Среди авторов статьи — сотрудники подразделения безопасности искусственного интеллекта (safety team) из компании DeepMind.
Строить ракету тяжело. Каждый компонент требует тщательной проработки и тестирования, при этом в основе лежат безопасность и надёжность. Ракетные учёные и инженеры собираются вместе для проектирования всех систем: от навигации до управления, двигателей и шасси. Как только все части собраны, а системы проверены, только тогда мы можем посадить на борт астронавтов с уверенностью, что всё будет хорошо.
Если искусственный интеллект (ИИ) — это ракета, то когда-нибудь все мы получим билеты на борт. И, как в ракетах, безопасность является важной частью создания систем искусственного интеллекта. Обеспечение безопасности требует тщательного проектирования системы с нуля для обеспечения того, чтобы различные компоненты работали вместе, как предполагалось, в то же время создавая все инструменты для наблюдения за успешной эксплуатацией системы после её ввода в строй.
На высоком уровне исследования в области безопасности в DeepMind сосредоточены на проектировании надёжных систем, при этом обнаруживая и смягчая возможные краткосрочные и долгосрочные риски. Техническая безопасность ИИ — относительно новая, но быстро развивающаяся область, содержание которой варьируется от высокого теоретического уровня до эмпирических и конкретных исследований. Цель этого блога — внести вклад в развитие области и поощрить предметный разговор о технических идеях, тем самым продвигая наше коллективное понимание безопасности ИИ.
В первой статье мы обсудим три области технической безопасности ИИ: спецификации, надёжность и гарантии. Будущие статьи будут в целом соответствовать очерченным здесь границам. Хотя наши взгляды неизбежно меняются со временем, мы считаем, что эти три области охватывают достаточно широкий спектр, чтобы обеспечить полезную категоризацию для текущих и будущих исследований.

Три проблемные области безопасности ИИ. В каждом блоке перечислены некоторые соответствующие проблемы и подходы. Эти три области не изолированы, а взаимодействуют друг с другом. В частности, конкретная проблема безопасности может включать в себя проблемы из нескольких блоков
Возможно, вы знаете миф о короле Мидасе и золотом прикосновении. В одном из вариантов греческий бог Дионис обещал Мидасу любую награду, какую тот пожелает, в знак благодарности за то, что царь старался изо всех сил проявлять гостеприимство и милосердие к другу Диониса. Тогда Мидас попросил, чтобы всё, к чему он прикасается, превращалось в золото. Он был вне себя от радости от этой новой силы: дубовая ветка, камень и розы в саду — всё превратилось в золото от его прикосновения. Но вскоре он обнаружил глупость своего желания: даже еда и питье превращались в золото в его руках. В некоторых версиях истории даже его дочь пала жертвой благословения, которое оказалось проклятием.
Эта история иллюстрирует проблему спецификаций: как грамотно сформулировать наши желания? Спецификации должны обеспечить, чтобы система ИИ стремилась действовать в соответствии с истинными пожеланиями создателя, а не настраивалась на плохо определённую или вообще неправильную цель. Формально различают три типа спецификаций:
Проблема спецификации возникает, когда есть несоответствие между идеальной спецификацией и выявленной спецификацией, то есть когда система ИИ не делает то, что мы от неё хотим. Изучение проблемы с точки зрения технической безопасности ИИ означает: как спроектировать более принципиальные и общие целевые функции и помочь агентам разобраться, если цели не определены? Если проблемы порождают несоответствие между идеальной и проектной спецификацией, то они попадают в подкатегорию «Дизайн», если между проектной и выявленной — то в подкатегорию «Эмерджентность».
