
Любительский перевод визуальных новелл, если сравнивать с переводами других игр, имеет ряд особенностей и подразумевает работу с большим количеством текста. Пожалуй, подавляющее большинство всех визуальных новелл было выпущено на японском языке, лишь немногие были переведены на английский(официально или любителями) и еще меньше было переведено на другие языки.
Поэтому, при работе с переводом приходится сталкиваться с японскими движками, многие из которых оказываются не слишком дружелюбными к локализаторам. Из-за этого, довольно быстро приходит осознание, что наличие переводческих навыков, знания языка, большого энтузиазма и свободного времени, вовсе не означает, что переведенная версия игры скоро увидит свет.
Очень приближенно, процесс перевода любой игры(не только визуальных новелл), подразумевает:
- Распаковку игровых ресурсов(если они не находятся в открытом доступе)
- Перевод необходимых частей
- Обратная запаковка перевода
Однако в случае с японскими визуальными новеллами это обычно выглядит так:
- Распаковка игровых ресурсов
- Перевод текстовой части игры(игрового сценария)
- Перевод графической части игры
- Обратная запаковка перевода
- Переделка движка, чтобы заставить его работать с переведенным контентом
Надеюсь, наш опыт окажется для кого-то полезным.
В далеком 2013 году(а возможно и раньше) я задумал перевести с японского визуальную новеллу Bishoujo Mangekyou -Norowareshi Densetsu no Shoujo- (美少女万華鏡 -呪われし伝説の少女-). Опыт перевода игр у меня уже был, но раньше приходилось переводить только новеллы на относительно простых и известных движках вроде Kirikiri.
Здесь же нашей команде переводчиков предстояло вскрыть движок этой новеллы, еще до того, как добраться до собственно самого текста.
Начнем с описания .exe файла, где упомянуты слова QLIE и IMOSURUME. В самом файле встречается строка FastMM Borland Edition 2004, 2005 Pierre le Riche, значит движок, скорее всего, написан на Delphi.


При беглом гуглении удается узнать, что Qlie — это название движка для визуальных новелл, выпущенном компанией Warmth Entertainment. По видимому, IMOSURUME – внутреннее имя скриптового движка, а Qlie – коммерческое название. Есть сайт qlie.net, где перечислены игры, выпущенные на этом движке и официальный сайт компании Warmth Entertainment.
Но нигде в свободном доступе нет ни официальных инструментов для работы с движком, ни документации к нему, что ожидаемо.
Поэтому разбираться с игрой приходится самостоятельно, опираясь на неофициальные утилиты. Для начала стоит найти все части игры, которые нужно будет переводить.
Игровые архивы находятся в файлах data0.pack, data1.pack и data7.pack в подпапке \GameData. Заставки лежат в папке \GameData\Movie, но их пока можно не трогать.

В hex-редакторе видно, что никаких узнаваемых заголовков у игровых архивов .pack нет, зато в конце файла есть кусок, похожий на оглавление и метка FilePackVer3.0

К счастью, для данного формата уже есть распаковщик и даже не один. Мы использовали консольный exfp3_v3 от asmodean.
Распаковка не так проста, как может показаться. Поскольку движок поддерживает несколько архивных форматов(FilePackVer1.0, FilePackVer1.0, FilePackVer3.0), и в данном случае используется FilePackVer3.0, для правильной распаковки потребуется еще и специальный файл-ключ key.fkey, которым зашифрован архив. Он находится в подпапке \Dll

Кроме того, exfp3_v3 должен уточнить, архив из какой именно игры он распаковывает.
Поэтому требуется еще и указать номер игры из предложенного распаковщиком списка(игры серии Bishoujo Mangekyou там под номером 15), либо указать исполняемый файл игры в качестве третьего параметра для распаковщика.

Уже после распаковки игровых файлов, появилась логичная мысль: а как в будущем запаковать обратно игру с готовым переводом? Ведь распаковщик не поддерживает обратную операцию.
По нашей просьбе w8m (большое ему за это спасибо) добавил в свою программу arc_conv.exe возможность запаковывать игровые архивы. Достаточно запаковать все измененные файлы в новый архив(например, data8.pack), поместить в папку GameData, и они автоматически подтянуться в игру.
