Внутреннее устройство словарей в Python не ограничивается одними лишь бакетами и закрытым хешированием. Это удивительный мир разделяемых ключей, кеширования хешей, DKIX_DUMMY и быстрого сравнения, которое можно сделать ещё быстрее (ценой бага с примерной вероятностью в 2^-64).
Если вы не знаете количество элементов в только что созданном словаре, сколько памяти расходуется на каждый элемент, почему теперь (CPython 3.6 и далее) словарь реализован двумя массивами и как это связано с сохранением порядка вставки, или просто не смотрели презентацию Raymond Hettinger «Modern Python Dictionaries A confluence of a dozen great ideas». Тогда добро пожаловать.
Впрочем, люди знакомые с лекцией, тоже могут найти немного подробностей и свежей информации, и для совсем новичков, не знакомых с бакетами и закрытым хешированием, статья тоже будет интересна.
Словари в CPython везде, на них основаны классы, глобальные переменные, параметры kwargs, интерпретатор создаёт тысячи словарей, даже, если вы сами не добавили ни одной фигурной скобки в свой скрипт. Но для решения многих прикладных задач словари так же используются, неудивительно, что их реализация продолжает улучшаться и всё больше обрастать разными трюками.
Если вы знакомы с работой стандартного Hashmap и закрытого хеширования, можете переходить к следующей главе.
Идея, лежащая в основе словарей проста: если у нас есть массив, в котором хранятся объекты одинакового размера, то мы легко получаем доступ к нужному объекту, зная индекс.
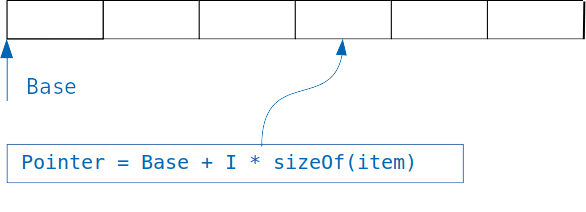
Мы просто добавляем к смещению массива индекс, помноженный на размер объекта, и получаем адрес искомого объекта.
Но что, если мы хотим организовать поиск не по целочисленному индексу, а по переменной другого типа, например, находить пользователей по адресу их почты?
В случае простого массива нам придётся просматривать почты всех пользователей в массиве и сравнивать их с искомой, такой подход называется линейным поиском и, очевидно, что он куда медленнее обращения к объекту по индексу.
Линейный поиск может быть значительно ускорен, если мы ограничим размер области, в которой необходимо осуществлять поиск. Обычно это достигается взятием остатка от хеша. Поле, по которому осуществляется поиск, — ключом.
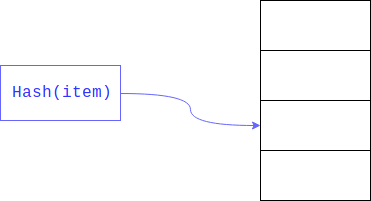
В итоге линейный поиск осуществляется не по всему большому массиву, а по его части.
Но что, если там уже есть элемент? Такое вполне может случится, так как никто не гарантировал, что остатки от деления хеша будут уникальны (как и сам хеш). В этом случае объект будет помещён по следующему индексу, если и он занят, то сместится ещё на один индекс и так пока не найдёт свободный. При извлечении элемента, будут просмотрены все ключи с одинаковым хешем.
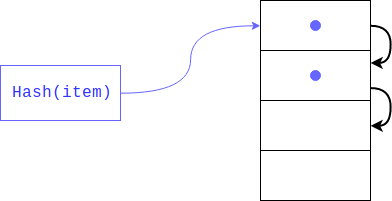
Данный тип хеширования называется закрытым. Если в словаре остаётся мало свободных ячеек, то такой поиск грозит выродиться в линейный, соответственно мы потеряем весь выигрыш, ради которого и создавался словарь, во избежание подобного интерпретатор сохраняет массив заполненным на 1/2 — 2/3. Если свободных ячеек не хватает, то создаётся новый массив в два раза больше предыдущего и элементы из старого переносятся в новый по одному.
