Достался мне тут довольно интересный проектик: на рентгенограммах сварных швов находить проволочные образцы стандартных размеров. Казалось бы, сколько уже было написано по поводу поиска паттернов на изображении, выработаны стандартные подходы и методики, но когда речь заходит о реальных задачах академические методы оказываются не настолько эффективны, как от них ожидается. Для затравочки, попробуйте найти здесь все семь проволочек:
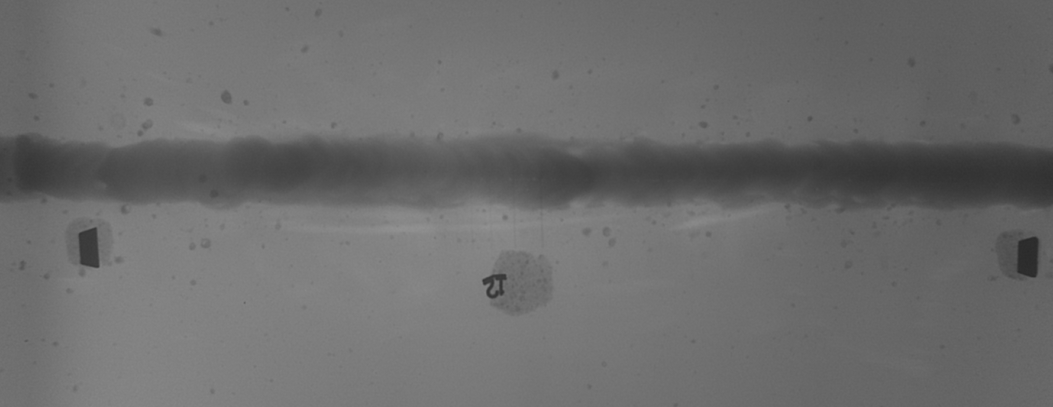
На самом деле, это далеко не самый простой кадр, но в итоге даже на нем все нашлось:

Итак, какие же условия мне были озвучены:
– файлы будут tiff и могут быть довольно большими — больше 200 Мб
– изображения могут быть как позитивные, так и негативные
– на одной картинке могут быть несколько эталонов, надо найти все
– образцы лежат либо почти вертикально (+-10 градусов) или почти горизонтально
– на кадрах могут быть другие эталоны и прочие элементы
– швы могут быть как прямыми, так и эллиптическими, горизонтальными и вертикальными
– образец может лежать на шве или поблизости от него
Максимальное время поиска эталонов на снимке:
– 3 секунды для снимка размером меньше 100 МБ
– 5 секунд для снимка больше 100 МБ и меньше 200 МБ
– 10 секунд, для снимка размером больше 200 МБ.
Так же мне были даны ГОСТы двух типов эталонов, которые выглядили как-то так:
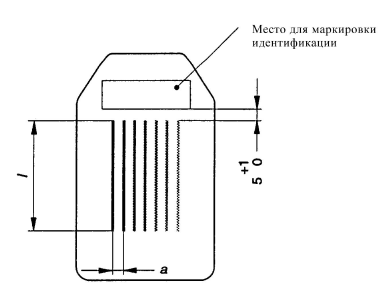
Т.е. каждый эталон состоит из 7 проволочек определенной длины и уменьшающегося диаметра расположенных на заданных расстояних.
Длины бывают разные: 10, 20, 25, 50 мм.
Для каждой длины есть набор эталонов с различными толщинами проволочек, например, один эталон с длиной проволочек 25 мм имеет диаметры проволочек 3.2мм, 2.5мм, 2мм, 1.6мм, 1.25мм, 1.0мм, 0.8мм, 0.63мм, а другой — 1.0мм, 0.8мм, 0.63мм, 0.5мм, 0.4мм, 0.32мм, 0.25мм.
Всего таким образом было порядка 16 эталонов.
Таким образом, мне надо было локализовать полностью детерминированные объекты на изображениях различного качества.
Мне сразу подумалось об использовании обучаемых классификаторов, но смутил тот факт, что у меня было всего 82 файла с различными эталонами, а для нормального треннинга классификатора все-таки нужны тысячи изображений. Так что этот путь пришлось отмести сразу.