Вернемся к распакованным ресурсам. Файлы игрового сценария из архива data0.pack можно найти в подпапке \scenario\ks_01\
Все файлы сценария с расширением .s закодированы в далеко не самой удобной кодировке Shift Jis, и никакие юникодные кодировки движок не поддерживает. Cтроки для перевода выглядят приблизительно как эти:
【キリエ】 %1_kiri1478% 「へえ……分かっているじゃない」 私が献上したロシアンティーを見て、キリエは嬉しそうに目を細める。 ^cface,,赤目微笑01 【キリエ】 %1_kiri1479% 「日本人は、ジャムを紅茶に入れて飲むのが、ロシアンティーだと勘違いしている人が多いのだけれど……」
Можно заметить, что каждая фраза на японском предваряется именем героя в японских скобках. (【】), который эту фразу произносит(в игре она выводится в верхней части окна с текстом). Или же, если это слова автора, то имя не добавляется.

Но остаются еще служебные команды.
Команды движка в сценарии чем-то напоминают язык разметки TeX, но намного более не интуитивны и неудобны, по сравнению с командами Kirikiri или RenPy.
Вот некоторые из них:
@@@ — тройная собака. Часто файлы скрипта начинаются именно с этой команды. По видимому, загрузка определений из сторонних файлов. Например:
@@@Library\Avg\header.s
@@ — двойная собака. Метка в файле скрипта. На нее позже можно будет выполнить переход.%1_kiri1478% — проигрывание файла озвучки. Эти команды вставляются между именем героя и текстом, который выводится на экран. «1_kiri1478» — в данном случае, имя файла из папки \voice\ файла data1.pack Интересно, что в команде используется японский процент(%), а не обычный.^savedate, ^saveroute, ^savescene, — три команды, которые скорее всего используются в системе сохранений игры и должны заносить в сэйв информацию о месте и времени сохранения игрока.Например:
^savedate,"現在" ^saveroute,"美少女万華鏡-1-" ^savescene,"呪われし伝説の少女 オープニング"
То есть, дата: настоящий момент, ветка: Bishoujo Mangekyou -1-, сцена: Norowareshi Densetsu no Shoujo Opening. Эти данные должны были отображаться в слоте сохранения, но, видимо разработчики решили от этого отказаться. В итоге
^saveroute во всех частях сценария одинаковый, ^savedate сменяется с «настоящего момента» на «мечтания», а в ^savescene меняются внутриигровые дни(вернее, ночи).^facewindow, – состояние текстбокса с выводимым на экран текстом. (Показан — 1 или нет — 0)^sload, — проигрывание внутриигровых звуков из папки \sound\ на соответствующем канале.sload,Env1,◆セミ01アブラゼミ
Проигрывание звука цикад на канале Env1
У команды есть два необязательных параметра, первый отвечает за закольцовывание звука, а второй пока остается загадкой, но он используется в игре редко.
^sload,SE1,■クチュ音01,1
Проигрывание закольцованного звука на канале SE1.
^eeffect – вывод на экран спецэффекта на определенное количество секунд. Судя по всему, поддерживает последовательный вывод нескольких эффектов.^eeffect,WhiteFlash
Эффект белой вспышки.
^ffade – эффект перехода при смене экрана.Имеет целую кучу дополнительных параметров, но реально полезны только несколько: название эффекта перехода, дополнительная картинка, если она требуется и время выполнения перехода.
^ffade,Overlap,,1000
Растворение одной картинки в другой, за 1 секунду.
^iload – загрузка фоновой картинки на экран. Изображению можно присвоить id для обращения к нему в будущем.^iload,BG1,0_black.png
Вывод файла 0_black.png в качестве фона с id BG1
^we и ^wd — включение и выключение изображения в окне.^facewindow,1 и ^facewindow,0 Включение и выключение изображения героя в окне диалога.^mload — проигрывание музыки на определенном канале.^mload,BGM1,nbgm13
Проигрывание трека nbgm13 на канале BGM1
Одни из самых важных команд:
\jmp — переход к метке с указанным именем.^select — вывод на экран окошка выбора, где игрок должен выбрать один из вариантов.Например:
^select, Да, Нет \jmp,"@@route01a"+ResultBtnInt[0] @@route01a0
Здесь переход будет выполнен после ответа на вопрос, а номер ответа(0 или 1) возвращается из ResultBtnInt[0]. В итоге,
\jmp переместит повествование на метку @@route01a + номер ответа. То есть, @@route01a0 или @@route01a1Неприятная особенность в том, что обычная запятая в этих командах служит разделителем и не может быть использована в самих вариантах ответа. У японцев такой проблемы нет, они используют японскую запятую(、). Мы в данном случае можем заменить запятую на ‚ (U+201A SINGLE LOW-9 QUOTATION MARK).
Например:
^select, Пожалуй‚ я соглашусь, Нет‚ спасибо
Остальные команды не так важны в первом приближении.
Конечно, перед переводом сценарий стоит перекодировать во что-то более удобное, например в UTF-8, чтобы сочетать кириллические и японские символы.
