
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
что преобразование из 192000 Гц в 44100 Гц является сжатием без потерь— я бы лучше сказал, что такое преобразование не внесёт в звук значительных искажений.
Частоты выше 20 КГц — это не ультразвук, а тонкие детали волнового профиля.
22.5кгц будут представлены 2мя дискретными показаниями и форма волны не будет восстановлена так как не понятно там синус или пила или прямоугольный импульс
наш мозг не может интерпретировать форму сигнала на вч и ему побарабану, там синус, пила или прямоугольный импульс


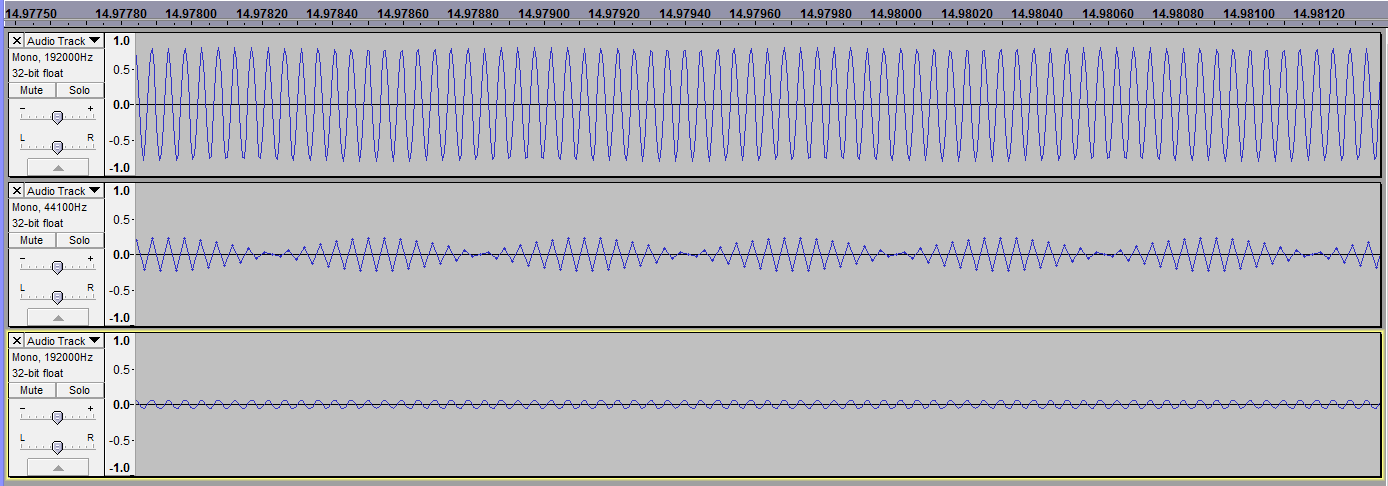
должен тебя огорчить, когда ты без экспериментов возьмёшься за практику, съиграв чтото и отстроив красиво свой трек, пересемплировать его хоть куда-то обнаружится сложной задачей в экспериментах именно, когда матчасть, будет убеждать тебя "да забей! всё тут нормально" предлагая раз за разом тебе будто чужую одежду или укушенное яблоко вместо припасённого тобой к этой знаменательной дате... всё что ты говоришь - отлично подтверждается в видеотракте, но не в работе с аппаратурой композитора, всегда находящего как подчеркнуть прелести имеющегося оборудования, просто оставляя удачно звучащие варианты выбирая, и вдруг "математически и оптически(глаз видит одну октаву тремя резонаторами оценивая спектр света) неотличимый результат обработки" не содержит никаких музыкальных "алмазиков тобой отполированых" в режиме 24бит 192кгц, и писать в 16 44100 невозможно, тк включив 24 192 потом ты заметишь кучу нестыковок, в низком разрешении не слышавшихся... а их полировка время немало требует и выполняется с контролем сохранения "алмазиков" не всегда легко удаваясь
Сейчас подумал - посмотри на свои фотографии произвольно сделанные, и представь что тебе в паспортном столе предложили бы выбрать на паспорт лучшую фотку с одной камеры серию снимков делавшей, установленной рядом со второй, которая распечатывать паспорт будет выбранного номера снимка, но видишь ты одним фотоаппаратом, а получаешь "с незначительной погрешностью, туже резкость и цветность
это не заметишь на вокале или гитаре играя, это заметно на тембре волнового синтеза звуков, белый шум 44100 16 никогда не напоминает звук ветра получаемый в 192 24
Бесполезно проводить тесты на исходниках в виде классики или голоса, это всё достаточно медленно звучит - реальную разницу можно услышать только в спидкоре зарендеренном в высокой частоте, вы различите больше киков и снейров даже если у вас нет звуковой карты и фиговые динамики/наушники

Проверяем на практике бессмысленность высоких частот дискретизации