
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Знакомые скаллисты говорят, что с помощью cats получается почти 1в1 как в хаскель варианте. Теперь понятно, почему в Тинькове именно скалу используют, однако.
Хорошая статья. Я считаю, сложность программирования на Хаскеле сильно преувеличена, как и простота программирования на Го. Из-за императивной сущности языка, отсутствия иммутабельности и хорошей типизации граблей там предостаточно. Так, чтобы эффективно использовать Го, необходимо изучить мануал Effective Go, и понимать модель вычислений в Go, например
Understanding real-world concurrency bugs in Go.
Вот и у меня было такое подозрение, но "люди говорят, милорд", никаких данных на руках у меня не было. Поэтому и появилась необходимость провести независимое расследование. Еще забавно, что для варианта на хаскелле мне хватило интуиции, а вот чтобы написать самое правильное последнее решение на го, как мне сказал человек его написавший "нужно хотя бы полгодика пописать именно на го".
В изначальном варианте в Go подозрительно выглядит строка
resNode.children = append(resNode.children, &commentTree{})Дело в том что в Go slice внутри это обычный массив с capacity. Соответственно если capacity превышено то создается новый массив с увеличенным capacity, в него переписываются старые значения и добавляются новые. Если это делается в одном потоке то все норм, но в многопоточном варианте будут проблемы. Все таки в go идеоматическим вариантом было бы передача значений по каналам и аккумулирование детей в родительском потоке отвечающем за текущий набор детей.
Здесь самый на мой взгляд интересный вопрос в плане производительности. Скажем если сгенерить большое дерево (ну скажем пусть будет 1 млн узлов) и выбрать из него процентов 5 данных что получится по скорости и потреблению памяти? Причем если в плане haskel в целом замеров в сети много то вот сравнение go vs C# было бы интересным ИМХО
Вообще говоря, правильное решение этой задачи — хранить дерево в нормализованной форме (Dictionary( NodeId , NodeData )). Это мало того, что упрощает задачу "получить список идентификаторов всех узлов", так ещё и не вызывает экспоненциального роста потребления всех ресурсов, когда условия меняются так, что в дереве вдруг появляются циклы.
Это решает одни проблемы, но добавляет другие. Например, если мы берем ту же дополнительную задачу на условное выкидывание детей, то все что нам нужно сделать — проверить в обработчике условие, и если оно выполняется, то мы сразу выкинем все поддерево.
В случае с Dictionary нам придется по нему руками (потенциально долго) ходить и удалять все NodeId того поддерева, которое мы хотим удалить.
По условию изначальной задачи даже в планах не стоит модифицикация полученного дерева, а потому я согласен с vintage.
Всё как всегда: без внятного ТЗ — результат ХЗ :)
Так я же не возражаю, а просто обращаю внимание на особенности решения. Мы ведь по сути этим и занимаемся, пишем что-то на разных языках а потом смотрим, насколько гибким получилось полученное решение, что мы в его рамках можем сделать дешево, а что дорого, и так далее. Для решения исходной задачи решение, конечно, подойдет, но когда мы начнем мутировать условия (как происходит в реальной жизни) то начинаются сложности.
Что касается вопроса с "ТЗ", то у меня опыт такой, что иногда бывает задача её не доехала до мастера, а тестируется на регрессе в девелопе, а тебе уже приходят задачи на её модификацию и доработки.
проверить в обработчике условие, и если оно выполняется, то мы сразу выкинем все поддерево.
Ага, конечно, а кто удалит остальные ссылки на удалённые узлы? А delete на сервер кто по каждому узлу пошлёт?
Она дедлочится потому, что автор данного текста на самом деле не понимает того, что происходит в программе, хотя и заявляет, что понимает каждую строчку. Я надеюсь, что автор честно сам себе в этом признается.
Не понимаю, я же это прямо написал в самой статье, в чем собственно и посыл. Есть много простого кода, но где-то забралась банальная опечатка или неправильное понимание примитива (в моем случае — неправильное понимание записи for ch in range channel).