После смены движка(об этом следующей части), игра воспринимает и русский текст, и японский. Но пока для совместимости требуется закодировать японские символы в Shift Jis, а кириллические – в кодировке cp1251.
Мы быстренько набросали программку на Питоне для перекодировки с учетом кириллицы:
UTF8 to cp1251 and ShiftJIS
# -*- coding: utf-8 -*- # UTF8 to cp1251 and ShiftJIS recoder # by Chtobi and Nazon, 2016 import codecs import argparse from os import path JAPANESE_CODEPAGE = 'shift_jis' UTF_CODEPAGE = 'utf-8' RUS_CODEPAGE = 'cp1251' def nonrus_handler(e): if e.object[e.start:e.end] == '~': # UTF-8: 0xEFBD9E -> SHIFT-JIS: 0x8160 japstr_byte = b'\x81\x60' elif e.object[e.start:e.end] == '-': # UTF-8: 0xEFBC8D -> SHIFT-JIS: 0x817C japstr_byte = b'\x81\x7c' else: japstr_byte = (e.object[e.start:e.end]).encode(JAPANESE_CODEPAGE) return japstr_byte, e.end if __name__ == '__main__': arg_parser = argparse.ArgumentParser(prog="Recode to cp1251 and ShiftJIS", description="Program to encode UTF8 text file to " "cp1251 for all cyrillic symbols and ShiftJIS for others. " "Output file will be inputfilename.s", usage="recode_to_cp1251_shiftjis.py file_name") arg_parser.add_argument('file_name', nargs=1, type=argparse.FileType(mode='r', bufsize=-1), help="Input text file name. Only files coded in UTF8 are allowed.\n") codecs.register_error('nonrus_handler', nonrus_handler) input_name = arg_parser.parse_args().file_name[0].name output_name = path.splitext(input_name)[0] + ".s" with open(input_name, 'rt', encoding=UTF_CODEPAGE) as input_file: with open(output_name, 'wb') as output_file: for line in input_file: for char1 in line: bytes_out = bytes(line, UTF_CODEPAGE) output_file.write(char1.encode(RUS_CODEPAGE, "nonrus_handler")) print("Done.")
Однако и тут не обошлось без проблем. Программа, при попытке перекодировать символ «тильды» ~(U+FF5E FULLWIDTH TILDE) выдавала ошибку «UnicodeEncodeError: 'Shift Jis' codec can't encode character '\uff5e' in position 0: illegal multibyte sequence»
Сначала я грешил на Питон, но в итоге выяснился довольно необычный нюанс. Существует неопределенность между методами соотношения юникодных и не юникодных японских кодировок в зависимости от конкретной реализации.
В итоге, Windows соотносит символ Shift Jis с кодом 0x8160 с юникодным ~ (U+FF5E FULLWIDTH TILDE), а другие перекодировщики(например, утилита iconv) соотносят тот же символ с 〜(U+301C WAVE DASH), согласно официальной таблицы соотношений юникода — ftp://ftp.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/SHIFT JIS.TXT
Для определения соответствий между символами Microsoft, видимо, решили использовать схемы из своей кодировки cp932, которая является расширенной версией Shift Jis.
Та же ситуация с символом с кодом 0x817C, который перекодируется в UTF8 как -(U+FF0D FULLWIDTH HYPHEN-MINUS) в Windows, или как − (U+2212 MINUS SIGN) в iconv.
Поскольку все файлы сценария были сначала переконвертированы из Shift Jis в UTF8 с помощью Notepad++(а он использует таблицу соответствия, принятую в Windows), то при обратной конвертации из UTF8 в Shift Jis через нашу питоновскую программу, появлялась пресловутая ошибка перекодировки.
Поэтому пришлось учитывать случаи появления ~ и -отдельными условиями.
Были и другие мелкие недочеты — например, многоточие … (U+2026 HORIZONTAL ELLIPSIS) заменялось кириллическим многоточием из cp1251, а не японским из Shift Jis.
После перевода текста можно переходить к работе с игровой графикой.
Графические файлы игры находятся в тех же pack архивах, но после распаковки над ними еще предстоит потрудиться. Например, почти все png картинки распаковываются в виде файлов типа sample+DPNG000+x32y0.png Иными словами, png изображения порезаны на горизонтальные полоски, толщиной 88 пикселей и каждая полоска записана в отдельный файл. В имени файла указан порядковый номер полоски(DPNG000...009) и координаты x,y.

Я до сих пор теряюсь в догадках, зачем это было нужно. Если для затруднения рипанья ресурсов из игры, то это явно не самый лучший метод.
