Привет, Хабр! Продолжаем серию статей об участии команды из Санкт-Петербургского Государственного Университета (мы называем себя EnterTildeDot) на крупнейших в мире студенческих суперкомпьютерных соревнованиях.

В этой статье мы рассмотрим путь на ASC’18 на примере одного участника команды, уделив особое внимание визитной карточке соревнований и современных суперкомпьютеров в целом — Linpack. Ну что ж, давайте посмотрим на секрет достижения рекорда и антирекорда производительности вычислительной системы.
Краткий экскурс по суперкомпьютерным соревнованиям
Общую информацию о том, что же это за соревнования такие можно найти в наших прошлых статьях, включая длиннопост про конкурс этого года. Тем не менее, для полноты картины, некоторую информацию про конкурс в целом, мы всё же приведем и здесь.
Asian Supercomputer Challenge — одно из трёх основных командных соревнований по высокопроизводительным вычислениям, ежегодно привлекающее к участию всё больше и больше студенческих команд со всего мира. ASC, как и другие подобные соревнования предполагает наличие отборочного и финального тура со следующими положениями:
- Основной вид деятельности: решение HPC задач;
- Команда: 5 студентов + тренер;
- Отборочный этап: заочное описание proposal с описанием решения представленных задач, на основе которого определяется список из 20 финалистов.
- Заключительный этап: очное соревнование для 20 команд длительностью около 5 соревновательных дней, включающее полную сборку и настройку вычислительного кластера, решение задач, презентацию. Кластер собирается исходя из ограничений на мощность в 3 кВт, либо из предоставленного организаторами железа, либо из собственного. Кластер не имеет выхода в интернет. Задачи частично совпадают с заданиями отборочного этапа, однако присутствует и неизвестное задание — Mystery Application.
Ну что ж, а теперь по порядку с отступлениями на ликбез. В отличие от остальных участников команды, которые уже выходили в финал ASC’17, я влился в конкурсное движение только в этом году. Я пришел в команду в сентябре, задания отборочного этапа рассылаются лишь в январе, так что у меня было достаточно времени, чтобы изучить основные концепции конкурса, а также заняться проработкой единственного заранее известного задания — HPL&HPCG. Задание в том или ином виде встречается почти каждый год, однако не всегда заранее известно на каком оборудовании необходимо выполнять задание (иногда организаторы предоставляют удаленный доступ к собственным ресурсам).
HPL
HPL (High Performance Computing Linpack Benchmark) — тест производительности вычислительной системы, на основе результатов которого формируется современный список лучших в мире суперкомпьютеров. Суть теста заключается в решении плотных систем линейных алгебраических уравнений. Появление данного бенчмарка ввело метрику, позволяющую ранжировать суперкомпьютеры, вместе с тем оказав своим появлением некоторую “медвежью услугу” HPC сообществу. Если посмотреть на список лучших суперкомпьютеров, то можно понять, что секрет Линпака был разгадан довольно таки быстро — возьми так много графических ускорителей, сколько только сможешь и будешь в топе. Разумеется, есть и исключения, но преимущественно верхние места занимают именно суперкомпьютеры с графическими ускорителями. В чем же заключается “медвежья услуга”? Дело в том, что кроме измерения производительности, Линпак не используется нигде более и не имеет ничего общего с реальными вычислительными задачами. В результате, суперкомпьютерная гонка ушла в сторону получения наибольшей эффективности Линпака, а не реальных workload-ов, подобно нарешиванию типовых задачек ЕГЭ вместо освоения школьной программы.
Разработчиками HPL был также создан еще один пакет — HPCG, на основе которого также формируется рейтинг суперкомпьютеров. Принято считать, что данный бенчмарк наиболее близок к реальным задачам, чем HPL, и, в некотором роде, значительное несоответствие позиций суперкомпьютера в этих двух списках отражает реальное положение дел. Однако последние рейтинги (June 2018) стали приятным исключением, и, наконец-то, первые позиции списков совпали.
А теперь про настоящий HPL
Возвращаемся к более практическим моментам рассказа и конкурсу. Линпак опенсурсен, доступен к скачиванию на официальном сайте, однако, едва ли в мировом топе действительно есть суперкомпьютер, производительность которого была измерена именно этой версией бенчмарка. Производители ускорителей выпускают собственные версии HPL, оптимизированные под конкретные устройства, что позволяет получить значительный выигрыш в производительности. Безусловно, кастомные версии HPL должны удовлетворять определенным критериям и должны успешно проходить специальные тесты.
