real = tf.placeholder(tf.float32, (None, *real_dim), name='inputs_real') # inputs_z for Generator inputs_z = tf.placeholder(tf.float32, (None, z_dim), name="input_z") # Two different learning rate : one for the generator, one for the discriminator learning_rate_G = tf.placeholder(tf.float32, name="learning_rate_G") learning_rate_D = tf.placeholder(tf.float32, name="learning_rate_D") return inputs_real, inputs_z, learning_rate_G, learning_rate_D
Дискриминатор и генератор
Мы используем
tf.variable_scope по двум причинам.Во-первых, чтобы быть уверенными, что имена всех переменных начинаются с generator/discriminator. Позднее это нам поможет при обучении двух нейросетей.
Во-вторых, мы будем повторно использовать эти сети с разными входными данными:
- Мы обучим генератор, а потом возьмём образца сгенерированных им изображений.
- В дискриминаторе будем совместно использовать переменные для фальшивых и настоящих входных изображений.
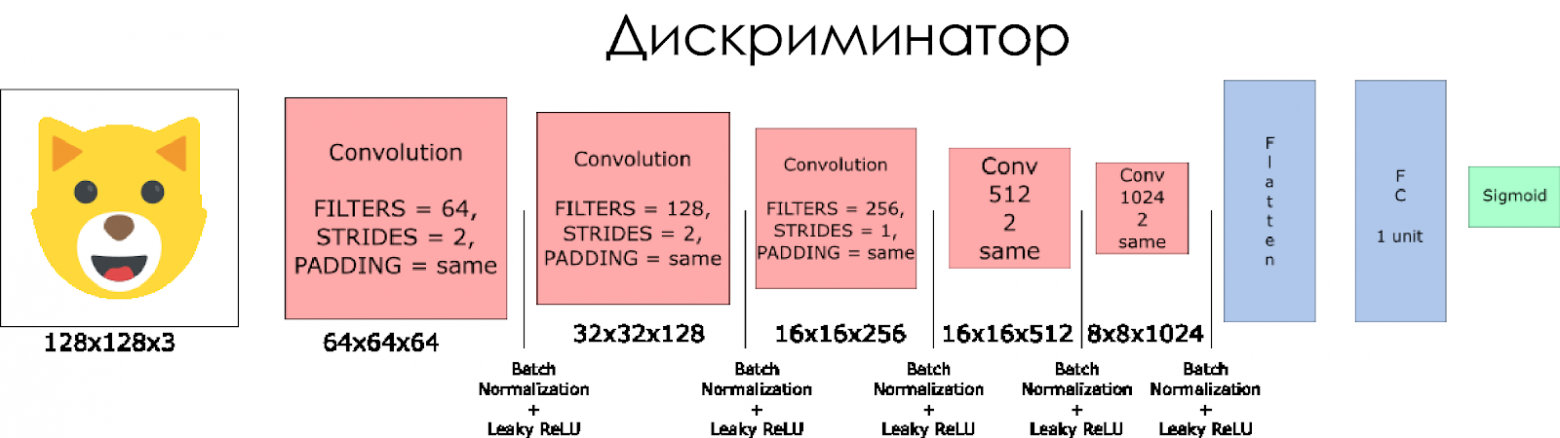
Давайте создадим дискриминатор. Помните, что в качестве входных данных он берёт настоящее или фальшивое изображение и в ответ выдаёт 0 или 1.
Несколько примечаний:
- Нам нужно удвоить размер фильтра в каждом свёрточном слое.
- Не рекомендуется использовать понижающую выборку (downsampling). Вместо этого применим только свёрточные слои субдискретизации (strided convolutional layers).
- В каждом слое используем пакетную нормализацию (batch normalization) (за исключением входного слоя), поскольку это снижает ковариационный сдвиг (covariance shift). Подробнее можно почитать в этой замечательной статье.
