
[Советуем почитать] Другие 19 частей цикла
Часть 1: Обзор движка, механизмов времени выполнения, стека вызовов
Часть 2: О внутреннем устройстве V8 и оптимизации кода
Часть 3: Управление памятью, четыре вида утечек памяти и борьба с ними
Часть 4: Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
Часть 5: WebSocket и HTTP/2+SSE. Что выбрать?
Часть 6: Особенности и сфера применения WebAssembly
Часть 7: Веб-воркеры и пять сценариев их использования
Часть 8: Сервис-воркеры
Часть 9: Веб push-уведомления
Часть 10: Отслеживание изменений в DOM с помощью MutationObserver
Часть 11: Движки рендеринга веб-страниц и советы по оптимизации их производительности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 13: Анимация средствами CSS и JavaScript
Часть 14: Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Часть 15: Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
Часть 16: Как работает JS: системы хранения данных
Часть 17: Как работает JS: технология Shadow DOM и веб-компоненты
Часть 18: Как работает JS: WebRTC и механизмы P2P-коммуникаций
Часть 19: Как работает JS: пользовательские элементы
Часть 2: О внутреннем устройстве V8 и оптимизации кода
Часть 3: Управление памятью, четыре вида утечек памяти и борьба с ними
Часть 4: Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
Часть 5: WebSocket и HTTP/2+SSE. Что выбрать?
Часть 6: Особенности и сфера применения WebAssembly
Часть 7: Веб-воркеры и пять сценариев их использования
Часть 8: Сервис-воркеры
Часть 9: Веб push-уведомления
Часть 10: Отслеживание изменений в DOM с помощью MutationObserver
Часть 11: Движки рендеринга веб-страниц и советы по оптимизации их производительности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 13: Анимация средствами CSS и JavaScript
Часть 14: Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Часть 15: Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
Часть 16: Как работает JS: системы хранения данных
Часть 17: Как работает JS: технология Shadow DOM и веб-компоненты
Часть 18: Как работает JS: WebRTC и механизмы P2P-коммуникаций
Часть 19: Как работает JS: пользовательские элементы
Сегодня мы публикуем перевод 18 части серии материалов, посвящённых всему, что связано с JavaScript. Здесь мы поговорим о технологии WebRTC, которая направлена на организацию прямого обмена данными между браузерными приложениями в реальном времени.
Обзор
Что такое WebRTC? Для начала стоит сказать, что аббревиатура RTC расшифровывается как Real Time Communication (связь в режиме реального времени). Уже одно это даёт немало информации о данной технологии.
WebRTC занимает весьма важную нишу среди механизмов веб-платформы. Ранее P2P-технологии (peer-to-peer, соединения типа «точка-точка», одноранговые, пиринговые сети), используемые такими приложениями, как настольные чаты, давали им возможности, которых не было у веб-проектов. WebRTC меняет ситуацию в лучшую для веб-технологий сторону.
WebRTC, если рассматривать эту технологию в общих чертах, позволяет веб-приложениям создавать P2P-соединения, о которых мы поговорим ниже. Кроме того, мы затронем здесь следующие темы для того, чтобы показать полную картину внутреннего устройства WebRTC:
- P2P-коммуникации.
- Файрволы и технология NAT Traversal.
- Сигналирование, сессии и протоколы.
- API WebRTC.
P2P-коммуникации
Предположим, два пользователя запустили, каждый в своём браузере, приложение, которое позволяет организовать видеочат с использованием WebRTC. Они хотят установить P2P-соединение. После того, как решение принято, нужен механизм, который позволяет браузерам пользователей обнаружить друг друга и наладить связь с учётом имеющихся в системах механизмов защиты информации. После установки связи пользователи смогут обмениваться мультимедийной информацией в реальном времени.
Одна из главных сложностей, связанных с P2P-соединениями браузеров заключается в том, что браузерам сначала надо обнаружить друг друга, после чего — установить сетевое соединение, основанного на сокетах для обеспечения двунаправленной передачи данных. Предлагаем обсудить сложности, связанные с установкой подобных соединений.
