Привет, Хабр! Меня зовут Дичковский Алексей, и я хочу вам рассказать о том, как я потратил полтора месяца своей жизни на написание бота для упрощённой версии DotA.
Ежегодно компания Mail.ru проводит онлайн-чемпионат по программированию игровых стратегий (Russian AI Cup 2016). Я принимал участие в данном соревновании в 2012 году (СodeTanks) и, совсем немного, в 2013 (СodeTroopers). В этом году, изрядно наевшись веб разработкой, я решил попробовать принять участие ещё раз. Я изначально не надеялся (но, конечно же, очень хотел) занять какое-либо призовое место и в целом для меня это был скорее тест, насколько я ещё могу реализовать нечто интересное. О том, что из этого получилось, можно прочитать под катом.

Достаточно неслучайно заметив анонс грядущего соревнования на сайте russianaicup.ru, я начал готовиться. Имея опыт участия ранее, я посчитал, что шаблон для своего кастомного визуализатора мне очень пригодится и сэкономит немного времени во время самого соревнования. Вся подготовка в целом заключалась в написании своего визуализатора, который изначально умел выводить только несколько базовых фигур.
7 ноября, в день старта RAIC 2016, первое, что я сделал — открыл правила и стал читать, что же организаторы приготовили нам в этом году. DotA? Да ну, не может быть… Да точно DotA! После прочтения правил осталось стойкое ощущение, что кода писать надо будет много… Очень много. И осознание этого в самом начале не сильно придавало вдохновения. Также в этом году старт конкурса совпал с днём рождения моей жены, поэтому пришлось отложить начало разработки на день, ведь в ближайшие полтора месяца меня будет сложно выковырять из-за ПК. Возможно, это также помогло мне немного более точно осмыслить, каким будет мой бот в этом соревновании.С самого начала у меня был какой-то план, и я его придерживался.
Первые три вечера ушло на создание проекта, прикручивание линий, вдоль которых будем ходить в атаку, плохонький выбор одной из трёх линий (на старте игры — как у quick start guy — базовой стратегии, предоставляемой организаторами, после смерти — где врагов побольше и своих поменьше), а также прикручивание визуализатора, “скелет” которого был написан за неделю до RAIC. Дальше надо было учиться как-то ходить… Заниматься большим количеством геометрии было жутко лень, а пролазить в “щели” между миньонами, магами и деревьями таки хотелось… Т.к. других вариантов на ум не пришло, то решил сделать локальную “сетку”, по которой можно ходить, и заодно в неё заложить подсчёт опасности и полезности нахождения в той или иной точке.
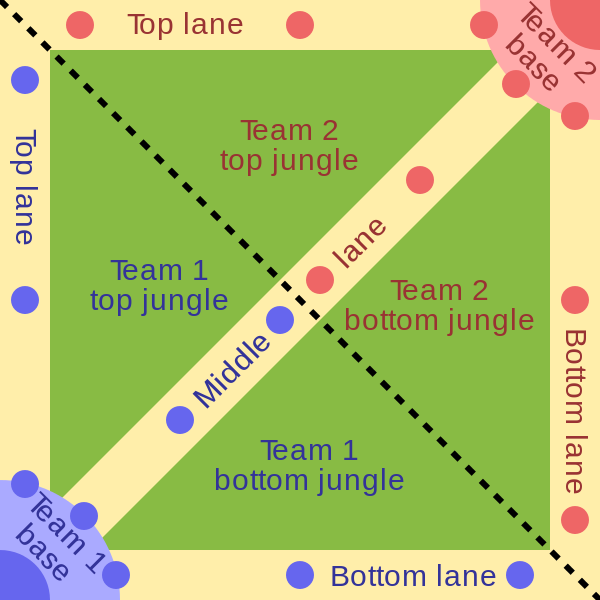
Схема игровой карты. Линии, по которым стоит атаковать вражескую базу (top/bottom/middle lane), отделены друг от друга лесом.
Пятница и выходные прошли за раздумьем, стоит ли оно того или всё же не ввязываться в это дело… Но всё же к вечеру воскресенья что-то с движением было реализовано. Первый вариант сетки был с шагом 2 размером в 401 * 301 точку (расстояние 600 вперёд вдоль линии боя, 300 в сторону и 200 назад). В каждой точке этой сетки вёлся подсчёт score — “полезности нахождения” за вычетом “опасности нахождения” в ней. В конечном варианте ячейка сетки состояла из множества полей и учитывала опасность от миньонов, опасность от магов, опасность от зданий, полезность нахождения в зоне, из которой я могу атаковать врагов (были разделены на две разные переменные для ближнего и дальнего боя, в каждой из них учитывалось только лучшее значение), полезность нахождения в зоне вокруг покалеченных врагов (для получения опыта за их убийство) и дополнительные две переменные otherDanger и otherBonus для реализациикостылей случаев вроде сбора бонусов, создания опасной зоны в месте появления вражеских крипов, предотвращение ненужного ухода в лес, забивания в угол карты и т.д. Каждый ход пересоздавать такую матрицу очень не хотелось, поэтому при обновлении её координат (она двигалась вместе с магом) все эти значения обнулялись.

Изначальный вариант матрицы. Расстояние до переднего края матрицы — 600 “пикселей”. Направо и налево — 300, назад — 200. Расстояние между точками — 2. Матрица получилась чересчур большой. Количество точек в самой матрице — 401 * 301. Она всегда направлена вдоль линии сражения, независимо от ориентации мага.
Запуски на локал раннере показали, что что-то мой подход работает слишком медленно… По условиям соревнования на каждый тик стратегии выделялось 10 мсек, а по моим измерениям на локальной машине выходило ощутимо больше. Отфильтровал мир до необходимого минимума: живые юниты и башни на расстоянии 600 до моей локальной сетки, деревья — так, чтобы обсчёт учитывал их как препятствия, но добавлял как можно меньше “лишних” деревьев. Дополнительно увеличил шаг сетки до 3, и получил производительность более похожей на ту, что надо. Оптимизации всё ещё были необходимы, но на первое время решил, чтои так сойдёт достаточно. Всё же прошла уже практически неделя, а выкинуть что-то своё на поля сражений хотелось. Точка, к которой двигался, выбиралась как просто лучшая среди точек на матрице по значению score. Поиск пути я устроил приоритетной очередью, где весом ребра было не расстояние (хотя как второй фактор оно таки учитывалось), а опасность получить оплеуху от вражеской команды, при этом не учитывая полезность нахождения в ней. При таком подходе может быть найден такой путь, который хоть и будет коротким, если бы бот умел ходить только по точкам матрицы, но будет ломаным, что здорово мешает быстрому перемещению. Эту проблему я решил бинарным поиском вдоль всего пути, где проверял возможность пройти из своей точки в искомую напрямик (перед запуском бинпоиска проверялась достижимость конечной точки пути). Т.о. если препятствий на пути не было — бот просто шёл прямиком к точке назначения.
Хорошо, ходить можем, немного бояться вражеских магов и миньонов умеем… А как же бой? Хм… Создал лист целей, отфильтровал их так, чтобы деревья не мешали стрелять (попутно забывая, что отфильтрованы деревья так, чтобы посчитать их как препятствие на сетке опасности, чего явно недостаточно, если цель стоит сразу за деревом), задал целям приоритеты, зависящие от того, какой % хп цели остался. Приоритет магов и башен на первое время поставил в 5 и 6 раз выше, чем у миньонов. Затем учу бота поворачивать для выстрела — если мы можем с текущей позиции стрелять и количество тиков до перезарядки уже где-то на грани того, за сколько мы можем “довернуть” на цель — поворачиваемся к цели, иначе поворот в сторону движения.
Поработав с локал раннером, с грустью понял — всё таки вариант пути не очень годится… Во время выхода из “опасных” зон сразу пытаемся бежать в оптимальную точку, но ведь от удара миньона можно просто убежать задом (скорость передвижения миньонов равна скорости движения мага задом и боком), если бежать строго от него. Учимся убегать от вражеских миньонов — теперь пытаемся бежать по прямой не к конечной точке, а к такой промежуточной точке на пути, опасность в которой ощутимо меньше опасности в текущей точке моего мага. Изменил поиск точки, к которой перемещаемся — теперь она выбирается не сразу, а по мере поиска путей по всей матрице, учитывая кроме score целевой точки ещё и опасность, которой мы подвергнемся по пути к ней. На этом этапе это была банально сумма всех опасностей * 0.02 (все коэффициенты с самого начала и до конца выбирались на глаз, менялись редко).
После реализации нового выбора пути и более детального тестирования в локал раннерегрустим и думаем оставить дурную затею (RAIC) я заметил, что во временные рамки код опять не влазит. Включив профайлер java кода, увидел, что всё-таки хоть поиск пути и кушает немало, но основная нагрузка — это вычисление score для каждой точки матрицы. Ведь для каждой точки матрицы идёт проверка по всем юнитам с расчётом от них расстояния до этой точки, даже если это расстояние сильно больше, чем то, на котором данный юнит может повлиять на мою матрицу… Хм. Вынес подсчёт опасностей в отдельные от обновления координат сетки циклы, создал структуру для применения влияния юнита на score точек сетки. Перед тем, как считать расстояние от юнита до каждой точки очередной строки матрицы, стал проверять расстояние от юнита до отрезка, концами которого являются концы этой строчки. Теперь если юнит гарантированно не может повлиять на score точек в данной строке матрицы опасностей — просто пропускаю целиком всю строку. И вот эта оптимизация уже позволяла локально вполне сносно вкладываться в лимиты. Всё это казалось жутко кривым, но как-то работало…
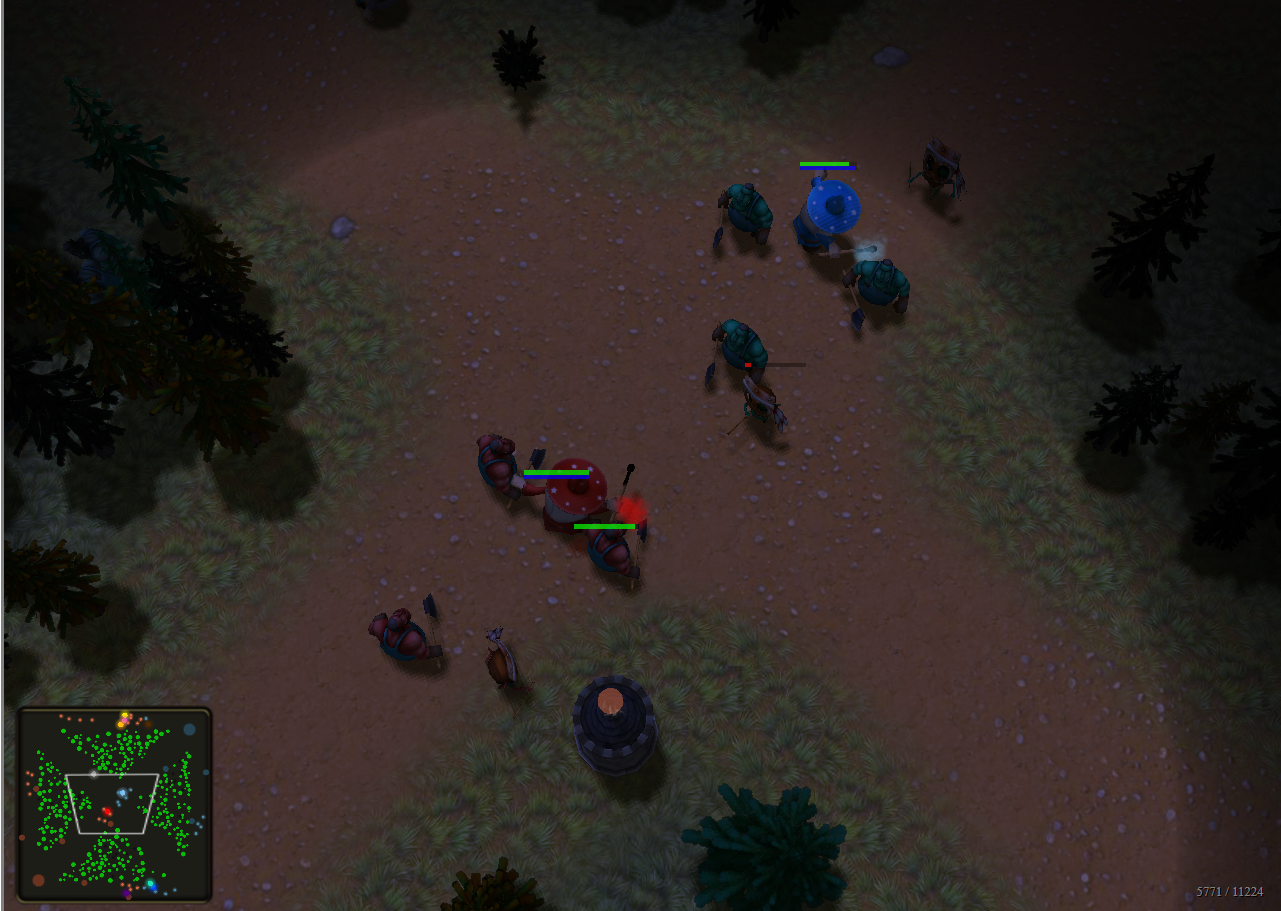
И всё ещё, пожалуй, бот не готов к первым боям. В ближнем бою магковырять спичкой бить посохом не умеет, деревья — непреодолимое препятствие, вражеские маги и миньоны постоянно выгоняли меня с линии в лес… Добавляю проверку на то, что рядом есть кто-то или что-то, что можно стукнуть, и если нет нужды сейчас поворачивать для выстрела — давай-ка стукнем это что-то посохом. Исправляю проблему того, что по деревьям вообще стрелять не хотим (хотя приоритет выстрела установил в 0, но если нет других целей). Добавляю штраф за отхождение далеко от центра линии… Значительно уменьшил матрицу, в которой считаю очки (до расстояния в 351 вперёд и по 150 назад и по бокам. Казалось размер не сильно влияет на поведение) и первая версия пошла в бой!