Задача поиска линейных отрезков сама по себе неплохо отражена в литературе.
Первое же что приходит в голову это искать отрезки преобразованием Хафа, но, во-первых, оно очень ресурсоемкое, а во-вторых, слабые сигналы среди более сильных после преобразования будет искать ничуть не легче. Даже если взять довольно удачное кадрирование:

то найти проволочки все равно довольно затруднительно:

( вот как оно должно было бы выглядеть: ->
->  )
)
Другой вариант был бы использовать фильтрации контуров, но возникает проблема: а как выбирать порог бинаризации в автоматическом режиме?
Да и что делать с контурами, которые в основном выбирают сварной шов или что-то еще?
-> 

Детектор контуров с различными уровнями бинаризации
То же относится и к другим детекторам конутров типа бимлетов.
Как оказалось, крайне продуктивным шагом было простое вычисление градиентной карты, т.е. просто вычисление разницы между двумя соседними пикселами. Подобный шаг резко выделяет острые края и практически стирает все медленные переходы. Вот что, например, получилось после применения градиентов дважды:
было:
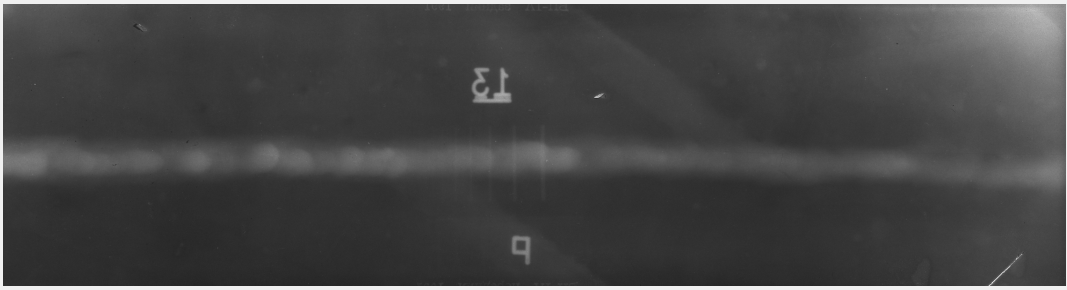
стало:

На нижней картинке для наглядности повышен контраст.
Согласитесь, даже невооруженным глазом стало гораздо легче найти проволочки.
Тут же сразу стала видна и другая проблема — шум.Причем уровень шума неравномерен по картинке.
Как же нам выделять области интереса для более детальной проработки? Необходим какой-то метод, который учитывал бы локальный уровень шума и детектирвал выбросы, значительно превосходящие среднесатитстическое отклонение.
Так как вся геометрия эталонов нам известна заранее, то мы можем выбрать размер окна в котором будет собираться локальная статистика, тем самым мы сможем автоматизировать выбор порога бинаризации. Мало того, так как нам заранее известно, что проволочки будут примерно вертикально, то я решил сделать дополнительный фильтр: если в выбранном окне значимых выбросов больше, чем 1/2 вертикального размера окна, то всю вертикальную полосу выбираем как область интереса для дальнейшего анализа (забегая вперед скажу, что еще добавил дополнительный статистический детектор для выбросов, которые в несколько раз превышают стандартное отклонение — это понадобилось, чтобы всякие буквы и цифры на кадре тоже попали целиком в область дальнейшего анализа, где их можно было бы отфильтровать. Без этого очень много ложных срабатываний было из-за частичного нахождения областей на буквах и цифрах).
Вот что получилось на этом этапе:
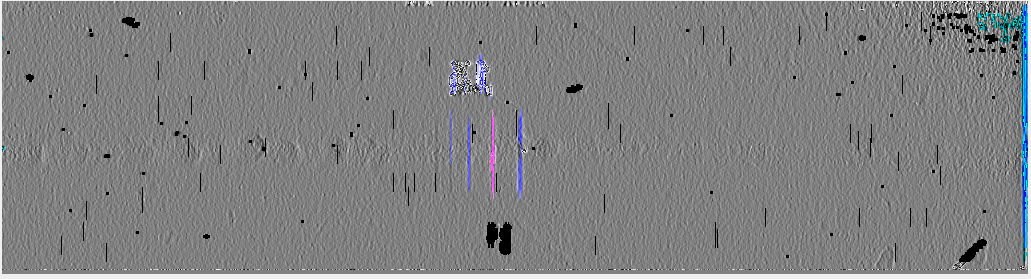
Здесь синим, розовым и черным цветами обозначены полученные области интереса. Розовым выделен текущий кластер для которого производится распознание.