Чтобы склеить разрезанные png файлы, в свое время был создан маленький скрипт merge_dpng на Перле от asmodeus, который использует ImageMagick. К сожалению, и с ним возникли проблемы. Во-первых, нужен был Перл, которым я не пользовался и даже после его установки, выяснилось, что скрипт неправильно работает.
По этому поводу мы написали аналогичную программу на питоне:
Qlie engine dpng files merger
# -*- coding: utf-8 -*- # Qlie engine dpng files merger # by Chtobi and Nazon, 2016 # Requires ImageMagick magick.exe on the path. import os import glob import re import argparse import subprocess IMGMAGIC = os.path.dirname(os.path.abspath(__file__)) + '\\' + 'magick.exe' IMGMAGIC_PARAMS1 = ['-background', 'rgba(0,0,0,0)'] IMGMAGIC_PARAMS2 = ['-mosaic'] INPUT_FILES_MASK = '*+DPNG[0-9][0-9][0-9]+*.png' SPLIT_MASK = '+DPNG' x_y_ajusts_re = re.compile('(.+)\+DPNG[0-9][0-9][0-9]\+x(\d+)y(\d+)\.') if __name__ == '__main__': arg_parser = argparse.ArgumentParser(prog="DPNG Merger\n" "Program to merge sliced png files from QLIE engine. " "All files with mask *+DPNG[0-9][0-9][0-9]+*.png" "into the input directory will be merged and copied to the" "output directory.\n", usage="connect_png.py input_dir [output_dir]\n") arg_parser.add_argument("input_dir_param", nargs=1, help="Full path to the input directory.\n") arg_parser.add_argument("output_dir_param", nargs='?', default=os.path.dirname(os.path.abspath(__file__)), help="Full path to the output directory. " "It would be a script parent directory if not specified.\n") input_dir = arg_parser.parse_args().input_dir_param[0] output_dir = arg_parser.parse_args().output_dir_param[0] os.chdir(input_dir) all_append_files = glob.glob(INPUT_FILES_MASK) # Select only files with DPNG prep_bunches = [] for file_in_dir in all_append_files: # Check all files and put all splices that should be connected in separate list for num, bunch in enumerate(prep_bunches): name_first_part = bunch[0].partition(SPLIT_MASK)[0] # Part of the filename before +DPNG should be unique if name_first_part == file_in_dir.partition(SPLIT_MASK)[0]: prep_bunches[num].append(file_in_dir) break else: prep_bunches.append([file_in_dir]) os.chdir(os.path.dirname(os.path.abspath(__file__))) # Go to the script parent dir for prepared_bunch in prep_bunches: sorted_bunch = sorted(prepared_bunch) # Prepare -page params for imgmagic png_pages_params = [["(", "-page", "+{0}+{1}".format(*[(x_y_ajusts_re.match(part_file).group(2)), x_y_ajusts_re.match(part_file).group(3)]), input_dir+part_file, ")"] for part_file in sorted_bunch] connect_png_list = \ [imgmagick_page for imgmagick_pages in png_pages_params for imgmagick_page in imgmagick_pages] output_file = output_dir + sorted_bunch[0].partition(SPLIT_MASK)[0] + ".png" subprocess.check_output([IMGMAGIC] + IMGMAGIC_PARAMS1 + connect_png_list + IMGMAGIC_PARAMS2 + [output_file])
Казалось бы, теперь мы получили весь набор картинок, который появляется в игре? Отнюдь — если просмотреть все соединенные картинки из всех архивов, то все равно окажется, что каких-то не хватает, хотя в игре они есть. Дело в том, что в движке имеется еще один тип файлов — с расширением .b. Это что-то вроде анимации с записанными внутри изображениями и звуками.
Хранящиеся внутри ресурсы достать довольно легко, но, увы, ни один из готовых распаковщиков .b файлов в нашем случае не отработал как надо. Либо некоторые файлы оставались нераспакованными, либо случались ошибки из-за японских имен, а загружаться с японской локалью не хотелось.
Тут пригодился еще один наш скрипт. Поскольку тогда мы не были знакомы с чем-то вроде Kaitai Struct, пришлось действовать почти с нуля.
Формат .b файлов оказался простым и, к тому же, от нашего распаковщика требовалась возможность распаковывать ресурсы только из этой игры. В других играх на движке Qlie появлялись дополнительные виды ресурсов внутри .b файлов, но мы на них подробно останавливаться не будем.
Итак, открываем любой .b файл в шестнадцатиричном редакторе и смотрим в начало. Перед оценкой следует учесть, что порядок байтов всех числовых значений будет Little-endian.
- Заголовок файла abmp12
- Десять байт 0x00
- Заголовок первой секции abdata12 со служебной информацией.
