
Представьте, что в ресторане вам предложили попробовать новый соус к вашему любимому блюду, отметив, что так оно становится в два раза вкуснее. В таком случае вам не останется ничего, кроме как сделать это. Ведь иначе определить, почему официант оценил свои субъективные чувства как «в два раза вкуснее», а не, например, в три, никак не удастся. Когда речь заходит о расходах на ИТ-инфраструктуру, мало кто готов положиться в этом вопросе на чьи-либо чувства или интуицию. Для выбора «в два раза более вкусного варианта» потребуется найти достоверный и надежный метод оценки экономической эффективности.
Особенно важен такой расчет, если вам необходимо убедить руководство, в том числе финансового директора, в правильности вашего решения.
Цель этой статьи — разобраться в методике TCO для разных вариантов получения права пользования ИТ-инфраструктурой и провести соответствующие расчеты, дабы выявить наиболее экономически эффективную альтернативу.
РЕЗУЛЬТАТАМИ ИССЛЕДОВАНИЯ ЯВЛЯЮТСЯ (UPD)
- понимание необходимости учитывать уровень отказоустойчивости ИТ-систем как ключевую характеристику «to compare apples to apples»;
- расчет совокупной стоимости владения ИТ-инфраструктурой для двух шаблонов использования: ERP-система и веб-ресурсы спортивного портала;
- сравнительный анализ совокупных затрат на владение собственной ИТ-инфраструктурой и на аренду облака;
- факторный анализ экономии на преимуществах облачных технологий и выявление наиболее благоприятных шаблонов использования облака.
Что такое TCO?
Совокупная стоимость владения или стоимость жизненного цикла (англ. Total Cost of Ownership, TCO,) — это общая величина целевых затрат, которые вынужден нести владелец с момента начала реализации вступления в состояние владения до момента выхода из состояния владения и исполнения владельцем полного объёма обязательств, связанных с владением.
Методика TCO была разработана в конце 80-х годов XX века компанией Gartner Group для расчета финансовых затрат на владение компьютерами на платформе Wintel (MS Windows+Intel). Она была усовершенствована в 1994 г. фирмой Interpose и переработана в полноценную модель анализа финансовой стороны использования информационных технологий. При таком расчете TCO затраты на создание аппаратной платформы, покупка лицензий на программное обеспечение, расходы на оплату труда ИТ-специалистов и прочее — это так называемые «прямые» или «бюджетные» расходы. Но есть еще неявные финансовые вливания в содержание своей ИТ-инфраструктуры, затраты и потери, связанные с её функционированием и так далее. Причем, авторы методики TCO утверждают, что такие издержки составляют основную долю совокупной стоимости владения ИТ-инфраструктурой. Эти затраты называются «непрямыми расходами», и согласно многолетней практике расчетов TCO превышают упомянутые выше «прямые расходы» в 3–5 раз.
То есть на самом деле предприятия тратят на содержание своего «железа» гораздо больше средств, чем предполагают. Почему так происходит и можно ли оптимизировать затраты на собственную IT-инфраструктуру?
Именно эти цели и преследует методика TCO. Но для того, чтобы понять, как можно управлять расходами на содержание, нужно сначала прояснить, как они рассчитываются [1].
На сегодняшний день универсальной методики определения (расчета) совокупной стоимости владения не существует, поскольку, в зависимости от объекта владения характеристики владения, структура затрат и принципы их определения могут различаться в значительной степени. Однако, существуют общие подходы определения стоимости на всех этапах жизненного цикла. Ключевым принципом, реализуемым при разработке методик определения совокупной стоимости владения, является системный подход.
Для укрупненной оценки стоимости владения могут применяться упрощенные методики расчета TCO, выявляющие, прежде всего, структуру затрат, и дающие представление о вероятных потерях в процессе владения.
Таким образом, необходимо делать индивидуальный расчет TCO для каждого случая и, несмотря на то, что большинство затрат могут быть определены заранее, либо спрогнозированы с высокой точностью, некоторые затраты носят вероятностный характер, что влечет за собой риск существенных отклонений действительных расходов от прогнозных (расчетных).
Как мы рекомендуем считать совокупную стоимость владения ИТ-инфраструктурой и почему
TCO или оценка полной стоимости владения по причине своего вероятностного характера скорее важна не сама по себе, сколько применима для сравнения расходов на альтернативные способы получения необходимых вычислительных ресурсов.
Наиболее популярной альтернативой покупки собственного оборудования и ПО виртуализации является аренда готовой ИТ-инфраструктуры в облаке по модели IaaS (англ. Infrastructure as a Service — Инфраструктура как услуга).
В расчёте TCO облака нет ничего сложного: берем и складываем все платежи провайдеру за период. Посчитать совокупные расходы на собственную инфраструктуру значительно сложнее, и об этом мы подробно поговорим далее.
Вам уже удалось провести необходимые расчеты? Теперь можно сравнить? Да, если вы сделали это правильно.
Не стоит забывать о важной характеристике создаваемой ИТ-инфраструктуры как системы — об уровне отказоустойчивости или бесперебойности процесса её работы. Понятно, что чем выше уровень доступности сервисов, тем лучше: работа офисных сотрудников не простаивает по причине сбоя на сервере системы автоматизации бухгалтерского учета, а покупатели не уходят из интернет-магазина из-за «ошибки 503».
В общем, бизнес хотел бы получить 99,99% доступности. Однако создание решения такого уровня потребует значительных инвестиций. Таким уровнем отказоустойчивости обладает, например, решение на основе двух СХД с синхронным зеркалированием, расположенных в паре географически удаленных друг от друга центров обработки данных. Не удивительно, что стоимость такой услуги будет в 2 раза выше.