Что же делать, если элемент был удалён? В таком случае в массиве образуется пустая ячейка и алгоритм поиска по ключу, не может различить, эта ячейка пуста, потому что элемента с таким хешем не было в словаре, или потому что он был удалён. Во избежание потери данных при удалении ячейка помечается специальным флагом (DKIX_DUMMY). Если во время поиска элемента встретится этот флаг, то поиск продолжится, ячейка считается занятой, в случае вставки ячейка будет перезаписана.
Каждый элемент словаря должен содержать ссылку на целевой объект и ключ. Ключ необходимо хранить для обработки коллизий, объект — по очевидным причинам. Так как и ключ, и объект могут быть любого типа и размера мы не можем хранить в структуре непосредственно их, они лежат в динамической памяти, а в структуре элемента списка хранятся ссылки на них. То есть размер одного элемента должен быть равен минимум размеру двух указателей (16 байт на 64-битных системах). Однако интерпретатор хранит ещё и хеш, сделано это для того, чтобы не перевычислять его при каждом увеличении размера словаря. Вместо того, чтобы вычислять хеш от каждого ключа по-новому и брать остаток от деления на количество бакетов, интерпретатор просто читает уже сохранённое значение. Но, что если объект ключа изменили? В таком случае хеш должен пересчитаться и сохранённое значение будет неверным? Такая ситуация невозможна, так как изменяемые типы не могут быть ключами словаря.
Структура элемента словаря определена следующим образом:
Минимальный размер словаря объявлен константой PyDict_MINSIZE, которая равна 8. Разработчики решили, что это оптимальный размер, для того, чтобы избежать лишнего расходования памяти на хранение пустых значений и времени на динамическое расширение массива. Таким образом при создании словаря (до версии 3.6) вам требовалось минимум 8 элементов в словаре * 24 байт в структуре = 192 байта (это без учёта остальных полей: расходы на саму переменную типа словарь, счётчик числа элементов и т.д.)
Словари используются и для реализации полей пользовательских классов. Python позволяет динамически изменять количество атрибутов, эта динамика не требует дополнительных расходов, так как добавление/удаление атрибута по сути эквивалентно соответствующей операции над словарём. Однако данным функционалом пользуется меньшинство программ, большинство ограничивается полями, объявленными в __init__. Но каждый объект должен хранить свой словарь, со своими ключами и хешами, несмотря на то, что они совпадают с другими объектами. Логичным улучшением тут выглядит хранение общих ключей только в одном месте, именно это и было реализовано в PEP 412 — Key-Sharing Dictionary. Возможность динамического изменения словаря при этом не исчезла: если меняется порядок или количество ключей словарь преобразуется из разделяющего ключи в обычный.
Во избежание коллизий максимальная «загрузка» словаря составляет 2/3 от текущего размера массива.
Таким образом первое расширение произойдёт при добавлении 6-го элемента.
Массив получается довольно разряжен, во время работы программы от половины до трети ячеек остаются пустыми, что ведёт к увеличенному расходу памяти. Для того, чтобы обойти это ограничение и по возможности хранить только необходимые данные был добавлен новый уровень абстракции массив.
Вместо хранения разряженного массива, например:
Начиная с версии 3.6 словари организованны следующим образом:
Т.е. хранятся только те записи, которые действительно необходимы, они вынесены из хеш-таблицы в отдельный массив, а в хеш-таблице хранятся только индексы соответствующих записей. Если изначально на массив уходило 192 байт, то сейчас только 80 (3 * 24-байт для каждой записи + 8 байт на indices). Достигнуто сжатие в 58%.[2]
Размер элемента в indices тоже меняется динамически, изначально он равен одному байту, то есть весь массив может быть помещён в один регистр, когда индекс начинает не влезать в 8 бит, то элементы расширяются до 16, потом до 32 бит. Есть специальные константы DKIX_EMPTY и DKIX_DUMMY, для пустого и удалённого элемента, соответственно расширение индексов до 16 байт происходит, когда элементов в словаре становится более 127.
Новые объекты добавляются в entries, то есть при расширении словаря нет необходимости их перемещать, необходимо лишь увеличить размер indices и перезаполнить его индексами.
При итерировании по словарю, массив indices не нужен, элементы последовательно возвращаются из entries, т.к. элементы добавляются каждый раз в конец entries, то словарь автоматически сохраняет порядок вхождения элементов. Таким образом, кроме уменьшения необходимой памяти для хранения словаря, мы получили более быстрое динамическое расширение и сохранение порядка ключей. Уменьшение памяти хорошо и само по себе, но в то же время может увеличить быстродействие, так как позволяет большему числу записей влезть в кеш процессора.
Эта реализация настолько понравилась разработчикам CPython, что словари теперь обязаны сохранять порядок вставки по спецификации. Если раньше порядок словарей был детерминирован, т.е. жёстко определялся хешем и был неизменен от запуска к запуску, потом к нему добавили немного случайности, чтобы ключи шли каждый раз по-разному, то теперь ключи словаря обязаны сохранять порядок следования. Насколько это было необходимо, и что делать, если появится ещё более эффективная реализация словаря, но не сохраняющая порядок вставки, непонятно.
Впрочем, и так раздавались просьбы реализовать механизм сохранения порядка объявления атрибутов в классах и в kwargs, данная реализация позволяет закрыть эти проблемы без специальных механизмов.
Вот как это выглядит в коде CPython:
Но итерирование устроено сложнее, чем можно было изначально подумать, существуют дополнительные механизмы проверки, что словарь не был изменён во время итерирования, один из них — версия словаря в виде 64-битного числа, который хранит каждый словарь.
Напоследок рассмотрим механизм разрешения коллизий. Дело в том, что в python значения хеш-функции легко предсказуемы:
А так как при создании словаря от этих хешей берётся остаток от деления, то по сути определяют, в какой бакет пойдёт запись, лишь несколько последних бит ключа (если он целочисленный). Можно представить себе ситуацию, когда у нас много объектов «хотят» попасть в соседние бакеты, в таком случае при поиске придётся просмотреть множество объектов, которые находятся не на своих местах. Для уменьшения числа коллизий и увеличения числа бит, определяющих, в какой бакет пойдёт запись был реализован следующий механизм:
perturb — целочисленная переменная, инициализируемая хешем. Следует заметить, что в случае большого числа коллизий она обнуляется и следующий индекс вычисляется по формуле:
При извлечении элемента из словаря осуществляется такой же поиск: вычисляется индекс слота, в котором должен находиться элемент, если слот пуст, то выбрасывается исключение «значение не найдено». Если же значение в данном слоте есть, необходимо проверить, что его ключ соответствует искомому, это вполне может не выполняться, если произошла коллизия. Однако ключом может быть почти любой объект, в том числе такой, для которого, операция сравнения занимает значительное время. Дабы избежать длительной операции сравнения, в Python применено несколько трюков:
сначала сравниваются указатели, если указатель ключа искомого объекта равен указателю объекта, по которому осуществляется поиск, то есть указывают на одну и ту же область памяти, то сравнение сразу же возвращает истинно. Но и это не всё. Как известно, у равных объектов должны быть равные хеши, из чего следует, что объекты с разными хешами не равны. После проверки указателей проверяются хеши, если они не равны, вернётся false. И лишь, если хеши равны, будет вызвано честное сравнение.
Какова вероятность такого исхода? Примерно 2^-64, разумеется из-за лёгкой предсказуемости значения хеша, можно легко подобрать такой пример, но в реальности до этой проверки выполнение доходит не часто, насколько? Raymond Hettinger собрал интерпретатор, изменив последнюю операцию сравнения простым return true. Т.е. интерпретатор считал объекты равными, если их хеши равны. После чего натравил на такой интерпретатор автоматизированные тесты многих популярных проектов, которые завершились успешно. Может показаться странным считать объекты с равными хешами равными, не проверять дополнительно их содержимое, и целиком полагаться только на хеш, но вы это делаете регулярно, когда пользуетесь протоколами git или torrent. Они считают файлы (блоки файлов) равными, если равны их хеши, что вполне может привести к ошибкам, но их создатели (и все мы) надеемся, стоит заметить, небезосновательно, что вероятность коллизии крайне мала.
