Не так давно я стал присматриваться к языку программирования
Язык
Чтобы сравнить код и производительность
Статья построена следующим образом: в первой части я опишу основные плюсы и минусы, на которые я обратил внимание, работая с
Данная статья достаточно субъективная. Даже сравнение производительности программ, которые делают одинаковые вещи, но написаны на разных языках, подвержены авторскому подходу. Поэтому я не претендую на объективные замеры, и, чтобы не навязывать свои результаты, предлагаю всем ознакомится с кодом программ и с подходом к замеру производительности. Код выложен на github. Буду рад любой критике и замечаниям. Начнем.
+ Разработчики
+Компилятор строг к тексту программы, который подается ему на вход: в его выводе можно увидеть какой код не используется, какие переменные можно изменить на константный тип, и даже предупреждения, связанные со стилем программирования. Часто для ошибок компиляции приведены варианты ее устранения, а ошибки при инстанциировании обобщенного кода (шаблонов) лаконичны и понятны (привет ошибкам с шаблонами
+ При присваивании или передачи аргументов по умолчанию работает семантика перемещения (аналог
+ Все строки — это
+ Есть поддержка итераторов и замыканий (лямбда функций). Благодаря этому можно писать однострочные конструкции, которые выполняют множество операций с сложной логикой (то, чем славится
+-В
- Нужно писать программы так, чтобы компилятор (точнее borrow checker) поверил, что вы не делаете ничего плохого с памятью (или с ресурсами в целом). Часто это работает как надо, но иногда приходится писать код в несколько хитрой форме только для того, что бы удовлетворить условиям borrow checker'а.
- В
-
Нужно для для каждого значения из вектора B найти его позицию в векторе A. По сути нужно применить n раз бинарный поиск, где n — кол-во элементов в B (массив A предварительно отсортирован). Поэтому тут я приведу функцию бинарного поиска.
Кто первый раз видит
Формально задача звучит так: для заданного массива подсчитать кол-во перестановок, необходимых для сортировки массива. По факту нам требуется реализовать сортировку слиянием, подсчитывая по ходу длину перестановок элементов.
Давайте рассмотрим код чтения массива с
Приведу сначала неправильную сигнатуру вызова функции
Данная конструкция не взлетит в
Для заданной строки нужно построить беспрефиксный код и вывести закодированное сообщение. Для данной задачи нужно построить дерево на основе частотных характеристик символов в исходном сообщении. Построение деревьев, списков, графов на
Заведем класс Node:
Метод для посещения нод дерева сверху вниз и для составления таблицы кодирования.