- Восемь байт 0x00
- Размер секции abdata12, четырехбайтовое целое. Можно смело ее пропустить.
- Заголовок секции abimage10
- Семь байт 0x00
- Количество файлов в секции, однобайтовое целое. В данном случае – в секции один файл.
- Заголовок секции abgimgdat13
- Шесть байт 0x00
- Длина имени файла внутри секции, двухбайтовое целое. В данном случае длина – 4 байта.
- Имя файла в кодировке Shift Jis
- Длина записи контрольной суммы файла, двухбайтовое целое.
- Сама контрольная сумма файла.
- Неизвестный байт, судя по всему, всегда равен 0x03 или 0x02
- Двенадцать неизвестных байтов, возможно, связаны с анимацией
- Размер png файла внутри секции, четырехбайтовое целое.
И наконец, сам png файл.
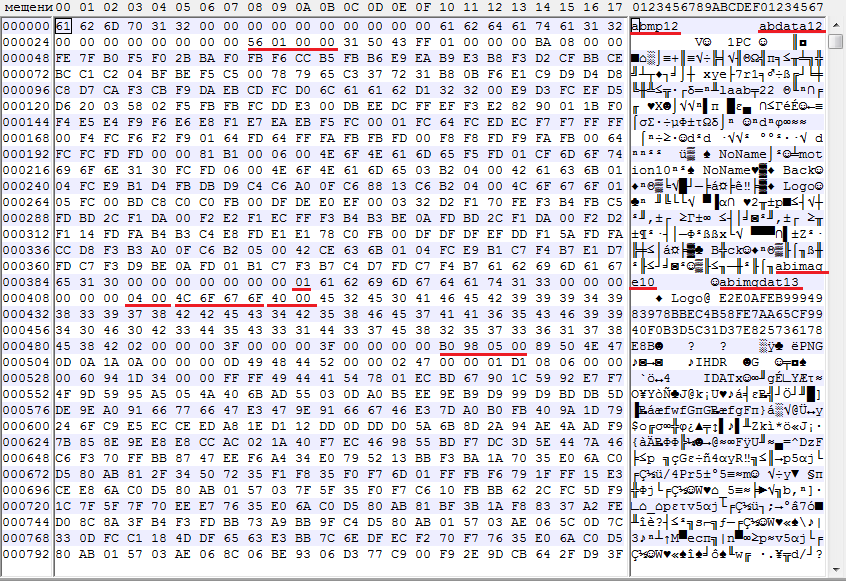
Секция absound аналогична по строению abimage.
AnimatedBMP extractor
# -*- coding: utf-8 -*- # Extract b # AnimatedBMP extractor for Bishoujo Mangekyou game files # by Chtobi and Nazon, 2016 import glob import os import struct import argparse from collections import namedtuple b_hdr = b'abmp12'+bytes(10) signa_len = 16 b_abdata = (b'abdata10'+bytes(8), b'abdata11'+bytes(8), b'abdata12'+bytes(8), b'abdata13'+bytes(8)) b_imgdat = (b'abimgdat10'+bytes(6), b'abimgdat11'+bytes(6), b'abimgdat14'+bytes(6)) b_img = (b'abimage10'+bytes(7), b'abimage11'+bytes(7), b'abimage12'+bytes(7), b'abimage13'+bytes(7), b'abimage14'+bytes(7)) b_sound = (b'absound10'+bytes(7), b'absound11'+bytes(7), b'absound12'+bytes(7)) # not sure about structure of sound11 and sound12 b_snd = (b'absnddat11'+bytes(7), b'absnddat10'+bytes(7), b'absnddat12'+bytes(7)) Abimgdat13_pattern = namedtuple('Abimgdat13', ['signa', 'name_size_len', 'hash_size_len', 'unknown1_len', 'unknown2_len', 'data_size_len']) Abimgdat13 = Abimgdat13_pattern(signa=b'abimgdat13'+bytes(6), name_size_len=2, hash_size_len=2, unknown1_len=1, unknown2_len=12, data_size_len=4) Abimgdat14_pattern = namedtuple('Abimgdat14', ['signa', 'name_size_len', 'hash_size_len', 'unknown1_len', 'data_size_len']) Abimgdat14 = Abimgdat14_pattern(signa=b'abimgdat14'+bytes(6), name_size_len=2, hash_size_len=2, unknown1_len=77, data_size_len=4) Abimgdat_pattern = namedtuple('Abimgdat', ['name_size_len', 'hash_size_len', 'unknown1_len', 'data_size_len']) # probably, abimgdat10,abimgdat11 and others Other_imgdat = Abimgdat_pattern(name_size_len=2, hash_size_len=2, unknown1_len=1, data_size_len=4) Absnddat11_pattern = namedtuple('Absnddat11', ['signa', 'name_size_len', 'hash_size_len', 'unknown1_len', 'data_size_len']) Absnddat11 = Absnddat11_pattern(signa=b'absnddat11'+bytes(7), name_size_len=2, hash_size_len=2, unknown1_len=1, data_size_len=4) def create_parser(): arg_parser = argparse.ArgumentParser(prog='AnimatedBMP extractor\n', usage='extract_b input_file_name output_dir\n', description='AnimatedBMP extractor for QLIE engine *.b files.\n') arg_parser.add_argument('input_file_name', nargs='+', help="Input file with full path(wildcards are supported).\n") arg_parser.add_argument('output_dir', nargs=1, help="Output directory.