Собственная версия HPL есть у каждого вендора под каждый ускоритель, однако, в отличии от оригинального бенчмарка, ни о каком open-source тут уже речь не идёт. Nvidia выпускает версии HPL, оптимизированные под каждую из карточек, при этом код поставляется уже не в виде исходников, а бинарниками. Кроме того, существует только два способа получить доступ к ним:
- У Вас есть суперкомпьютер с карточками Nvidia, способный войти в топ — Nvidia найдет Вас сама. Увы, но бинарники Вы скорее всего не получите, ровно как и не будет возможности поучаствовать в оптимизации параметров HPL. Так или иначе, вы получите адекватное значение производительности, полученное на оптимизированном бенчмарке.
- Вы — участник одного из трех студенческих суперкомпьютерных соревнований. Но к этой части мы еще вернемся.
Так в чем же всё таки суть задания, особенно если умные дяди из крупных компаний уже оптимизировали бенчмарк под ваше оборудование?
В случае отборочного этапа конкурса — описать возможные действия по увеличению производительности системы. В данном случае, гнаться за абсолютными числами производительности не приходится, так как у одних команд может быть доступ к большому и классному кластеру из 226 узлов с современными ускорителями, а у других — только к университетскому компьютерному классу номер 226, который мы называем кластером.

В случае заключительного этапа, уже имеет смысл сравнивать абсолютные значения производительности. Не сказать, что тут все находятся в равных условиях, но по крайней мере есть ограничение на допустимую максимальную мощность системы.
Результат выполнения бенчмарка преимущественно зависит от двух компонент: конфигурации кластера и настройки параметров непосредственно бенчмарка. Также стоило бы отметить и влияние выбора компиляторов и библиотек для матричных и векторных вычислений, однако тут всё довольно таки скучно, все используют компилятор от Intel + MKL. А в случае бинарников и вовсе выбирать не приходится, так как они уже собраны. Результатом выполнения HPL является численное значение, показывающее, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система. Основная единица измерения — FLOPS (FLoating-point Operations Per Second) с соответствующими приставками. В случае заключительного этапа соревнований, почти всегда речь идёт о Тера-скейл системах.
Оптимизация результатов
Настройка параметров бенчмарка заключается в осмысленном подборе входных данных вычисляемой Линпаком задачи (HPL.dat файл). В данном случае, наибольшее влияние оказывает размерность этой задачи — размер матрицы, размер блоков на которые разбивается матрица, в каком соотношении распределять блоки и т.д… В общей сложности параметров несколько десятков, возможных значений — тысячи. Брутфорс — не лучший выбор, особенно при условии, что тест на относительно небольших системах выполняется от пары минут до пары часов, в зависимости от конфигурации (для GPU тест выполняется значительно быстрее).
У меня было достаточно времени, чтобы изучить, как уже описанные в других источниках закономерности, способствующие оптимизации результатов бенчмарка, так и выявить новые. Я стал запускать тесты огромное количество раз, заводил множество гугл табличек, пытался получить доступ к системам с неопробованной ранее конфигурацией, чтобы запустить бенчмарк и на них. В результате, еще до начала отборочного этапа был протестирован ряд систем, как CPU, так и GPU, включая даже совершенно неподходящие для этого Nvidia Quadro P5000. К моменту начала отборочного этапа, мы получили доступ к нескольким узлам с P100 и P6000, что очень сильно помогло нам в подготовке. Конфигурация данной системы во многом была похожа на ту, что мы планировали собирать в рамках заключительного этапа конкурса, а также, мы наконец получили доступ к низкоуровневым настройкам, включая изменение частоты.
Что касается конфигурации, наибольшее влияние оказывает наличие и количество ускорителей. В случае тестирования системы с GPU, наиболее оптимальным является вариант, когда основная вычислительная часть задачи делегируется именно GPU составляющей. CPU-компонента при этом также будет загружена вспомогательными задачами, однако вклад в производительность системы вносить не будет. Но при этом пиковая производительность CPU обязана быть учтена в пиковой производительности системы в целом, что может смотреться крайне невыгодно с точки зрения отношения максимальной производительности к пиковой (теоретической). При запуске HPL на GPU, система с 2 GPU ускорителями и двумя процессорами будет как минимум не уступать системе с 2 GPU и 20 CPU.
