Подвернулась мне задачка разработать универсальный каталог товаров и услуг, по совместительству каталог предприятий, документов и чего угодно ещё. В работе этот «опыт» не пригодился, а идея хорошая, по-моему скромному мнению :) Хочется поделиться, и послушать критику.
Каталог подразумевает упорядоченность — иерархию, подразумевает непосредственно хранение информации, и конечно поиск, наверное аналитику… что-то ещё? Больше ничего в голову не приходит.
Теперь по пунктам.
Однозначно группировка информации будет древовидной, от абстрактного «Каталог» к более частному, к более конкретному (например «молоток»). Уровень детализации может быть любым, не будем себя держать в рамках «раздел», «подраздел», «категория», «подкатегория», пусть глубина ветвления будет бесконечной.
Информация будет храниться в какой то СУБД, для работы с иерархией эта СУБД должна уметь иерархические запросы, таких СУБД не мало, из бесплатных самая попсовая это PostgreSQL.
DDL таблички Дерево Элементов:
id — идентификатор строки таблицы.
element_tree_id — ссылка на родительский элемент дерева.
is_hidden — флаг удалённой записи ( 0 — действительная запись, 1 — удалённая), почему для записи только поднимается флаг, вместо удаления? потому что когда встречаешь в логах идентификатор и тебе хочется посмотреть что он из себя представляет, очень удобно сделать селелект в текущей базе, вместо того что бы делать этот селект в бэкапе (и не факт что в этом бэкапе эта запись найдётся).
insert_date — дата добавления записи, удобно когда ты знаешь — это 100 летняя запись или она вставилась пять минут назад в результате не удачного инсерта.
Конечно людям которые хорошо знакомы с системой всё это (is_hidden ,insert_date) не очень надо, но для тех кто смотрит на систему как баране на новые ворота, эти поля очень пригодятся, я в своей практике обычно в роли барана :)
CONSTRAINT fk_element_tree — внешний ключ к самой себе — указатель на родительский элемент.
INDEX ix_element_tree_element_tree_id_id — индекс для поиска дочерних веток (узлов потомков), если родителя мы найдём по первичному ключу, то для ускоренного поиска потомков нам надо завести отдельный индекс.
Как мог заметить кто то опытный и продвинутый, в таблице нет колонок для имени элемента. А почему? А потому что иерархия это только иерархия, и упорядочены не узлы дерева, а те таблицы которые к иерархии пристыкованы, поэтому имена в таблицах, а в иерархии только группировка элементов.
В конечном итоге любой каталог это перечень отдельных рубрик. Рубрика это некая группа сущностей обладающих уникальным набором характеристик. То есть имеем отношение собственно Сущности и сгруппированные сущности — Рубрика, и кроме того Рубрика является ещё и группировкой для уникальных Характеристик этих Сущностей.
То есть информация разделяется на три части — Сущность, Характеристика, Рубрика, где Рубрика это точка соединения нескольких Сущностей и Характеристик.
На языке СУБД это звучит так:
Таблица Рубрики
Таблица Сущностей (некая Штука, которая может оказаться как товаром, так и услугой, или компанией, или вообще отчётом и чем угодно ещё):
Таблица Характеристики (свойства):
Тут мы видим новые колонки:
code — уникальный код (мнемоника) для записи, прописывать в запросах и конфигах идентификаторы не камильфо, потому что идентификаторы могут на разных машинах быть разными и следить за тем что бы они были одними и теми же слегка утомительно, значительно удобней использовать код записи — его и запомнить проще чем набор цифр идентификатора, да и в коде когда видишь слово, а не магические числа становиться чуть более понятней суть происходящего.
title — наименование (name пришлось заменить на title, потому что name это ключевое слово для PostgreSql).
description — описание ( имя используется для выбора в списке, а описание для собственно описания назначения записи).
Теперь о том как всё это связано.
Рубрики пристыкованы к дереву элементов, стыковка выполнена отдельной таблицей:
Таблица выполняет роль «связи один к одному», таблица имеет два внешних ключа, для каждой колонки ключа есть свой индекс.
