Для coding-агентов проблема понимания существующего кода в реальных корпоративных репозиториях стоит очень остро. Приступая к каждой новой задаче, агенту нужно погрузиться в контекст: понять, что делает проект, как устроена его архитектура, где находится нужный код. Если проект не подготовлен заранее и агент вынужден разбираться самостоятельно, возникают фундаментальные ограничения:
Проблема контекстного окна
Проблема локального контекста - агент видит отдельные файлы, но может не понимать их роль в системе.
Проблема неявных зависимостей
Поэтому агенту нужен механизм, позволяющий быстро погружаться в контекст и находить именно нужный фрагмент кода среди сотен и тысяч файлов - и вот здесь появляются различные инструменты: семантический RAG по коду и докстрингам, графы зависимостей, якорная разметка, - или такой подход, как CodeWiki.
В этой статье я расскажу о том, как был создан CodeWiki Skill для Claude Code (и не только) - инструмент, который автоматически генерирует полноценную структурированную документацию, используя мультиагентный подход. По ходу статьи мы разберём три взаимосвязанные темы:
Что такое Skills - как они устроены изнутри и как они взаимодействуют с агентом. Затрону только самые интересные моменты, а про сами Skills уже достаточно много написано.
Что такое CodeWiki - проект, ставший основой для нашего скилла, и какую архитектурную проблему он решает.
Как работает CodeWiki Skill - практическая реализация на Claude Code с субагентами, скриптами и верификацией.
Часть 1. Skills для агентов
1. Что такое Skill?
Если смотреть сквозь призму того, как агент видит окружающий мир, Skill - это обычный инструмент (tool) с именем Skill, который передается модели.
Когда Claude Code запускается, он сканирует директории skills/, читает YAML-заголовки каждого SKILL.md и формирует описание инструмента Skill. Это описание - перечень всех доступных скиллов с их названиями и кратким описанием - попадает в параметр description:
{ "type": "function", "function": { "name": "Skill", "description": "<skill><name>\codewiki-orchestrator</name>\n<description>\nTransform codebase into comprehensive documentation using a multi-agent approach. Orchestrate analysis, architecture planning, and writing tasks." "<skill><name>\doc-coauthoring\n</name>\n<description>\nGuide users through a structured workflow for co-authoring documentation." ..... "required": ["skill"] } } }
Таким образом, Claude «видит» доступные скиллы через описание инструмента и самостоятельно решает, какой из них применить, основываясь на контексте разговора.
2. Как Skill попадает в контекст агента
Здесь начинается самое интересное. Когда Claude принимает решение использовать скилл, происходит следующее:
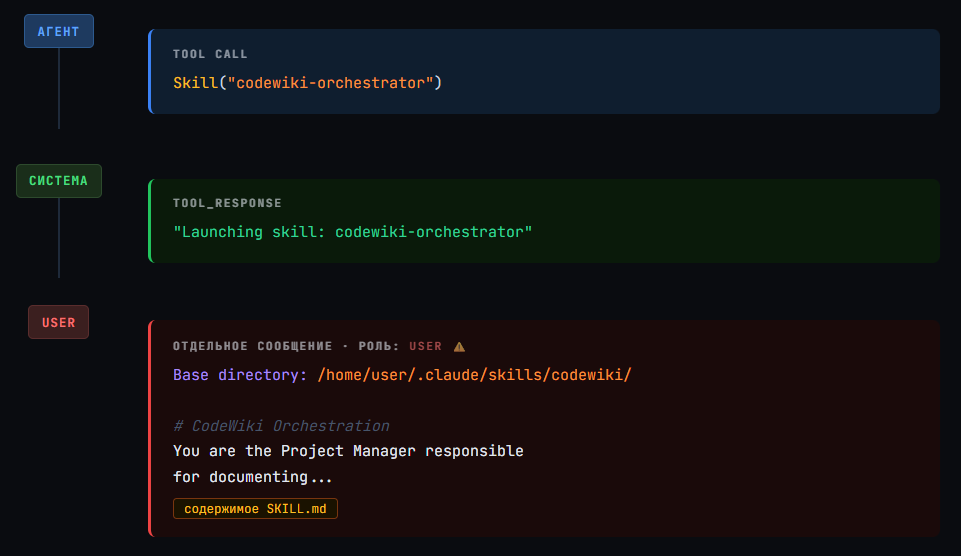
Обратите внимание: содержимое SKILL.md передаётся не как tool_response, а как отдельное сообщение в роли user. Это намеренное архитектурное решение - в обучающей выборке моделей гораздо больше примеров, где пользователи дают инструкции, нежели где инструменты возвращают инструкции. Поэтому такой формат более надёжно «активирует» нужное поведение модели.