Каждому ли необходимо такое решение? Конечно, нет. Если мы говорим об ожидаемом уровне доступности в 99,95% или 4 часа 23 минуты простоя в год, мы ожидаемо проигрываем всего 0,04% аптайма решению, которое в 2 раза дороже. В невисокосном году 8760 часов, а значит, если не произойдет природных катакликзмов, от которых нас спасло бы только катастрофоустойчивое решение, мы добавляем всего 3,5 часа в год ко времени безотказной работы ИТ-инфраструктуры в год, вкладывая значительные средства.
Итак, мы подходим к вопросу сколько стоит минута простоя для вашего бизнеса и какой уровень отказоустойчивости вам нужен. Знакомы ли вы со страшным словосочетанием “cost of downtime”?

Согласно опросу, проведенному институтом Ponemon в 2014 году, средняя стоимость минутного простоя составляет 7 900 долларов США по сравнению с 5 600 долларов США за минуту четырьмя годами ранее. Несмотря на то, что эти цифры могут выглядеть катастрофическими, они легко могут быть отброшены как релевантные только для нескольких крупнейших компаний в США.
Для гиганта электронной коммерции, такого как Amazon, цифры еще выше. Сообщалось о потерях до 66 240 долларов за каждую минуту простоя сервиса. В это время минута простоя для небольших предприятий обходится значительно дешевле, относительная стоимость по-прежнему значительна. Удивительно, но усилия, направленные на измерение и управление этими рисками, только недавно стали приоритетом для бизнеса. В результате легко совершить ошибку, проигнорировав опасность простоя IT-инфраструктуры, и не попытаться оценить его влияние на результаты деятельности.
Как вы можете оценить потери за время простоя, если вы малый или средний бизнес? Неудивительно, что соответствующая математика убытков меньше впечатляет. Но не позволяйте цифрам обмануть вас. Даже нишевый розничный магазин с относительно скромным доходом ощутит «боль» простоя. Давайте посмотрим на список факторов, которые в совокупности формируют общую стоимость потерь:
Прямые потери дохода от продаж

Это может показаться тривиальным, но предполагая, что доход генерируется онлайн или строго зависит от работы ИТ, вам потребуется просто разделить сумму годовых продаж на 525 600 (60 мин. X 24 часа x 365 дней) для определения средней стоимости простоя в минуту. Таким образом, формула убытка может выглядеть примерно так:

Где t обозначает количество минут простоя вашей IT-инфраструктуры.
Стоимость потерь в производительности сотрудников
Оценочная стоимость времени, работников, на которых влияет простой и которые не могут работать как обычно.
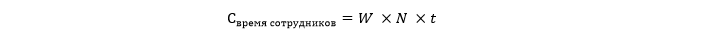
Где W обозначает среднюю почасовую заработную плату на одного работника, а N обозначает количество сотрудников, пострадавших от простоя. t в этом случае выражено в часах.
Стоимость восстановления ИТ-инфраструктуры
Стоимость времени ИТ-персонала, занятого восстановлением вашей системы из резервной копии или заменой вышедшего из строя оборудования.
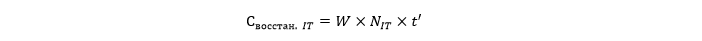
Где N_IT обозначает количество сотрудников, занятых в ИТ-операциях по восстановлению вместо иной полезной для бизнеса деятельности, а t' обозначает время, необходимое для исправления проблем всех затронутых систем и их возврата к нормальному состоянию.
Прогнозируемая потеря дохода из-за снижения лояльности клиентов
Для простоты давайте предположим, что рассматриваемый бизнес не является широко освещаемым средствами массовой информации, поэтому прогнозируемый потерянный доход рассчитаем на основе потери возможных повторных продаж.

Где r обозначает средний показатель (rate, процент) снижения повторных продаж, а Д — доход от повторных продаж за год.
Прогнозируемая потеря дохода из-за ущерба репутации
Потерянные продажи клиентам, исследующим рынок в поиске лучшей сделки или собирающим рекомендации.
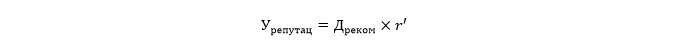
Где r' обозначает процент снижения продаж, связанный с клиентами, пришедшими с сайтов с отзывами для сравнения товаров/услуг и из социальных сетей.
Таким образом, формула общей стоимости простоя (TCoDT, total cost of downtime) может выглядеть примерно так:
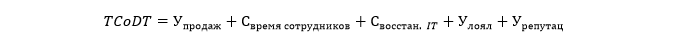
Где У_продаж, С_время сотрудников, С_восстан. IT, У_лоял, У_репутац соответственно означают потерянный доход, стоимость потерь из-за снижения производительности сотрудников, стоимость восстановления ИТ-инфраструктуры, прогнозируемую потерю повторных продаж и прогнозируемые потери из-за ущерба репутации.
В качестве примера рассмотрим интернет-магазин с 50 миллионами рублей продаж и 15 сотрудниками в штате. Почасовые 5708 рублей или чуть более 95 рублей в минуту являются прямыми потерями дохода.
Какой продолжительности ожидаемый простой в течение года ждет компанию?
Многое зависит от того как организована IT-система этого бизнеса. Хорошо изученными и типовыми объектами являются публичные центры обработки данных. Uptime Institute создал уровневую систему классификации для систематической оценки различных сооружений и оборудования центров обработки данных с точки зрения потенциальной производительности инфраструктуры или способности безотказно работать (uptime). Система состоит из четырех уровней, каждый уровень включает в себя требования нижних уровней (Tier):
- Tier I: Basic Capacity — базовый потенциал, инфраструктура без резервирования;
- Tier II: Redundant Capacity Components — дублирование критически важных компонентов, инфраструктура с резервированием;
- Tier III: Concurrently Maintainable — инфраструктура с возможностью параллельного ремонта/обслуживания без остановки работы;
- Tier IV: Fault Tolerant — отказоустойчивая инфраструктура.

