

Не прошло и года, как я добрался до продолжения статьи про асинхронность. Эта статья развивает идеи той, самой первой статьи про асинхронность [1]. В ней обсуждается достаточно сложная задача, на примере которой будет раскрыта мощь и гибкость использования сопрограмм в различных нетривиальных сценариях. В заключение будут рассмотрены две задачи на состояние гонки (race-condition), а также небольшой, но очень приятный бонус.
За всё это время первая статья уже выбилась в поисковый топ.
Итак, поехали!

Задача
Изначальная формулировка незамысловата и звучит так:
Получить тяжелый объект по сети и передать его в UI.
Будем усложнять задачу, добавив «интересные» требования на UI:
- Действие порождается из UI-потока через какое-либо событие.
- Результат нужно возвратить обратно в UI.
- Мы не хотим блокировать UI, поэтому операцию необходимо производить асинхронно.
Добавим «веселые» условия на получение объекта:
- Операции с сетью медленные, поэтому объект будем кешировать.
- Хочется иметь персистентный кеш, чтобы после рестарта объекты сохранялись.
- Персистентное устройство медленное, поэтому для более быстрой отдачи объектов будем дополнительно кешировать их в памяти.
Займемся аспектами производительности:
- Хочется иметь параллельную, а не последовательную запись в кеши (персистентное хранилище и память).
- Чтение из кешей должно быть также параллельным, при этом если значение найдено в одном из кешей, то сразу использовать его, не дожидаясь ответа от другого кеша.
- Сетевые операции не должны никоим образом интерферировать с кешами, то есть если, например, кеши тупят, то это не должно сказываться на сетевых взаимодействиях.
- Хочется поддерживать большое количество соединений в ограниченном количестве потоков, то есть хочется асинхронного сетевого взаимодействия для более бережного отношения к ресурсам.
Усугубим логикой:
- Нам потребуется отмена операций.
- При этом если мы получили-таки по сети наш объект, то дальше отмена не должна применяться на последующие операции по обновлению кеша, то есть необходимо реализовать «отмену отмены» на некоторую совокупность действий.
Если кому-то показалось недостаточно хардкорно, то добавим еще требований:
- Необходимо реализовать таймауты на операции. Причем таймауты должны быть как на всю операцию, так и на некоторые части. Например:
- таймаут на все сетевое взаимодействие: соединение, запрос, ответ;
- таймаут на всю операцию, включая сетевое взаимодействие и работу с кешами.
- Планировщики операций могут быть как свои собственные, так и инородные (например, планировщик в UI-потоке).
- Никакие операции не должны блокировать потоки. Это означает, что запрещено использование мьютексов и других средств синхронизации, так как они будут блокировать наши потоки.

Вот теперь достаточно. Если у кого-то сразу появился ответ, как это сделать, то я с удовольствием познакомлюсь с таким решением. Ну а ниже я предлагаю свое решение: понятно, что в нем акцент будет делаться не на реализацию, например, кешей и персистентности, а на конкретное параллельное и асинхронное взаимодействие с учетом требования к блокировкам и планировщикам.
Решение
Для решения будем использовать следующую модель.
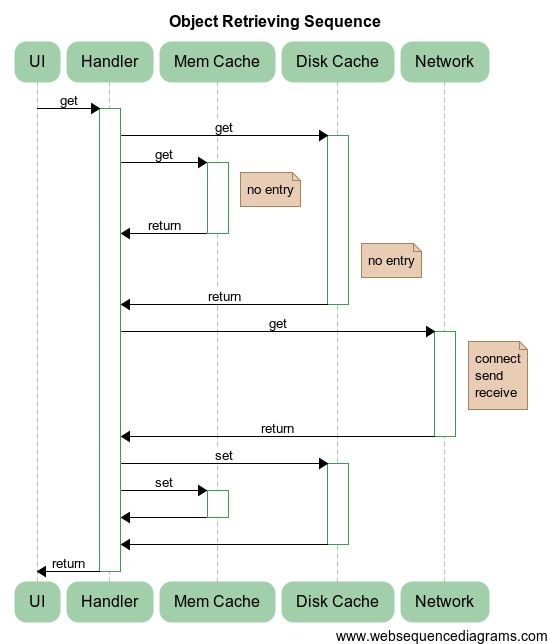
Опишу суть происходящего:
UI,Mem Cache,Disk Cache,Networkсуть объекты, которые выполняют соответствующие операции над нашим свежесозданным обработчикомHandler.Handlerвыполняет нехитрую последовательность:
- Параллельно запускает операцию получения данных из кешей объектов
Mem CacheиDisk Cache. В случае успеха, то есть при получении ответа с найденным результатом хотя бы из одного кеша, сразу возвращает результат. А в случае неуспеха (как на диаграмме) выполнение продолжается. - После ожидания отсутствия результата от обоих кешей
Handlerобращается кNetworkдля получения объекта по сети. Для этого происходит подключение к сервису (connect), отправка запроса (send) и получение ответа (receive). Такие операции выполняются асинхронно и не блокируют другие сетевые взаимодействия. - Полученный от компонента
Networkобъект записывается параллельно в оба кеша. - После ожидания завершения записи в кеши происходит возврат значения в UI-поток.
- Параллельно запускает операцию получения данных из кешей объектов
- В программе присутствуют следующие планировщики и ассоциированные с ними объекты:
- UI-поток, который инициирует асинхронную операцию
Handlerи в который должен вернуться результат; - общий пул потоков, в котором выполняются все основные операции, включая
Mem CacheиDisk Cache; - сетевой пул потоков для
Network. Создается отдельно от основного пула потоков для того, чтобы загруженность основного пула не влияла на сетевой пул потоков.
- UI-поток, который инициирует асинхронную операцию
Как я уже писал ранее, объекты будем реализовывать простейшим способом, так как для аспектов асинхронности это не имеет особого значения:
// stub: дисковый кеш
struct DiskCache
{
boost::optional<std::string> get(const std::string& key)
{
JLOG("get: " << key);
return boost::optional<std::string>();
}
void set(const std::string& key, const std::string& val)
{
JLOG("set: " << key << ";" << val);
}
};
// кеш в памяти: хеш-таблица
struct MemCache
{
boost::optional<std::string> get(const std::string& key)
{
auto it = map.find(key);
return it == map.end()
? boost::optional<std::string>()
: boost::optional<std::string>(it->second);
}
void set(const std::string& key, const std::string& val)
{
map[key] = val;
}
private:
std::unordered_map<std::string, std::string> map;
};
struct Network
{
// ...
