 Генетические алгоритмы были изобретены в 1950-х годах как результат первых экспериментов по моделированию естественной эволюции на компьютере. С тех пор они используются для решения самых разнообразных оптимизационных задач, где градиентные методы почему-то не подходят. Биологическая составляющая генетических алгоритмов имеет здесь очень упрощенный вид и речь в данном случае идет скорее о следовании общей идее эволюционного отбора, чем полноценному его моделированию. Тем не менее, иногда результаты работы ГА получается интерпретировать в биологическом смысле. В нашей статье мы рассказываем об опыте применения генетических алгоритмов для задачи распознавания лиц с целью получения «регионов важности» лица. Применение этого подхода позволило в среднем на 20% повысить точность распознавания нашей системы распознавания лиц.
Генетические алгоритмы были изобретены в 1950-х годах как результат первых экспериментов по моделированию естественной эволюции на компьютере. С тех пор они используются для решения самых разнообразных оптимизационных задач, где градиентные методы почему-то не подходят. Биологическая составляющая генетических алгоритмов имеет здесь очень упрощенный вид и речь в данном случае идет скорее о следовании общей идее эволюционного отбора, чем полноценному его моделированию. Тем не менее, иногда результаты работы ГА получается интерпретировать в биологическом смысле. В нашей статье мы рассказываем об опыте применения генетических алгоритмов для задачи распознавания лиц с целью получения «регионов важности» лица. Применение этого подхода позволило в среднем на 20% повысить точность распознавания нашей системы распознавания лиц.Существующие подходы для распознавания лиц
Исторически, примерно после 20-ти лет интенсивных исследований в области компьютерного распознавания лиц, в начале 2000-х годов выделилось две базовых группы методов сравнения лиц: «холистические подходы», «holistic approaches» (или «глобальные подходы») и «признаковые подходы», «feature-based approaches» (или «структурные подходы») [1]. В первом случае, лица рассматриваются как цельные изображения, которые сравниваются между собой. Во втором случае, из изображения лица выделяются локальные признаки, такие как информация об абсолютном и взаимном расположении глаз, носа, рта и т.п. Обе группы имеют свои недостатки: холистические подходы показали в целом большую надежность в близких к идеальным условиям распознавания по сравнению с признаковыми подходами, однако признаковые подходы лучше себя зарекомендовали в ситуации, когда отдельные части лица почему-либо не видны (например, закрыты элементами одежды или очками). Применение к задаче распознавания лиц модных в настоящее время SIFT-подобных методов извлечения признаков в чистом виде дают неудовлетворительные результаты, поскольку на лице человека обычно слишком мало «углов», для которых определяются ключевые точки. Алгоритмы же типа «dense-SIFT» с вычислением признаков по заданной решетке ключевых точек хотя и демонстрируют хорошее качество распознавания [2], не всегда являются удобными для практического применения из-за большого размера векторов признаков и большого времени, которое требуется для их вычисления. В этих условиях в последние годы популярность набрала группа методов, которые условно можно назвать «модульными подходами» [4-9], в том числе метод локальных бинарных шаблонов.
Кластерные подходы для сравнения лиц
Суть кластерных подходов для сравнения лиц заключается в разделении изображения лица на некоторое количество участков, к каждому из которых можно применить холистический подход и сравнивать их попарно, т.е. независимо от других участков. В таком случае можно надеяться на то, что если некоторые пары участков сравниваемых изображений не будет совпадать между собой в силу вышеупомянутых мешающих факторов вроде теней и перекрытий, оставшиеся пары участков обеспечат нужную степень взаимной корреляции, которой будет достаточно для правильного итогового решения совпадения/несовпадения лиц.
В качестве холистического подхода может применяться метод главных компонент [4], моментные инварианты [5], локальные бинарные шаблоны (ЛБШ) [6, 7], вейвлеты Габора [8], вейвлеты Хаара [9] и др. методы. В нашем проекте мы используем комбинированный подход ЛБШ [7] и моменты псевдо-Зернике [5].
Матрица весов важности участков лица
В нашей системе распознавания лиц, внедренной в приложение «ZZPhoto», мы учитываем неодинаковую важность разных участков лица для сравнения лиц путем разделения изображения лица на
 участка (рис. 1) и присваивания каждому из них своего весов
участка (рис. 1) и присваивания каждому из них своего весов  , значения весов принимают одно из четырех дискретных значений,
, значения весов принимают одно из четырех дискретных значений, 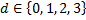 .