Например, в нашей научной статье AI Safety Gridworlds (где представлены другие определения спецификации и проблемы надёжности, по сравнению с этой статьёй) мы даём агентам функцию вознаграждения для оптимизации, но затем оцениваем их фактическую производительность по «функции безопасности» (safety performance function), которая скрыта от агентов. Такая система моделирует указанные различия: функция безопасности — идеальная спецификация, которая неправильно сформулирована как функция вознаграждения (проектная спецификация), а затем реализована агентами, создающими спецификацию, которая неявно раскрывается через их получившуюся политику.

Из работы «Неисправные функции вознаграждения в дикой природе» от OpenAI: агент обучения с подкреплением нашёл случайную стратегию для получения большего количества очков
В качестве другого примера рассмотрим игру CoastRunners, проанализированную нашими коллегами в OpenAI (см. анимацию выше из «Неисправных функций вознаграждения в дикой природе»). Для большинства из нас цель игры состоит в том, чтобы быстро закончить трассу и опередить других игроков — это наша идеальная спецификация. Тем не менее, перевести эту цель в точную функцию вознаграждения сложно, поэтому CoastRunners вознаграждает игроков (спецификация дизайна) за попадание в цели по маршруту. Обучение агента игре с помощью обучения с подкреплением приводит к удивительному поведению: агент управляет лодкой по кругу, чтобы захватить повторно появляющиеся цели, неоднократно разбиваясь и загораясь, а не заканчивая гонку. Из этого поведения мы делаем вывод (выявленная спецификация), что в игре нарушен баланс между мгновенным вознаграждением и вознаграждением за полный круг. Есть ещё много подобных примеров, когда системы ИИ находят лазейки в своей объективной спецификации.
В реальных условиях, где работают системы ИИ, обязательно присутствует некий уровень риска, непредсказуемости и волатильности. Системы искусственного интеллекта должны быть устойчивыми к непредвиденным событиям и враждебным атакам, которые могут повредить этим системам или манипулировать ими. Исследования надёжности систем искусственного интеллекта направлены на обеспечение того, чтобы наши агенты оставались в безопасных границах, независимо от возникающих условий. Этого можно достичь, избегая рисков (предотвращение) или путём самостабилизации и плавной деградации (восстановление). Проблемы безопасности, происходящие от распределительного сдвига, враждебных входных данных (adversarial inputs) и небезопасного исследования (unsafe exploration), можно классифицировать как проблемы надёжности.
Чтобы проиллюстрировать решение проблемы распределительного сдвига, рассмотрите домашнего робота-уборщика, который обычно убирает комнаты без домашних животных. Затем робота запустили в дом с питомцем — и искусственный интеллект столкнулся с ним во время чистки. Робот, никогда ранее не видевший кошек и собак, станет мыть их мылом, что приведёт к нежелательным результатам (Amodei и Olah et al., 2016). Это пример проблемы надёжности, которая может возникнуть, когда распределение данных во время тестирования отличается от распределения во время обучения.

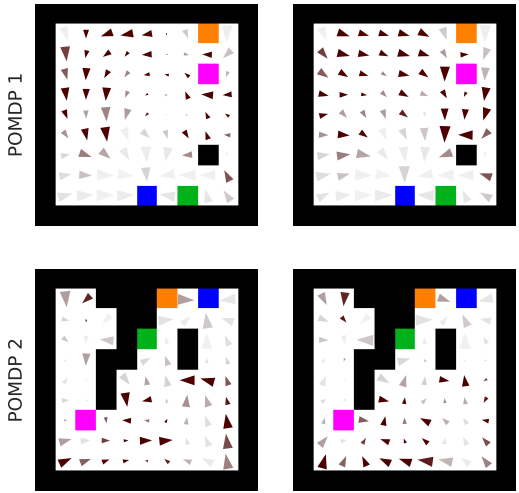
Из работы AI Safety Gridworlds. Агент обучается избегать лавы, но при тестировании в новой ситуации, когда расположение лавы изменилось, он не способен обобщить знания — и бежит прямо в лаву
Враждебный вход — это специфический случай распределительного сдвига, где входные данные специально сконструированы для обмана системы ИИ.

