
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
В этом случая я бы предпочёл отдельно описание алгоритма (в шапке файла или вообще в отдельном документе), а в коде всё равно обошёлся бы без комментариев.Вы практически сформулировали концепцию javadoc'а — специальных комментариев в шапке метода, рассчитанных на машинную обработку;-).
“Don’t comment bad code—rewrite it.”
― Brian W. Kernighan, The Elements of Programming Style
// Версия кода "hash = (65599 * hash) +c", которая выполняется быстрее
hash = (hash << 6) + (hash << 16) - hash + c;
hash = (hash << 6) + (hash << 16) - hash + c
// Версия кода "hash = (65599 * hash) +c", которая выполняется быстрее
hash = (hash << 6) + (hash << 16) - hash + c;
hash = getHash();
getHash(){return leftShift(6)+ leftShift(16) - hash + wtfC;}
// вот тут можно написать что это полиномиальный хеш с множителем 65599 по естественному 32-битному модулю
class Hash {
// ...
public:
Hash() : hash_(0) { }
void update(C c) {
// а вот эту часть кода мы сейчас пытаемся сделать более читаемой
hash_ = (hash_ << 6) + (hash_ << 16) - hash_ + c;
}
uint32_t get() const { return hash_; }
private:
uint32_t hash_;
};
std::string s1 = "hello", s2="world";
std::cerr << Hash(s1.begin(), s1.end()).hexdigest() << std::endl;
std::cerr << Hash('x').hexdigest() << std::endl;
Hash h;
h.update(s1.begin(), s1.end());
h.update(s2.begin(), s2.end());
std::cerr << h.hexdigest() << std::endl;
Ну вообще я бы тут подстраивался не столько под читаемость самого класса, а под читаемость кода, который будет этот класс использовать.
Поэтому не зная где и как он будет использоваться — идеально не написать.
Вот зачем хешу знать что это символы в кодировке utf-8? Он хеширует просто последовательность байт.
Что касается интерфейса (имя функции update, а также что я не стал вводить класс HashBuilder()) — его я почерпнул из питоновского hashlib.
В таком случае зачем передавать в него какой-то C? Передавайте последовательность байт.
2) Опять же в hashlib update — обновляет содержимое внутреннего члена — строки и такое имя метода оправдано, а вычисления происходят в digest или hexdigest — что опять же более ожидаемо. У вас же updade занимается вычислениями — имя метода вводит в заблуждение.
1) Название класса MD5 — гораздо читаемее чем Hash, потому что пользователю становится ясно чего ожидать от него. Hash — это хорошее имя для интерфейса, а не для имплементации.
Но если в вашей системе, которая решает другую задачу, есть несколько методов получения хэша, то это плохо. Это гораздо хуже чем один метод, который просто возвращает хэш. Вам не нужно знать реализацию, вам нужен просто хэш. Имя метода GetHash идеально для этого.
Ну случай если я захочу хешировать не последовательность байт, а последовательность двухбайтных чисел.
Даже если бы у нас был 10-гигабайтный входной файл, можно было бы не имея такого количества оперативной памяти вычислить его хеш, читая его по кусочкам и вызывая update() много раз.
Но если это единственный алгоритм хеширования в своей области видимости, и другие не нужны — то можно назвать его просто Hash.
Имя метода GetHash идеально для этого.
И ваш код будет так же хорошо работать с двухбайтными числами?
Может быть в таком случае этот самый поток чисел лучше всего будет назвать как-то более вменяемо чем 'C'?
Примеры из других использований этого глагола наводят на мысль что тут старое должно быть обновлено новым.
Вообще с учетом того, что у нас есть неявное состояние класса Hash — нам нужно знать его реализацию, чтобы понять как будет работать наш код с ним. Например мы получили параметром Hash, вызвали в нем update(«данные на которых мы хотим получить hash»), а в какой-то реализации нам прислали не новый объект, а какой-то уже попользованый и мы надолго засели в дебаггере, пока не отматерим создателя класса выяснив что он к тому же не сделал для нас reset() — зачем тогда вообще отдельный объект?
1) Вы никогда не знаете что с вашим кодом будет потом.
2) Работающий код всегда лучше чем неработающий, потому даже если вы назовете его class A и он будет работать — это уже хорошо.
3) Если вы все-таки хотите чтобы код был читаемым — лучше не делать в стиле «и так сойдет» для внутреннего потребления. Вам или кому-то другому придется разбираться в реализации класса через некоторое время, чтобы понять что за функцию хэширования вы там используете. Хорошо тут всего 2 строки, а если что-то сложнее типа SHA1?
Я надеюсь это сарказм?
Вы же не предлагаете создавать метод leftShift?