. 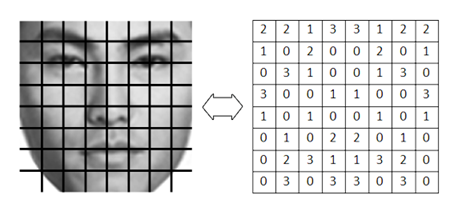
Рис 1. а) Разделение лица на 8х8 = 64 непересекающихся квадратных участка. б) Значения матрицы весов важности участков лица.
Чем больше значение веса, тем большее влияние имеет совпадение/несовпадение соответствующего участка лица на итоговое решения алгоритма сравнения. На рис. 6 более важные участки лица выделены более красным оттенком.
Использование полного перебора для определения оптимальной матрицы весов важности на практике затруднительно, поскольку нам пришлось бы рассматривать
 вариантов матрицы весов (здесь стоит степень 32, а не 64, так как используются симметричные по горизонтали матрицы весов из-за, в общем случае, симметричной природы лица человека). Поэтому, для поиска лучшей матрицы необходимо использовать более интеллектуальный алгоритм поиска. В итоге, мы остановились на генетических алгоритмах (ГА).
вариантов матрицы весов (здесь стоит степень 32, а не 64, так как используются симметричные по горизонтали матрицы весов из-за, в общем случае, симметричной природы лица человека). Поэтому, для поиска лучшей матрицы необходимо использовать более интеллектуальный алгоритм поиска. В итоге, мы остановились на генетических алгоритмах (ГА).Генетические алгоритмы
Генетические алгоритмы хорошо себя зарекомендовали как средство глобальной оптимизации, когда нельзя применить градиентные оптимизационные методы. Их плюсы – не требуется дифференцируемая модель оптимизируемого объекта, а также меньший риск попадания в локальный минимум. Их минус – значительно меньшая скорость сходимости по сравнению с градиентными методами. Суть генетических алгоритмов заключается в моделировании процесса естественного отбора как средства нахождения оптимального решения, при этом используется механизм передачи наследственной информации из поколения в поколение посредством генов. В качестве меры успешности «жизни» организма используется целевая функция оптимизации, которая в терминах ГА называется «фитнес-функцией». Перед описанием работы алгоритма ГА для нашего случая, перечислим список понятий, с которыми мы оперируем и кратко поясним их смысл.
Фитнес-функция – определяет качество «жизни» отдельного индивида в поколении (популяции). Роль фитнес-функции в нашем случае выполняет программный эксперимент по распознаванию лиц с помощью нашего алгоритма сравнения лиц на заданной базе изображений лиц. Результатом работы фитнес-функции является процент правильно распознанных лиц для определенной хромосомы.
Хромосома – определяет индивид в популяции, фактически это наша матрица весов важности участков лица. Каждая хромосома является кандидатом на решение целевой задачи.
Приспособленность – качество жизни индивида, закодированного хромосомой. Является результатом применения фитнес-функции к хромосоме. В нашем случае это точность классификации с заданной матрицей весов важности участков лица.
Популяция – набор из 100 различных хромосом, гены кодируются значениями из допустимого набора {0,1,2,3}. Значения могут быть как полностью случайными (первая популяция), так и являться продуктом эволюционного процесса (скрещивания и мутаций).
Скрещивание (размножение) – процедура получения новой хромосомы. Новая хромосома «ребенка» формируется из частей хромосом «родителей». Точка скрещивания выбирается с помощью генератора случайных чисел каждый раз для каждой пары родителей. Выбор родителей выполняется процедурой селекции.
Селекция – процедура выбора хромосом «родителей», из которых будут формироваться хромосомы для новой популяции. Селекция призвана увеличить вероятность попадания во множество «родителей» хромосом, показавших лучшую приспособленность в последней на текущий момент популяции. Мы используем стохастический подход, вероятность
 выбора i-й хромосомы:
выбора i-й хромосомы: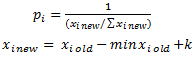
где:
 .
.Мутация – процедура замены одного значения хромосомы на случайное значение после скрещивания, вероятность мутации задана заранее.
Элитизм – особенность формирования нового поколения, суть которого заключается в том, что в новое поколение прямо включаются лучшие родительские особи. Их число может быть от 1 и больше.