И Рубрика и Элемент дерева могут быть стыкованы только один раз, поэтому для каждой колонки сделан индекс с уникальностью.
Каждая рубрика имеет свой набор Характеристик (свойств):
У таблицы два внешних ключа, связи вида «один ко многим».
У одной Рубрики одна Характеристика один раз — обеспечивается индексом, у разных Рубрик может быть одна и та же Характеристика — индекс по Характеристике без уникальности значений.
Каждая рубрика имеет свой набор Сущностей (Штук):
У таблицы два внешних ключа, связи вида «один ко многим». У одной Рубрики несколько Сущностей, каждая Сущность может принадлежать только одной Рубрике.
Это была структура хранения информации, а где же сама информация?
Сама информация храниться отдельно.
Таблица Значения (значение информационной характеристики):
Эта табличка не совсем обычная, по сути это просто ячейка «памяти», которая хранит значение (raw). Значение конкретной характеристики (property_id). Значение заданное конкретным Редактором (redactor_id). Из таблички не ясно к чему относиться значение этой характеристики, то ли к модели молотка, то ли к модели видеокарты, стыковка с Сущностью это задача отдельной таблицы, но об этом пока рано, надо про Редакторов рассказать:
Зачем нам Редактор? Информационный каталог предполагался чем то вроде Википедии, где каждый Редактор мог задать свою версию значений Характеристик для каждой Сущности. И собственно Система должна была работать с вариациями Редакторов для представления одной и той же Сущности, считать аналитику по этим вариациям.
Таблица Значений хранит только строковое представление информации о Характеристике. Это собственно пользовательский ввод. Система работает с другим представлением этой информации, с представлением зависящим от типа данных. Для каждого типа данных своя таблица.
Строки
*для хранения строк в PostgreSql следует использовать TEXT
Числа
Даты (отметки времени)
Временные интервалы
Типы данных специально выбраны «международные», что бы можно было перенести структуру БД на любую платформу, на любую СУБД.
Название «matter» выбрано за созвучность словам «материя» и «суть».
И ещё об одной вещи не рассказал, это опции:
Опции нужны в качестве тегов, которые определяют каким образом обрабатывать Характеристики, как по ним проводить аналитику, какой механизм поиска использовать, с каким типом данных сохранять, какие права (разрешения) требуются для доступа и вся подобная бизнес логика завязана на опциях.
Опции стыкуются с Характеристиками:
Контент соединяется с Сущностями:
Собственно это все составные Информационного каталога.
Теперь самый главный вопрос, к чему такое количество связывающих табличек, неужели нельзя соединять таблицы напрямую?
Ответ в том что такая «архитектура» нацелена на максимальную модульность. Каждая таблица заточена под одну функцию и эти функции можно гибко комбинировать. Гибкость нарушает только таблица Значений — content, конечно связь с Редакторами можно было вынести в отдельную таблицу, но это уж слишком через край (хотя в следующей реализации я так и сделаю). Связь content с property жёсткая потому что Значение (content) не возможно интерпретировать вне Характеристики (property).
Гибкость связей сделана ради удобства перекидывания субъектов между другими субъектами Системы.
То есть мы Сущность с одни и тем же набором Значений можем перекидывать между разными Рубриками, и в каждой Рубрике мы у Сущности будем видеть и работать только с теми Характеристиками которые определены для этой Рубрики. Можем свободно перекинуть Значения от одной Сущности к другой, при этом не затронув самих значений.
Можем использовать только строковое представление информации и забыть об узкоспециализированных представлениях в таблицах *_matter.
Можем пользоваться только Рубриками без раскидывания Рубрик по Дереву элементов. А можем напротив по Дереву раскидать только те Рубрики которым хотим дать доступ пользователям, а системные Рубрики к дереву не стыковать и таким образом скрыть их от пользователей.
Можем для Рубрики добавлять или удалять Характеристики, при этом Значения ни как не пострадают и не будут задеты.
То есть от проекта к проекту можем использовать только тот функционал который нужен, а который не нужен можно выпилить в два счёта, просто исключив из сборки не нужные классы.
