Привет, Хабр! Представляю вашему вниманию перевод статьи "Land Cover Classification with eo-learn: Part 1" автора Matic Lubej.
Предисловие
Примерно полгода назад был сделан первый коммит в репозиторий eo-learn на GitHub. Сегодня, eo-learn превратился в замечательную библиотеку с открытым исходным кодом, готовую для использования кем угодно, кто заинтересован в данных EO (Earth Observation — пр. пер.). Все в команде Sinergise ожидали момента перехода от этапа построения необходимых инструментов, к этапу их использования для машинного обучения. Пришло время представить вам серию статей, касающихся классификации покрова земли используя eo-learn
eo-learn — это Python-библиотека с открытым исходным кодом, которая работает как мост, соединяющий Наблюдение Земли/Удалённые Сенсоры (Earth Observation/Remote Sensing) с экосистемой библиотек для машинного обучения у Python. Мы уже писали отдельный пост в нашем блоге, с которым рекомендуем ознакомиться. Библиотека использует примитивы из библиотек numpy и shapely для хранения и манипуляции данными со спутников. На данный момент она доступна в GitHub-репозитории, и документация доступна по соответствующей ссылке на ReadTheDocs.
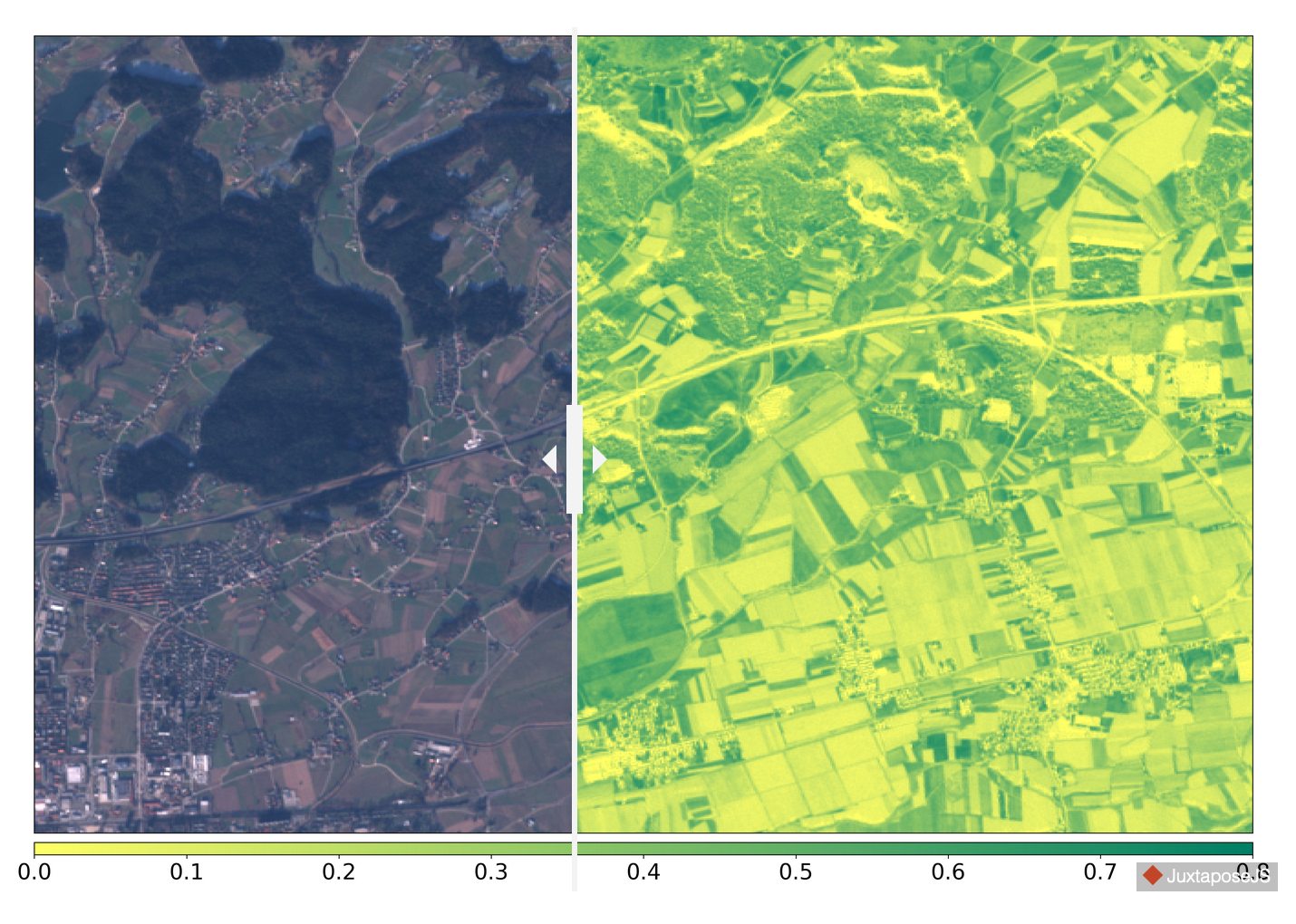
Изображение со спутника Sentinel-2 и NDVI-маска небольшой территории в Словении, зимой
Для демонстрации возможностей eo-learn, мы решили использовать наш мульти-темпоральный конвейер для классификации покрова территории Республики Словения (страна, где мы живём), используя данные за 2017 год. Поскольку полная процедура может быть слишком сложной для одной статьи, мы решили разделить её на три части. Благодаря этому не возникнет нужды пропускать этапы и сразу переходить к машинному обучению — сначала нам придётся действительно понять данные, с которыми мы работаем. Каждая статься будет сопровождаться примером в виде блокнота Jupyter Notebook. Также, для интересующихся, мы уже приготовили полный пример, покрывающий все этапы.