Описание хода эксперимента
- Генерируется начальная популяция из 100 хромосом, значения которых заполнены случайными значениями.
- К каждой хромосоме популяции применяется фитнес-функция, которая определения значения приспособленности для хромосом.
- С помощью селекции отбираются наиболее приспособленные хромосомы, которые формируют множество «родителей».
- Из множества родителей отбираются случайные пары, выполняется скрещивание и формируются хромосомы «детей».
- К хромосомам «детей» применяется процедура мутации.
- Полученные хромосомы формируют новую популяцию, к которой выполняются шаги 2) – 5).
- Если улучшение не происходит длительное время (скажем, 30 популяций и более), происходит остановка. Хромосома, показавшая лучшую приспособленность, является решением задачи.
Эксперименты
Можно дать следующую биологическая интерпретация для наших экспериментов: биологические индивидуумы, которые обращают внимание «не на те» участки лица, вымирают; те же индивидуумы, которые имеют хорошую способность к распознаванию, выживают и дают более многочисленное потомство.
Первый эксперимент проводился на известной базе изображений лиц Color FERET [11]. Из данной базы было отобрано изображения лиц 100 человек, сфотографированных во время нескольких сессий, по 5 примеров лиц на человека. Примеры изображений из Color FERET Face Database показаны на рис. 2. В этой базе собраны изображения лиц, полученные за несколько фото-сессий в разных условиях освещенности и с разными выражениями лица. Выделение собственно участков лиц производилось в автоматическом режиме модулем выделения лиц на основе детектора лиц Виолы-Джонса, входящего в состав OpenCV. Он дополнительно включает в себя нормализацию изображения по величине, положенню и углу поворота во фронтальной плоскости (для чего на лице дополнительно производится поиск глаз, носа и рта).

Рис. 2. Примеры лиц из Color FERET Face Database.
Суть эксперимента состоит в классификации лиц в режиме «одно лицо на одну персону» («Single face Per Person»). Алгоритм распознавания получает на вход одно фото лица каждого человека из базы, после чего проводит сравнение выбранного лица со всеми остальными своими и чужими изображениями лиц в базе и строит зависимости ошибок аутентификации 1-го и 2-го рода от порогового значения аутентификации, т.е. кривые зависимостей False Accept Rate (FAR), и False Reject Rate (FRR). Ошибка FAR соответствует ситуации «ложный доступ», когда система ложно «узнает чужого, как своего»; ошибка FRR – это «пропуск цели», когда система ложно «не узнает своего». По условиям решаемой нами прикладной задачи, значение было FRR зафиксировано не должно превышать 20%. По результатам экспериментов на всех лицах формируется итоговая ошибка распознавания, в роли которой используется ошибка HTER (Half Total Error Rate), т.е. ошибка доступа, равная среднему FAR и FRR.
Для Color FERET Face Database ошибка распознавания FAR с единичными весами составила 21% (т.е. 79% корректных ответов), что близко к современному state-of-art уровню методов распознавания лиц. После применения генетических алгоритмов для оптимизации матрицы весов важности участков лица (рис. 3), ошибку распознавания FAR удалось понизить до 12%, т.е. уменьшить почти в 2 раза по сравнению с исходной.

Рис. 3. Результат применения генетических алгоритмов для оптимизации матрицы весов важности участков лица на базе Color FERET.
Для организации эксперимента с различными расами, а также, более приближенного к реальным условиям, мы собрали собственную базу лиц ZZWolf ABC Face Database, включающую в себя лица людей различных рас (ABC = Asian, Black, Caucasian). База лиц содержит выборки лиц для трех основных рас, по 10 лиц для 10-ти человек (5 мужчин и 5 женщин) каждой расы, фото лиц были собраны в интернете, всего 300 лиц. Это в основном лица известных людей (актеров и политиков), снимки сделаны различными фото-камерами, в разное время (разница в сьемках может составлять годы) и в различных условиях освещения.

Рис. 4. Примеры лиц из ZZWolf ABC Face Database. Выделение, нормализация и препроцессинг лиц осуществлялся автоматически.
В итоге, ошибка распознавания лиц на новой базе составила в среднем 37,2%. После применения генетических алгоритмов удалось понизить ошибку до 32 %.

Рис. 5. Результат применения генетических алгоритмов для оптимизации матрицы весов важности участков лица на базе ZZWolf ABC Face Database для различных рас.
