
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Ну, а если хочется поговорить, то можно забить на ограничения (в сумме, а не в первой строке), добавляя Note:
fix: fixed bug with blablabla
Note: this fix if temporary blablabla long blablabla cause only 1st line will be displayed boldНа самом деле почему нет? Использую подобное для всяких мелких демок до 10к строк. Они всё равно в лучшем случае потом на сниппеты растаскиваются. И их читаю только я.
Мастер Вэ Ку доедал свой обед, когда ученик ворвался в его комнату и упал на колени к ногам Мастера. Слезы текли по лицу ученика и он был в полном отчаянии. Мастер Вэ Ку поставил горшок и спросил: «Что так расстроило тебя, о, юный ученик?»
«Учитель»,-сказал он, — «Я сдаюсь. Я никогда не постигну мастерства Vim! Я никогда не сумею постигнуть пути великих предков! Я никогда не осознаю суровой простоты и божественной пустоты совершенного применения Vim!»
«С чего это ты так решил?»
«Я твой худший ученик. Когда я боролся с написанием простейшего макроса, мои товарищи легко писали рекурсивные макросы. Когда я пытался вспомнить регулярное выражение для пробелов, мои соученики писали тесты гигантской сложности в Vimscript. У меня всё получается слишком медленно, я боюсь, что у меня ничего не выйдет – я опозорен.
Мастер Вэ Ку встал. «Подойди со мной к окну»,-сказал он.
Студент поднялся с пола, проследовал за Мастером Вэ Ку к окну и посмотрел на соседский дом, что был через улицу. Через окно они вместе увидели молодого человека в костюме и галстуке, работавшего над документом.
«Что ты видишь?»,-спросил Мастер Вэ Ку. Студент наблюдал какое-то время:
«Этот молодой человек использует Microsoft Excel чтобы создать таблицу. Он заносит цифры руками в каждую ячейку. Он даже не знает как использовать формулы. Он делает заглавные буквы, нажимая Caps Lock, а затем нажимает её опять, когда всё готово. Он всё так медленно делает! Я не понимаю, как он может быть таким довольным?»
«Посмотрев на этого молодого человека, чем ты не доволен?»,-вернулся к разговору Мастер Вэ Ку.
И студент немедленно достиг просветления. Звали его Ку А и позднее он стал одним из великих Мастеров.
The commit message describes what the commit will do if publishedМожет это специфика именно en? У нас в команде без всяких оговоренных заранее конвенций пишут интуитивно «fixed» и т.п, т.к. воспринимаем это как уже свершившееся действие — баг исправлен.
Исправляют бла бла
Может это специфика именно en?
Сам всегда писал и до сих пор пишу в прошедшем времени, но прочитав сравнение с Fossil пришёл к выводу, что для git более естественным форматов является именно продолжение "When applied, this commit will ...".
Насколько я понимаю, git изначально предполагал обмен изменениями через почтовые списки рассылки. То есть над проектом работает большое количество разработчиков, они присылают свои коммиты в виде писем в список рассылки. Условный Торвальдс смотрит рассылку, скажем, раз в день, и видит 10 разных патчей на одно состояние master`а, которые надо изучить и влить в общую историю.
При такой разработке "When applied, this commit will ..." выглядит логичнее. Во-первых, он больше подходит для письма — "смотрите, я написал такой патч, если вы его возьмёте, то он ...". Во-вторых, как вливать эти патчи в общую историю? На каждый из них делать ветку и merge? Тогда история превратится в серию "клубков" из мержей, по одному клубку на каждый день. Получается, нужен rebase. А если rebase и apply — это нормальный процесс вливания большинства патчей, то коммит уже нельзя считать чем-то совершённым. Коммит становится инструкцией по изменению кода, а когда и в каком порядке эти инструкции будут выполнены, заранее не известно.
никогда не видел, чтобы интеграция Git в IDE могла сравниться по простоте и возможностям с командной строкой (как только вы с ней разберетесь).