Вместе с содержимым скилла агент получает полный путь к директории скилла. Это критически важно: агент может продолжить читать другие файлы из той же директории - промпты, скрипты, справочные материалы.
3. Принцип постепенного раскрытия информации
Это одна из ключевых концепций при проектировании скиллов. Идея проста: давать агенту ровно столько информации, сколько ему нужно на каждом шаге. Здесь останавливаться я не стану, т.к. эта концепция не только про Skills, а вообще про правильный архитектурный подход подачи информации в AI агентов.
4. Скрипты внутри скилла: тяжёлая аналитическая работа
Markdown-файлы с инструкциями - это мощно, но настоящая сила скиллов проявляется в сочетании с исполняемыми скриптами. Директория scripts/ может содержать Python, Bash или любые другие скрипты, которые агент запускает через инструмент Bash.
Это позволяет вынести из контекста агента всю «тяжелую» работу: парсинг файлов, построение графов зависимостей, валидацию, генерацию HTML. Агент становится оркестратором, а не исполнителем низкоуровневых задач.
Но здесь есть важный нюанс, о котором часто забывают: часто скрипты нуждаются в зависимостях. И если не описать агенту явно, как эти зависимости устанавливать, он потратит 3-4 итерации на отладку, пытаясь угадать правильный способ. Здесь бы конечно от Аnthropic получить большей стандартизации.
Для себя же я выбрал подход - использовать uv (современный быстрый менеджер пакетов Python) и прямо в SKILL.md описать правила работы с окружением:
## 🐍 Python Environment Rules (CRITICAL) **CRITICAL:** This project uses UV for all Python operations to ensure isolation. 1. **NEVER** use `python -m`, `pip install`, or `python script.py` directly. 2. **ALWAYS** work from the skill directory and use: - `uv pip install -r requirements.txt` for setup - `uv run python scripts/...` for script execution
И создать соответствующий requirements.txt в директории скилла:
tree-sitter>=0.23.0 tree-sitter-languages>=1.10.0 pydantic>=2.0.0 jinja2
Итоги первой части
Skills - это не просто подсказки для агента. Это полноценная плагинная архитектура с мощными концепциями, и я попробую раскрыть их в полной мере.
Теперь переходим к следующей части - CodeWiki.
Часть 2. CodeWiki: фреймворк для иерархической генерации документации
1. Что такое CodeWiki
CodeWiki - это фреймворк с открытым исходным кодом для автоматизированного документирования на уровне репозитория. Он генерирует целостную документацию, которая описывает не только отдельные функции, но и их взаимодействие на уровне файлов, модулей и системы.
Поддерживаемые языки
CodeWiki поддерживает 7 языков программирования: Python, Java, JavaScript, TypeScript, C, C++ и C#.