Следующий момент — автор скачал хаскелевскую библиотеку, которая берёт на себя все проблемы с распараллеливанием, затем вставил её в свой код на хаскеле, потом не нашёл аналога на го и начал изобретать велосипед «своими руками», после чего изобретение «не поехало». И какой из этого делается вывод? Ну конечно же — го отстой, а хаскель — это круто.
Так я только рад буду, если вы покажете какую-нибудь библиотеку на го, которая позволит сделать все то же самое. Если вы мне дадите готовый код, я его в Upd. к посту добавлю.
И наконец, на С# код написан много быстрее, чем на хаскеле. Из минусов — некоторая кажущаяся объёмность переделки кода под новую структуру. Но разве мы постоянно меняем структуры в программе? Вроде нет. Тогда каков вес этого минуса? И каков вес плюса, позволившего очень быстро написать решение на привычном языке?
На сишарпе я написал намного быстрее потому что я на нем больше 6 лет пишу продакшн, а хаскелль и го видел впервые в жизни. Моя грубая оценка: опытный го-разработчик написал бы минут за 5, а опытный хаскеллист минуты за три.
В целом мне тоже го не нравится, но всё же в данном тексте вижу необъективность, а потому показываю пальцем. Сорри, автор, минусуй, может и не проиграешь.
Все возражения абсолютно логичны, зачем мне минусовать? Конструктивно обсудить все проблемы всегда выгоднее для всех, либо вы ошибаетесь и передумаете, либо я, тогда тем более нужно это выяснить и написать опровержение в статье.
я точно знаю что происходит на каждой строчке программы
Я же специально выделил часть вашего текста:
Ну так все правильно, каждая строчка понятна, а при их композиции произошла фигня. Потому что строчек много, и комбинаторный взрыв происходит очень неприятный.
Так суть-то не в показе библиотеки, а в сравнении двух языков на основании нахождения для одного из них уменьшающего сложность решения. Простая случайность (нагуглилось нужное) приводит к выводу о порочности всего языка. Вот про это я и говорил.
Мне кажется, что такой библиотеки просто в принципе нет, по крайней мере я не представляю, как её создать с теми возможностями, что дает Go. Впрочем, я признаю, что могу ошибаться — достаточно продемонстрировать контрпример и всё станет понятно.
Пусть даже так (хотя не факт), но что это меняет? В любой серьёзной разработке собственно написание кода — это малая часть работы. И разница 3-5 минут вообще ничего не решает.
Ну во-первых 3-5 минут это почти в 2 раза. Во-вторых, как правильно замечено, чтение кода занимает б0льшую часть времени. Поэтому язык, где по сигнатуре можно понять всё, что происходит внутри (например, есть вывод на экран/запись в БД/… или нет) очень экономит это самое время. Ну и в-третьих мне кажется, что 15 строк прочитать проще, чем 60. Это еще раньше подмечено было, раздел "Не очень выразительный" (заголовок желтоват, но тот поинт актуален).
И вот в случае хаскеля простота обучения, скажем прямо, так себе. А в случае го — всё доступно. Именно поэтому гуглы и придумали го, ибо им нужны миллионы индусов, которые задёшево и быстро освоят новый язык. Представьте себе, сколько времени займёт освоение хаскеля обычным индусом (из тех самых миллионов). Представили? Вот поэтому го идёт в массы, а хаскель тихо курит бамбук в академической среде.
Для человека с хотя бы годом опыта работы в любом несистемном языке не будет никаких проблем с изучением хаскелля, мне казалось я достаточно по шагам описал возможный процесс.
Ну а быть или не быть "обычным индусом" каждый человек пусть решает сам. Мне кажется, что разработчики достойны лучшего и должны ценить своё время. То, что может проверить машина, должна проверять машина — это если в двух словах о том, какая у меня позиция по теме.
ЗЫ. Это всё не спора ради. Просто замечания по смыслу текста. Надеюсь на некоторое дополнение к статье с осмыслением данных замечаний. Хотя с другой стороны — количество просмотров упадёт буквально через пару дней, так что может и не стоит заморачиваться с дописанием.