// получение объекта по сети
std::string get(const std::string& key)
{
net::Socket socket;
JLOG("connecting");
socket.connect(address, port);
// первый байт - размер строки
Buffer sz(1, char(key.size()));
socket.write(sz);
// затем - строка
socket.write(key);
// получаем размер результата
socket.read(sz);
Buffer val(size_t(sz[0]), 0);
// получаем сам результат
socket.read(val);
JLOG("val received");
return val;
}
private:
std::string address;
int port;
// ...
};
// UI-объект: взаимодействие с UI
struct UI : IScheduler
{
void schedule(Handler handler)
{
// запуск операции в UI-потоке
// ...
}
void handleResult(const std::string& key, const std::string& val)
{
TLOG("UI result inside UI thread: " << key << ";" << val);
// TODO: add some actions
}
};
Как правило, все UI-фрейворки содержат метод, который позволяет запускать в UI-потоке необходимые действия (например, в Android:
Activity.runOnUiThread, Ultimate++: PostCallback, Qt: через signal-slot механизм). Эти методы и должны быть использованы в реализации метода UI::schedule.Инициализация всего хозяйства происходит в императивном стиле:
// создаем пул потоков для общих действий
ThreadPool cpu(3, "cpu");
// создаем пул потоков для сетевых действий
ThreadPool net(2, "net");
// планировщик для сериализации действий с диском
Alone diskStorage(cpu, "disk storage");
// планировщик для сериализации действий с памятью
Alone memStorage(cpu, "mem storage");
// задание планировщика по умолчанию
scheduler<DefaultTag>().attach(cpu);
// привязка сетевого сервиса к сетевому пулу
service<NetworkTag>().attach(net);
// привязка обработки таймаутов к общему пулу
service<TimeoutTag>().attach(cpu);
// привязка дискового портала к дисковому планировщику
portal<DiskCache>().attach(diskStorage);
// привязка портала памяти к соответствующему планировщику
portal<MemCache>().attach(memStorage);
// привязка сетевого портала к сетевому пулу
portal<Network>().attach(net);
UI& ui = single<UI>();
// привязка UI-портала к UI-планировщику
portal<UI>().attach(ui);
В UI-потоке на некоторое действие пользователя выполняем:
go([key] {
// timeout для всех операций: 1с=1000 мс
Timeout t(1000);
std::string val;
// получить результат из кешей параллельно
boost::optional<std::string> result = goAnyResult<std::string>({
[&key] {
return portal<DiskCache>()->get(key);
}, [&key] {
return portal<MemCache>()->get(key);
}
});
if (result)
{
// результат найден
val = std::move(*result);
JLOG("cache val: " << val);
}
else
{
// кеши не содержат результата
// получаем объект по сети
{
// таймаут на сетевую обработку: 0.5с=500 мс
Timeout tNet(500);
val = portal<Network>()->get(key);
}
JLOG("net val: " << val);
// начиная с этого момента и до конца блока
// отмена (и таймауты) отключены
EventsGuard guard;
// параллельно записываем в оба кеша
goWait({
[&key, &val] {
portal<DiskCache>()->set(key, val);
}, [&key, &val] {
portal<MemCache>()->set(key, val);
}
});
JLOG("cache updated");
}
// переходим в UI и обрабатываем результат
portal<UI>()->handleResult(key, val);
});

Реализация используемых примитивов
Как заметил внимательный читатель, я использовал немалое количество примитивов, о реализации которых можно только догадываться. Поэтому ниже приведено описание подхода и используемых классов. Думаю, это прояснит, что же такое порталы, как их использовать, а также ответит на вопрос о телепортациях.

Ожидающие примитивы
Начнем с самого простого – ожидающих примитивов.
goWait: запуск асинхронной операции и ожидание завершения
Итак, для затравки реализуем функцию, которая будет асинхронно запускать операцию и ожидать ее завершения:
void goWait(Handler);
Конечно, в качестве реализации вполне подойдет запуск обработчика в текущей сопрограмме. Но в более сложных сценариях нас это не устроит, поэтому для реализации этой функции будем создавать новую сопрограмму:
void goWait(Handler handler) {
deferProceed([&handler](Handler proceed) {
go([proceed, &handler] { // создаем новую сопрограмму
handler();
proceed(); // продолжаем выполнение сопрограммы
});
});
}
Опишу вкратце, что тут происходит. На вход функции goWait мы получаем обработчик, который должен быть запущен в новой сопрограмме. Для выполнения необходимых операций мы используем функцию
deferProceed, которая реализована следующим образом:typedef std::function<void(Handler)> ProceedHandler;
void deferProceed(ProceedHandler proceed) {
auto& coro = currentCoro();
defer([&coro, proceed] {
proceed([&coro] { coro.resume(); });
});
}
Что делает эта функция? Она фактически оборачивает вызов defer для более удобного использования (что такое
defer и почему его нужно использовать, описано в моей предыдущей статье), а именно: она принимает не Handler, а ProceedHandler, в который в качестве входного параметра передается Handler для продолжения выполнения сопрограммы. Собственно, сам proceed сохраняет в своем объекте ссылку на текущую сопрограмму и вызывает coro.resume(). Таким образом мы инкапсулируем всю работу с сопрограммами, и пользователю нужно работать только с proceed-обработчиком.Возвращаемся к функции
goWait. Итак, при вызове deferProceed у нас есть proceed, который необходимо позвать по окончании операции в handler. Все, что нам остается сделать, это создать новую сопрограмму, запустить в ней наш обработчик handler, а после его завершения сразу позвать proceed, который внутри себя позовет coro.resume(), продолжив тем самым выполнение исходной сопрограммы.Это дает нам ожидание без блокировки потока: во время вызова
goWait мы как бы ставим наши операции в текущей сопрограмме на паузу, а когда завершится переданный обработчик, продолжим исполнение как ни в чем не бывало.goWait: запуск нескольких асинхронных операций и ожидание их завершения
Теперь реализуем функцию, которая запускает целую пачку асинхронных операций и ожидает их завершения:
void goWait(std::initializer_list<Handler> handlers);
На вход у нас подается список обработчиков, которые необходимо запустить асинхронно, то есть каждый обработчик запустится в своей сопрограмме. Существенное отличие от предыдущей функции в том, что нам необходимо продолжить выполнение исходной сопрограммы только после завершения всех обработчиков. Некоторые используют для этих целей всякие мьютексы и condition variables (и так действительно кое-кто реализовывает!), но нам так делать нельзя (см. требования), поэтому будем искать другие пути реализации.
