
Хабр Курсы для менеджеров
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Листал, увидел фразу "Судья заключил" в абзаце про гигачат, понял, что генеренка.
Жаль(
Ну и да, часто от модели хочется рассуждений.
А от ее автора - фиксированной небольшой, суммы за месячную подписку и общаний не юзать данные для обучения. А тут с этим....
Мечты, мечты.. Где Ваша сладость? )
Собирать данные это основная задача всего ПО интернета от браузера до ИИ и даже автоперекладчика шрифта рус/лат. Как эт-та "не юзать"? )))
Судья заключил, да. Хотите перепишу? Сути это не меняет
Но ИИ использовался в статье – генерация картинки. Ревью тоже было сделано с ИИ
Ну и sidecomment. Проблема сегодня, что люди как только видят признаки "ИИ сгенерированный текст", в местах где его нет, добавляют ярлык "ИИ/AI slop" и перестают смотреть на суть.
Есть исследования, которые говорят, что ИИ тексты снижают доверие к информации / автору примерно на 40%. Но основная причина снижения такого доверия – "отсутствие вклада или труда". То есть доверие возникает, когда люди видят, что автор потратил свое время. Если не видят этого – следом присваивают соответствующий ярлык.
Но при этом, статья, как правило, это лишь меньшая часть вложения трудов.
Gemini 2.5
Давно уже 3.1. Слоп?
Кими, без впн в России и без русского.
И работает из России без VPN
Увы не работает
Что именно? Выше написали, что Кими недоступен, что мы могли пропустить
Открыл, работает. Возможно, вы хотите сказать, что нельзя оплатить? @caesium-137
GigaChat-2-Pro – 2,82, худший результат среди всех 54 моделей.
У вас в таблице он на 52 месте, а на 54 у вас Phi-4.
разница между Kimi (4,75) и GigaChat (3,75) на том же сценарии с бюджетом – это не только разница моделей. Это разница в подходе.
Это разница в 2 года. Сам Сбер в недавнем анонсе ультры писал, что она на уровне GPT-4o.
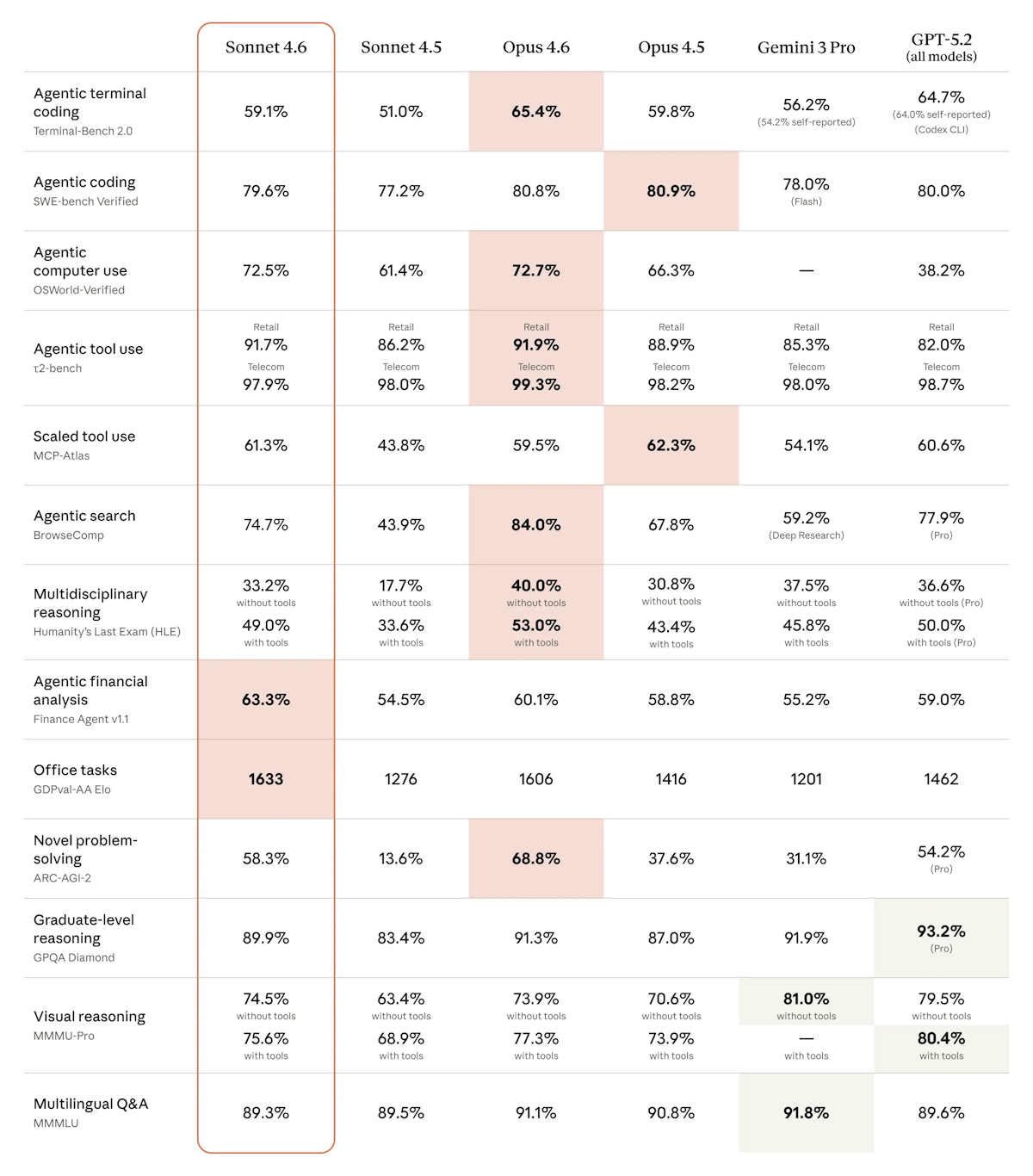
Claude Sonnet 4.5 4.78
Claude Opus 4.5 4.78
Claude Sonnet 4.6 4.77
У меня складывается впечатление, что тут одно из двух:
1.) Ваш бенчмарк и/или судья не в состоянии различить передовые модели (или потому что очень просто и все справляются, или потому что судья не может сам понять, где лучше/хуже) и там все едино.
2.) Доверительный интервал намного больше, чем два знака после запятой, поэтому вы фиксируете шум, а не актуальные значения (у вас топ 7 моделей ложатся в 1 десятую).
Иначе мне сложно объяснить почему Opus 4.5 и Sonnet 4.5 показывает одинаковые результаты, хотя очевидно и по всем остальным бенчмаркам, что Opus, разумеется, показывает лучшие результаты, чем Sonnet. Аналогично с тем, что Sonnet 4.6 хуже, чем Sonnet 4.5 - тут
