Идея использовать git для хранения всех своих фотографий.
Как оказалось, GIT с большим трудом справляется с этой задачей.
Если нужны только директивы смотрите в последний параграф.
Я обнаружил, что на клиенте приходится отключать архивирование чтобы побыстрее проходили команды add и commit. А на сервере, кроме отключения архивирования нужно еще ограничить использование памяти, и скорректировать политику упаковки/распаковки объектов.
Клонировать по ssh довольно медленно и требует много ресурсов на сервере. Поэтому для таких репозиториев лучше использовать «тупой» http протокол. Кроме того, нужно обновить git до последней версии, т.к. у 1.7.1 проблемы с нехваткой памяти.
Есть еще возможность прописать
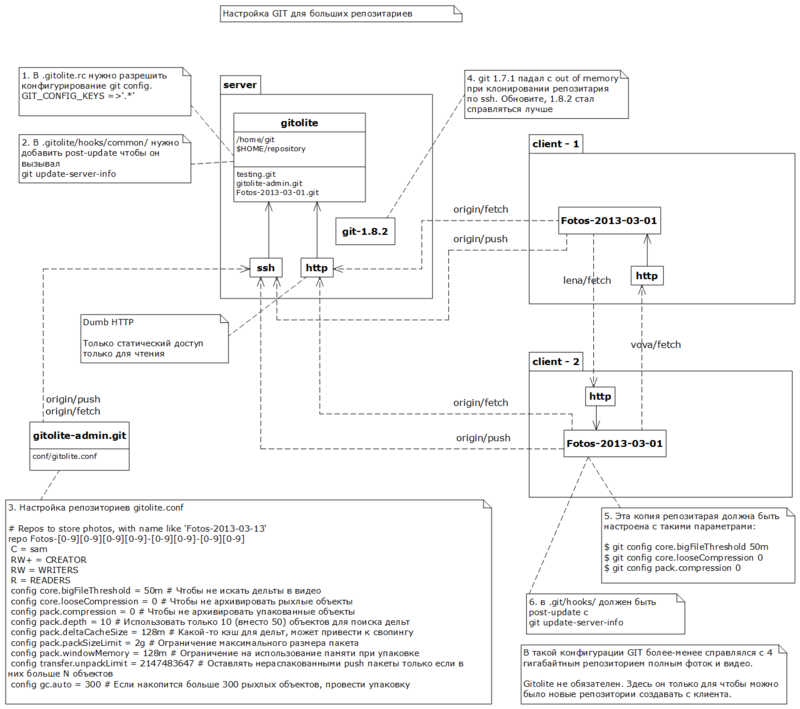
Для работы на сервере я выбрал gitolite. Это обертка для git, для управления репозиториями. По большому счету только из-за wild repo — репозиториев создающихся по требованию. Но также пригодилась его способность прописывать настройки в репозитории.
На сервере
Все расписано в книге, в главе 4.8.
Настройка gitolite производится на клиенте. Клонируем gitolite-admin, вносим измения, commit, push. Настроим wild репозитории — добавим в файл
После клонирования пустого репозитория в первый комит был добавлен файл
Во второй комит добавлена папка с 367 файлами, объемом 3.7 гигабайт.
293 фотографии в jpg — 439 мегабайт
37 видеороликов в avi — 3.26 гигабайт
37 THM файлов — 0.3 мегабайт
9 минут push занимался локальными вычислениями, затем 14 минут пересылкой.
Идея, подкрутить git, чтобы он не пытался сжимать видео и фото. Как выключить по типу файлов я не обнаружил, пришлось полностью отключить сжатие.
Клонируем пустой репозиторий и настраиваем его.
На клиенте
Эти команды сохраняют настройки локально (для текущего репозитория, т.е. в файле .git/config)
На клиенте
После выполнения команды push на сервере репозиторий не содержал никаких дополнительных настроек (так и должно быть). Локальный репозиторий остался в рыхлом состоянии, а на сервере оказался упакован. Но при этом размер пакета оказался 3.7 гигабайт. На сервере не было настроек pack.packsizelimit=2g (но и они бы не спасли).