- В качестве функции активации воспользуемся Leaky ReLU, это поможет избежать эффекта «исчезающего» градиента.
def discriminator(x, is_reuse=False, alpha = 0.2): ''' Build the discriminator network. Arguments --------- x : Input tensor for the discriminator n_units: Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out, logits: ''' with tf.variable_scope("discriminator", reuse = is_reuse): # Input layer 128*128*3 --> 64x64x64 # Conv --> BatchNorm --> LeakyReLU conv1 = tf.layers.conv2d(inputs = x, filters = 64, kernel_size = [5,5], strides = [2,2], padding = "SAME", kernel_initializer=tf.truncated_normal_initializer(stddev=0.02), name='conv1') batch_norm1 = tf.layers.batch_normalization(conv1, training = True, epsilon = 1e-5, name = 'batch_norm1') conv1_out = tf.nn.leaky_relu(batch_norm1, alpha=alpha, name="conv1_out") # 64x64x64--> 32x32x128 # Conv --> BatchNorm --> LeakyReLU conv2 = tf.layers.conv2d(inputs = conv1_out, filters = 128, kernel_size = [5, 5], strides = [2, 2], padding = "SAME", kernel_initializer=tf.truncated_normal_initializer(stddev=0.02), name='conv2') batch_norm2 = tf.layers.batch_normalization(conv2, training = True, epsilon = 1e-5, name = 'batch_norm2') conv2_out = tf.nn.leaky_relu(batch_norm2, alpha=alpha, name="conv2_out") # 32x32x128 --> 16x16x256 # Conv --> BatchNorm --> LeakyReLU conv3 = tf.layers.conv2d(inputs = conv2_out, filters = 256, kernel_size = [5, 5], strides = [2, 2], padding = "SAME", kernel_initializer=tf.truncated_normal_initializer(stddev=0.02), name='conv3') batch_norm3 = tf.layers.batch_normalization(conv3, training = True, epsilon = 1e-5, name = 'batch_norm3') conv3_out = tf.nn.leaky_relu(batch_norm3, alpha=alpha, name="conv3_out") # 16x16x256 --> 16x16x512 # Conv --> BatchNorm --> LeakyReLU conv4 = tf.layers.conv2d(inputs = conv3_out, filters = 512, kernel_size = [5, 5], strides = [1, 1], padding = "SAME", kernel_initializer=tf.truncated_normal_initializer(stddev=0.02), name='conv4') batch_norm4 = tf.layers.batch_normalization(conv4, training = True, epsilon = 1e-5, name = 'batch_norm4') conv4_out = tf.nn.leaky_relu(batch_norm4, alpha=alpha, name="conv4_out") # 16x16x512 --> 8x8x1024 # Conv --> BatchNorm --> LeakyReLU conv5 = tf.layers.conv2d(inputs = conv4_out, filters = 1024, kernel_size = [5, 5], strides = [2, 2], padding = "SAME", kernel_initializer=tf.truncated_normal_initializer(stddev=0.02), name='conv5') batch_norm5 = tf.layers.batch_normalization(conv5, training = True, epsilon = 1e-5, name = 'batch_norm5') conv5_out = tf.nn.leaky_relu(batch_norm5, alpha=alpha, name="conv5_out") # Flatten it flatten = tf.reshape(conv5_out, (-1, 8*8*1024)) # Logits logits = tf.layers.dense(inputs = flatten, units = 1, activation = None) out = tf.sigmoid(logits) return out, logits
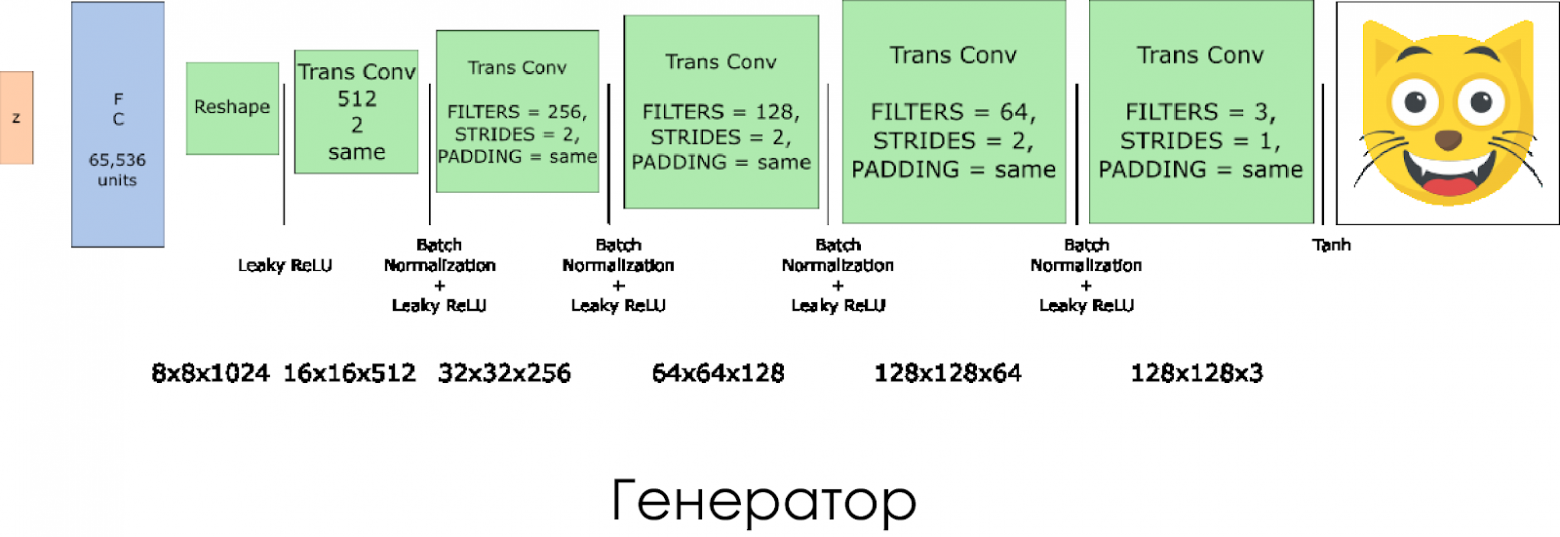
Мы создали генератор. Помните, что он берёт в качестве входных данных вектор шума (z) и благодаря транспорированным свёрточным слоям (transposed convolution layers) создаёт фальшивое изображение.
На каждом слое мы уменьшаем размер фильтра вдвое, и также вдвое увеличиваем размер картинки.
Лучше всего генератор работает при использовании