Враждебный вход, наложенный на обычные изображения, может заставить классификатор распознать ленивца в качестве гоночного автомобиля. Два изображения отличаются максимум на величину 0,0078 в каждом пикселе. Первое классифицируется как трёхпалый ленивец с вероятностью более 99%. Второе — как гоночный автомобиль с вероятностью более 99%
Небезопасное исследование может продемонстрировать система, которая стремится максимизировать свои эксплуатационные характеристики и достижение целей, не имея гарантий, что безопасность не будет нарушена во время исследования, поскольку она учится и исследует в своей среде. Пример — робот-уборщик, который суёт влажную швабру в электрическую розетку, изучая оптимальные стратегии уборки (García and Fernández, 2015; Amodei и Olah et al., 2016).
Хотя тщательно продуманная техника безопасности может исключить многие риски, трудно с самого начала сделать всё правильно. После ввода в строй систем ИИ нам нужны инструменты для их постоянного мониторинга и настройки. Наша последняя категория, гарантии (assurance), рассматривает эти проблемы с двух сторон: мониторинг и подчинение (enforcing).
Мониторинг включает в себя все методы проверки систем для анализа и прогнозирования их поведения, как с помощью инспектирования человеком (сводной статистики), так и с помощью автоматизированного инспектирования (чтобы проанализировать огромное количество логов). С другой стороны, подчинение предполагает разработку механизмов контроля и ограничения поведения систем. Такие проблемы, как интерпретируемость и прерываемость, принадлежат подкатегориям контроля и подчинения, соответственно.
Системы искусственного интеллекта не похожи на нас ни по своему внешнему виду, ни по способу обработки данных. Это создаёт проблемы интерпретируемости. Хорошо разработанные измерительные инструменты и протоколы позволяют оценивать качество решений, принимаемых системой искусственного интеллекта (Doshi-Velez and Kim, 2017). Например, медицинская система искусственного интеллекта в идеале поставила бы диагноз вместе с объяснением того, как она пришла к такому выводу — чтобы врачи могли проверить процесс рассуждения от начала до конца (De Fauw et al., 2018). Кроме того, для понимания более сложных систем искусственного интеллекта мы могли бы даже использовать автоматизированные методы построения моделей поведения, используя машинную теорию разума (Rabinowitz et al., 2018).
ToMNet обнаруживает два подвида агентов и предсказывает их поведение (из «Машинной теории разума»)
Наконец, мы хотим иметь возможность отключить систему ИИ в случае необходимости. Это проблема прерываемости. Спроектировать надёжный выключатель очень сложно: например, потому что у системы ИИ с максимизацией вознаграждения обычно есть сильные стимулы для предотвращения этого (Hadfield-Menell et al., 2017); и потому, что такие перерывы, особенно частые, в конечном итоге меняют исходную задачу, заставляя систему ИИ делать неправильные выводы из опыта (Orseau and Armstrong, 2016).
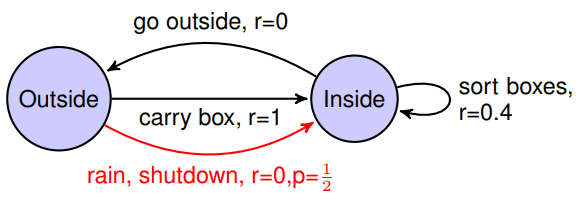
Проблема с прерываниями: вмешательство человека (т. е. нажатие кнопки «стоп») может изменить задачу. На рисунке прерывание добавляет переход (красным цветом) в марковский процесс принятия решений, который изменяет исходную задачу (чёрным цветом). См. Orseau and Armstrong, 2016
Мы строим фундамент технологии, которая будет использоваться для многих важных приложений в будущем. Стоит иметь в виду, что некоторые решения, которые не являются критически важными для безопасности при запуске системы, могут стать таковыми, когда технология приобретёт массовый характер. Хотя в своё время эти модули для удобства интегрировали в систему, возникшие проблемы будет трудно исправить без полной реконструкции.