- В первой статье, мы проведём вас через процедуру выбора/разбиения зоны интереса (далее — AOI, area of interest), и получения необходимой информации, такой как данных со спутниковых сенсоров и облачных масок. Также покажем пример того, как создать из векторных данных растровую маску данных о реальном покрытии территории. Всё это является необходимыми шагами для получения надёжного результата.
- Во второй части, мы нырнём с головой в подготовку данных к процедуре машинного обучения. Этот процесс включает в себя взятие случайных образцов для тренировки\валидации пикселей, удаление облачных снимков, интерполяцию темпоральных данных для заполнения "дыр", и т.д.
- В третьей части будет рассмотрена тренировка и валидация классификатора, а также, разумеется, красивые графики!

Изображение со спутника Sentinel-2 и NDVI-маска небольшой территории в Словении, летом
Зона интереса? Выбирай!
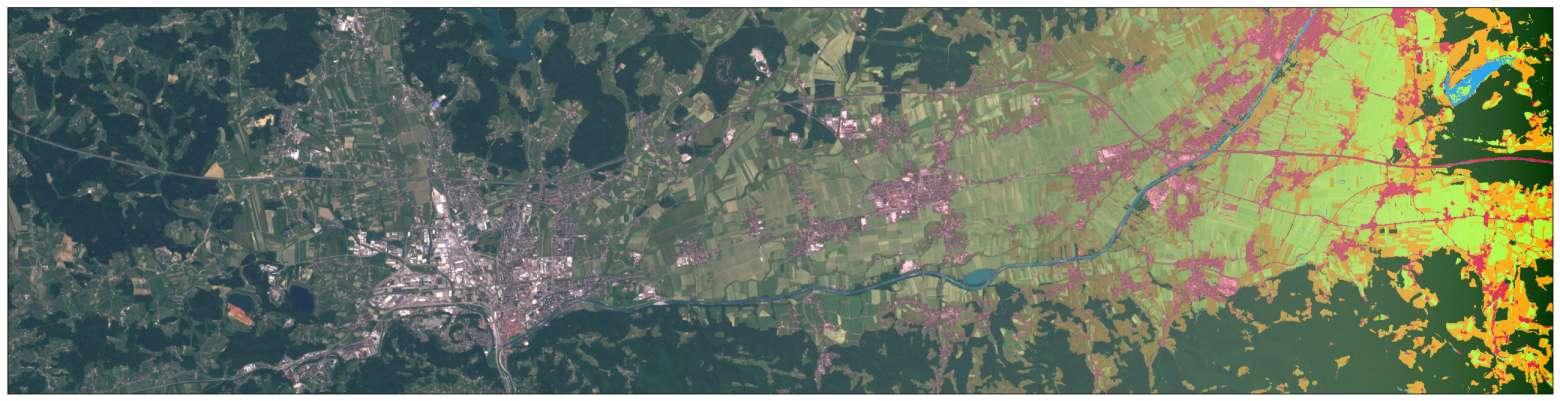
Библиотека eo-learn позволяет разделить AOI на небольшие фрагменты, которые могут быть обработаны в условиях ограниченных вычислительных ресурсов. В этом примере, граница Словении была взята из Natural Earth, однако, можно выбрать зону любого размера. Также мы добавили буфер к границе, после чего размерность AOI составила примерно 250х170 км. Используя магию библиотек geopandas и shapely, мы создали инструмент для разбития AOI. В этом случае мы разделили территорию на 25х17 квадратов одинакового размера, в результате чего мы получили ~300 фрагментов 1000х1000 пикселей, в разрешении 10м. Решение про разделение на фрагменты принимается в зависимости от доступных вычислительных мощностей. В результате выполнения этого шага мы получаем список квадратов, покрывающих AOI.