Обратная задача: для известной таблицы кодирования и закодированной строки получить исходное сообщение. Для декодирования удобно пользоваться бинарным деревом кодирования, поэтому в программе нам нужно из таблицы кодирования получить дерево декодирования. На словах задача простая: нужно перемещаться вниз по дереву (0 — влево, 1 — вправо), создавая промежуточные узлы при необходимости, и в листья дерева помещать символ исходного сообщения. Но для
Нужно для двух строк посчитать расстояние Левенштейна — кол-во действий редактирования строк, чтобы из одной получить другую. Код функции:
В конце, как обещал, прикладываю таблицу сравнения времени работы программ, описанных выше. Запуск производился на современной рабочей станции Intel Core i7-4770, 16GB DDR3, SSD, Linux Mint 18.1 64-bit. Использовались компиляторы:
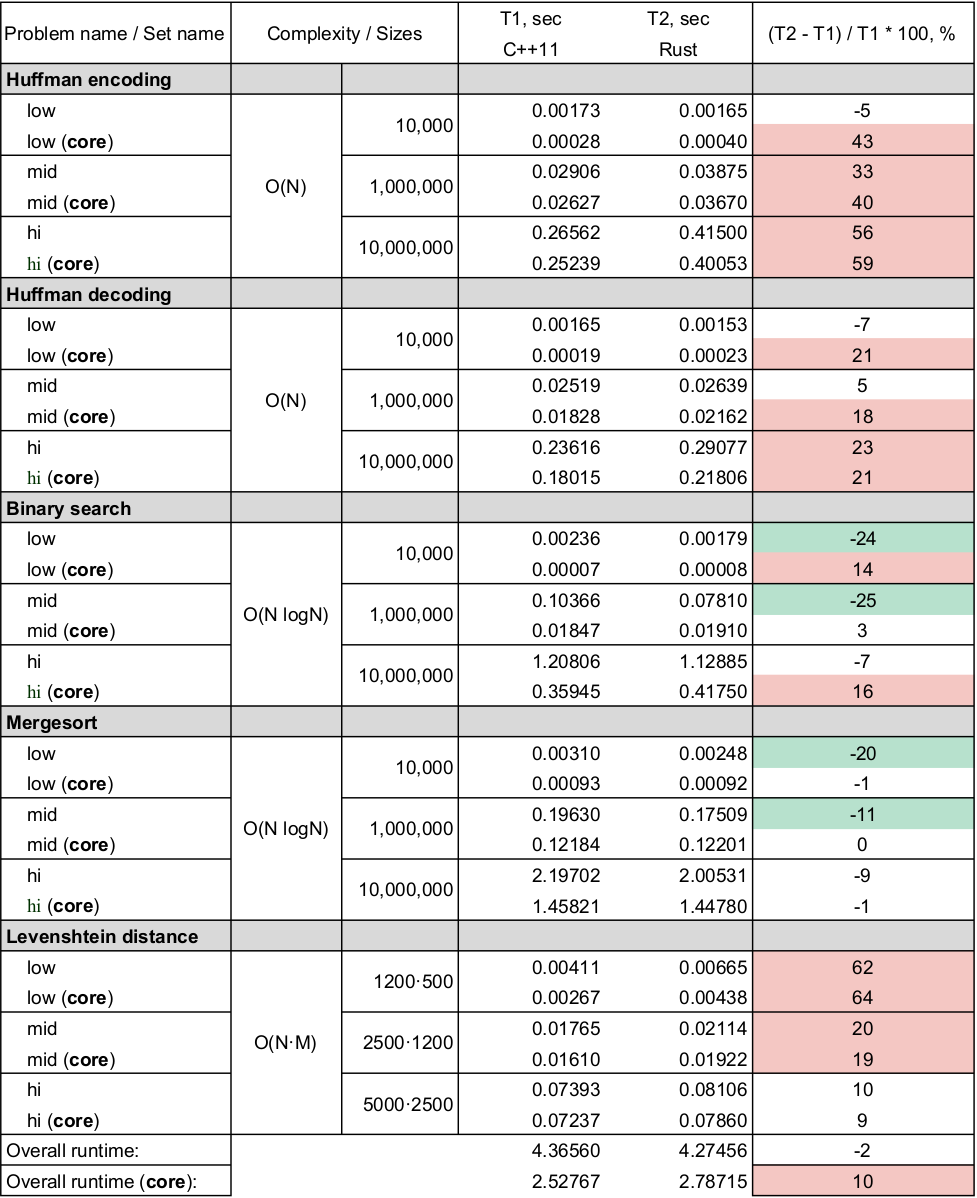
Пару замечаний по результатам:
Повторюсь, что статья субъективна, и признана в первую очередь оценить в грубом масштабе, где находится
Вы можете ознакомиться со всеми кодами, необходимыми для повторения замеров на github: https://github.com/dmitryikh/rust-vs-cpp-bench.
Спасибо, что дочитали до конца!
Спасибо за вашу работу в комментариях!
Я учел ряд ваших замечаний:
Теперь ситуация стала более объективной. Но в целом, оба языка держаться в поле ±10% на данных задачах.
Rust. Прочитав Rustbook, изучив код некоторых популярных проектов, я решил своими руками попробовать этот язык программирования и своими глазами оценить его преимущества и недостатки, его производительность и эко-систему.Язык
Rust позиционирует себя, как язык системного программирования, поэтому основным его vis-à-vis следует называть C/C++. Сравнивать же молодой и мультипарадигмальный Rust, который поддерживает множество современных конструкций программирования (таких, как итераторы, RAII и др.) с «голым» C я считаю не правильно. Поэтому в данной статье речь пойдет об сравнении с C++.Чтобы сравнить код и производительность
Rust и C++, я взял ряд алгоритмических задач, которые нашел в онлайн курсах по программированию и алгоритмам.Статья построена следующим образом: в первой части я опишу основные плюсы и минусы, на которые я обратил внимание, работая с
Rust. Во второй части я приведу краткое описание алгоритмических задач, которые были решены в Rust и C++, прокомментирую основные моменты реализации программ. В третьей части будет приведена таблица замера производительности программ на Rust и C++.Данная статья достаточно субъективная. Даже сравнение производительности программ, которые делают одинаковые вещи, но написаны на разных языках, подвержены авторскому подходу. Поэтому я не претендую на объективные замеры, и, чтобы не навязывать свои результаты, предлагаю всем ознакомится с кодом программ и с подходом к замеру производительности. Код выложен на github. Буду рад любой критике и замечаниям. Начнем.