В общем можем крутить и вертеть данными как нам заблагорассудиться без каких либо изменений в структуре БД, и соответственно без изменений в классах работающих с этими данными, при изменении логики пришлось бы менять только слой бизнес логики без изменения слоя доступа к данным без изменения «примитивных» классов отвечающих за интерфейс редактирование данных.
При возросших накладных расходах на доступ к данным, мы получили большую гибкость и большую устойчивость к неосторожным действиям пользователей, можно проводить некоторые эксперименты без необходимости бэкапов, для таких «рисковых» и ленивых программистов как я это большой плюс :)
Ко всей этой «красоте» есть ещё и PHP код, но о нём в следующий раз, а учитывая мой «Recovery mode», только через неделю.
PS. Наверное после ваших замечаний надо будет ещё раз про эту «архитектуру» написать, а потом можно будет рассказать и про PHP классы для работы с этой системой хранения и обработки данных.
Идеальный каталог, набросок архитектуры
Каталог подразумевает упорядоченность — иерархию, подразумевает непосредственно хранение информации, и конечно поиск, наверное аналитику… что-то ещё? Больше ничего в голову не приходит.
Теперь по пунктам.
Иерархия
Однозначно группировка информации будет древовидной, от абстрактного «Каталог» к более частному, к более конкретному (например «молоток»). Уровень детализации может быть любым, не будем себя держать в рамках «раздел», «подраздел», «категория», «подкатегория», пусть глубина ветвления будет бесконечной.
Информация будет храниться в какой то СУБД, для работы с иерархией эта СУБД должна уметь иерархические запросы, таких СУБД не мало, из бесплатных самая попсовая это PostgreSQL.
DDL таблички Дерево Элементов:
CREATE TABLE element_tree ( id SERIAL PRIMARY KEY NOT NULL, element_tree_id INTEGER, is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_element_tree FOREIGN KEY (element_tree_id) REFERENCES element_tree (id) ); CREATE INDEX ix_element_tree_element_tree_id_id ON element_tree (element_tree_id, id);
Пояснения к структуре таблицы
id — идентификатор строки таблицы.
element_tree_id — ссылка на родительский элемент дерева.
is_hidden — флаг удалённой записи ( 0 — действительная запись, 1 — удалённая), почему для записи только поднимается флаг, вместо удаления? потому что когда встречаешь в логах идентификатор и тебе хочется посмотреть что он из себя представляет, очень удобно сделать селелект в текущей базе, вместо того что бы делать этот селект в бэкапе (и не факт что в этом бэкапе эта запись найдётся).
insert_date — дата добавления записи, удобно когда ты знаешь — это 100 летняя запись или она вставилась пять минут назад в результате не удачного инсерта.
Конечно людям которые хорошо знакомы с системой всё это (is_hidden ,insert_date) не очень надо, но для тех кто смотрит на систему как баране на новые ворота, эти поля очень пригодятся, я в своей практике обычно в роли барана :)
CONSTRAINT fk_element_tree — внешний ключ к самой себе — указатель на родительский элемент.
INDEX ix_element_tree_element_tree_id_id — индекс для поиска дочерних веток (узлов потомков), если родителя мы найдём по первичному ключу, то для ускоренного поиска потомков нам надо завести отдельный индекс.
Как мог заметить кто то опытный и продвинутый, в таблице нет колонок для имени элемента. А почему? А потому что иерархия это только иерархия, и упорядочены не узлы дерева, а те таблицы которые к иерархии пристыкованы, поэтому имена в таблицах, а в иерархии только группировка элементов.
Непосредственное хранении информации
В конечном итоге любой каталог это перечень отдельных рубрик. Рубрика это некая группа сущностей обладающих уникальным набором характеристик. То есть имеем отношение собственно Сущности и сгруппированные сущности — Рубрика, и кроме того Рубрика является ещё и группировкой для уникальных Характеристик этих Сущностей.
То есть информация разделяется на три части — Сущность, Характеристика, Рубрика, где Рубрика это точка соединения нескольких Сущностей и Характеристик.