С предварительной обработкой справились, надо переходить непосредственно к распознанию эталонов.
Первый шаг тут — кластеризация. Нужно как-то разбить все найденные точки на кластеры, чтобы потом уже работать с ними.
Тут довольно хорошо подошел вариант просто добавлять к текущему кластеру все новые точки, если они расположены +-2 пикселя по вертикали/горизонтали.
В принципе, этот метод может подвести, если сварной шов разбивает проволочку на две разнесенные области, поэтому был предусмотрен второй вариант кластеризации, когда просматривалось +15 точек по вертикали.
Тут опять же возможны разные варианты.
Поскольку кластеры уже выделены, можно было бы взять их и попытаться в изначальную картинку вписать рассчитанные варианты эталонов с разными углами, масштабами, сдвигами… Но как оказалось, это опять же довольно трудозатратно и можно придумать велосипед.
А именно: раз у нас почти вертикальные полоски, давайте просто вдоль них сделаем проекцию даже не изначальной картинки и не карты градиентов, а найденных кластеров. Этого оказалось достаточно, чтобы определить какой именно эталон на снимке, если есть кластеры, соответсвующие хотя бы трем проволочкам.
На самом деле, я пробовал делать проекции и по изначальной картинке и по карте градиентов, но там шум был довольно сильный, а так как мы уже с ним успешно поборолись при поиске кластеров, то можно просто воспользоваться полученными результатами.
Все это привело к следующему алгоритму:
1. для каждого эталона проверяем что длина кластера примерно соответствует длине проволочек эталона.
2. берем кластер, считаем проекцию вдоль него +-100-150 пикселей справа и слева, у нас образуется одномерный! массив с пиками в местах найденных кластеров.
То что массив одномерный сразу дает нам выигрыш в производительности, плюс не надо искать углы (проволочки-то параллельные).
3. для нескольких близких масштабов (нам масштаб известен только приближенно) вычисляем как будет выглядеть подобная проекция каждого эталона и делаем свертку полученной проекции эталона и проекции вдоль кластера + считаем сколько вообще пиков в проекции вдоль кластера есть.
4. если с обоих сторон от кластера имеются другие кластеры — мы в середине эталона, идем к следующему кластеру
5. если с обоих сторон ничего не обнаружено — мы скорее всего наткнулись на ложный кластер, образованный «артефактами»
6. если с одной стороны ничего нет, а с другой меньше двух пиков — это либо артефакты, либо проволочки слишком тонкие, в люом случае мы не сможем точно установить куда наш эталон повернут только по двум проволочкам
7. если с одной стороны больше 2ух пиков — проверяем, что свертка с эталонной проекцией дает ощутимый вклад.
сама свертка считалась так:
где WSKernel — эталонная проекция, которая имеет 1 в местах где есть проволочка и -1 где ее нет (т.е. имеет вид 1,1,1,1,1,1,-1,-1,-1,-1,1,1,1,...)
ltrtr — это собственно проекция вдоль кластера
tracemax — это максимум интенсивности проекции вдоль кластера
Все это работает так, чтобы в местах где пик есть и он совпадает с эталоном давать положительный вклад (-k*tracemax нужен чтобы штрафовать за ненахождение проволочки в нужном месте, k=0.1 оказалось наиболее продуктивным), а там где он есть, но не совпадает — отрицательный.
После прохода по нескольким масштабам и эталонам выбирается максимальный вклад и считается, что этот кластер соответствует этому эталону с вычисленным коэффициентом масштаба.
Дальше — только отрисовка и выдача результатов.