2. Архитектура CodeWiki
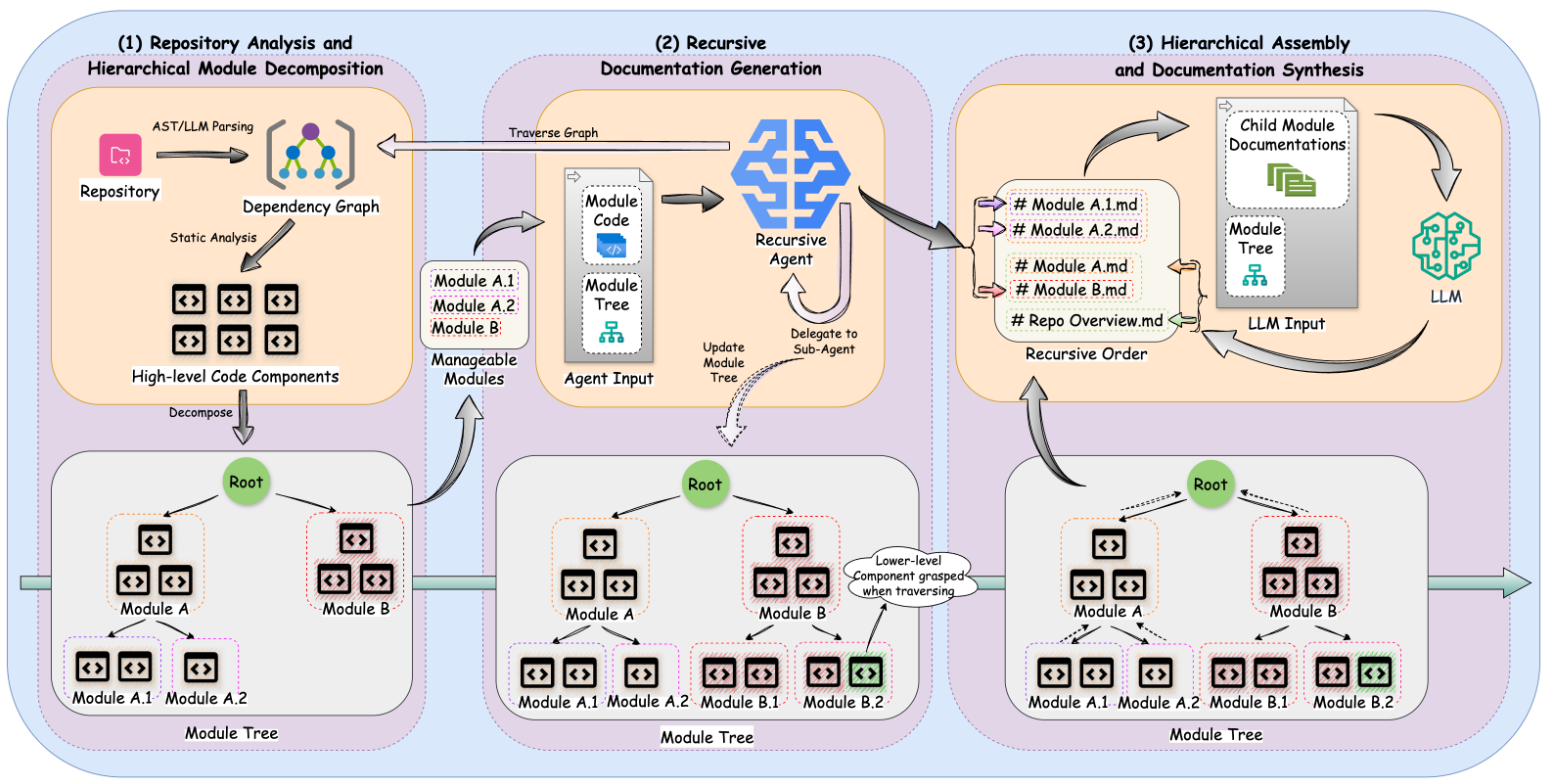
Ключевая идея CodeWiki - иерархическая декомпозиция, вдохновлённая принципами динамического программирования. Вместо того чтобы пытаться обработать весь репозиторий сразу (что невозможно из-за ограничений контекста), система разбивает его на управляемые модули и обрабатывает их снизу вверх.
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ │ 1. Валидация │───>│ 2. Анализ │───>│ 3. Кластери- │ │ & Инит │ │ зависимостей │ │ зация │ └──────────────────┘ └──────────────────┘ └──────────────────┘ CLI + конфиг LLM Tree-Sitter AST LLM → module_tree.json Граф + DAG │ ┌───────────────────────────────────┘ v ┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ │ 4. Оркестрация │───>│ 5. Агенты │───>│ 6. Сборка │ │ (Bottom-Up) │ │ (pydantic-ai) │ │ Overview │ └──────────────────┘ └──────────────────┘ └──────────────────┘ Leaf → Parent Родитель читает Листья → Корень Tools + субагенты доки детей, не код → module.md │ v ┌──────────────────┐ │ 7. HTML Output │ └──────────────────┘ index.html + Mermaid
Этап 1: Анализ зависимостей
Прежде чем писать текст, CodeWiki должен понять структуру кода.