Хотя Uptime Institute удалил информацию об «ожидаемом в год простое» из Tier Standard в 2009 году [2,3], мы можем сделать выводы о том, что ранее, публикуя эти данные, эксперты по эксплуатации дата-центров обобщили информацию о сбоях и пришли к выводу, что базовая инфраструктура без резервирования ожидаемо безотказно работает 99,671% в год или простаивает из-за аварий 28,8 часа.
Нередко в компаниях или их удаленных филиалах, серверы в которых размещаются локально, отсутствуют выделенные помещения для серверных и коммутационных узлов, стойки не защищены, отсутствует контроль доступа, нет резервирования, кабельная организация находится на низком уровне, а о специализированном охлаждении и системах пожаротушения вовсе не задумываются. И это даже не Tier 1 с ожидаемым простоем более суток. Пожар в таких помещениях более вероятен, а итоговый простой может длиться месяц и привести к банкротству.

«Плачевное» состояние серверных может стать причиной крупных аварий
Тут нужно отметить, что вся ИТ-система организации — это связка систем обеспечения (электроэнергия, охлаждение, безопасность и т.д.), каналов связи, собственно серверного, сетевого оборудования и систем хранения данных, общесистемного и прикладного программного обеспечения. В такой многоуровневой системе общий ожидаемый uptime является произведением уровней отказоустойчивости каждой составляющей или
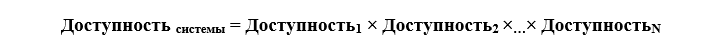
Например, Доступность = 99,671% (локальный ЦОД без резервирования) × 99,671% (ИТ оборудование без резервирования) = 99,343% или около 2,5 суток ожидаемого простоя, если сбои вызваны разными причинами и в разное время.
Предположим, у вас достаточно хорошо организованная деятельность, и простой ИТ-инфраструктуры продолжается не более девяти часов в год, немного не дотягивая до трех девяток (99,9%). Это означает, что все работники, затронутые сбоем (предположительно 2/3), не могли нормально работать, по крайней мере, в течение этого периода времени. Если мы возьмем среднюю почасовую заработную плату с налогами и сборами в 500 рублей, это обойдется компании в 45000 рублей по причине потери производительности.
Логично, что ИТ-команда потратит еще какое-то времени на выяснение того, что пошло не так, чтобы затем предотвратить повторные сбои. Представьте, что вашим IT-гениям потребуется 50 часов (800 рублей/час), чтобы всё исправить. Это время работники могли бы потратить на решения задач развития вашего бизнеса. Даже если вы выделите только одного сотрудника на эту проблему, это дополнительные 40000 рублей, которые нужно включить в стоимость восстановления IT.
Наконец, не только клиенты, которых вы потеряли, «отправив» одному из ваших конкурентов, никогда не вернутся, новые клиенты с меньшей вероятностью будут делать у вас покупки по совету партнеров или по рекомендациям и отзывам на сайтах для сравнения товаров и услуг.
Итак, оценочно добавим убыток в размере 50000 рублей, чтобы учесть дополнительные 1% прогнозируемых потерь на повторных продажах за год и 35000 рублей за 2%-ную потерю продаж по отзывам и рекомендациям, вызванных простоем. Вырисовывается неприятная картина, но давайте сложим все это:
| Потери продаж |
51 372 |
| Потери производительности |
45 000 |
| Стоимость восстановления IT |
40 000 |
| Потери на повторных продажах |
50 000 |
| Потери на продажах по отзывам |
35 000 |
| Общая стоимость простоя IT- инфраструктуры |
221 372 руб. |
Согласно опросу представителей крупного бизнеса США, 37% организаций оценивают день простоя в потери более 10 000 долларов США, что перекликается с 38% респондентов, сообщивших о годовом доходе более 10 миллионов долларов. Таким образом, хотя цифры для малого и среднего бизнеса значительно ниже, чем фактические потери за время простоя для корпораций, также ясно, что даже малые предприятия, которые полагаются на современные технологии, должны серьезно относиться к проблеме безотказной работы с учетом их масштаба.
При более длительном простое, который вынуждены терпеть ваши клиенты, с каждым дополнительным часом вероятные потери на повторных продажах и по причине негативных отзывов растут быстрее. Таким образом, авария в ИТ-инфраструктуре может стать не только причиной убытков, но и лишить компанию финансовой устойчивости.
Статья 4 Закона от 24 июля 2007 № 209-ФЗ и постановление Правительства РФ от 4 апреля 2016 № 265 сообщают нам о доходе и количестве сотрудников, которые являются критериями получения бизнесом определенного законного статуса.
| Предельное значение среднесписочной численности работников за предыдущий календарный год |
Доходы за год по правилам налогового учета не превысят: |
15 человек — для микропредприятий; 16–100 человек — для малых предприятий; 101–250 человек — для средних предприятий |
120 млн руб. — для микропредприятий; 800 млн руб. — для малых предприятий; 2000 млн руб. — для средних предприятий |
Расчеты выше описывают ту работу, которую должны сделать ИТ-директора в качестве отправной точки для выбора альтернативных вариантов. Определив свой риск-аппетит и допустимый убыток от простоя ИТ-системы, необходимо спроектировать все элементы системы, исходя из общего запланированного уровня бесперебойности процесса. Полученный результат должен соответствовать тактическим и стратегическим бизнес-целям, а не ограничивать или быть препятствием к их достижению.
В рамках этой работы, мы обозначим целевой уровень бесперебойности работы ИТ на уровне 99,95% в год. Далее перейдем к расчету совокупной стоимости владения для разных моделей использования ИТ-инфраструктуры только с заданным уровнем ожидаемой отказоустойчивости.
TCO on-premise решения
Чтобы добавить немного универсальности в наш пример, мы будем говорить об одной конфигурации оборудования, но для двух шаблонов её использования. Нашими примерами будут
- ERP на 350 пользователей
- Веб-сайт популярного спортивного портала
Расчет TCO будем производить на периоды 3 и 5 лет.