Ну и пара примеров:






На самом деле, это далеко не самый простой кадр, но в итоге даже на нем все нашлось:
Итак, какие же условия мне были озвучены:
– файлы будут tiff и могут быть довольно большими — больше 200 Мб
– изображения могут быть как позитивные, так и негативные
– на одной картинке могут быть несколько эталонов, надо найти все
– образцы лежат либо почти вертикально (+-10 градусов) или почти горизонтально
– на кадрах могут быть другие эталоны и прочие элементы
– швы могут быть как прямыми, так и эллиптическими, горизонтальными и вертикальными
– образец может лежать на шве или поблизости от него
Максимальное время поиска эталонов на снимке:
– 3 секунды для снимка размером меньше 100 МБ
– 5 секунд для снимка больше 100 МБ и меньше 200 МБ
– 10 секунд, для снимка размером больше 200 МБ.
Так же мне были даны ГОСТы двух типов эталонов, которые выглядили как-то так:
Т.е. каждый эталон состоит из 7 проволочек определенной длины и уменьшающегося диаметра расположенных на заданных расстояних.
Длины бывают разные: 10, 20, 25, 50 мм.
Для каждой длины есть набор эталонов с различными толщинами проволочек, например, один эталон с длиной проволочек 25 мм имеет диаметры проволочек 3.2мм, 2.5мм, 2мм, 1.6мм, 1.25мм, 1.0мм, 0.8мм, 0.63мм, а другой — 1.0мм, 0.8мм, 0.63мм, 0.5мм, 0.4мм, 0.32мм, 0.25мм.
Всего таким образом было порядка 16 эталонов.
Таким образом, мне надо было локализовать полностью детерминированные объекты на изображениях различного качества.
Выбор пути
Мне сразу подумалось об использовании обучаемых классификаторов, но смутил тот факт, что у меня было всего 82 файла с различными эталонами, а для нормального треннинга классификатора все-таки нужны тысячи изображений. Так что этот путь пришлось отмести сразу.
Задача поиска линейных отрезков сама по себе неплохо отражена в литературе.
Первое же что приходит в голову это искать отрезки преобразованием Хафа, но, во-первых, оно очень ресурсоемкое, а во-вторых, слабые сигналы среди более сильных после преобразования будет искать ничуть не легче. Даже если взять довольно удачное кадрирование:
то найти проволочки все равно довольно затруднительно:
( вот как оно должно было бы выглядеть:
-> )Другой вариант был бы использовать фильтрации контуров, но возникает проблема: а как выбирать порог бинаризации в автоматическом режиме?
Да и что делать с контурами, которые в основном выбирают сварной шов или что-то еще?
-> Детектор контуров с различными уровнями бинаризации
То же относится и к другим детекторам конутров типа бимлетов.
Что же можно сделать чтобы улучшить ситуацию?
Как оказалось, крайне продуктивным шагом было простое вычисление градиентной карты, т.е. просто вычисление разницы между двумя соседними пикселами. Подобный шаг резко выделяет острые края и практически стирает все медленные переходы. Вот что, например, получилось после применения градиентов дважды:
было:
стало:
На нижней картинке для наглядности повышен контраст.
Согласитесь, даже невооруженным глазом стало гораздо легче найти проволочки.
Тут же сразу стала видна и другая проблема — шум.Причем уровень шума неравномерен по картинке.
Как же нам выделять области интереса для более детальной проработки? Необходим какой-то метод, который учитывал бы локальный уровень шума и детектирвал выбросы, значительно превосходящие среднесатитстическое отклонение.
Так как вся геометрия эталонов нам известна заранее, то мы можем выбрать размер окна в котором будет собираться локальная статистика, тем самым мы сможем автоматизировать выбор порога бинаризации. Мало того, так как нам заранее известно, что проволочки будут примерно вертикально, то я решил сделать дополнительный фильтр: если в выбранном окне значимых выбросов больше, чем 1/2 вертикального размера окна, то всю вертикальную полосу выбираем как область интереса для дальнейшего анализа (забегая вперед скажу, что еще добавил дополнительный статистический детектор для выбросов, которые в несколько раз превышают стандартное отклонение — это понадобилось, чтобы всякие буквы и цифры на кадре тоже попали целиком в область дальнейшего анализа, где их можно было бы отфильтровать. Без этого очень много ложных срабатываний было из-за частичного нахождения областей на буквах и цифрах).