На языке СУБД это звучит так:
Таблица Рубрики
CREATE TABLE rubric ( id SERIAL PRIMARY KEY NOT NULL, code CHAR(100), title VARCHAR(4000), description VARCHAR(4000), is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now() ); CREATE UNIQUE INDEX ux_rubric_code ON rubric (code);
Таблица Сущностей (некая Штука, которая может оказаться как товаром, так и услугой, или компанией, или вообще отчётом и чем угодно ещё):
CREATE TABLE item ( id SERIAL PRIMARY KEY NOT NULL, code CHAR(100), title VARCHAR(4000), description VARCHAR(4000), is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now() ); CREATE UNIQUE INDEX ux_item_code ON item (code);
Таблица Характеристики (свойства):
CREATE TABLE property ( id SERIAL PRIMARY KEY NOT NULL, code CHAR(100), title VARCHAR(4000), description VARCHAR(4000), is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now() ); CREATE UNIQUE INDEX ux_property_code ON property (code);
Тут мы видим новые колонки:
code — уникальный код (мнемоника) для записи, прописывать в запросах и конфигах идентификаторы не камильфо, потому что идентификаторы могут на разных машинах быть разными и следить за тем что бы они были одними и теми же слегка утомительно, значительно удобней использовать код записи — его и запомнить проще чем набор цифр идентификатора, да и в коде когда видишь слово, а не магические числа становиться чуть более понятней суть происходящего.
title — наименование (name пришлось заменить на title, потому что name это ключевое слово для PostgreSql).
description — описание ( имя используется для выбора в списке, а описание для собственно описания назначения записи).
Теперь о том как всё это связано.
Организация информации в каталоге
Рубрики пристыкованы к дереву элементов, стыковка выполнена отдельной таблицей:
CREATE TABLE rubric_element_tree ( id SERIAL PRIMARY KEY NOT NULL, rubric_id INTEGER NOT NULL, element_tree_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_rubric_element_tree_rubric_id FOREIGN KEY (rubric_id) REFERENCES rubric (id), CONSTRAINT fk_rubric_element_tree_element_tree_id FOREIGN KEY (element_tree_id) REFERENCES element_tree (id) ); CREATE UNIQUE INDEX ux_rubric_element_tree_rubric_id ON rubric_element_tree (rubric_id); CREATE UNIQUE INDEX ux_rubric_element_tree_element_tree_id ON rubric_element_tree (element_tree_id);
Таблица выполняет роль «связи один к одному», таблица имеет два внешних ключа, для каждой колонки ключа есть свой индекс.
И Рубрика и Элемент дерева могут быть стыкованы только один раз, поэтому для каждой колонки сделан индекс с уникальностью.
Каждая рубрика имеет свой набор Характеристик (свойств):
CREATE TABLE rubric_property ( id SERIAL PRIMARY KEY NOT NULL, rubric_id INTEGER NOT NULL, property_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_rubric_property_rubric_id FOREIGN KEY (rubric_id) REFERENCES rubric (id), CONSTRAINT fk_rubric_property_property_id FOREIGN KEY (property_id) REFERENCES property (id) ); CREATE UNIQUE INDEX ux_rubric_property_rubric_id ON rubric_property (rubric_id, property_id); CREATE INDEX ix_rubric_property_property_id ON rubric_property (property_id);
У таблицы два внешних ключа, связи вида «один ко многим».
У одной Рубрики одна Характеристика один раз — обеспечивается индексом, у разных Рубрик может быть одна и та же Характеристика — индекс по Характеристике без уникальности значений.
Каждая рубрика имеет свой набор Сущностей (Штук):
CREATE TABLE rubric_item ( id SERIAL PRIMARY KEY NOT NULL, rubric_id INTEGER NOT NULL, item_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_rubric_item_rubric_id FOREIGN KEY (rubric_id) REFERENCES rubric (id), CONSTRAINT fk_rubric_item_item_id FOREIGN KEY (item_id) REFERENCES item (id) ); CREATE UNIQUE INDEX ux_rubric_item_rubric_id_item_id ON rubric_item (rubric_id, item_id); CREATE UNIQUE INDEX ux_rubric_item_item_id ON rubric_item (item_id);
У таблицы два внешних ключа, связи вида «один ко многим». У одной Рубрики несколько Сущностей, каждая Сущность может принадлежать только одной Рубрике.