Описав предложения по возможной оптимизации результатов HPL, я закончил со своей частью proposal-а для отборочного этапа, и, пройдя в финал соревнований, начался новый этап соревнований — поиск спонсоров. С одной стороны, мы нуждались в спонсоре, который возьмет на себя расходы на перелет команды в Китай, с другой стороны — спонсор, который любезно согласится предоставить команде графические ускорители. С первым нам в конечном счете повезло, некоторую часть денег выделил университет, а полностью покрыть билеты помогла компания Devexperts. Со спонсорами же, у которых мы планировали одолжить карточки, повезло меньше, и вот мы снова летим в финал с базовой конфигурацией кластера без единого шанса на конкурентоспособность в HPL. Ну ничего, выжмем по максимуму из того что дадут, думали мы.
Финал ASC’18
И вот мы в Китае, в крошечном по Китайским меркам городке — Наньчанге, в финале. Два дня собираем кластер, а дальше — задачки.

В этом году всем командам предоставили по 4 карточки Nvidia V100, преимущества над другими командами нам это не дало, но зато дало возможность запускать HPL не на CPU. Узлов изначально всем дают по 10, однако лишние (помним про ограничение на 3 кВт) необходимо вернуть прежде чем наступит этап выполнения основных конкурсных заданий. Здесь есть некоторая хитрость — снижая частоту CPU и GPU, снижается их производительность, однако можно подобрать такие значения для частоты, что за единицу потребляемой энергии мы получаем большую производительность. Снижая частоту, мы получаем возможность добавить еще больше ускорителей, что в конечном счете скажется на производительности в лучшую сторону. Увы, данная хитрость пригодилась бы нам куда больше, если бы мы приехали на конкурс с чемоданом ускорителей, как другие участники. Тем не менее, мы смогли позволить себе оставить максимальное количество CPU. Так как не все задания конкурса требуют GPU, то было подозрение, что в некотором роде это может сыграть нам на руку.
Так, наиболее распространенная конфигурация кластера в финале конкурса — минимум узлов, максимум карточек.
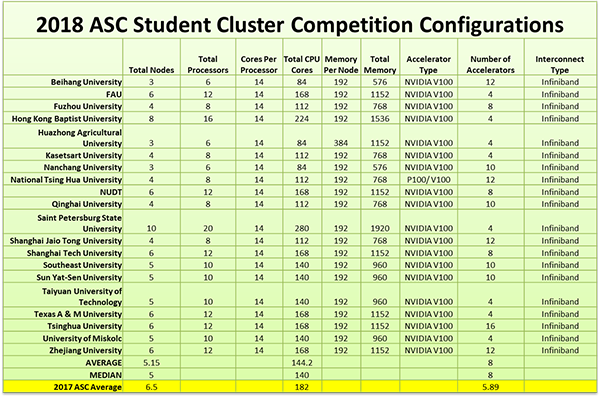
Финальный линпак и немного о рекордах
Задачи на конкурсе были привязаны к определенным соревновательным дням, и HPL стал первой из них, разумеется, после сборки кластера. Дедлайн подачи результатов HPL — обед третьего соревновательного дня, кроме того, доступ к остальным заданиям этого соревновательного дня открывается сразу после сдачи Линпака. Тем не менее, Линпак начинают гонять уже в первые дни. Во-первых, чтобы убедиться, что кластер собран корректно, а во-вторых, настройка Линпака дело не быстрое, и так как никаких дополнительных входных данных не требуется, то почему бы и нет.
Мы собрали свой кластер довольно таки быстро и принялись в том числе и за Линпак. Для своей конфигурации мы получали вполне адекватные значения — порядка 20 TFlops, и всё бы ничего, да вот после вывода результата была строка с ошибкой. Ранее подобные ошибки я получал лишь когда намеренно указывал некорректные размеры блоков, на которые делится матрица задачи. Тут нас ждала очень неприятная неожиданность. Ранее я рассказывал, что нам дали 4 карточки V100, ну так вот… Бинарники HPL мы для них не получили и никто нам с этим помочь не мог. Прошло уже несколько месяцев, а для меня всё еще загадка, что же произошло на том финале с нашим Линпаком. Мы меняли версии компиляторов и прочих библиотек в надежде избавиться от ошибки, многократно проверяли правильно ли мы поставили ускорители (так как делали мы это впервые), но исправить ошибку нам так и не удалось.