Когда веб-приложению нужны какие-то данные или ресурсы, оно загружает их с сервера и на этом всё заканчивается. Адрес сервера известен приложению. Если же речь идёт, например, о создании P2P-чата, работа которого основана на прямом соединении браузеров, адреса этих браузеров заранее неизвестны. В результате для того, чтобы установить P2P-соединение, придётся справиться с некоторыми проблемами.
Файрволы и протокол NAT Traversal
Обычные компьютеры, как правило, не имеют назначенных им статических внешних IP-адресов. Причина этого заключается в том, что подобные компьютеры обычно находятся за файрволами и NAT-устройствами.
NAT — это механизм, который транслирует внутренние локальные IP-адреса, расположенные за файрволом, во внешние глобальные IP-адреса. Технология NAT используется, во-первых, из соображений безопасности, а во-вторых — из-за ограничений, накладываемым протоколом IPv4 на количество доступных глобальных IP-адресов. Именно поэтому веб-приложения, использующие WebRTC, не должны полагаться на то, что текущее устройство имеет глобальный статический IP-адрес.
Посмотрим как работает NAT. Если вы находитесь в корпоративной сети и подключились к WiFi, вашему компьютеру будет назначен IP-адрес, который существует только за вашим NAT-устройством. Предположим, что это — IP-адрес 172.0.23.4. Для внешнего мира, однако, ваш IP-адрес может выглядеть как 164.53.27.98. Внешний мир, в результате, видит ваши запросы как приходящие с адреса 164.53.27.98, но, благодаря NAT, ответы на запросы, выполненные вашим компьютером к внешним сервисам, будут отправлены на ваш внутренний адрес 172.0.23.4. Это происходит с использованием таблиц трансляций. Обратите внимание на то, что в дополнение к IP-адресу для организации сетевого взаимодействия нужен ещё и номер порта.
Учитывая то, что в процесс взаимодействия вашей системы с внешним миром вовлечён NAT, вашему браузеру, для установления WebRTC-соединения, нужно узнать IP-адрес компьютера, на котором работает браузер, с которым вы хотите связаться.
Именно здесь на сцену выходят серверы STUN (Session Traversal Utilities for NAT) и TURN (Traversal Using Relays around NAT). Для обеспечения работы технологии WebRTC сначала делается запрос к STUN-серверу, направленный на то, чтобы узнать ваш внешний IP-адрес. Фактически, речь идёт о запросе, выполняемом к удалённому серверу с целью выяснить то, с какого IP-адреса сервер получает этот запрос. Удалённый сервер, получив подобный запрос, отправит ответ, содержащий видимый ему IP-адрес.
Исходя из предположения работоспособности этой схемы и того, что вы получили сведения о своём внешнем IP-адресе и порте, затем вы можете сообщить другим участникам системы (будем называть их «пирами») о том, как связаться с вами напрямую. Эти пиры, кроме того, могут сделать то же самое, используя STUN или TURN-серверы, и могут сообщить вам о том, какие адреса назначены им.
Сигналирование, сессии и протоколы
Процесс выяснения сетевой информации, описанный выше, является одной из частей большой системы сигналирования, которая основана, в случае с WebRTC, на стандарте JSEP (JavaScript Session Establishment Protocol). Сигналирование включает в себя обнаружение сетевых ресурсов, создание сессий и управление ими, обеспечение безопасности связи, координацию параметров медиаданных, обработку ошибок.
Для того чтобы соединение работало, пиры должны договориться о форматах данных, которыми они будут обмениваться, и собрать сведения о сетевых адресах компьютера, на котором работает приложение. Механизм сигналирования для обмена этой важнейшей информацией не является частью API WebRTC.
Сигналирование не определяется стандартом WebRTC, и оно не реализуется в его API для того, чтобы обеспечить гибкость в используемых технологиях и протоколах. За сигналирование и серверы, которые его поддерживают, отвечает разработчик WebRTC-приложения.
Исходя из предположения о том, что ваше WebRTC-приложение, работающее в браузере, способно определить внешний IP-адрес браузера, используя STUN, как описано выше, следующим шагом является шаг обсуждения параметров сессии и установки соединения с другим браузером.
Изначальное обсуждение параметров сессии и установление соединения происходит с использованием протокола сигналирования/связи, специализирующегося на мультимедиа-коммуникациях. Этот протокол, кроме того, отвечает за соблюдение правил, в соответствии с которыми осуществляется управление сессией и её прекращение.