\n") return arg_parser def check_type(file_buf): if file_buf.startswith(b'\x89' + b'PNG'): return '.png' elif file_buf.startswith(b'BM'): return '.bmp' elif file_buf.startswith(b'JFIF', 6): return '.jpg' elif file_buf.startswith(b'IMOAVI'): return '.imoavi' elif file_buf.startswith(b'OggS'): return '.ogg' elif file_buf.startswith(b'RIFF'): return '.wav' else: return '' def bytes_shiftjis_to_utf8(shiftjis_bytes): shiftjis_str = shiftjis_bytes.decode('shift_jis', 'strict') utf_str = shiftjis_str.encode('utf-8', 'strict').decode('utf-8', 'strict') return utf_str def check_signa(f_buffer): if f_buffer.endswith(b_abdata): return 'abdata' elif f_buffer.endswith(b_img): return 'abimgdat' elif f_buffer.endswith(b_sound): return 'absound' def prepare_filename(out_file_name, out_dir, postfix=''): ready_name = out_dir + os.path.basename(out_file_name) + postfix return ready_name def create_file(file_name_hndl, out_buffer): if len(out_buffer) != 0: with open(file_name_hndl, 'wb') as ext_file: ext_file.write(out_buffer) else: print("Zero file. Skipped.") def check_file_header(file_handle, bytes_num): file_handle.seek(0) readed_bytes = file_handle.read(bytes_num) if readed_bytes == b_hdr: print("File is valid abmp") return True else: print("Can't read header. Probably, wrong file...") return False if __name__ == '__main__': parser = create_parser() arguments = parser.parse_args() all_b_files = glob.glob(arguments.input_file_name[0]) output_dir = arguments.output_dir[0] for b_file in all_b_files: file_buffer = bytearray(b'') with open(b_file, 'rb') as bfile_h: check_file_header(bfile_h, len(b_hdr)) read_byte = bfile_h.read(1) file_buffer.extend(read_byte) while read_byte: read_byte = bfile_h.read(1) file_buffer.extend(read_byte) # Finding content sections signature check_result = check_signa(file_buffer) if check_result: if check_result == 'abdata': file_buffer = bytearray(b'') read_length = bfile_h.read(4) size = struct.unpack('<L', read_length)[0] file_buffer.extend(bfile_h.read(size)) # Adding _abdata to separate from other parts outfile_name = prepare_filename(b_file, output_dir, '_abdata') create_file(outfile_name, file_buffer) elif check_result == 'abimgdat': images_number = struct.unpack('B', bfile_h.read(1))[0] # Number of pictures in section for i1 in range(images_number): file_buffer = bytearray(b'') file_name = '' imgsec_hdr = bfile_h.read(signa_len) if imgsec_hdr == Abimgdat13.signa: file_name_size = struct.unpack('<H', bfile_h.read(Abimgdat13.name_size_len))[0] # Decode filename to utf8 file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size)) # CRC size hash_size = struct.unpack('<H', bfile_h.read(Abimgdat13.hash_size_len))[0] # Picture CRC (don't need it) pic_hash = bfile_h.read(hash_size) unknown1 = bfile_h.read(Abimgdat13.unknown1_len) unknown2 = bfile_h.read(Abimgdat13.unknown2_len) pic_size = struct.unpack('<L', bfile_h.read(Abimgdat13.data_size_len))[0] print("pic_size:", pic_size) file_buffer.extend(bfile_h.read(pic_size)) elif imgsec_hdr == Abimgdat14.signa: file_name_size = struct.unpack('<H', bfile_h.read(Abimgdat14.name_size_len))[0] file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size)) hash_size = struct.unpack('<H', bfile_h.read(Abimgdat14.hash_size_len))[0] pic_hash = bfile_h.read(hash_size) bfile_h.seek(Abimgdat14.unknown1_len, os.SEEK_CUR) pic_size = struct.unpack('<L', bfile_h.read(Abimgdat14.data_size_len))[0] file_buffer.extend(bfile_h.read(pic_size)) else: # probably