Идея на самом деле достаточно тривиальна: необходимо завести счетчик, который по достижении определенного значения будет вызывать
proceed. Каждый обработчик по своем завершении будет обновлять счетчик, и таким образом последний из обработчиков продолжит выполнение исходной сопрограммы. Однако тут есть одна маленькая сложность: счетчик необходимо разделять между запущенными сопрограммами, и последний обработчик должен не только позвать proceed, но и удалить этот счетчик из памяти. Все это можно реализовать следующим образом:void goWait(std::initializer_list<Handler> handlers)
{
deferProceed([&handlers](Handler proceed) {
std::shared_ptr<void> proceeder(nullptr, [proceed](void*) { proceed(); });
for (const auto& handler: handlers)
{
go([proceeder, &handler] {
handler();
});
}
});
}
В самом начале мы запускаем старый добрый
deferProceed, а вот внутри него спрятана небольшая магия. Мало кто знает, что при конструировании shared_ptr можно передать не только указатель на данные, но и deleter, который будет удалять объект, вызывая не delete ptr, а обработчик. Собственно, туда-то мы и засунем вызов proceed, чтобы в конце продолжить исходную сопрограмму. При этом нет необходимости удалять сам объект, так как мы туда кладем «ничто» – nullptr. Дальше все просто: в цикле проходим по всем обработчикам и запускаем их в создаваемых сопрограммах. Тут тоже есть один нюанс: мы захватываем по значению наш proceeder, что будет приводить к его копированию, а значит, увеличению нашего атомарного счетчика ссылок внутри shared_ptr. После окончания работы handler наша лямбда с захваченным proceeder будет удаляться, что приведет к уменьшению счетчика. Кто последним уменьшит счетчик до нуля и удалит объект proceeder, тот и позовет deleter для разделяемого shared_ptr, то есть вызовет в конце концов coro.proceed().
Для большей ясности ниже приведена последовательность операций на примере запуска двух обработчиков в различных потоках:
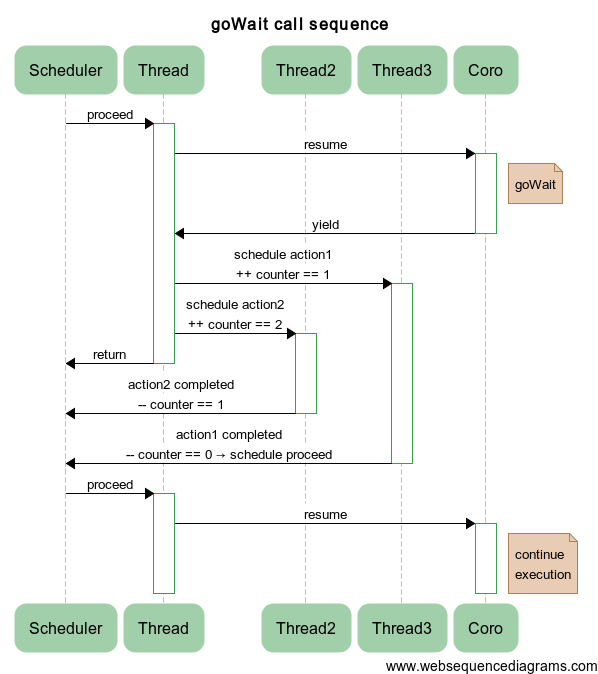
Пример: рекурсивно-параллельные числа Фибоначчи
Для иллюстрации использования рассмотрим следующий пример. Предположим, на нас нашла блажь и нам захотелось посчитать ряд Фибоначчи рекурсивно и параллельно. Нет проблем:
int fibo (int v)
{
if (v < 2)
return v;
int v1, v2;
goWait({
[v, &v1] { v1 = fibo(v-1); },
[v, &v2] { v2 = fibo(v-2); }
});
return v1 + v2;
}
Отмечу, что здесь никогда не будет переполнения стека: каждый вызов функции
fibo происходит в своей собственной сопрограмме.Waiter: запуск нескольких асинхронных операций и ожидание их завершения
Часто нам необходимо не просто дождаться фиксированного набора обработчиков, но и между делом сделать что-то полезное и только потом дождаться. Иногда мы вообще не знаем, какое количество обработчиков может понадобиться, то есть мы их создаем по ходу выполнения наших операций. Фактически нам необходимо оперировать с группой обработчиков как единым целым. Для этого можно использовать примитив
Waiter со следующим интерфейсом:struct Waiter
{
Waiter& go(Handler);
void wait();
};
Тут всего два метода:
- go: запустить еще один обработчик;
- wait: дождаться всех запущенных обработчиков.
Запускать вышеуказанные методы можно несколько раз за все время жизни объекта
Waiter.Идея реализации ровно такая же: необходимо иметь
proceeder, который продолжал бы работу нашей сопрограммы. Однако добавляется небольшая тонкость: теперь proceeder разделяется между запущенными сопрограммами и объектом Waiter. Соответственно, в момент вызова метода wait нам необходимо избавиться от копии в самом Waiter. Вот как это можно сделать:void Waiter::wait()
{
if (proceeder.unique())
{
// только Waiter владеет proceeder =>
JLOG("everything done, nothing to do");
return;
}
defer([this] {
// перемещаем proceeder в область вне сопрограммы
auto toDestroy = std::move(proceeder);
// разделяемый proceeder удалится либо здесь,
// либо в какой-либо сопрограмме обработчика
});
// proceeder в этот момент был удален,
// восстановим его снова для последующего использования
init0();
}
И опять ничего не нужно делать! Спасибо за это
shared_ptr. Аминь!
Пример: рекурсивно-параллельные числа Фибоначчи
Для закрепления материала рассмотрим альтернативную реализацию нашей блажи с использованием
Waiter:int fibo (int v)
{
if (v < 2)
return v;
int v1;
Waiter w;
w.go([v, &v1] { v1 = fibo(v-1); });
int v2 = fibo(v-2);
w.wait();
return v1 + v2;
}
Еще вариант:
int fibo (int v)
{
if (v < 2)
return v;
int v1, v2;
Waiter()
.go([v, &v1] { v1 = fibo (v-1); })
.go([v, &v2] { v2 = fibo (v-2); })
.wait();
return v1 + v2;
}
Выбирай не хочу.
goAnyWait: запуск нескольких асинхронных операций и ожидание завершения хотя бы одной
По-прежнему будем запускать несколько операций одновременно. Но ожидать мы будем ровно до тех пор, пока не завершится хотя бы одна операция:
size_t goAnyWait(std::initializer_list<Handler> handlers);
На вход у нас подается список обработчиков, на выходе – номер обработчика, который завершился первым.
