[часть 2 из 2]

Как нам это удалось
Мы решили перейти на GCP, чтобы повысить производительность приложений — увеличив при этом масштаб, но без существенных затрат. Весь процесс занял более 2 месяцев. Для решения этой задачи мы сформировали специальную группу инженеров.
В этой публикации мы расскажем о выбранном подходе и его реализации, а также о том, как нам удалось достичь главной цели, — осуществить этот процесс максимально гладко и перенести всю инфраструктуру на облачную платформу Google Cloud Platform, не снижая качества обслуживания пользователей.

Планирование
- Подготовлен подробный контрольный список, определяющий каждый возможный шаг. Создана блок-схема для описания последовательности.
- Разработан план возврата в исходное состояние, который мы, если что, могли бы использовать.
Несколько мозговых штурмов — и мы определили самый понятный и простой подход для реализации схемы «активный-активный». Он заключается в том, что небольшой набор пользователей размещается на одном облаке, а остальные — на другом. Однако этот подход вызывал проблемы, особенно на стороне клиента (связанные с управлением DNS), и приводил к задержкам при репликации баз данных. Из-за этого его практически невозможно было реализовать безопасно. Очевидный метод не дал нужного решения, и нам пришлось разработать специализированную стратегию.
Опираясь на диаграмму зависимостей и требования эксплуатационной безопасности, мы разделили инфраструктурные услуги на 9 модулей.

(Основные модули для развертывания хостинга инфраструктуры)
Каждая инфраструктурная группа управляла общими внутренними и внешними службами.
⊹ Инфраструктурная служба обмена сообщениями: MQTT, HTTPs, Thrift, сервер Gunicorn, модуль организации очереди, клиент Async, сервер Jetty, кластер Kafka.
⊹ Службы хранилища данных: распределенный кластер MongoDB, Redis, Cassandra, Hbase, MySQL и MongoDB.
⊹ Инфраструктурная аналитическая служба: кластер Kafka, кластер хранилища данных (HDFS, HIVE).
Подготовка к знаменательному дню:
✓ Подробный план перехода на GCP для каждой службы: последовательность, хранилище данных, план возврата в исходное состояние.
✓ Межпроектные сетевые взаимодействия (общее виртуальное частное облако VPC[XPN]) в GCP для изоляции различных частей инфраструктуры, оптимизации управления, повышения безопасности и связности.
✓ Несколько VPN-туннелей между GCP и запущенным виртуальным частным облаком (VPC) для упрощения передачи больших объемов данных по сети в процессе репликации, а также для возможного впоследствии развертывания параллельной системы.
✓ Автоматизация установки и настройки всего стека с помощью системы Chef.
✓ Скрипты и инструменты автоматизации для развертывания, мониторинга, ведения журналов и т. д.
✓ Настройка всех требуемых подсетей и управляемых правил брандмауэра для системного потока.
✓ Репликация в нескольких центрах обработки данных (Multi-DC) для всех систем хранения данных.
✓ Настройка балансировщиков нагрузки (GLB/ILB) и групп управляемых экземпляров (MIG).
✓ Скрипты и код для переноса контейнера хранилища объектов в облачное хранилище GCP Cloud Storage с контрольными точками.
Вскоре мы выполнили все необходимые предварительные требования и подготовили контрольный список элементов для переноса инфраструктуры на платформу GCP. После многочисленных обсуждений, а также учитывая количество служб и диаграмму их зависимостей, мы решили выполнить перенос облачной инфраструктуры в GCP за три ночи, чтобы охватить все службы серверной части и хранилища данных.
Переход
Стратегия переноса балансировщика нагрузки:
Используемый ранее управляемый кластер HAProxy мы заменили глобальным балансировщиком нагрузки для обработки десятков миллионов подключений активных пользователей ежедневно.
⊹ Этап 1:
- Созданы MIG с правилами перенаправления пакетов для пересылки всего трафика на IP-адреса MQTT в существующем облаке.
- Создан балансировщик SSL и TCP Proxy с MIG в качестве серверной части.
- Для MIG запущен HAProxy с серверами MQTT в качестве серверной части.
- В DNS в политике маршрутизации с учетом весовых коэффициентов добавлен внешний IP-адрес GLB.
Постепенно развернуты пользовательские подключения при отслеживании их показателей.
⊹ Этап 2: Промежуточный этап перехода, начало развертывания служб в GCP.
⊹ Этап 3: Заключительный этап перехода, все службы перенесены в GCP.