Но если в вашей системе, которая решает другую задачу, есть несколько методов получения хэша, то это плохо. Это гораздо хуже чем один метод, который просто возвращает хэш. Вам не нужно знать реализацию, вам нужен просто хэш. Имя метода GetHash идеально для этого.
Hash(s1.begin(), s1.end()).get()
getHash(s1.begin(), s1.end())
(65599 * hash), чем внимательно вчитаться и перевести с английского fastMultiplicationBy65599. В итоге, даже после того, как я переведу, я не буду точно уверен, что там имеется в виду, и, может, захочу еще посмотреть реализацию.// Версия кода "hash = (65599 * hash) +c", которая выполняется быстрее
(65599 * hash)hash = fastMultiplicationBy65599(hash) + c
hash = fastMultiplication<65599>(hash) + c
// Версия кода "hash = (65599 * hash) +c", которая выполняется быстрее
hash = (hash << 6) + (hash << 16) - hash + c;
#if 1 /* optimization */
hash = (hash << 6) + (hash << 16) - hash + c;
#else
hash = (65599 * hash) + c;
#endif
448: 80 91 71 00 lds r24, 0x0071
44c: 90 91 72 00 lds r25, 0x0072
450: 80 91 71 00 lds r24, 0x0071
454: 90 91 72 00 lds r25, 0x0072
458: 80 91 71 00 lds r24, 0x0071
45c: 90 91 72 00 lds r25, 0x0072
460: 80 91 71 00 lds r24, 0x0071
464: 90 91 72 00 lds r25, 0x0072hash = (hash << 6) + (hash << 16) - hash + c;
//8048373: 69 d2 3f 00 01 00 imul $0x1003f,%edx,%edx
//..
//804837c: 01 d0 add %edx,%eax
hash = 65599U * hash + c;
// 8048368: 89 d3 mov %edx,%ebx
// 804836a: c1 e3 06 shl $0x6,%ebx
// 804836d: 89 d1 mov %edx,%ecx
// 804836f: c1 e1 10 shl $0x10,%ecx
// 8048372: 01 d9 add %ebx,%ecx
// 8048374: 29 d1 sub %edx,%ecx
// 8048376: 01 c8 add %ecx,%eax
$i++;
$i=0; // взводим переменную для счетчика того-то
while (foobar) {
...
$i++;
...
}
i с j, а потом выяснять, почему в некоторых случаях программа работает неправильно, — долгое и увлекательное занятие, правда, в общем, практически бесполезное…Что, в этом случае, меня может остановить от написания комментария, на который я потрачу, от силы, пару минут?
// здесь покоятся последние надежды на нормальный код в релизе 1.3.1
в реальной жизни, не всегда получается выдавать красивый и логичный код
быть внимательным, и не забывать исправлять комментарии при исправлении кода
чистый код в комментариях не нуждается, он и так понятен
/**
* Метод выхода, посылаем далеко-далеко, отбираем печеньки,
* ломаем ножки, пусть ползёт как может. Злые мы, злые!
*/
public function Logout () {
...
}
Онегин, добрый мой приятель,
Родился на брегах Невы,
Где, может быть, родились вы
Или блистали, мой читатель;
Место рождения Онегина Е. расположено на берегах р.Нева, предположительно совпадает с местом рождения адресата данного текста
def get_transaction_id(request):
"""Returns the current transaction id from the request
:param request: The current request object
:type request: django.http.request.HttpRequest
:return: The retrieved transaction identifier or None if not valid or not available
:rtype: int or None
"""
...
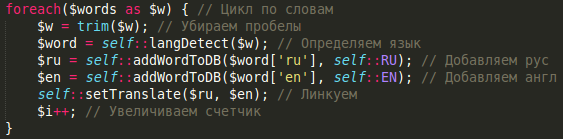
foreach($words as $w) {
// почему здесь вообще делается trim? как-то не связано с остальной частью кода
$w = trim($w);
// langDetect - сомнительное название (detectLanguage?). В любом случае, исходя из названия функции я бы предположил что она вернёт "язык". Но тогда почему мы записываем результат в переменную с именем $word? Функция с именем langDetect принимает слово, и возвращает слово. Что она вообще делает?
$word = self::langDetect($w);
// внезапно узнаем что $word - это не слово, а какой-то dict? Всё равно непонятно какова семантика того что вернула langDetect. Может быть она получила слово и вернула его переводы на русский и английский? Тогда и функцию, и $word нужно переименовать. Кстати а почему захардкожены именно эти два языка? Других никогда не будет? Почему ключи в словаре это строки 'ru', 'en', а не self::RU, self::EN?
// Ок, а что делает addWordToDB - в принципе можно догадаться. Сохраняет пару слово-язык в базу, и возвращает какой-то уникальный идентификатор.