Это была структура хранения информации, а где же сама информация?
Сама информация храниться отдельно.
Хранение информации
Таблица Значения (значение информационной характеристики):
CREATE TABLE content ( id SERIAL PRIMARY KEY NOT NULL, raw VARCHAR(4000), redactor_id INTEGER NOT NULL, property_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_content_redactor_id FOREIGN KEY (redactor_id) REFERENCES redactor (id), CONSTRAINT fk_content_property_id FOREIGN KEY (property_id) REFERENCES property (id) ); CREATE INDEX ix_content_redactor_id ON content (redactor_id); CREATE INDEX ix_content_property_id ON content (property_id);
Эта табличка не совсем обычная, по сути это просто ячейка «памяти», которая хранит значение (raw). Значение конкретной характеристики (property_id). Значение заданное конкретным Редактором (redactor_id). Из таблички не ясно к чему относиться значение этой характеристики, то ли к модели молотка, то ли к модели видеокарты, стыковка с Сущностью это задача отдельной таблицы, но об этом пока рано, надо про Редакторов рассказать:
CREATE TABLE redactor ( id SERIAL PRIMARY KEY NOT NULL, code CHAR(100), title VARCHAR(4000), description VARCHAR(4000), is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now() ); CREATE UNIQUE INDEX ux_redactor_code ON redactor (code);
Зачем нам Редактор? Информационный каталог предполагался чем то вроде Википедии, где каждый Редактор мог задать свою версию значений Характеристик для каждой Сущности. И собственно Система должна была работать с вариациями Редакторов для представления одной и той же Сущности, считать аналитику по этим вариациям.
Таблица Значений хранит только строковое представление информации о Характеристике. Это собственно пользовательский ввод. Система работает с другим представлением этой информации, с представлением зависящим от типа данных. Для каждого типа данных своя таблица.
Строки
CREATE TABLE string_matter ( content_id INTEGER NOT NULL, id SERIAL PRIMARY KEY NOT NULL, string VARCHAR(4000), insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_string_matter_content_id FOREIGN KEY (content_id) REFERENCES content (id) ); CREATE UNIQUE INDEX ux_string_matter_content_id ON string_matter (content_id);
*для хранения строк в PostgreSql следует использовать TEXT
Числа
CREATE TABLE digital_matter ( content_id INTEGER NOT NULL, id SERIAL PRIMARY KEY NOT NULL, digital DOUBLE PRECISION, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_digital_matter_content_id FOREIGN KEY (content_id) REFERENCES content (id) ); CREATE UNIQUE INDEX ux_digital_matter_content_id ON digital_matter (content_id);
Даты (отметки времени)
CREATE TABLE date_matter ( content_id INTEGER NOT NULL, id SERIAL PRIMARY KEY NOT NULL, date_time TIMESTAMP WITH TIME ZONE insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_date_matter_content_id FOREIGN KEY (content_id) REFERENCES content (id) ); CREATE UNIQUE INDEX ux_date_matter_content_id ON date_matter (content_id);
Временные интервалы
CREATE TABLE duration_matter ( content_id INTEGER NOT NULL, id SERIAL PRIMARY KEY NOT NULL, duration INTERVAL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_duration_matter_content_id FOREIGN KEY (content_id) REFERENCES content (id) ); CREATE UNIQUE INDEX ux_duration_matter_content_id ON duration_matter (content_id);
Типы данных специально выбраны «международные», что бы можно было перенести структуру БД на любую платформу, на любую СУБД.
Название «matter» выбрано за созвучность словам «материя» и «суть».
И ещё об одной вещи не рассказал, это опции:
CREATE TABLE option ( id SERIAL PRIMARY KEY NOT NULL, code CHAR(100), title VARCHAR(4000), description VARCHAR(4000), is_hidden INTEGER DEFAULT 0, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now() ); CREATE UNIQUE INDEX ux_option_code ON option (code);
Опции нужны в качестве тегов, которые определяют каким образом обрабатывать Характеристики, как по ним проводить аналитику, какой механизм поиска использовать, с каким типом данных сохранять, какие права (разрешения) требуются для доступа и вся подобная бизнес логика завязана на опциях.