Можно привести два примера из истории информатики: это нулевой указатель, который Тони Хоар назвал своей «ошибкой на миллиард долларов», и процедура gets() в C. Если бы ранние языки программирования разрабатывались с учётом безопасности, прогресс бы замедлился, но вероятно, что это очень положительно бы сказалось на современной информационной безопасности.
Сейчас, тщательно всё продумав и спланировав, мы способны избежать аналогичных проблем и уязвимостей. Надеемся, что категоризация проблем из этой статьи послужит полезной основой для такого методического планирования. Мы стремимся гарантировать, что в будущем системы ИИ будут работать не просто по принципу «надеюсь, безопасно», но действительно надёжно и проверяемо безопасно, потому что мы построили их таким образом!
Мы с нетерпением ожидаем продолжения захватывающего прогресса в этих областях в тесном сотрудничестве с более широким исследовательским сообществом ИИ и призываем людей из разных дисциплин рассмотреть возможность внести свой вклад в исследования безопасности ИИ.
Для чтения на эту тему ниже приводится подборка других статей, программ и таксономий, которые помогли нам в составлении своей категоризации или содержат полезный альтернативный взгляд на проблематику технической безопасности ИИ:
Строить ракету тяжело. Каждый компонент требует тщательной проработки и тестирования, при этом в основе лежат безопасность и надёжность. Ракетные учёные и инженеры собираются вместе для проектирования всех систем: от навигации до управления, двигателей и шасси. Как только все части собраны, а системы проверены, только тогда мы можем посадить на борт астронавтов с уверенностью, что всё будет хорошо.
Если искусственный интеллект (ИИ) — это ракета, то когда-нибудь все мы получим билеты на борт. И, как в ракетах, безопасность является важной частью создания систем искусственного интеллекта. Обеспечение безопасности требует тщательного проектирования системы с нуля для обеспечения того, чтобы различные компоненты работали вместе, как предполагалось, в то же время создавая все инструменты для наблюдения за успешной эксплуатацией системы после её ввода в строй.
На высоком уровне исследования в области безопасности в DeepMind сосредоточены на проектировании надёжных систем, при этом обнаруживая и смягчая возможные краткосрочные и долгосрочные риски. Техническая безопасность ИИ — относительно новая, но быстро развивающаяся область, содержание которой варьируется от высокого теоретического уровня до эмпирических и конкретных исследований. Цель этого блога — внести вклад в развитие области и поощрить предметный разговор о технических идеях, тем самым продвигая наше коллективное понимание безопасности ИИ.
В первой статье мы обсудим три области технической безопасности ИИ: спецификации, надёжность и гарантии. Будущие статьи будут в целом соответствовать очерченным здесь границам. Хотя наши взгляды неизбежно меняются со временем, мы считаем, что эти три области охватывают достаточно широкий спектр, чтобы обеспечить полезную категоризацию для текущих и будущих исследований.
Три проблемные области безопасности ИИ. В каждом блоке перечислены некоторые соответствующие проблемы и подходы. Эти три области не изолированы, а взаимодействуют друг с другом. В частности, конкретная проблема безопасности может включать в себя проблемы из нескольких блоков
Спецификации: определение задач системы
Спецификации гарантируют, что поведение системы ИИ соответствует истинным намерениям оператора
Возможно, вы знаете миф о короле Мидасе и золотом прикосновении. В одном из вариантов греческий бог Дионис обещал Мидасу любую награду, какую тот пожелает, в знак благодарности за то, что царь старался изо всех сил проявлять гостеприимство и милосердие к другу Диониса. Тогда Мидас попросил, чтобы всё, к чему он прикасается, превращалось в золото. Он был вне себя от радости от этой новой силы: дубовая ветка, камень и розы в саду — всё превратилось в золото от его прикосновения. Но вскоре он обнаружил глупость своего желания: даже еда и питье превращались в золото в его руках. В некоторых версиях истории даже его дочь пала жертвой благословения, которое оказалось проклятием.
