На Хабре уже были статьи о подробностях реализации менеджера памяти CPython, Pandas, я написал статью про реализацию словаря.
Казалось бы, что можно написать про обычный целочисленный тип? Однако тут не всё так просто и целочисленный тип не такой уж и очевидный.
Если вам интересно, почему x * 2 быстрее x << 1.
И как провернуть следующий трюк:
То вам стоит ознакомиться с данной статьёй.
В python нет примитивных типов — все переменные представляют собой объекты и размещаются в динамической памяти. При этом целые числа представлены только одним типом (decimal мы не рассматриваем) — PyLongObject. Реализация и объявления которого лежат в файлах longobject.h, longintrepr.h и longobject.c.
В любой объект в CPython входят два поля: ob_refcnt — счётчик ссылок на объект и ob_type — указатель на тип объекта, к объектам, которые могут менять свою длину, добавляется поле ob_size — текущий аллоцированный размер (используемый может быть меньше).
Таким образом целочисленный тип представлен массивом переменной длины из отдельных разрядов (digit), поэтому python из коробки поддерживает длинную арифметику, во второй версии языка был отдельный тип «обычных» целых.«Длинные» целые создавались с помощью литера L или, если результат операций с обычными вызывал переполнение, в третьей версии от него было решено отказаться.
Целое значение, хранимое структурой _longobject оказывается равно:
В качестве разряда используется 32-битный безнаковый тип(uint32_t) на 64-битных системах и 16-битный беззнаковый тип(unsigned short) на 32-разрядных.
Использованные в реализации алгоритмы накладывают строгие ограничения на SHIFT из предыдущей формулы, в частности, оно должно делиться на 15, поэтому сейчас cpython поддерживает два значения: 30 и 15, соответственно для 64 и 32-битных систем. Для отрицательных значений ob_size имеет отрицательное значение, ноль задаётся числом, у которого ob_size = 0.
При выполнении арифметических операций интерпретатор проверяет текущую длину операндов, если они оба состоят из одного разряда, то выполняется стандартная арифметика.
Умножение имеет похожую структуру, кроме того в интерпретаторе реализован алгоритм Карацубы и быстрого возведения в квадрат, однако они выполняются не при каждом «длинном умножении», а лишь для достаточно больших чисел, число разрядов в которых задаются двумя константами:
Однако, команды сдвига не имеют проверки на случай «коротких» целых, они всегда выполняются для случая длинной арифметики. Поэтому умножение на 2 оказывается быстрее сдвига. Интересно заметить, что деление оказывается медленнее правого сдвига, который тоже не проверяет случая одноразрядных целых. Но деление устроено более сложно: есть один метод, который высчитывает сначала частное, потом остаток, ему передаётся NULL, если нужно подсчитать что-то одно, то есть метод должен проверять и этот случай, всё это увеличивает накладные расходы.
Функция сравнения также не имеет частного случая для «коротких» целых.
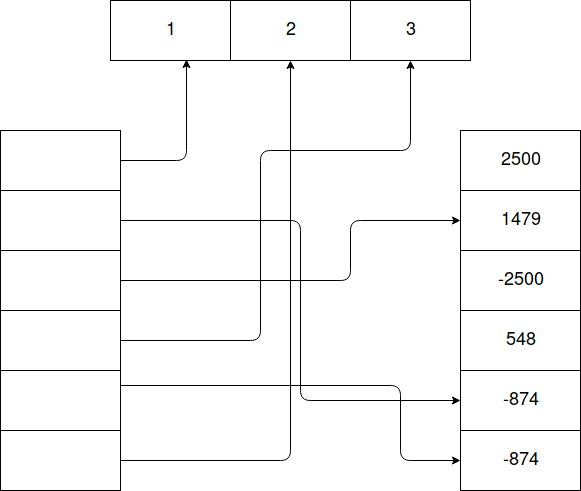
При создании переменной целого типа интерпретатор должен выделить достаточную область в динамической памяти, после чего установить счётчик ссылок(тип ssize_t), указатель на тип PyLongObject, текущий размер массива разрядов(тоже ssize_t) и инициализировать сам массив. Для 64-разрядных систем минимальный размер структуры составит: 2 * ssize_t + указатель + digit = 2 * 8 + 8 + 4 = 28 байт. Дополнительные проблемы появляются при создании списков чисел: так как числа не являются примитивным типом, а списки в python хранят ссылки на объекты, то объекты лежат в динамической памяти не последовательно.
Такое размещение замедляет итерирование по массиву: по сути осуществляется случайный доступ, что делает невозможным предсказание переходов.
Во избежание излишних выделений динамической памяти, что замедляет время работы и способствует фрагментации памяти, в cpython реализована оптимизация: на этапе запуска предвыделяется массив маленьких целых чисел: от -5 до 256.