Вот что получилось на этом этапе:
Здесь синим, розовым и черным цветами обозначены полученные области интереса. Розовым выделен текущий кластер для которого производится распознание.
С предварительной обработкой справились, надо переходить непосредственно к распознанию эталонов.
Первый шаг тут — кластеризация. Нужно как-то разбить все найденные точки на кластеры, чтобы потом уже работать с ними.
Тут довольно хорошо подошел вариант просто добавлять к текущему кластеру все новые точки, если они расположены +-2 пикселя по вертикали/горизонтали.
В принципе, этот метод может подвести, если сварной шов разбивает проволочку на две разнесенные области, поэтому был предусмотрен второй вариант кластеризации, когда просматривалось +15 точек по вертикали.
Распознавание эталонов
Тут опять же возможны разные варианты.
Поскольку кластеры уже выделены, можно было бы взять их и попытаться в изначальную картинку вписать рассчитанные варианты эталонов с разными углами, масштабами, сдвигами… Но как оказалось, это опять же довольно трудозатратно и можно придумать велосипед.
А именно: раз у нас почти вертикальные полоски, давайте просто вдоль них сделаем проекцию даже не изначальной картинки и не карты градиентов, а найденных кластеров. Этого оказалось достаточно, чтобы определить какой именно эталон на снимке, если есть кластеры, соответсвующие хотя бы трем проволочкам.
На самом деле, я пробовал делать проекции и по изначальной картинке и по карте градиентов, но там шум был довольно сильный, а так как мы уже с ним успешно поборолись при поиске кластеров, то можно просто воспользоваться полученными результатами.
Все это привело к следующему алгоритму:
1. для каждого эталона проверяем что длина кластера примерно соответствует длине проволочек эталона.
2. берем кластер, считаем проекцию вдоль него +-100-150 пикселей справа и слева, у нас образуется одномерный! массив с пиками в местах найденных кластеров.
То что массив одномерный сразу дает нам выигрыш в производительности, плюс не надо искать углы (проволочки-то параллельные).
3. для нескольких близких масштабов (нам масштаб известен только приближенно) вычисляем как будет выглядеть подобная проекция каждого эталона и делаем свертку полученной проекции эталона и проекции вдоль кластера + считаем сколько вообще пиков в проекции вдоль кластера есть.
4. если с обоих сторон от кластера имеются другие кластеры — мы в середине эталона, идем к следующему кластеру
5. если с обоих сторон ничего не обнаружено — мы скорее всего наткнулись на ложный кластер, образованный «артефактами»
6. если с одной стороны ничего нет, а с другой меньше двух пиков — это либо артефакты, либо проволочки слишком тонкие, в люом случае мы не сможем точно установить куда наш эталон повернут только по двум проволочкам
7. если с одной стороны больше 2ух пиков — проверяем, что свертка с эталонной проекцией дает ощутимый вклад.
сама свертка считалась так:
if (WSKernel[i] == 1) { // punish more if there is no line: convlft += WSKernel[i] * (ltrtr[lngth - i] - k * tracemax); //ltrtr is always positive as a sum of presences of clusters convrgt += WSKernel[i] * (ltrtr[lngth + i] - k * tracemax); } else // WSKernel[[i]]==-1 { convlft += WSKernel[i] * ltrtr[lngth - i]; convrgt += WSKernel[i] * ltrtr[lngth + i]; }
где WSKernel — эталонная проекция, которая имеет 1 в местах где есть проволочка и -1 где ее нет (т.е. имеет вид 1,1,1,1,1,1,-1,-1,-1,-1,1,1,1,...)
ltrtr — это собственно проекция вдоль кластера
tracemax — это максимум интенсивности проекции вдоль кластера
Все это работает так, чтобы в местах где пик есть и он совпадает с эталоном давать положительный вклад (-k*tracemax нужен чтобы штрафовать за ненахождение проволочки в нужном месте, k=0.1 оказалось наиболее продуктивным), а там где он есть, но не совпадает — отрицательный.
После прохода по нескольким масштабам и эталонам выбирается максимальный вклад и считается, что этот кластер соответствует этому эталону с вычисленным коэффициентом масштаба.
Дальше — только отрисовка и выдача результатов.
Ну и пара примеров:

