Здравствуй Хабр! Хочу рассказать как мы делали свою собственную Big Data.
Каждый стартап хочет собрать что-то дешевое, качественное и гибкое. Обычно так не бывает, но у нас, похоже, получилось! Ниже идёт описание нашего решения и много моего сугубо субъективного мнения по этому поводу.
И да, секрет в том, что используется 6 сервисов гугла и собственного кода почти не писалось.
Что было нужно?
Работаю в весёлом сингапурском стартапе – Bubbly, который делает голосовую социальную сеть. Фишка в том, что можно пользоваться без смартфона, достаточно старой доброй нокии. Пользователь звонит на специальный номер и может прослушивать сообщения, записывать свои сообщения и т.п. Всё голосом, даже не нужно уметь читать, чтобы пользоваться.
В Юго-Восточной Азии у нас десятки миллионов пользователей. Но так как работает это через операторов сотовой связи, в других странах про нас никто ничего не знает. Эти пользователи генерят огромное количество активности, которую хочется регистрировать и всячески анализировать:
- Сделать красивый дэш-борд с ключевыми метриками, обновляющимися в он-лайн режиме
- Мониторить работу сервиса и ошибки
- Делать А\Б тесты и анализировать поведение пользователей
- Делать отчеты для наших партнёров
- …
В общем, задачи, которые нужны всем и всегда практически.
Зачем изобретать велосипед?
Казалось бы – зачем что-то строить, если есть уже готовые решения? Руководили мной такие мотивы:
1. Не хочу использовать Mixpanel (сорри гайс!)
- Если нет полного контроля над данными, то всегда найдётся вопрос, на который чужая готовая система ответа не даёт. Да, я знаю, что есть Mixpanel export APIs и они позволяют многое. Но по факту столько раз уже натыкался на подобные ситуации. Хочется полного контроля.
- Кучу всяческих «хотелок» придётся прикручивать в чужому проприетарному продукту, что не очень удобно. Например, SMS-alert начальнику саппорта, если что-то поломалось. Или специальные отчёты сторонним партнёрам. И такие фичи все заранее не предскажешь.
- Это реально дорого! Я знаю, что многие вместо всех данных загружают туда только случайную выборку, чтобы хоть как-то снизить затраты. Но это очень сомнительное счастье само по себе.
2. Если так хочется «своего» решения, почему тогда не замутить Hadoop со всем фаршем?
- Нужно поднять сервера и всё настроить. Есть конечно hosted Hadoop, где всё уже «настроено», но разбираться с этими настройками всё равно придётся.
- Hadoop – это только хранение и запросы. Все остальные фичи придётся делать самому.
MySQL под задачу понятно не подходит, так как данных у нас для него слишком много.
Кратко как это работает у нас
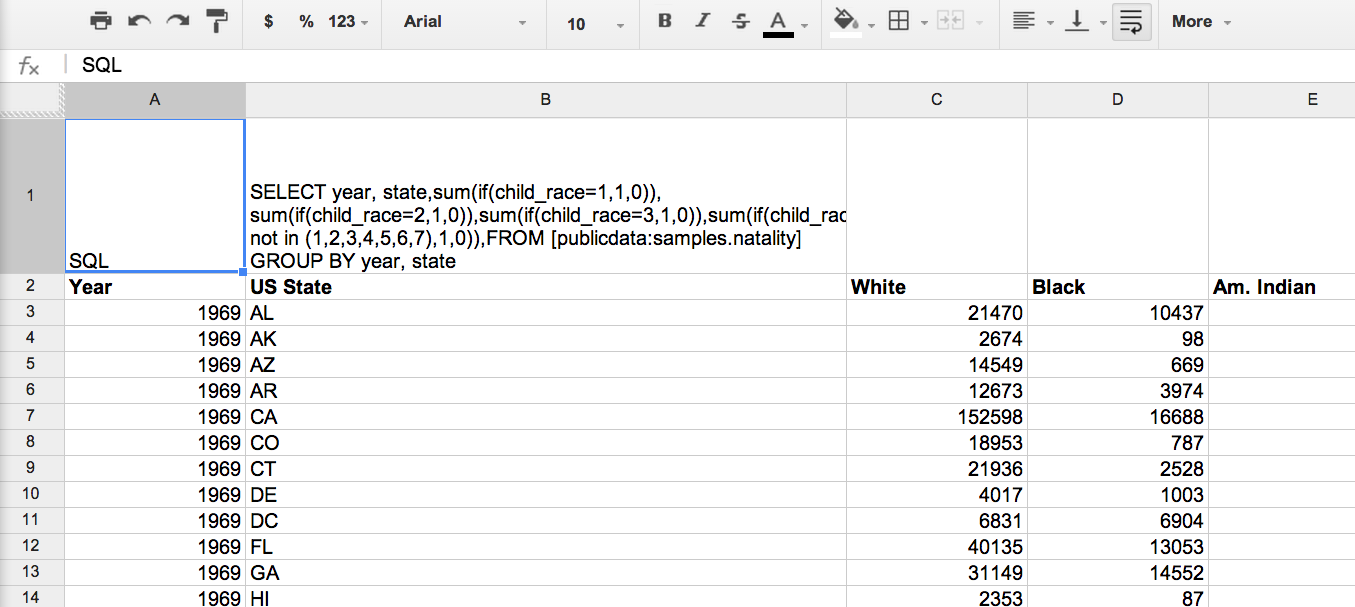
- Мы заливаем все «события» от пользователей с наших серверов в Google Big Query
- Используем Google Spreadsheets для запросов к Big Query и последующей обработки данных. Вся логика сидит в Spreadsheets и привязанных к нему скриптах.
