Задаетесь вопросами: «Как написать чисто, понятно? Как быстро разобраться в чужом коде?»
Вспомните о приведенных ниже правилах и примените их!
В статье не рассматриваются базовые правила именования переменных и функций, синтаксические отступы и масштабная тема рефакторинга. Рассматриваются 5 простых правил по упрощению кода и снижению нагрузки на мозг в процессе разработки.
Рассмотрим процесс восприятия данных, чтобы соотнести описанные правила с процессом восприятия и определить критерии простого кода.
Упрощенный процесс восприятия состоит из следующих этапов:
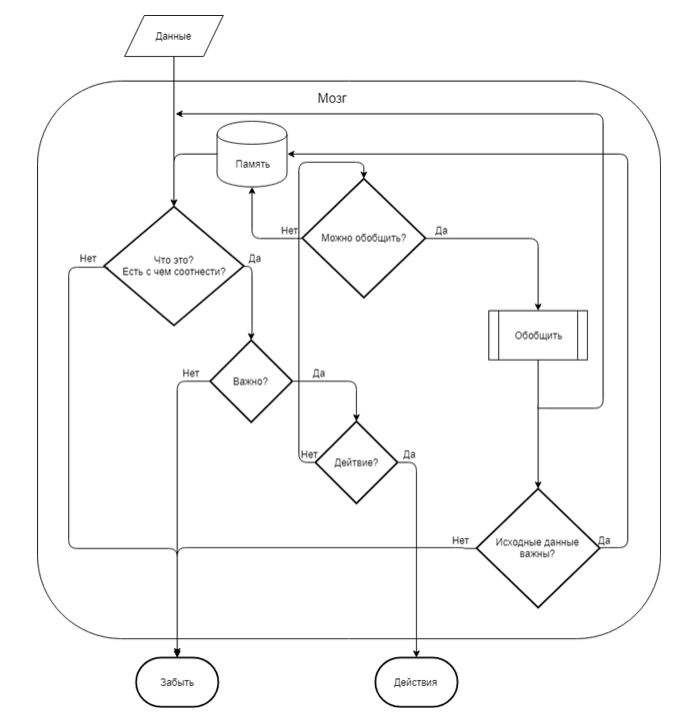
Ученые разделяют память на кратковременную и долгосрочную. Кратковременная память мала по объему, но извлечение и сохранение информации выполняет мгновенно. Кратковременная память — кэш мозга. В нем может храниться 7+-2 слов, цифр, предметов. Долгосрочная память больше по объему, но она требует больших затрат энергии (усилий) на сохранение и извлечение информации, чем краткосрочная.
Выводы:
Приступим к описанию правил.
Правило 1. Используем в условиях утверждение, избавляемся от «не».
Удаление оператора «не» уменьшает количество анализируемых элементов. Также, во многих языках программирования для оператора отрицания используется «!». Данный знак легко пропустить при прочтении кода.
Сравните:
После:
Правило 2. Уменьшение уровня вложенности.
Во время анализа кода каждый уровень вложенности требуется удерживать в памяти. Уменьшаем количество уровней – уменьшаем затраты мыслетоплива.
Рассмотрим способы уменьшения количества уровней вложенности.
1) Возврат управления. Отсекаем часть случаев и сосредотачиваемся на оставшихся.
Преобразуем в
или
или
Расширенный пример приведен в правиле 5. Обратите внимание на выброс исключения.
2) Выделение метода. Имя функции — результат обобщения.
в
3) Объединение условий.
в
4) Вынесение переменных и разделение на смысловые блоки. В результате блоки можно изменять независимо, а главное читать и воспринимать такой код гораздо проще. Один блок – одна функциональность. Частый случай — поиск с обработкой. Необходимо разбить код на отдельные смысловые блоки: поиск элемента, обработка.
в
Правило 3. Избавляемся от индексаторов и обращений через свойства.
Индексатор — операция обращения к элементу массива по индексу arr[index].
В процессе восприятия кода, мозг оперирует символами [] как разделителями, а индексатором как выражением.
Индексатор — место частых ошибок. В силу кратких имен индексов перепутать I, j или k очень легко.
В приведенном выше примере в строчке result[fieldsGroups[j].groupName] = {}; допущена ошибка:
используется j, вместо i.
Для того, чтоб обнаружить где используется именно i-тое значение приходится:
1) визуально выделять переменную массива
2) анализировать каждое вхождение на использование нужного индексатора I,j, i-1, j-1 и т.д., держа в восприятии места использования индексаторов и уже отождествленные обращения.