В ночь перед сдачей Линпака мы еще раз внимательно изучили критерии оценивания заданий, так вот, для Линпака формула состояла из двух компонент — некоторое значение, зависящее от результата команды, которая выиграет Линпак, и коэффициент за успешное выполнение задания. Так оказалось, что этот коэффициент настолько большой, что сдавать адекватное значение Линпака, но с непонятной ошибкой совершенно невыгодно по сравнению со сдачей любого значения, но без ошибки. Тщательно всё обдумав, с учетом того, что на поиск решения ошибки было потрачено много времени и, что получение датасетов от следующих заданий полностью зависит от времени сдачи Линпака, мы решили тактически слить это задание. Так был установлен абсолютный “рекорд” в истории суперкомпьютерных соревнований среди корректных значений. Наш Линпак разразился значением 0.01 TFlops. Безусловно, оптимизировав бенчмарк под имеющиеся CPU, мы бы получили несколько большее значение производительности, однако на баллах бы это отразилось не сильно, а времени потрачено было бы значительно больше. Помним, что на CPU Линпак работает намного дольше. Лучший результат показал университет National Tsing Hua University — 43 TFlops. Спустя день-два, Jack Dongarra (создатель Линпака), входящий в оргкомитет соревнования, невзначай поинтересовался у нас, мол как там Линпак? По-видимому, на тот момент он еще не видел доску с результатами: его WHAAAT-реакция стоила каждого часа, потраченного нами на HPL.

Mystery Application
Сдав бенчмарки, согласно подготовленному заранее плану, я влился в часть команды, которая должна была заниматься Mystery Application. Что это будет за задание заранее никто не знал, так что готовились к худшему — заранее устанавливали с флешки на кластер всё, что только может пригодиться. Как правило, основная сложность заданий из этой секции — собрать их. В этот раз всё оказалось несколько иначе. Приложение собрали чуть ли не с первого раза, без каких либо проблем. Проблемы начались, когда на большинстве из представленных dataset-ов мы получали ошибку по адресу, при том что это было фортран-приложение. Судя по доске с результатами, не только у нас это задание вызвало проблемы.
Секретное оружие: CPU
Ну что ж, последнее задание, в котором я принимал участие, было запланировано на следующий соревновательный день. В отличии от Mystery Application, мы ранее уже видели пакет с которым нам предстояло работать — это был cfl3d. Когда мы узнали, что это продукт NASA, почему-то все обрадовались, думая, что уж там то точно всё будет хорошо и со сборкой, и с оптимизацией. Когда мы тестировали пакет дома, то со сборкой проблем не возникло, а вот примеры использования были весьма интересные. У большинства примеров были зависимости на установку дополнительных средств, случалось и такое, что в попытке загуглить один из таких инструментов — инструмент XX, мы находили статью года 1995, где было сказано, что теперь инструмент XX устарел и используйте YY. Сайт продукта из тех же времен — документация частенько отправляла пользователя на страницы сайта, но вот только сайт на фреймах и дальше главной страницы уйти не получится. Актуальность примеров оставляла желать лучшего.
Если совсем просто, то суть задания заключалась в хитром разбиении многоуровневого грида с сохранением заданного уровня точности. Разумеется, основной метрикой тут было время. Как-то так случилось, что в этот день мы уже были максимально расслаблены и просто делали, что должны были. Задача была для CPU, а это именно то, чего у нас было много. Входные файлы задачи имели весьма специфический вид и, зачастую, большой размер — до сотен строчек. Членом нашей команды был написан скрипт, который автоматизировал процесс формирования входного файла, что ускорило процесс, вероятно, в сотни раз. В конечном счете, все датасеты были успешно завершены и оптимизированы, оставалось даже время попытаться пересобрать пакет с какими-нибудь интересными опциями, но особого ускорения мы уже не получили. Это задание мы выполнили лучше других, получив специальный приз Application Innovation, а также 11 место в общекомандном зачете (из 20 в финале, из 300+ среди всех участников конкурса).

Таблица с конфигурациями вычислительных систем, а также главное фото взяты с сайта http://www.hpcwire.com/.