Парсинг: Используется библиотека
tree-sitterдля построения абстрактного синтаксического дерева (AST) каждого файла. Это позволяет точно определить классы, функции и вызовы, игнорируя форматирование.Построение графа: Строится ориентированный граф вызовов. Узлы — это функции/классы, ребра — вызовы или наследование.
Топологическая сортировка: Алгоритм находит циклические зависимости и разрывает их, превращая граф в DAG . Это критично для определения порядка обработки.
Этап 2: Логическая кластеризация
Файловая структура не всегда отражает бизнес-логику.
Система выделяет листовые узлы (компоненты, которые ни от кого не зависят).
LLM-Кластеризация: Специальный промпт отправляется в LLM с просьбой сгруппировать разрозненные файлы в логические модул.
Результат сохраняется в
module_tree.json- карта будущей документации.
Этап 3: Рекурсивная генерация документации
Это сердце фреймворка. Используется подход снизу-вверх:
Листовые модули (Leaf Modules):
Создается AI-агент (используется фреймворк
Pydantic AI). Ему передается исходный код модуля.Агент пишет подробную документацию и генерирует диаграммы (Mermaid).
Особенность: Агент видит только код своего модуля, что гарантирует точность и не перегружает контекст.
Родительские модули (Parent Modules):
Когда все "дети" задокументированы, запускается Агент для родительского модуля.
Ключевая фишка: Этот агент не читает исходный код детей заново. Вместо этого он читает уже сгенерированную документацию детей.
Это позволяет системе обрабатывать репозитории любого размера, так как на верхних уровнях мы работаем с абстракциями (документацией), а не с миллионами строк кода.
Этап 4: Мультимодальный синтез
В финале CodeWiki собирает все артефакты воедино:
Генерируется
overview.md- высокоуровневое описание архитектуры всего проекта.Создается статический HTML-сайт (опционально, флаг
--github-pages), где встроен JS-рендер для диаграмм Mermaid.Проставляются перекрестные ссылки, чтобы пользователь мог путешествовать по документации как по Википедии.
Итоги второй части
CodeWiki оказался гибким инструментом, который позволяет обрабатывать огромные репозитории и создавать документацию.
Давайте перейдем к самой интересной части, - попытке объединения таких концепций как Skills + Coding Agent и проекта CodeWiki
Часть 3. Реализация CodeWiki Skill: шесть фаз глазами Claude Code
Чтобы понять, как работает CodeWiki Skill, нужно смотреть на него как на мультиагентный процесс.
Главный агент - оркестратор - никогда не читает исходный код репозитория сам. Он управляет: запускает инструменты, создаёт субагентов, контролирует выполнение, проверяет результаты. Всю тяжёлую работу делают либо Python-скрипты, либо субагенты.
Вот полная структура директории скилла:
codewiki-skill/ ├── SKILL.md # Главный файл — инструкции оркестратора ├── requirements.txt # Зависимости для Python-скриптов ├── prompts/ │ ├── component.md # Промпт для документирования компонентов (leaf) │ ├── module.md # Промпт для документирования модулей (container) │ ├── structuring-modules.md # Промпт для субагента-кластеризатора │ └── system.md # Промпт для генерации overview.md ├── scripts/ │ ├── analyze_dependencies.py # Фаза 1: AST-парсинг и построение графа │ ├── generate_tasks.py # Фаза 3: Генерация файлов-заданий │ ├── fetch_context.py # Фаза 4: Извлечение контекста для субагентов │ ├── verify_completion.py # Фаза 5: Верификация полноты документации │ └── build_static_site.py # Фаза 6: Сборка статического сайта ├── src/ │ └── dependency_analyzer/ # Ядро из CodeWiki: анализаторы для 7 языков └── templates/ └── github_pages/ └── viewer_template.html # Шаблон SPA-сайта
В SKILL.md находится полное описание всего workflow оркестратора: какие фазы выполнять, в каком порядке, что делать ��амому, а что делегировать субагентам, какие команды запускать на каждом шаге. Давайте пройдемся по этому workflow.