Жалкое зрелище, душераздирающее зрелище… Маг столбенеет при подходе вражеского мага (т.к. по всей матрице поиска становится слишком опасно), его зажимают миньоны, он застревает, пытаясь убежать за край карты, убегает в угол карты, откуда убежать получается только на свою базу через 1.2к тиков (время на возрождение)… Исправляю все эти недочёты, добавляя дополнительные штрафы за нахождение в точках около края карты, добавляем край карты как препятствие, убираю остолбенение, если везде очень опасно (сумма опасностей больше хп моего мага). Всё это немного помогает, и теперь, хотя всё равно эффект не очень, как-то жить можно. А тем временем топы уже вовсю бегают за бонусами.
Как научить бота
Что ж, надо и мне учиться бегать за бонусами… За них дают весьма немало очков. Только вот непонятно, как. Для начала решил научиться пользоваться скоростью по максимуму… Заодно задел на будущее — учимся учитывать все ауры и пассивные навыки, статус HASTENED (ускорение) — и теперь, если меня вдруг миньоны затолкают на бонус, я буду быстрее бегать! Затем, понаблюдав за боями с другими соперниками, понял, что я постоянно попадаю под вражеские башни… А один их выстрел это более трети хп мага. Добавил их положение в мире и запомнил время до следующего выстрела. Заодно сделал так, чтобы во время перезарядки башен мой маг подходил чуть ближе. Всё ещё плохо убегаем от миньонов, т.к. бежим строго по своей сетке, а её направление редко совпадает с направлением, в котором следовало бы убегать от миньона. В итоге выходит, что мой бот убегает от миньона “слегка наискосок”, а последний, направляясь строго на меня, отрыв постоянно сокращает. Решение — добавил локально рассмотрение нескольких направлений одного шага примерно в ту сторону, в которую мой бот считает, что стоит двигаться (направление к ближайшим точкам на пути + угол, который можно рассмотреть дополнительно)… Вот тут и структуры для расчёта очков в точке пригодятся. Выбираем точку из этого множества в первую очередь с большей полезностью нахождения в ней для себя, а во вторую — поближе к искомому направлению движения… Теперь можно нормально обходить по красивой окружности опасные зоны, а не дёргаться по принципу «шаг вперёд — шаг в сторону», да и убегать от миньонов теперь можно куда более эффективно ровно по прямой. Ещё добавим в матрицу опасность от зоны появления вражеских миньонов за некоторое количество времени до их появления, чтобы можно было вовремя отойти оттуда и не оказаться в их окружении…
(Кликабельно, внутри gif-ка)
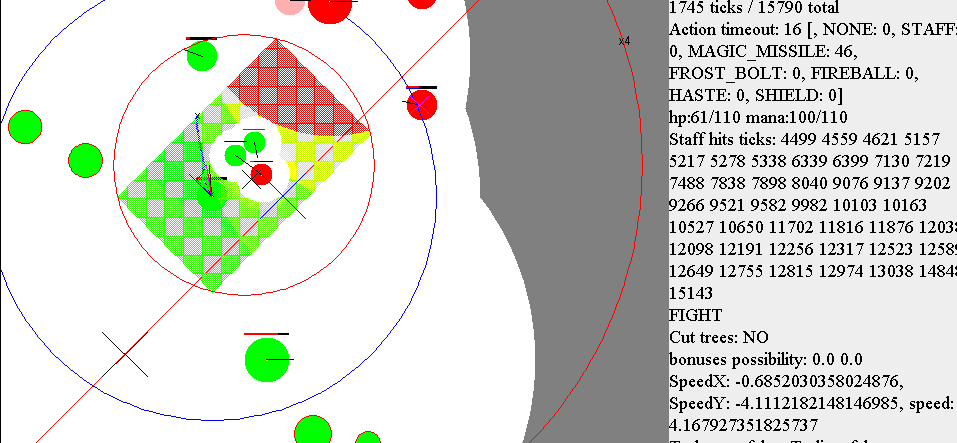
Скриншот из визуализатора. Зелёный круг чуть с краю от центра разукрашенного прямоугольника (вокруг которого нет “белой” зоны, в которую нельзя шагнуть) — маг, которым управляет стратегия. Красные — враги, зелёные — свои. Синяя неровная линия от центра моего мага — путь, куда мы сейчас идём. Чёрные полоски из центра мага — какой угол рассматривается при попытке подобрать наилучший шаг. Розовая — направление, в котором на данный момент вероятнее всего лучше идти. Красная — выбранное направление для следующего шага.
Проснувшись утром в субботу, был наполнен решимости что-то придумать с бонусами, но обнаружил, что мой бот добрался примерно до топ 100, и там неожиданно начали стрелять не в центр, а в краешек моего мага, почти в каждом рейтинговом бою жестоко и уверенно избивая его, пока тот не мог ничего ответить. Однако делать так же не хотелось, т.к. топы хоть ещё и не умеют уворачиваться, но точно скоро будут, а хочется то туда, наверх… План пришёл в голову простой и одновременно сложный — а не буду я делать так же, я попытаюсь просто уворачиваться, благо за те 12 тиков, которые летит снаряд, можно вполне себе неплохо отойти… Скорости мага недостаточно, если стреляют в центр, но вот от такой проблемы помочь может.
Для начала надо запоминать тик появления всех снарядов, чтобы впоследствии можно было подсчитать, куда максимум может долететь каждый из них. В финале в целом можно будет игнорировать все выстрелы от союзников, но в первых двух раундах игнорировать выстрелы не очень-то союзных магов не стоит. Т.к. конкуренция по очкам также работает и внутри одной команды, “союзные” маги тоже часто любят добивать своих (пламенный привет mortido). Затем проверяем, пересекается ли снаряд со мной, если я буду стоять на месте (расстояние до отрезка полёта снаряда меньше, чем сумма радиусов моего мага и снаряда, к которому дополнительно прибавляется расстояние, на которое я могу шагнуть, чтобы случайно не шагнуть под снаряд). Если хотя бы один снаряд может в меня попасть — пытаемся уклониться. Первым делом — подсчитаю, сколько чего бот “поймает”, если будет просто стоять на месте (вариант, когда просто боится шагнуть под снаряд). Этот базовый урон беру за начальный и пытаюсь отойти в любую сторону со скоростью, как если бы я шёл боком или задом. Также при этом учитывается суммарное количество очков в точках, через которые мы пройдём во время уворота (если стоим на месте — складываем одну и ту же точку то количество тиков, которое понадобится). Если на этом этапе не получилось увернуться от снаряда — пытаюсь бежать во все стороны на максимально возможной скорости (поворачивая в выбранную сторону). При попытках отойти или отбежать от снаряда также проверяю, что я не натыкаюсь на препятствие, допуская, что все миньоны двигаются прямолинейно всё время, а маги, здания и деревья стоят на месте. Если на текущем тике я упёрся в препятствие, на следующем тике я всё равно попытаюсь повторить шаг. Вдруг кто-нибудь да отойдёт… Получилось увернуться от снаряда? Блокируем поиск пути, перемещаемся в направлении, где урона получил бы поменьше и находиться побезопасней. А если при этом ещё поворот в определённую сторону помог убежать — блокируем управление поворотом бота на этом тике и крутим его в ту сторону, в которую бежим (поворачивает то мой в последнюю очередь, после расчёта выстрела).
Одновременно с написанием алгоритма уворота пришло осознание, что стрелять в центр не самый лучший вариант… Лучше стрелять в точку чуть спереди от центра мага, тогда убегать надо дольше и одинаково долго и вперёд, и назад. Решил оставить это знание на будущее.
Так шаг за шагом, написав ворох улучшений (в т.ч. очередное улучшение способа определения, когда же стоит рубить эти ненавистные мной на пару с ботом деревья), я всё же сел писать именно поход за бонусами. К тому времени в топе за них началась настоящая драка и нечасто можно было любой бонус спокойно и безнаказанно забрать. Стал запоминать, где в последний раз видели вражеских магов, чтобы не идти в сторону бонуса в случае, если с большой вероятностью они смогут его забрать раньше меня. На тиках, кратных 2500, вероятность нахождения бонусов на своих местах устанавливалась в 1. Если какой-либо вражеский маг вне зоны видимости мог за время, пока он не виден, добежать до бонуса, то вероятность нахождения бонуса в точке постепенно уменьшалась. И чем ближе маг был к бонусу в последний раз перед тем, как его видели — тем сильнее падала вероятность того, что бонус всё ещё находится на своём месте. Также стал запоминать положение вражеских миньонов, чтобы можно было возвращаться в точку на линии их движения на расстояние своего выстрела. В коде добавилась четвёртая “линия” — она просто задавала направление, в котором мне хочется идти. Также, при активировании этой линии, в матрице опасностей точкам, ближе к целевой, начислял дополнительный бонус. Теперь бот двигался в ту сторону и не слишком сильно застревал для добивания вражеских миньонов, магов или башен.
(Кликабельно, внутри gif-ка)

Пкреключение на четвёртую «псевдо» линию. Она задавала направление матрицы строго в точку, к которой было необходимо идти. В данном случае маг немного заранее отправился к ближайшему бонусу через лес.
Одновременно с написанием походов за бонусами добавил возможность смены линии атаки кроме как на момент смерти (изначальная реализация не подразумевала такой возможности в других ситуациях). Т.к. теперь у меня есть запомненные данные по местонахождению всех бывших в зоне видимости юнитов, то бот стал лучше понимать, на какой из линий наша оборона слабее нападающих (на это перестал влиять временный выход вражеских магов и миньонов из поля зрения). В целом с этого момента и до конца раунда 2 выбор линии выглядел как “идём туда, где врагов побольше, а своих магов поменьше”.
Как последний штрих, но всё-таки немного отдельно стоящий, я всё же в третий раз переписал алгоритм поиска лучшей позиции и пути к ней. В последней и финальной его итерации лучшей точкой считалась та, где сумма среднего score на пути к ней и score в самой точке была максимальной. Для этого сначала опять же приоритетной очередью искал путь по матрице, значения score в которой для этого поиска было уменьшено на максимальное его значение (чтобы избежать положительных “петель”). После такого изменения в ходьбе бота обнаружился серьёзный недостаток — он стал очень любить бегать вокруг вражеских миньонов и зданий, часто заходя им за спину, чем сам себе отрезал путь к отступлению от вражеских магов. Разделил поля опасности от миньонов на 2 части: теперь кроме зоны атаки дополнительно выделялась зона, в которой миньон будет атаковать меня (минимум из view range и расстояния до ближайшего союзного мне юнита). Этим мне удалось избавиться от данной проблемы, и выбираемый моим ботом путь теперь стал выглядеть ощутимо более логичным, чем ранее.
(Кликабельно, внутри gif-ка)

Скриншот из визуализатора. В данном случае алгоритм уворота заблокировал контроль поворота мага и сам поворачивает в сторону бега (статус RUN_FROM_PROJECTILE). Также видно, что бот запомнил последнее положение одного из вражеских магов. В дополнение рисуется ориентировочное максимальное расстояние, на которое данный маг мог убежать.