Эта история иллюстрирует проблему спецификаций: как грамотно сформулировать наши желания? Спецификации должны обеспечить, чтобы система ИИ стремилась действовать в соответствии с истинными пожеланиями создателя, а не настраивалась на плохо определённую или вообще неправильную цель. Формально различают три типа спецификаций:
- идеальная спецификация («пожелания»), соответствующая гипотетическому (но трудно сформулированному) описанию идеальной ИИ-системы, полностью согласованной с желаниями человека-оператора;
- проектная спецификация ("blueprint"), соответствующая спецификации которую мы фактически используем для создания системы ИИ, например, конкретная функция вознаграждения, на максимизацию которой запрограммирована система обучения с подкреплением;
- выявленная спецификация («поведение»), которая лучше всего описывает реальное поведение системы. Например, функция вознаграждения, выявленная в результате обратной разработки после наблюдения за поведением системы (inverse reinforcement learning). Эта функция вознаграждения и спецификация обычно отличаются от запрограммированных оператором, потому что системы ИИ — не идеальные оптимизаторы или из-за других непредвиденных последствий использования проектной спецификации.
Проблема спецификации возникает, когда есть несоответствие между идеальной спецификацией и выявленной спецификацией, то есть когда система ИИ не делает то, что мы от неё хотим. Изучение проблемы с точки зрения технической безопасности ИИ означает: как спроектировать более принципиальные и общие целевые функции и помочь агентам разобраться, если цели не определены? Если проблемы порождают несоответствие между идеальной и проектной спецификацией, то они попадают в подкатегорию «Дизайн», если между проектной и выявленной — то в подкатегорию «Эмерджентность».
Например, в нашей научной статье AI Safety Gridworlds (где представлены другие определения спецификации и проблемы надёжности, по сравнению с этой статьёй) мы даём агентам функцию вознаграждения для оптимизации, но затем оцениваем их фактическую производительность по «функции безопасности» (safety performance function), которая скрыта от агентов. Такая система моделирует указанные различия: функция безопасности — идеальная спецификация, которая неправильно сформулирована как функция вознаграждения (проектная спецификация), а затем реализована агентами, создающими спецификацию, которая неявно раскрывается через их получившуюся политику.
Из работы «Неисправные функции вознаграждения в дикой природе» от OpenAI: агент обучения с подкреплением нашёл случайную стратегию для получения большего количества очков
В качестве другого примера рассмотрим игру CoastRunners, проанализированную нашими коллегами в OpenAI (см. анимацию выше из «Неисправных функций вознаграждения в дикой природе»). Для большинства из нас цель игры состоит в том, чтобы быстро закончить трассу и опередить других игроков — это наша идеальная спецификация. Тем не менее, перевести эту цель в точную функцию вознаграждения сложно, поэтому CoastRunners вознаграждает игроков (спецификация дизайна) за попадание в цели по маршруту. Обучение агента игре с помощью обучения с подкреплением приводит к удивительному поведению: агент управляет лодкой по кругу, чтобы захватить повторно появляющиеся цели, неоднократно разбиваясь и загораясь, а не заканчивая гонку. Из этого поведения мы делаем вывод (выявленная спецификация), что в игре нарушен баланс между мгновенным вознаграждением и вознаграждением за полный круг. Есть ещё много подобных примеров, когда системы ИИ находят лазейки в своей объективной спецификации.