Что плохого и хорошего в Rust
+ Разработчики
Rust поставляют свой компилятор уже с «батарейками внутри» тут есть: компилятор, менеджер пакетов (он же сборщик проектов, он же отвечает за запуск тестов), генератор документации и отладчик gdb. Исходный код на Rust может включать в себя сразу тесты и документацию, и чтобы собрать все это не требуется дополнительных программ или библиотек. +Компилятор строг к тексту программы, который подается ему на вход: в его выводе можно увидеть какой код не используется, какие переменные можно изменить на константный тип, и даже предупреждения, связанные со стилем программирования. Часто для ошибок компиляции приведены варианты ее устранения, а ошибки при инстанциировании обобщенного кода (шаблонов) лаконичны и понятны (привет ошибкам с шаблонами
STLв C++).+ При присваивании или передачи аргументов по умолчанию работает семантика перемещения (аналог
std::move, но не совсем). Если функция принимает ссылку на объект необходимо явно взять адрес (символ &, как в C++).+ Все строки — это
юникод в кодировке UTF-8. Да, для подсчета количества символов нужно О(N) операций, но зато никакого зоопарка с кодировками.+ Есть поддержка итераторов и замыканий (лямбда функций). Благодаря этому можно писать однострочные конструкции, которые выполняют множество операций с сложной логикой (то, чем славится
Python).+-В
Rust отсутствуют исключения, обработку ошибок необходимо делать после вызова каждой функции. Причем Rust не позволит получить возвращаемое значение, если вы не обработаете случай неуспешного завершения функции. Есть макросы и встроенные конструкции языка, которые позволяют упростить эту обработку и не сильно раздувать код проверками.- Нужно писать программы так, чтобы компилятор (точнее borrow checker) поверил, что вы не делаете ничего плохого с памятью (или с ресурсами в целом). Часто это работает как надо, но иногда приходится писать код в несколько хитрой форме только для того, что бы удовлетворить условиям borrow checker'а.
- В
Rust нет классов, но есть типажи, на основе которых можно построить объектно ориентированную программу. Но скопировать реализацию с полиморфными классами в C++ в язык Rust напрямую не получиться.-
Rust достаточно молод. Мало полезного материала в сети, на StackOverflow. Мало хороших библиотек. Например, нет библиотек для построения GUI, нет портов wxWidgets, Qt.Алгоритмические задачи на Rust
Бинарный поиск
Нужно для для каждого значения из вектора B найти его позицию в векторе A. По сути нужно применить n раз бинарный поиск, где n — кол-во элементов в B (массив A предварительно отсортирован). Поэтому тут я приведу функцию бинарного поиска.
// return position of the element if found fn binary_search(vec: &[u32], value: u32) -> Option<usize> { let mut l: i32 = 0; let mut r: i32 = vec.len() as i32 - 1; while l <= r { let i = ((l + r) / 2) as usize; if vec[i] == value { return Some(i); } else if vec[i] > value { r = i as i32 - 1; } else if vec[i] < value { l = i as i32 + 1; } } None }
Кто первый раз видит
Rust, обратите внимание на пару особенностей:- Тип возвращаемого значения указывается в конце объявления функции
- Если переменная изменяемая, то нужно указывать модификатор
mut Rustне переводит типы неявно, даже числовые. Поэтому нужно писать явный перевод типаl = i as i32 + 1
Сортировка слиянием
Формально задача звучит так: для заданного массива подсчитать кол-во перестановок, необходимых для сортировки массива. По факту нам требуется реализовать сортировку слиянием, подсчитывая по ходу длину перестановок элементов.
Давайте рассмотрим код чтения массива с
stdinfn read_line() -> String { let mut line = String::new(); io::stdin().read_line(&mut line).unwrap(); line.trim().to_string() } fn main() { // 1. Read the array let n: usize = read_line().parse().unwrap(); let mut a_vec: Vec<u32> = vec![0; n as usize]; for (i, token) in read_line().split_whitespace().enumerate() { a_vec[i] = token.parse().unwrap(); } ...