(Этапы переноса балансировщика нагрузки)
На данном этапе все работало, как и ожидалось. Вскоре настало время для развертывания нескольких внутренних HTTP-служб в GCP с маршрутизацией — учитывая вес коэффициентов. Мы внимательно следили за всеми показателями. Когда мы начали постепенно увеличивать трафик, то за день до запланированного перехода задержки при взаимодействии VPC через VPN (регистрировались задержки в 40 мс — 100 мс, хотя раньше они были менее 10 мс) выросли.
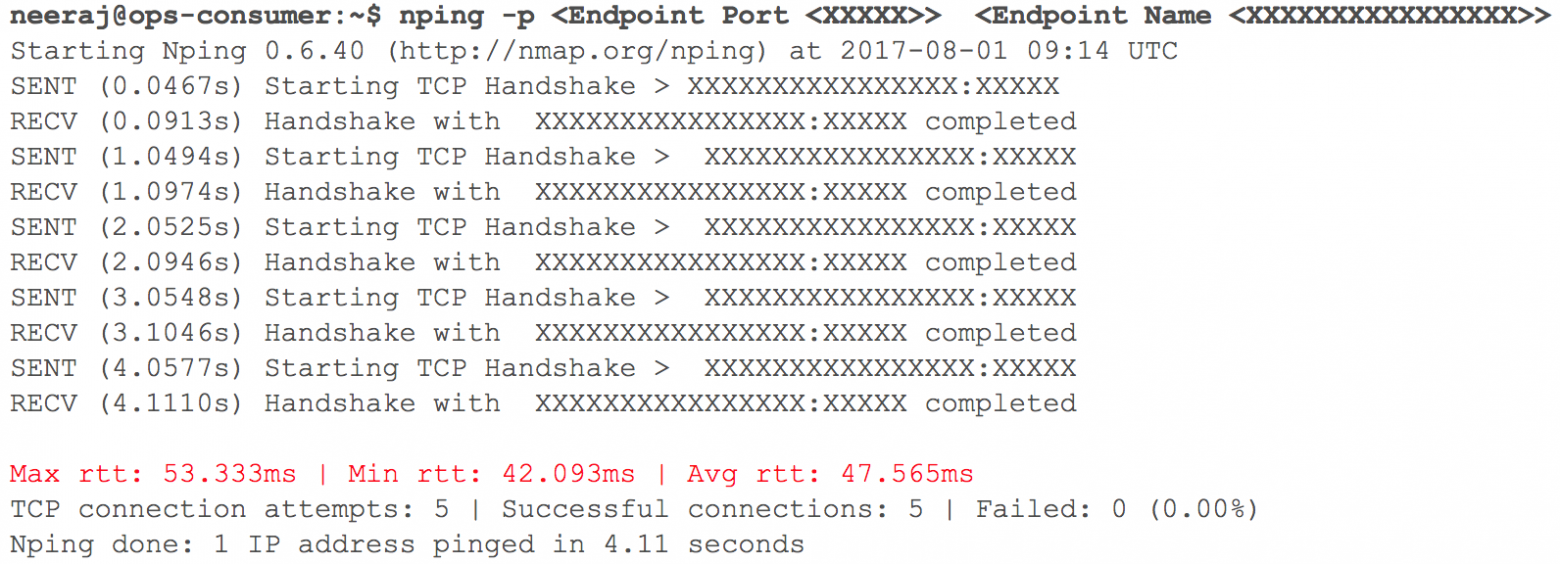
(Снапшот проверки задержки сети при взаимодействии двух VPC)
Мониторинг четко показал: с обоими облачными сетевыми каналами, использующими VPN-туннели, что-то не так. Даже пропускная способность VPN-туннеля не достигала оптимальной отметки. Эта ситуация начала негативно влиять на некоторые из наших пользовательских служб. Мы немедленно вернули все перенесенные ранее HTTP-службы в исходное состояние. Связались с командами поддержки TAM и облачных сервисов, предоставили необходимые исходные данные и начали разбираться, почему растут задержки. Специалисты поддержки пришли к выводу: достигнута максимальная пропускная способность сети в облачном канале между двумя поставщиками облачных сервисов. Отсюда и рост задержек в сети при переносе внутренних систем.
Этот инцидент заставил приостановить переход в облако. Поставщики облачных сервисов не могли удвоить пропускную способность канала достаточно быстро. Поэтому мы вернулись к этапу планирования и пересмотрели стратегию. Решили выполнить перенос облачной инфраструктуры в GCP за одну ночь вместо трех и включили в план все службы серверной части и хранилища данных. Когда наступил час «X», все прошло как по маслу: рабочие нагрузки были успешно перенесены в Google Cloud незаметно для наших пользователей!
Стратегия переноса базы данных:
Необходимо было перенести более 50 конечных точек базы данных для реляционной СУБД, хранилище в оперативной памяти, а также NoSQL и распределенные и масштабируемые кластеры с низкой задержкой. Реплики всех баз данных мы разместили в GCP. Это было сделано для всех развертываний, за исключением HBase.
⊹ Репликация «ведущий-ведомый»: реализована для кластеров MySQL, Redis, MongoDB и MongoS.
⊹ Репликация Multi-DC: реализована для кластеров Cassandra.
⊹ Сдвоенные кластеры: для Hbase в GCP был настроен параллельный кластер. Существующие данные были перенесены, была настроена двойная запись в соответствии со стратегией поддержания согласованности данных в обоих кластерах.
В случае с HBase проблема заключалась в настройке с помощью Ambari. Мы столкнулись с некоторыми сложностями при размещении кластеров в нескольких центрах обработки данных, например, возникали проблемы с DNS, скриптом распознавания стоек и т. д.
Заключительные шаги (после переноса серверов) включали перенос реплик на главные серверы и отключение старых баз данных. Как и планировалось, определяя очередность переноса баз данных, мы использовали Zookeeper для необходимой настройки кластеров приложений.