С этого момента и до самого раунда 1 больше особых улучшений не делалось. Исправлялись баги и серьёзные недочёты в коэффициентах. Постепенно рейтинг моего бота рос, пока не обосновался в десятке. На этом этапе можно было отметить, что % побед у моего бота весьма мал по сравнению с другими участниками из топа песочницы. Видимо осторожное отношение к бонусам не давало набирать максимальное количество очков, но выживаемость у мага была на более-менее приемлемом уровне, за счёт чего свои очки он стабильно набирал.
По итогам первого раунда я занял 8 строчку в рейтинге, что для меня оказалось приятной неожиданностью. Правила раунда 2 отличались от правил раунда 1 наличием возможности изучения и применения навыков. В последний день перед запуском в песочнице игр по правилам 2 раунда была прикручена возможность стрельбы ледяными стрелами. В первый же вечер на фоне того, что мало какие стратегии умели пользоваться навыками и уворачиваться, выглядело весьма впечатляюще. Однако… Спустя всего 1 день стало очевидно, что против ботов, выбравших файрбол в качестве первой ульты, сражаться получается плохо. Попытки исправить это коэффициентами и добавлением учёта радиуса взрыва от файрбола в алгоритм уворота ни к чему не привели. Не можешь победить врага — возглавь его. Следующим этапом стало написание стрельбы файрболом. В общем то ничего лучше перебора выстрела вокруг стоящих на месте миньонов (так, чтобы задеть последних краем файрбола и краем взрыва), зданий и всех вражеских магов (при этом считая, что последние всегда оптимально пытаются от взрыва убежать) быстро не придумалось и как временный вариант был сделан именно такой перебор. Учитывались только те варианты выстрела, которые я могу сделать с текущим радиусом каста. Но… Нет ничего более постоянного, чем временное. До самого финала алгоритм перебора остался точно таким же, за исключением уточнения, может ли вражеский маг убежать от моего файрбола или нет.
После вполне удачного тестирования использования файрбола на полях сражений, я заполучил первое место в песочнице и решил заняться улучшением того, что уже было написано. Написал класс WizardsInfo, в котором хранилась информация о пассивных навыыках, ультах, действующих на мага аурах. Переключил код, где использовалась подобная информация, на использование нового класса. И, как обнаружилось через целую неделю, серьёзно сломал свои увороты. При отсутствии статуса ускорения бот при симуляции попыток увернуться пытался сделать это на скорости на 30% меньше, чем у него было на самом деле. Заметил я это совсем не сразу потому, что в общем-то они работали, но стали делать своё дело намного хуже.
По итогам просмотра боёв на сайте, где меня часто убивали агрессивные стратегии, окажись они вдвоём на меня одного, для улучшения отступление был добавлен разворот матрицы поиска пути на 180 градусов (т.е. она в таком случае считалась на большее расстояние назад, чем вперёд), если мой бот считал, что находится в опасности (например, вышел на двоих вражеских магов и рядом со мной нет союзников). Исправил атаку неразрушимых зданий (по правилам нельзя было нанести вред второй башне на линии, не уничтожив первую, однако вторая башня из соседней линии была достаточно близко, чтобы бот отвлекался на неё). Было очень много попыток улучшить ситуацию с помощью изменения влияния врагов на score в матрице. Из явно позитивных изменений — при расчёте области опасности от вражеских магов стал учитываться угол их поворота, кроме кулдаунов умений вражеских магов стало учитываться также наличие маны и время её восстановления. Полностью переписана система таргетинга с той целью, чтобы маг более аккуратно выбирал, каким заклинанием он воспользуется в следующий раз (например, зачем вообще тратить ману даже на базовые магические ракеты, если у нас есть файрбол, а маны не осталось? Можно же бить посохом или просто стоять в сторонке). Добавлен учёт возможности уворота вражеского мага от моего выстрела. В расчёте выстрела с помощью базового заклинания и ледяной стрелы для вражеских магов теперь стал пытаться выстрелить в две точки — центр цели и в точку, при стрельбе в которую сбоку убегать одинаково долго и вперёд, и назад (эта точка находится чуть спереди от центра мага). Тут я использовал знание, полученное при написании алгоритма уворота. А рейтинг всё таял и таял, отчего становилось всё грустнее и грустнее.
И всё-таки, через неделю после поломки алгоритма уклонения я, рассматривая очередной бой через свой визуализатор, обнаружил, что мой бот, запустив логику уклонения и спокойно и аккуратно уходя от выпущенного снаряда “в чистом поле”, вдруг неожиданно стал считать, что уклониться-то от снаряда он не может, и продолжил бой, как ни в чём не бывало поймав порцию урона. Это заставило меня перепроверить конкретно данную ситуацию. Баг, ставший виновником недельной грусти и печали, был локализован и жестоко наказан.
После исправления проблемы в алгоритме уворота рейтинг снова начал расти, и я перестал бояться не пройти в финал. Однако за время, необходимое для подготовки к раунду 2, хотелось бы научиться пользоваться всеми ультами, чтобы потом можно было их использовать в финале. Но сначала… Мой маг всё ещё очень пассивно стоит на линии и не особо предпринимает попыток к атаке вражеских магов, которые держатся на расстоянии. И это хотелось бы исправить. На прошлой неделе была переписана система таргетинга, и теперь в неё можно было более или менее легко вставитьданный костыль данное улучшение. Я научил бота подбегать напрямую к желаемой цели, если исполненный выстрел в неё более или менее перекрывал риск на пути к точке выстрела. Бот стал играть ощутимо агрессивней, гораздо чаще заставляя врагов отступать от линии сражения, чтобы подлечиться, и намного реже отпуская подлечиться едва живых врагов.
А далее… За оставшееся время до включения в песочнице правил финала научил мага использовать заклинание ускорения и щита, отрегулировал использование всех боевых заклинаний вроде фростболта, исправил очередную проблему с застреванием в деревьях (которая обнаружилась почти прямо перед раундом 2), и… Для случая, если количество врагов на линии бота больше, чем количество союзников, учитывая самого бота, включил изучение ветки навыков, которая отвечает за скорость бега. И тут был замечен баг, исправление которого было отправлено в 0:00:01, т.е. с опозданием всего на одну секунду. А именно — незадолго до 2 раунда я таки решил научить своего бота накладывать заклинание ускорения на союзников, но сломал наложение этого заклинания на себя. И если на линии был бой 2 на 3, то всё было хорошо (т.к. по правилам при наложении заклинания ускорения на союзника маг, который его накладывает, также получает копию заклинания на себя), то в бою 1 на 2 данная проблема была таки весьма критична. Проблема дала о себе знать буквально в первые же бои в первой части второго раунда, т.к. выбор линии у моего бота до сих пор работал по алгоритму, реализованному для раунда 1, т.е. он выбирал ту линию, где меньше всего своих. Но это не помешало ему занять место в верхних строчках по итогу первой части второго раунда.
Ко второй части раунда была добавлена логика поиска целей для файрбола за зоной каста мага (одновременно с доработкой логики набегания для выстрела при его использовании), исправлены очередные замеченные проблемы с застреванием в деревьях (да, деревья всё ещё побеждали моего бота). Логика применения заклинаний стала гораздо лучше учитывать то, когда же необходимое количества маны восстановится для очередного заклинания. Уже после запуска второй части раунда 2 была немного подправлена стрельба по миньонам (теперь стрелял в передний край, т.е. туда, куда миньон смотрит. При стрельбе в центр миньон мог отбежать от снаряда, если бежал в сторону от нас).
В финале правила отличались тем, что теперь всеми магами за одну из сторон управляет стратегия одного человека, что открывало новые просторы для командной игры. Первое, что я попытался сделать — скопировать исходники для раунда 2 и положить их рядом, чтобы запускать их в случае, если игра идёт по правилам раунда 2, т.к. усложнять логику, делая зависимость от текущих правил игры не хотелось совсем. Но…. Система решила, что мои решения принимать она больше не хочет, и несколько часов было потрачено на поиски причины, почему же система выдаёт ошибку о том, что я её присылаю «некорректный архив»… Если бы не общий чат, то поиск причины мог бы затянуться и на гораздо большее время. А оказалось — система просто не хочет принимать исходники, которые в распакованном варианте занимают более мегабайта на диске. Как я умудрился написать больше, чем на мегабайт??? В общем,с помощью лома и какой-то матери исходники, не находящиеся в активной разработке, были ужаты минифификаторами, выкинуты визуализаторы для первых двух раундов и необходимый мегабайт был достигнут. Впоследствии в системе расширили возможность посылки исходников до 2МБ и данный пункт нашёл отражение в правилах, но в ту ночь, чтобы отослать пробный вариант стратегии на финал (все свои маги отправлялись на центральную линию), пришлось потратить достаточно много времени. В итоге отправил непроверенную версию и пошёл спать. В этой версии все мои маги должны были учить разные ветки навыков и атаковать через одну центральную линию (т.н. “пуш по миду”). А с утра обнаружил, что такая тактика вполне неплохо себя проявляет даже с учётом того, что в 2 ночи я залил версию с багом и мои маги вообще не хотели учить какие-либо навыки.
Исправив проблему с навыками и убрав групповое хождение за бонусами (теперь за бонусом ходил только ближайший из моих магов), приступил к написанию группового взаимодействия. Времени было выделено по сравнению с другими раундами ощутимо меньше (всего неделя), а писать надо было по сути нечто совершенно новое. Взаимодействие между союзниками в раундах 1 и 2 было сильно затруднено ввиду сильной разности стратегий, поэтому мной оно писалось отдельно именно для финала.
Первой проблемой, с которой столкнулся “пуш по миду”, была перегруженность линии союзными магами, которые мешали друг другу уворачиваться от снарядов соперников и часто блокировали пути отхода на безопасное расстояние от врагов. Решение было достаточно простым и очевидным — добавил штраф за нахождение слишком близко с союзными магами, который игнорировался, когда текущий маг сам находился в опасности. Теперь мои маги не мешали друг другу уворачиваться, а если кто-либо из моих хотел отступить в более безопасное место, он как бы “расталкивал” остальных. Вместе с этой правкой добавилась ещё одна — сделал дополнительное положительное поле на расстоянии в 600 от каждого союзного мага, благодаря чему в поведении ботов оставалось достаточно свободы, но разбегаться слишком далеко друг от друга они уже не хотели.
(Кликабельно, внутри gif-ка)
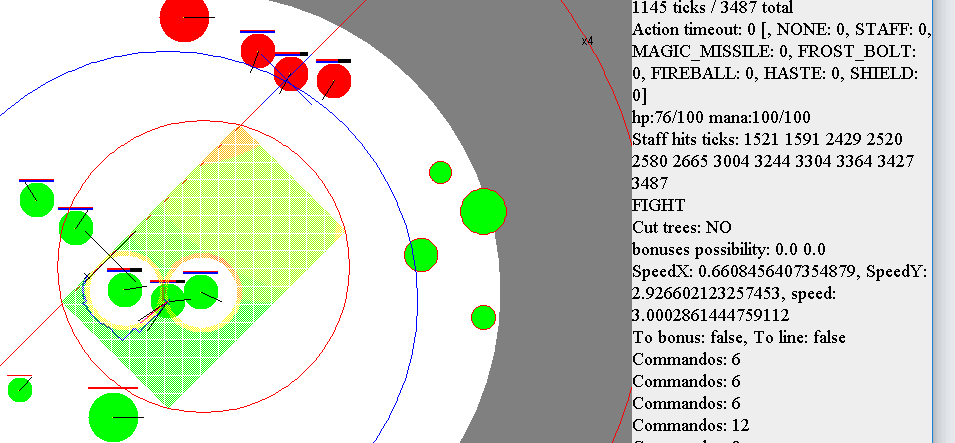
Опасность вокруг союзных магов при игре 2*5. Т.к. она отключалась, если находимся в «опасной» зоне — иногда помогала отступить, “расталкивая” своих магов. В конце гифки можно заметить зону “притяжения”. К своим магам.
Следующая вполне решаемая проблема, с которой столкнулся “пуш по миду”, была адаптивная стратегия от Ивана Тямгина tyamgin, которая возвращалась на защиту в 4 человека, увидев пятерых в атаке на центре. Но изначально делала это так, что все эти 4 мага вступали в бой каждый со своей стороны, как бы окружая моих. Попав в такое окружение, мои боты терялись и не могли сообразить, кого же лучше бить первым. И за время замешательства один его маг, который оставался на боковой линии, часто успевал дойти до моей базы и уничтожить её.