После клонирования репозиторий оказался запакован, и пакет был размером 3.7 гигабайт, несмотря на локальные установки в 2 гигабайта
На клиенте
Предположение, что сервер не справляется (задыхается на свопе) из-за отсутствия ограничений на размер пакета, слишком большого bigFileThreshold и отсутствия ограничений на использование памяти для поиска дельт.
Я предпринял попытку перепаковать репозиторий на сервере. Установил на сервере
И запустил, опять на сервере
После этого были созданы пакеты размером до 2 гигабайт, но огромный пакет не был удален. Попытка провести сборку мусора падала от нехватки памяти, или задыхалась на свопе. В общем я удалил системную настройку, и решил прописывать в каждый репозиторий.
В новых репозиториях для фоток мы пропишем
Все это мы будем прописывать в каждый репозиторий для фоток. Для этого сконфигурируем gitolite.
Перед тем, как добавлять конфиги нужно на сервере, в файле
А вот как будет выглядеть конфиг gitolite.
Если не указывать большой
Клонируем новый пустой репозиторий и проверяем, чтобы на сервере в нем были прописаны необходимые настройки.
Клиент
Сервер
Клиентская копия репозитория настроена по-умолчанию. Поэтому перед тем как добавлять 3.7 гигабайта фоток нужно снова настроить
Клиент
И на клиенте и на сервере остались рыхлые репозитории.
Попытки клонировать новый репозиторий по ssh провалились. На серверной стороне git 1.7.1 падал с Out Of Memory.
После обновления гит перестал падать по out of memory. Но в начале клонирования выбрал всю память — 1 гигабайт, после начала пересылки сократил до 250 мегабайт.
Собственно клонирование заняло 48 минут. И на клиенте репозиторий содержал один пак размером 3.7 гигабайт.
Идея в том, чтобы на сервере отказаться от выполнения какой-либо работы при скачивании репозитория.
К счастью git умеет делать fetch через http. Все что для этого нужно выполнить
Мы возьмем пример, и настроим gitolite прописывать этот хук всем репозиториям.
На сервере
Теперь, после следующего обновления репозиторий станет доступен для http.
Чтобы не зарываться в подробности настройки http, я воспользуюсь «игрушечным» веб сервером. Создам папку
На сервере
На клиенте
Время выполнения 4 минуты! 3.7 Гигабайт за 4 минуты! Это нам подходит.
Для обслуживания больших репозиториев Git-ом необходимо Clone и Fetch выполнять по http. Прописать кучу настроек и желательно обновить гит.
Серверный репозиторий
Клиентский репозиторий
Спасибо, что сподвигли меня разобраться в этом вопросе.
Чего хотелось добиться?
- Скидывать фотки одной кучей (DCIM), а когда будет время сортировать по папкам.
- Скинуть фотки с одного компа, а работать с ними с другого.
- Чтобы перемещение-переименование фоток и папок волшебным образом синхронизировалось на всех компьютерах.
- Чтобы можно было редактировать фотки, но иметь возможность восстановить оригинал.
- Чтобы сохранялась история правок.
Как оказалось, GIT с большим трудом справляется с этой задачей.
Получившаяся конфигурация, кратко
Если нужны только директивы смотрите в последний параграф.
Я обнаружил, что на клиенте приходится отключать архивирование чтобы побыстрее проходили команды add и commit. А на сервере, кроме отключения архивирования нужно еще ограничить использование памяти, и скорректировать политику упаковки/распаковки объектов.
Клонировать по ssh довольно медленно и требует много ресурсов на сервере. Поэтому для таких репозиториев лучше использовать «тупой» http протокол. Кроме того, нужно обновить git до последней версии, т.к. у 1.7.1 проблемы с нехваткой памяти.