abimgdat10, abimgdat11... file_name_size = struct.unpack('<H', bfile_h.read(Other_imgdat.name_size_len))[0] file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size)) hash_size = struct.unpack('<H', bfile_h.read(Other_imgdat.hash_size_len))[0] pic_hash = bfile_h.read(hash_size) bfile_h.seek(Other_imgdat.unknown1_len, os.SEEK_CUR) pic_size = struct.unpack('<L', bfile_h.read(Other_imgdat.data_size_len))[0] file_buffer.extend(bfile_h.read(pic_size)) for i, letter in enumerate(file_name): # Replace any unusable symbols from filename with _ if letter == '<' or letter == '>' or letter == '*' or letter == '/': file_name = file_name.replace(letter, "_") # Checking file signature and adding proper extension outfile_name = prepare_filename(b_file, output_dir, '_' + file_name + check_type(file_buffer)) create_file(outfile_name, file_buffer) file_buffer = bytearray(b'') elif check_result == 'absound': sound_files_number = struct.unpack('B', bfile_h.read(1))[0] for i2 in range(sound_files_number): file_buffer = bytearray(b'') file_name = '' sndsec_hdr = bfile_h.read(signa_len) if sndsec_hdr == Absnddat11.signa: file_name_size = struct.unpack('<H', bfile_h.read(Absnddat11.name_size_len))[0] file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size)) hash_size = struct.unpack('<H', bfile_h.read(Absnddat11.hash_size_len))[0] snd_hash = bfile_h.read(hash_size) unknown1 = bfile_h.read(Absnddat11.unknown1_len) snd_size = struct.unpack('<L', bfile_h.read(Absnddat11.data_size_len))[0] file_buffer.extend(bfile_h.read(snd_size)) else: file_name_size = struct.unpack('<H', bfile_h.read(Absnddat11.name_size_len))[0] file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size)) hash_size = struct.unpack('<H', bfile_h.read(Absnddat11.hash_size_len))[0] snd_hash = bfile_h.read(hash_size) unknown1 = bfile_h.read(Absnddat11.unknown1_len) snd_size = struct.unpack('<L', bfile_h.read(Absnddat11.data_size_len))[0] file_buffer.extend(bfile_h.read(snd_size)) for i, letter in enumerate(file_name): if letter == '<' or letter == '>' or letter == '*' or letter == '/': file_name[i] = '_' outfile_name = prepare_filename(b_file, output_dir, '_' + file_name + check_type(file_buffer)) print("create absound") create_file(outfile_name, file_buffer) file_buffer = bytearray(b'')
Скрипт должен автоматически распаковывать найденные файлы png, jpg, bmp, ogg и wav. Но помимо этого, внутри попадаются еще и неизвестные файлы imoavi.
Суть в том, что в игре все анимации сделаны либо как полноценное видео в ogv формате, либо как анимированные движком изображения, которые записаны в .b файлы, либо как анимированные последовательности jpg файлов в формате imoavi.
В данном случае, нас интересовали и jpg изображения, поэтому пришлось разбираться с ними также.
В imoavi существуют две секции: SOUND и MOVIE. В секции MOVIE через 47 байтов после заголовка, находятся четыре байта размера jpg файла. Файлы записаны друг за другом в исходном виде, разделенные последовательностью в 19 байт, где записан размер следующего файла.
Озвученные imoavi в игре не попадались, поэтому секция SOUND всегда пустая.
Ну и раз уж мы начали заниматься вытаскиванием всех ресурсов игры, заодно был написан и маленький скрипт для вытаскивания jpg из imoavi.