Тут задачи всё-таки весьма специфические, так что вполне может быть
Здесь все в рамках погрешности, вы правы. Можно считать качество одним и тем же
Бенчмарк не знает ничего про модели, передовые или нет. Оценивается результат ответа на вопрос, его глубина, содержание, точность цифр, актуальность информации, эффективность (стоимость). В результате, может оказаться что передовая модель, которая стоит дороже (Opus) имеет меньшее количество баллов в рейтинге. Но это в рамках погрешности, как вы правильно заметили.
Относительно интерпретации, то в этой редакции статьи мы убрали разделение на Эшелоны / Кластеры / Tier. Но изначально предполагалось, что все выше 4.50 – это все премиальное качество и нет смысла смотреть на места. И если смотреть так, GLM-5 и выше – одного качества. Для конечного потребителя особой разницы нет, не видно.
Здесь все в рамках погрешности, вы правы. Можно считать качество одним и тем же
Но у вас на сайте пишется другое:
анализ и планирование – Claude Sonnet 4.5, обучение и управление командой – Claude Sonnet 4.6
Ну очевидно же, что смысла использовать Sonnet 4.5 при доступном 4.6 нет ровно никакого. Ценник одинаковый, по вашему заявлению выше "они одинаковые", по индустриально стандартным бенчмаркам 4.6 лучше, чем 4.5, по АБСОЛЮТНО ВСЕМ категориям (где-то больше, где-то меньше).
Но изначально предполагалось, что все выше 4.50 – это все премиальное качество и нет смысла смотреть на места. И если смотреть так, GLM-5 и выше – одного качества. Для конечного потребителя особой разницы нет, не видно.
Я очень не согласен с этим утверждением. Говорю как ежедневный пользователь Claude/ChatGPT/Gemini + Nemotron3. И речь не только и не столько про код, а больше про то, что у вас называется "управленческие задачи".
Для меня, вот разница есть и ее видно (например, на большом контексте). Ровно как и Opus vs Sonnet. И я не такой один "In Claude Code, our early testing found that users preferred Sonnet 4.6 over Sonnet 4.5 roughly 70% of the time."
Более того, хоть я и люблю Nemotron 3 Super (120B-A12B) за скорость, очень очевидно, что это модель среднего размера и до того же GLM-5 (744B-A40B) ей далеко. Что хорошо видно у того же Artificial Analysis, где у Nemotron 3 Super Intelligence Index - 35, а у GLM-5 - 50.
Тут вопрос в том, что ваш бенчмарк не может эту разницу различить - например, аналогично MMMLU там у всех Tier1 ~90%, а маленьких (типа Nemotron 3 Nano 30B-A3B) - 80%. Это не показатель модели. А показатель теста/бенчмарка, который не видит разницы.