Для решения такой проблемы я начал выделять подобие “кластера” моих магов для атаки — собиралась группа для активных действий, которая состояла из всех более-менее целых юнитов, находящихся близко друг к другу (в пределах около 350 пикселей от среднего арифметического их координат). Если таковых находилось более двух — в среднем радиусе действия (~900 пикселей) искал магов, которые не находятся под своей вышкой и рядом с ними нет магов для помощи (максимум один, но для целей без таковой поддержки приоритет был больше). Цель, у которой пассивными навыками была выбрана скорость или имела статус ускорения, игнорировались, т.к. гоняться за ними выходило себе дороже. Если подходящие цели находились — мои маги всей толпой бежали в сторону бедолаги, довольно эффективно набирая себе опыт иотправляя заблудившихся магов на тот свет лишая отколовшихся от общей группы магов телесной оболочки. Для этого использовалась четвёртая “псевдо линия”, которая первоначально была сделана для сбора бонусов и смены линии. В ней ранее был предусмотрен достаточно сильный бонус за то, чтобы маг “шёл в нужном направлении”, которое задавалось просто координатой, куда мы хотим попасть. Агрессивная атака одиночных врагов впоследствии достаточно сильно помогала в боях против стратегий, которые упорно пытались ходить через лес и всячески окружать мои основные силы.
Следующая проблема — урон базы врага достаточно высок, и, разбив полностью центральную линию, мои частенько долго не решались на штурм. Так они могли дождаться, пока по другим линиям враги не дойдут до моей базы и не уничтожат её раньше, чем мои всё же решатся на бой. В целом нерешительность убирать не хотелось, ведь база врага действительно опасное место, но добавилось одно условие — если мы имеем подавляющее преимущество в численности или на любой из боковых линий была уничтожена моя вторая башня, то опасность от базы начинала игнорироваться и всем магам дружно было приказано заходить на вражескую базу с более удобной стороны с помощью всё той же четвёртой “псевдо линии”, которая дополнительно стимулировала данную атаку (при игре за академию это сторона, чуть правее вражеской базы, т.к. ближайшая к базе башня не так сильно мешает).
После этих улучшений проигрышей в боях 2*5 практически не осталось, и я сосредоточился на попытках написать альтернативные тактики на случай, если всё-таки вариант атаки по центру действительно начнут массово побеждать. Однако у моей стратегии не очень хорошо получалось противостоять моей же изначальной тактике на финал и после не очень многочисленных экспериментов на эту тему эту идею я всё-таки отбросил.
Пришла пятница — последний день перед первой частью финала. На работе был взят отгул, всё шло просто замечательно и ничто не предвещало беды. В четверг ночью моя стратегия всё ещё ощутимо более стабильно выигрывала, чем стратегии ближайших преследователей, и в пятницу я уже думал было расслабиться, но не тут то было. Антон Чумаченко (Antmsu), видимо не очень любивший всё это время спать по ночам, за время моего сна исправил некоторые недочёты в своей стратегии и теперь его стратегия почти постоянно стала меня побеждать. Расслабиться морально уже не получалось, и я начал искать подходы к тому, как сломить конкретно эту стратегию в честном бою. Ближе к вечеру успехов в этом с помощью небольших изменений достичь так и не получилось, а ломать стратегию, протестированную практически на всех финалистах, жутко не хотелось. К тому же после обеда меня также практически постоянно стал побеждать NighTurs, и ситуация стала выглядеть совсем уж удручающе по сравнению с тем, что было ещё в четверг вечером… В целом настроение в тот день намного проще передать через изображения, нежели словами.

Коммиты и ветки в локальном Git репозитории в последний день перед стартом финала. Единственный коммит в 4.30 PM, который ушёл дальше, не содержал ровным счётом никаких улучшений для стратегии.

Внимательно понаблюдав за поведением соперников в последние пару часов перед первой частью финала, я собрался с духом и попытался что-то изменить в микро управлении бота, опираясь на свои наблюдения. Изменения были незначительны и придали дополнительную агрессивность моей стратегии, однако запускать непроверенные изменения в финал против всех участников я не стал. В итоге воспользовался возможностью проверить ник соперника и только для Antmsu и NighTurs включал последние апдейты, всё равно всё выглядело так, что с ними в бою терять уже нечего.
Всем (включая меня) очень понравилась неожиданная стратегия от Кирилла Болонкина (core2duo), которая мне в первой части финала нанесла 6 поражений из 6, но проиграла все 6 боёв NighTurs, тем самым, как казалось на утро, нанеся мне практически контрольный удар в плане возможности вернуться на позицию хотя бы в топ 2. Посмотрев первые пару боёв, я решил, что ждать чуда смысла нет, и результаты лучше будет посмотреть утром. Я предполагал, что меня ожидает примерно третье место, но морально готовился к более плохому варианту.

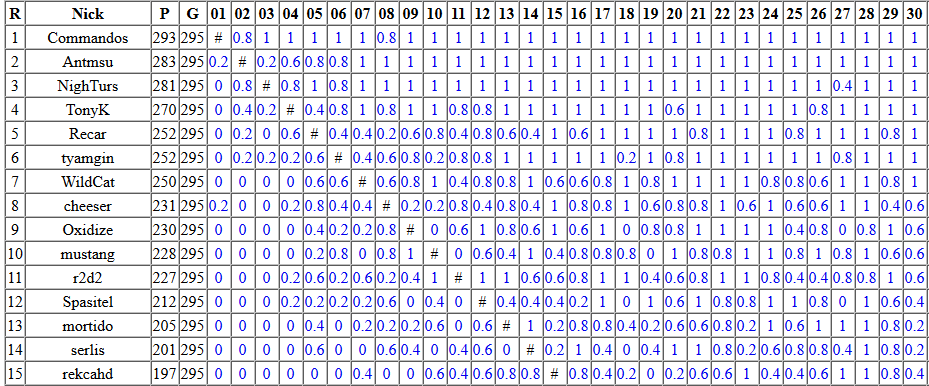
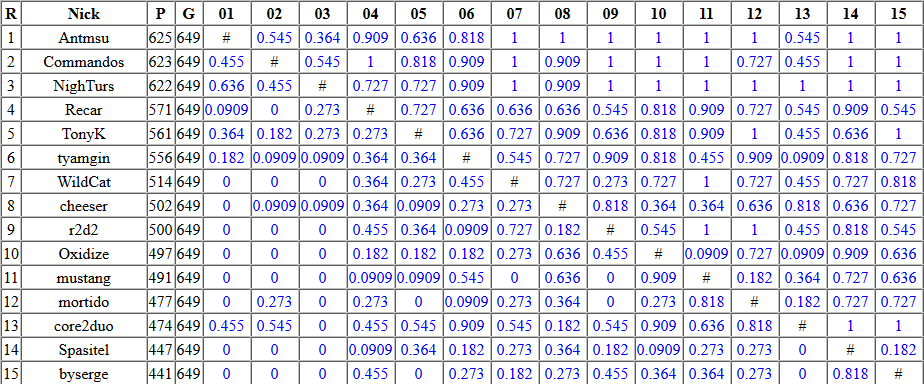
Результаты лучших участников первой части финала russian ai cup 2016. P — количество побед, G — количество игр. Мой ник в Russian Ai Cup — Commandos. Кликабельно.
Изучив промежуточные результаты финала после первой части, все, включая меня, сходились во мнении, что участники из топ 2 будут выяснять отношения “между собой”, а я с большой долей вероятности сохраню третью позицию. В какой-то мере это меня утешало, т.к. по результатам было видно, что хотя бы третье место потерять уже относительно сложно, но…Ipad? А зачем мне вообще Ipad? Я хочу MacBook! Хотя бы Air… В общем, проведя в относительно депрессивном состоянии всю пятницу я решил, что последние сутки перед второй частью финала терять на ожидание того, что же будет дальше, нельзя. И я абсолютно точно хочу подняться выше. Тем не менее, несколько часов были проведены в раздумьях, как же получить желаемый результат. Всего 12 и 13 игр было проиграно текущей двойкой лидеров финала, и я от них отставал на целых 12 и 11 игр соответственно. Даже если я начну побеждать их со 100% шансом, что выглядело маловероятно, этого всё равно не хватит, чтобы догнать их и тем более обогнать. И мной было принято решение просмотреть проигрыши со всеми игроками и исправить это. Мне нужен был практически 100%-ый результат. Да ну, это невозможно, может лучше на корпоратив сходи.
Первой, конечно же, обращала на себя внимание стратегия core2duo. Управление магами на микро уровне у него было достаточно слабое и можно было практически со 100% гарантией победы пойти на него в атаку в лоб. Это, на мой взгляд, идеальная тактика в данном случае, но всё ещё хотелось чего-то более универсального на случай появления клонов данной стратегии. Решение было простое — если на линиях, отличной от центральной, находится слишком много вражеских магов, я сильно повышал бонус за нахождение моих магов в точках, из которых они смогут наносить урон. С этим подходом моя стратегии практически постоянно побеждала при игре с core2duo, но ожидая новых подвохов от последнего для подстраховки добавил проверку: if (“core2duo”.equals(playerName)) — идём в прямую атаку на ближайшего вражеского мага, где бы тот ни находился. Кроме около 100% вероятности победы при текущих стратегиях это ещё и принесло дополнительную уверенность, что больше ничего плохого он мне сделать не сможет.
Вторым пунктом шёл единственный мой проигрыш стратегии участника GreenTea. В этой игре мои маги очень упорно не хотели идти на финальный штурм при равной численности, но гораздо, гораздо более потрёпанном сопернике. При рассмотрении этой игры более пристально с помощью дебага дополнительно нашёлся ещё один баг — при поиске “кластера” моих магов для создания атакующей группы в случае, если хотя бы один маг был слишком далеко, группа не могла быть найдена из-за проблемы в обновлении среднего арифметического позиций магов “кластера” при исключении самого дальнего из них. Исправив данный баг и дописав логику для форсирования атаки на вражескую базу в случае, если обороняющийся соперник имеет намного меньшее количество хит поинтов, я перешёл к рассмотрению следующих проблем.
Далее шли проигрыши участникам TonyK и tyamgin. Тестирование с последними на тот момент версиями TonyK не выявило сколь либо большого числа поражений, и я подумал, что в его стратегиях что-то было сломано. На всякий случай ту же слегка более агрессивную тактику, которая играла в первой части финала только с Antmsu и NighTurs, проверил и на нём. Т.к. видимых проблем не возникло — оставил всё как есть. То же самое мелкое изменение было применено и в боях с tyamgin. Визуально оно давало небольшой позитивный эффект, и по результатам проверок также было оставлено как есть.
Остальные 4 участника, с которыми я имел поражения в первой части финала, выделялись из общей кучи тем, что все они так же, как и я, всеми пятью магами шли по центральной линии. Это была львиная часть моих поражений (конечно, если забыть про стратегию core2duo), и решить всё это подбором коэффициентов и мелкими правками в микро контроле магов, как я это пытался сделать накануне в пятницу против Antmsu, мне представлялось очень маловероятным. Вдохновившись опытом, полученным от core2duo, я решил попытаться сделать для них нечто особенное. Было достаточно несложно заметить, что 3 из 4 этих стратегий на момент первой части финала (а перед второй частью финала все 4, что мне неплохо помогло) без остановки шли в атаку на первую же вышку врага вплоть до ближнего боя. План был прост — а что, если попытаться разбить целую группу атакующих на две части? К тому же когда они подбегают к моей вышке, то становятся уязвимы для захода с фланга… По плану не у всех из них будет возможность отступить в одном направлении, и максимально быстрое наступление в попытке прижать часть магов соперника к лесу может, в теории, принести желаемый результат.

План атаки с фланга. Красными стрелками обозначены мои планируемые передвижения, синими — ожидаемое поведение соперника. Кликабельно.
Для проверки этой теории изначально я модифицировал свою версию так, чтобы она игнорировала опасность от первой вышки и шла на неё в атаку. Затем моя изменённая стратегия запускалась с помощью local-runner против моей же версии, которая уже умела делать заход с фланга для данного случая. Результаты получились весьма убедительными — пусть и с потерями в виде вышки, а иногда ещё и 1 мага, но безрассудная атака с фланга чаще всего приводила к получению ощутимого преимущества в начале игры, и этого оказывалось достаточно, чтобы оставшаяся часть сражения практически стабильно проходила уже в пользу свежего обновления. Воодушевившись локальным успехом, я решил проверить, как данная идея будет работать в боевых условиях на mortido и ud1, т.к. по моим предположениям, они не станут тратить время на серьёзные попытки написать что-то, что ломало бы мой подход. Проверка в боевых условиях также была успешно пройдена, и я заменил данную стратегию предыдущим вариантом, чтобыне светить увеличить вероятность сюрприза для участников топ 2. Дальнейшее шлифование мелочей проходило с помощью local-runner, и уже примерно к 4 часам ночи реализация нового варианта атаки была завершена.
