Привет, Хабр! Недавно начал свое знакомство с библиотекой глубокого обучения (Deep Learning) от Google под названием TensorFlow. И захотелось в качестве эксперимента написать карту самоорганизации Кохонена. Поэтому решил заняться ее созданием используя стандартный функционал данной библиотеки. В статье описано что из себя представляет карта самоорганизации Кохонена и алгоритм ее обучения. А также приведен пример ее реализации и что из этого всего вышло.

Для начала разберемся что из себя представляет карта самоорганизации (Self-orginizing Map), или просто SOM. SOM – это искусственная нейронная сеть основанная на обучении без учителя. В картах самоорганизации нейроны помещени в узлах решетки, обычно одно- или двумерной. Все нейроны этой решетки связаны со всеми узлами входного слоя.
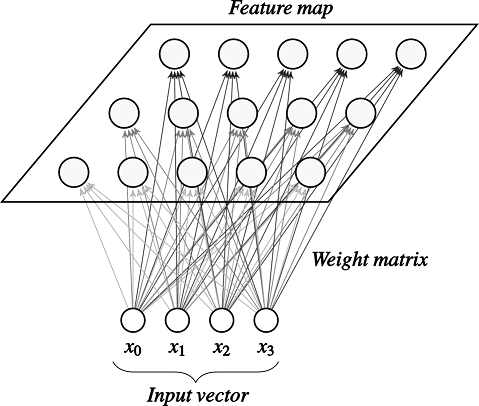
SOM преобразует непрерывное исходное пространство в дискретное выходное пространство
в дискретное выходное пространство  .
.
Обучение сети состоит из трех основных процессов: конкуренция, кооперация и адаптация. Ниже описаны все шаги алгоритма обучения SOM.
Шаг 1: Инициализация. Для всех векторов синаптических весов, — общее количество нейронов,
— общее количество нейронов,  — размерность входного пространства, выбирается случайное значение от -1 до 1.
— размерность входного пространства, выбирается случайное значение от -1 до 1.
Шаг 2: Подвыборка. Выбираем вектор![$\mathbf{x} = [x_1,x_2,...,x_m]$](https://habrastorage.org/getpro/habr/formulas/8dc/639/564/8dc63956442d0cdf733066a391cbdbbf.svg) из входного пространства.
из входного пространства.
Шаг 3: Поиск победившего нейрона или процесс конкуренции. Находим наиболее подходящий (победивший нейрон) на шаге
на шаге  , используя критерий минимума Евклидова расстояния (что эквивалентно максимуму скалярных произведений
, используя критерий минимума Евклидова расстояния (что эквивалентно максимуму скалярных произведений  ):
):
Шаг 4: Процесс кооперации. Нейрон-победитель находится в центре топологической окрестности «сотрудничающих» нейронов. Ключевой вопрос: как определить так называемую топологическую окрестность (topological neighbourhood) победившего нейрона? Для удобства обозначим ее символом: , с центром в победившем нейроне
, с центром в победившем нейроне  . Топологическая окрестность должна быть симметричной относительно точки максимума, определяемой при
. Топологическая окрестность должна быть симметричной относительно точки максимума, определяемой при  ,
,  — это латеральное расстояние (lateral distance) между победившим и соседними нейронами
— это латеральное расстояние (lateral distance) между победившим и соседними нейронами  .
.
Типичным примером, удовлетворяющим условию выше, является функция Гаусса: — эффективная ширина (effective width). Латеральное расстояние определяется как:
— эффективная ширина (effective width). Латеральное расстояние определяется как:  в одномерном, и:
в одномерном, и:  в двумерном случае. Где
в двумерном случае. Где  определяет позицию возбуждаемого нейрона, а
определяет позицию возбуждаемого нейрона, а  — позицию победившего нейрона (в случае двумерной решетки
— позицию победившего нейрона (в случае двумерной решетки  , где
, где  и
и  координаты нейрона в решетке).
координаты нейрона в решетке).
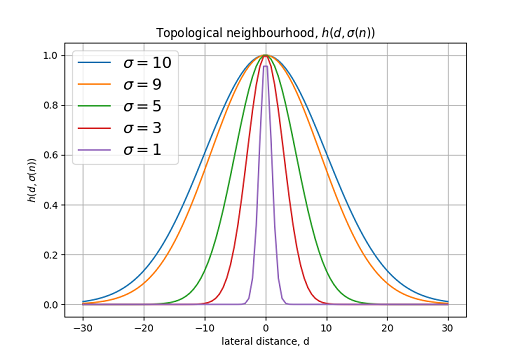
График функции топологической окрестности для различных.
Для SOM характерно уменьшение топологической окрестности в процессе обучения. Достичь этого можно изменяя по формуле: — некоторая константа, — шаг обучения,
— некоторая константа, — шаг обучения,  — начальное значение .
— начальное значение .

