Как можно перевести бизнес-требования в конкретные структуры данных на примере проектирования «с нуля» базы для мессенджера.

Наша база будет не такой масштабной и распределенной, как у ВКонтакте или Badoo, а «чтобы было», но было хорошо — функционально, быстро и умещалось на одном сервере PostgreSQL — чтобы можно было развернуть отдельный экземпляр сервиса где-то на стороне, например.
Поэтому не будем затрагивать вопросы шардинга, репликации и геораспределенных систем, а сосредоточимся на схемных решениях внутри БД.
Наш обмен сообщениями мы будем проектировать не абстрактно, а встраивать в окружение корпоративной соцсети. То есть люди у нас не «просто переписываются», а общаются между собой в контексте решения определенных бизнес-задач.
А какие бывают задачи у бизнеса?.. Посмотрим на примере Василия — руководителя отдела разработки.
Остановимся пока на этом перечне «очевидных» потребностей.
Схемно пока все получается очень похоже на email-переписку — традиционный инструмент ведения бизнеса. Таки да, «алгоритмически» многие задачи бизнеса похожи друг на друга, поэтому и инструменты для их решения будут структурно сходны.
Давайте зафиксируем уже получившуюся логическую схему отношений сущностей. Для простоты понимания нашей модели воспользуемся самым примитивным вариантом отображения ER-модели без усложнений UML или IDEF-нотаций:
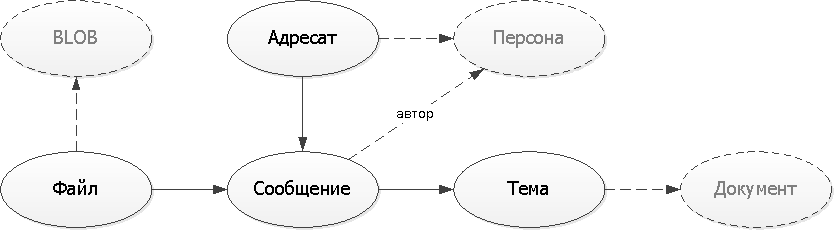
В нашем примере персона, документ и бинарное «тело» файла — это «внешние» сущности, которые самостоятельно существуют и без нашего сервиса. Поэтому просто будем воспринимать их в дальнейшем как некоторые ссылки «куда-то» по UUID.
Поскольку сообщения у нас пишут много людей сразу, часть из них вообще могут делать это в оффлайн-режиме, то самый простой вариант — использовать UUID в качестве идентификаторов не только для внешних сущностей, но и для всех объектов внутри нашего сервиса. Причем генерировать их можно даже на клиентской стороне — это поможет нам поддержать отправку сообщений при кратковременной недоступности БД, а вероятность коллизии крайне мала.
Черновая структура таблиц в нашей базе примет вот такой вид:
Все, мы спроектировали базу, в которую можно отлично писать и как-то читать.
Давайте поставим себя на место пользователя нашего сервиса — что мы захотим делать с его помощью?
Наша структура позволяет решить обе эти задачи «вообще», но быстро — нет. Проблема в том, что для сортировки в рамках первой задачи невозможно создать индекс, подходящий для каждого из участников (и придется извлекать все записи), а для решения второй необходимо извлекать все-все сообщения по теме.
Обе наши проблемы помогут решить дополнительные таблицы, в которые мы будем дублировать часть данных, необходимых для формирования на них подходящих к нашим задачам индексов.