Опции стыкуются с Характеристиками:
CREATE TABLE property_option ( id SERIAL PRIMARY KEY NOT NULL, property_id INTEGER NOT NULL, option_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_property_option_property_id FOREIGN KEY (property_id) REFERENCES property (id), CONSTRAINT fk_property_option_option_id FOREIGN KEY (option_id) REFERENCES option (id) ); CREATE UNIQUE INDEX ux_property_option_property_id_option_id ON property_option (property_id, option_id); CREATE INDEX ix_property_option_option_id ON property_option (option_id);
Контент соединяется с Сущностями:
CREATE TABLE item_content ( id SERIAL PRIMARY KEY NOT NULL, item_id INTEGER NOT NULL, content_id INTEGER NOT NULL, insert_date TIMESTAMP WITH TIME ZONE DEFAULT now(), CONSTRAINT fk_item_content_item_id FOREIGN KEY (item_id) REFERENCES item (id), CONSTRAINT fk_item_content_content_id FOREIGN KEY (content_id) REFERENCES content (id) ); CREATE UNIQUE INDEX ux_item_content_item_id_content_id ON item_content (item_id, content_id); CREATE UNIQUE INDEX ux_item_content_content_id ON item_content (content_id);
Собственно это все составные Информационного каталога.
Фишка «архитектуры»
Теперь самый главный вопрос, к чему такое количество связывающих табличек, неужели нельзя соединять таблицы напрямую?
Ответ в том что такая «архитектура» нацелена на максимальную модульность. Каждая таблица заточена под одну функцию и эти функции можно гибко комбинировать. Гибкость нарушает только таблица Значений — content, конечно связь с Редакторами можно было вынести в отдельную таблицу, но это уж слишком через край (хотя в следующей реализации я так и сделаю). Связь content с property жёсткая потому что Значение (content) не возможно интерпретировать вне Характеристики (property).
Гибкость связей сделана ради удобства перекидывания субъектов между другими субъектами Системы.
То есть мы Сущность с одни и тем же набором Значений можем перекидывать между разными Рубриками, и в каждой Рубрике мы у Сущности будем видеть и работать только с теми Характеристиками которые определены для этой Рубрики. Можем свободно перекинуть Значения от одной Сущности к другой, при этом не затронув самих значений.
Можем использовать только строковое представление информации и забыть об узкоспециализированных представлениях в таблицах *_matter.
Можем пользоваться только Рубриками без раскидывания Рубрик по Дереву элементов. А можем напротив по Дереву раскидать только те Рубрики которым хотим дать доступ пользователям, а системные Рубрики к дереву не стыковать и таким образом скрыть их от пользователей.
Можем для Рубрики добавлять или удалять Характеристики, при этом Значения ни как не пострадают и не будут задеты.
То есть от проекта к проекту можем использовать только тот функционал который нужен, а который не нужен можно выпилить в два счёта, просто исключив из сборки не нужные классы.
В общем можем крутить и вертеть данными как нам заблагорассудиться без каких либо изменений в структуре БД, и соответственно без изменений в классах работающих с этими данными, при изменении логики пришлось бы менять только слой бизнес логики без изменения слоя доступа к данным без изменения «примитивных» классов отвечающих за интерфейс редактирование данных.
При возросших накладных расходах на доступ к данным, мы получили большую гибкость и большую устойчивость к неосторожным действиям пользователей, можно проводить некоторые эксперименты без необходимости бэкапов, для таких «рисковых» и ленивых программистов как я это большой плюс :)
Ко всей этой «красоте» есть ещё и PHP код, но о нём в следующий раз, а учитывая мой «Recovery mode», только через неделю.
PS. Наверное после ваших замечаний надо будет ещё раз про эту «архитектуру» написать, а потом можно будет рассказать и про PHP классы для работы с этой системой хранения и обработки данных.