Для проверки на топ 2 участниках я залил обновлённую версию в 11.39, т.е. за 21 минуту до начала второй части финала. Тестирование на топ 2 было пройдено успешно (1 поражение из 4 игр, но, как оказалось, шанс на мою победу был даже выше), и в таком виде стратегия осталась до конца.
После запуска игр я уже был в состоянии выжатого лимона и ушёл вздремнуть. После небольшого отдыха меня ждало две новости, одна приятная и одна не очень. Приятная — моя стратегия действительно шла практически без поражений (всего одно поражение за две волны, а это 118 игр). Неприятная — тестирование проходило заметно медленней, чем в первый день, и было достаточно сомнительно, что волн будет столько же, сколько и в предыдущий… А по итогам первых волн казалось, что обогнать хотя бы одного из двух первых участников практически невозможно. Но тем не менее даже за 5 волн с большой долей везения моей стратегии всё же удалось занять вторую строчку в итоговом результате.
Результаты лучших участников второй части финала russian ai cup 2016. Кликабельно.
Окончательные результаты лучших участников финала russian ai cup 2016. Кликабельно.
Несмотря на выпадение из жизни на полтора месяца, однозначно не жалею, что не забросил идею в самом начале. Задача получилась очень объёмной и по мере реализации постоянно приходилось выбирать, какие особенности правил и в каких случаях учитывать, а какие стоит проигнорировать. Учесть в конечной реализации все нюансы было практически невозможно, что, пожалуй, являлось дополнительным интересным и сложным моментом в конкурсе, хотя финальный алгоритм и оставил ощущение незавершённости. Хотелось бы высказать организаторам RAIC благодарность за проведение настолько масштабного и и увлекательного конкурса, и, уже практически по традиции, особую благодарность хотелось бы высказать Роману Удовиченко (Romka) за создание общего чата, где многие участники находили для себя полезную информацию, весьма информативные таблицы с промежуточными результатами (можно видеть на скриншотах выше), которые помогли мне в подготовке к последней части финала, и за первоначальную вычитку данного поста.
UPD. Частично восстановил репозиторий. Пришлось подрезать пару первых коммитов. Также к жизни не возвращал все мёртвые бранчи.
Ежегодно компания Mail.ru проводит онлайн-чемпионат по программированию игровых стратегий (Russian AI Cup 2016). Я принимал участие в данном соревновании в 2012 году (СodeTanks) и, совсем немного, в 2013 (СodeTroopers). В этом году, изрядно наевшись веб разработкой, я решил попробовать принять участие ещё раз. Я изначально не надеялся (но, конечно же, очень хотел) занять какое-либо призовое место и в целом для меня это был скорее тест, насколько я ещё могу реализовать нечто интересное. О том, что из этого получилось, можно прочитать под катом.
Достаточно неслучайно заметив анонс грядущего соревнования на сайте russianaicup.ru, я начал готовиться. Имея опыт участия ранее, я посчитал, что шаблон для своего кастомного визуализатора мне очень пригодится и сэкономит немного времени во время самого соревнования. Вся подготовка в целом заключалась в написании своего визуализатора, который изначально умел выводить только несколько базовых фигур.
7 ноября, в день старта RAIC 2016, первое, что я сделал — открыл правила и стал читать, что же организаторы приготовили нам в этом году. DotA? Да ну, не может быть… Да точно DotA! После прочтения правил осталось стойкое ощущение, что кода писать надо будет много… Очень много. И осознание этого в самом начале не сильно придавало вдохновения. Также в этом году старт конкурса совпал с днём рождения моей жены, поэтому пришлось отложить начало разработки на день, ведь в ближайшие полтора месяца меня будет сложно выковырять из-за ПК. Возможно, это также помогло мне немного более точно осмыслить, каким будет мой бот в этом соревновании.
Первая неделя, или “во что я ввязываюсь…?”
Первые три вечера ушло на создание проекта, прикручивание линий, вдоль которых будем ходить в атаку, плохонький выбор одной из трёх линий (на старте игры — как у quick start guy — базовой стратегии, предоставляемой организаторами, после смерти — где врагов побольше и своих поменьше), а также прикручивание визуализатора, “скелет” которого был написан за неделю до RAIC. Дальше надо было учиться как-то ходить… Заниматься большим количеством геометрии было жутко лень, а пролазить в “щели” между миньонами, магами и деревьями таки хотелось… Т.к. других вариантов на ум не пришло, то решил сделать локальную “сетку”, по которой можно ходить, и заодно в неё заложить подсчёт опасности и полезности нахождения в той или иной точке.
Схема игровой карты. Линии, по которым стоит атаковать вражескую базу (top/bottom/middle lane), отделены друг от друга лесом.
Пятница и выходные прошли за раздумьем, стоит ли оно того или всё же не ввязываться в это дело… Но всё же к вечеру воскресенья что-то с движением было реализовано. Первый вариант сетки был с шагом 2 размером в 401 * 301 точку (расстояние 600 вперёд вдоль линии боя, 300 в сторону и 200 назад). В каждой точке этой сетки вёлся подсчёт score — “полезности нахождения” за вычетом “опасности нахождения” в ней. В конечном варианте ячейка сетки состояла из множества полей и учитывала опасность от миньонов, опасность от магов, опасность от зданий, полезность нахождения в зоне, из которой я могу атаковать врагов (были разделены на две разные переменные для ближнего и дальнего боя, в каждой из них учитывалось только лучшее значение), полезность нахождения в зоне вокруг покалеченных врагов (для получения опыта за их убийство) и дополнительные две переменные otherDanger и otherBonus для реализации
Изначальный вариант матрицы. Расстояние до переднего края матрицы — 600 “пикселей”. Направо и налево — 300, назад — 200. Расстояние между точками — 2. Матрица получилась чересчур большой. Количество точек в самой матрице — 401 * 301. Она всегда направлена вдоль линии сражения, независимо от ориентации мага.
Запуски на локал раннере показали, что что-то мой подход работает слишком медленно… По условиям соревнования на каждый тик стратегии выделялось 10 мсек, а по моим измерениям на локальной машине выходило ощутимо больше. Отфильтровал мир до необходимого минимума: живые юниты и башни на расстоянии 600 до моей локальной сетки, деревья — так, чтобы обсчёт учитывал их как препятствия, но добавлял как можно меньше “лишних” деревьев. Дополнительно увеличил шаг сетки до 3, и получил производительность более похожей на ту, что надо. Оптимизации всё ещё были необходимы, но на первое время решил, что
Хорошо, ходить можем, немного бояться вражеских магов и миньонов умеем… А как же бой? Хм… Создал лист целей, отфильтровал их так, чтобы деревья не мешали стрелять (попутно забывая, что отфильтрованы деревья так, чтобы посчитать их как препятствие на сетке опасности, чего явно недостаточно, если цель стоит сразу за деревом), задал целям приоритеты, зависящие от того, какой % хп цели остался. Приоритет магов и башен на первое время поставил в 5 и 6 раз выше, чем у миньонов. Затем учу бота поворачивать для выстрела — если мы можем с текущей позиции стрелять и количество тиков до перезарядки уже где-то на грани того, за сколько мы можем “довернуть” на цель — поворачиваемся к цели, иначе поворот в сторону движения.
Тестирование с local runner.
Поработав с локал раннером, с грустью понял — всё таки вариант пути не очень годится… Во время выхода из “опасных” зон сразу пытаемся бежать в оптимальную точку, но ведь от удара миньона можно просто убежать задом (скорость передвижения миньонов равна скорости движения мага задом и боком), если бежать строго от него. Учимся убегать от вражеских миньонов — теперь пытаемся бежать по прямой не к конечной точке, а к такой промежуточной точке на пути, опасность в которой ощутимо меньше опасности в текущей точке моего мага. Изменил поиск точки, к которой перемещаемся — теперь она выбирается не сразу, а по мере поиска путей по всей матрице, учитывая кроме score целевой точки ещё и опасность, которой мы подвергнемся по пути к ней. На этом этапе это была банально сумма всех опасностей * 0.02 (все коэффициенты с самого начала и до конца выбирались на глаз, менялись редко).
После реализации нового выбора пути и более детального тестирования в локал раннере
И всё ещё, пожалуй, бот не готов к первым боям. В ближнем бою маг
Жалкое зрелище, душераздирающее зрелище… Маг столбенеет при подходе вражеского мага (т.к. по всей матрице поиска становится слишком опасно), его зажимают миньоны, он застревает, пытаясь убежать за край карты, убегает в угол карты, откуда убежать получается только на свою базу через 1.2к тиков (время на возрождение)… Исправляю все эти недочёты, добавляя дополнительные штрафы за нахождение в точках около края карты, добавляем край карты как препятствие, убираю остолбенение, если везде очень опасно (сумма опасностей больше хп моего мага). Всё это немного помогает, и теперь, хотя всё равно эффект не очень, как-то жить можно. А тем временем топы уже вовсю бегают за бонусами.
Как научить бота ходить за бонусами делать всё что угодно, но только не то, что надо.
Что ж, надо и мне учиться бегать за бонусами… За них дают весьма немало очков. Только вот непонятно, как. Для начала решил научиться пользоваться скоростью по максимуму… Заодно задел на будущее — учимся учитывать все ауры и пассивные навыки, статус HASTENED (ускорение) — и теперь, если меня вдруг миньоны затолкают на бонус, я буду быстрее бегать! Затем, понаблюдав за боями с другими соперниками, понял, что я постоянно попадаю под вражеские башни… А один их выстрел это более трети хп мага. Добавил их положение в мире и запомнил время до следующего выстрела. Заодно сделал так, чтобы во время перезарядки башен мой маг подходил чуть ближе. Всё ещё плохо убегаем от миньонов, т.к. бежим строго по своей сетке, а её направление редко совпадает с направлением, в котором следовало бы убегать от миньона. В итоге выходит, что мой бот убегает от миньона “слегка наискосок”, а последний, направляясь строго на меня, отрыв постоянно сокращает. Решение — добавил локально рассмотрение нескольких направлений одного шага примерно в ту сторону, в которую мой бот считает, что стоит двигаться (направление к ближайшим точкам на пути + угол, который можно рассмотреть дополнительно)… Вот тут и структуры для расчёта очков в точке пригодятся. Выбираем точку из этого множества в первую очередь с большей полезностью нахождения в ней для себя, а во вторую — поближе к искомому направлению движения… Теперь можно нормально обходить по красивой окружности опасные зоны, а не дёргаться по принципу «шаг вперёд — шаг в сторону», да и убегать от миньонов теперь можно куда более эффективно ровно по прямой. Ещё добавим в матрицу опасность от зоны появления вражеских миньонов за некоторое количество времени до их появления, чтобы можно было вовремя отойти оттуда и не оказаться в их окружении…
(Кликабельно, внутри gif-ка)

Скриншот из визуализатора. Зелёный круг чуть с краю от центра разукрашенного прямоугольника (вокруг которого нет “белой” зоны, в которую нельзя шагнуть) — маг, которым управляет стратегия. Красные — враги, зелёные — свои. Синяя неровная линия от центра моего мага — путь, куда мы сейчас идём. Чёрные полоски из центра мага — какой угол рассматривается при попытке подобрать наилучший шаг. Розовая — направление, в котором на данный момент вероятнее всего лучше идти. Красная — выбранное направление для следующего шага.
Neo mod.
Проснувшись утром в субботу, был наполнен решимости что-то придумать с бонусами, но обнаружил, что мой бот добрался примерно до топ 100, и там неожиданно начали стрелять не в центр, а в краешек моего мага, почти в каждом рейтинговом бою жестоко и уверенно избивая его, пока тот не мог ничего ответить. Однако делать так же не хотелось, т.к. топы хоть ещё и не умеют уворачиваться, но точно скоро будут, а хочется то туда, наверх… План пришёл в голову простой и одновременно сложный — а не буду я делать так же, я попытаюсь просто уворачиваться, благо за те 12 тиков, которые летит снаряд, можно вполне себе неплохо отойти… Скорости мага недостаточно, если стреляют в центр, но вот от такой проблемы помочь может.