Фаза 0: Подгтовка окружения
Оркестратор устанавливает зависимости для Python-скриптов, которые ему понадобятся дальше.
uv venv && uv pip install -r requirements.txt
Фаза 1: Скриптовый анализ репозитория
Оркестратор запускает скрипт analyze_dependencies.py. Этот скрипт запускает построитель графа зависимостей и сохраняет два ключевых артефакта:
graph_raw.json- полная база знаний. Содержит для каждого компонента: имя, тип (class/function/method), путь к файлу, полный исходный код, список зависимостей.structure_summary.json- облегчённая версия без source code, которую будем передавать для кластеризации .
uv run python scripts/analyze_dependencies.py \\ --repo-path ../.. \\ --output-dir ../../codewiki
Фаза 2: Кластеризация
Дальше начинается иерархическая декомпозиция кода. Оркестратор делегирует эту задачу субагенту.
Субагент получает промпт из prompts/structuring-modules.md, который задаёт роль «Системного архитектора - специалиста по кластеризации». Его задача - трансформировать плоский список файлов в семантическую иерархию модулей.
Ключевой момент: субагент архитектор должен группировать файлы по функциональному смыслу, а не только по физическому расположению в папках.
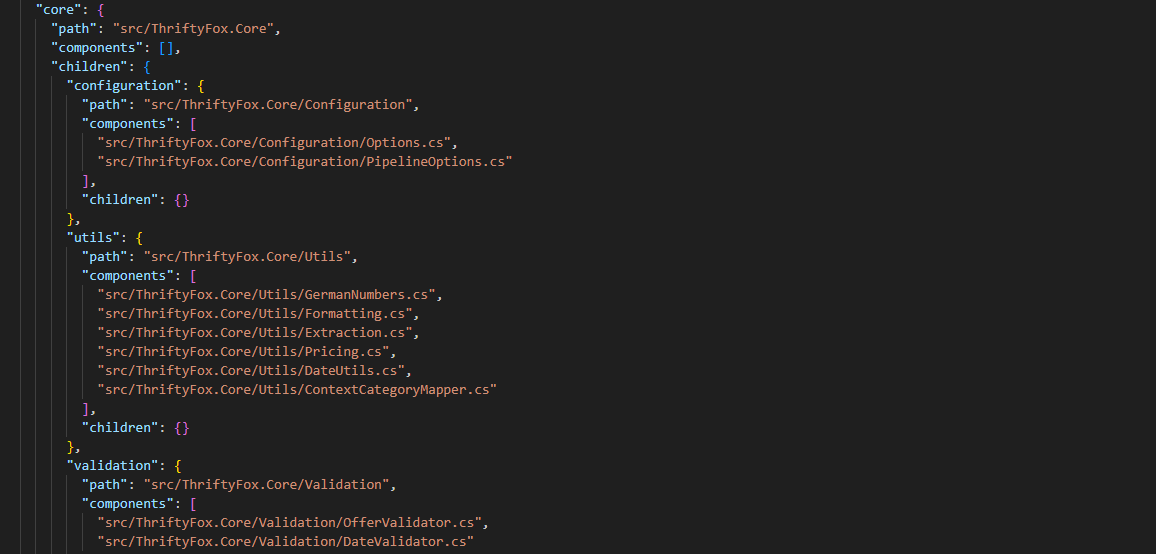
На выходе получаем файлmodule_tree.json - иерархический JSON с двумя типами узлов. Leaf-узлы (листья) привязаны к конкретным компонентам кода и будут задокументированы по исходному тексту. Container-узлы не содержат компонентов напрямую - они объединяют дочерние модули и будут задокументированы на основе их уже готовой документации. Эта иерархия - основа bottom-up стратегии выполнения всего скилла.