tanh в качестве выходной функции активации (output activation function).def generator(z, output_channel_dim, is_train=True): ''' Build the generator network. Arguments --------- z : Input tensor for the generator output_channel_dim : Shape of the generator output n_units : Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out: ''' with tf.variable_scope("generator", reuse= not is_train): # First FC layer --> 8x8x1024 fc1 = tf.layers.dense(z, 8*8*1024) # Reshape it fc1 = tf.reshape(fc1, (-1, 8, 8, 1024)) # Leaky ReLU fc1 = tf.nn.leaky_relu(fc1, alpha=alpha) # Transposed conv 1 --> BatchNorm --> LeakyReLU # 8x8x1024 --> 16x16x512 trans_conv1 = tf.layers.conv2d_transpose(inputs = fc1, filters = 512, kernel_size = [5,5], strides = [2,2], padding = "SAME", kernel_initializer=tf.truncated_normal_initializer(stddev=0.02), name="trans_conv1") batch_trans_conv1 = tf.layers.batch_normalization(inputs = trans_conv1, training=is_train, epsilon=1e-5, name="batch_trans_conv1") trans_conv1_out = tf.nn.leaky_relu(batch_trans_conv1, alpha=alpha, name="trans_conv1_out") # Transposed conv 2 --> BatchNorm --> LeakyReLU # 16x16x512 --> 32x32x256 trans_conv2 = tf.layers.conv2d_transpose(inputs = trans_conv1_out, filters = 256, kernel_size = [5,5], strides = [2,2], padding = "SAME", kernel_initializer=tf.truncated_normal_initializer(stddev=0.02), name="trans_conv2") batch_trans_conv2 = tf.layers.batch_normalization(inputs = trans_conv2, training=is_train, epsilon=1e-5, name="batch_trans_conv2") trans_conv2_out = tf.nn.leaky_relu(batch_trans_conv2, alpha=alpha, name="trans_conv2_out") # Transposed conv 3 --> BatchNorm --> LeakyReLU # 32x32x256 --> 64x64x128 trans_conv3 = tf.layers.conv2d_transpose(inputs = trans_conv2_out, filters = 128, kernel_size = [5,5], strides = [2,2], padding = "SAME", kernel_initializer=tf.truncated_normal_initializer(stddev=0.02), name="trans_conv3") batch_trans_conv3 = tf.layers.batch_normalization(inputs = trans_conv3, training=is_train, epsilon=1e-5, name="batch_trans_conv3") trans_conv3_out = tf.nn.leaky_relu(batch_trans_conv3, alpha=alpha, name="trans_conv3_out") # Transposed conv 4 --> BatchNorm --> LeakyReLU # 64x64x128 --> 128x128x64 trans_conv4 = tf.layers.conv2d_transpose(inputs = trans_conv3_out, filters = 64, kernel_size = [5,5], strides = [2,2], padding = "SAME", kernel_initializer=tf.truncated_normal_initializer(stddev=0.02), name="trans_conv4") batch_trans_conv4 = tf.layers.batch_normalization(inputs = trans_conv4, training=is_train, epsilon=1e-5, name="batch_trans_conv4") trans_conv4_out = tf.nn.leaky_relu(batch_trans_conv4, alpha=alpha, name="trans_conv4_out") # Transposed conv 5 --> tanh # 128x128x64 --> 128x128x3 logits = tf.layers.conv2d_transpose(inputs = trans_conv4_out, filters = 3, kernel_size = [5,5], strides = [1,1], padding = "SAME", kernel_initializer=tf.truncated_normal_initializer(stddev=0.02), name="logits") out = tf.tanh(logits, name="out") return out
Потери в дискриминаторе и генераторе
Поскольку мы одновременно обучаем генератор и дискриминатор, нам нужно вычислить потери для обеих нейросетей. Дискриминатор должен выдавать 1, когда он «считает» изображение настоящим, и 0, если изображение фальшивое. В соответствии с этим и нужно настроить потери. Потеря дискриминатора вычисляется как сумма потерь для настоящего и фальшивого изображения:
d_loss = d_loss_real + d_loss_fake где
d_loss_real — это потеря, когда дискриминатор считает изображение фальшивым, а на самом деле оно настоящее. Вычисляется так:- Используем
d_logits_real, все метки равны 1 (потому что все данные настоящие). labels = tf.ones_like(tensor) * (1 - smooth). Воспользуемся label smoothing: уменьшим значения меток с 1,0 до 0,9, чтобы помочь дискриминатору обобщать лучше.
d_loss_fake — это потеря, когда дискриминатор считает изображение настоящим, а на самом деле оно фальшивое.- Используем
d_logits_fake, все метки равны 0.
Для потери генератора используется
d_logits_fake из дискриминатора. На этот раз все метки равны 1, потому что генератор хочет обмануть дискриминатор.def model_loss(input_real, input_z, output_channel_dim, alpha): """ Get the loss for the discriminator and generator :param input_real: Images from the real dataset :param input_z: Z input :param out_channel_dim: The number of channels in the output image :return: A tuple of (discriminator loss, generator loss) """ # Generator network here g_model = generator(input_z, output_channel_dim) # g_model is the generator output # Discriminator network here d_model_real, d_logits_real = discriminator(input_real, alpha=alpha) d_model_fake, d_logits_fake = discriminator(g_model,is_reuse=True, alpha=alpha) # Calculate losses d_loss_real = tf.reduce_mean( tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real, labels=tf.ones_like(d_model_real))) d_loss_fake = tf.reduce_mean( tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.zeros_like(d_model_fake))) d_loss = d_loss_real + d_loss_fake g_loss = tf.reduce_mean( tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.ones_like(d_model_fake))) return d_loss, g_loss
Оптимизаторы
После вычисления потерь нужно по отдельности обновить генератор и дискриминатор. Для этого с помощью
tf.trainable_variables() создадим список всех переменных, определённых в нашем графе.def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1): """ Get optimization operations :param d_loss: Discriminator loss Tensor :param g_loss: Generator loss Tensor :param learning_rate: Learning Rate Placeholder :param beta1: The exponential decay rate for the 1st moment in the optimizer :return: A tuple of (discriminator training operation, generator training operation) """ # Get the trainable_variables, split into G and D parts t_vars = tf.trainable_variables() g_vars = [var for var in t_vars if var.name.startswith("generator")] d_vars = [var for var in t_vars if var.name.startswith("discriminator")] update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) # Generator update gen_updates = [op for op in update_ops if op.name.startswith('generator')] # Optimizers with tf.control_dependencies(gen_updates): d_train_opt = tf.train.AdamOptimizer(learning_rate=lr_D, beta1=beta1).minimize(d_loss, var_list=d_vars) g_train_opt = tf.train.AdamOptimizer(learning_rate=lr_G, beta1=beta1).minimize(g_loss, var_list=g_vars) return d_train_opt, g_train_opt
Обучение
Теперь реализуем обучающую функцию. Идея довольно проста:
- Сохраняем нашу модель раз в пять периодов (epoch).