Сейчас вам должна быть окончательна понятна структура словаря, которая выглядит следующим образом:
В предыдущей главе было рассмотрено то, что уже реализовано и может использоваться каждым в своей работе, но улучшения этим, разумеется, не ограничиваются: в планах на версию 3.8 стоит поддержка reversed словарями. Действительно, ничто не мешает вместо итерирования с начала массива элементов и увеличения индексов начать с конца и уменьшать индексы.
Для более глубокого погружения в тему рекомендуется ознакомиться со следующими материалами:
Если вы не знаете количество элементов в только что созданном словаре, сколько памяти расходуется на каждый элемент, почему теперь (CPython 3.6 и далее) словарь реализован двумя массивами и как это связано с сохранением порядка вставки, или просто не смотрели презентацию Raymond Hettinger «Modern Python Dictionaries A confluence of a dozen great ideas». Тогда добро пожаловать.
Впрочем, люди знакомые с лекцией, тоже могут найти немного подробностей и свежей информации, и для совсем новичков, не знакомых с бакетами и закрытым хешированием, статья тоже будет интересна.
Словари в CPython везде, на них основаны классы, глобальные переменные, параметры kwargs, интерпретатор создаёт тысячи словарей, даже, если вы сами не добавили ни одной фигурной скобки в свой скрипт. Но для решения многих прикладных задач словари так же используются, неудивительно, что их реализация продолжает улучшаться и всё больше обрастать разными трюками.
Базовая реализация словарей (через Hashmap)
Если вы знакомы с работой стандартного Hashmap и закрытого хеширования, можете переходить к следующей главе.
Идея, лежащая в основе словарей проста: если у нас есть массив, в котором хранятся объекты одинакового размера, то мы легко получаем доступ к нужному объекту, зная индекс.
Мы просто добавляем к смещению массива индекс, помноженный на размер объекта, и получаем адрес искомого объекта.
Но что, если мы хотим организовать поиск не по целочисленному индексу, а по переменной другого типа, например, находить пользователей по адресу их почты?
В случае простого массива нам придётся просматривать почты всех пользователей в массиве и сравнивать их с искомой, такой подход называется линейным поиском и, очевидно, что он куда медленнее обращения к объекту по индексу.
Линейный поиск может быть значительно ускорен, если мы ограничим размер области, в которой необходимо осуществлять поиск. Обычно это достигается взятием остатка от хеша. Поле, по которому осуществляется поиск, — ключом.
В итоге линейный поиск осуществляется не по всему большому массиву, а по его части.
Но что, если там уже есть элемент? Такое вполне может случится, так как никто не гарантировал, что остатки от деления хеша будут уникальны (как и сам хеш). В этом случае объект будет помещён по следующему индексу, если и он занят, то сместится ещё на один индекс и так пока не найдёт свободный. При извлечении элемента, будут просмотрены все ключи с одинаковым хешем.
Данный тип хеширования называется закрытым. Если в словаре остаётся мало свободных ячеек, то такой поиск грозит выродиться в линейный, соответственно мы потеряем весь выигрыш, ради которого и создавался словарь, во избежание подобного интерпретатор сохраняет массив заполненным на 1/2 — 2/3. Если свободных ячеек не хватает, то создаётся новый массив в два раза больше предыдущего и элементы из старого переносятся в новый по одному.
Что же делать, если элемент был удалён? В таком случае в массиве образуется пустая ячейка и алгоритм поиска по ключу, не может различить, эта ячейка пуста, потому что элемента с таким хешем не было в словаре, или потому что он был удалён. Во избежание потери данных при удалении ячейка помечается специальным флагом (DKIX_DUMMY). Если во время поиска элемента встретится этот флаг, то поиск продолжится, ячейка считается занятой, в случае вставки ячейка будет перезаписана.