Фаза 3: Генерация задач
Когда module_tree.json готов, оркестратор мог бы просто обойти его и начать раздавать задания субагентам напрямую. Но вместо этого он запускает скрипт generate_tasks.py, который создаёт отдельные таски для описания каждого компонента/модуля/системы:
codewiki/tasks/ ├── 0001_task_chunking.md ├── 0002_task_embeddings.md ├── 0003_task_extractors.md ├── 0004_task_retrieval.md ├── ... └── 9999_task_repository_overview.md
Каждый task-файл содержит:
тип задач -
COMPONENT,MODULE,OVERVIEWсписком компонентов или дочерних модулей,
и самым важным: встроенным
INSTRUCTION_TEMPLATE(промпт - как именно описывать компонент/модуль/систему).
Зачем это нужно? Причин несколько, и каждая из них отражает реальную проблему в агентных системах.
Детерминированный порядок выполнения. Скрипт обходит дерево модулей снизу вверх и нумерует задачи последовательно. Листья (комонент) получают меньшие номера, контейнеры(модуль) бо́льшие. Оркестратор просто сортирует файлы по имени и отдает субагентам в этом порядке - никакого сложного управления зависимостями.
Самодостаточность задания. Каждый файл задания содержит не только список компонентов, но и встроенный промпт (INSTRUCTION_TEMPLATE). Субагент-писатель не обращается к директории prompts/ сам - вся инструкция уже внутри его задания. Это исключает целый класс ошибок: «субагент прочитал не тот промпт» или «субагент начал примерять роль оркестратора».
Контрольная точка для верификации. После выполнения всех задач скрипт верификации знает точный список ожидаемых файлов. Он сравнивает файлы задач с файлами документации - и сразу видит, что пропущено.
Восстановление после сбоя. Если какой-то субагент завис или завершился с ошибкой, оркестратор не перезапускает всё с нуля, он запустит субагента только для пропущенных модулей.
Фаза 4: Генерация описаний (Execution Loop)
Это самый масштабный этап. Оркестратор берет файлы задач батчами по 3 штуки (количество батча регулируется через промт) и каждое задание передает отдельному Writer-субагенту, ждет завершения батча, потом берет следующий.
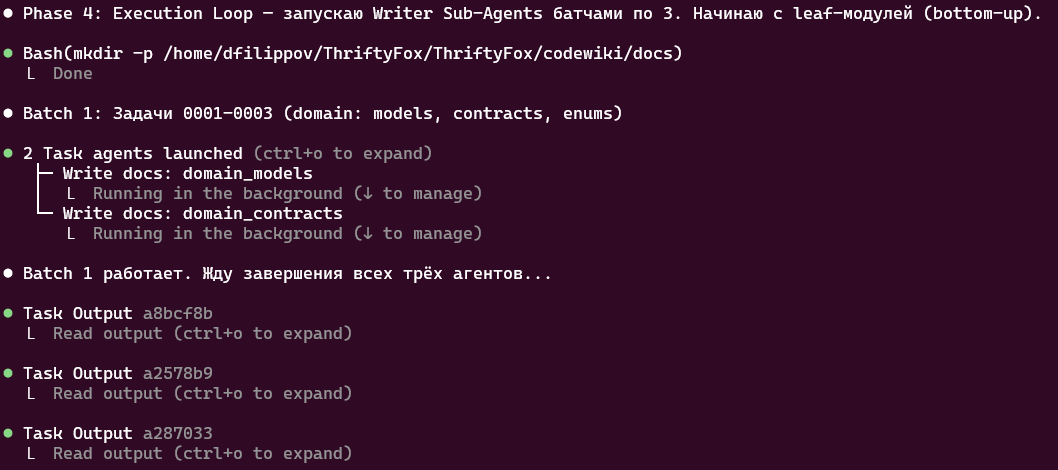
Каждый Writer-субагент выполняет четкий алгоритм:
Шаг 1: Получить задание. Прочитать файл задачи (например, 0001_task_auth_core.md)
Шаг 2: Собрать контекст. Запустить скрипт fetch_context.py, который извлекает из graph_raw.json исходный код и зависимости только нужных файлов.
Шаг 3: Написать документ. Используя полученную инструкцию и контекст, Writer-субагент создает Markdown-файл.