Для начала надо запоминать тик появления всех снарядов, чтобы впоследствии можно было подсчитать, куда максимум может долететь каждый из них. В финале в целом можно будет игнорировать все выстрелы от союзников, но в первых двух раундах игнорировать выстрелы не очень-то союзных магов не стоит. Т.к. конкуренция по очкам также работает и внутри одной команды, “союзные” маги тоже часто любят добивать своих (пламенный привет mortido). Затем проверяем, пересекается ли снаряд со мной, если я буду стоять на месте (расстояние до отрезка полёта снаряда меньше, чем сумма радиусов моего мага и снаряда, к которому дополнительно прибавляется расстояние, на которое я могу шагнуть, чтобы случайно не шагнуть под снаряд). Если хотя бы один снаряд может в меня попасть — пытаемся уклониться. Первым делом — подсчитаю, сколько чего бот “поймает”, если будет просто стоять на месте (вариант, когда просто боится шагнуть под снаряд). Этот базовый урон беру за начальный и пытаюсь отойти в любую сторону со скоростью, как если бы я шёл боком или задом. Также при этом учитывается суммарное количество очков в точках, через которые мы пройдём во время уворота (если стоим на месте — складываем одну и ту же точку то количество тиков, которое понадобится). Если на этом этапе не получилось увернуться от снаряда — пытаюсь бежать во все стороны на максимально возможной скорости (поворачивая в выбранную сторону). При попытках отойти или отбежать от снаряда также проверяю, что я не натыкаюсь на препятствие, допуская, что все миньоны двигаются прямолинейно всё время, а маги, здания и деревья стоят на месте. Если на текущем тике я упёрся в препятствие, на следующем тике я всё равно попытаюсь повторить шаг. Вдруг кто-нибудь да отойдёт… Получилось увернуться от снаряда? Блокируем поиск пути, перемещаемся в направлении, где урона получил бы поменьше и находиться побезопасней. А если при этом ещё поворот в определённую сторону помог убежать — блокируем управление поворотом бота на этом тике и крутим его в ту сторону, в которую бежим (поворачивает то мой в последнюю очередь, после расчёта выстрела).
Одновременно с написанием алгоритма уворота пришло осознание, что стрелять в центр не самый лучший вариант… Лучше стрелять в точку чуть спереди от центра мага, тогда убегать надо дольше и одинаково долго и вперёд, и назад. Решил оставить это знание на будущее.
И всё же — бонусы.
Так шаг за шагом, написав ворох улучшений (в т.ч. очередное улучшение способа определения, когда же стоит рубить эти ненавистные мной на пару с ботом деревья), я всё же сел писать именно поход за бонусами. К тому времени в топе за них началась настоящая драка и нечасто можно было любой бонус спокойно и безнаказанно забрать. Стал запоминать, где в последний раз видели вражеских магов, чтобы не идти в сторону бонуса в случае, если с большой вероятностью они смогут его забрать раньше меня. На тиках, кратных 2500, вероятность нахождения бонусов на своих местах устанавливалась в 1. Если какой-либо вражеский маг вне зоны видимости мог за время, пока он не виден, добежать до бонуса, то вероятность нахождения бонуса в точке постепенно уменьшалась. И чем ближе маг был к бонусу в последний раз перед тем, как его видели — тем сильнее падала вероятность того, что бонус всё ещё находится на своём месте. Также стал запоминать положение вражеских миньонов, чтобы можно было возвращаться в точку на линии их движения на расстояние своего выстрела. В коде добавилась четвёртая “линия” — она просто задавала направление, в котором мне хочется идти. Также, при активировании этой линии, в матрице опасностей точкам, ближе к целевой, начислял дополнительный бонус. Теперь бот двигался в ту сторону и не слишком сильно застревал для добивания вражеских миньонов, магов или башен.
(Кликабельно, внутри gif-ка)

Пкреключение на четвёртую «псевдо» линию. Она задавала направление матрицы строго в точку, к которой было необходимо идти. В данном случае маг немного заранее отправился к ближайшему бонусу через лес.
Одновременно с написанием походов за бонусами добавил возможность смены линии атаки кроме как на момент смерти (изначальная реализация не подразумевала такой возможности в других ситуациях). Т.к. теперь у меня есть запомненные данные по местонахождению всех бывших в зоне видимости юнитов, то бот стал лучше понимать, на какой из линий наша оборона слабее нападающих (на это перестал влиять временный выход вражеских магов и миньонов из поля зрения). В целом с этого момента и до конца раунда 2 выбор линии выглядел как “идём туда, где врагов побольше, а своих магов поменьше”.
Как последний штрих, но всё-таки немного отдельно стоящий, я всё же в третий раз переписал алгоритм поиска лучшей позиции и пути к ней. В последней и финальной его итерации лучшей точкой считалась та, где сумма среднего score на пути к ней и score в самой точке была максимальной. Для этого сначала опять же приоритетной очередью искал путь по матрице, значения score в которой для этого поиска было уменьшено на максимальное его значение (чтобы избежать положительных “петель”). После такого изменения в ходьбе бота обнаружился серьёзный недостаток — он стал очень любить бегать вокруг вражеских миньонов и зданий, часто заходя им за спину, чем сам себе отрезал путь к отступлению от вражеских магов. Разделил поля опасности от миньонов на 2 части: теперь кроме зоны атаки дополнительно выделялась зона, в которой миньон будет атаковать меня (минимум из view range и расстояния до ближайшего союзного мне юнита). Этим мне удалось избавиться от данной проблемы, и выбираемый моим ботом путь теперь стал выглядеть ощутимо более логичным, чем ранее.
(Кликабельно, внутри gif-ка)
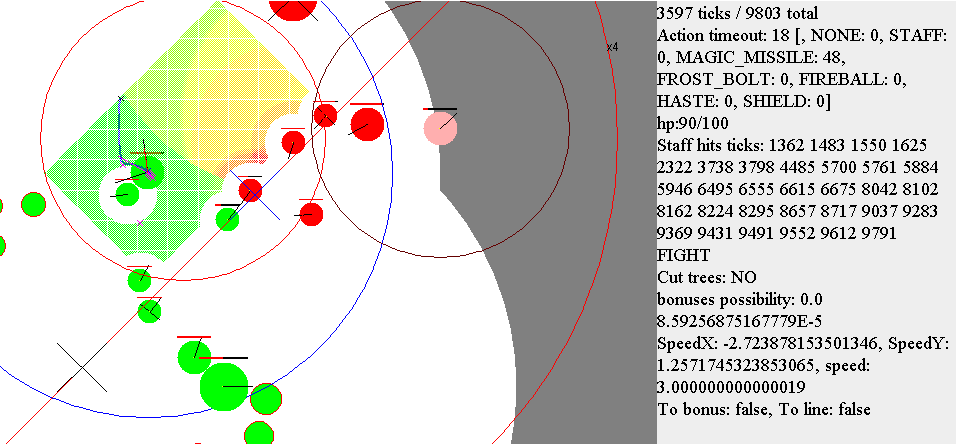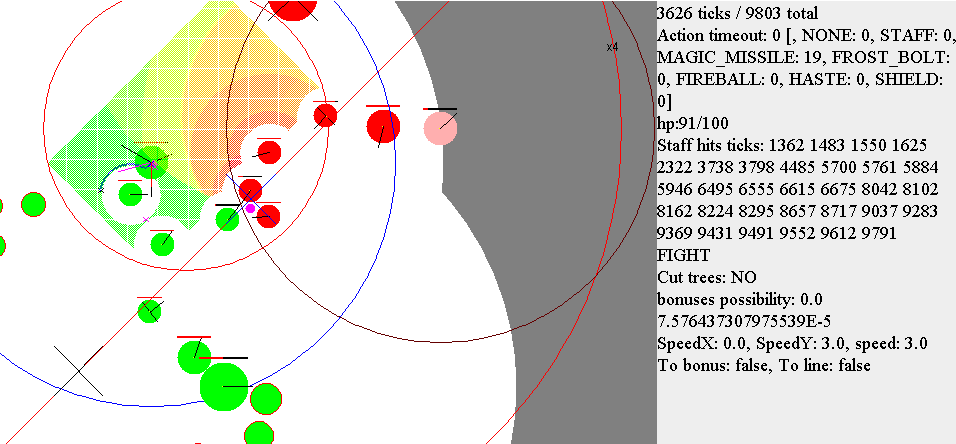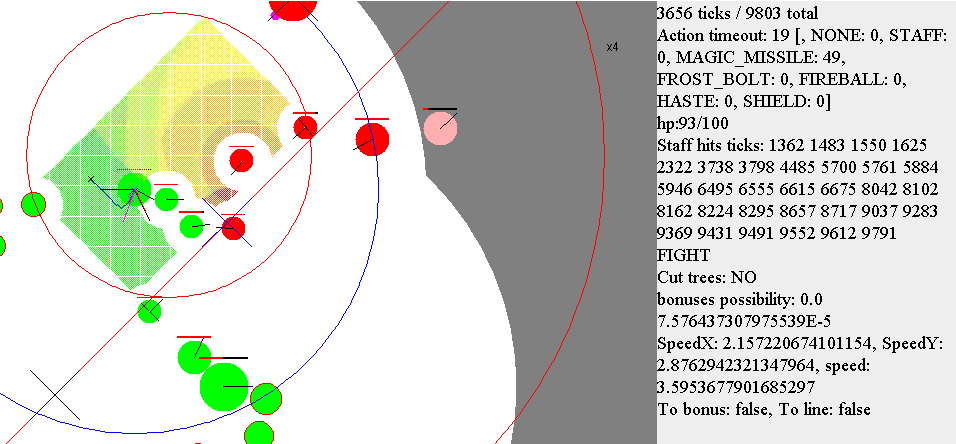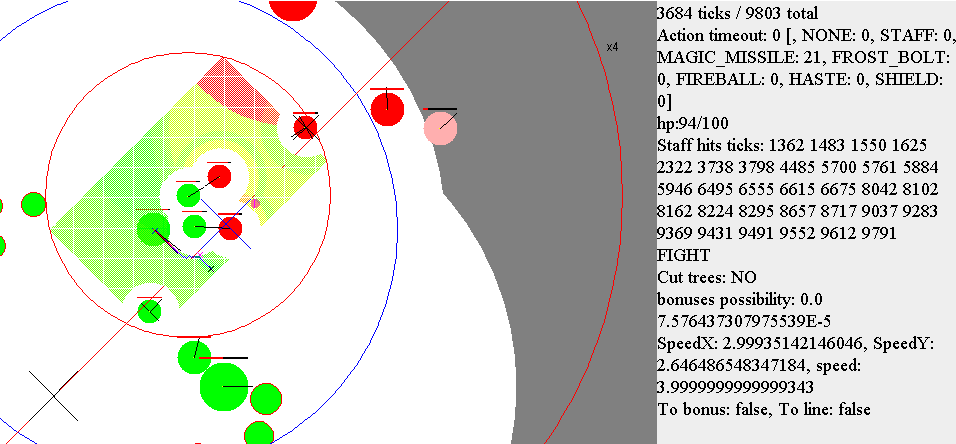
Скриншот из визуализатора. В данном случае алгоритм уворота заблокировал контроль поворота мага и сам поворачивает в сторону бега (статус RUN_FROM_PROJECTILE). Также видно, что бот запомнил последнее положение одного из вражеских магов. В дополнение рисуется ориентировочное максимальное расстояние, на которое данный маг мог убежать.
С этого момента и до самого раунда 1 больше особых улучшений не делалось. Исправлялись баги и серьёзные недочёты в коэффициентах. Постепенно рейтинг моего бота рос, пока не обосновался в десятке. На этом этапе можно было отметить, что % побед у моего бота весьма мал по сравнению с другими участниками из топа песочницы. Видимо осторожное отношение к бонусам не давало набирать максимальное количество очков, но выживаемость у мага была на более-менее приемлемом уровне, за счёт чего свои очки он стабильно набирал.
После первого раунда.
По итогам первого раунда я занял 8 строчку в рейтинге, что для меня оказалось приятной неожиданностью. Правила раунда 2 отличались от правил раунда 1 наличием возможности изучения и применения навыков. В последний день перед запуском в песочнице игр по правилам 2 раунда была прикручена возможность стрельбы ледяными стрелами. В первый же вечер на фоне того, что мало какие стратегии умели пользоваться навыками и уворачиваться, выглядело весьма впечатляюще. Однако… Спустя всего 1 день стало очевидно, что против ботов, выбравших файрбол в качестве первой ульты, сражаться получается плохо. Попытки исправить это коэффициентами и добавлением учёта радиуса взрыва от файрбола в алгоритм уворота ни к чему не привели. Не можешь победить врага — возглавь его. Следующим этапом стало написание стрельбы файрболом. В общем то ничего лучше перебора выстрела вокруг стоящих на месте миньонов (так, чтобы задеть последних краем файрбола и краем взрыва), зданий и всех вражеских магов (при этом считая, что последние всегда оптимально пытаются от взрыва убежать) быстро не придумалось и как временный вариант был сделан именно такой перебор. Учитывались только те варианты выстрела, которые я могу сделать с текущим радиусом каста. Но… Нет ничего более постоянного, чем временное. До самого финала алгоритм перебора остался точно таким же, за исключением уточнения, может ли вражеский маг убежать от моего файрбола или нет.