AOI (территория Словении) разделена на небольшие квадраты размером примерно 1000х1000 пикселей в разрешении 10м.
Получение данных со спутников Sentinel
После определения квадратов, eo-learn позволяет в автоматическом режиме скачать данные со спутников Sentinel. В этом примере, мы получим все Sentinel-2 L1C снимки, которые были сделаны в 2017 году. Стоит заметить, что продукты Sentinel-2 L2A, а также дополнительные источники данных (Landsat-8, Sentinel-1) могут быть добавлены в конвейер схожим образом. Также стоит заметить, что использование L2A-продуктов может улучшить результаты классификации, но мы решили использовать L1C для универсальности решения. Это было выполнено с использованием sentinelhub-py, библиотека, которая работает как обёртка над сервисами Sentinel-Hub. Использование этих сервисов бесплатно для исследовательских институтов и стартапов, но в остальных случаях необходимо оформить подписку.

Цветные изображения одного фрагмента в разные дни. Некоторые снимки облачные, а значит необходим детектор облаков.
В дополнение к данным Sentinel, eo-learn позволяет прозрачно получать доступ к данным об облаках и облачных вероятностях благодаря библиотеке s2cloudless. Эта библиотека предоставляет средства для автоматического определения облаков попиксельно. Детали можно прочитать здесь.
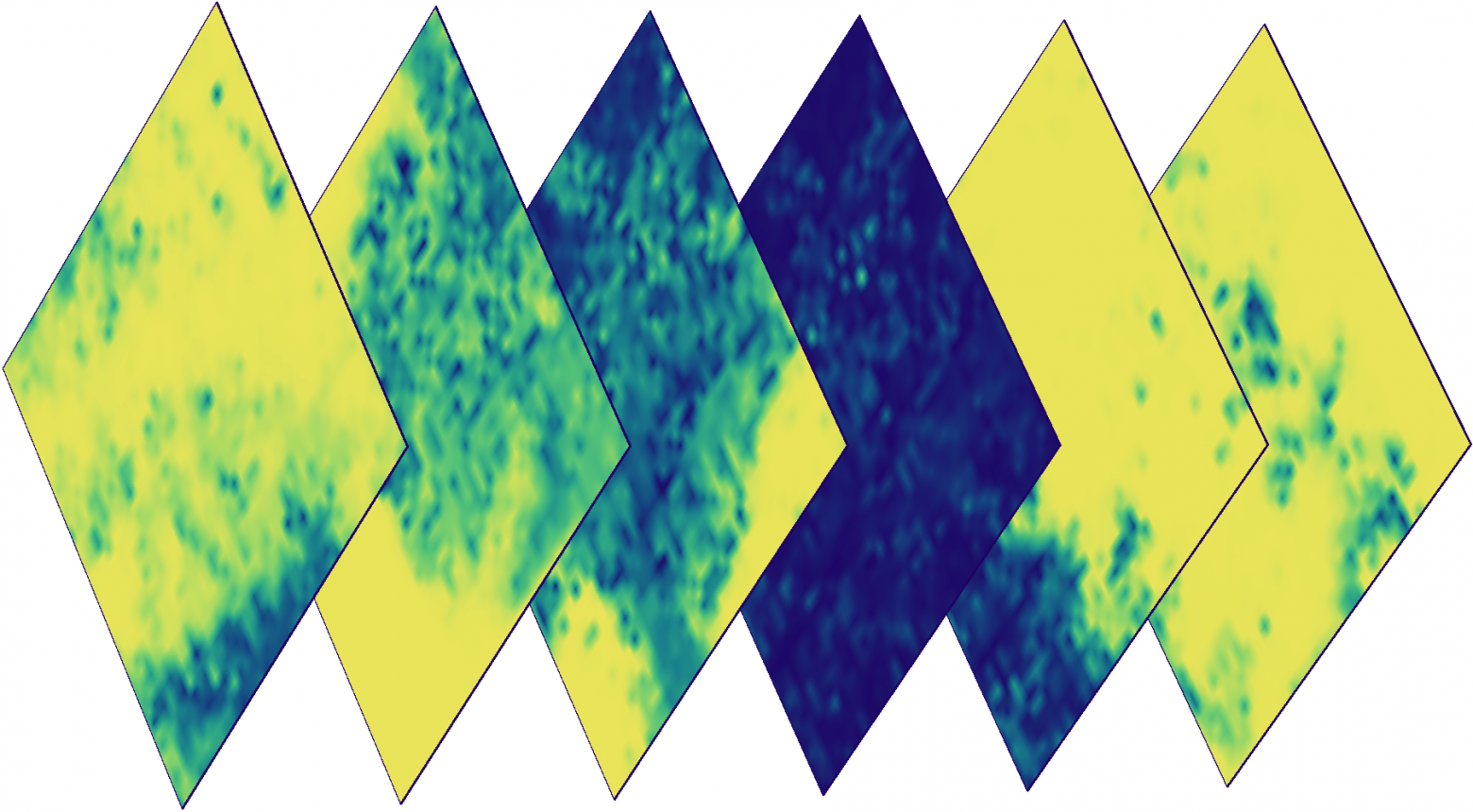
Маски облачной вероятности для снимков, указанных выше. Цвет обозначает вероятность облачности конкретного пикселя (синий — низкая вероятность, желтый — высокая).
Добавление настоящих данных
Обучение с учителем требует наличия карты с настоящими данными, или истины. Последний термин не стоит воспринимать буквально, поскольку в реальности данные являются лишь приближением того, что находится на поверхности. К сожалению, поведение классификатора сильно зависит от качества этой карты (впрочем, как