Приобретение собственного оборудования
Для выполнения вычислений под эти задачи будет использоваться следующая конфигурация оборудования. Ориентируясь на среднерыночные цены для high-end серверного оборудования и mid-range СХД, получаем ожидаемые затраты:
| Оборудование |
Цена |
| 3+1 Серверы: CPU Xeon® E5 4 core 2,6GHz, RAM 64 Gb, 2х10Gb |
1 500 000 рублей |
| СХД SAS общим объемом 11 Тб (оперативные данные до 1Тб RAID1, остальные исторические RAID6) |
2 300 000 рублей |
| 1+1 Коммутаторы |
200 000 рублей |
Надежность таких систем исчисляется количеством «девяток», порядка, к примеру 99,999% заявленного времени бесперебойной работы в год. Большинство операций ремонта и многие операции апгрейда железа и ПО (увы, не все), могут производиться без прерывания работы. А мы помним о том, что выстаиваем систему с общей отказоустойчивостью не ниже 99,95%. Таким образом, мы экономим, не покупая high-end СХД, которая стоит в несколько раз дороже, но и не теряем в бесперебойности работы.
Серверное оборудование выбрано high-end, так как именно для серверов уровня предприятия реализуются разнообразные функции мониторинга и управления, обеспечивается отказоустойчивость и хорошая масштабируемость.
Итак, мы получили первые капитальные затраты на покупку оборудования. Они составили 3 000 000 рублей.
На этом можно было бы закончить с затратами на оборудование, но так как мы рассчитываем TCO и на 5 лет, а стандартная гарантия заканчивается зачастую по истечению 3 лет, добавим стоимость продления гарантийного обслуживания на 2 года. Так как стоимость продления гарантии различается для каждого вендора, оценочно обозначим эти затраты как 20% от стоимости оборудования за 2 года или 600 000 рублей в нашем случае. Расчет процентного соотношения стоимости постгарантийного обслуживания мы проводили на примере техники HPE [4].
Площадка для размещения: ЦОД или on-premise
Далее нам необходимо решить, где мы разместим наше оборудование. Хорошо, если у вас есть прекрасная серверная, которая напичкана современными системами, но что если строить её с нуля? В какую сумму обойдется такой проект?
Чтобы как-то оценить затраты мы обратились к исследованию «Оценка совокупной стоимости владения центром обработки данных» Л.А. Пироговой, В.И. Грекул и Б.Е. Поклонова [5]. Исходя из анализа рынка строительства коммерческих ЦОДов, по результатам регрессионного моделирования капитальных затрат на строительство 1 стойки в ЦОДе в Москве авторы приходят к доверительному интервалу от 59 до 88 тысяч долларов США. Таким образом, даже экономя на масштабе, чтобы получить надежную площадку для размещения оборудования, которая может соответствовать ожидаемому простою оборудования не ниже 99,95%, необходимо потратить около 4,5 млн. рублей только на строительство и оборудование без учета операционных расходов. Конечно, вариант таких непрофильных затрат отпадает почти для всех организаций.
Логичным вариантом является размещение серверов или аренда стойки в коммерческом ЦОДе, так называемый Colocation. Рынок услуг коммерческих дата-центров хорошо развит, такой подход к размещению оборудования стал общепринятым по причинам очевидной экономической целесообразности.
Размещение 6 юнитов в ЦОДе Tier III (резервирование систем электропитания, охлаждения, телеком инфраструктуры и систем пожаротушения, возможность ремонта систем без остановки работы серверной комнаты) в Москве по среднерыночным ценам с учетом дополнительного к базовым тарифам расхода электроэнергии и гарантированным каналом составит порядка 40 000 рублей в месяц.
Если вы всё же решились размещать оборудование в собственной серверной, то следует учесть, полное энергопотребление вашего ЦОДа (серверной) — это энергопотребление ИТ-оборудования плюс потребление всего того, что поддерживает его работу, а именно:
- систем электропитания, в том числе ИБП, распределительных устройств, генераторов, батарей; сюда же входят потери при распределении внешнего питания к ИТ-оборудованию;
- компонентов систем охлаждения: чиллеров, градирен, насосов, вентиляционных установок и кондиционеров машинных залов, увлажнителей и т.п.;
- других нагрузок, например, освещения ЦОДа.
Для определения энергоэффективности в отрасли принято использовать показатель PUE. Параметр PUE (Power Usage Effectiveness) определяется как отношение энергопотребностей ИТ-инфраструктуры ко всей энергии, поступающей в дата-центр. Идеальное значение PUE равно единице, в этом случае вся используемая площадкой энергия идет на поддержку работы серверов. На практике такая ситуация невозможна, минимальные значения PUE достигают около 1,1-1,15, организация работы с использованием «самых лучших методов» дает в среднем 1,6, а по миру в среднем показатель PUE для дата-центров TIER III составляет 1,98.
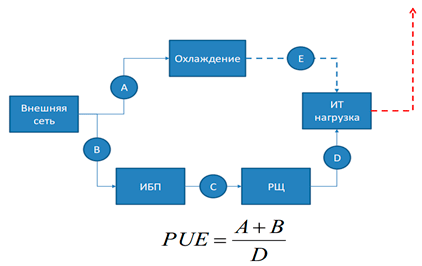
Источник: APC by Schneider Electric, 2010
Таким образом если номинальная мощность вашего ИТ-оборудования 4 кВт, то при PUE, равном 2, вам потребуется 8 кВт*ч. Если серверная работает круглосуточно, за месяц выйдет около 5800 кВт, что по тарифу 5 рублей за кВт даст затраты на 29000 рублей. Из этого становится понятно, что в цене размещения в коммерческом дата-центре значительную часть затрат занимает электроэнергия, а прочие расходы распределены на многочисленных арендаторов, которые платят меньше, чем если бы реализовывали такие условия на предприятии локально.