Для реализации этого примитива немного модернизируем наш подход. Теперь мы будем разделять не
void* ptr == nullptr, а вполне себе конкретный атомарный счетчик counter. В самом начале он инициализирован значением 0. Каждый обработчик в конце своей работы увеличивает счетчик. И если вдруг оказалось, что произошло изменение значения с 0 до 1, то он и только он вызывает proceed():size_t goAnyWait(std::initializer_list<Handler> handlers)
{
VERIFY(handlers.size() >= 1, "Handlers amount must be positive");
size_t index = static_cast<size_t>(-1);
deferProceed([&handlers, &index](Handler proceed) {
std::shared_ptr<std::atomic<int>> counter =
std::make_shared<std::atomic<int>>();
size_t i = 0;
for (const auto& handler: handlers)
{
go([counter, proceed, &handler, i, &index] {
handler();
if (++ *counter == 1)
{
// ага, попался!
index = i;
proceed();
}
});
++ i;
}
});
VERIFY(index < handlers.size(), "Incorrect index returned");
return index;
}
Как нетрудно догадаться, этот фокус можно использовать также для случаев, когда нужно дождаться двух, трех и более обработчиков.
goAnyResult: запуск нескольких асинхронных операций и ожидание получения хотя бы одного результата
Теперь перейдем к самому вкусному, что, собственно, и необходимо для нашей задачи. А именно: запустить несколько операций и дождаться нужного нам результата. При этом любой обработчик может и не вернуть результат. То есть работу свою он доделает, но при этом скажет: «Ну не шмогла я, не шмогла».
При таком подходе появляется дополнительная сложность. Ведь все обработчики могут завершить работу, а результат мы так и не получим. Поэтому придется, во-первых, каким-то образом в конце всех операций проверять, получили ли мы нужный результат, а во-вторых, возвращать «пустой» результат. Для сигнализации пустоты будем использовать
boost::optional<T_result>, при этом goAnyResult получается с таким вот незамысловатым прототипом:template<typename T_result>
boost::optional<T_result> goAnyResult(
std::initializer_list<
std::function<
boost::optional<T_result>()
>
> handlers)
Ничего страшного тут нет: мы просто передаем список обработчиков, которые опционально возвращают наш
T_result. То есть обработчики должны иметь сигнатуру:boost::optional<T_result> handler();
Ситуация по сравнению с предыдущим примитивом лишь слегка модифицируется. Счетчик остается тот же самый, только теперь при его уничтожении необходимо проверить
counter, и если при его увеличении мы получили 1, то необходимо вернуть «пустое» значение, так как никто до этого не смог передернуть счетчик и вернуть необходимый результат. Таким образом, вместо простого атомарного значения для counter мы имеем целый объект Counter:template<typename T_result>
boost::optional<T_result> goAnyResult(
std::initializer_list<
std::function<
boost::optional<T_result>()
>
> handlers)
{
typedef boost::optional<T_result> Result;
typedef std::function<void(Result&&)> ResultHandler;
struct Counter
{
Counter(ResultHandler proceed_) : proceed(std::move(proceed_)) {}
~Counter()
{
tryProceed(Result()); // в деструкторе продолжаем по-любому
}
void tryProceed(Result&& result)
{
if (++ counter == 1)
proceed(std::move(result));
}
private:
std::atomic<int> counter;
ResultHandler proceed;
};
Result result;
deferProceed([&handlers, &result](Handler proceed) {
std::shared_ptr<Counter> counter = std::make_shared<Counter>(
[&result, proceed](Result&& res) {
result = std::move(res);
proceed();
}
);
for (const auto& handler: handlers)
{
go([counter, &handler] {
Result result = handler();
if (result) // пытаемся продолжить только при наличии результата
counter->tryProceed(std::move(result));
});
}
});
return result;
}
Интрига тут состоит в том, что
std::move перемещает результат только тогда, когда условие внутри tryProceed выполняется. А все потому, что std::move не выполняет перемещение как таковое, как бы кому-то этого ни хотелось. Это всего лишь cast-операция над ссылками.С ожиданиями разобрались, переходим к планировщикам и пулам потоков.
Планировщик, пулы, синхронизация
Интерфейс планировщика
После рассмотрения, так сказать, базовых основ, переходим к десерту.
Введем интерфейс планировщика:
struct IScheduler : IObject
{
virtual void schedule(Handler handler) = 0;
};
Его задача – исполнять обработчики. Обратите внимание, что у интерфейса планировщика нет ни отмен, ни таймаутов, ни отложенных операций. Интерфейс планировщика должен быть кристально чистым, чтобы его можно было легко состыковать с различными фреймворками (ср. с [2]: тут тебе и отмена, и акторы, и задержки, будет очень удобно скрещивать с UI-планировщиками).

Пул потоков
Нам потребуется пул потоков для выполнения различных действий, реализующий интерфейс планировщика:
typedef boost::asio::io_service IoService;
struct IService : IObject
{
virtual IoService& ioService() = 0;
};
struct ThreadPool : IScheduler, IService
{
ThreadPool(size_t threadCount);
void schedule(Handler handler)
{
service.post(std::move(handler));
}
private:
IoService& ioService();
std::unique_ptr<boost::asio::io_service::work> work;
boost::asio::io_service service;
std::vector<std::thread> threads;
};
Что мы тут имеем?
- Конструктор, в котором задаем количество потоков.
- Реализацию интерфейса планировщика с использованием
boost::asio::io_service::post. - Член класса
work, который удерживает цикл событийio_service, так как в противном случае при отсутствии событий цикл завершит свою работу и потоки схлопнутся. - Массив потоков.