В итоге список чисел в cpython представляется в памяти как-то так:
Существует возможность достучаться до предвыделенного списка малых целых из скрипта, вооружившись вот этой статьёй и стандартным модулем ctypes:
Disclaimer: Следующий код поставляется as is, автор не несёт никакой ответственности и не может гарантировать состояние интерпретатора, а также душевное здоровье вас и ваших коллег, после запуска этого кода.
В данном списке хранятся честные PyLongObject, то есть у них есть счётчик ссылок, например, можно узнать, сколько нулей использует ваш скрипт и сам интерпретатор.
Из внутренней реализации целых чисел следует, что арифметика в cpython не может быть быстрой, там, где другие языки последовательно итерируются по массиву, читая числа в регистры и непосредственно вызывая несколько инструкций процессора, cpython мечется по всей памяти, выполняя довольно сложные методы. В простейшем случае одноразрядных целых, в которых достаточно было бы вызвать одну инструкцию интерпретатор должен сравнить размеры, после чего создать объект в динамической памяти, заполнить служебные поля, и вернуть указатель на него, более того, эти действия требуют блокировки GIL. Теперь вы понимаете, почему возникла библиотека numpy и почему она так популярна.
Закончить же статью про целый тип в cpython хотелось бы, внезапно, информацией про булевый тип.
Дело в том, что долгое время в python не было отдельного типа для булевых переменных, все логические функции возвращали 0 и 1. Однако, всё же новый тип решили ввести. При этом реализован он был как дочерний тип к целому.
При этом каждое из значений булевого типа является синглтоном, булевая переменная — это указатель на экземпляр True или False (похожим образом реализован None).
PyObject_IsTrue(x) — хитрый механизм вычисления булевого значения, посмотреть можно здесь в разделе про функцию bool или в документации.
Такое наследство ведёт к некоторым забавным эффектам, вроде, точного равенства True и 1, невозможности иметь в словаре и множестве одновременно True и 1 в качестве ключей, допустимости арифметических операций над булевым типом:
Язык python великолепен своей гибкостью и читаемостью, однако, надо учитывать, что всё это имеет свою цену, например, в виде лишних абстракций и overhead, над которым мы зачастую не задумываемся и не догадываемся. Надеюсь, данная статья позволила вам немного развеять «туман войны» над исходным кодом интерпретатора, возможно, даже побудить на его изучение. Код интерпретатора очень лёгок в прочтении, почти как и код на самом python, а его изучение позволит не только узнать как реализован интерпретатор, но и интересные алгоритмические и системные решения, а также, возможно, писать более эффективный код или стать разработчиком самого cpython.
Казалось бы, что можно написать про обычный целочисленный тип? Однако тут не всё так просто и целочисленный тип не такой уж и очевидный.
Если вам интересно, почему x * 2 быстрее x << 1.
И как провернуть следующий трюк:
>>> 42 == 4 True >>> 42 4 >>> 1 + 41 4
То вам стоит ознакомиться с данной статьёй.
В python нет примитивных типов — все переменные представляют собой объекты и размещаются в динамической памяти. При этом целые числа представлены только одним типом (decimal мы не рассматриваем) — PyLongObject. Реализация и объявления которого лежат в файлах longobject.h, longintrepr.h и longobject.c.
struct _longobject { PyObject_VAR_HEAD // стандартный заголовок для объектов переменной длины digit ob_digit[1]; // массив чисел };
В любой объект в CPython входят два поля: ob_refcnt — счётчик ссылок на объект и ob_type — указатель на тип объекта, к объектам, которые могут менять свою длину, добавляется поле ob_size — текущий аллоцированный размер (используемый может быть меньше).
Таким образом целочисленный тип представлен массивом переменной длины из отдельных разрядов (digit), поэтому python из коробки поддерживает длинную арифметику, во второй версии языка был отдельный тип «обычных» целых.«Длинные» целые создавались с помощью литера L или, если результат операций с обычными вызывал переполнение, в третьей версии от него было решено отказаться.
# python2 num1 = 42 print num1, type(num1) # 42 <type 'int'> num2 = 42L print num2, type(num2) # 42 <type 'long'> num3 = 2 ** 100 print num3, type(num3) # 1267650600228229401496703205376 <type 'long'>
Целое значение, хранимое структурой _longobject оказывается равно:

В качестве разряда используется 32-битный безнаковый тип(uint32_t) на 64-битных системах и 16-битный беззнаковый тип(unsigned short) на 32-разрядных.
Использованные в реализации алгоритмы накладывают строгие ограничения на SHIFT из предыдущей формулы, в частности, оно должно делиться на 15, поэтому сейчас cpython поддерживает два значения: 30 и 15, соответственно для 64 и 32-битных систем. Для отрицательных значений ob_size имеет отрицательное значение, ноль задаётся числом, у которого ob_size = 0.