и для большинства других задач в машинном обучении). Размеченные карты чаще всего доступны в виде векторных данных в формате shapefile (например, предоставляются государством или сообществом). eo-learn содержит инструменты для растеризации векторных данных в виде растровой маски.

Процесс растеризации данных в маски на примере одного квадрата. На левом изображении показаны полигоны в векторном файле, посередине изображены растерные маски для каждой метки — черный и белый цвета обозначают наличие и отсутствие конкретного признака, соответственно. На правом изображении показана комбинированная растровая маска, на которой разные цвета обозначают разные метки.
Соединяем всё вместе
Все эти задачи ведут себя как строительные блоки, которые могут быть объединены в удобную последовательность действий, исполняемую для каждого квадрата. Из-за потенциально крайне большого количества таких фрагментов, автоматизация конвейера абсолютно необходима
# Определим задачу eo_workflow = eolearn.core.LinearWorkflow( add_sentinel2_data, # получение данных со спутника Sentinel-2 add_cloud_mask, # получение маски вероятности облаков append_ndvi, # расчёт NDVI append_ndwi, # расчёт NDWI append_norm, # расчёт статистических характеристик изображения add_valid_mask, # создание маски присутствия данных add_count_valid, # подсчёт кол-ва пикселей с данными в изображении *reference_task_array, # добавление масок с метками из референсного файла save_task # сохраняем изображения )
Ознакомление с фактическими данными — первый шаг в работе с задачами подобного рода. Используя маски облаков в паре с данными из Sentinel-2, можно определить количество качественных наблюдений всех пикселей, а также среднюю вероятность облаков по конкретной зоне. Благодаря этому можно лучше понять существующие данные, и использовать это при отладке дальнейших проблем.