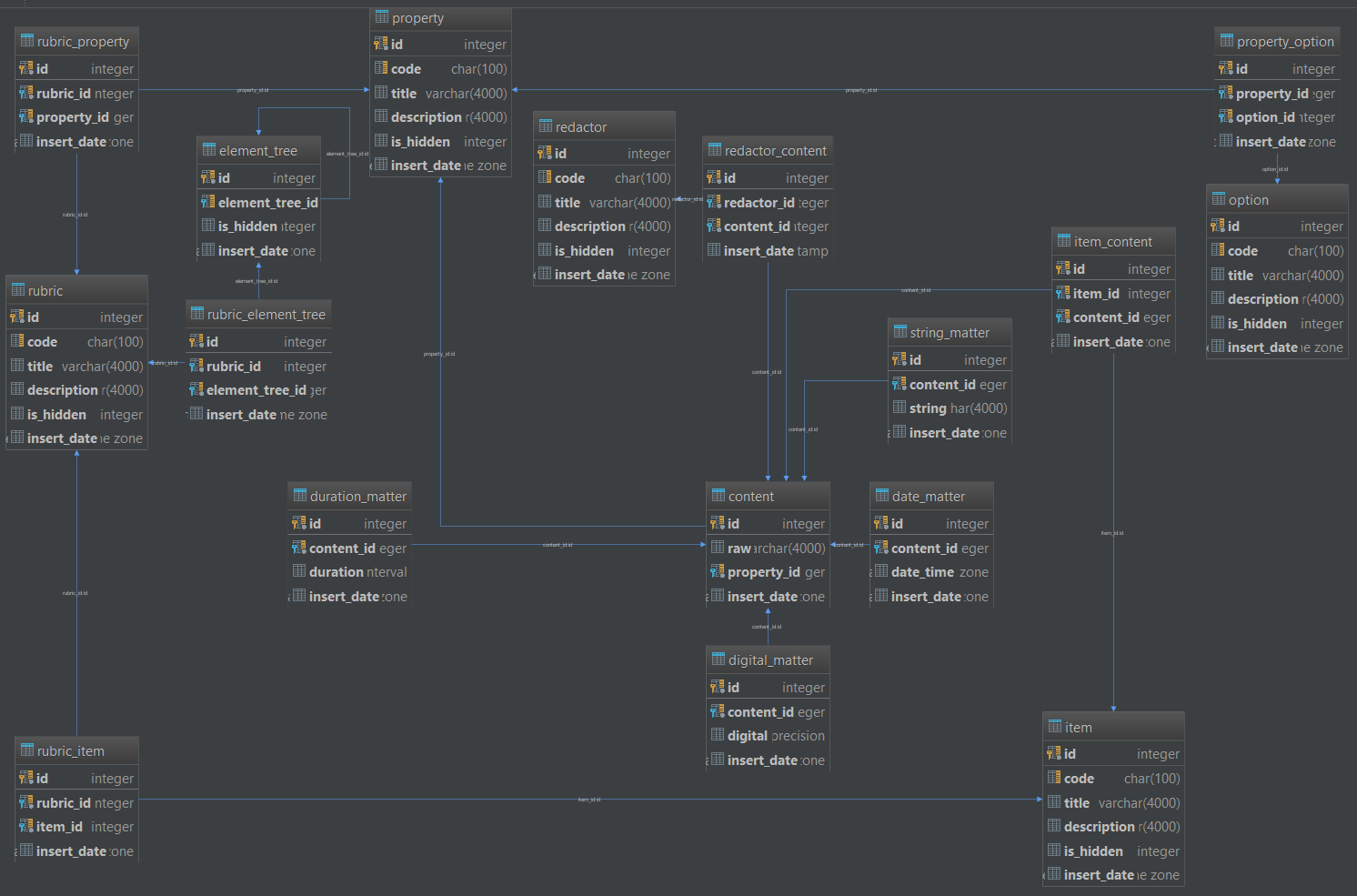
ER-Диаграмма
Продолжение
Идеальный каталог, набросок архитектуры