Для меня особенной разницы нет. Rebase и merge чаще предпочитаю делать в командной строке, так как есть иллюзия большего контроля над процессом (видишь больше служебной информации).
Но в общем, да: поддержка Git в IDEA очень хороша, поэтому все чаще предпочитаю делать все из PyCharm, даже rebase.
Непонятно, почему вопрос ко мне. Я такие ситуации просто не создаю.
10-к строк измененного текста, то как разбить на несколько логических коммитов?
подряд с 10-к строк измененного текстаи этот блок мне нужно растащить по разным коммитам.
В Intellij:
Правый клик на мега-коммит, 'Intereactively rebase from here'.
Там нужный мега-коммит помечаем как edit. Запускаем процесс.
Далее reset HEAD~ (лично мне проще это сделать из командной строки, но можно и через гуй сделать soft reset).
И дальше просто открываем диалог коммита и выбираем нужные куски/выключаем ненужные.
Или с помощью клавиатуры (если кусок один и большой) — просто удаляем блоки, которые не должны попасть в текущий коммит.
После коммита повторяем процесс.
Можно периодически кликать на редактируемый коммит в журнале (покуда он по-прежнему доступен) и делать compare with local, пока все изменения не будут учтены.
В самом конце кликаем на "продолжить rebase". Если это был верхний коммит, на этом всё закончился. Если он был где-то в глубине истории — поверх наребейзится оставшийся "хвост".

Вот уже никогда не понимал противопоставление GUI и command line. GUI позволяет исключить класс ошибок, связанный с неправильным набором команд, и упрощает многие действия. Command line даёт все возможности. Свой инструмент для своих задач.
сделать некоторую уникальную вещь можно только в командной строкеКаждый раз, когда такое слышу, прошу примеров, но никогда их не получаю.
Вот у нас во флоу есть такая задачка: перед вливанием таск-ветки в RC-ветку её нужно отребейзить на RC-ветку.
Это, конечно, не ежедневная задача, но пару раз в неделю — легко.
Вот так это делается через CLI:
git stash && mvn clean -P coverage && git co master && git pull && git co RC/1.3.0 && git pull && git co CBRPIS-1052 && git pull && git rebase RC/1.3.0 && git push -f && git co RC/1.3.0 && git merge --ff-only CBRPIS-1052 && git push && git br -d CBRPIS-1052 && git stash popНу можно выкинуть зачистку проекта и проход через master:
git stash && git co RC/1.3.0 && git pull && git co CBRPIS-1052 && git pull && git rebase RC/1.3.0 && git push -f && git co RC/1.3.0 && git merge --ff-only CBRPIS-1052 && git push && git stash popРасскажите как это накликать в GUI :)
Да чего тут интересного-то?
Всего лишь ребейз ветки.
Но нужно:
Ничего сложного или интересного.
Но сделать это через GUI явно будет не так быстро и просто как через CLI.
И это даже не уникальная вещь, пример которой вы просили.
Самая обычная задачка.
У консоли конечно преимущество в автоматизации. У GUI преимущество в наглядности и удобстве выполнения того, что требует внимания. Ну скажем если бы вы не знали точные названия веток, и нужные действия зависели от коммитов в них.
Интерактивный ребейз например делается так. Дифф, история, групповые отметки, всё рядом.
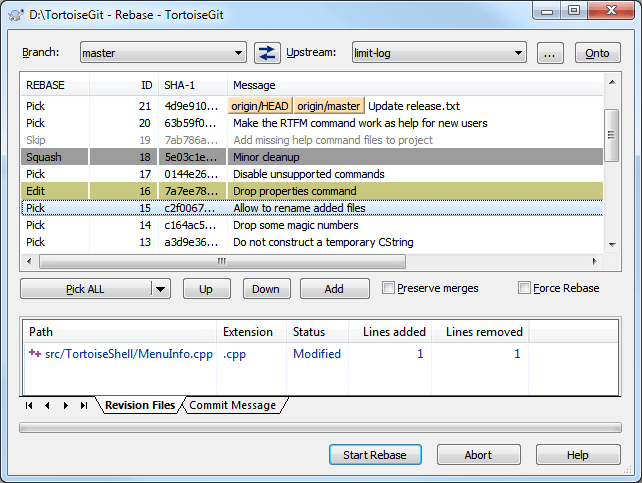
Ну или вот есть задачка с которой я часто сталкиваюсь: пересортировка/объединение коммитов в ветке.