Один из таких протоколов называется SIP (Session Initiation Protocol). Обратите внимание на то, что благодаря гибкости подсистемы сигналирования WebRTC, SIP — это не единственный протокол сигналирования, который можно использовать. Выбранный протокол сигналирования, кроме того, должен работать с протоколом уровня приложения, который называется SDP (Session Description Protocol), который используется при применении WebRTC. Все метаданные, имеющие отношение к мультимедиа-данным, передаются с использованием протокола SDP.
Любой пир (то есть — приложение, использующее WebRTC), который пытается связаться с другим пиром, генерирует набор маршрутов-кандидатов протокола ICE (Interactive Connectivity Establishment). Кандидаты представляют некую комбинацию IP-адреса, порта и транспортного протокола, которые можно использовать. Обратите внимание на то, что один компьютер может обладать множеством сетевых интерфейсов (проводных, беспроводных, и так далее), поэтому ему может быть назначено несколько IP-адресов, по одному на каждый интерфейс.
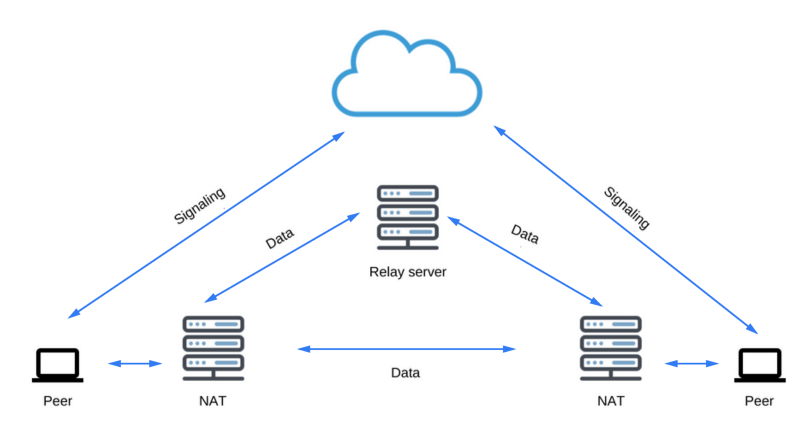
Вот диаграмма с MDN, иллюстрирующая вышеописанный процесс обмена данными.
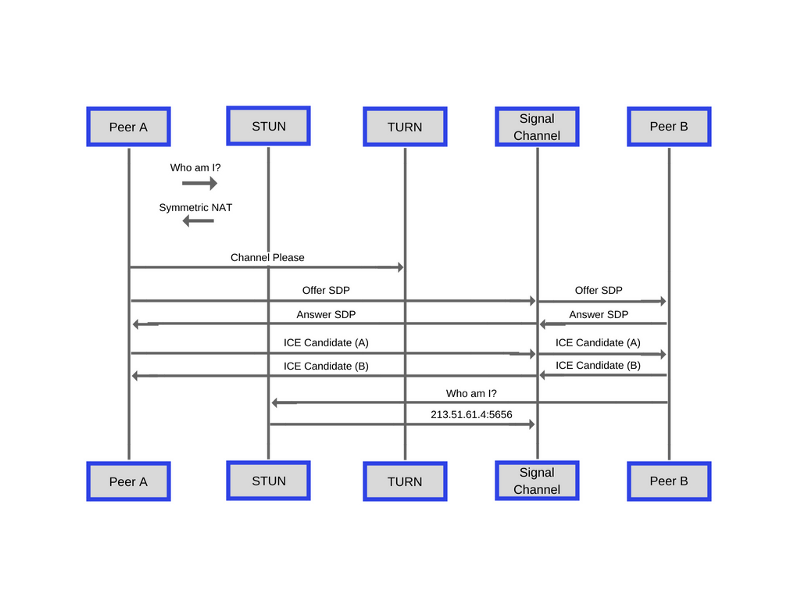
Процесс обмена данными, необходимыми для установления P2P-соединения
Установление соединения
Каждый пир сначала выясняет свой внешний IP-адрес как описано выше. Затем динамически создаются «каналы» сигналирующих данных, служащие для обнаружения пиров и поддержки обмена данными между ними, для обсуждения параметров сессий и их установки.