Есть еще возможность прописать
*.* -delta в .gitattributes, это приведет к отключению дельта упаковки. Т.е. даже при изменении только exif данных файл будет копироваться в репозиторий целиком. Здесь я этот подход не рассмотрел.Подробности
Для работы на сервере я выбрал gitolite. Это обертка для git, для управления репозиториями. По большому счету только из-за wild repo — репозиториев создающихся по требованию. Но также пригодилась его способность прописывать настройки в репозитории.
Установка gitolite
На сервере
useradd git su - git git clone git://github.com/sitaramc/gitolite gitolite/install -to $HOME/bin gitolite setup -pk sam.pub
Все расписано в книге, в главе 4.8.
Настройка gitolite производится на клиенте. Клонируем gitolite-admin, вносим измения, commit, push. Настроим wild репозитории — добавим в файл
gitolite-admin/conf/gitolite.conf такой блок# Repos to store photos, with name like 'Fotos-2013-03-13' repo Fotos-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9] C = sam RW+ = CREATOR RW = WRITERS R = READERS
Первый эксперимент (Добавление 3.7 гигабайт фотографий в git)
После клонирования пустого репозитория в первый комит был добавлен файл
.gitignore содержащий одну строчку — Thumbs.db.Во второй комит добавлена папка с 367 файлами, объемом 3.7 гигабайт.
293 фотографии в jpg — 439 мегабайт
37 видеороликов в avi — 3.26 гигабайт
37 THM файлов — 0.3 мегабайт
git clone git@my-server:Fotos-2013-03-01 cd 2013-03-01 echo Thumbs.db > .gitignore git add .gitignore git commit -m 'Initial commit' git add <папка> # выполнялась 4 минуты 46 секунд git commit # выполнялась 47 секунд git push --all # выполнялась 23 минуты 50 секунд
9 минут push занимался локальными вычислениями, затем 14 минут пересылкой.
Второй эксперимент
Идея, подкрутить git, чтобы он не пытался сжимать видео и фото. Как выключить по типу файлов я не обнаружил, пришлось полностью отключить сжатие.
Клонируем пустой репозиторий и настраиваем его.
На клиенте
git clone git@my-server:Fotos-2013-03-02 cd 2013-03-02 git config core.bigFileThreshold 50m git config core.looseCompression 0 git config pack.compression 0
Эти команды сохраняют настройки локально (для текущего репозитория, т.е. в файле .git/config)
core.bigFileThreshold — отключает поиск частичных изменений (дельт) в файлах больше 50 мегабайт (по умолчанию 512 мегабайт)core.looseCompression — отключает упаковку арихватором объектов в «рыхлом» состоянии.pack.compression — отключает упаковку архиватором объектов в упакованном состоянии.На клиенте
git add <папка> # выполнялась 2 минуты 16 секунд git commit # выполнялась 47 секунд git push --all # выполнялась 7 минут 20 секунд # из них 2 минуты 43 секунды вычисления 4 минуты 37 секунд передача.
После выполнения команды push на сервере репозиторий не содержал никаких дополнительных настроек (так и должно быть). Локальный репозиторий остался в рыхлом состоянии, а на сервере оказался упакован. Но при этом размер пакета оказался 3.7 гигабайт. На сервере не было настроек pack.packsizelimit=2g (но и они бы не спасли).
Клонирование репоизитория 3.7G в одном пакете по ssh
git clone git@my-server:Fotos-2013-03-02 # Выполнялась 46 минут.
После клонирования репозиторий оказался запакован, и пакет был размером 3.7 гигабайт, несмотря на локальные установки в 2 гигабайта
На клиенте
git config --system -l | grep packsize pack.packsizelimit=2g
Перенастройка сервера
Предположение, что сервер не справляется (задыхается на свопе) из-за отсутствия ограничений на размер пакета, слишком большого bigFileThreshold и отсутствия ограничений на использование памяти для поиска дельт.
