
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Плотность распределения суммы из 12 равномерное распределенных нез. величин относится к классу нормального распределения? Не верю.Это вообще к чему? Как бы слова «Ирвин-Холл» и «Нормальное» существенно различаются, я уже не говорю о формулах распределения. Ежу понятно, что сумма 12 стандартных равномерных случайных величин имеет конечный носитель и (в точности) нормальным быть не может.
 , cooтвeтcтвeннo в oбщeм cлучae нaм нужнo
, cooтвeтcтвeннo в oбщeм cлучae нaм нужнo
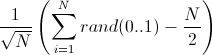

Хоть s и является функцией от x и y, от каждой из этих координат в отдельности s будет независима.
Сейчас, когда одна команда процессора за мгновение вычисляет одновременно синус и косинус, думаю, эти методы могут еще посоревноваться.
def randnorm():
while True:
x = 2 * math.pi * random.random()
y = math.sqrt(-2 * math.log(random.random()))
yield math.cos(x) * y
yield math.sin(x) * y
спасибо за очень полезную статью!

Преобразование равномерно распределенной случайной величины в нормально распределенную