Эти «каналы» неизвестны и недоступны внешнему миру, для доступа к ним требуется уникальный идентификатор.
Обратите внимание на то, что благодаря гибкости WebRTC, и тому факту, что процесс сигналирования не определён стандартом, концепция «каналов» и порядок их использования могут слегка различаться в зависимости от используемых технологий. На самом деле, некоторые протоколы не требуют наличия механизма «каналов» для организации обмена данными. Мы, для целей этого материала, предполагаем, что «каналы» в реализации системы используются.
Если два или более пиров подключены к одному и тому же «каналу», пиры получают возможность обмениваться данными и обсуждать информацию о сессии. Этот процесс похож на шаблон издатель-подписчик. В целом, инициирующий соединение пир отправляет «предложение», используя протокол сигналирования, такой, как SIP или SDP. Инициатор ожидает получения «ответа» от получателя предложения, который подключён к рассматриваемому «каналу».
После того, как ответ получен, происходит процесс определения и обсуждения лучших ICE-кандидатов, собранных каждым пиром. После того, как выбраны оптимальные ICE-кандидаты, согласовываются параметры данных, которыми будут обмениваться пиры и механизм сетевой маршрутизации (IP-адрес и порт).
Затем устанавливается активная сетевая сокет-сессия между пирами. Далее, каждый пир создаёт локальные потоки данных и конечные точки каналов данных, и начинается двусторонняя передача мультимедиа-данных с использованием применяемой технологии.
Если процесс переговоров о выборе наилучшего ICE-кандидата успехом не увенчался, что иногда происходит по вине файрволов и NAT-систем, используется запасной вариант, заключающийся в применении, в качестве ретранслятора, TURN-сервера. Этот процесс задействует сервер, который работает как посредник, ретранслирующий данные, которыми обмениваются пиры. Обратите внимание на то, что эта схема не является настоящим P2P-соединением, в которой пиры передают данные напрямую друг другу.
При использовании запасного варианта с применением TURN для обмена данными, каждому пиру уже не нужно знать о том, как связываться с другими и как передавать ему данные. Вместо этого пирам нужно знать, какому внешнему TURN-серверу нужно отправлять мультимедийные данные в реальном времени и от какого сервера их нужно получать в течение сеанса связи.
Важно понимать, что сейчас речь шла о резервном способе организации связи. TURN-серверы должны быть весьма надёжными, иметь большую полосу пропускания и серьёзную вычислительную мощность, поддерживать работу с потенциально большими объёмами данных. Использование TURN-сервера, таким образом, очевидно, приводит к дополнительным затратам и к увеличению сложности системы.
API WebRTC
Есть три основных категории API, существующих в WebRTC:
- API Media Capture and Streams ответственно за захват мультимедиа-данных и работу с потоками. Это API позволяет подключаться к устройствам ввода, таким, как микрофоны и веб-камеры, и получать от них потоки медиа-данных.
- API RTCPeerConnection . Используя API данной категории можно, с одной конечной точки WebRTC, отправлять, в реальном времени, захваченный поток аудио или видеоданных через интернет другой конечной точке WebRTC. Используя это API можно создавать соединения между локальной машиной и удалённым пиром. Оно предоставляет методы для соединения с удалённым пиром, для управления соединением и для отслеживания его состояния. Его же механизмы используются для закрытия ненужных соединений.
- API RTCDataChannel . Механизмы, представленные этим API, позволяют передавать произвольные данные. Каждый канал данных (data channel) связан с интерфейсом RTCPeerConnection.
Поговорим об этих API.
API Media Capture and Streams
API Media Capture and Streams, которое часто называют Media Stream API или Stream API — это API, которое поддерживает работу с потоками аудио и видео-данных, методы для работы с ними. Средствами этого API задаются ограничения, связанные с типами данных, здесь имеются коллбэки успешного и неуспешного завершения операций, применяемые при использовании асинхронных механизмов работы с данными, и события, которые вызываются в процессе работы.