Я предпринял попытку перепаковать репозиторий на сервере. Установил на сервере
git config --system pack.packsizelimit 2g
И запустил, опять на сервере
git repack -A
После этого были созданы пакеты размером до 2 гигабайт, но огромный пакет не был удален. Попытка провести сборку мусора падала от нехватки памяти, или задыхалась на свопе. В общем я удалил системную настройку, и решил прописывать в каждый репозиторий.
В новых репозиториях для фоток мы пропишем
core.bigFileThreshold = 50m # Чтобы не искать дельты в видео core.looseCompression = 0 # Чтобы не архивировать рыхлые объекты pack.compression = 0 # Чтобы не архивировать упакованные объекты pack.depth = 10 # Использовать только 10 (вместо 50) объектов для поиска дельт pack.deltaCacheSize = 128m # Какой-то кэш для дельт который может привести к свопингу pack.packSizeLimit = 2g # Ограничение максимального размера пакета pack.windowMemory = 128m # Ограничение на использование памяти при упаковке transfer.unpackLimit = 2147483647 # Оставлять нераспакованными push пакеты только если в них больше N объектов gc.auto = 300 # Если накопится больше 300 рыхлых объектов, провести упаковку
Все это мы будем прописывать в каждый репозиторий для фоток. Для этого сконфигурируем gitolite.
Перед тем, как добавлять конфиги нужно на сервере, в файле
.gitolite.rc разрешить конфигурационные параметры. Вот такой строчкойGIT_CONFIG_KEYS => '.*',
А вот как будет выглядеть конфиг gitolite.
# Repos to store photos, with name like 'Fotos-2013-03-13' repo Fotos-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9] C = sam RW+ = CREATOR RW = WRITERS R = READERS config core.bigFileThreshold = 50m # Чтобы не искать дельты в видео config core.looseCompression = 0 # Чтобы не архивировать рыхлые объекты config pack.compression = 0 # Чтобы не архивировать упакованные объекты config pack.depth = 10 # Использовать только 10 (вместо 50) объектов для поиска дельт config pack.deltaCacheSize = 128m # Какой-то кэш для дельт, может привести к свопингу config pack.packSizeLimit = 2g # Ограничение максимального размера пакета config pack.windowMemory = 128m # Ограничение на использование памяти при упаковке config transfer.unpackLimit = 2147483647 # Оставлять нераспакованными push пакеты только если в них больше N объектов config gc.auto = 300 # Если накопится больше 300 рыхлых объектов, провести упаковку
Если не указывать большой
transfer.unpackLimit, то git, получив наш push, содержащий 3.7 гигабайта, оставляет его одним пакетом. Несмотря на ограничение pack.packSizeLimit = 2g.gc.auto 300 необходимо, чтобы в репозитории на сервере не накапливалось слишком много рыхлых объектов. Чтобы "git gc --auto", когда сработает не зависала надолго. По умолчанию gc.auto = 6700.Третий эксперимент
Клонируем новый пустой репозиторий и проверяем, чтобы на сервере в нем были прописаны необходимые настройки.
Клиент
git clone git@my-server:Fotos-2013-03-03 cd 2013-03-03
Сервер
cd repositories/Fotos-2013-03-03 cat config
Клиентская копия репозитория настроена по-умолчанию. Поэтому перед тем как добавлять 3.7 гигабайта фоток нужно снова настроить
Клиент
git config core.bigFileThreshold 50m git config core.looseCompression 0 git config pack.compression 0 # Добавляем фотки git add <folder> # Это заняло 2.5 минут # Создаем комит git commit # Это заняло 45 секунд # Отсылаем на сервер git push --all # 22.5 минут # В том числе вычисления 7.5 минут, передача 15 минут
И на клиенте и на сервере остались рыхлые репозитории.
Попытки клонировать новый репозиторий по ssh провалились. На серверной стороне git 1.7.1 падал с Out Of Memory.