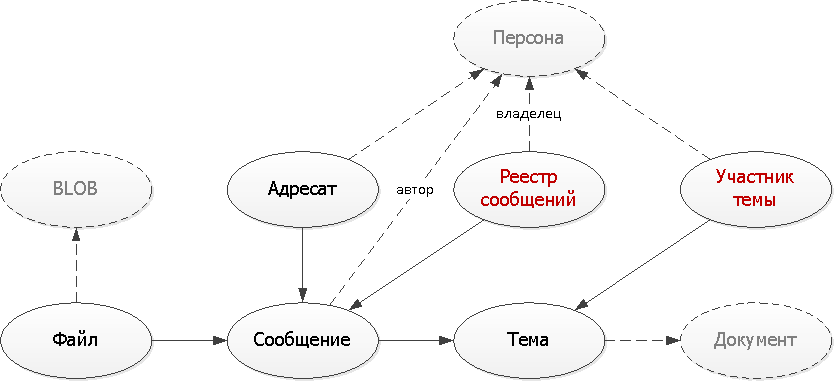
Здесь мы применили два типичных подхода, применяемых при создании вспомогательных таблиц:
В следующей части статьи речь пойдет про внедрение секционирования в структуру нашей базы.
- Часть 1: проектируем каркас базы
- Часть 2: секционируем «наживую»
Наша база будет не такой масштабной и распределенной, как у ВКонтакте или Badoo, а «чтобы было», но было хорошо — функционально, быстро и умещалось на одном сервере PostgreSQL — чтобы можно было развернуть отдельный экземпляр сервиса где-то на стороне, например.
Поэтому не будем затрагивать вопросы шардинга, репликации и геораспределенных систем, а сосредоточимся на схемных решениях внутри БД.
Шаг 1: Немного бизнес-специфики
Наш обмен сообщениями мы будем проектировать не абстрактно, а встраивать в окружение корпоративной соцсети. То есть люди у нас не «просто переписываются», а общаются между собой в контексте решения определенных бизнес-задач.
А какие бывают задачи у бизнеса?.. Посмотрим на примере Василия — руководителя отдела разработки.
- «Николай, вот по этой задаче патч нужен уже сегодня!»
Значит, переписка может вестись в контексте какого-то документа. - «Коля, го вечером в доту?»
То есть даже у одной пары собеседников общение одновременно может вестись по разным темам. - «Петр, Николай, посмотрите в аттаче прайс на новый сервер.»
Так, у одного сообщения может быть несколько адресатов. При этом сообщение может содержать прикрепленные файлы. - «Семен, и ты тоже взгляни.»
И должна быть возможность в уже существующую переписку пригласить нового участника.
Остановимся пока на этом перечне «очевидных» потребностей.
Без понимания прикладной специфики задачи и задаваемых ей ограничений, спроектировать эффективную схему БД для ее решения практически невозможно.
Шаг 2: Минимальная логическая схема
Схемно пока все получается очень похоже на email-переписку — традиционный инструмент ведения бизнеса. Таки да, «алгоритмически» многие задачи бизнеса похожи друг на друга, поэтому и инструменты для их решения будут структурно сходны.
Давайте зафиксируем уже получившуюся логическую схему отношений сущностей. Для простоты понимания нашей модели воспользуемся самым примитивным вариантом отображения ER-модели без усложнений UML или IDEF-нотаций:
В нашем примере персона, документ и бинарное «тело» файла — это «внешние» сущности, которые самостоятельно существуют и без нашего сервиса. Поэтому просто будем воспринимать их в дальнейшем как некоторые ссылки «куда-то» по UUID.
Рисуйте схемы как можно проще — большинство тех, кому вы их будете показывать, не являются экспертами в чтении UML/IDEF. Но — рисуйте обязательно.
Шаг 3: Набрасываем структуру таблиц
Про имена таблиц и полей
К «русским» названиям полей и таблиц можно относиться по-разному, но это дело вкуса. Поскольку у нас в «Тензоре» нет разработчиков-иностранцев, а PostgreSQL позволяет нам давать названия хоть иероглифами, если они заключены в кавычки, то мы предпочитаем именовать объекты однозначно-понятно, чтобы не возникало разночтений.
Поскольку сообщения у нас пишут много людей сразу, часть из них вообще могут делать это в оффлайн-режиме, то самый простой вариант — использовать UUID в качестве идентификаторов не только для внешних сущностей, но и для всех объектов внутри нашего сервиса. Причем генерировать их можно даже на клиентской стороне — это поможет нам поддержать отправку сообщений при кратковременной недоступности БД, а вероятность коллизии крайне мала.