Через CLI это быстро: git stash && git rebase --interactive origin/RC/1.3.0 && git stash pop и там уже можно переставлять объединять коммиты как хочется.
Причём обычно это команда вызывает не один раз, а несколько: сначала переставить и проверить что оно отработало, потом уже объеденить.
Как это быстро делать через GUI я даже не скажу на вскидку.
А уж как разбить один коммит на несколько отдельных в GUI я вообще не знаю.
А такая задача встречается по нескольку раз в несколько месяцев.
В смысле — сначала собрал большой коммит и уже потом понял что лучше было разбить на несколько атомарных и вообще их пересортировать.
Так и использование CLI не есть призыв отказаться от GUI :)
Я просто показывал что есть задачи которые удобнее выполнить в CLI.
Я нигде не призывал использовать только CLI.
Все приведенные тут остальные использования git, где командная строка клеится через && некорректны.
А вот тут можно подробнее?
Если вы про скрипт — да, можно и так, но пока мне удобнее скопировать и вставить из файлика.
Или есть что-то более критичное?
набрать текст многим дольше чем нажать кнопку
А код они как набирают? :)
Но все гораздо хуже, когда вы пытаетесь с помощью IDE сделать коммит, слияние, перебазирование (rebase) или сложный анализ истории коммитов.
Юзаю GitExtensions — rebase там прекрасно работает. Анализ истории — не знаю, такое редко использую.
Я постоянно читаю комментарии к коммитам. Представьте, вы работаете над унаследованным проектом, который писался кучей людей несколько лет. Открываете новый файл, там неочевидная конструкция, и вы не можете понять, зачем она.
Если коммиты пишутся хорошо, то можно понять в чем дело по одному только взгляду на git blame. К сожалению, чаще всего это не так, так как многие пишут в commit message что попало, типа: "Fixed a bug" или "Refactoring" или "Today's work" или тому подобный бред, который вообще не помогает понять историю изменений.
Да, я тоже считаю, что нужна общая дисциплина, в которой и хорошие комментарии надо писать не только к коду, но и к коммитам тоже.
Системы контроля версий существуют в том числе и потому, что история изменений тоже имеет ценность.
У меня на GitHub только private-репозитории для проектов под NDA. За исключением пары pet projects и пары небольших клонов созданных для создания PR с исправлением какой-нибудь ерунды в open source библиотеках.
А что вы хотите увидеть? Пример моего плохого кода? Или наоборот, пример идеального?
Я идеально не пишу, но сообщения к коммитам стараюсь писать осмысленные, чтобы хотя бы мне через месяц было понятно, зачем я сделал то или иное изменение.
Я не говорил, что пишу коммиты именно так, как описано в статье. Я пишу осмысленные коммиты, как правило, это одна строка с таким описанием изменения, по которому можно понять, зачем оно было сделано, со ссылкой на соответствующий тикет в багтрекере. Напимер, Do not display QA Check button when evaluation hasn't been performed (#270).
Я не вижу смысла предоставлять какие-то пруфы, так как это не rocket science и требует, в общем-то, минимальных усилий от разработчика. Не сложнее, чем чистить зубы два раза в день, некий минимальный уровень гигиены.