Imoavi extractor
# -*- coding: utf-8 -*- # Extract imoavi # Imoavi extractor for Bishoujo Mangekyou game files # by Chtobi and Nazon, 2016 import glob import os import struct import argparse imoavi_hdr = b'IMOAVI' hdr_len = len(imoavi_hdr) def create_file(file_name, out_buffer, wr_mode='wb'): if len(out_buffer) != 0: with open(file_name, wr_mode) as ext_file: ext_file.write(out_buffer) else: print("Zero file. Skipped.") def prepare_filename(file_name, out_dir, postfix=''): ready_name = out_dir + os.path.basename(file_name) + postfix return ready_name def create_parser(): arg_parser = argparse.ArgumentParser(prog='Imoavi extractor\n', usage='extract_imoavi input_file_name output_dir\n', description='Imoavi extractor for QLIE engine *.imoavi files.\n') arg_parser.add_argument('input_file_name', nargs='+', help="Input file with full path(wildcards are supported).\n") arg_parser.add_argument('output_dir', nargs='+', help="Output directory.\n") return arg_parser if __name__ == '__main__': parser = create_parser() arguments = parser.parse_args() all_imoavi = glob.glob(arguments.input_file_name[0]) output_dir = arguments.output_dir[0] for imoavi_f in all_imoavi: file_buffer = bytearray(b'') with open(imoavi_f, 'rb') as imoavi_h: # Read imoavi file header imoavi_h.read(hdr_len) imoavi_h.seek(2, os.SEEK_CUR) # 0x00 imoavi_h.seek(1, os.SEEK_CUR) # 0x64 imoavi_h.seek(3, os.SEEK_CUR) # 0x00 imoavi_h.seek(5, os.SEEK_CUR) # SOUND imoavi_h.seek(3, os.SEEK_CUR) # 0x00 imoavi_h.seek(1, os.SEEK_CUR) # 0x64 imoavi_h.seek(11, os.SEEK_CUR) imoavi_h.seek(5, os.SEEK_CUR) # Movie imoavi_h.seek(3, os.SEEK_CUR) # 00 ?? imoavi_h.seek(1, os.SEEK_CUR) # 0x64 imoavi_h.seek(3, os.SEEK_CUR) # 0x00 ?? imoavi_h.seek(4, os.SEEK_CUR) # ?? imoavi_h.seek(1, os.SEEK_CUR) # Number of jpg files in section imoavi_h.seek(4, os.SEEK_CUR) # 0x00 imoavi_h.seek(1, os.SEEK_CUR) # 0x05 ??? imoavi_h.seek(2, os.SEEK_CUR) # 0x00 ?? imoavi_h.seek(4, os.SEEK_CUR) # 720 ?? imoavi_h.seek(4, os.SEEK_CUR) # Full size without header? to_next_size = struct.unpack('<L', imoavi_h.read(4))[0] # Bytes till next header imoavi_h.seek(16, os.SEEK_CUR) # 0x00 jpg_size = struct.unpack('<L', imoavi_h.read(4))[0] imoavi_h.seek(4, os.SEEK_CUR) # 0x00 file_num = 0 file_buffer.extend(imoavi_h.read(jpg_size)) outfile_name = prepare_filename(imoavi_f, output_dir, '_' + (str(file_num)).zfill(3) + '.jpg') create_file(outfile_name, file_buffer) while to_next_size != 0: file_buffer = bytearray(b'') to_next_size = struct.unpack('<L', imoavi_h.read(4))[0] if to_next_size == 24: # 0x1C header for index part file_buffer.extend(imoavi_h.read(to_next_size)) outfile_name = prepare_filename(imoavi_f, output_dir, '_' + '.index') create_file(outfile_name, file_buffer, 'ab') # concatenate with index file else: imoavi_h.seek(2, os.SEEK_CUR) # unknown imoavi_h.seek(2, os.SEEK_CUR) # Unknown, almost always FF FF or FF FE file_num = struct.unpack('B', imoavi_h.read(1))[0] # File number imoavi_h.seek(11, os.SEEK_CUR) # 0x00 jpg_size = struct.unpack('<L', imoavi_h.read(4))[0] imoavi_h.seek(4, os.SEEK_CUR) # 0x00 file_buffer.extend(imoavi_h.read(jpg_size)) outfile_name = prepare_filename(imoavi_f, output_dir, '_' + (str(file_num)).zfill(3) + '.jpg') create_file(outfile_name, file_buffer)
После распаковки, можно убедиться, что анимация из заставки в меню хранится как раз в файле 1_タイトル画面ムービー.b в формате imoavi.

На этом с игровыми ресурсами все.
К сожалению, в процессе перевода выяснилось еще несколько неприятных нюансов, которые преодолеть так и не удалось. Игра, как я уже писал, не поддерживает юникодных кодировок. Поэтому, весь переведенный текст выводится с неправильным межбуквенным интервалом. Было еще несколько проблем с обратной запаковкой файлов и с запуском игры без смены системной кодировки на японскую.
В какой-то момент мы(вернее, тот, кто отвечал за техническую часть перевода в нашей команде) задумались: а может, не стоит таскаться со старым движком, а портировать новеллу на движок Renpy, заодно получив и кроссплатформерность?
Возможно, мы поторопились, но в какой-то момент, бросать начатое стало жалко и ничего не оставалось, кроме как закончить перевод.
С чем же нам пришлось столкнуться во время портирования?
Об этом во второй части.
Ссылки:
Наши скрипты на bitbucket
О движке Qlie на японском
Таблица кодировки Shift Jis
Подробнее о проблеме перекодировки из Shift Jis в UTF-8
Утилита exfp3_v3 от asmodean