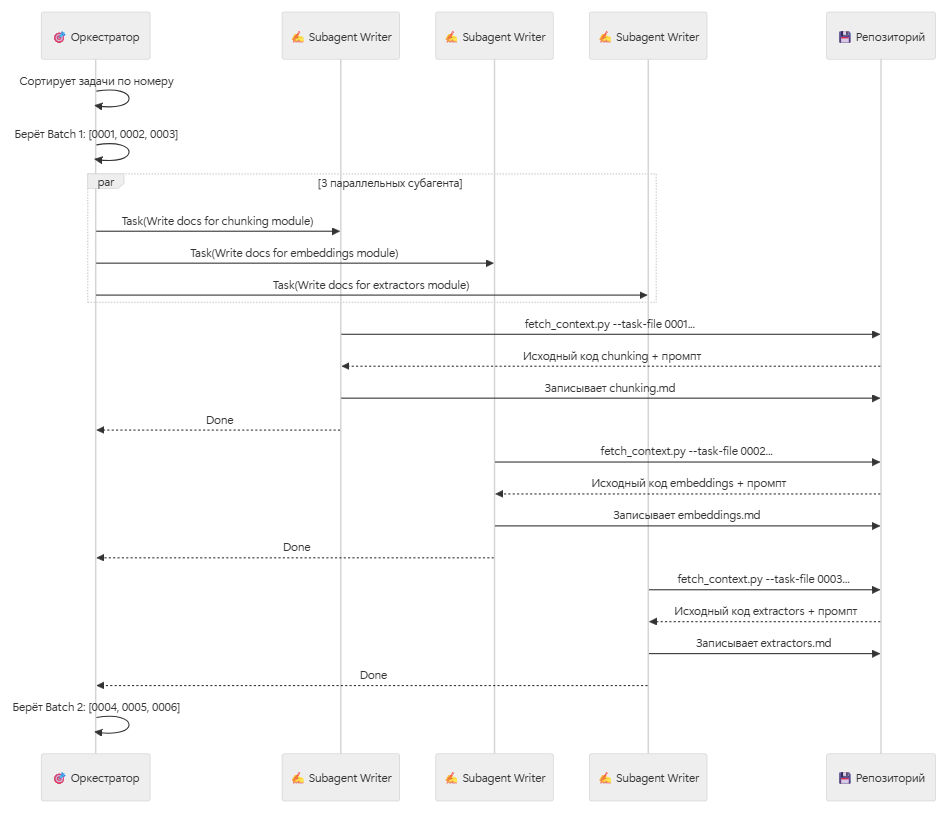
Задачи пронумерованы в порядке bottom-up обхода дерева: сначала листья, потом контейнеры, и последним - overview. Это гарантирует, что к моменту генерации контейнерного модуля вся документация его дочерних модулей уже готова.
Фаза 5: Верификация - оркестратор проверяет результат
Дальше в пайплайне идет контроль качества по факту оркестратор запускает скрипт verify_completion.py , которые сверяет module_tree.json и созданные .md файлы в docs/. Если чего-то не хватает - возвращает ошибку и список пропусков, после чего оркестратор принимает решение довыполнить недостающие модули и продолжить.
Это важный практический момент: агентный пайплайн без верификации превращается в "надеюсь, всё сгенерировалось". Здесь же пайплайн ведёт себя как сборка: либо зеленый, либо говорим, что именно не собрано.
Фаза 6: Сборка статического сайта
Когда все модули задокументированы, оркестратор запускает последний скрипт build_static_site.py .
Скрипт собирает все Markdown-файлы, строит навигационное дерево из module_tree.jsonи генерирует единый index.html.

В итоге получается локальная wiki с сайдбаром по модулю и страницами. Результат можно открыть локально или опубликовать на GitHub Pages без каких-либо дополнительных настроек.
Часть 4. Структура получаемой документации: граф система–модули–компоненты
Ключевой результат работы CodeWiki Skill - это документация в папке codewiki/docs и это не просто набор Markdown-файлов, а связный граф, где каждый узел - это страница документации, а каждое ребро - это ссылка.
