Если вы достаточно долго увлекаетесь нейросетевыми технологиями, то наверняка встречались с мнением, кратко заключенным в риторическом вопросе: «Как ты объяснишь человеку, когда нейросеть считает, что у него рак?». И если в лучшем случае такие мысли заставят тебя сомневаться в использовании нейросетей в достаточно ответственных сферах, то в худшем случае ты можешь и потерять весь свой интерес.
Мне попался лучший вариант — я спокойно принимал такую ограниченность и, особо не задумываясь, продолжал применять нейросетевые технологии в сфере компьютерного зрения.
Задача
Недавно на меня выпала задача — максимально быстро создать работоспособный детектор эмоций. Условия были поставлены достаточно четко — фронтально расположенное лицо разрешением 100х100. В поисках готового датасета я потратил пару часов и понял, что мне практически ничего не подходит. Либо же даже в «исследовательских целях» получить доступ к датасету было слишком трудно. Выход был найден быстро — взять десяток художественных фильмов и простым прогоном по ним каскада Хаара выгрузить все лица. За ночь было получено более(!) 30к изображений. Далее полученные изображения были рассортированы по 5 основным эмоциям(happy, sad, neutral, angry, surprised). Конечно, далеко не все изображения подошли и в итоге на каждую категорию пришлось по 400-500 изображений лиц.
Тут то всё и завязалось с темой объяснения результатов работы нейронных сетей. Даже имея достаточно качественную кастомную аугментацию данных, такой набор данных казался явно недостаточным. При обучении сети на основе блоков Resnet получились следующие цифры для метрик:

На лицо переобучение на фоне недостаточного числа примеров, но из-за неимения времени необходимо было срочно убедиться, что сеть работает хоть сколько-то удовлетворительно и при определении эмоций не полагается, например, на фон.
Раньше мне уже приходилось работать с такими инструментами как Lime и Keras-Vis, но именно тут они могли стать философским камнем, превращающим черный ящик в нечто более прозрачное. Суть обоих инструментов примерно одинакова — определить области исходного изображения, несущие наибольший вклад в итоговое решение сети. Для теста я снял видео, на котором имитировал различные эмоции. Выгрузив выражения лица, соответствующие различным эмоциям, я прогнал по ним вышеописанные инструменты
Получились следующие результаты от Lime:

К сожалению, даже меняя различные параметры функций, от Lime не удалось получить достаточно человекопонятного отображения. На принадлежность к классу «angry» почему-то влияет правая половина лица. Единственное, что для «happy» логично выделена область рта и типичных для улыбки ямочек.
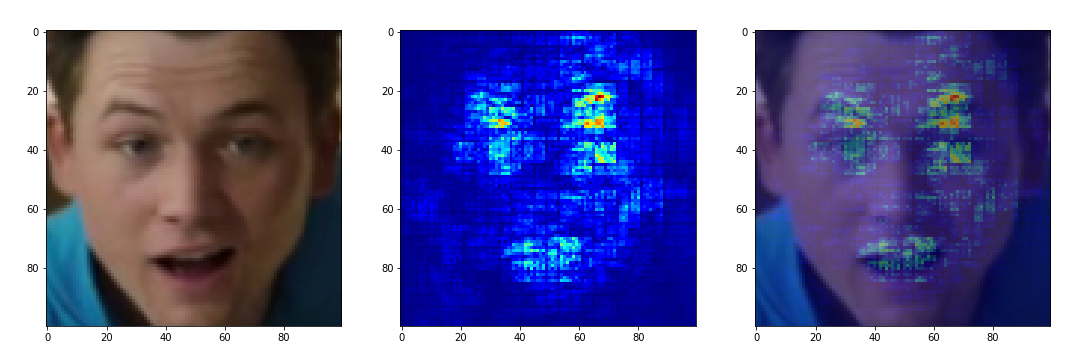
Далее, всё те же изображения были прогнаны через Keras-Vis и бинго:

«Happy» ищет расположение глаз и форму рта. «Sad» ориентируется на опущенные брови и веки. «Neutral» старается смотреть на всё лицо в целом и ни в чем невиновные нижние углы изображения. «Angry» логично ориентируется на сдвинутые брови, НО забывает про форму рта и зачем-то ищет фичи в правом нижнем углу. А «Surprised» смотрит на форму рта и левое(!) приподнятое веко — пора бы начать признавать и правое.
Результаты порадовали и дали возможность увидеть сильные и слабые стороны получившейся сети. Почувствовав слабости в классификации классов «Surprised» и «Angry», я нашел в себе силы слегка увеличить выборку и добавил капельку больше дропаута. На следующей итерации были получены следующие результаты:

Видно, что области активаций в большей степени локализовались. Исчезло внимание сети на фон в случае с «Angry». Конечно, сеть всё ещё имеет свои минусы, забывая про бровь с одной стороны и тд. Но данный подход позволил глубже понять, что и почему делает полученная модель. Данный подход идеален в случаях, когда у нас есть сомнения в правильной сходимости сети.
Выводы
Нейронные сети остаются всего лишь решением сложной задачи оптимизации. Но даже простейшие карты внимания сети вносят долю прозрачности в эти дебри. Данный подход можно использовать наравне с обычным ориентированием на функцию потерь, что позволит получать еще более осознанные сети.
Если вспомнить про риторический вопрос из начала статьи, то можно сказать, что использование карт внимания вместе с итоговым откликом сети уже несет в себе определенное человекопонятное объяснение, которого так не хватало.
Визуализируйте, визуализируйте и еще раз визуализируйте!