При выполнении арифметических операций интерпретатор проверяет текущую длину операндов, если они оба состоят из одного разряда, то выполняется стандартная арифметика.
static PyObject * long_add(PyLongObject *a, PyLongObject *b) { ... // оба операнда - вмещаются в один разряд if (Py_ABS(Py_SIZE(a)) <= 1 && Py_ABS(Py_SIZE(b)) <= 1) { // суммировать их и выдать результат return PyLong_FromLong(MEDIUM_VALUE(a) + MEDIUM_VALUE(b)); } ... };
Умножение имеет похожую структуру, кроме того в интерпретаторе реализован алгоритм Карацубы и быстрого возведения в квадрат, однако они выполняются не при каждом «длинном умножении», а лишь для достаточно больших чисел, число разрядов в которых задаются двумя константами:
// в случае неравных операндов #define KARATSUBA_CUTOFF 70 // в случае возведения в квадрат #define KARATSUBA_SQUARE_CUTOFF (2 * KARATSUBA_CUTOFF)
static PyObject * long_mul(PyLongObject *a, PyLongObject *b) { ... // оба операнда - вмещаются в один разряд if (Py_ABS(Py_SIZE(a)) <= 1 && Py_ABS(Py_SIZE(b)) <= 1) { // stwodigits - знаковый тип, вмещающий два разряда // int64_t на 64-битных системах и long на 32-битных. stwodigits v = (stwodigits)(MEDIUM_VALUE(a)) * MEDIUM_VALUE(b); return PyLong_FromLongLong((long long)v); } ... // "Школьное" умножение в столбик O(N^2), если оба операнда достаточно малы. i = a == b ? KARATSUBA_SQUARE_CUTOFF : KARATSUBA_CUTOFF; if (asize <= i) { if (asize == 0) return (PyLongObject *)PyLong_FromLong(0); else return x_mul(a, b); } ... };
Однако, команды сдвига не имеют проверки на случай «коротких» целых, они всегда выполняются для случая длинной арифметики. Поэтому умножение на 2 оказывается быстрее сдвига. Интересно заметить, что деление оказывается медленнее правого сдвига, который тоже не проверяет случая одноразрядных целых. Но деление устроено более сложно: есть один метод, который высчитывает сначала частное, потом остаток, ему передаётся NULL, если нужно подсчитать что-то одно, то есть метод должен проверять и этот случай, всё это увеличивает накладные расходы.
Функция сравнения также не имеет частного случая для «коротких» целых.
static int long_compare(PyLongObject *a, PyLongObject *b) { Py_ssize_t sign; // случай, когда длины чисел не равны просто определяем // в каком больше разрядов с учётом знака if (Py_SIZE(a) != Py_SIZE(b)) { sign = Py_SIZE(a) - Py_SIZE(b); } else { Py_ssize_t i = Py_ABS(Py_SIZE(a)); // для "коротких" целых будем просто меньше крутиться в цикле while (--i >= 0 && a->ob_digit[i] == b->ob_digit[i]) ; if (i < 0) sign = 0; else { sign = (sdigit)a->ob_digit[i] - (sdigit)b->ob_digit[i]; if (Py_SIZE(a) < 0) sign = -sign; } } return sign < 0 ? -1 : sign > 0 ? 1 : 0; }
Массивы (списки) чисел
При создании переменной целого типа интерпретатор должен выделить достаточную область в динамической памяти, после чего установить счётчик ссылок(тип ssize_t), указатель на тип PyLongObject, текущий размер массива разрядов(тоже ssize_t) и инициализировать сам массив. Для 64-разрядных систем минимальный размер структуры составит: 2 * ssize_t + указатель + digit = 2 * 8 + 8 + 4 = 28 байт. Дополнительные проблемы появляются при создании списков чисел: так как числа не являются примитивным типом, а списки в python хранят ссылки на объекты, то объекты лежат в динамической памяти не последовательно.
Такое размещение замедляет итерирование по массиву: по сути осуществляется случайный доступ, что делает невозможным предсказание переходов.
Во избежание излишних выделений динамической памяти, что замедляет время работы и способствует фрагментации памяти, в cpython реализована оптимизация: на этапе запуска предвыделяется массив маленьких целых чисел: от -5 до 256.