Метод
getUserMedia() API MediaDevices запрашивает у пользователя разрешение на работу с устройствами ввода, которые производят потоки MediaStream со звуковыми или видео-дорожками, содержащими запрошенные типы медиаданных. Такой поток может включать, например, видеодорожку (её источником является либо аппаратный либо виртуальный видеоисточник, такой как камера, устройство для записи видео, сервис совместного использования экрана и так далее), аудиодорожку (её, похожим образом, могут формировать физические или виртуальные аудиоисточники, наподобие микрофона, аналогово-цифрового конвертера, и так далее), и, возможно, дорожки других типов.Этот метод возвращает промис, который разрешается в объект MediaStream. Если пользователь отклонил запрос на получение разрешения, или соответствующие медиаданные недоступны, тогда промис разрешится, соответственно, с ошибкой
PermissionDeniedError или NotFoundError.Доступ к синглтону
MediaDevice можно получить через объект navigator:navigator.mediaDevices.getUserMedia(constraints) .then(function(stream) { /* использовать поток */ }) .catch(function(err) { /* обработать ошибку */ });
Обратите внимание на то, что при вызове метода
getUserMedia() ему нужно передать объект constraints, который сообщает API о том, какой тип потока оно должно вернуть. Тут можно настраивать много всего, включая то, какую камеру требуется использовать (переднюю или заднюю), частоту кадров, разрешение, и так далее.Начиная с версии 25, браузеры, основанные на Chromium, позволяют передавать аудиоданные из
getUserMedia() аудио- или видео-элементам (однако, обратите внимание на то, что по умолчанию медиа-элементы будут отключены).Метод
getUserMedia() так же может быть использован как узел ввода для Web Audio API:function gotStream(stream) { window.AudioContext = window.AudioContext || window.webkitAudioContext; var audioContext = new AudioContext(); // Создать AudioNode из потока var mediaStreamSource = audioContext.createMediaStreamSource(stream); // Подключить его к целевому объекту для того, чтобы слышать самого себя, // или к любому другому узлу для обработки! mediaStreamSource.connect(audioContext.destination); } navigator.getUserMedia({audio:true}, gotStream);
Ограничения, связанные с защитой личной информации
Несанкционированный захват данных с микрофона или камеры — это серьёзное вмешательство в личную жизнь пользователя. Поэтому использование
getUserMedia() предусматривает реализацию весьма специфических требований по оповещению пользователя о происходящем и по управлению разрешениями. Метод getUserMedia() всегда должен получать разрешение пользователя перед открытием любого устройства ввода, собирающего медиаданные, такого, как веб-камера или микрофон. Браузеры могут предлагать возможность однократной установки разрешения для домена, но они обязаны запросить разрешение, как минимум, при первой попытке обращения к медиа-устройствам, и пользователь должен явно дать подобное разрешение.Кроме того, тут важны правила, связанные с уведомлением пользователя о происходящем. Браузеры обязаны отображать индикатор, который указывает на использование микрофона или камеры. Отображение подобного индикатора не зависит от наличия в системе аппаратных индикаторов, указывающих на работу подобных устройств. Кроме того, браузеры должны показывать индикатор того, что на использование устройства ввода дано разрешение, даже если устройство в некий момент времени не используется для записи соответствующих данных.
Интерфейс RTCPeerConnection
Интерфейс RTCPeerConnection представляет собой WebRTC-соединение между локальным компьютером и удалённым пиром. Он предоставляет методы для подключения к удалённой системе, для поддержки соединения и мониторинга его состояния, и для закрытия соединения после того, как оно больше не нужно.
Вот диаграмма архитектуры WebRTC, демонстрирующая роль RTCPeerConnection.