Особенности реализации в Python
Каждый элемент словаря должен содержать ссылку на целевой объект и ключ. Ключ необходимо хранить для обработки коллизий, объект — по очевидным причинам. Так как и ключ, и объект могут быть любого типа и размера мы не можем хранить в структуре непосредственно их, они лежат в динамической памяти, а в структуре элемента списка хранятся ссылки на них. То есть размер одного элемента должен быть равен минимум размеру двух указателей (16 байт на 64-битных системах). Однако интерпретатор хранит ещё и хеш, сделано это для того, чтобы не перевычислять его при каждом увеличении размера словаря. Вместо того, чтобы вычислять хеш от каждого ключа по-новому и брать остаток от деления на количество бакетов, интерпретатор просто читает уже сохранённое значение. Но, что если объект ключа изменили? В таком случае хеш должен пересчитаться и сохранённое значение будет неверным? Такая ситуация невозможна, так как изменяемые типы не могут быть ключами словаря.
Структура элемента словаря определена следующим образом:
typedef struct { Py_hash_t me_hash; // хеш PyObject *me_key; // указатель на ключ PyObject *me_value; // указатель на хранимый объект } PyDictKeyEntry;
Минимальный размер словаря объявлен константой PyDict_MINSIZE, которая равна 8. Разработчики решили, что это оптимальный размер, для того, чтобы избежать лишнего расходования памяти на хранение пустых значений и времени на динамическое расширение массива. Таким образом при создании словаря (до версии 3.6) вам требовалось минимум 8 элементов в словаре * 24 байт в структуре = 192 байта (это без учёта остальных полей: расходы на саму переменную типа словарь, счётчик числа элементов и т.д.)
Словари используются и для реализации полей пользовательских классов. Python позволяет динамически изменять количество атрибутов, эта динамика не требует дополнительных расходов, так как добавление/удаление атрибута по сути эквивалентно соответствующей операции над словарём. Однако данным функционалом пользуется меньшинство программ, большинство ограничивается полями, объявленными в __init__. Но каждый объект должен хранить свой словарь, со своими ключами и хешами, несмотря на то, что они совпадают с другими объектами. Логичным улучшением тут выглядит хранение общих ключей только в одном месте, именно это и было реализовано в PEP 412 — Key-Sharing Dictionary. Возможность динамического изменения словаря при этом не исчезла: если меняется порядок или количество ключей словарь преобразуется из разделяющего ключи в обычный.
Во избежание коллизий максимальная «загрузка» словаря составляет 2/3 от текущего размера массива.
#define USABLE_FRACTION(n) (((n) << 1)/3)
Таким образом первое расширение произойдёт при добавлении 6-го элемента.
Массив получается довольно разряжен, во время работы программы от половины до трети ячеек остаются пустыми, что ведёт к увеличенному расходу памяти. Для того, чтобы обойти это ограничение и по возможности хранить только необходимые данные был добавлен новый
Вместо хранения разряженного массива, например:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'} # -> entries = [['--', '--', '--'], [-8522787127447073495, 'barry', 'green'], ['--', '--', '--'], ['--', '--', '--'], ['--', '--', '--'], [-9092791511155847987, 'timmy', 'red'], ['--', '--', '--'], [-6480567542315338377, 'guido', 'blue']]
Начиная с версии 3.6 словари организованны следующим образом:
indices = [None, 1, None, None, None, 0, None, 2] entries = [[-9092791511155847987, 'timmy', 'red'], [-8522787127447073495, 'barry', 'green'], [-6480567542315338377, 'guido', 'blue']]
Т.е. хранятся только те записи, которые действительно необходимы, они вынесены из хеш-таблицы в отдельный массив, а в хеш-таблице хранятся только индексы соответствующих записей. Если изначально на массив уходило 192 байт, то сейчас только 80 (3 * 24-байт для каждой записи + 8 байт на indices). Достигнуто сжатие в 58%.[2]
Размер элемента в indices тоже меняется динамически, изначально он равен одному байту, то есть весь массив может быть помещён в один регистр, когда индекс начинает не влезать в 8 бит, то элементы расширяются до 16, потом до 32 бит. Есть специальные константы DKIX_EMPTY и DKIX_DUMMY, для пустого и удалённого элемента, соответственно расширение индексов до 16 байт происходит, когда элементов в словаре становится более 127.