После вполне удачного тестирования использования файрбола на полях сражений, я заполучил первое место в песочнице и решил заняться улучшением того, что уже было написано. Написал класс WizardsInfo, в котором хранилась информация о пассивных навыыках, ультах, действующих на мага аурах. Переключил код, где использовалась подобная информация, на использование нового класса. И, как обнаружилось через целую неделю, серьёзно сломал свои увороты. При отсутствии статуса ускорения бот при симуляции попыток увернуться пытался сделать это на скорости на 30% меньше, чем у него было на самом деле. Заметил я это совсем не сразу потому, что в общем-то они работали, но стали делать своё дело намного хуже.
По итогам просмотра боёв на сайте, где меня часто убивали агрессивные стратегии, окажись они вдвоём на меня одного, для улучшения отступление был добавлен разворот матрицы поиска пути на 180 градусов (т.е. она в таком случае считалась на большее расстояние назад, чем вперёд), если мой бот считал, что находится в опасности (например, вышел на двоих вражеских магов и рядом со мной нет союзников). Исправил атаку неразрушимых зданий (по правилам нельзя было нанести вред второй башне на линии, не уничтожив первую, однако вторая башня из соседней линии была достаточно близко, чтобы бот отвлекался на неё). Было очень много попыток улучшить ситуацию с помощью изменения влияния врагов на score в матрице. Из явно позитивных изменений — при расчёте области опасности от вражеских магов стал учитываться угол их поворота, кроме кулдаунов умений вражеских магов стало учитываться также наличие маны и время её восстановления. Полностью переписана система таргетинга с той целью, чтобы маг более аккуратно выбирал, каким заклинанием он воспользуется в следующий раз (например, зачем вообще тратить ману даже на базовые магические ракеты, если у нас есть файрбол, а маны не осталось? Можно же бить посохом или просто стоять в сторонке). Добавлен учёт возможности уворота вражеского мага от моего выстрела. В расчёте выстрела с помощью базового заклинания и ледяной стрелы для вражеских магов теперь стал пытаться выстрелить в две точки — центр цели и в точку, при стрельбе в которую сбоку убегать одинаково долго и вперёд, и назад (эта точка находится чуть спереди от центра мага). Тут я использовал знание, полученное при написании алгоритма уворота. А рейтинг всё таял и таял, отчего становилось всё грустнее и грустнее.
И всё-таки, через неделю после поломки алгоритма уклонения я, рассматривая очередной бой через свой визуализатор, обнаружил, что мой бот, запустив логику уклонения и спокойно и аккуратно уходя от выпущенного снаряда “в чистом поле”, вдруг неожиданно стал считать, что уклониться-то от снаряда он не может, и продолжил бой, как ни в чём не бывало поймав порцию урона. Это заставило меня перепроверить конкретно данную ситуацию. Баг, ставший виновником недельной грусти и печали, был локализован и жестоко наказан.
Подготовка к раунду 2.
После исправления проблемы в алгоритме уворота рейтинг снова начал расти, и я перестал бояться не пройти в финал. Однако за время, необходимое для подготовки к раунду 2, хотелось бы научиться пользоваться всеми ультами, чтобы потом можно было их использовать в финале. Но сначала… Мой маг всё ещё очень пассивно стоит на линии и не особо предпринимает попыток к атаке вражеских магов, которые держатся на расстоянии. И это хотелось бы исправить. На прошлой неделе была переписана система таргетинга, и теперь в неё можно было более или менее легко вставить
А далее… За оставшееся время до включения в песочнице правил финала научил мага использовать заклинание ускорения и щита, отрегулировал использование всех боевых заклинаний вроде фростболта, исправил очередную проблему с застреванием в деревьях (которая обнаружилась почти прямо перед раундом 2), и… Для случая, если количество врагов на линии бота больше, чем количество союзников, учитывая самого бота, включил изучение ветки навыков, которая отвечает за скорость бега. И тут был замечен баг, исправление которого было отправлено в 0:00:01, т.е. с опозданием всего на одну секунду. А именно — незадолго до 2 раунда я таки решил научить своего бота накладывать заклинание ускорения на союзников, но сломал наложение этого заклинания на себя. И если на линии был бой 2 на 3, то всё было хорошо (т.к. по правилам при наложении заклинания ускорения на союзника маг, который его накладывает, также получает копию заклинания на себя), то в бою 1 на 2 данная проблема была таки весьма критична. Проблема дала о себе знать буквально в первые же бои в первой части второго раунда, т.к. выбор линии у моего бота до сих пор работал по алгоритму, реализованному для раунда 1, т.е. он выбирал ту линию, где меньше всего своих. Но это не помешало ему занять место в верхних строчках по итогу первой части второго раунда.
Ко второй части раунда была добавлена логика поиска целей для файрбола за зоной каста мага (одновременно с доработкой логики набегания для выстрела при его использовании), исправлены очередные замеченные проблемы с застреванием в деревьях (да, деревья всё ещё побеждали моего бота). Логика применения заклинаний стала гораздо лучше учитывать то, когда же необходимое количества маны восстановится для очередного заклинания. Уже после запуска второй части раунда 2 была немного подправлена стрельба по миньонам (теперь стрелял в передний край, т.е. туда, куда миньон смотрит. При стрельбе в центр миньон мог отбежать от снаряда, если бежал в сторону от нас).
Подготовка к финалу.
В финале правила отличались тем, что теперь всеми магами за одну из сторон управляет стратегия одного человека, что открывало новые просторы для командной игры. Первое, что я попытался сделать — скопировать исходники для раунда 2 и положить их рядом, чтобы запускать их в случае, если игра идёт по правилам раунда 2, т.к. усложнять логику, делая зависимость от текущих правил игры не хотелось совсем. Но…. Система решила, что мои решения принимать она больше не хочет, и несколько часов было потрачено на поиски причины, почему же система выдаёт ошибку о том, что я её присылаю «некорректный архив»… Если бы не общий чат, то поиск причины мог бы затянуться и на гораздо большее время. А оказалось — система просто не хочет принимать исходники, которые в распакованном варианте занимают более мегабайта на диске. Как я умудрился написать больше, чем на мегабайт??? В общем,
Исправив проблему с навыками и убрав групповое хождение за бонусами (теперь за бонусом ходил только ближайший из моих магов), приступил к написанию группового взаимодействия. Времени было выделено по сравнению с другими раундами ощутимо меньше (всего неделя), а писать надо было по сути нечто совершенно новое. Взаимодействие между союзниками в раундах 1 и 2 было сильно затруднено ввиду сильной разности стратегий, поэтому мной оно писалось отдельно именно для финала.
Первой проблемой, с которой столкнулся “пуш по миду”, была перегруженность линии союзными магами, которые мешали друг другу уворачиваться от снарядов соперников и часто блокировали пути отхода на безопасное расстояние от врагов. Решение было достаточно простым и очевидным — добавил штраф за нахождение слишком близко с союзными магами, который игнорировался, когда текущий маг сам находился в опасности. Теперь мои маги не мешали друг другу уворачиваться, а если кто-либо из моих хотел отступить в более безопасное место, он как бы “расталкивал” остальных. Вместе с этой правкой добавилась ещё одна — сделал дополнительное положительное поле на расстоянии в 600 от каждого союзного мага, благодаря чему в поведении ботов оставалось достаточно свободы, но разбегаться слишком далеко друг от друга они уже не хотели.
(Кликабельно, внутри gif-ка)

Опасность вокруг союзных магов при игре 2*5. Т.к. она отключалась, если находимся в «опасной» зоне — иногда помогала отступить, “расталкивая” своих магов. В конце гифки можно заметить зону “притяжения”. К своим магам.
Следующая вполне решаемая проблема, с которой столкнулся “пуш по миду”, была адаптивная стратегия от Ивана Тямгина tyamgin, которая возвращалась на защиту в 4 человека, увидев пятерых в атаке на центре. Но изначально делала это так, что все эти 4 мага вступали в бой каждый со своей стороны, как бы окружая моих. Попав в такое окружение, мои боты терялись и не могли сообразить, кого же лучше бить первым. И за время замешательства один его маг, который оставался на боковой линии, часто успевал дойти до моей базы и уничтожить её.
Для решения такой проблемы я начал выделять подобие “кластера” моих магов для атаки — собиралась группа для активных действий, которая состояла из всех более-менее целых юнитов, находящихся близко друг к другу (в пределах около 350 пикселей от среднего арифметического их координат). Если таковых находилось более двух — в среднем радиусе действия (~900 пикселей) искал магов, которые не находятся под своей вышкой и рядом с ними нет магов для помощи (максимум один, но для целей без таковой поддержки приоритет был больше). Цель, у которой пассивными навыками была выбрана скорость или имела статус ускорения, игнорировались, т.к. гоняться за ними выходило себе дороже. Если подходящие цели находились — мои маги всей толпой бежали в сторону бедолаги, довольно эффективно набирая себе опыт и
Следующая проблема — урон базы врага достаточно высок, и, разбив полностью центральную линию, мои частенько долго не решались на штурм. Так они могли дождаться, пока по другим линиям враги не дойдут до моей базы и не уничтожат её раньше, чем мои всё же решатся на бой. В целом нерешительность убирать не хотелось, ведь база врага действительно опасное место, но добавилось одно условие — если мы имеем подавляющее преимущество в численности или на любой из боковых линий была уничтожена моя вторая башня, то опасность от базы начинала игнорироваться и всем магам дружно было приказано заходить на вражескую базу с более удобной стороны с помощью всё той же четвёртой “псевдо линии”, которая дополнительно стимулировала данную атаку (при игре за академию это сторона, чуть правее вражеской базы, т.к. ближайшая к базе башня не так сильно мешает).
После этих улучшений проигрышей в боях 2*5 практически не осталось, и я сосредоточился на попытках написать альтернативные тактики на случай, если всё-таки вариант атаки по центру действительно начнут массово побеждать. Однако у моей стратегии не очень хорошо получалось противостоять моей же изначальной тактике на финал и после не очень многочисленных экспериментов на эту тему эту идею я всё-таки отбросил.
Финал
Пришла пятница — последний день перед первой частью финала. На работе был взят отгул, всё шло просто замечательно и ничто не предвещало беды. В четверг ночью моя стратегия всё ещё ощутимо более стабильно выигрывала, чем стратегии ближайших преследователей, и в пятницу я уже думал было расслабиться, но не тут то было. Антон Чумаченко (Antmsu), видимо не очень любивший всё это время спать по ночам, за время моего сна исправил некоторые недочёты в своей стратегии и теперь его стратегия почти постоянно стала меня побеждать. Расслабиться морально уже не получалось, и я начал искать подходы к тому, как сломить конкретно эту стратегию в честном бою. Ближе к вечеру успехов в этом с помощью небольших изменений достичь так и не получилось, а ломать стратегию, протестированную практически на всех финалистах, жутко не хотелось. К тому же после обеда меня также практически постоянно стал побеждать NighTurs, и ситуация стала выглядеть совсем уж удручающе по сравнению с тем, что было ещё в четверг вечером… В целом настроение в тот день намного проще передать через изображения, нежели словами.
Коммиты и ветки в локальном Git репозитории в последний день перед стартом финала. Единственный коммит в 4.30 PM, который ушёл дальше, не содержал ровным счётом никаких улучшений для стратегии.
Внимательно понаблюдав за поведением соперников в последние пару часов перед первой частью финала, я собрался с духом и попытался что-то изменить в микро управлении бота, опираясь на свои наблюдения. Изменения были незначительны и придали дополнительную агрессивность моей стратегии, однако запускать непроверенные изменения в финал против всех участников я не стал. В итоге воспользовался возможностью проверить ник соперника и только для Antmsu и NighTurs включал последние апдейты, всё равно всё выглядело так, что с ними в бою терять уже нечего.