[IMPROVE]
- CJP (New boolean-sub-mode)
- Kernel (JS for the Scroll to element, logout-method)
[IMPROVE][REFACTOR]
- Modules[ADD]
- Rewrited JSON, packages for modules of CMS
[IMPROVE][REFACTOR]
- Ejected sources from Modules to classes
- Log-subsystem
- Main class of AST[IMPROVE][ADD]
- Microkernel [Subsystem for checking JS-errors]
[IMPROVE][REFACTOR]
- CJP
- Kernel
- Modules
- Moved subsystems from the Modules to standalone java classes [StepByStep, Pages]Ну и мои 5 копеек. Я пишу обычно идентификатор скоупа и пояснение что в нём произошло. Если это новый скоуп, то его краткое описание. Например:
$mol_textarea - multiline text editor
$conduit_article_editor: $mol_textarea for Content, style fixesIMHO, слишком большие месседжи не есть хорошо, вот почему:
Как автор:
Как читатель:
Жесть
По моему опыту люди пишут комментарии отвечающие на вопрос "что тут происходит" в сложных местах и всяких хаках, а история комитов отвечает на вопрос "зачем".
Если переносить файл командой git mv, то ничего не потеряется. Если функцию переносить из файла в файл, то в той же IDEA можно достаточно легко отследить ее миграцию используя функцию "Annotate previous version."
Вообще, ничего идеального нет, но в общем и целом, если писать осмысленные коммиты, то это иногда сильно упрощает понимание кода.
Может быть есть мега-мозги, которые помнят каждую деталь, которую они сделали в своей жизни, я же даже возвращаясь к своему проекту спустя три-четыре месяца не всегда могу ответить на вопрос, зачем же здесь сделано именно так. Что уж говорить, когда смотрю на чужой код.
С хорошей историей нередко можно разобраться в том, почему было принято то или иное решение.
В жизни вообще нет никаких гарантий. Все рано или поздно сломается либо само по себе, либо потому что кто-то по глупости или намеренно сломает. Даже железная двутавровая балка рано или поздно либо проржавеет, либо лопнет от усталости металла, либо ее кто-то украдет на металлолом.
Контр-примеры можно найти к чему угодно в этой жизни. И любую практику можно довести до абсурда. Истина, как всегда, где-то посередине.
Что касается миграции, то я в свое время работал над достаточно большим проектом, который за 10 лет совершил миграции Subversion -> Mercurial -> Git (непонятно, зачем был нужен последний шаг, но не я принимал такие решения). Тем не менее, вся история осталась доступна, начиная с первого коммита.
Но стоит кому-то перенести код из одного места в другое, и git blame превращается в тыкву.Не обязательно, просто переносить надо умеючи, и думать про историю изменений. Даже когда между VCS'ками переезжаешь, это вполне реально — к примеру, FreeBSD, когда переезжала с CVS на Subversion, всю многолетнюю историю изменений сохранила.
Поэтому единственная полезная функция комментариев к коммитам — семантическая идентификация этих самых коммитов в истории изменений.Не согласен. Коммит-логи — такая же неотъемлемая часть проекта, как и сам код и комментарии к нему, и требования к качеству оных совершенно аналогичные.
Я скажу так: лучше комментируйте свой код, пишите четкие комментарии по делу
Возьмем например этот коммит: "Fix a bug when having more than one named handler per message subscriber". Изменено 2 файла в нескольких местах. Вы в каждом месте будете один и тот же комментарий писать? А если 10 файлов изменено?
Плохо переходили.
Я когда переходил с SVN на GIT сохранил всю историю коммитов с комментариями авторами и датами.
А про «А потом команда перешла с Jira на аналог и все ваши номера стали пустым местом» можно также ответить — плохо переходили, раз не смогли сохранить номера.
Можно, но тут сложнее.
Я когда переходил с SVN на GIT сохранил всю историю коммитов с комментариями авторами и датами.
Заметьте что тут я не говорил про идентификаторы коммитов — их невозможно сохранить.
Та же фигня будет и с тикетами:
Самое важное в последнем пункте — в коммите ссылаются на идентификатор тикета, а вот идентификатор тикета сохранить очень сложно.