Таблица 1. Результаты распознавания на базе ZZWolf ABC Faces
| Для азиатов |
Для чернокожих |
Для белых |
Среднее |
|
| Единичные веса важности (все участки лица равноценны) |
38,0% |
35,3% |
38,3% |
37,2% |
| Веса важности оптимизированы генетическими алгоритмами |
34,3% |
29,0% |
32,8% |
32,0% |
Итоговые оптимизированные матрицы важности участков лиц показаны на рис. 6, для разных рас они различаются. Наша выборка лиц «ZZWolf ABC Face Database» является небольшой по объему, поэтому мы не претендуем на то, что полученные нами экспериментально матрицы важности участков лиц для различных рас являются оптимальными при любых условиях и полностью соответствуют биологическим системам распознавания лиц у реальных людей.
Рис. 6. Матрицы важности участков лиц для различных рас. Чем более красный цвет, тем большую важность он составляет.
Тем не менее, если принять гипотезу о том, что люди разных рас при распознавании лиц друг друга больше внимания уделяют участкам лица, характерным именно для своей расы и из-за этого представителям различных рас (например, европейцам и азиатам) бывает сложно узнавать друг друга, то результаты можно проинтерпретировать следующим образом: для белых самую большую важность имеет область глаз, для чернокожих – область носа, а для азиатов – область ушей и область лба над набровными дугами.
Выводы
В статье представлен метод улучшения точности работы алгоритма распознавания лиц, который используется в программе «ZZPhoto» на основе использования генетических алгоритмов. Эксперименты на различных базах лиц показывают улучшение качества распознавания от 20% до 2-х раз. Метод является достаточно общим и может быть применен для различных кластерных алгоритмов распознавания лиц. Результаты экспериментов на выборке лиц представителей различных рас дают любопытные результаты, возможно, объясняющие некоторые естественные механизмы распознавания лиц у людей.
Список литературы
- W. Zhao, R. Chellappa, P. J. Phillips, A. Rosenfeld. Face recognition: A literature survey, Journal ACM Computing Surveys (CSUR), 2003, Volume 35, Issue 4, pp. 399 – 458.
- P. Dreuw, P. Steingrube, H. Hanselmann, H. Ney. SURF-Face: Face Recognition Under Viewpoint Consistency Constraints // Proceedings British Machine Vision Conference, 2009.
- R. Gottumukkal, V.K. Asari. An improved face recognition technique based on modular PCA approach // Pattern Recognition Letters, 2004, Volume 25, Issue 4, pp. 429 – 436.
- H.V. Nguyen, L. Bai, L. Shen. Local Gabor Binary Pattern Whitened PCA: A Novel Approach for Face Recognition from Single Image Per Person // Advances in Biometrics. Lecture Notes in Computer Science Volume 5558, 2009, pp. 269 – 278.
- H.R. Kanana, K. Faez, Y. Gaob. Face recognition using adaptively weighted patch PZM array from a single exemplar image per person // Pattern Recognition, 2008, Volume 41, Issue 12, pp. 3799 – 3812.
- S. Nikan, M. Ahmadi. Human face recognition under occlusion using LBP and entropy weighted voting // 2012 21st International Conference on Pattern Recognition (ICPR), 11-15 Nov. 2012, pp. 1699 – 1702.
- T. Ahonen, A. Hadid, M. Pietikainen. Face Description with Local Binary Patterns: Application to Face Recognition // Pattern Analysis and Machine, 2006, Volume 28, Issue, 12, pp. 2037 – 2041.
- B. Kepenekci, F.B. Tek, G. Bozdagi Akar, Occluded face recognition based on Gabor wavelets, ICIP 2002, September 2002, Rochester, NY, MP-P3.10.
- H.-S. Le, H. Li, Recognizing frontal face images using hidden Markov models with one training image per person, Proceedings of the 17th International Conference on Pattern Recognition (ICPR04), vol. 1, 2004, pp. 318–321.
- Д. Рутковская, М. Пилиньский, Л. Рутковский. Нейронные сети, генетические алгоритмы и нечеткие системы // Пер. с польского М.: Горячая линия-Телеком,2004 – 452 с.
- www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html
- www.nist.gov/itl/iad/ig/colorferet.cfm
UPDATE: Названия рас приведены в соответствие с англоязычной Википедией.