- Далее визуализируем полученные данные с помощью Google Charts.
- Хостим эти графики на Google Drive
- В единый «дэш боард» эти графики собираются в Google Sites
- И наконец, поверх Google Sites стоит Google Analytics, который смотрит за пользователями всей этой аналитики.
Преимущества этого подхода (нет я не пиарю Google за деньги, a жаль)
Big Query — плюсы
- Эта база данных может хранить огромное количество данных. Вопрос масштабируемости не стоит.
- Стоит это копейки по сравнению с другими решениями. О расходах ниже пишу отдельно.
- Фактически любой запрос занимает менее 20 секунд. Это сильно отличается от Hadoop, где счёт в лучшем случае на минуты. Для стандартных, определённых раз и навсегда запросов разница кажется маленькой. Но если ты смотришь на данные «в свободном полёте» (ad hoc) или чинишь что-то методом проб и ошибок, то даже небольшие паузы рвут весь рабочий процесс и снижают эффективность работы аналитика в разы. А по жизни получается, что только такими задачами и занимаешься целый день. Очень важное преимущество Big Query.
- Мелкие плюшки, такие как web-интерфейс, на самом деле, сильно помогают.
Улучшения:
Очень хотелось Big Query сделать schemaless, просто чтобы добавлять события в систему и ни о чем не думать. Поэтому к загрузчику прикрутили кусочек кода, который проверяет текущую схему таблицы в Big Query и сравнивает с тем, что он хочет загрузить. Если есть новые колонки, то они добавляются в таблицу через Big Query API.
Google Spreadsheets – плюсы
Лучше электронных таблиц для анализа данных нет ничего. Это моя аксиома. Для данной задачи Spreadsheets подходит лучше MS Excel (как бы я его не любил). Причины такие:
- Работает с Big Query из коробки (туториал от Goolge)
- Всё лежит в облаке и скрипты могут обновлять данные по расписанию
- Кроссплатформенность! Одинаково работает под PC и Mac.
- Уже есть куча полезных функций — email и т.п.
Улучшения:
Cкрипт из туториала был немного доработан. Теперь он проверяет каждый лист в электронных таблицах. Если в клетке A1 написано «SQL», то значит в А2 лежит запрос к Big Query. Результаты запроса скрипт положит на этом же листе.
Это нужно, чтобы при использовании не касаться кода вообще. Создал новый лист, написал запрос, получил результат.
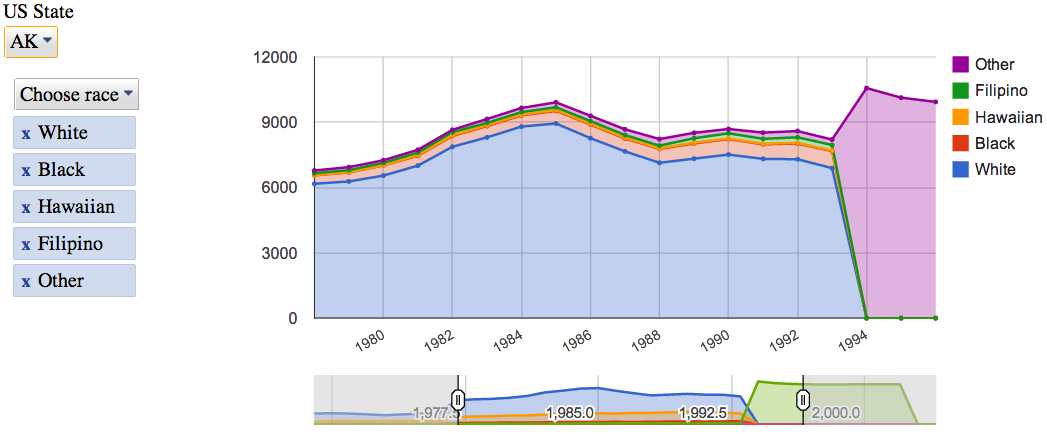
Google Charts – плюсы
- Библиотек по визуализации много, но есть ощущение что у гуглов всё более надёжно и функционально (если конечно они Charts не спишут как Reader).
- Работает со Spreadsheets из коробки (туториал от Google)
- Подкупили их интерактивные контролы, которые позволяют довольно глубоко играть с данными даже бизнес-людям, которые ни SQL, ни Excel не используют.