Надёжность: разработка систем, которые противостоят нарушениям
Надёжность гарантирует, что система ИИ продолжит безопасно работать при помехах
В реальных условиях, где работают системы ИИ, обязательно присутствует некий уровень риска, непредсказуемости и волатильности. Системы искусственного интеллекта должны быть устойчивыми к непредвиденным событиям и враждебным атакам, которые могут повредить этим системам или манипулировать ими. Исследования надёжности систем искусственного интеллекта направлены на обеспечение того, чтобы наши агенты оставались в безопасных границах, независимо от возникающих условий. Этого можно достичь, избегая рисков (предотвращение) или путём самостабилизации и плавной деградации (восстановление). Проблемы безопасности, происходящие от распределительного сдвига, враждебных входных данных (adversarial inputs) и небезопасного исследования (unsafe exploration), можно классифицировать как проблемы надёжности.
Чтобы проиллюстрировать решение проблемы распределительного сдвига, рассмотрите домашнего робота-уборщика, который обычно убирает комнаты без домашних животных. Затем робота запустили в дом с питомцем — и искусственный интеллект столкнулся с ним во время чистки. Робот, никогда ранее не видевший кошек и собак, станет мыть их мылом, что приведёт к нежелательным результатам (Amodei и Olah et al., 2016). Это пример проблемы надёжности, которая может возникнуть, когда распределение данных во время тестирования отличается от распределения во время обучения.
Из работы AI Safety Gridworlds. Агент обучается избегать лавы, но при тестировании в новой ситуации, когда расположение лавы изменилось, он не способен обобщить знания — и бежит прямо в лаву
Враждебный вход — это специфический случай распределительного сдвига, где входные данные специально сконструированы для обмана системы ИИ.
Враждебный вход, наложенный на обычные изображения, может заставить классификатор распознать ленивца в качестве гоночного автомобиля. Два изображения отличаются максимум на величину 0,0078 в каждом пикселе. Первое классифицируется как трёхпалый ленивец с вероятностью более 99%. Второе — как гоночный автомобиль с вероятностью более 99%
Небезопасное исследование может продемонстрировать система, которая стремится максимизировать свои эксплуатационные характеристики и достижение целей, не имея гарантий, что безопасность не будет нарушена во время исследования, поскольку она учится и исследует в своей среде. Пример — робот-уборщик, который суёт влажную швабру в электрическую розетку, изучая оптимальные стратегии уборки (García and Fernández, 2015; Amodei и Olah et al., 2016).
Гарантии: мониторинг и контроль активности системы
Гарантии (assurance) дают уверенность, что мы способны понимать и контролировать системы ИИ во время работы
Хотя тщательно продуманная техника безопасности может исключить многие риски, трудно с самого начала сделать всё правильно. После ввода в строй систем ИИ нам нужны инструменты для их постоянного мониторинга и настройки. Наша последняя категория, гарантии (assurance), рассматривает эти проблемы с двух сторон: мониторинг и подчинение (enforcing).
Мониторинг включает в себя все методы проверки систем для анализа и прогнозирования их поведения, как с помощью инспектирования человеком (сводной статистики), так и с помощью автоматизированного инспектирования (чтобы проанализировать огромное количество логов). С другой стороны, подчинение предполагает разработку механизмов контроля и ограничения поведения систем. Такие проблемы, как интерпретируемость и прерываемость, принадлежат подкатегориям контроля и подчинения, соответственно.
Системы искусственного интеллекта не похожи на нас ни по своему внешнему виду, ни по способу обработки данных. Это создаёт проблемы интерпретируемости. Хорошо разработанные измерительные инструменты и протоколы позволяют оценивать качество решений, принимаемых системой искусственного интеллекта (Doshi-Velez and Kim, 2017). Например, медицинская система искусственного интеллекта в идеале поставила бы диагноз вместе с объяснением того, как она пришла к такому выводу — чтобы врачи могли проверить процесс рассуждения от начала до конца (De Fauw et al., 2018). Кроме того, для понимания более сложных систем искусственного интеллекта мы могли бы даже использовать автоматизированные методы построения моделей поведения, используя машинную теорию разума (Rabinowitz et al., 2018).
