Каждая компания это не звездные технологии и супер крутые программисты, а огромная гора bottleneck, неэффективностей и сумма плохих решений, которая как-то да едет и делает свою работу. Но вот вы решили сделать какие-то изменения и сразу начинаете сталкиваться с тем, что в огромном кол-ве бизнес процессов у вас проблемы. Ну и эти проблемы, конечно, нужно решать не идеальным способом, а оптимальным по трудозатратам.
Хочу поделится одним таким примером, связанных с моей темой анализа данных и управления данными. Во многих организациях существует финансовые службы, основная цель которых предоставлять финансовую информацию руководству о состоянии предприятия. Среди многих работ этих людей есть одна такая задача: составление прогноза выручки на следующий период (год, квартал у кого как). Этот прогноз выручки часто бывает первым этапов в согласовании планов на следующий период и составлении общего прогноза по прибылям и убыткам предприятия.
Все, кто занимается такого рода прогнозированием, понимают, что в этом вопросе важна не столько точность прогнозов, сколько правильные взаимосвязи между вашими предпосылками и результатами. Ведь что мы хотим от прогноза? Мы хотим узнать, что будет, если делать все как обычно (AS IS) и что будет, если мы что-то поменяем (сценарии). Для того, чтобы сделать эту работу финансовая служба должна придумать какую-то модель предприятия, которой она может легко управлять, легко объяснять бизнесу как она работает и легко предоставлять данные в различных разрезах, в которых бизнес захочет это дело посмотреть.
Это все отличные намерения, но тут мы сталкиваемся с суровой реальностью: методологические и технические навыки для выполнения этих задач в конкретных предприятиях откровенно слабы. Модели неудобные, быстро не изменяемые, не обновляемые, легко ничего не объясняется, файлы не удобные, а разрезы получить невозможно или очень долго. Давайте посмотрим конкретный пример, где всё плохо и как это можно исправить.
Где будет строить модель типичный сотрудник отдела финансов? Конечно в Excel. Для этого есть несколько по настоящему хороших причин:
- Опыт работы есть только с этим средством.
- Результат работы легко передать заказчику.
- Можно изменить любую деталь в модели.
- Excel довольно просто интегрирует в себя получение, хранение, обработку, прогнозирование, представление и визуализацию данных.
- Можно сделать так, чтобы потребители вашей работы легко разбирались в том, что вы им передали.
- Позволяет организовать простой интерактив и работу с моделью.
Одна из самых простых и одна из самых распространенных моделей прогнозирования выручки это очень простая формула: количество клиентов за период * средний чек = выручка.
То, что было до нас выглядело так (данные, конечно же заменены на демонстрационные):
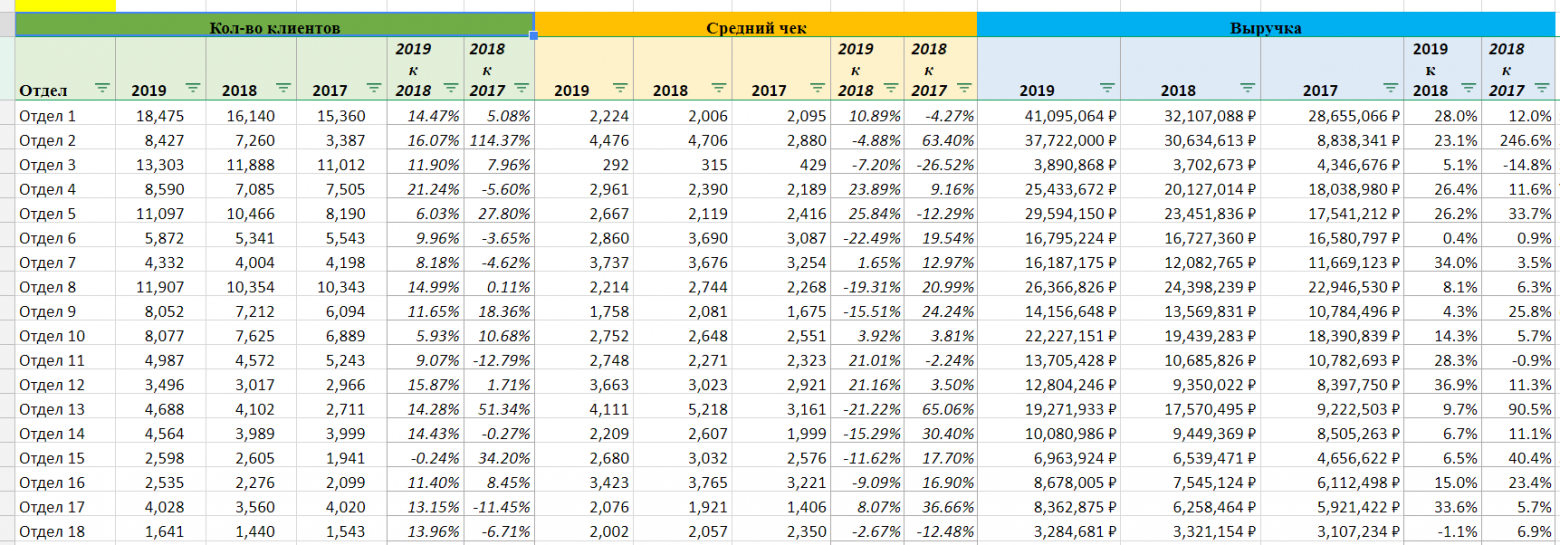
Какие проблемы есть на этом листе:
- Исходные данные по 2017 и 2018 году введены как значения. Подразумевается, что для реализации различных версий бюджета будут напрямую исправляться эти значения. Это большой объем работы (т.к. таких листов около 30 по различным подразделениям), в котором наверняка будут сделаны ошибки, перепутаны столбцы и колонки.