Новые объекты добавляются в entries, то есть при расширении словаря нет необходимости их перемещать, необходимо лишь увеличить размер indices и перезаполнить его индексами.
При итерировании по словарю, массив indices не нужен, элементы последовательно возвращаются из entries, т.к. элементы добавляются каждый раз в конец entries, то словарь автоматически сохраняет порядок вхождения элементов. Таким образом, кроме уменьшения необходимой памяти для хранения словаря, мы получили более быстрое динамическое расширение и сохранение порядка ключей. Уменьшение памяти хорошо и само по себе, но в то же время может увеличить быстродействие, так как позволяет большему числу записей влезть в кеш процессора.
Эта реализация настолько понравилась разработчикам CPython, что словари теперь обязаны сохранять порядок вставки по спецификации. Если раньше порядок словарей был детерминирован, т.е. жёстко определялся хешем и был неизменен от запуска к запуску, потом к нему добавили немного случайности, чтобы ключи шли каждый раз по-разному, то теперь ключи словаря обязаны сохранять порядок следования. Насколько это было необходимо, и что делать, если появится ещё более эффективная реализация словаря, но не сохраняющая порядок вставки, непонятно.
Впрочем, и так раздавались просьбы реализовать механизм сохранения порядка объявления атрибутов в классах и в kwargs, данная реализация позволяет закрыть эти проблемы без специальных механизмов.
Вот как это выглядит в коде CPython:
struct _dictkeysobject { Py_ssize_t dk_refcnt; /* Size of the hash table (dk_indices). It must be a power of 2. */ Py_ssize_t dk_size; /* Function to lookup in the hash table (dk_indices): - lookdict(): general-purpose, and may return DKIX_ERROR if (and only if) a comparison raises an exception. - lookdict_unicode(): specialized to Unicode string keys, comparison of which can never raise an exception; that function can never return DKIX_ERROR. - lookdict_unicode_nodummy(): similar to lookdict_unicode() but further specialized for Unicode string keys that cannot be the <dummy> value. - lookdict_split(): Version of lookdict() for split tables. */ dict_lookup_func dk_lookup; /* Number of usable entries in dk_entries. */ Py_ssize_t dk_usable; /* Number of used entries in dk_entries. */ Py_ssize_t dk_nentries; /* Actual hash table of dk_size entries. It holds indices in dk_entries, or DKIX_EMPTY(-1) or DKIX_DUMMY(-2). Indices must be: 0 <= indice < USABLE_FRACTION(dk_size). The size in bytes of an indice depends on dk_size: - 1 byte if dk_size <= 0xff (char*) - 2 bytes if dk_size <= 0xffff (int16_t*) - 4 bytes if dk_size <= 0xffffffff (int32_t*) - 8 bytes otherwise (int64_t*) Dynamically sized, SIZEOF_VOID_P is minimum. */ char dk_indices[]; /* char is required to avoid strict aliasing. */ /* "PyDictKeyEntry dk_entries[dk_usable];" array follows: see the DK_ENTRIES() macro */ };
Но итерирование устроено сложнее, чем можно было изначально подумать, существуют дополнительные механизмы проверки, что словарь не был изменён во время итерирования, один из них — версия словаря в виде 64-битного числа, который хранит каждый словарь.