Стратегия переноса служб приложений
Для переноса рабочих нагрузок служб приложений с текущего хостинга в облако GCP мы использовали подход «lift-and-shift». Для каждой службы приложений мы создали группу управляемых экземпляров (MIG) с автоматическим масштабированием.
В соответствии с подробным планом мы начали переносить службы в GCP с учетом очередности и зависимостей хранилищ данных. Все службы стека обмена сообщениями были перенесены в GCP без малейшего простоя. Да, возникали некоторые незначительные сбои, но с ними мы разбирались немедленно.

С самого утра, по мере увеличения активности пользователей, мы внимательно следили за всеми информационными панелями и показателями, чтобы быстро выявить проблемы. Кое-какие затруднения и правда возникли, но мы смогли оперативно устранить их. Одна из проблем была обусловлена ограничениями внутреннего балансировщика нагрузки (ILB), способного обслуживать не более 20 000 одновременных подключений. А нам нужно было в 8 раз больше! Поэтому мы добавили дополнительные ILB в наш слой управления соединениями.
В первые часы пиковой нагрузки после перехода мы контролировали все параметры особенно тщательно, поскольку вся нагрузка стека обмена сообщениями была перенесена в GCP. Было несколько незначительных сбоев, с которыми мы очень быстро разобрались. При переносе других служб мы придерживались того же подхода.
Перенос хранилища объектов:
Службу хранилища объектов мы используем в основном тремя способами.
⊹ Хранение медиафайлов, отправляемых в личный или групповой чат. Срок хранения определяется политикой управления жизненным циклом.
⊹ Хранение изображений и миниатюр пользовательского профиля.
⊹ Хранение медиафайлов из разделов «Истории» и «Timeline» и соответствующих миниатюр.
Мы использовали инструмент переноса хранилищ от Google для копирования старых объектов из S3 в GCS. Мы также применяли пользовательскую MIG на основе Kafka для переноса объектов из S3 в GCS, когда требовалась специальная логика.
Переход с S3 на GCS включал следующие шаги:
● Для первого варианта использования хранилища объектов мы начали записывать новые данные как в S3, так и в GCS, а после истечения срока действия начали считывать данные из GCS, используя логику на стороне приложения. Перенос старых данных не имеет смысла, и такой подход экономически эффективен.
● Для второго и третьего вариантов использования мы начали записывать новые объекты в GCS и изменили путь для чтения данных таким образом, чтобы поиск сначала выполнялся в GCS и только затем, если объект не найден, — в S3.
На планирование, проверку правильности концепции, подготовку и прототипирование ушли месяцы, зато потом мы решились на переход и осуществили его очень быстро. Оценили риски и поняли, что быстрая миграция — предпочтительней и практически незаметна.
Этот масштабный проект помог нам занять уверенные позиции и повысить производительность команды во многих сферах, поскольку большая часть ручных операций по управлению облачной инфраструктурой теперь в прошлом.
● Что касается пользователей, теперь мы получили все необходимое, чтобы обеспечить высочайшее качество их обслуживания. Простои почти исчезли, а новые функции внедряются быстрее.
● Наша команда тратит меньше времени на задачи технического обслуживания и может сосредоточиться на проектах в области автоматизации и создании новых инструментов.
● Мы получили доступ к беспрецедентному набору инструментов для работы с большими данными, а также готовый функционал для машинного обучения и анализа. Подробности об этом см. здесь
● Приверженность Google Cloud к работе с открытым проектом Kubernetes также соответствует нашему плану развития на этот год.