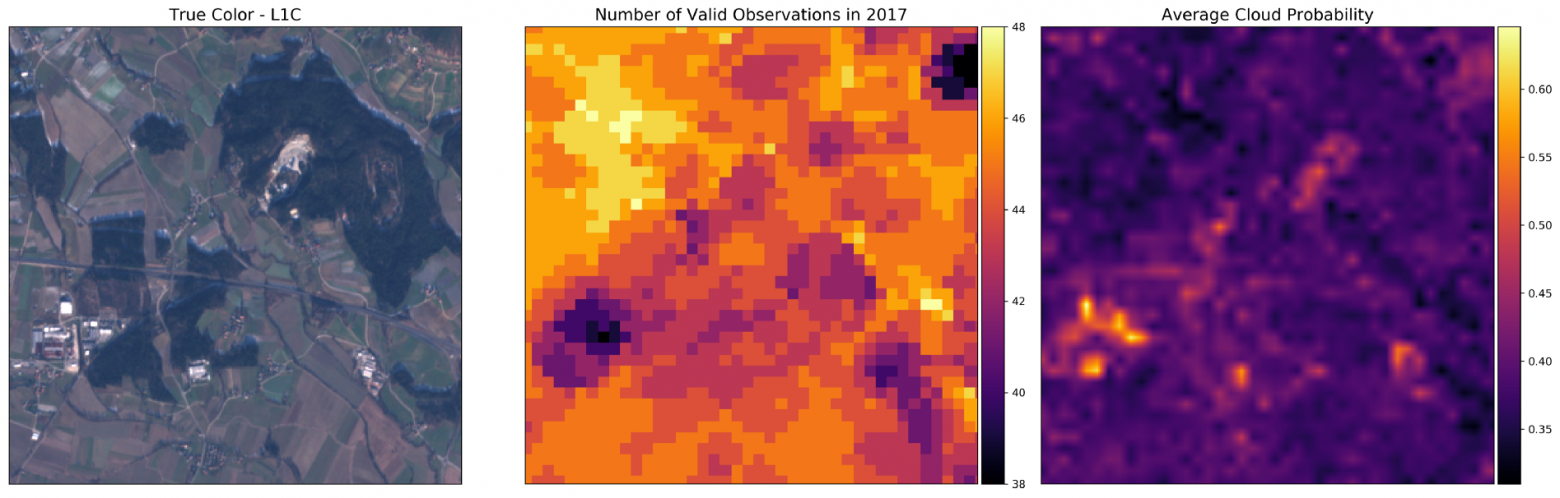
Цветное изображение (слева), маска количества качественных замеров для 2017 года (центр), и средняя вероятность облачности для 2017 года (справа) для случайного фрагмента из AOI.
Кому-то может быть интересно среднее значение NDVI для произвольной зоны, игнорируя облака. Используя маски облачности, можно посчитать среднее значение любого признака, игнорируя пиксели без данных. Таким образом, благодаря маскам, мы можем очистить изображения от шума практически для любого признака в наших данных.
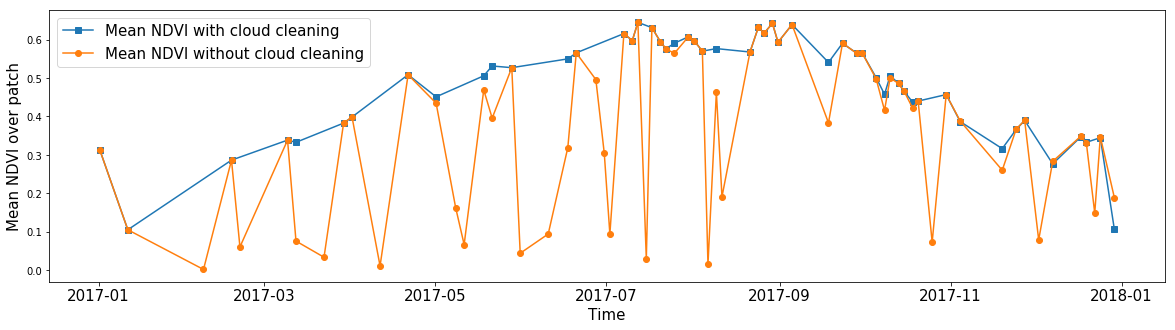
Среднее значение NDVI всех пикселей в случайном фрагменте AOI на протяжении года. Синей линией показан результат расчёта, полученный если игнорировать значения внутри облаков. Оранжевой линией показано среднее значение, когда все пиксели учтены.
"А как же масштабирование?"
После того как мы настроили наш конвейер на примере одного фрагмента, всё что осталось сделать — это запустить аналогичную процедуру для всех фрагментов автоматически (если позволяют ресурсы — параллельно), пока вы расслабляетесь с чашечкой кофе и думаете о том, как большой босс будет приятно удивлён результатами вашей работы. После окончания работы конвейера можно экспортировать интересующие вас данные в единое изображение в формате GeoTIFF. Скрипт gdal_merge.py получает снимки и соединяет их, в результате чего мы получаем картинку, покрывающую всю страну.