Мы закрепляем расходы 40 000 рублей в месяц на размещение оборудования в коммерческом дата-центре как экономически оптимальный выбор и в дальнейшем будем использовать для расчетов только этот вариант.
Расходы на программное обеспечение
Почему мы будем рассматривать пример с использованием виртуализации? Виртуализация может повысить адаптивность, гибкость и масштабируемость ИТ-среды и существенно снизить расходы. Виртуализация ускоряет развертывание рабочих нагрузок, повышает их производительность и доступность, а также дает возможность автоматизировать процессы, в результате чего ИТ-инфраструктура компании становится более управляемой и экономичной. В число дополнительных преимуществ входят следующие:
- сокращение капитальных и эксплуатационных расходов;
- минимизация или исключение простоев;
- повышение скорости реагирования, адаптивности и общей эффективности работы ИТ-персонала;
- ускорение инициализации приложений и ресурсов;
- обеспечение непрерывности бизнеса и аварийного восстановления;
- упрощение управления ЦОД;
- создание полностью программного ЦОД.
ИТ-отделы сталкиваются с ограничениями современных серверов x86, которые предназначены для одновременного выполнения только одной операционной системы и одного приложения. В результате даже в небольших центрах обработки данных приходится развертывать большое число серверов, загрузка каждого из которых составляет всего лишь 5–15%. Это неэффективно с любой точки зрения [6].
При виртуализации программное обеспечение используется для имитации наличия оборудования и создания виртуальной компьютерной системы. Благодаря этому бизнес-подразделения могут запускать несколько виртуальных систем, а также несколько операционных систем и приложений на одном сервере. Такой подход обеспечивает экономию при масштабировании и повышение эффективности.
Можно ли использовать бесплатные платформы виртуализации?
В случае, если вам НЕ требуется массовое развертывание виртуальных серверов в организации, постоянный контроль производительности физических серверов при изменяющейся нагрузке и высокая степень их доступности, вы можете использовать виртуальные машины на основе бесплатных платформ для поддержания внутренних серверов организации [7]. При увеличении числа виртуальных серверов и высокой степени их консолидации на физических платформах требуется применение мощных средств управления и обслуживания виртуальной инфраструктуры. В зависимости от того, необходимо ли вам использовать различные системы и сети хранения данных, например, Storage Area Network (SAN), средства резервного копирования и восстановления после сбоев и «живую» миграцию запущенных виртуальных машин на другое оборудование, вам может не хватить возможностей бесплатных платформ виртуализации, однако, надо отметить, что и бесплатные платформы постоянно обновляются и приобретают новые функции, что расширяет сферу их использования.
Еще один важный момент — техническая поддержка. Бесплатные платформы виртуализации существуют либо в рамках сообщества Open Source, где множество энтузиастов занимаются доработкой продукта и его поддержкой, либо поддерживаются вендором платформы. Первый вариант предполагает активное участие пользователей в развитии продукта, составление ими отчетов об ошибках и не гарантирует решения ваших проблем при использовании платформы, во втором же случае, чаще всего, техническая поддержка вообще не предоставляется. Поэтому квалификация персонала, разворачивающего бесплатные платформы, должна быть на высоком уровне.
Таким образом, мы подходим к выводу о том, что для корпоративного сценария использования, например, ERP системы, нам потребуется платное программное обеспечение виртуализации с расширенным функционалом. Лидирующие позиции на рынке занимаем VMware. Все компании из списка Fortune 500 выбирают инфраструктурную платформу VMware, которая помогла заказчикам сэкономить десятки миллиардов долларов.
Важным фактором в выборе программной платформы VMware является самая низкая совокупная стоимость владения по сравнению с решениями конкурентов. Вы можете самостоятельно воспользоваться калькуляторами совокупной стоимости владения и окупаемости инвестиций для сравнения с альтернативами, такими как решения от Microsoft и традиционная ИТ-инфраструктура [8].
Так как изначально мы решили, что будем рассматривать два сценария использования, то для кейса со спортивным порталом, условимся, что будут использоваться бесплатные, open-source программные решения, а в случае с ERP — лицензионное ПО от VMware.
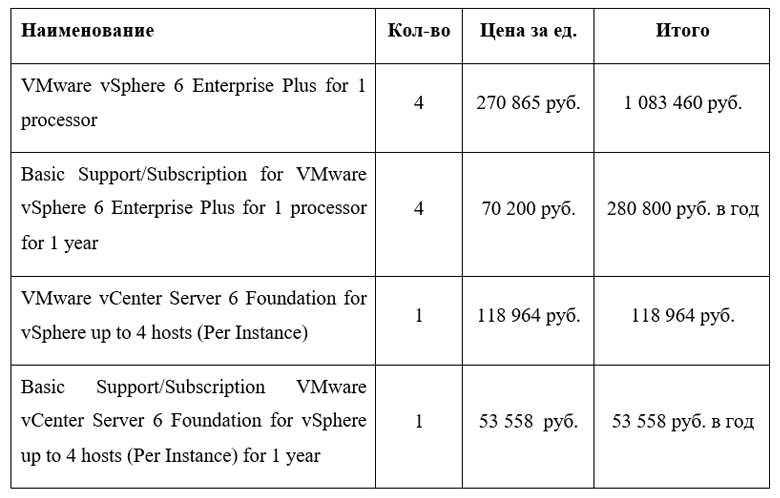
Итого за ПО виртуализации — 1,2 млн. рублей. Ежегодные расходы на техническую поддержку и доступ к обновлению продуктов — 334 тыс. рублей.
Добавим к этому лицензию на ПО для СХД среднего уровня — 100 тыс. рублей.
Расходы на оплату труда персонала
В то время, как фактические расходы на персонал для поддержки стабильной работы ИТ-инфраструктуры обычно состоят из оплаты труда нескольких разных людей, для простоты мы воспользуемся простым соотношением между количеством серверов и количеством человек, которое вывела компания AWS для использования в своих моделях затрат. Назовем это коэффициентом «server-to-admin».
