
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Почему MIPS-подобный RISC, а не собственная реализация RISC-V?
Здравствуйте,
Конвейер делали?
Пока нет.
Харрис и Харрис читали, там куча всякого, что было бы вам интересно и помогло бы улучшить результат.
Спасибо большое за наводку.
Почему MIPS-подобный RISC, а не собственная реализация RISC-V
Не сильно знаком с RISC-V. Изучения MIPS был частью университетского курса.
В ПЛИС пробовали заливать? )
Пробовал заливать в Cyclone 4. Столкнулся с некоторыми проблемами.
По поводу конвейера, не могу не прорекламировать проект под названием SchoolMIPS (https://github.com/MIPSfpga/schoolMIPS). Кроме конвейера там имеется сопроцессор и шина AHB-lite в топовой ветке. Плюс он реализован по цифровой схемотехнике от Харрис и Харрис. И собственно из него черпаю вдохновение для своего ядра, правда на основе risc-v. И ещё по поводу ресурсов, попробуйте синтезировать только ALU, ресурсов потребуется сразу же больше.
Складывается впечатление что у каждого второго электронщика есть своя «великая и гениальная» архитектура процессора. Обычно она лежит в голове или в заметках где-нибудь внутри «Новая папка (3)» на файлопомойке.Как у каждого второго программиста есть великая и гениальная операционка.
Здравствуйте, опередили однако) (сам недавно сел за описание небольшого ядра). Интересно сколько занимает Ваш проект на циклоне 4 или на любой другой ПЛИС, ибо увидел пару операций в АЛУ, которые "съедают" достаточно много ресурсов (/ и %)?
Здраствуйте,
Вот так выглядит вывод quartus prime после компиляции для cyclone4. Сейчас пробую портировать на cyclone 4. Код можно найти тут.
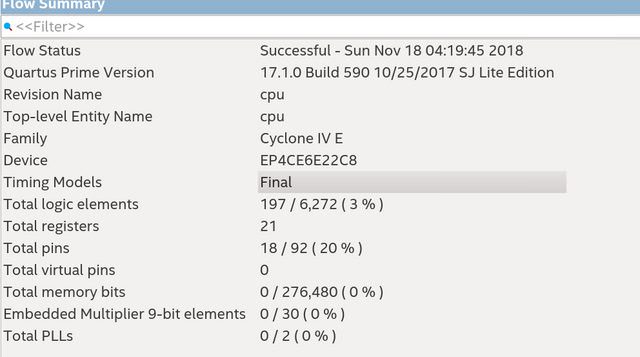
Здраствуйте, спасибо за советы.
Можете, пожалуйста, рассказать поподробнее, почему такие конструкции некорректно работают?
Написание простого процессора и окружения для него