Выделив индексатор в переменную, сократим количество опасных мест и сможем легко задействовать мозг на восприятие переменной, без необходимости запоминания.
После переработки:
Визуальное выделение происходит гораздо проще, а современные среды разработки и редакторы помогают, выделяя подстроки в разных участках кода.
Правило 4. Группируем блоки по смыслу.
Используем психологический эффект восприятия — «Эффект близости»: близко расположенные фигуры при восприятии объединяются. Получить код, подготовленный для анализа и обобщения в процессе восприятия, и сократить количество информации, сохраняемой в памяти, можно расположив рядом строки, объединенные смыслом или близкие по функционалу, разделив их пустой строкой.
До:
После:
В верхнем примере 7 блоков, в нижнем 3: получение значений, накопление в цикле, установка свойств менеджера.
Отступами хорошо выделять места, на которые стоит обратить внимание. Так, строки
помимо зависимости от предыдущих вычислений, накапливают значения в переменной accumulatedPercentage. Для акцентирования внимания на отличии, код выделен отступом.
Одним из частных случаев применения правила является объявление локальных переменных как можно ближе к месту использования.
Правило 5. Следование принципу единственности ответственности.
Это первый из принципов SOLID в ООП, но помимо классов может быть применён к проектам, модулям, функциям, блокам кода, проектным командам или отдельным разработчикам. При вопросе кто или что отвечает за данную область сразу ясно — кто или что. Одна связь всегда проста. Каждый класс обобщается до одного понятия, фразы, метафоры. В результате меньше запоминать, процесс восприятия проходит проще и эффективнее.
В заключении комплексный пример:
После замены индексаторов ContainsKeу, инвертирования ветвления, выделения метода и уменьшения уровней вложенности получилось:
Первая функция отвечает за получение состояний из словарей, вторая за их комбинирование в новое.
Представленные правила просты, но в комбинации дают мощный инструмент по упрощению кода и снижению нагрузки на память в процессе разработки. Всегда их соблюдать не получится, но в случае если вы осознаете, что не понимаете код, проще всего начать с них. Они не раз помогали автору в самых затруднительных случаях.
Вспомните о приведенных ниже правилах и примените их!
В статье не рассматриваются базовые правила именования переменных и функций, синтаксические отступы и масштабная тема рефакторинга. Рассматриваются 5 простых правил по упрощению кода и снижению нагрузки на мозг в процессе разработки.
Рассмотрим процесс восприятия данных, чтобы соотнести описанные правила с процессом восприятия и определить критерии простого кода.
Упрощенный процесс восприятия состоит из следующих этапов:
- Поступающая через рецепторы данные соотносятся с предыдущим опытом.
- Если соотнесения нет – это шум. Шум быстро забывается. Если есть с чем соотнести, происходит опознавание фактов.
- Если факт важен — запоминаем, либо обобщаем, либо действуем, например говорим или набираем код.
- Для сокращения объема запоминаемой и анализируемой информации используется обобщение.
- После обобщения, информация вновь соотносится и анализируется (этап 1).
Ученые разделяют память на кратковременную и долгосрочную. Кратковременная память мала по объему, но извлечение и сохранение информации выполняет мгновенно. Кратковременная память — кэш мозга. В нем может храниться 7+-2 слов, цифр, предметов. Долгосрочная память больше по объему, но она требует больших затрат энергии (усилий) на сохранение и извлечение информации, чем краткосрочная.
Выводы:
- чем меньше элементов, тем меньше тратится энергии,
- требуется сокращать количество воспринимаемых элементов до 9,
- как можно меньше задействовать долгосрочную память: обобщать или забывать.
Приступим к описанию правил.
Правило 1. Используем в условиях утверждение, избавляемся от «не».
Удаление оператора «не» уменьшает количество анализируемых элементов. Также, во многих языках программирования для оператора отрицания используется «!». Данный знак легко пропустить при прочтении кода.
Сравните:
if (!entity.IsImportAvaible) { //код 1 } else { //код 2 }
После:
if (entity.IsImportAvaible) { //код 2 } else { //код 1 }
Правило 2. Уменьшение уровня вложенности.
Во время анализа кода каждый уровень вложенности требуется удерживать в памяти. Уменьшаем количество уровней – уменьшаем затраты мыслетоплива.
Рассмотрим способы уменьшения количества уровней вложенности.
1) Возврат управления. Отсекаем часть случаев и сосредотачиваемся на оставшихся.
if (conributor != null) { //код }
Преобразуем в
if(contributor == null) { return; } //код
или
while(условие 1) { if(условие 2) { break; } //код }
или
for(;условие 1;) { if(условие 2) { continue; } //код }
Расширенный пример приведен в правиле 5. Обратите внимание на выброс исключения.