Основываясь на обсуждениях с клиентами, AWS обнаружили, что соотношение 50 к 1 представляет собой хорошее среднее значение, полученное из диапазона, характерного для множества компаний. Мы рекомендуем скорректировать это допущение на основе ваших собственных исследований и опыта и включать в расходы на персонал всех людей, занимающихся созданием и управлением вашим физическим центром обработки данных, а не только людей, которые устанавливают и администрируют серверы. Фактическое соотношение между людьми и серверами может сильно варьироваться, поскольку оно зависит от ряда факторов, таких как сложность автоматизации, используемые инструменты, выбор в пользу виртуализованной или не виртуализированной среды.
Так как мы говорим о некотором абстрактном сотруднике, который будет иметь разную специализацию, соответствующую текущим задачам, мы воспользуемся медианной месячной зарплатой ИТ-специалиста за 1-ое полугодие 2018 года из отчета сервиса «Мой круг» [9].
Согласно опросу, она составляет 90 000 рублей на человека после вычета всех налогов и сборов. Добавив еще 50% на выплаты в ПФР, ФОМС, ФСС и НДФЛ, получаем 135 000 рублей. Это затраты на одного ИТ-специалиста, который на 100% загружен работой с ИТ-инфраструктурой, создание которой мы описываем в нашем кейсе.
Так как у нас 4 сервера и 1 СХД, применив «server-to-admin», равный 50 к 1, получаем около 10% затрат рабочего времени одного «универсального» сотрудника или 13,5 тыс. рублей затрат в месяц.
Общие затраты на собственную инфраструктуру
Capex (capital expense или capital expenditure) означают капитальные затраты или расходы. Это затраты, как правило, разовые (нерегулярные), направляемые компанией на покупку внеоборотных активов, их модернизацию и реконструкцию.
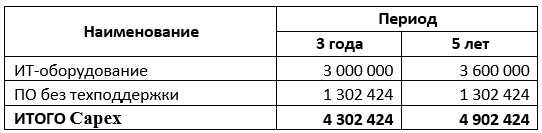
Opex (англ. operating expense, operating expenditure — операционные издержки) — затраты, которые несет компания в процессе текущей деятельности для обеспечения функционирования. Такие расходы также называют затратами текущего периода.
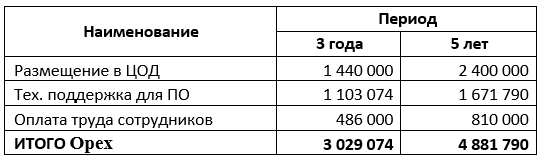
Итоговый TCO такой инфраструктуры составит 7 331 498 рубля за 3 года, и 9 884 214 рублей за 5 лет.

Таким образом, первоначальные инвестиции в ПО и оборудование в перспективе 5 лет возрастают более чем в 2 раза. Сами по себе 4,8 миллионы необходимые для запуска этой инфраструктуры также содержат в себе риски.
Во-первых, цена ошибки. Если мы говорим не о стабильном предприятии с хорошо прогнозируемой потребностью в вычислительных мощностях, а рассматриваем стартап с новым сервисом, который пытается завоевать рынок, все первоначальные инвестиции могут быть потрачены впустую. Да, конечно, купленное оборудование можно продать. Однако, такие сделки проводятся с большим дисконтом, а поиск покупателя может длиться месяцы.
Во-вторых, стоимость денег. Зачастую такие проекты реализуются с привлечением кредитных средств. Получив кредит на 4 млн. рублей с процентной ставкой около минимального порога для юр. лиц в 12% годовых, сумма процентов за 3 года составит 783 тыс. рублей.
Мы не будем добавлять в наш расчет TCO эти опциональные расходы, однако, когда вы будете делать анализ своего кейса, необходимо учитывать условия получения денег вашим бизнесом и прибавлять соответствующие затраты.
Получается, владеть «своим железом» довольно дорого. Альтернативным вариантом является использование облачных услуг. Перейдем к сравнению.
Раcсчитываем TCO облака
Так как мы не можем говорить о расходах на облако, не выбрав конкретного провайдера, делать анализ TCO мы будем на своем собственном примере.
Корпоративный облачный провайдер Cloud4Y с момента основания в 2009 году ориентирован на потребности и высокие требования бизнеса к IT-услугам. Мы предлагаем программно-конфигурируемые дата-центры (vDC) на базе кластерных решений VMware vSphere с управлением посредством портала самообслуживания VMware vCloud Director.
Помимо модели IaaS (инфраструктура как услуга), мы разработали и успешно предоставляем клиентам множество актуальных и популярных SaaS-продуктов (1С в облаке, удаленные рабочие столы, корпоративная почта, антиспам и многое другое).
Используемый стек технологий VMware (vSphere, NSX, vCloud Director), надежное оборудование (блейд-серверы HP, all-flash СХД, коммутаторы Cisco и Juniper), расположенное в сети безопасных дата-центров TIER 3, объединенных оптическим кольцом высокой доступности с дублированием каналов связи обеспечивают должное качество услуг и отказоустойчивость необходимые для Enterprise-клиентов.

Cloud4Y предусмотрено полное аппаратное резервирование серверного и сетевого оборудования. Резервное копирование осуществляется в географически удаленный ЦОД. По умолчанию реализованы кластерные опции VMware: «живая миграция» vMotion, автоматический перенос виртуальной машины на резервный хост в случае сбоя VMware HA (High availability), балансировка нагрузки между хостами VMware DRS.
Если необходимо сократить время простоя до минимального времени, есть возможность использовать технологию VMware Fault Tolerance. Основную идею опции можно описать, как создание синхронно работающей реплики виртуальной машины на другом сервере и мгновенное переключение на неё при выходе из строя основного хоста.