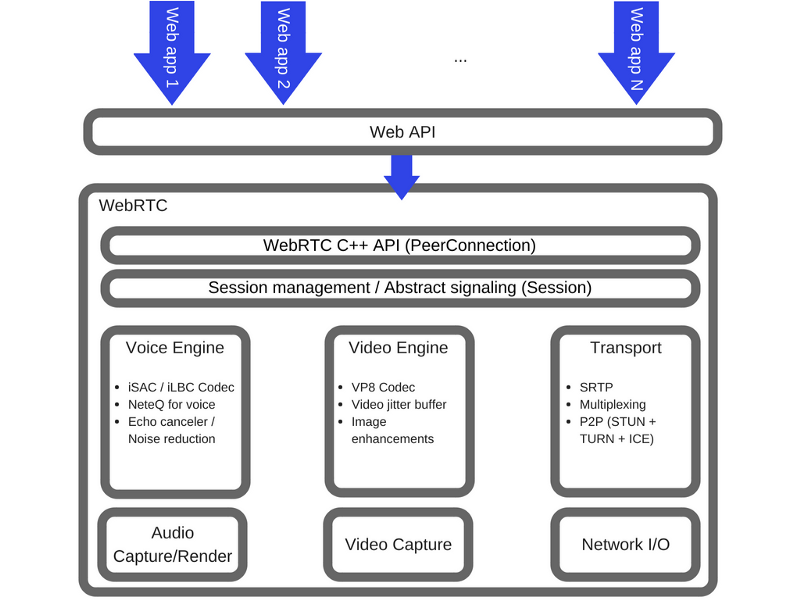
Роль RTCPeerConnection
С точки зрения JavaScript, главное знание, которое можно извлечь из анализа этой диаграммы, заключается в том, что RTCPeerConnection абстрагирует веб-разработчика от сложных механизмов, расположенных на более глубоких уровнях системы. Кодеки и протоколы, используемые WebRTC, выполняют огромную работу для того, чтобы сделать возможным обмен данными в реальном времени, причём, даже при использовании ненадёжных сетей. Вот некоторые из задач, решаемые этими механизмами:
- Маскирование потери пакетов.
- Подавление эхо.
- Адаптация полосы пропускания.
- Динамическая буферизация для устранения «дрожания».
- Автоматический контроль уровня громкости.
- Уменьшение и подавление шума.
- «Очистка» изображения.
API RTCDataChannel
Так же, как в случае с аудио- и видео-данными, WebRTC поддерживает передачу в реальном времени других типов данных. API RTCDataChannel позволяет организовать P2P-обмен произвольными данными.
Существует множество сценариев использования этого API. Вот некоторые из них:
- Игры.
- Текстовые чаты реального времени.
- Передача файлов.
- Организация децентрализованных сетей.
Это API ориентировано на максимально эффективное использование возможностей API RTCPeerConnection и позволяет организовать мощную и гибкую систему обмена данными в P2P-среде. Среди его возможностей можно отметить следующие:
- Эффективная работа с сессиями с применением RTCPeerConnection.
- Поддержка множества одновременно используемых каналов связи с приоритизацией.
- Поддержка надёжных и ненадёжных методов доставки сообщений.
- Встроенные средства управления безопасностью (DTLS) и перегрузками.
Синтаксис тут похож на тот, который используется при работе с технологией WebSocket. Здесь применяется метод
send() и событие message:var peerConnection = new webkitRTCPeerConnection(servers, {optional: [{RtpDataChannels: true}]} ); peerConnection.ondatachannel = function(event) { receiveChannel = event.channel; receiveChannel.onmessage = function(event){ document.querySelector("#receiver").innerHTML = event.data; }; }; sendChannel = peerConnection.createDataChannel("sendDataChannel", {reliable: false}); document.querySelector("button#send").onclick = function (){ var data = document.querySelector("textarea#send").value; sendChannel.send(data); }
WebRTC в реальном мире
В реальном мире для организации WebRTC-коммуникации нужны сервера. Системы это не слишком сложные, благодаря им реализуется выполнение следующей последовательности действий:
- Пользователи обнаруживают друг друга и обмениваются сведениями друг о друге, например, именами.
- Клиентские WebRTC-приложения (пиры) обмениваются сетевой информацией.
- Пиры обмениваются сведениями о медиа-данных, такими, как формат и разрешение видео.
- Клиентские WebRTC-приложения устанавливают соединение, обходя NAT-шлюзы и файрволы.
Другими словами, WebRTC нуждается в четырёх типах серверных функций:
- Средства для обнаружения пользователей и организации их взаимодействия.
- Сигналирование.
- Обход NAT и файрволов.
- Серверы-ретрансляторы, используемые в тех случаях когда не удаётся установить P2P-соединение.