2) Выделение метода. Имя функции — результат обобщения.
if(условие рассылки) { foreach(var sender in senders) { sender.Send(message); } }
в
if(условие рассылки) { SendAll(senders, message); } void SendAll(IEnumerable<Sender> senders, string message) { foreach(var sender in senders) { sender.Send(message); } }
3) Объединение условий.
if (contributor == null) { if (accessMngr == null) { //код } }
в
if (contributor == null && accessMngr == null) { //код }
4) Вынесение переменных и разделение на смысловые блоки. В результате блоки можно изменять независимо, а главное читать и воспринимать такой код гораздо проще. Один блок – одна функциональность. Частый случай — поиск с обработкой. Необходимо разбить код на отдельные смысловые блоки: поиск элемента, обработка.
for (int i=0;i<array.length;i++) { if (array[i] == findItem) { //обработка array[i] break; } }
в
for(int i=0;i<array.length;i++) { if(array[i] == findItem) { foundItem =array[i]; break; } } if (foundItem != null) { //обработка foundItem }
Правило 3. Избавляемся от индексаторов и обращений через свойства.
Индексатор — операция обращения к элементу массива по индексу arr[index].
В процессе восприятия кода, мозг оперирует символами [] как разделителями, а индексатором как выражением.
function updateActiveColumnsSetting(fieldsGroups) {
var result = {};
for (var i = 0; i < fieldsGroups.length; i++) {
var fields = fieldsGroups[i].fields;
for (var j = 0; j < fields.length; j++) {
if (!result[fieldsGroups[i].groupName]) {
result[fieldsGroups[j].groupName] = {};
}
result[fieldsGroups[i].groupName][fields[j].field]
= createColumnAttributes(j, fields[j].isActive);
}
}
return JSON.stringify(result);
}
Индексатор — место частых ошибок. В силу кратких имен индексов перепутать I, j или k очень легко.
В приведенном выше примере в строчке result[fieldsGroups[j].groupName] = {}; допущена ошибка:
используется j, вместо i.
Для того, чтоб обнаружить где используется именно i-тое значение приходится:
1) визуально выделять переменную массива
function updateActiveColumnsSetting(fieldsGroups) {
var result = {};
for (var i = 0; i < fieldsGroups.length; i++) {
var fields = fieldsGroups[i].fields;
for (var j = 0; j < fields.length; j++) {
if (!result[fieldsGroups[i].groupName]) {
result[fieldsGroups[j].groupName] = {};
}
result[fieldsGroups[i].groupName][fields[j].field]
= createColumnAttributes(j, fields[j].isActive);
}
}
return JSON.stringify(result);
}
2) анализировать каждое вхождение на использование нужного индексатора I,j, i-1, j-1 и т.д., держа в восприятии места использования индексаторов и уже отождествленные обращения.
Выделив индексатор в переменную, сократим количество опасных мест и сможем легко задействовать мозг на восприятие переменной, без необходимости запоминания.
После переработки:
function updateActiveColumnsSetting(fieldsGroups) { var columnsGroups = {}; for (var i = 0; i < fieldsGroups.length; i++) { var fieldsGroup = fieldsGroups[i]; var groupName = fieldsGroup.groupName; var columnsGroup = columnsGroups[groupName]; if (!columnsGroup) { columnsGroup = columnsGroups[groupName] = {}; } var fields = fieldsGroup.fields; for (var j = 0; j < fields.length; j++) { var fieldInfo = fields[j]; columnsGroup[fieldInfo.field] = createColumnAttributes(j, field.isActive); } } return columnsGroups; }
Визуальное выделение происходит гораздо проще, а современные среды разработки и редакторы помогают, выделяя подстроки в разных участках кода.
function updateActiveColumnsSetting(fieldsGroups) {
var columnsGroups = {};
for (var i = 0; i < fieldsGroups.length; i++) {
var fieldsGroup = fieldsGroups[i];
var groupName = fieldsGroup.groupName;
var columnsGroup = columnsGroups[groupName];
if (!columnsGroup) {
columnsGroup = columnsGroups[groupName] = {};
}
var fields = fieldsGroup.fields;
for (var j = 0; j < fields.length; j++) {
var fieldInfo = fields[j];
columnsGroup[fieldInfo.field]
= createColumnAttributes(j, field.isActive);
}
}
return columnsGroups;
}
Правило 4. Группируем блоки по смыслу.
