Хочу поделиться опытом решения задачи по машинному обучению и анализу данных от Kaggle. Данная статья позиционируется как руководство для начинающих пользователей на примере не совсем простой задачи.
Выборка данных содержит порядка 10000 строк и 15 столбцов.Вот некоторые из параметров:
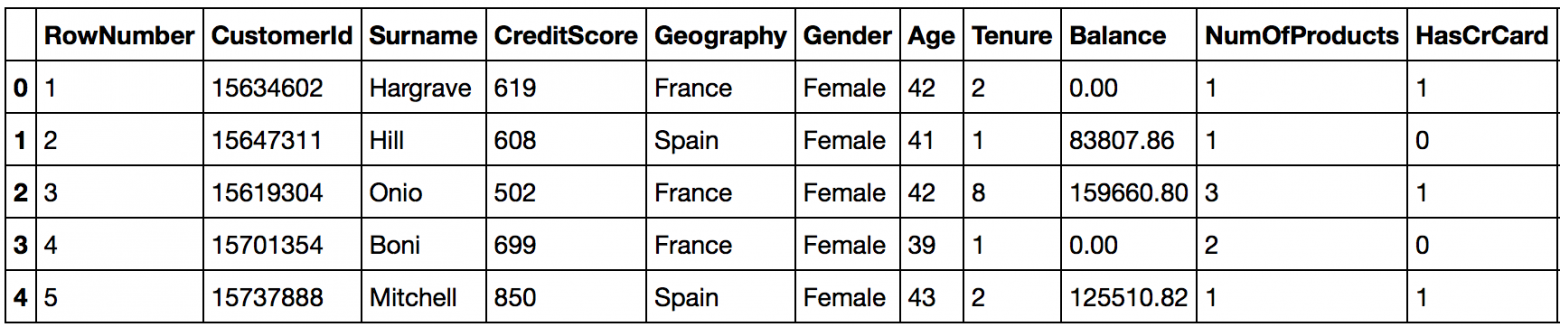
Для правильной работы классификатора необходимо преобразование категориального признака в числовой.На представленных выше данных в глаза сразу бросается два столбца: «Пол» и «Географическое положение». Проведем преобразования:

Корреляционная показывает, какие параметры будут влиять на результат. Сразу можно выделить 3 положительные корреляции: «Баланс счета», «Возраст», «Географическое положение».
Для избежания проблем с переобучением разделим наш набор данных:

Точность предсказания составила ~78%, что является неплохим результатом.
Выборка данных
Выборка данных содержит порядка 10000 строк и 15 столбцов.Вот некоторые из параметров:
- Возраст
- Пол
- Количество денежных средств на счету
Задача
- Найти параметры максимально влияющие на отток клиентов.
- Создание гипотезы, предсказывающей отток клиентов банка.
Инструментарий
- pandas
- sklearn
- matplotlib
- numpy
Импорт библиотек
import pandas as pd from sklearn.cross_validation import train_test_split from sklearn import svm import seaborn as sns import matplotlib.pyplot as plt from sklearn.metrics import mean_squared_error import numpy as np from sklearn.naive_bayes import GaussianNB
Загрузка и просмотр данных
dataframe = pd.read_csv("../input/Churn_Modelling.csv") dataframe.head()
Преобразование данных
Для правильной работы классификатора необходимо преобразование категориального признака в числовой.На представленных выше данных в глаза сразу бросается два столбца: «Пол» и «Географическое положение». Проведем преобразования:
dataframe['Geography'].replace("France",1,inplace= True) dataframe['Geography'].replace("Spain",2,inplace = True) dataframe['Geography'].replace("Germany",3,inplace=True) dataframe['Gender'].replace("Female",0,inplace = True) dataframe['Gender'].replace("Male",1,inplace=True)
Создание корреляционной матрицы
correlation = dataframe.corr() plt.figure(figsize=(15,15)) sns.heatmap(correlation, vmax=1, square=True,annot=True,cmap='cubehelix') plt.title('Correlation between different fearures') plt.show()
Корреляционная показывает, какие параметры будут влиять на результат. Сразу можно выделить 3 положительные корреляции: «Баланс счета», «Возраст», «Географическое положение».
Кросс валидация
Для избежания проблем с переобучением разделим наш набор данных:
X_train, X_test, y_train, y_test = train_test_split( X, Y, test_size=0.4, random_state=0)
Прогноз
clf = GaussianNB() clf = clf.fit(X_train ,y_train) clf.score(X_test, y_test)
Точность предсказания составила ~78%, что является неплохим результатом.