И в результате нумерация или:
О, а расскажите как, я скину, тому кто делал переход.
7 (семь!, боже как давно) лет назад я сделал это примерно так: https://github.com/valery1707/docs-linux/blob/master/vcs/git-svn-convert.txt
С тех пор много воды утекло — что-то могло и измениться, но не думаю что сейчас невозможно нормально мигрировать с TFS на GIT/HG/Whatever — скорее всего плохо искали.
Более того, я уверен что вам историю коммитов можно даже и восстановить, если остался доступ к TFS: сначала мигрировать корректно, а потом наложить все коммиты что вы создали позднее.
Проблема в том что в БагТрекере не всегда ясно зачем нужны эти изменения — в лучшем случае из-за чего. А это не одно и тоже.
Очень часто баз описан как Стоппер! Ничего не работает - NullPointerException.
Да, можно и в тикете написать из-за чего происходит ошибка и зачем мы вносим изменения.
Но есть вторая проблема: отделение изменений от причин их создания.
Да, есть трекер в котором разработчик возможно это описал.
Но нужно ещё попасть из коммита в трекер — скопировать ID тикете, открыть трекер, найти там тикет.
Потом среди кучи комментариев понять какой из них описывает собственно изменения, а какие просто описывают поиск ошибки и обсуждают меню корпоративного обеда.
А ещё часто бывает когда в рамках одного тикете решаются несколько разных проблем. Есть тикет Не работает экспорт файла: сначала там были ошибки в формате, потом NPE в паре мест, потом мы файл не создавали по какой-то причине, а потом оказалось что ожидался XML внутри ZIP, а мы сделали JSON.
Тикет один, коммитов много, причина каждого коммита хорошо если вообще понятна из комментариев к тикету.
Другая ситуация: Тикет один и даже понятный и лаконичный.
Но коммитов много, так как задача большая и много атомарных коммитов лучше через изменение 50% системы с одним коммитом Так нужно для тикета #13257.
Так что уверен что баг-трекер не панацея и нормальные комментарии к коммитам необходимы.
У нас баги описывают правильно, с шагами, что ожидалось и что получилось. Формулировок «Ничего не работает» не пишут.
Вам повезло. Вот правда.
Разница между тикетом и коммитом состоит в том что
требовать) полноценного описанияПисать кучу текста в коммит и дублировать в таск-трекер — вот такого не должно быть.
Я и не говорил про дублирование.
В тикете не всегда обязательно писать полное описание причин ошибки и методов её устранения.
У на это таск-трекер. Если у вас это коммиты, ну ок, хотя лично мне было бы неудобно, наверно.
Удобство — понятие относительное.
Мне вот удобно всё видеть в коммитах потому что я могу прямо из среды разработки в offline в отпуске на Багамах в туалете понять что и зачем происходили в классе. Да хоть из консоли, лишь бы исходники были.
А вам исходников не достаточно — нужен доступ ещё и к таск-трекеру. Причём не только сетевой доступ, но и организационный. Ну ок.
в тикете не всю информацию стоит раскрывать (показывать заказчику что у нас была огромная дырень в безопасности, которую мы закроем при обновлении через 2 месяца — вот он обрадуется прямо сейчас, ага)
Clean your room (приберись в комнате)
Close the door (закрой дверь)
Я бы сказал, в английском это смотрится более естественно, так как там меньше разных словоформ. Инфинитив без to это самая нейтральная форма. У нас нейтральной считается обезличенные "добавлено", "изменено".
Если переводить на русский, то лучше тоже инфинитивом, ну как команды типа "Стоять!" — "Прибраться в комнате", "Закрыть дверь", "Смержить ветку 'myfeature'". Чтобы можно было мысленно добавить "Надо" или "Надо было".
[mandatory ticket name][optional subsystem] description
[SPARK-6237][NETWORK] Network-layer changes to allow stream upload.
[SPARK-18073][DOCS][WIP] Migrate wiki to spark.apache.org web site
Как следует писать комментарии к коммитам