График изменением в процессе обучения.
Функция по окончании этапа обучения должна охватывать только ближайших соседей. На рисунках ниже приведены графики функции топологической окрестности для двумерной решетки.

Из данного рисунка видно, что в начале обучения топологическая окрестность охватывает практически всю решетку.

В конце обучения сужается до ближайших соседей.
Шаг 5: Процесс адаптации. Процесс адаптации включает в себя изменение синаптических весов сети. Изменение вектора весов нейрона в решетке можно выразить следующим образом: — параметр скорости обучения.
— параметр скорости обучения.
В итоге имеем формулу обновленного вектора весов в момент времени:
В алгоритме обучения SOM также рекомендуется изменять параметр скорости обучения в зависимости от шага.
где — еще одна константа алгоритма SOM.
— еще одна константа алгоритма SOM.
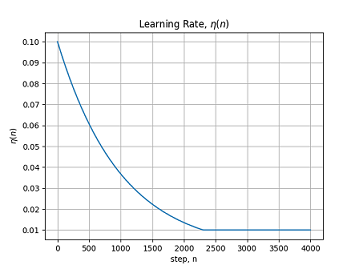
График изменением в процессе обучения.
После обновления весов возвращаемся к шагу 2 и так далее.
Обучения сети состоит из двух этапов:
Этап самоорганизации — может занять до 1000 итерций а может и больше.
Этап сходимости — требуется для точной подстройки карты признаков. Как правило, количесвто итераций, достаточное для этапа сходимости может превышать количество нейоронов в сети в 500 раз.
Эвристика 1. Начальное значение параметра скорости обучения лучше выбрать близким к значению: ,
,  . При этом оно не должно опускаться ниже значения 0.01.
. При этом оно не должно опускаться ниже значения 0.01.
Эвристика 2. Исходное значение следует установить примерно равной радиусу решетки, а константу опрелить как: .
Теперь перейдем от теории к практической реализации самоорганизующейся карты (SOM) с помощью Python и TensorFlow.
Для начала создадим класс SOMNetwork и создадим операции TensorFlow для инициализации всех констант:
Далее создадим функцию для создания операции процесса конкуренции:
Нам осталось создать основную операцию обучения для процессов кооперации и адаптации:
В итоге мы реализовали SOM и получили операцию training_op с помощью которой можно обучать нашу нейронную сеть, передавая на каждой итерации входной вектор и номер шага как параметр. Ниже приведен граф операций TensorFlow построенный с помощью Tesnorboard.

Граф операций TensorFlow.
Для тестирования работы программы, будем подавать на вход трехмерный вектор![$\mathbf{x} = (x_1, x_2, x_3), \:x_i = [0, 1]$](https://habrastorage.org/getpro/habr/formulas/dd6/21e/43e/dd621e43e4bd6b514da2c5dd84751955.svg) . Данный вектор можно представить как цвет из трех
. Данный вектор можно представить как цвет из трех  компонент.
компонент.
Создадим экземпляр нашей SOM сети и массив из рандомных векторов (цветов):
Теперь можно реализовать основной цикл обучения:
После обучения сеть преобразует непрерывное входное пространство цветов в дискретную градиентную карту, при подаче одной гаммы цветов всегда будут активироваться нейроны из одной области карты соответствующей данному цвету (активируется один нейрон наиболее подходящий подаваемому вектору). Для демонстрации можно представить вектор синаптических весов нейронов как цветовое градиентное изображение.
На рисунке представлена карта весов для сети 20х20 нейронов, после 200тыс. итераций обучения:

Карта весов в начале обучения (слева) и в конце обучения (справа).