Техническая поддержка оказывается в режиме 24*7*365. Саппорт разделён на три линии:
- Первая линия техподдержки занимается вопросами доступности и техническими вопросами до уровня ОС включительно, заводит тикеты и консультирует клиентов. В случае запросов, не влияющих на данные, и не касающиеся финансов, вопросы клиентов могут быть решены ей любым из доступных способов.
- Вторая линия техподдержки занимается вопросами уровня гипервизоров и ОС, настройки клиентского ПО, кастомизации, разбора логов, интеграционными вопросами и глубокой поддержкой информационных систем клиентов.
- Третья линия поддержки решает задачи глобально на сетевом уровне, уровне систем хранения данных и отвечает за архитектуру и доступность в целом.
Мы видим, что все компоненты облака Cloud4Y спроектированы для обеспечения максимального уровня бесперебойности работы. Это позволяет говорить об общем ожидаемом уровне доступности системы 99,982% в год. Ни один элемент системы, будь то сеть, оборудование, площадка размещения или платформа виртуализации, не является слабым звеном.
Уровень доступности 99,982% выше, чем запланированный нами минимальный уровень. Итак, перейдем к расчету TCO в облаке и узнаем сможем ли мы получить услуги без премии за повышенную отказоустойчивость.
Альтернативной по номиналу конфигурацией в облаке будет 32 vCPU, 256 Gb RAM и 11 Tb Medium SAS (4400 IOPS). При расчете на калькуляторе на сайте мы получаем 250 824 рублей в месяц и предложение скидки. В зависимости от проекта скидка будет отличаться, но запланируем возможную скидку на уровне 20%, что в итоге даст нам 2 407 910 рублей в год, 7,22 млн. за 3 года и 12 млн. рублей за 5 лет.
На этом этапе облачное решение проигрывает созданию собственной ИТ-инфраструктуры, но не стоит торопиться с выводами.
Резервирование
Во-первых, аппаратное резервирование уже предусмотрено провайдером, в случае сбоя вам будет выделен другой хост из пула ресурсов провайдера. Значит альтернативной конфигурацией по мощности будет 24 vCPU, 196 Gb RAM и 1 Tb Medium SAS и 10 Tb Low. Получаем уже 187 793 рублей в месяц или 150 234 руб. с учетом скидки.
С учетом этой корректировки мы уже выходим на совокупную стоимость ниже, чем у собственной архитектуры. Мы говорили о 7,3 млн. рублей за 3 года, и 9,9 млн. рублей за 5 лет для собственного «железа». На данном этапе облако уже обходится дешевле — 5,4 и 9 млн. рублей соответственно.
Эластичность
Важным преимуществом облачных вычислений является эластичность (rapid elasticity). Ресурсы могут быть оперативно выделены и освобождены, в некоторых случаях автоматически, для быстрого масштабирования соразмерно со спросом. Для потребителя возможности предоставления ресурсов видятся как неограниченные, то есть они могут быть присвоены в любом количестве и в любое время.
Другими словами, если вам нужно 30 CPU, то вы просто арендуете 30 CPU в облаке. Но, если вы строите собственные ресурсы, то вы определённо не будете создавать именно 30. Представьте, что вы ИТ-директор спортивного веб-портал, и готовите вычислительные мощности для прохождения Чемпионата мира по футболу. В этом случае вы должны быть готовы к пику посещений в этот период, а ключевой вопрос для вас — каких именно ресурсов будет достаточно. Если их запланировать слишком мало, то в период крупных спортивных событий их не хватит, а если слишком много, то они будут простаивать остальную часть времени.
В начале мы говорили о том, что рассмотрим два шаблона использования. В случае с ERP системой мы будем повышать объем использованных ресурсов с 2/3 в первые три года, до полной утилизации (полезной загрузки) в течении 4 и 5 года. Для ресурсов спортивного портала мы предусмотрим два пика почти 100%-загрузки в год длительностью 1 месяц каждый, в остальное время ресурсы будут использоваться только на 40%.

Именно высокая утилизация ресурсов и эффективное управление позволяет облачным провайдерам зарабатывать на своем деле. Как это поможет сэкономить арендаторам?
Приступим к расчетам.
ERP-сценарий: 2/3 утилизации ресурсов (121 тыс. руб/мес.) в первые три года обойдутся в 4,356 млн. рублей, а все 5 лет с учетом роста — 7,961 млн. рублей.
Спортивный портал: 1/6 утилизации до 100% от максимального количества ресурсов, и 5/6 — 40% утилизации. Ресурсы СХД — рост от 40% до 90% за 5 лет.
На графике ниже можно видеть, как растут расходы в течение 5 лет и как влияют пики пользовательской активности на портале на расходы на облачную инфраструктуру.

Используя ресурсы по мере необходимости, можно сократить затраты до 2,494 млн. руб. за три года и 4,543 млн. руб. за 5 лет.
Итак, мы готовы наконец сравнить TCO облачного решения и покупки собственного «железа».
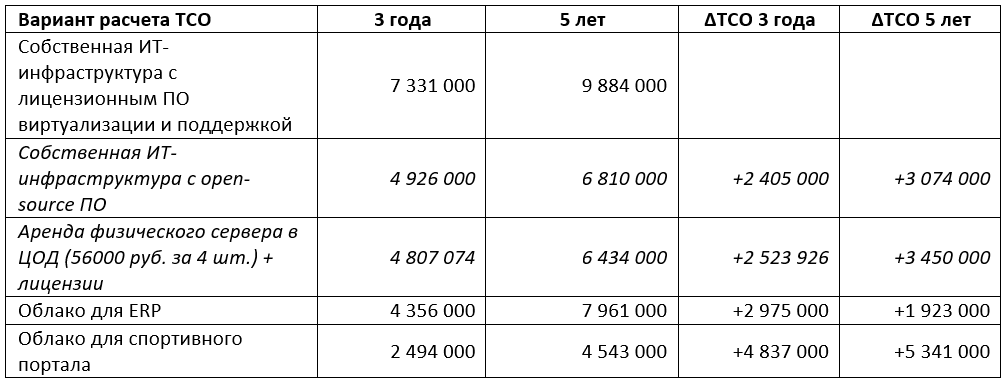
Облако для сценария корпоративного использования по нашим расчетам обходится дешевле на 1,9 млн рублей или 19,5% дешевле за 5 лет и 40,5% дешевле в перспективе 3 лет.