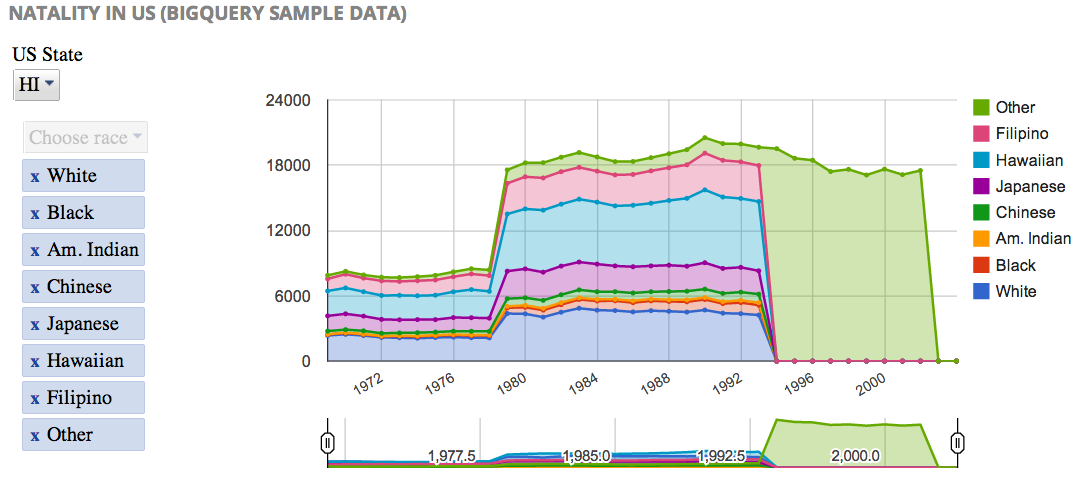
Google Sites / Google Drive – плюсы
- Можно пользоваться гугловской проработанной системой прав доступа. В Dropbox нельзя дать read-olny доступ, а здесь можно.
- Google Sites имеют wysiwyg-редактор, что мне лично очень нравится.
- После того как всю систему построил на гугловых сервисах, решил ими пользоваться до конца из принципа.
Google Analytics
Рекурсия! У нашего Dash Board порядка 30 юзеров. Достаточно для того, чтобы анализировать статистику использования ресурса. Google Sites, что не удивительно, с Google Analytics интегрируются в пару кликов. Посещаемость страниц объективно показывает, какие данные наиболее интересны, чтобы в этом направлении улучшать систему.
О расходах на решение
Считаю, что в любой системе самое дорогое это время необходимое на разработку и человеко-дни потраченные на разработку и поддержку. В этом смысле данное решение идеально, так как своего кода почти не писалось. Весь проект делал один человек, в параллель с другими задачами, и первая версия была сделана за месяц.
Есть, конечно, подозрения, что интеграция между сервисами гуглов может ломаться (по их туториалу видно, что это уже случалось) и потребуются усилия на поддержку. Но не ожидаю ничего страшного.
Что касается прямых расходов, то во всей системе только Big Query стоит денег. Оплачивается хранение данных и запросы к данным. Но это просто копейки! Мы пишем по 60 млн событий в день и ни разу более 200 USD в месяц не платили.
Важная надстройка к Big Query
Big Query по умолчанию сканирует всю таблицу. Если события за всё время хранить в одном месте, то запросы становятся медленнее и дороже со временем.
Наиболее интересны всегда данные за последнее время, поэтому мы пришли к месячному ротиванию этих таблиц. Каждый месяц таблица events бэкапится в events_201401Jan, events_201402Feb и так далее.
Чтобы к такой структуре удобно было делать запросы, расширили немного язык SQL. Благо всё контролирует собственный скрипт из Spreadsheets, и он может наши запросы парсить и обрабатывать как нужно. Добавил такие команды:
- FROMDATASET dataset – запрашивает по очереди все таблицы в дата-сете. Это на случай, если нужно запросить данные за весь период времени
- FROMLAST table – запрашивает текущую таблицу и таблицу за последний месяц. Это для запросов, которым нужны данные за последние 7 дней, например. Чтобы в начале месяца запрос возвращал полные 7 дней, а не то что есть на текущий месяц.
Планы на будущее:
- Пилить скрипт запускающий SQL. Хочу чтобы он кроме FROMLAST умел всякие полезные трансформации типа PIVOT и т.п.
- Пилить JavaScript для Google Charts. Хочу в идеале избавиться от необходимости трогать код вообще. Чтобы как в Excel pivot charts – переключать одним кликом и тип графика, и какие серии по какой оси, и т.п. Но это глобальные планы.
- Хочу поэкспериментировать с nested data. Мы можем на сервере отсортировывать все события из отдельной сессии пользователя в одну запись. То есть события внутри сессии (звонка в нашем случае) будут «детьми» этой сессии. В теории это должно упростить некоторые замороченные запросы.
Как это всё работает можно посмотреть на примере здесь.
Очень хочется, чтобы знающие люди сказали своё мнение. Для того эта статья и писалась.
PS Прошу об ошибках по тексту и моих англицизмах писать в личку, всё поправлю.
PPS Я совсем не программист, поэтому мой код может быть страшен (но он работает!). Буду рад конструктивной критике.