Используем психологический эффект восприятия — «Эффект близости»: близко расположенные фигуры при восприятии объединяются. Получить код, подготовленный для анализа и обобщения в процессе восприятия, и сократить количество информации, сохраняемой в памяти, можно расположив рядом строки, объединенные смыслом или близкие по функционалу, разделив их пустой строкой.
До:
foreach(var abcFactInfo in abcFactInfos)
{
var currentFact = abcInfoManager.GetFact(abcFactInfo);
var percentage = GetPercentage(summaryFact, currentFact);
abcInfoManager.SetPercentage(abcFactInfo, percentage);
accumPercentage += percentage;
abcInfoManager.SetAccumulatedPercentage(abcFactInfo, accumPercentage);
var category = GetAbcCategory(accumPercentage, categoryDictionary);
abcInfoManager.SetCategory(abcFactInfo, category);
}
После:
foreach (var abcFactInfo in abcFactInfos)
{
var currentFact = abcInfoManager.GetFact (abcFactInfo);
var percentage = GetPercentage(summaryFact, currentFact);
accumPercentage += percentage;
var category = GetAbcCategory(accumPercentage, categoryDictionary);
abcInfoManager.SetPercentage(abcFactInfo, percentage);
abcInfoManager.SetAccumulatedPercentage(abcFactInfo, accumPercentage);
abcInfoManager.SetCategory(abcFactInfo, category);
}
В верхнем примере 7 блоков, в нижнем 3: получение значений, накопление в цикле, установка свойств менеджера.
Отступами хорошо выделять места, на которые стоит обратить внимание. Так, строки
accumPercentage += percentage;
var category = GetAbcCategory(accumPercentage, categoryDictionary);
помимо зависимости от предыдущих вычислений, накапливают значения в переменной accumulatedPercentage. Для акцентирования внимания на отличии, код выделен отступом.
Одним из частных случаев применения правила является объявление локальных переменных как можно ближе к месту использования.
Правило 5. Следование принципу единственности ответственности.
Это первый из принципов SOLID в ООП, но помимо классов может быть применён к проектам, модулям, функциям, блокам кода, проектным командам или отдельным разработчикам. При вопросе кто или что отвечает за данную область сразу ясно — кто или что. Одна связь всегда проста. Каждый класс обобщается до одного понятия, фразы, метафоры. В результате меньше запоминать, процесс восприятия проходит проще и эффективнее.
В заключении комплексный пример:
private PartnerState GetPartnerStateForUpdate(
PartnerActivityInfo partner,
Dictionary<int, PartnerState> currentStates,
Dictionary<int, PartnerState> prevStates)
{
PartnerState updatingState;
if (prevStates.ContainsKey(partner.id))
{
if (currentStates.ContainsKey(partner.id))
{
var prevState = prevStates[partner.id];
updatingState = currentStates[partner.id];
//Код 1
}
else
{
//Код 2
}
}
else if (currentStates.ContainsKey(partner.id))
{
updatingState = currentStates[partner.id];
}
else
{
throw new Exception(string.Format("Для партнера {0} не найдено текущее и предыдущее состояние на месяц {1}", partner.id, month));
}
return updatingState;
}
После замены индексаторов ContainsKeу, инвертирования ветвления, выделения метода и уменьшения уровней вложенности получилось:
private PartnerState GetPartnerStateForUpdate(
PartnerActivityInfo partner,
Dictionary<int, PartnerState> currentStates,
Dictionary<int, PartnerState> prevStates)
{
PartnerState currentState = null;
PartnerState prevState = null;
prevStates.TryGetValue(partner.id, out prevState);
currentStates.TryGetValue(partner.id, out currentState);
currentState = CombineStates(currentState, prevState);
return currentState;
}
private PartnerState CombineStates(
PartnerState currentState,
PartnerState prevState)
{
if (currentState == null
&& prevState == null)
{
throw new Exception(string.Format(
"Для партнера {0} не найдено текущее и предыдущее состояние на месяц {1}" , partner.id, month));
}
if (currentState == null)
{
//Код 1
}
else if (prevState != null)
{
//Код
}
return currentState;
}
Первая функция отвечает за получение состояний из словарей, вторая за их комбинирование в новое.
Представленные правила просты, но в комбинации дают мощный инструмент по упрощению кода и снижению нагрузки на память в процессе разработки. Всегда их соблюдать не получится, но в случае если вы осознаете, что не понимаете код, проще всего начать с них. Они не раз помогали автору в самых затруднительных случаях.