Помимо этого, наш класс реализует (причем приватно) некий мутный интерфейс
IService с методом ioService, который возвращает IoService, который есть boost::asio::io_service. Выглядит все это странно, но я сейчас попытаюсь объяснить, в чем тут фишка.Дело в том, что для работы с сетевыми сокетами и таймаутами нам необходим расширенный интерфейс планировщика. Этот интерфейс на самом деле спрятан внутри
boost::asio::io_service. Остальные компоненты, которые я буду использовать в дальнейшем, должны каким-то образом получать доступ к экземпляру boost::asio::io_service. Чтобы предотвратить простой доступ к этому классу, я ввел интерфейс IService, позволяющий получать заветный экземпляр. Однако в реализации метод сделан приватным. Это обеспечивает некоторый уровень защиты от неправильного использования, так как, чтобы вытащить этот объект наружу, сначала потребуется преобразовать ThreadPool в IService, а затем позвать нужный метод. Альтернативой было бы использование дружеских классов. Но я не хотел портить ThreadPool знаниями о возможных вариантах использования, поэтому посчитал, что применяемый подход является разумной платой за инкапсуляцию.Класс сопрограммы
После введения пула потоков и планировщика настала очередь ввести класс для манипуляций над сопрограммами. Называться он будет, как это ни странно,
Journey (почему так, будет ясно позже):struct Journey
{
void proceed();
Handler proceedHandler();
void defer(Handler handler);
void deferProceed(ProceedHandler proceed);
static void create(Handler handler, mt::IScheduler& s);
private:
Journey(mt::IScheduler& s);
struct CoroGuard
{
CoroGuard(Journey& j_) : j(j_) { j.onEnter0(); }
~CoroGuard() { j.onExit0(); }
coro::Coro* operator->() { return &j.coro; }
private:
Journey& j;
};
void start0(Handler handler);
void schedule0(Handler handler);
CoroGuard guardedCoro0();
void proceed0();
void onEnter0();
void onExit0();
mt::IScheduler* sched;
coro::Coro coro;
Handler deferHandler;
};
Что тут бросается в глаза?
- Приватный конструктор. Он вызывается статическим публичным методом
create. Journeyсодержит внутри себя указатель на планировщикsched, саму сопрограммуcoroиdeferHandler-обработчик, который вызывается внутриdefer.CoroGuard– прокси-класс, который при каждой операции над сопрограммой автоматически выполняет действияonEnter0при входе в нее иonExit0при выходе.
Чтобы понять, как это работает, посмотрим на реализацию нескольких простых методов:
void Journey::schedule0(Handler handler)
{
VERIFY(sched != nullptr, "Scheduler must be set in journey");
sched->schedule(std::move(handler));
}
void Journey::proceed0()
{
// используем защитник для продолжения сопрограммы
guardedCoro0()->resume();
}
Journey::CoroGuard Journey::guardedCoro0()
{
return CoroGuard(*this);
}
// возврат в сопрограмму можно делать только с использованием планировщика
void Journey::proceed()
{
schedule0([this] {
proceed0();
});
}
// тот самый обработчик, который возвращает управление сопрограмме
Handler Journey::proceedHandler()
{
return [this] {
proceed();
};
}
// запуск новой сопрограммы
// см. также задачу 1
void Journey::start0(Handler handler)
{
schedule0([handler, this] {
// снова используем защитник
guardedCoro0()->start([handler] {
JLOG("started");
// не забывает про исключения
try
{
handler();
}
catch (std::exception& e)
{
(void) e;
JLOG("exception in coro: " << e.what());
}
JLOG("ended");
});
});
}
Давайте теперь разберем работу defer:
void Journey::defer(Handler handler)
{
// запоминаем обработчик
deferHandler = handler;
// и выходим из текущей сопрограммы
coro::yield();
}
// deferProceed, используемый ранее
void Journey::deferProceed(ProceedHandler proceed)
{
defer([this, proceed] {
proceed(proceedHandler());
});
}
Все просто! Осталось понять, где же запускаются наши отложенные обработчики
deferHandler.TLS Journey* t_journey = nullptr;
void Journey::onEnter0()
{
t_journey = this;
}
// см. также задачу 2
void Journey::onExit0()
{
if (deferHandler == nullptr)
{
// нет обработчика => действия завершены, можно самоликвидироваться
delete this;
}
else
{
// в противном случае выполняем отложенное действие
deferHandler();
deferHandler = nullptr;
}
// восстанавливаем значение, так как теперь находимся вне сопрограммы
t_journey = nullptr;
}
Ну и напоследок рассмотрим реализацию статической функции
create:void Journey::create(Handler handler, mt::IScheduler& s)
{
(new Journey(s))->start0(std::move(handler));
}
Стоит отметить, что пользователь не имеет никакой возможности явного создания
Journey, то есть он вообще не подозревает о том, что есть такой класс. Но об этом чуть позже, а сейчас…Телепортация
Наконец переходим к клубничке! Телепортация… Речь пойдет про примитив, который возможно реализовать только с использованием сопрограмм. А этот примитив настолько мощный и настолько простой, что стоит на нем остановиться поподробнее и посмаковать. Ведь это ж клубничка!
Проще всего начать обсуждение с реализации:
void Journey::teleport(mt::IScheduler& s)
{
if (&s == sched)
{
JLOG("the same destination, skipping teleport <-> " << s.name());
return;
}
JLOG("teleport " << sched->name() << " -> " << s.name());
sched = &s;
defer(proceedHandler());
}
Тут делаются две вещи:
- Проверяется, отличается ли планировщик сопрограммы от того планировщика, который подали на вход метода. Если он совпадает с ним, то ничего делать не надо, планировщик и так нужный.
- Если отличается, то происходит смена планировщика сопрограммы и перевхождение в сопрограмму:
deferвыполняет функцию, которая приводит к выходу из сопрограммы и запуску обработчика для скорейшего продолжения сопрограммы. Однако для возврата будет использоваться новый планировщик, поэтому вход в сопрограмму произойдет уже в новом пуле потоков.

Схема ниже поясняет процесс переключения исполнения сопрограммы с
Scheduler/Thread на Scheduler2/Thread2: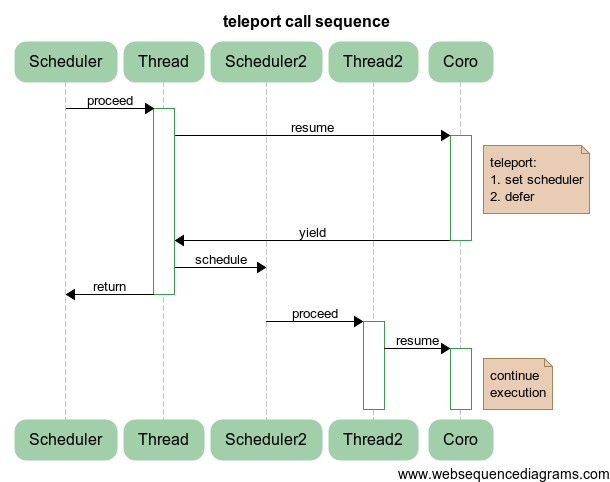
Что это нам дает? На самом деле это дает переключение между пулами потоков, а также, вообще говоря, между планировщиками. В частности, можно переключаться между UI-потоком и потоками вычислений, чтобы UI, что называется, не тупил:
auto result = someCalculations();
teleport(uiScheduler);
showResult(result);
teleport(calcScheduler);
auto newResult = continueSmartCalculations(result);
teleport(uiScheduler);
updateResult(newResult);
//…
То есть, для того чтобы сходить в UI, нужно всего лишь телепортироваться в нужный поток, и все будет потокобезопасно в соответствии с требованиями разработки UI-приложений. Тот же самый прием можно применить, если нам нужно сходить, например, в сетевой пул потоков или пул потоков базы данных – в общем, в любое место, где можно воспользоваться интерфейсом планировщика.