#ifndef NSMALLPOSINTS #define NSMALLPOSINTS 257 // Как и положено в python правая граница не входит. #endif #ifndef NSMALLNEGINTS #define NSMALLNEGINTS 5 #endif
В итоге список чисел в cpython представляется в памяти как-то так:
Существует возможность достучаться до предвыделенного списка малых целых из скрипта, вооружившись вот этой статьёй и стандартным модулем ctypes:
Disclaimer: Следующий код поставляется as is, автор не несёт никакой ответственности и не может гарантировать состояние интерпретатора, а также душевное здоровье вас и ваших коллег, после запуска этого кода.
import ctypes # структура PyLongObject class IntStruct(ctypes.Structure): # объявление полей _fields_ = [("ob_refcnt", ctypes.c_long), ("ob_type", ctypes.c_void_p), ("ob_size", ctypes.c_long), ("ob_digit", ctypes.c_int)] def __repr__(self): return ("IntStruct(ob_digit={self.ob_digit}, ob_size={self.ob_size}, " "refcount={self.ob_refcnt})").format(self=self) if __name__ == '__main__': # получаем адрес числа 42 int42 = IntStruct.from_address(id(42)) print(int42) int_minus_2 = IntStruct.from_address(id(-2)) print(int_minus_2) # ob_digit=2, ob_size=-1 # меняем значение в списке предвыделенных чисел int42.ob_digit = 4 print(4 == 42) # True print(1 + 41) # 4
В данном списке хранятся честные PyLongObject, то есть у них есть счётчик ссылок, например, можно узнать, сколько нулей использует ваш скрипт и сам интерпретатор.
Из внутренней реализации целых чисел следует, что арифметика в cpython не может быть быстрой, там, где другие языки последовательно итерируются по массиву, читая числа в регистры и непосредственно вызывая несколько инструкций процессора, cpython мечется по всей памяти, выполняя довольно сложные методы. В простейшем случае одноразрядных целых, в которых достаточно было бы вызвать одну инструкцию интерпретатор должен сравнить размеры, после чего создать объект в динамической памяти, заполнить служебные поля, и вернуть указатель на него, более того, эти действия требуют блокировки GIL. Теперь вы понимаете, почему возникла библиотека numpy и почему она так популярна.
Закончить же статью про целый тип в cpython хотелось бы, внезапно, информацией про булевый тип.
Дело в том, что долгое время в python не было отдельного типа для булевых переменных, все логические функции возвращали 0 и 1. Однако, всё же новый тип решили ввести. При этом реализован он был как дочерний тип к целому.
PyTypeObject PyBool_Type = { PyVarObject_HEAD_INIT(&PyType_Type, 0) // длина булевого типа меняться не может // однако, так как он наследуется от целого // там уже присутствует поле ob_size "bool", // имя типа sizeof(struct _longobject), // размер в памяти ... &PyLong_Type, // базовый тип ... bool_new, // конструктор };
При этом каждое из значений булевого типа является синглтоном, булевая переменная — это указатель на экземпляр True или False (похожим образом реализован None).
struct _longobject _Py_FalseStruct = { PyVarObject_HEAD_INIT(&PyBool_Type, 0) { 0 } }; struct _longobject _Py_TrueStruct = { PyVarObject_HEAD_INIT(&PyBool_Type, 1) { 1 } }; static PyObject * bool_new(PyTypeObject *type, PyObject *args, PyObject *kwds) { PyObject *x = Py_False; long ok; if (!_PyArg_NoKeywords("bool", kwds)) return NULL; if (!PyArg_UnpackTuple(args, "bool", 0, 1, &x)) return NULL; ok = PyObject_IsTrue(x); if (ok < 0) return NULL; return PyBool_FromLong(ok); } PyObject *PyBool_FromLong(long ok) { PyObject *result; if (ok) result = Py_True; else result = Py_False; Py_INCREF(result); return result; }
PyObject_IsTrue(x) — хитрый механизм вычисления булевого значения, посмотреть можно здесь в разделе про функцию bool или в документации.
Такое наследство ведёт к некоторым забавным эффектам, вроде, точного равенства True и 1, невозможности иметь в словаре и множестве одновременно True и 1 в качестве ключей, допустимости арифметических операций над булевым типом:
>>> True == 1 True >>> {True: "true", 1: "one"} {True: 'one'} >>> True * 2 + False / (5 * True) - (True << 3) -6.0 >>> False < -1 False
Язык python великолепен своей гибкостью и читаемостью, однако, надо учитывать, что всё это имеет свою цену, например, в виде лишних абстракций и overhead, над которым мы зачастую не задумываемся и не догадываемся. Надеюсь, данная статья позволила вам немного развеять «туман войны» над исходным кодом интерпретатора, возможно, даже побудить на его изучение. Код интерпретатора очень лёгок в прочтении, почти как и код на самом python, а его изучение позволит не только узнать как реализован интерпретатор, но и интересные алгоритмические и системные решения, а также, возможно, писать более эффективный код или стать разработчиком самого cpython.