что все выше 4.50
А почему 4.5? На примере Nemotron 3 Super и GLM это тоже не очевидно. Почему не 4.0? Или любое другое число?
Короче, я к тому, что судя по результатам (там много такого, но просто пример с Claude самый наглядный), ваш бенчмарк имеет low statistical power & discrimination index, как минимум, для Tier-1 моделей, но несмотря на это, вы формулируете выводы из серии "Китайские модели уже догнали по качеству западные аналоги", "В России без ограничений доступны модели уровня Claude. Лучшая доступная модель – Kimi K2.5 (4.74), всего на 0.06 балла ниже глобального лидера GPT-5.4 (4.80)." и т.д. Эти заявления не могут быть сделаны на базе ваших бенчмарков. Я вот открываю ARC-AGI-v2 и там разница есть.
Более того, после того, как становится очевидным, что он не может различать топовые модели, то не понятно, а с какого момента он начинает это делать и почему именно с этого?
Спасибо за развёрнутый комментарий – по существу вы правы, и я это признаю.
По статистической мощности. В основе исследования – 4 сценария на категорию на модель, двое LLM-судей (Claude Opus 4.5 + Gemini 3 Pro). Мы сами считали post-hoc тесты (сейчас перепроверили эти цифры): Tukey HSD даёт p-adj = 1.0000 для всех попарных сравнений в топ-15. Minimum Detectable Difference (MDD) при количестве сценариев в рамках одной модели 4 – 1.255 балла. То есть бенчмарк статистически не может различить модели внутри верхней группы. Мы это знали и прописали в методологии equivalence bands: разница < 0,10 – «идентичны», 0,10–0,30 – «в рамках шума». Но в статье эти оговорки потерялись, а утверждения вроде «отстаёт на 0,06» остались. Это ошибка подачи – выводы вышли за рамки того, что данные позволяют утверждать.
По Claude 4.5 vs 4.6. В наших данных по категориям: анализ – 4.83 vs 4.71, команда – 4.70 vs 4.84. Это внутри нашего же значения "шума". Рекомендовать 4.5 при доступном 4.6 по той же цене – действительно не имеет смысла. Поправим.
По порогу 4.50. Согласен – он не обоснован статистически. В ANOVA все 54 модели попали в один статистический tier. Граница произвольная.
Что бенчмарк может, а что – нет. Он хорошо разделяет уровни: GigaChat (2.82) vs Kimi (4.74) – разница 1.92, это выше MDD, Cohen’s d > 0.8. Российские модели объективно отстают от глобального топа – это подтверждается. Но ранжировать внутри топ-15–20 он не может.
Заявления "китайские модели догнали западные" на основе разницы в 0.06 – некорректны. Корректно сказать "топ-15 моделей статистически неразличимы на нашем наборе задач".
Пример с Nemotron 3 Super vs GLM-5 – точный. У нас Cohen’s d между ними 0.006. Бенчмарк этого не видит – и это его ограничение, а не свойство моделей.
Что будем менять. Уберём рекомендацию 4.5 vs 4.6. Переформулируем топ как кластер («эти N моделей статистически неразличимы»), а не ранжированный список. Добавим equivalence bands на страницу результатов – они есть в методологии, но не дошли до публичной версии.
z.ai с с GLM-5 вроде тоже без VPN работает у меня из России
Спасибо за труд, статейку добавил в закладки
не защищаю наши модели, но красивая упаковка по типу «с этим можно идти на совещание» ничего не говорит о качестве контента. Откладывание рекламного бюджета до появления результатов, возможно, самый ценный совет из всех прогонов.
А «тут мы получили неплохо структурированный текст, а тут он ещё лучше структурирован!!!» это не качество смысла. Даже то, что цифры сбиты не качество. Самые дорогие ошибки выглядят наиболее гармонично.
Мы проводили слепое тестирование моделей, чтобы сделать калибровку, с участием людей. Можно посмотреть ответы тут (ну и дать вашу оценку, к этим постам – это улучшить нашу калиброку)
https://mysummit.school/evaluate
В целом же, вы действительно правы, что ИИ может написать хорошо структурированный текст, но пустой по сути. У нас есть все ответы моделей, их можно выложить для примера, но их все равно никто читать не будет, поэтому лежат в архиве.
В нашем же случае, были эталонные ответы к моделям (что мы ждали увидеть в ответ), и с этими эталонами сравнивали ответы. Поэтому оценка "можно идти на совещание", основана именно на сравнении с эталоном
По сути о бесплатности можно говорить, только если подразумевается чатик, который не особо то и нужен. Если же работать нормально, через API, то из бесплатных (да и то с оговорками на собственное приложение и ограниченное количество запросов) остаются только z.ai и qwen.
{kind=link}
Kimi K2.5 наступает на пятки GPT-5.4. И работает из России без VPN