Порталы

Теперь можно переходить к вишенке. Я бы даже сказал, к сладкой и сочной черешенке. Как вы уже успели заметить, для обновления состояния UI-приложения нам потребовалось сделать телепортацию сначала в UI-планировщик, а затем обратно. Для того чтобы каждый раз этого не делать, создадим портал, который произведет обратное возвращение автоматически, как только необходимое действие завершится.
struct Portal
{
Portal(mt::IScheduler& destination) :
source(journey().scheduler())
{
JLOG("creating portal " << source.name() << " <=> " << destination.name());
teleport(destination);
}
~Portal()
{
teleport(source);
}
private:
mt::IScheduler& source;
};
То есть в конструкторе мы запоминаем источник (текущий планировщик сопрограммы), а затем телепортируем сопрограмму в известное направление. В деструкторе происходит телепортация в исходный планировщик.
Благодаря такой RAII-идиоме не нужно беспокоиться о том, что мы внезапно можем оказаться не там, где ожидалось (например, не будем делать тяжелые вычисления в UI-потоке либо в сетевом пуле потоков), все будет делаться автоматически.
Давайте рассмотрим пример:
ThreadPool tp1(1, "tp1");
ThreadPool tp2(1, "tp2");
go([&tp2] {
Portal p(tp2);
JLOG("throwing exception");
throw std::runtime_error("exception occur");
}, tp1);
Сопрограмма стартует в tp1, затем создается портал и происходит переключение в tp2. После генерации исключения вызывается деструктор портала, который фактически замораживает раскрутку исключений, телепортирует в tp1 и продолжает сопрограмму, которая продолжит раскрутку исключения уже в другом потоке. Бесплатно и без СМС!

Для того чтобы еще более усугубить использование порталов (хотя, казалось бы, куда уж), навернем:
struct Scheduler
{
Scheduler();
void attach(mt::IScheduler& s)
{
scheduler = &s;
}
void detach()
{
scheduler = nullptr;
}
operator mt::IScheduler&() const
{
VERIFY(scheduler != nullptr, "Scheduler is not attached");
return *scheduler;
}
private:
mt::IScheduler* scheduler;
};
struct DefaultTag;
template<typename T_tag>
Scheduler& scheduler()
{
return single<Scheduler, T_tag>();
}
template<typename T>
struct WithPortal : Scheduler
{
struct Access : Portal
{
Access(Scheduler& s) : Portal(s) {}
T* operator->() { return &single<T>(); }
};
Access operator->() { return *this; }
};
template<typename T>
WithPortal<T>& portal()
{
return single<WithPortal<T>>();
}
Это позволяет нам привязывать порталы к классам, как в следующем примере:
ThreadPool tp1(1, "tp1");
ThreadPool tp2(1, "tp2");
struct X
{
void op() {}
};
portal<X>().attach(tp2);
go([] {
portal<X>()->op();
}, tp1);
В этом примере мы привязали портал
X к пулу потоков tp2. Таким образом, при каждом вызове метода единственного экземпляра класса X (используется в return &single<T>()) будет происходить переход сопрограммы в нужный нам пул потоков. Наш контекст исполнения Journey будет путешествовать туда-сюда, телепортируясь сквозь порталы используемых объектов!
Это дает нам возможность не следить за тем, где следует вызывать методы наших классов. Классы самостоятельно озаботятся переключением в нужный поток и возвращением обратно. Именно этот подход и использовался в самом начале при решении задачи. Это позволило достичь высокой ясности кода и использовать всю мощь сопрограмм, телепортаций и порталов.
Неблокирующие мьютексы
Для работы с разделяемыми ресурсами часто применяют мьютексы. Оно и понятно: такой примитив просто использовать и в большинстве случаев он себя оправдывает.
Но что происходит с мьютексом, когда кто-то уже захватил ресурс? В этом случае происходит ожидание на мьютексе до тех пор, пока ресурс не освободится. При этом поток блокируется и перестает выполнять полезную работу.
А чего бы нам хотелось? С точки зрения производительности нам бы хотелось, чтобы потоки были задействованы чуть более чем полностью, а не отвлекались на ожидания. «Будет исполнено», – ответила сопрограмма и самодовольно ухмыльнулась.
Реализовать неблокирующие мьютексы с использованием сопрограмм можно различными способами. Я применю элегантный способ, позволяющий повторно использовать уже имеющийся функционал с минимальным количеством добавлений. Для этого создадим новый планировщик:
struct Alone : mt::IScheduler
{
Alone(mt::IService& service);
void schedule(Handler handler)
{
strand.post(std::move(handler));
}
private:
boost::asio::io_service::strand strand;
};
В конструкторе класса
Alone в качестве входного параметра используется интерфейс IService, который позволяет нам корректно инициализировать io_service::strand из boost.asio. Фактически это еще один планировщик boost.asio, который гарантирует, что в одно и то же время будет запущено не более одного обработчика. Это как раз и соответствует нашим представлениям о том, что такое мьютекс (mutual exclusion).Так как идиома
Alone реализует интерфейс планировщика, мы без зазрения совести можем использовать всю мощь наших телепортаций и порталов, как будто так и надо.Для закрепления материала рассмотрим код:
struct MemCache
{
boost::optional<std::string> get(const std::string& key);
void set(const std::string& key, const std::string& val);
};
// инициализация
ThreadPool common_pool(3); // общий пул потоков
Alone mem_alone(common_pool); // сериализация действий с памятью
portal<MemCache>().Attach(mem_alone); // привязка портала для памяти
// теперь выполняем необходимые операции
auto value = portal<MemCache>()->get(key);
// или
portal<MemCache>()->set(anotherKey, anotherValue);
Доступ к объекту будет сериализован автоматически, при этом поток не будет блокироваться в случае параллельного доступа к объекту. Чудеса, да и только!