- У классов нет конструкторов, но можно делать статические методы-фабрики, которые возвращают объекты классов, как
String::new()выше. - Функции, которые могут ничего не вернуть, возвращают объект
Option, который содержитNoneили результат корректного завершения функции. Методunwrapпозволяет получить результат или вызываетpanic!, если вернулсяNone. - Метод
String::parseпарсит строку в тип возвращаемого значения, т.е. происходит вывод типа по возвращаемому значению. Rustподдерживает итераторы (как генераторы в Python). Связкаsplit_whitespace().enumerate()генерирует итератор, который лениво читает следующий токен и инкрементирует счетчик.
Приведу сначала неправильную сигнатуру вызова функции
_merge, которая сливает in place два отсортированных подмассива.fn _merge(left_slice: &mut [u32], right_slice: &mut [u32]) -> u64
Данная конструкция не взлетит в
Rust без unsafe кода, т.к. тут мы передаем два изменяемых подмассива, которые располагаются в исходном массиве. Система типов в Rust не позволяет иметь две изменяемых переменных на один объект (мы знаем, что подмассивы не пересекаются по памяти, но компилятор — нет). Вместо этого надо использовать такую сигнатуру:fn _merge(vec: &mut [u32], left: usize, mid: usize, right: usize) -> u64
Кодирование Хаффмана
Для заданной строки нужно построить беспрефиксный код и вывести закодированное сообщение. Для данной задачи нужно построить дерево на основе частотных характеристик символов в исходном сообщении. Построение деревьев, списков, графов на
Rust — задачи не из простых, т.к., например, в случае двусвязного списка нам необходимо иметь два mut указателей на один нод, а это запрещено системой типов. Поэтому эффективно написать двусвязный список без unsafe кода не получится. В данной задаче мы имеем однонаправленное дерево, поэтому эта особенность нас не коснется, но есть свои сложности реализации.Заведем класс Node:
// Type of the reference to the node type Link = Option<Box<Node>>; // Huffman tree node struct #[derive(Debug,Eq)] struct Node { freq: u32, letter: char, left: Link, right: Link, } impl Ord for Node { // reverse order to make Min-Heap fn cmp(&self, b: &Self) -> Ordering { b.freq.cmp(&self.freq) } }
- Можем использовать типы до их описания.
- Тут можно видеть странный синтаксис наследования
#[derive(Debug,Eq)].Debug— поддерживаем форматированную печать объекта по-умолчанию.Eq— определяем операцию сравнения на равенство. - Для Node определяется типаж сравнения на больше/меньше
Ord. Типажи позволяют расширять возможности объектов. В частности, здесь мы сможем использоватьNodeдля хранения Min-куче.
Метод для посещения нод дерева сверху вниз и для составления таблицы кодирования.
impl Node { ... // traverse tree building letter->code `map` fn build_map(&self, map: &mut HashMap<char, String>, prefix: String) { match self.right { Some(ref leaf) => leaf.build_map(map, prefix.clone() + "1"), _ => { }, } match self.left { Some(ref leaf) => { leaf.build_map(map, prefix + "0"); }, _ => { map.insert(self.letter, prefix); }, } } }
- Рекурсивно вызывает ветки бинарного дерева, если их указатель не пустой
&Some(ref leaf). - Конструкция
matchпохожа наswitchвC.matchдолжен обработать все варианты, поэтому тут присутсвует_ => { }. - Помните про семантику перемещения по-умолчанию? Поэтому нам нужно писать
prefix.clone(), чтобы в каждую ветвь дерева передалась своя строка.
Декодирование Хаффмана
Обратная задача: для известной таблицы кодирования и закодированной строки получить исходное сообщение. Для декодирования удобно пользоваться бинарным деревом кодирования, поэтому в программе нам нужно из таблицы кодирования получить дерево декодирования. На словах задача простая: нужно перемещаться вниз по дереву (0 — влево, 1 — вправо), создавая промежуточные узлы при необходимости, и в листья дерева помещать символ исходного сообщения. Но для
Rust задача оказалась сложная, ведь нам нужно перемещаться по изменяемым ссылкам, создавать объекты, и при этом избегать ситуации, когда объектом владеет более одной переменной. Код функции заполнения бинарного дерева:fn add_letter(root: &mut Link, letter: char, code: &str) { let mut p: &mut Node = root.as_mut().unwrap(); for c in code.chars() { p = match {p} { &mut Node {left: Some(ref mut node), ..} if c == '0' => { node }, &mut Node {left: ref mut opt @ None, ..} if c == '0' => { *opt = Node::root(); opt.as_mut().unwrap() }, &mut Node {right: Some(ref mut node), ..} if c == '1' => { node }, &mut Node {right: ref mut opt @ None, ..} if c == '1' => { *opt = Node::root(); opt.as_mut().unwrap() }, _ => { panic!("error"); } } } p.letter = letter; }
- Тут
matchиспользуется для сравнения структуры переменнойp.&mut Node {left: Some(ref mut node), ..} if c == '0'означает «еслиpэто изменяемая ссылка на объектNodeу, которого полеleftуказывает на существующийnodeи при этом символcравен '0'». - В
Rustнет исключений, поэтомуpanic!("...")раскрутит стек и остановит программу (или поток).