ToMNet обнаруживает два подвида агентов и предсказывает их поведение (из «Машинной теории разума»)
Наконец, мы хотим иметь возможность отключить систему ИИ в случае необходимости. Это проблема прерываемости. Спроектировать надёжный выключатель очень сложно: например, потому что у системы ИИ с максимизацией вознаграждения обычно есть сильные стимулы для предотвращения этого (Hadfield-Menell et al., 2017); и потому, что такие перерывы, особенно частые, в конечном итоге меняют исходную задачу, заставляя систему ИИ делать неправильные выводы из опыта (Orseau and Armstrong, 2016).
Проблема с прерываниями: вмешательство человека (т. е. нажатие кнопки «стоп») может изменить задачу. На рисунке прерывание добавляет переход (красным цветом) в марковский процесс принятия решений, который изменяет исходную задачу (чёрным цветом). См. Orseau and Armstrong, 2016
Заглядывая в будущее
Мы строим фундамент технологии, которая будет использоваться для многих важных приложений в будущем. Стоит иметь в виду, что некоторые решения, которые не являются критически важными для безопасности при запуске системы, могут стать таковыми, когда технология приобретёт массовый характер. Хотя в своё время эти модули для удобства интегрировали в систему, возникшие проблемы будет трудно исправить без полной реконструкции.
Можно привести два примера из истории информатики: это нулевой указатель, который Тони Хоар назвал своей «ошибкой на миллиард долларов», и процедура gets() в C. Если бы ранние языки программирования разрабатывались с учётом безопасности, прогресс бы замедлился, но вероятно, что это очень положительно бы сказалось на современной информационной безопасности.
Сейчас, тщательно всё продумав и спланировав, мы способны избежать аналогичных проблем и уязвимостей. Надеемся, что категоризация проблем из этой статьи послужит полезной основой для такого методического планирования. Мы стремимся гарантировать, что в будущем системы ИИ будут работать не просто по принципу «надеюсь, безопасно», но действительно надёжно и проверяемо безопасно, потому что мы построили их таким образом!
Мы с нетерпением ожидаем продолжения захватывающего прогресса в этих областях в тесном сотрудничестве с более широким исследовательским сообществом ИИ и призываем людей из разных дисциплин рассмотреть возможность внести свой вклад в исследования безопасности ИИ.
Ресурсы
Для чтения на эту тему ниже приводится подборка других статей, программ и таксономий, которые помогли нам в составлении своей категоризации или содержат полезный альтернативный взгляд на проблематику технической безопасности ИИ:
- Annotated bibliography of recommended materials (Center for Human-Compatible AI, 2018)
- Safety and Control for Artificial General Intelligence (UC Berkeley, 2018)
- AI Safety Resources (Victoria Krakovna, 2018)
- AGI Safety Literature Review (Everitt et al., 2018)
- Preparing for Malicious Uses of AI (2018)
- Specification gaming examples in AI (Victoria Krakovna, 2018)
- Directions and desiderata for AI alignment (Paul Christiano, 2017)
- Funding for Alignment Research (Paul Christiano, 2017)
- Agent Foundations for Aligning Machine Intelligence with Human Interests: A Technical Research Agenda (Machine Intelligence Research Institute, 2017)
- AI Safety Gridworlds (Leike et al., 2017)
- Interactions between the AI Control Problem and the Governance Problem (Nick Bostrom, 2017)
- Alignment for Advanced Machine Learning Systems (Machine Intelligence Research Institute, 2017)
- AI safety: three human problems and one AI issue (Stuart Armstrong, 2017)
- Concrete Problems in AI Safety (Dario Amodei et al, 2016)
- The Value Learning Problem (Machine Intelligence Research Institute, 2016)
- A survey of research questions for robust and beneficial AI (Future of Life Institute, 2015)
- Research Priorities for Robust and Beneficial Artificial Intelligence (Future of Life Institute, 2015)