Карта весов для сети 100x100 нейронов, после 350тыс. итераций обучения.
В итоге создана самоорганизующаяся карта и показан пример ее обучения на входном векторе состоящим из трех компонент. Для обучения сети можно использовать вектор любой размерности. Так же можно преобразовать алгоритм для работы в пакетном режиме. При этом порядок представления сети входных данных не влияет на окончательную форму карты признаков и нет необходимости в изменении параметра скорости обучения со временем.
P.S.: Полный код программы можно найти тут.
О картах самоорганизации
Для начала разберемся что из себя представляет карта самоорганизации (Self-orginizing Map), или просто SOM. SOM – это искусственная нейронная сеть основанная на обучении без учителя. В картах самоорганизации нейроны помещени в узлах решетки, обычно одно- или двумерной. Все нейроны этой решетки связаны со всеми узлами входного слоя.
SOM преобразует непрерывное исходное пространство
в дискретное выходное пространство .
Алгоритм обучения SOM
Обучение сети состоит из трех основных процессов: конкуренция, кооперация и адаптация. Ниже описаны все шаги алгоритма обучения SOM.
Шаг 1: Инициализация. Для всех векторов синаптических весов,
![$\mathbf{w}_j = [w_{j1},w_{j2},...,w_{jm}]^T\:j = 1,2,...,l$](https://habrastorage.org/getpro/habr/formulas/7f1/9e9/5b2/7f19e95b2a37612de1910613b0a3ebf6.svg)
— общее количество нейронов, — размерность входного пространства, выбирается случайное значение от -1 до 1.Шаг 2: Подвыборка. Выбираем вектор
из входного пространства.Шаг 3: Поиск победившего нейрона или процесс конкуренции. Находим наиболее подходящий (победивший нейрон)
на шаге , используя критерий минимума Евклидова расстояния (что эквивалентно максимуму скалярных произведений ):
Евклидово расстояние.
Евклидово расстояние ( ) определятся как:
) определятся как:
) определятся как:Шаг 4: Процесс кооперации. Нейрон-победитель находится в центре топологической окрестности «сотрудничающих» нейронов. Ключевой вопрос: как определить так называемую топологическую окрестность (topological neighbourhood) победившего нейрона? Для удобства обозначим ее символом:
, с центром в победившем нейроне . Топологическая окрестность должна быть симметричной относительно точки максимума, определяемой при , — это латеральное расстояние (lateral distance) между победившим и соседними нейронами .Типичным примером, удовлетворяющим условию выше,
является функция Гаусса:
— эффективная ширина (effective width). Латеральное расстояние определяется как: в одномерном, и: в двумерном случае. Где определяет позицию возбуждаемого нейрона, а — позицию победившего нейрона (в случае двумерной решетки , где и координаты нейрона в решетке).График функции топологической окрестности для различных
.Для SOM характерно уменьшение топологической окрестности в процессе обучения. Достичь этого можно изменяя
по формуле:
— некоторая константа, — шаг обучения, — начальное значение .График изменением
в процессе обучения.Функция
по окончании этапа обучения должна охватывать только ближайших соседей. На рисунках ниже приведены графики функции топологической окрестности для двумерной решетки.Из данного рисунка видно, что в начале обучения топологическая окрестность охватывает практически всю решетку.
В конце обучения
сужается до ближайших соседей.Шаг 5: Процесс адаптации. Процесс адаптации включает в себя изменение синаптических весов сети. Изменение вектора весов нейрона
в решетке можно выразить следующим образом:
— параметр скорости обучения. В итоге имеем формулу обновленного вектора весов в момент времени
:
В алгоритме обучения SOM также рекомендуется изменять параметр скорости обучения
в зависимости от шага.
где
— еще одна константа алгоритма SOM. График изменением
в процессе обучения.После обновления весов возвращаемся к шагу 2 и так далее.
Эвристики алгоритма обучения SOM
Обучения сети состоит из двух этапов:
Этап самоорганизации — может занять до 1000 итерций а может и больше.
Этап сходимости — требуется для точной подстройки карты признаков. Как правило, количесвто итераций, достаточное для этапа сходимости может превышать количество нейоронов в сети в 500 раз.
Эвристика 1. Начальное значение параметра скорости обучения лучше выбрать близким к значению:
, . При этом оно не должно опускаться ниже значения 0.01.Эвристика 2. Исходное значение
следует установить примерно равной радиусу решетки, а константу опрелить как: 
.Реализация SOM с помощью Python и TensorFlow
Теперь перейдем от теории к практической реализации самоорганизующейся карты (SOM) с помощью Python и TensorFlow.
Для начала создадим класс SOMNetwork и создадим операции TensorFlow для инициализации всех констант:
import numpy as np import tensorflow as tf class SOMNetwork(): def __init__(self, input_dim, dim=10, sigma=None, learning_rate=0.1, tay2=1000, dtype=tf.float32): #если сигма на определена устанавливаем ее равной половине размера решетки if not sigma: sigma = dim / 2 self.dtype = dtype #определяем константы использующиеся при обучении self.dim = tf.constant(dim, dtype=tf.int64) self.learning_rate = tf.constant(learning_rate, dtype=dtype, name='learning_rate') self.sigma = tf.constant(sigma, dtype=dtype, name='sigma') #тау 1 (формула 6) self.tay1 = tf.constant(1000/np.log(sigma), dtype=dtype, name='tay1') #минимальное значение сигма на шаге 1000 (определяем по формуле 3) self.minsigma = tf.constant(sigma * np.exp(-1000/(1000/np.log(sigma))), dtype=dtype, name='min_sigma') self.tay2 = tf.constant(tay2, dtype=dtype, name='tay2') #input vector self.x = tf.placeholder(shape=[input_dim], dtype=dtype, name='input') #iteration number self.n = tf.placeholder(dtype=dtype, name='iteration') #матрица синаптических весов self.w = tf.Variable(tf.random_uniform([dim*dim, input_dim], minval=-1, maxval=1, dtype=dtype), dtype=dtype, name='weights') #матрица позиций всех нейронов, для определения латерального расстояния self.positions = tf.where(tf.fill([dim, dim], True))
Далее создадим функцию для создания операции процесса конкуренции:
def __competition(self, info=''): with tf.name_scope(info+'competition') as scope: #вычисляем минимум евклидова расстояния для всей сетки нейронов distance = tf.sqrt(tf.reduce_sum(tf.square(self.x - self.w), axis=1)) #возвращаем индекс победившего нейрона (формула 1) return tf.argmin(distance, axis=0)
Нам осталось создать основную операцию обучения для процессов кооперации и адаптации:
def training_op(self): #определяем индекс победившего нейрона win_index = self.__competition('train_') with tf.name_scope('cooperation') as scope: #вычисляем латеральное расстояние d #для этого переводим инедкс победившего нейрона из 1d координаты в 2d координату coop_dist = tf.sqrt(tf.reduce_sum(tf.square(tf.cast(self.positions - [win_index//self.dim, win_index-win_index//self.dim*self.dim], dtype=self.dtype)), axis=1)) #корректируем сигма (используя формулу 3) sigma = tf.cond(self.n > 1000, lambda: self.minsigma, lambda: self.sigma * tf.exp(-self.n/self.tay1)) #вычисляем топологическую окрестность (формула 2) tnh = tf.exp(-tf.square(coop_dist) / (2 * tf.square(sigma))) with tf.name_scope('adaptation') as scope: #обновляем параметр скорости обучения (формула 5) lr = self.learning_rate * tf.exp(-self.n/self.tay2) minlr = tf.constant(0.01, dtype=self.dtype, name='min_learning_rate') lr = tf.cond(lr <= minlr, lambda: minlr, lambda: lr) #вычисляем дельта весов и обновляем всю матрицу весов (формула 4) delta = tf.transpose(lr * tnh * tf.transpose(self.x - self.w)) training_op = tf.assign(self.w, self.w + delta) return training_op
В итоге мы реализовали SOM и получили операцию training_op с помощью которой можно обучать нашу нейронную сеть, передавая на каждой итерации входной вектор и номер шага как параметр. Ниже приведен граф операций TensorFlow построенный с помощью Tesnorboard.
Граф операций TensorFlow.
Тестирование работы программы
Для тестирования работы программы, будем подавать на вход трехмерный вектор
. Данный вектор можно представить как цвет из трех компонент.Создадим экземпляр нашей SOM сети и массив из рандомных векторов (цветов):
#сеть размером 20х20 нейронов som = SOMNetwork(input_dim=3, dim=20, dtype=tf.float64, sigma=3) test_data = np.random.uniform(0, 1, (250000, 3))
Теперь можно реализовать основной цикл обучения:
training_op = som.training_op() init = tf.global_variables_initializer() with tf.Session() as sess: init.run() for i, color_data in enumerate(test_data): if i % 1000 == 0: print('iter:', i) sess.run(training_op, feed_dict={som.x: color_data, som.n:i})
После обучения сеть преобразует непрерывное входное пространство цветов в дискретную градиентную карту, при подаче одной гаммы цветов всегда будут активироваться нейроны из одной области карты соответствующей данному цвету (активируется один нейрон наиболее подходящий подаваемому вектору). Для демонстрации можно представить вектор синаптических весов нейронов как цветовое градиентное изображение.
На рисунке представлена карта весов для сети 20х20 нейронов, после 200тыс. итераций обучения:
Карта весов в начале обучения (слева) и в конце обучения (справа).
Карта весов для сети 100x100 нейронов, после 350тыс. итераций обучения.
Заключение
В итоге создана самоорганизующаяся карта и показан пример ее обучения на входном векторе состоящим из трех компонент. Для обучения сети можно использовать вектор любой размерности. Так же можно преобразовать алгоритм для работы в пакетном режиме. При этом порядок представления сети входных данных не влияет на окончательную форму карты признаков и нет необходимости в изменении параметра скорости обучения со временем.
P.S.: Полный код программы можно найти тут.