Расстояние Левенштейна
Нужно для двух строк посчитать расстояние Левенштейна — кол-во действий редактирования строк, чтобы из одной получить другую. Код функции:
fn get_levenshtein_distance(str1: &str, str2: &str) -> u32 { let n = str1.len() + 1; let m = str2.len() + 1; // compute 2D indexes into flat 1D index let ind = |i, j| i * m + j; let mut vec_d: Vec<u32> = vec![0; n * m]; for i in 0..n { vec_d[ind(i, 0)] = i as u32; } for j in 0..m { vec_d[ind(0, j)] = j as u32; } for (i, c1) in str1.chars().enumerate() { for (j, c2) in str2.chars().enumerate() { let c = if c1 == c2 {0} else {1}; vec_d[ind(i + 1, j + 1)] = min( min( vec_d[ind(i, j + 1)] + 1 , vec_d[ind(i + 1, j)] + 1 ) , vec_d[ind(i, j)] + c ); } } return vec_d[ind(n - 1, m - 1)]; }
str1: &str— это срез строки. Легковесный объект, который указывает на строку в памяти, аналогstd::string_viewC++17.let ind = |i, j| i * m + j;— такой конструкцией определяется лямбда функция.
Замеры производительности Rust vs C++
В конце, как обещал, прикладываю таблицу сравнения времени работы программ, описанных выше. Запуск производился на современной рабочей станции Intel Core i7-4770, 16GB DDR3, SSD, Linux Mint 18.1 64-bit. Использовались компиляторы:
[>] rustc --version rustc 1.22.1 (* 2017-11-22) [>] g++ -v ... gcc version 7.2.0
Пару замечаний по результатам:
- Измерялось полное время работы программы, в которое включено чтение данных, полезные действия и вывод в
/dev/null - В * (core) измерялось только время работы алгоритмической части (без ввода/вывода)
- Делалось 10 прогонов каждой задачи на каждом наборе данных, далее результаты усреднялись
- Все скрипты, производящие компиляцию, подготовку тестовых данных и замеры производительности, представлены в репозитории. К ним есть описание.
- По моему мнению, на ряде задач
C++проигрывает из-за библиотеки потокового чтения/записиiostream. Но эту гипотезу еще предстоит проверить.И да, в коде естьstd::sync_with_stdio(false) - По моему мнению,
Rustсильно проигрывает в тестеHuffman encodingпо причинемедленных хешей в HashMap - На полном времени выполнения задач
Rustпоказал, что по производительности он не уступаетC++. В каждом языке есть свои особенность реализации стандартной библиотеки, которые сказывают на скорости работы задач. - На замерах только алгоритмической части,
Rustпроигрывает порядка 10%, но, думаю ситуация бы исправилась, если будем использовать хэши побыстрее в первой задаче.
Заключение
Повторюсь, что статья субъективна, и признана в первую очередь оценить в грубом масштабе, где находится
Rust по отношению к C++. Если у вас есть пожелания, идеи или замечания, которые позволят добавить статье объективности, пишите в комментарии.Вы можете ознакомиться со всеми кодами, необходимыми для повторения замеров на github: https://github.com/dmitryikh/rust-vs-cpp-bench.
Спасибо, что дочитали до конца!
Обновление от 11.12.2017
Спасибо за вашу работу в комментариях!
Я учел ряд ваших замечаний:
- Исправил функцию
binary_search. Теперь она возвращаетOption - Задача
Binary_searchтеперь принимает на вход отсортированный массив A, поэтому во время работы теперь не входит сортировка A - Добавил
-DNDEBUGпри компиляцииC++. Посыпаю голову пеплом.. - Исправлена грубая ошибка в задаче
Huffman_decoding, из-за который программа на C++ ДВАЖДЫ декодировала строку. Прошу прощения за это. - Добавлен замер времени выполнения только алгоритмической части, без учета операций ввода-вывода и загрузки программы.
Теперь ситуация стала более объективной. Но в целом, оба языка держаться в поле ±10% на данных задачах.

