
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
День добрый!
ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%BE_%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%B8 — при условии равной вероятности появления каждого символа и отсутствии шума в канале вырождается в двоичный логарифм от длины;
Тогда разумно наложить такое же требование на k, чтобы минимизировать c_0.
кол-во информации в одном символе при условии равновероятного появления [0,1] = 1/2*log_2(2) = 1/2 соотв. если сообщение длины n, то кол-во информации n/2;
меньше т.к. из перечня ключей выкидываются, например [2,2,2,3,3,5] =360 — они не привносят доп. простых множителей относительно [2,3,5] = 30, а длину с_1 увеличивают.
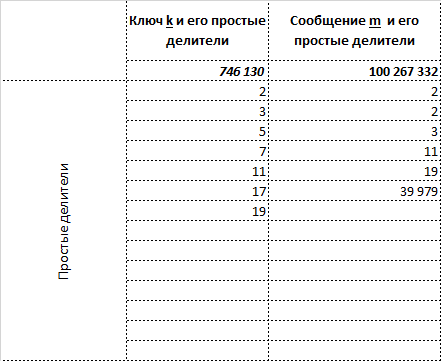
меньше т.к. из перечня ключей выкидываются, например [2,2,2,3,3,5] =360 — они не привносят доп. простых множителей относительно [2,3,5] = 30, а длину с_1 увеличивают.
кол-во информации в одном символе при условии равновероятного появления [0,1] = 1/2*log_2(2) = 1/2 соотв. если сообщение длины n, то кол-во информации n/2;
То есть в однобитном сообщении содержится полбита информации?
Не совсем так — то, что написал касалось сообщений длины n, где надо учитывать вероятность появления каждого символа, для сообщений длины 1 лучше говорить о собственной информации ссылка т.к. там всё детерминировано.
Не пытаетесь ли вы изобрести велосипед сжатие с использованием словаря ?
Если начинать сравнивать, то да. Просто хотелось сначала показать, что в самом сложном случае, когда берутся два почти случайные числа, можно, найдя общую информацию её не передавать. А так как Вы верно заметили, что реальные сообщения не случайны, то дальше хочется заняться уже переложением этой темы на практику.
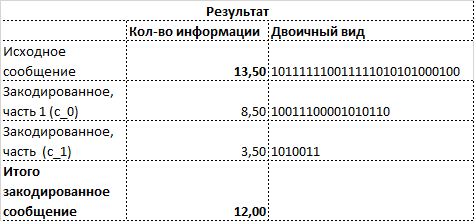
Передаваемая часть действительно будет одинаковой, в обоих случаях

Но т.к. ключ известен двум сторонам, то восстановить полученную информацию можно полностью т.к получив 11011 мы в обоих случаях восстанавливаем НОД(k,m)=1254 =[2,3,11,19].
Другое дело, что если ключ долго не менять, то поигравшись сообщениями (мы-то знаем делители сообщения) и понаблюдав за каналом, его можно и восстановить.
Вы правы. Но есть надежда на то, что поиск простых делителей довольно отработанный хоть и не очень быстрый алгоритм — делим на всё подряд до корня из числа с оценкой O(n^{0.5})
Кодирование с изъятием информации. Часть 2-я, математическая