Внешние события
Конечно, хорошо жить в своей маленькой песочнице и выполнять операции независимо от окружающей среды. Но жизнь на наш непонятный идеализм смотрит свысока, периодически поплевывая. Поэтому нам не остается ничего другого, кроме как подтереться и идти дальше, невзирая на все тяготы и лишения.

Что же нас ожидает в асинхронном программировании? А то, что некоторые действия, сегодня кажущиеся непреложными, в следующий момент необходимо будет пересмотреть и внести коррективы (см. «отмена»). То есть мы хотим отменять наши действия в зависимости от текущей конъюнктуры.
Нужно не только учитывать изменчивые условия выполнения: необходимо иметь возможность реагировать на сетевые факторы – корректно обрабатывать таймауты. Конечно, хорошо, когда мы смогли получить результат, но если результат получен не вовремя, то он может оказаться не нужным. Раньше надо было! Что толку, что мы выучили предмет сегодня, если экзамен был вчера, а мы на него не явились?
Все эти требования ложатся тяжким бременем на существующие фреймворки. Поэтому, как правило, на эти требования забивают и потом уже огребают на продакшене, когда что-то висит, что-то тупит, ресурсы заняты, а действие уныло продолжается несмотря на бесполезность результата. Давайте попытаемся сделать подход к этой штанге.
Для начала введем типы внешних событий и ассоциированных исключений:
enum EventStatus
{
ES_NORMAL,
ES_CANCELLED,
ES_TIMEDOUT,
};
struct EventException : std::runtime_error
{
EventException(EventStatus s);
EventStatus status();
private:
EventStatus st;
};
Для управления сопрограммой извне (см. отмена) необходим некоторый объект, разделяющий состояние между вызывающим и вызываемым:
struct Goer
{
Goer();
EventStatus reset();
bool cancel();
bool timedout();
private:
struct State
{
State() : status(ES_NORMAL) {}
EventStatus status;
};
bool setStatus0(EventStatus s);
State& state0();
std::shared_ptr<State> state;
};
Тут все довольно тривиально: у нас есть умный указатель состояния, который мы можем изменять и проверять.
Далее в наш класс-путешественник
Journey добавим обработку событий:void Journey::handleEvents()
{
// может быть вызван из деструктора
if (!eventsAllowed || std::uncaught_exception())
return;
auto s = gr.reset();
if (s == ES_NORMAL)
return; // нет событий
throw EventException(s);
}
void Journey::disableEvents()
{
handleEvents();
eventsAllowed = false;
}
void Journey::enableEvents()
{
eventsAllowed = true;
handleEvents();
}
Тут стоит обратить внимание на добавление флага, нужно ли обрабатывать события или нет. Иногда нам стоит доделать какие-то важные действия, прежде чем мы бросим исключение и раскрутим стек. Для этого предназначен защитник:
struct EventsGuard
{
EventsGuard(); // вызывает disableEvents()
~EventsGuard(); // вызывает enableEvents()
};
Возникает вопрос, а когда вызывается тот самый пресловутый
handleEvents? А вот когда:void Journey::defer(Handler handler)
{
// добавляем перед выходом из сопрограммы
handleEvents();
deferHandler = handler;
coro::yield();
// и сразу после пробуждения
handleEvents();
}
То есть в момент выполнения любого переключения контекста, например при асинхронной операции или телепортации. Если же мы выполняем какие-либо тяжелые синхронные операции, то для более оперативного реагирования на события необходимо вставлять в наши обработчики дополнительные вызовы
handleEvents. Это решит проблему отзывчивости наших операций на внешние события.Теперь реализуем запуск сопрограммы:
Goer go(Handler handler, mt::IScheduler& scheduler)
{
return Journey::create(std::move(handler), scheduler);
}
Journey::create возвращает разделяемое состояние Goer для осуществления реакции на внешние события:struct Journey
{
// …
Goer goer() const
{
return gr;
}
// …
private:
// …
Goer gr;
};
Goer Journey::create(Handler handler, mt::IScheduler& s)
{
return (new Journey(s))->start0(std::move(handler));
}
// см. задачу 1
Goer Journey::start0(Handler handler)
{
// …
return goer();
}
Небольшой пример использования:
Goer op = go(myMegaHandler);
// …
If (weDontNeedMegaHandlerAnymore)
op.cancel();
После вызова
op.cancel() произойдет изменение состояния, и при последующем вызове handleEvents() отмена начнет свое исключительное и раскрученное дело.
Как вы уже успели, наверно, заметить, создание путешественника
Journey, который будет ходить туда-сюда, телепортируясь сквозь порталы, происходит скрытно внутри функции go. Таким образом, пользователь даже не знает, что ему приходится иметь дело со скрытым объектом. Он просто вызывает отдельно стоящие методы: go, defer, deferProceed и т. д., которые внутри себя вспоминают экземпляр путешественника Journey, используя TLS.Обработка таймаутов
Давайте взглянем на реализацию вложенных таймаутов:
struct Timeout
{
Timeout(int ms);
~Timeout();
private:
boost::asio::deadline_timer timer;
};
Для этого будем использовать
boost::asio::deadline_timer:Timeout::Timeout(int ms) :
timer(service<TimeoutTag>(), boost::posix_time::milliseconds(ms))
{
// получаем текущее разделяемое состояние
Goer goer = journey().goer();
// запускаем асинхронный обработчик
timer.async_wait([goer](const Error& error) mutable {
// mutable, так как мы изменяем захваченное состояние goer
if (!error) // если не было отмены таймера, то таймаутим
goer.timedout();
});
}
Timeout::~Timeout()
{
// отменяем запущенный таймер
timer.cancel_one();
// проверяем, вдруг произошло событие
handleEvents();
}
Используя RAII-идиому, мы имеем возможность вкладывать обработку таймаутов друг в друга независимо, ни в чем себя не ограничивая.
Приведу тривиальный пример:
// внутри сопрограммы
Timeout t(100); // 100 мс
for (auto element: container)
{
performOperation(element);
handleEvents();
}
Не справились за 100 мс – до свидания!

Еще один пример демонстрирует возможность вложенных таймаутов:
// установка таймаута 200 мс на все операции
Timeout outer(200);
portal<MyObject>()->performOp();
{
// установка таймаута 100 мс
// только на операции внутри области видимости
Timeout inner(100);
portal<MyAnotherObject>()->performAnotherOp();
// а эту операцию защищаем от посягательств
EventsGuard guard;
performGuardedAction();
}
Задачи
Задач на состояние гонки у меня целых две. Вообще, отлавливать состояние гонки – очень «увлекательная» задача. Поэтому предоставляю вам возможность подумать над ними.