- Сохраняем картинку в папке с изображениями через каждые 10 обученных пакетов (batches).
- Через каждые 15 периодов отображаем
g_loss,d_lossи сгенерированное изображение. Это нужно потому, что Jupyter notebook может сбоить при отображении слишком большого количества картинок. - Или можем напрямую генерировать настоящие изображения, загружая сохранённую модель (это сэкономит 20 часов обучения).
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha): """ Train the GAN :param epoch_count: Number of epochs :param batch_size: Batch Size :param z_dim: Z dimension :param learning_rate: Learning Rate :param beta1: The exponential decay rate for the 1st moment in the optimizer :param get_batches: Function to get batches :param data_shape: Shape of the data :param data_image_mode: The image mode to use for images ("RGB" or "L") """ # Create our input placeholders input_images, input_z, lr_G, lr_D = model_inputs(data_shape[1:], z_dim) # Losses d_loss, g_loss = model_loss(input_images, input_z, data_shape[3], alpha) # Optimizers d_opt, g_opt = model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1) i = 0 version = "firstTrain" with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # Saver saver = tf.train.Saver() num_epoch = 0 if from_checkpoint == True: saver.restore(sess, "./models/model.ckpt") show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, True, False) else: for epoch_i in range(epoch_count): num_epoch += 1 if num_epoch % 5 == 0: # Save model every 5 epochs #if not os.path.exists("models/" + version): # os.makedirs("models/" + version) save_path = saver.save(sess, "./models/model.ckpt") print("Model saved") for batch_images in get_batches(batch_size): # Random noise batch_z = np.random.uniform(-1, 1, size=(batch_size, z_dim)) i += 1 # Run optimizers _ = sess.run(d_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_D: learning_rate_D}) _ = sess.run(g_opt, feed_dict={input_images: batch_images, input_z: batch_z, lr_G: learning_rate_G}) if i % 10 == 0: train_loss_d = d_loss.eval({input_z: batch_z, input_images: batch_images}) train_loss_g = g_loss.eval({input_z: batch_z}) # Save it image_name = str(i) + ".jpg" image_path = "./images/" + image_name show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, True, False) # Print every 5 epochs (for stability overwize the jupyter notebook will bug) if i % 1500 == 0: image_name = str(i) + ".jpg" image_path = "./images/" + image_name print("Epoch {}/{}...".format(epoch_i+1, epochs), "Discriminator Loss: {:.4f}...".format(train_loss_d), "Generator Loss: {:.4f}".format(train_loss_g)) show_generator_output(sess, 4, input_z, data_shape[3], data_image_mode, image_path, False, True) return losses, samples
Как запустить
Всё это можно запустить прямо на своём компьютере, если готовы ждать лет 10. Так что лучше воспользоваться облачными GPU-сервисами вроде AWS или FloydHub. Лично я обучал эту DCGAN в течение 20 часов на Microsoft Azure и их Deep Learning Virtual Machine. У меня нет деловых отношений с Azure, просто мне нравится их клиентское обслуживание.
Если у вас возникли какие-то сложности с запуском на виртуальной машине, обратитесь к этой замечательной статье.
Если улучшите модель, не стесняйтесь сделать pull request.