Обновление гит
Нужен рабочий гит любой версии (yum install git)
На сервере
Обновление гит на сервере
Нужен рабочий гит любой версии (yum install git)
На сервере
# 1. Достаем исходный код # git://git.kernel.org/pub/scm/git/git.git # 2. Устанавливаем всё необходимое для сборки (root) yum install gcc yum install openssl-devel yum install curl yum install libcurl-devel yum install expat-devel yum install asciidoc yum install xmlto # 3. собираем make prefix=/usr/local all doc # рекомендовали команду # make prefix=/usr/local all doc info # Но я застрял на "docbook2x-texi: command not found" # 4. Удаляем 1.7.1, и ставим 1.8.2 yum remove git # Чтобы удалить 1.7.1 make prefix=/usr/local install install-doc install-html /usr/local/bin/git --version git version 1.8.2
Продолжение третьего экперимента.
После обновления гит перестал падать по out of memory. Но в начале клонирования выбрал всю память — 1 гигабайт, после начала пересылки сократил до 250 мегабайт.
Собственно клонирование заняло 48 минут. И на клиенте репозиторий содержал один пак размером 3.7 гигабайт.
Статический HTTP для fetch
Идея в том, чтобы на сервере отказаться от выполнения какой-либо работы при скачивании репозитория.
К счастью git умеет делать fetch через http. Все что для этого нужно выполнить
git update-server-info после каждого обновления репозитория. Это делается обычно в hooks/post-update. И даже пример этого хука в git содержит именно эту команду.Мы возьмем пример, и настроим gitolite прописывать этот хук всем репозиториям.
На сервере
cp repositories/testing.git/hooks/post-update.sample .gitolite/hooks/common/post-update gitolite setup --hooks-only
Теперь, после следующего обновления репозиторий станет доступен для http.
Чтобы не зарываться в подробности настройки http, я воспользуюсь «игрушечным» веб сервером. Создам папку
/home/git/http-root. Добавлю в нее сслыку git->../repositories. И запущу оттуда «игрушечный» серверНа сервере
python -m SimpleHTTPServer > ../server-log.txt 2>&1 &
На клиенте
git clone http://my-server:8000/git/Fotos-2013-03-05.git
Время выполнения 4 минуты! 3.7 Гигабайт за 4 минуты! Это нам подходит.
Заключение
Для обслуживания больших репозиториев Git-ом необходимо Clone и Fetch выполнять по http. Прописать кучу настроек и желательно обновить гит.
Серверный репозиторий
git config core.bigFileThreshold 50m# Чтобы не искать дельты в видеоgit config core.looseCompression 0# Чтобы не архивировать рыхлые объектыgit config pack.compression 0# Чтобы не архивировать упакованные объектыgit config pack.depth 10# Использовать только 10 (вместо 50) объектов для поиска дельтgit config pack.deltaCacheSize 128m# Какой-то кэш для дельт, может привести к свопингуgit config pack.packSizeLimit 2g# Ограничение максимального размера пакетаgit config pack.windowMemory 128m# Ограничение на использование памяти при упаковкеgit config transfer.unpackLimit 2147483647# Оставлять нераспакованными push пакеты только если в них больше N объектовgit config gc.auto 300# Если накопится больше 300 рыхлых объектов, провести упаковку- Сделать доступ на чтение по протоколу HTTP (dumb http, НЕ какой-то там gitolite-овский smart)
Клиентский репозиторий
- Клонировать и обновлять по http
- Чтобы комитить нужно настроить url для push:
git remote set-url origin --push git@my-server:Fotos-2013-03-05 git config core.bigFileThreshold 50m# Чтобы не искать дельты в видеоgit config core.looseCompression 0# Чтобы не архивировать рыхлые объектыgit config pack.compression 0# Чтобы не архивировать упакованные объекты
Спасибо, что сподвигли меня разобраться в этом вопросе.