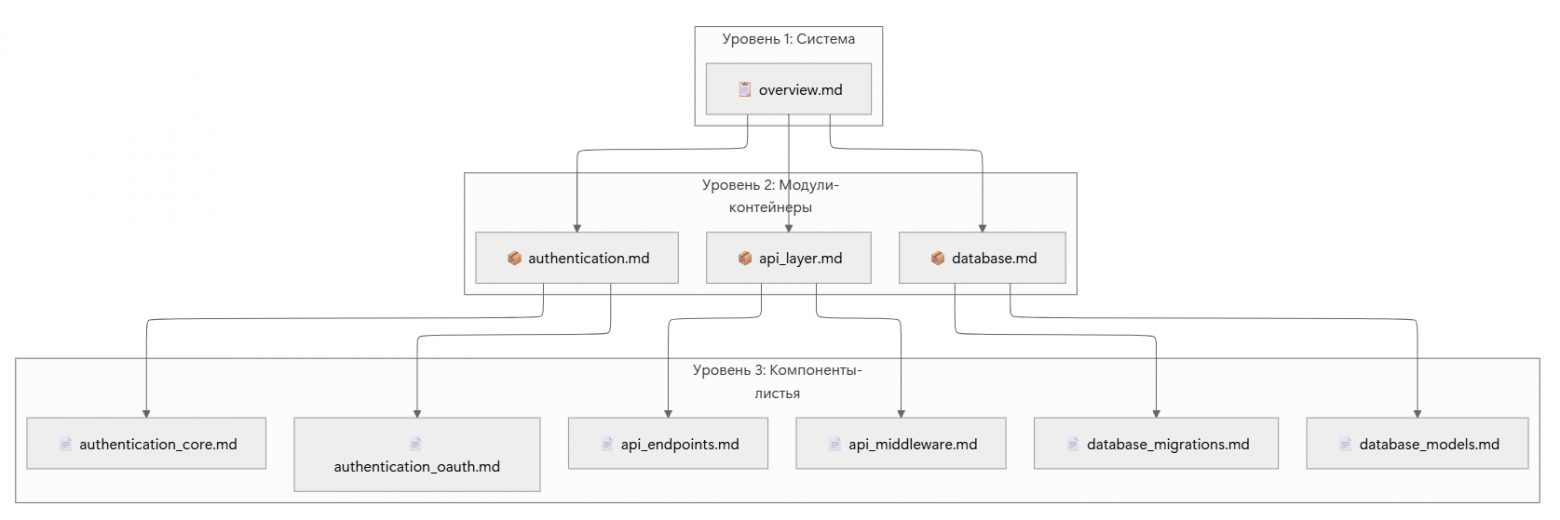
Этот граф имеет три уровня с чёткой иерархией: Overview (система), Module (модуль), Component (компонент). Именно эта трёхуровневая структура делает документацию максимально полезной для Coding-агентов, т.к. агент может использовать ее по принципу постепенного раскрытия информации.
Часть 5. Установка и перспективы
Исходный код CodeWiki Skill доступен в моем репозитории и устанавливается как обычный skill (достаточно скопировать в директорию .claude/skills/ ).
Запустить скилл можно просто попросив агента использовать codewiki-orchestrator для описания вашего репозитория.
⚠️ Будьте внимательны, для генерации документации в больших проектах - дневные лимиты токенов будут расходываться очень быстро.
Текущая реализация показывает сильные результаты, однако есть еще огромное количество направлений для развития скилла, которые планирую взять в работу:
Стабилизация workflow - есть фазы, на которых оркестратор идет в ненужные перепроверки работы субагентов и начинает читать файлы. А так же иногда субагенты создают файлы с неправильными именами, что критично для скриптов.
Улучшение промтов (папка prompts/) - для генераций описаний компонентов/модулей/системы.
Инкрементальная генерация - сейчас каждый запуск пересоздает всю документацию. Добавление кэширования и инкрементального обновления измененных узлов позволит использовать CodeWiki Skill на постоянной основе и включить его в основные workflow разработки, для поддержки документации в актульаном состоянии.
Пишите в комментариях, какие инстурменты используете для улучшения навигации агентов по коду?
И не забывайте заглядывать в мой Telegram канал.