Всем (включая меня) очень понравилась неожиданная стратегия от Кирилла Болонкина (core2duo), которая мне в первой части финала нанесла 6 поражений из 6, но проиграла все 6 боёв NighTurs, тем самым, как казалось на утро, нанеся мне практически контрольный удар в плане возможности вернуться на позицию хотя бы в топ 2. Посмотрев первые пару боёв, я решил, что ждать чуда смысла нет, и результаты лучше будет посмотреть утром. Я предполагал, что меня ожидает примерно третье место, но морально готовился к более плохому варианту.

Результаты лучших участников первой части финала russian ai cup 2016. P — количество побед, G — количество игр. Мой ник в Russian Ai Cup — Commandos. Кликабельно.
The last stand.
Изучив промежуточные результаты финала после первой части, все, включая меня, сходились во мнении, что участники из топ 2 будут выяснять отношения “между собой”, а я с большой долей вероятности сохраню третью позицию. В какой-то мере это меня утешало, т.к. по результатам было видно, что хотя бы третье место потерять уже относительно сложно, но…
Первой, конечно же, обращала на себя внимание стратегия core2duo. Управление магами на микро уровне у него было достаточно слабое и можно было практически со 100% гарантией победы пойти на него в атаку в лоб. Это, на мой взгляд, идеальная тактика в данном случае, но всё ещё хотелось чего-то более универсального на случай появления клонов данной стратегии. Решение было простое — если на линиях, отличной от центральной, находится слишком много вражеских магов, я сильно повышал бонус за нахождение моих магов в точках, из которых они смогут наносить урон. С этим подходом моя стратегии практически постоянно побеждала при игре с core2duo, но ожидая новых подвохов от последнего для подстраховки добавил проверку: if (“core2duo”.equals(playerName)) — идём в прямую атаку на ближайшего вражеского мага, где бы тот ни находился. Кроме около 100% вероятности победы при текущих стратегиях это ещё и принесло дополнительную уверенность, что больше ничего плохого он мне сделать не сможет.
Вторым пунктом шёл единственный мой проигрыш стратегии участника GreenTea. В этой игре мои маги очень упорно не хотели идти на финальный штурм при равной численности, но гораздо, гораздо более потрёпанном сопернике. При рассмотрении этой игры более пристально с помощью дебага дополнительно нашёлся ещё один баг — при поиске “кластера” моих магов для создания атакующей группы в случае, если хотя бы один маг был слишком далеко, группа не могла быть найдена из-за проблемы в обновлении среднего арифметического позиций магов “кластера” при исключении самого дальнего из них. Исправив данный баг и дописав логику для форсирования атаки на вражескую базу в случае, если обороняющийся соперник имеет намного меньшее количество хит поинтов, я перешёл к рассмотрению следующих проблем.
Далее шли проигрыши участникам TonyK и tyamgin. Тестирование с последними на тот момент версиями TonyK не выявило сколь либо большого числа поражений, и я подумал, что в его стратегиях что-то было сломано. На всякий случай ту же слегка более агрессивную тактику, которая играла в первой части финала только с Antmsu и NighTurs, проверил и на нём. Т.к. видимых проблем не возникло — оставил всё как есть. То же самое мелкое изменение было применено и в боях с tyamgin. Визуально оно давало небольшой позитивный эффект, и по результатам проверок также было оставлено как есть.
Остальные 4 участника, с которыми я имел поражения в первой части финала, выделялись из общей кучи тем, что все они так же, как и я, всеми пятью магами шли по центральной линии. Это была львиная часть моих поражений (конечно, если забыть про стратегию core2duo), и решить всё это подбором коэффициентов и мелкими правками в микро контроле магов, как я это пытался сделать накануне в пятницу против Antmsu, мне представлялось очень маловероятным. Вдохновившись опытом, полученным от core2duo, я решил попытаться сделать для них нечто особенное. Было достаточно несложно заметить, что 3 из 4 этих стратегий на момент первой части финала (а перед второй частью финала все 4, что мне неплохо помогло) без остановки шли в атаку на первую же вышку врага вплоть до ближнего боя. План был прост — а что, если попытаться разбить целую группу атакующих на две части? К тому же когда они подбегают к моей вышке, то становятся уязвимы для захода с фланга… По плану не у всех из них будет возможность отступить в одном направлении, и максимально быстрое наступление в попытке прижать часть магов соперника к лесу может, в теории, принести желаемый результат.
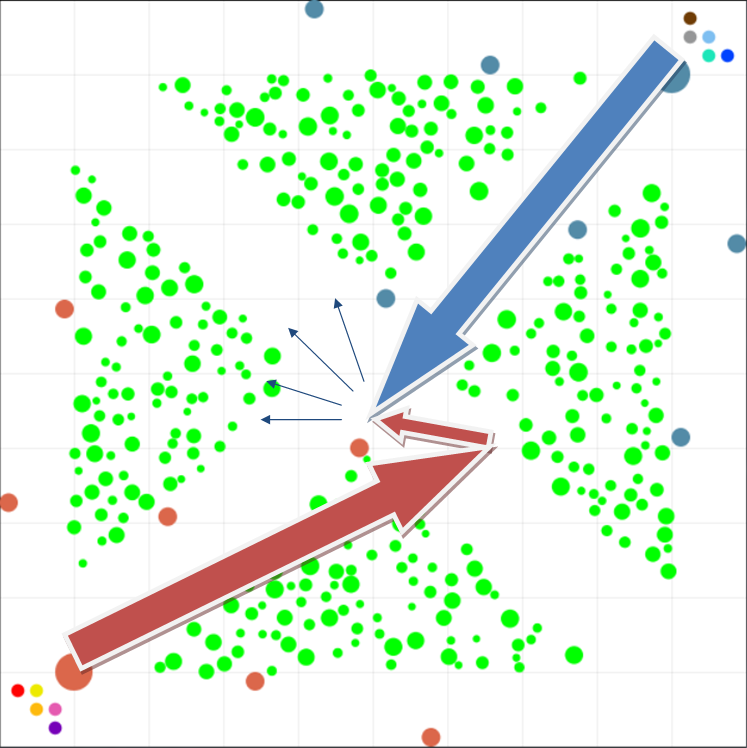
План атаки с фланга. Красными стрелками обозначены мои планируемые передвижения, синими — ожидаемое поведение соперника. Кликабельно.
Для проверки этой теории изначально я модифицировал свою версию так, чтобы она игнорировала опасность от первой вышки и шла на неё в атаку. Затем моя изменённая стратегия запускалась с помощью local-runner против моей же версии, которая уже умела делать заход с фланга для данного случая. Результаты получились весьма убедительными — пусть и с потерями в виде вышки, а иногда ещё и 1 мага, но безрассудная атака с фланга чаще всего приводила к получению ощутимого преимущества в начале игры, и этого оказывалось достаточно, чтобы оставшаяся часть сражения практически стабильно проходила уже в пользу свежего обновления. Воодушевившись локальным успехом, я решил проверить, как данная идея будет работать в боевых условиях на mortido и ud1, т.к. по моим предположениям, они не станут тратить время на серьёзные попытки написать что-то, что ломало бы мой подход. Проверка в боевых условиях также была успешно пройдена, и я заменил данную стратегию предыдущим вариантом, чтобы
Для проверки на топ 2 участниках я залил обновлённую версию в 11.39, т.е. за 21 минуту до начала второй части финала. Тестирование на топ 2 было пройдено успешно (1 поражение из 4 игр, но, как оказалось, шанс на мою победу был даже выше), и в таком виде стратегия осталась до конца.
После запуска игр я уже был в состоянии выжатого лимона и ушёл вздремнуть. После небольшого отдыха меня ждало две новости, одна приятная и одна не очень. Приятная — моя стратегия действительно шла практически без поражений (всего одно поражение за две волны, а это 118 игр). Неприятная — тестирование проходило заметно медленней, чем в первый день, и было достаточно сомнительно, что волн будет столько же, сколько и в предыдущий… А по итогам первых волн казалось, что обогнать хотя бы одного из двух первых участников практически невозможно. Но тем не менее даже за 5 волн с большой долей везения моей стратегии всё же удалось занять вторую строчку в итоговом результате.

Результаты лучших участников второй части финала russian ai cup 2016. Кликабельно.
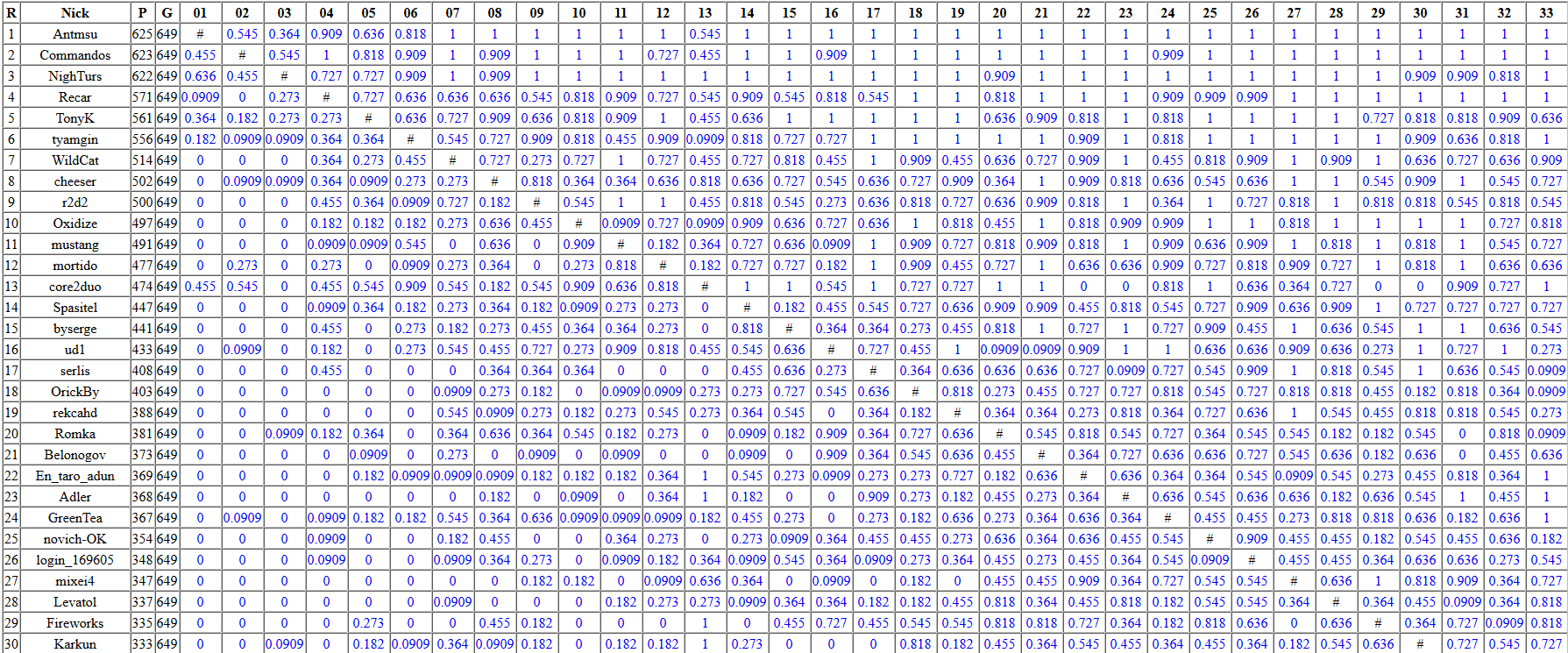
Окончательные результаты лучших участников финала russian ai cup 2016. Кликабельно.
Несмотря на выпадение из жизни на полтора месяца, однозначно не жалею, что не забросил идею в самом начале. Задача получилась очень объёмной и по мере реализации постоянно приходилось выбирать, какие особенности правил и в каких случаях учитывать, а какие стоит проигнорировать. Учесть в конечной реализации все нюансы было практически невозможно, что, пожалуй, являлось дополнительным интересным и сложным моментом в конкурсе, хотя финальный алгоритм и оставил ощущение незавершённости. Хотелось бы высказать организаторам RAIC благодарность за проведение настолько масштабного и и увлекательного конкурса, и, уже практически по традиции, особую благодарность хотелось бы высказать Роману Удовиченко (Romka) за создание общего чата, где многие участники находили для себя полезную информацию, весьма информативные таблицы с промежуточными результатами (можно видеть на скриншотах выше), которые помогли мне в подготовке к последней части финала, и за первоначальную вычитку данного поста.
UPD. Частично восстановил репозиторий. Пришлось подрезать пару первых коммитов. Также к жизни не возвращал все мёртвые бранчи.