Напоследок рассмотрим механизм разрешения коллизий. Дело в том, что в python значения хеш-функции легко предсказуемы:
>>>[hash(i) for i in range(4)] [0, 1, 2, 3]
А так как при создании словаря от этих хешей берётся остаток от деления, то по сути определяют, в какой бакет пойдёт запись, лишь несколько последних бит ключа (если он целочисленный). Можно представить себе ситуацию, когда у нас много объектов «хотят» попасть в соседние бакеты, в таком случае при поиске придётся просмотреть множество объектов, которые находятся не на своих местах. Для уменьшения числа коллизий и увеличения числа бит, определяющих, в какой бакет пойдёт запись был реализован следующий механизм:
// вместо простого i = i + 1 % n // был реализован следующий: #define PERTURB_SHIFT 5 perturb >>= PERTURB_SHIFT; j = (5*j) + 1 + perturb; // использовать значение j % n в качестве следующего индекса
perturb — целочисленная переменная, инициализируемая хешем. Следует заметить, что в случае большого числа коллизий она обнуляется и следующий индекс вычисляется по формуле:
j = (5 * j + 1) % n
При извлечении элемента из словаря осуществляется такой же поиск: вычисляется индекс слота, в котором должен находиться элемент, если слот пуст, то выбрасывается исключение «значение не найдено». Если же значение в данном слоте есть, необходимо проверить, что его ключ соответствует искомому, это вполне может не выполняться, если произошла коллизия. Однако ключом может быть почти любой объект, в том числе такой, для которого, операция сравнения занимает значительное время. Дабы избежать длительной операции сравнения, в Python применено несколько трюков:
# псевдокод алгоритма (на самом деле там, разумеется C) def eq(key, entity): if id(key) == id(entity): return True if hash(key) != hash(entity): return False return key == entity
сначала сравниваются указатели, если указатель ключа искомого объекта равен указателю объекта, по которому осуществляется поиск, то есть указывают на одну и ту же область памяти, то сравнение сразу же возвращает истинно. Но и это не всё. Как известно, у равных объектов должны быть равные хеши, из чего следует, что объекты с разными хешами не равны. После проверки указателей проверяются хеши, если они не равны, вернётся false. И лишь, если хеши равны, будет вызвано честное сравнение.
Какова вероятность такого исхода? Примерно 2^-64, разумеется из-за лёгкой предсказуемости значения хеша, можно легко подобрать такой пример, но в реальности до этой проверки выполнение доходит не часто, насколько? Raymond Hettinger собрал интерпретатор, изменив последнюю операцию сравнения простым return true. Т.е. интерпретатор считал объекты равными, если их хеши равны. После чего натравил на такой интерпретатор автоматизированные тесты многих популярных проектов, которые завершились успешно. Может показаться странным считать объекты с равными хешами равными, не проверять дополнительно их содержимое, и целиком полагаться только на хеш, но вы это делаете регулярно, когда пользуетесь протоколами git или torrent. Они считают файлы (блоки файлов) равными, если равны их хеши, что вполне может привести к ошибкам, но их создатели (и все мы) надеемся, стоит заметить, небезосновательно, что вероятность коллизии крайне мала.
Сейчас вам должна быть окончательна понятна структура словаря, которая выглядит следующим образом:
typedef struct { PyObject_HEAD /* Number of items in the dictionary */ Py_ssize_t ma_used; /* Dictionary version: globally unique, value change each time the dictionary is modified */ uint64_t ma_version_tag; PyDictKeysObject *ma_keys; /* If ma_values is NULL, the table is "combined": keys and values are stored in ma_keys. If ma_values is not NULL, the table is splitted: keys are stored in ma_keys and values are stored in ma_values */ PyObject **ma_values; } PyDictObject;
Будущие изменения
В предыдущей главе было рассмотрено то, что уже реализовано и может использоваться каждым в своей работе, но улучшения этим, разумеется, не ограничиваются: в планах на версию 3.8 стоит поддержка reversed словарями. Действительно, ничто не мешает вместо итерирования с начала массива элементов и увеличения индексов начать с конца и уменьшать индексы.
Дополнительные материалы
Для более глубокого погружения в тему рекомендуется ознакомиться со следующими материалами:
- Запись доклада в начале статьи
- Предложение новой реализации словарей
- Исходный код словаря в CPython
