
asyncpg — новая Python open-source библиотека для работы с PostgreSQL. Она была написана с использованием asyncio и Python 3.5. asyncpg — самый быстрый драйвер для работы с PostgreSQL среди похожих реализаций на Python, NodeJS и Go.
Почему asyncpg?
Мы создаем EdgeDB — базу данных нового поколения, с PostgreSQL на бэкенде. Нам необходима высокая производительность, низкая задержка доступа и дополнительные возможности самого PostgreSQL.
Самый очевидный вариант – использовать psycopg2 — популярнейший драйвер Python для работы с PostgreSQL. У него отличное комьюнити, он стабильный и проверенный временем. Также есть aiopg, который реализует асинхронный интерфейс, поверх psycopg2. Тогда очевиден вопрос — зачем писать свой велосипед? Короткий ответ: производительность и поддержка возможностей PostgreSQL. Ниже мы рассмотрим это более детально.
Особенности
Поддержка типов данных
Наше основное недовольство psycopg2 заключалось в посредственной обработке различных типов данных, в т.ч. массивов и составных типов. Множество различных типов данных — одна из отличительных особенностей PostgreSQL. И еще, из коробки psycopg2 поддерживает только простые типы данных — целые числа, строки, время и даты. Это заставляет писать свои типы, для чего-то другого.
Основная же причина этого кроется в том, что psycopg2 обменивается с сервером БД данными в текстовом формате, из-за чего немало данных приходится парсить, особенно это касается составных типов данных.
В отличие от psycopg2, asyncpg использует бинарный I/O протокол PostgreSQL, который, помимо преимуществ в производительности, также имеет родную поддержку контейнерных типов данных (массивы, диапазонные и составные типы).
Подготовленные запросы (prepare)
Также asyncpg использует подготовленные операторы PostgreSQL. Это отличная возможность для оптимизации, так как это позволяет избежать повторного парсинга, анализа и построения плана запроса. Кроме того, asyncpg кэширует I/O данные для каждого подготовленного оператора.
Подготовленные операторы в asyncpg могут быть созданы и использоваться напрямую. Они предоставляют API к получению и анализу результатов запроса. Большинство методов запроса создают подключение напрямую, и asyncpg создает и хранит в кэше подготовленные запросы.
Простота развертывания
Другой важной особенностью asyncpg является отсутствие зависимостей. Непосредственная реализация протокола PostgreSQL означает, что вам не нужно устанавливать libpq. Достаточно просто выполнить
pip install asyncpg. Кроме того, мы предоставляем пакет и для ручной сборки на Linux и macOS (Windows планируется в будущем).Производительность
Вскоре нам стало ясно, что реализуя протокол PostgreSQL напрямую, мы можем добиться значительного увеличения в скорости. Наш прошлый опыт с uvloop показал, что с помощью Cython можно создавать эффективные и производительные библиотеки. asyncpg полностью написан на Cython с управлением памятью и высокой оптимизацией. В результате asyncpg оказался в среднем в 3 раза быстрее, чем psycopg2 (или aiopg).
Тестирование
Так же, как и для uvloop, мы создали отдельную утилиту для тестирования pgbench и создания отчетов для asyncpg и других реализаций драйвера PostgreSQL. Мы замеряли скорость выполнения запроса (строк в секунду) и задержку. Основная цель этих тестов — узнать накладные расходы для данного драйвера.
Если честно, то все тесты были запущены в одном потоке (GOMAXPROCS=1 в случае с Golang) в асинхронном режиме. Python драйвера были запущены с использованием uvloop.
Данное тестирование проходило на чистом сервере с данной конфигурацией:
- CPU: Intel Xeon E5-1620 v2 @ 3.70GHz, 64GiB DDR3
- Gentoo Linux, GCC 4.9.3
- Go 1.6.3, Python 3.5.2, NodeJS 6.3.0
- PostgreSQL 9.5.2
Используемые драйвера:
- Python: asyncpg-0.5.2, psycopg2-2.6.2, aiopg-0.10.0, uvloop-0.5.0. aiopg — это крошечная обертка над psycopg2, для возможности асинхронной работы
- NodeJS: pg-6.0.0, pg-native-1.10.0
- Golang: github.com/lib/pg@4dd446efc1, github.com/jackc/pgx@b3eed3cce0
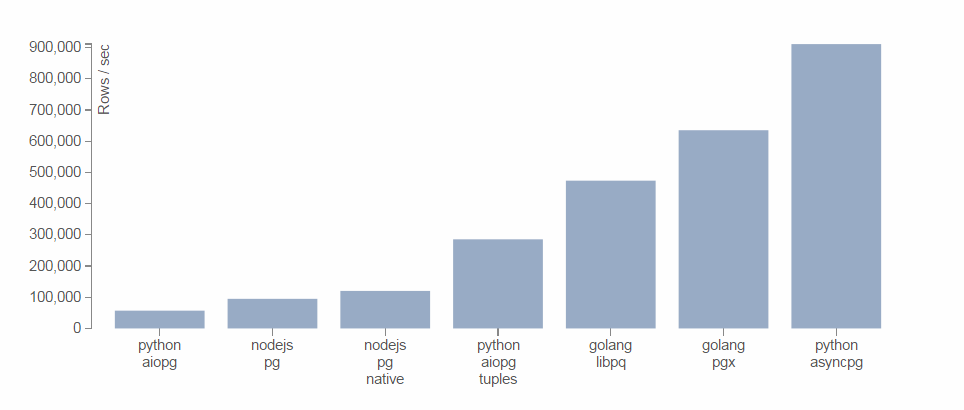

Графики показывают средние значения по результатам, полученные запуском 4 различных типов запросов:
— Прямой запрос по выбору всех строк из таблицы pg_type (около 350 строк). Он довольно близок к общему числу запросов приложения. В этом тесте asyncpg показывает указанную в заголовке производительность в 1 млн строк в секунду. Подробнее.
— Запрос генерирует 1000 строк, состоящих из одного целого числа. Этот тест предназначен для просмотра производительности при создании записей и получении результата. Подробнее.
— Запрос возвращает 100 строк, каждая из которых содержит 1 КБ бинарных данных (blob). Это стрессовый I/O тест. Подробнее.
— Запрос возвраща��т 100 строк, каждая из которых содержит массив из 100 целых чисел. Этот тест предназначен для проверки скорости декодирования массивов. Здесь asyncpg оказался медленнее, нежели более быстрая реализация на golang. Это связанно с расходами на создание и удаление кортежей в Python. Подробнее.
Заключение
Мы уверены, что с помощью Python возможно создавать высокопроизводительные и масштабируемые системы. Для этого нам нужно приложить усилия к созданию быстрых, высококачественных драйверов, циклов событий, фреймворков.
asyncpg — один из шагов в этом направлении. Это результат осмысленного проектирования, питаемый нашим опытом создания uvloop, а также эффективного использования Cython и asyncio.
Перевод статьи 1M rows/s from Postgres to Python