- Хотя 2018 год введен как значение, он еще не закончился, поэтому там введено значение с учетом прогноза, который сделан где-то отдельно.
- Прогноз сделан на целый год. Среди требований к прогнозированию было составить помесячный прогноз с одной стороны, а с другой стороны отобразить его в годовом разрезе, т.к. помесячный прогноз трудно анализировать и оценивать из-за обилия цифр. Соответственно одна из трудностей для этой модели — построить поверх еще одну модель, которая разбивает данные по месяцам с учетом сезонности. Все "задом наперед", не годовой результат из месячных, а месячные из годового.
- Исходные данные для модели нигде явно не фигурируют, нет на них ссылок и не ясно, верны ли те цифры, что мы видим, верно ли они извлечены из хранилища и суммированы.
- Если появится желание сделать перегруппировку состава отделов, то эта модель будет полностью выброшена.
- В следующем году тут мало что можно переиспользовать.
Этот лист это прогнозирование по одному из подразделений предприятия. Всего таких листов около 30. Все эти листы объединяются на лист всего предприятия в двух разрезах: по подразделения и по типам отделов. Грубо говоря у вас в каждом подразделении есть отдел, по производству упаковки. Вы хотели бы видеть и общий результат по подразделениям, а отдельно общий результат в разбивке по разным специализациям, типа производства упаковки. Лист выглядит концептуально так же, но он является суммой результатов на прошлых 30 листах.
Это суммирование реализовано самым простым способом: перебором всех ячеек нужных для суммирования. Т.к. не каждое подразделение содержит все отделы и положение строк в 30 листах отделов может быть разное, то для сборки совокупной выручки по отделам сотрудник должен был составить десятки формул, в которых явным образом указал, какие ячейки он хочет складывать.
Какие проблемы мы видим на обобщенных листах?
- Явный перебор ячеек для суммирования, а значит если кто-то подменит значения или смысл ячейки, на которую мы ссылаемся при суммировании, мы это не заметим и нам придется долго эту ошибку искать.
- При изменении структуры компании нам придется не только изменять листы подразделений, который были затронуты изменениями, но и исправлять лист с общей сборкой, ведь там не будет новых объектов, а удаленные будут выдавать ошибки.
- При изменении разреза, под которым мы хотим посмотреть на подразделение эта модель вообще ничего не может сделать и просто не работает. Если в отделах появится какая-то большая детализация, то по сути нам придется создавать еще один такой же обобщающий лист (который будет иметь уже в 10 раз больше прямых ссылок, которые надо "протыкать", где-то уже от 1000 до 10000).
- Модель вообще полностью разрушается, если изменения в компании приведут к другой группировке сущностей. Вся эта работа просто идет на выброс.
Таким образом, мы имеем жесткую, прямолинейную структуру модели, которая способна давать только один результат, может выдержать небольшие изменения в предпосылках и связана с огромными трудозатратами по обновлению или внесению изменений. И даже само создание этой структуры уже связано с большими трудозатратами.
Почему-то многие компании такие задачи готовы "закидывать телами" трудолюбивых сотрудников, кому не хватает и опыта и навыков сделать все проще, быстрее и удобнее. При этом это даже не вопрос денег. Реализация такого файла отнимает около 2 месяцев работы человека и то, без удовлетворения всех требований. А более разумный подход к организации работы с данными потребует у вас 1 недели не напряженной работы! За 2 месяца подготовки "плохим" способом вы теряете не только больше денег, но и кучу времени и нервов, т.к. принимая результат будете десятки раз ловить ошибки. Это тупейшая растрата ресурсов. Это как раз тот случай, когда простыми шагами, вы можете получить 10-ти кратный рост производительности труда!
О том, как мы добились повышения производительности труда в 10 раз и переделали модель в следующей статье.