Протокол STUN и его расширение TURN используются ICE для того, чтобы позволить RTCPeerConnection работать с механизмами обхода NAT и справляться с другими сложностями, возникающими при передаче данных по сети.
Как уже было сказано, ICE — это протокол для соединения пиров, таких, как два клиента видеочата. В самом начале сеанса связи ICE пытается соединить пиров напрямую, с наименьшей возможной задержкой, через UDP. В ходе этого процесса у STUN-серверов имеется единственная задача: позволить пиру, находящемуся за NAT, узнать свой публичный адрес и порт. Взгляните на этот список доступных STUN-серверов (такие серверы есть и у Google).
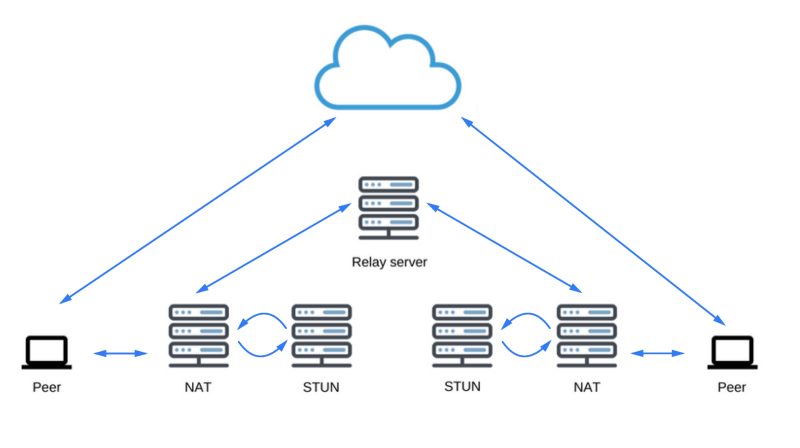
STUN-серверы
Обнаружение ICE-кандидатов
Если UDP-подключение установить не удаётся, ICE пробует установить TCP-соединение: сначала — по HTTP, потом — по HTTPS. Если прямое соединение установить не получается — в частности из-за невозможности обхода корпоративных NAT и файрволов, ICE использует посредника (ретранслятор) в виде TURN-сервера. Другими словами, ICE сначала попытается использовать STUN с UDP для прямого соединения пиров, и, если это не получится, воспользуется запасным вариантом с рентанслятором в виде TURN-сервера. Выражение «поиск кандидатов» относится к процессу поиска сетевых интерфейсов и портов.
Поиск подходящих сетевых интерфейсов и портов
Безопасность
Приложения для организации связи в реальном времени или соответствующие плагины могут привести к проблемам с безопасностью. В частности, речь идёт о следующем:
- Незашифрованные медиа-данные или другие данные могут быть перехвачены по пути между браузерами, или между браузером и сервером.
- Приложение может, без ведома пользователя, записывать и передавать злоумышленнику видео- и аудио-данные.
- Вместе с безобидно выглядящим плагином или приложением на компьютер пользователя может попасть вирус или другое вредоносное ПО.
В WebRTC имеются несколько механизмов, предназначенных для борьбы с этими угрозами:
- Реализации WebRTC используют безопасные протоколы вроде DTLS и SRTP.
- Для всех компонентов WebRTC-систем обязательно использование шифрования. Это относится и к механизмам сигналирования.
- WebRTC — это не плагин. Компоненты WebRTC выполняются в песочнице браузера, а не в отдельном процессе. Компоненты обновляются при обновлении браузера.
- Доступ к камере и микрофону должен даваться в явном виде. И, когда камера или микрофон используются, этот факт чётко отображается в пользовательском интерфейсе браузера.
Итоги
WebRTC — это весьма интересная и мощная технология для проектов, в рамках которых используется передача каких-либо данных между браузерами в реальном времени. Автор материала говорит, что в его компании, SessionStack, используют традиционные механизмы обмена данными с пользователями, предусматривающие применение серверов. Однако, если бы они использовали WebRTC для решения соответствующих задач, это позволило бы организовывать обмен данными напрямую между браузерами, что привело бы к уменьшению задержки при передачи данных и к сокращению нагрузки на инфраструктуру компании.
Уважаемые читатели! Пользуетесь ли вы технологией WebRTC в своих проектах?