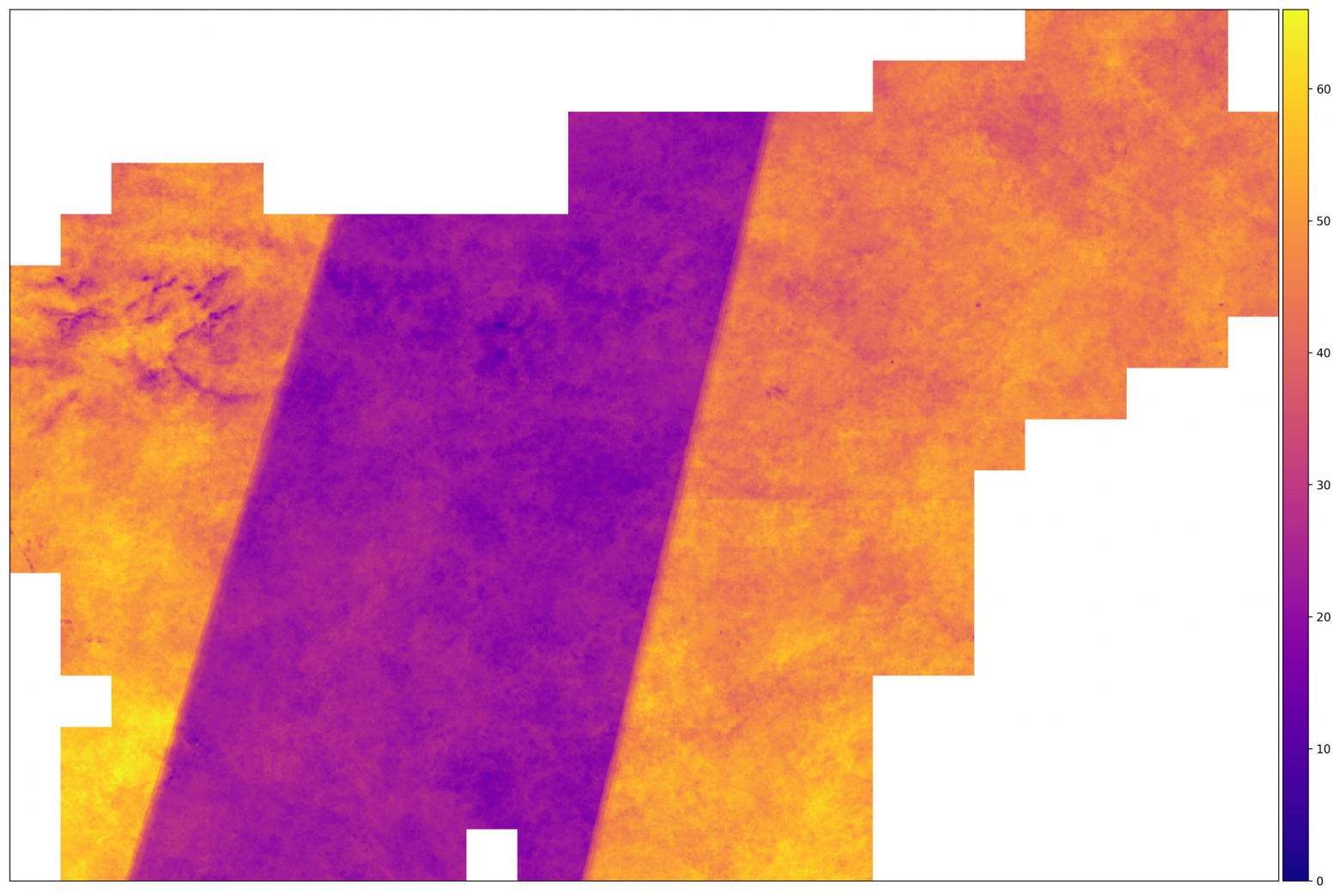
Количество корректных снимков для AOI в 2017 году. Регионы с большим количеством снимком находятся на территории, где траектория спутников Sentinel-2A и Sentinel-2B пересекаются. Посередине этого не происходит.
Из изображения выше можно сделать вывод о том, что входные данные неоднородны — для одних фрагментов количество снимков в два раза выше, чем для других. Это означает, что нам необходимо принять меры для нормализации данных — такие, как интерполяция по оси времени.
Выполнение указанного конвейера занимает примерно 140 секунд для одного фрагмента, что в сумме даёт ~12 часов при запуске процесса по всей AOI. Большую часть этого времени занимает скачивание спутниковых данных. Среднестатистический несжатый фрагмент с описанной конфигурацией занимает примерно 3 ГБ, что в сумме даёт ~1ТБ места для всей AOI.
Пример в Jupyter Notebook
Для более простого ознакомления с кодом eo-learn мы приготовили пример, покрывающий темы, обсуждённые в этом посте. Пример оформлен в виде блокнота Jupyter, и вы можете найти его в директории примеров пакета eo-learn.