Мы добавили варианты с использованием бесплатного программного обеспечение для виртуализации и с арендой физических серверов в ЦОДе со своей лицензией, но даже они проигрывают облаку на отрезке 3 лет. При сравнении 5-летнего TCO эти варианты оказываются «выгоднее», но они предполагают снижение управляемости, отказоустойчивости и гибкости. Такие варианты слабо применимы для корпоративного ИТ, в сценарии же использования для спортивного портала эти варианты проигрывают облаку и в ТСО-5лет.
Стоимость денег
По меньшей мере сэкономленные деньги могли быть использованы бизнесом для других проектов, а значит приносить прибыль. Взяв рентабельность инвестиций на уровне 10% в год, мы может говорить
- о прибыли от 1,7 млн. рублей от свободного денежного потока (разница между затратами на on-premise и cloud помесячно) и сэкономленных 1,9 млн. в течение 5 лет в сценарии с ERP
- и 2,5 млн. «неупущенной» прибыли для спортивного портала плюс сэкономленные 5,3 млн. рублей.
Pay as you go
Cloud4Y предоставляет модель оплаты «Pay as you go» по каждому типу ресурса по отдельности. Такой подход дает возможность оплачивать ресурсы по факту потребления. Используем сегодня ровно столько ядер и оперативной памяти, сколько нужно. Стоит отметить, что во всех случаях, плата за CPU и RAM берётся только за «включенное» время, в момент, когда вы не пользуетесь виртуальной машиной — плата не взимается. А вот за хранилище придётся платить в независимости от того, включена машина или выключена — плата берётся до момента, пока на диске есть данные, если диск чистый — плата не взимается.
На сайте вы можете найти калькулятор стоимости услуг, но стоит отметить, что он работает на основе предположения использования ВМ в режиме 24х7х30. Используя VM в режиме 12х5х30, стоимость услуги для вас может быть ниже более чем на 50-60%. Такой шаблон утилизации ресурсов характерен, например, для инфраструктуры виртуальных удаленных рабочих столов или «облачного офиса». Когда сотрудники организации не работают, виртуальные машины с их рабочими столами отключаются, и начинается экономия. Мы не рассматривали такой сценарий использования в сравнении TCO, но логично и проверено на практике, что облако обходит другие альтернативы и в этом кейсе.
Выводы

На графике ясно видно, что в течение всего 5-летнего срока эксплуатации ИТ-инфраструктуры облако Cloud4Y выигрывает у покупки собственного «железа». За пределами этого периода, скорее всего, серверы морально устареют и необходимо будет приобрести новые. За обновление оборудования в облаке отвечает также сам провайдер. Таким образом, рассмотрение более продолжительного периода не изменит ситуацию с экономической целесообразностью облака.
Существуют варианты, когда облако будет менее выгодно. В основном, это случаи с наличием уже приобретенного и простаивающего оборудования или покупкой серверов, чтобы незначительно увеличить уже существующие и эффективно используемые ресурсы. Также можно сделать вывод, о более существенном выигрыше облачных услуг в сценариях со скачкообразной или непредсказуемой загрузкой мощностей.
Для того, чтобы получить консультацию и расчет TCO в облаке для кейса вашей организации, обратитесь к любому менеджеру Cloud4Y удобным вам способом.
Источники
- Оптимизация расходов на IT // Интернет-проект «Корпоративный менеджмент». URL: www.cfin.ru/itm/tco.shtml (дата обращения 20.09.2018)
- Официальный сайт Uptime Institute. URL: ru.uptimeinstitute.com (дата обращения: 19.09.2018)
- Мифы и заблуждения относительно Tier-системы сертификации Uptime Institute // Сайт Cloud4Y. URL: www.cloud4y.ru/about/news/Myths-and-Misconceptions-Regarding-the-Uptime-Institute%E2%80%99s-Tier-Certification-System (дата обращения: 19.09.2018)
- Сайт Hewlett Packard Enterprise Support Services Central. URL: ssc.hpe.com/portal/site/ssc/?action=determineNodeContents&nodeId=30749 (дата обращения: 24.09.2018, выбранная длительность — 2 года)
- «Оценка совокупной стоимости владения центром обработки данных». URL: bijournal.hse.ru/data/2016/08/11/1118257058/%D0%9F%D0%B8%D1%80%D0%BE%D0%B3%D0%BE%D0%B2%D0%B0%20%D0%93%D1%80%D0%B5%D0%BA%D1%83%D0%BB%20%D0%9F%D0%BE%D0%BA%D0%BB%D0%BE%D0%BD%D0%BE%D0%B2%20%D0%A0%D0%A3%D0%A1.pdf (дата обращения: 24.09.2018)
- Принципы виртуализации // Официальный сайт VMware. URL: www.vmware.com/ru/solutions/virtualization.html (дата обращения: 25.09.2018)
- Бесплатные серверные платформы виртуализации. URL: www.ixbt.com/cm/virtualization-servers-free.shtml (дата обращения: 25.09.2018)
- VMware TCO Comparison Calculator. URL: tco.vmware.com/tcocalculator (дата обращения: 24.09.2018)
- Зарплаты ИТ-специалистов на середину 2018 года // Блог сервиса «Мой круг» на Хабр URL: habr.com/company/moikrug/blog/420391 (дата обращения: 20.09.2018)
Ссылка на бесплатную загрузку White Paper: Расчет TCO «Облако vs Покупка Серверов» (.pdf)