$ru = self::addWordToDB($word['ru'], self::RU);
$en = self::addWordToDB($word['en'], self::EN);
// Два глагола подряд - не могу перевести.
self::setTranslate($ru, $en);
$i++; // а это вообще что? В цикле нигде не используется. Выпилить, и заюзать array_length если мы хотим посчитать длину массива
}
Не зная, что код должен был делать, я не могу написать поясняющие комментарии.
$ru = self::addWordToDB($word['ru'], self::RU); имеет смысл. Значит, этот код не нуждается в комментариях.$ru = self::addWordToDB($word['ru'], self::RU); нужно комментировать все такие вызовы. Но это же бред. Возможно стоит прокомментировать сам метод addWordToDB? А он, оказывается, очень простой и понятен без комментариев. Тупик.Плохой код — комментарии не спасут.
/**
* Добавление слова // Не слова а целого словаря
*/
public static function add($words) // $dict. И в комментарии к функции написать в каком формате принимаем словарь (строки разделенные \n, в каждой строке два слова через пробел(ы?), какое из них русское, а какое - английское - определяется автоматически)
{
$words = explode("\n", $words); // lines? Хотя в контексте словарей можно и words назвать но на мой сторонний взгляд это путаница
$i = 0;
foreach($words as $w) { // as $line
$w = trim($w); // всё же я бы отдельной строкой сделал $words = map(trim, $words), в этом цикле trim неуместен. Хотя langDetect может сам trim сделать
$word = self::langDetect($w); // $translations = self::parseLine($line); // или не $translation а $words? или оставить $word?
$ru = self::addWordToDB($word['ru'], self::RU); // всё равно почему 'ru' захардкожено если есть константа?
$en = self::addWordToDB($word['en'], self::EN);
self::setTranslate($ru, $en); // addTranslation
$i++;
}
return $i; // зачем?
}
/**
* Запускается в основном потоке
*/
int
load_online(struct conn * conn ) {
…
}
/*
первый параметр всегда uid, по которому надо шардить, далее параметры для вывода
возвращает номер шарда, используется в sql_execute(const char* query , int shard_id);
*/
static int
sql_build(char* bufer, const char* template, uint64_t uid, ...) {
…
}
Самое главное, если вы решили отказаться от ..., убедитесь, что причина… не в банальной лени.
Иногда мне кажется, что компилятор игнорирует все мои комментарии
def intersect_solve(self, i, j, x2=None, y2=None):
self_intersect = x2 is None
x1, y1 = self.__x, self.__y
xy1 = np.dstack((x1, y1)).squeeze()
xy2 = xy1
dxy1 = np.diff(xy1, axis=0)
if self_intersect:
x2, y2 = x1, y1
dxy2 = dxy1
is_nans = (np.isnan(np.sum(dxy1[i, :] + dxy2[j, :], axis=1)))
else:
xy2 = np.dstack((x2, y2)).squeeze()
dxy2 = np.diff(xy2, axis=0)
is_nans = np.isnan(np.sum(dxy1[i, :] + dxy2[j, :], axis=1))
remove = np.flatnonzero(is_nans)
i = np.delete(i, remove)
j = np.delete(j, remove)
n = i.size
t = np.zeros((4, n))
a = np.zeros((4, 4))
a[(0, 1, 2, 3), (2, 2, 3, 3)] = -1
b = -np.dstack((x1[i], x2[j], y1[i], y2[j])).squeeze().transpose()
if n == 1:
b = b.reshape((b.size, 1))
anomalous = np.zeros(n, dtype=np.bool)
eps = np.finfo(np.float64).eps
for k in xrange(0, n):
a[(0, 2), (0, 0)] = dxy1[i[k], :]
a[(1, 3), (1, 1)] = dxy2[j[k], :]
try:
t[:, k] = linalg.solve(a, b[:, k])
except linalg.LinAlgError:
if self_intersect:
t[:, k] = np.nan
else:
t[0, k] = np.nan
v = (dxy1[i[k], :], xy2[j[k], :] - xy1[i[k], :])
m = np.vstack(v).squeeze()
try:
cond = np.array(np.linalg.cond(m, p=1), ndmin=2)
anomalous[k] = (linalg.inv(cond).squeeze() < eps)
except linalg.LinAlgError:
anomalous[k] = True
if self_intersect:
anomalous = np.any(np.isnan(t), axis=0)
return i, j, t, anomalous
curve_intersection_solving, и даже новичку гадать не пришлось. // Smart pointer to singleton instance of the font file loader.
IDWriteFontFileLoader* ResourceFontFileLoader::instance_(
new(std::nothrow) ResourceFontFileLoader()
);
static IDWriteFontFileLoader* instance_;
//deprecated use methodB(...)
public void methodA(...)
Почему [не]нужно комментировать код