Черновая структура таблиц в нашей базе примет вот такой вид:
Таблицы : RU
CREATE TABLE "Тема"( "Тема" uuid PRIMARY KEY , "Документ" uuid , "Название" text ); CREATE TABLE "Сообщение"( "Сообщение" uuid PRIMARY KEY , "Тема" uuid , "Автор" uuid , "ДатаВремя" timestamp , "Текст" text ); CREATE TABLE "Адресат"( "Сообщение" uuid , "Персона" uuid , PRIMARY KEY("Сообщение", "Персона") ); CREATE TABLE "Файл"( "Файл" uuid PRIMARY KEY , "Сообщение" uuid , "BLOB" uuid , "Имя" text );
Таблицы : EN
CREATE TABLE theme( theme uuid PRIMARY KEY , document uuid , title text ); CREATE TABLE message( message uuid PRIMARY KEY , theme uuid , author uuid , dt timestamp , body text ); CREATE TABLE message_addressee( message uuid , person uuid , PRIMARY KEY(message, person) ); CREATE TABLE message_file( file uuid PRIMARY KEY , message uuid , content uuid , filename text );
Самое простое при описании формата — начинать «раскручивать» граф связей от таблиц, которые не ссылаются сами ни на кого.
Шаг 4: Выясняем неочевидные потребности
Все, мы спроектировали базу, в которую можно отлично писать и как-то читать.
Давайте поставим себя на место пользователя нашего сервиса — что мы захотим делать с его помощью?
- Последние сообщения
Это хронологически отсортированный по различным признакам реестр «моих» сообщений. Где я один из адресатов, где я автор, где мне написали, а я не ответил, где не ответили мне, ... - Участники переписки
Кто вообще участвует в этом длинном-длинном чате?
Наша структура позволяет решить обе эти задачи «вообще», но быстро — нет. Проблема в том, что для сортировки в рамках первой задачи невозможно создать индекс, подходящий для каждого из участников (и придется извлекать все записи), а для решения второй необходимо извлекать все-все сообщения по теме.
Непредусмотренные пользовательские задачи могут поставить жирный крест на производительности.
Шаг 5: Разумная денормализация
Обе наши проблемы помогут решить дополнительные таблицы, в которые мы будем дублировать часть данных, необходимых для формирования на них подходящих к нашим задачам индексов.
Таблицы : RU
CREATE TABLE "РеестрСообщений"( "Владелец" uuid , "ТипРеестра" smallint , "ДатаВремя" timestamp , "Сообщение" uuid , PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение") ); CREATE INDEX ON "РеестрСообщений"("Владелец", "ТипРеестра", "ДатаВремя" DESC); CREATE TABLE "УчастникТемы"( "Тема" uuid , "Персона" uuid , PRIMARY KEY("Тема", "Персона") );
Таблицы : EN
CREATE TABLE message_registry( owner uuid , registry smallint , dt timestamp , message uuid , PRIMARY KEY(owner, registry, message) ); CREATE INDEX ON message_registry(owner, registry, dt DESC); CREATE TABLE theme_participant( theme uuid , person uuid , PRIMARY KEY(theme, person) );
Здесь мы применили два типичных подхода, применяемых при создании вспомогательных таблиц:
- Умножение записей
Формируем по одной исходной записи сообщения сразу несколько записей-следствий в разные виды реестров для разных владельцев — как для отправителя, так и для получателя. Зато каждый из реестров теперь ложится на индекс — ведь в типовом случае мы захотим видеть только первую страницу. - Уникализация записей
При каждой отправке сообщения внутри конкретной темы достаточно проверить, существует ли уже такая запись. Если нет — добавляем ее в наш «словарь».
В следующей части статьи речь пойдет про внедрение секционирования в структуру нашей базы.