Какова цель подобного упражнения? Перечислю:
- Анализ поведения поможет более детально понять, как работают сопрограммы.
- Конкурентность и асинхронность имеют специфические последствия. Знать о подводных камнях необходимо, чтобы в случае чего не огрести.
- Ну и наконец – просто размять мозг. Говорят, он от этого лучше работает.
Задача 1
Итак, задача под номером 1.
Имеется функция запуска сопрограммы:
Goer Journey::start0(Handler handler)
{
schedule0([handler, this] {
guardedCoro0()->start([handler] {
JLOG("started");
try
{
handler();
}
catch (std::exception& e)
{
(void) e;
JLOG("exception in coro: " << e.what());
}
JLOG("ended");
});
});
return goer();
}
Вот ровно в ней есть состояние гонки. Где? Что нужно поменять, чтобы исправить этот фатальный недостаток?
Ответ
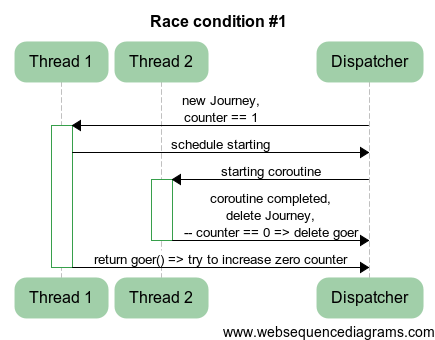
Goer Journey::start0(Handler handler)
{
+ Goer gr = goer();
schedule0([handler, this] {
guardedCoro0()->start([handler] {
JLOG("started");
@@ -121,7 +122,7 @@
JLOG("ended");
});
});
- return goer();
+ return gr;
}
Задача 2
Такое же условие. Есть код:
void Journey::onExit0()
{
if (deferHandler == nullptr)
{
delete this;
}
else
{
deferHandler();
deferHandler = nullptr;
}
t_journey = nullptr;
}
Где ошибочный код и как нужно его поправить?
Ответ
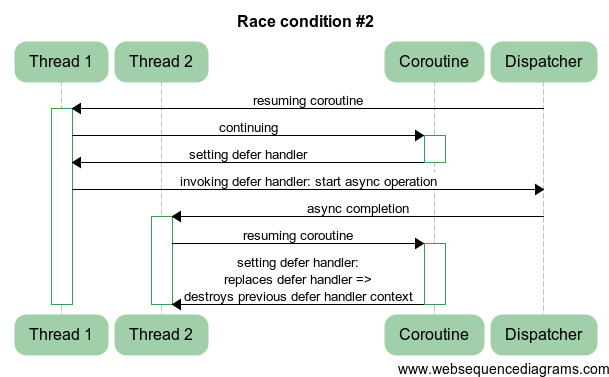
Помимо проблемы с замещением defer handler, возможно также двойное разрушение этого обработчика.
{
@@ -153,8 +154,8 @@
- deferHandler();
- deferHandler = nullptr;
+ Handler handler = std::move(deferHandler);
+ handler();
}
Помимо проблемы с замещением defer handler, возможно также двойное разрушение этого обработчика.
Бонус: сборщик мусора (GC)

Да, да, забубеним простейший GC на наших сопрограммах. Начнем сразу с примера:
struct A { ~A() { TLOG("~A"); } };
struct B:A { ~B() { TLOG("~B"); } };
struct C { ~C() { TLOG("~C"); } };
ThreadPool tp(1, "tp");
go([] {
A* a = gcnew<B>();
C* c = gcnew<C>();
}, tp);
Вывод в консоли:
tp#1: ~C
tp#1: ~B
tp#1: ~A
Обратите внимание на невиртуальные деструкторы и корректное разрушение объектов! Хотя кое-кто утверждает, что при наследовании всегда необходимо использовать виртуальные деструкторы.
Вся магия, как обычно, спрятана внутри:
template<typename T, typename... V>
T* gcnew(V&&... v) {
return gc().add(new T(std::forward(v)...));
}
GC& gc() { return journey().gc; }
struct GC {
~GC()
{
// удаляем в обратном порядке
for (auto& deleter: boost::adaptors::reverse(deleters))
deleter();
}
template<typename T> T* add(T* t)
{
// добавляем удалятор типа T
deleters.emplace_back([t] { delete t; });
return t;
}
private:
std::vector<Handler> deleters;
};
Экземпляр
GC хранится внутри путешественника Journey, который разрушается по окончании нашей сопрограммы. При этом накладывается ограничение: такие объекты не должны быть разделяемыми, они могут быть использованы лишь внутри сопрограммы.Выводы
Итак, мы рассмотрели несколько крайне полезных примитивов для построения достаточно сложных приложений:
- Неблокирующие примитивы ожидания завершения действий/результатов.
- Пулы потоков и планировщики.
- Неблокирующая синхронизация.
- Телепортация, то есть переключение между различными планировщиками.
- Порталы – мощная и гибкая абстракция выполнения действий в заданной среде: конкретном потоке, группе потоков, последовательно в группе потоков и т. д.
Предложенные подходы позволяют значительно упростить программный код, не расплачиваясь при этом производительностью. Ожидающие примитивы не блокируют потоки, что положительно сказывается на загрузке процессоров задачами. А использование неблокирующих мьютексов и вообще выводит синхронизацию на новый, доселе невиданный уровень.
Порталы позволяют полностью абстрагироваться от того, какие требования предъявляются к вызывающему. Это актуально при работе в гетерогенных условиях: база данных, сеть, диск, UI, разделяемые данные, тяжелые вычислительные операции. То есть при решении всех тех задач, в которых происходят обработка и передача данных между различными производителями и потребителями.
На самом деле это только введение в асинхронность на сопрограммах. Самая мякотка еще впереди! Надеюсь, статья доставила вам программистическое удовольствие.

Код
github.com/gridem/Synca
bitbucket.org/gridem/synca
Презентация C++ Party, Yandex
tech.yandex.ru/events/cpp-party/march-msk/talks/1761
Презентация C++ User Group
youtu.be/uUQX5QS1CCg
habrahabr.ru/post/212793
Литература
[1] Асинхронность: назад в будущее habrahabr.ru/post/201826
[2] Интерфейс Akka-планировщика doc.akka.io/docs/akka/2.1.4/scala/scheduler.html