Конечно, спасибо вам за замечания. А насчет просмотров — будем надеяться, что люди прочитают статью. Согласятся ли, возразят ли, главное получить информацию для размышления.
Для человека с хотя бы годом опыта работы в любом несистемном языке не будет никаких проблем с изучением хаскелля, мне казалось я достаточно по шагам описал возможный процесс.Надеюсь, никто камнями не закидает, но… Вроде знаю много языков, разбираясь в них на уровне от «в общих чертах» и выше, но от хаскелля я немного в ужасе (хотя статью про монады и хасскель переваривал когда-то на Хабре). Читал Ваше введение, читал… Вроде по-отдельности всё понятно. Но вдруг main очередного примера складывается в одну длинную строчку с кучей знаков препинания… И смысл улетел, смысл кода не вижу.
main = putStrLn . show . add 10 . add5 $ sqr 3-- ура! нет скобочекНу давайте разберемся. Точечки нам по сути просто экономят скобки. Читаем запись практически дословно:
Выводим на экран. Что?
Преобразованное в строку. Что?
Добавление 10 к чему?
Добавление5 к чему?
К квадрату трёх.
Получаем "выведи на экран преобразованное в строку добавление 10 к добавлению5 к квадрату трёх". Ничем не хуже WriteLine(ToString(Add(10, Add5(Sqr(3)))))). А еще не надо считать сколько скобочек надо закрывать чтобы выражение скомпилировалось. Поверьте, когда я в сишарпе работал с AST я мечтал чтобы в нем была такая возможность...
В таком случае не согласен.
Ну пишите скобки, если хотите, никто же не заставляет так писать. Мне просто показалось это удобным, потому что иметь как в лиспе )))))) в конце не круто.
Поверьте, когда я в сишарпе работал с AST я мечтал чтобы в нем была такая возможность...
Так всё равно же не помогло бы! Там-то сложные выражения частенько идут в середине, а "скобочно оптимизируется" только последний аргумент же.
Ну даже если в середине, можно себе упростить жизнь. Например так:
main :: IO ()
main = do
putStrLn . show $ (*) ((+) 10 5) $ (+) 2 3Естественно для арифметики и подходящих операторов писать нормально:
main :: IO ()
main = do
putStrLn . show $ (10 + 5) * (2 + 3)просто для иллюстрации возможности, вместо +/* могут быть нормальные функции.
Точки — это просто, попробуйте уследить за типами тут:
newtype Parser a = Parser { unParser :: String -> [(String, a)] }
instance Functor Parser where
fmap f = Parser . (fmap . fmap . fmap) f . unParserЯ щас что-нибудь однострочное на акка стримах скину тоже офигеете парсить что написано :)
Ответ просто — надо писать для людей, а не чтобы компилятор отстал.
ну, так в сях тоже можно #define TRUE FALSE и угадывай там, что же на самом деле было. Наговнякать можно на любом языке.
За типами пусть компилятор следит, он это хорошо умеет.
А так, после первого замешательства, даже понятно что происходит.
Первый fmap работает для кортежа (String, a), второй — для списка [(String, a)], третий — для функции String -> [(String, a)], через их все и пробрасывается f. Вызовы Parser и unParser — это просто распаковка и упаковка именованного типа.
Хотя я бы предпочёл всё же читать что-то более понятное...
Если рассматривать всяческие дурацкие способы, то можно взять пустую строку, распарсить её как a, применить к результату f, после чего возвращать результат как константу независимо от переданной строки. Или можно просто вернуть undefined, у нас же нетотальный язык.
Так что в общих чертах понимать что происходит всё равно надо.
Вам просто неоткуда взять a, кроме как из парсера-аргумента к fmap.
Зато строки я могу создавать без всяких там инстансов, ведь это конкретный тип данных. Говорю же, надо лишь распарсить пустую строку (и пофигу на неизбежную панику, на то пример
и дурацкий):
instance Functor Parser where
fmap f x = Parser $ const $ f $ snd $ head $ unParser x ""Вряд ли даже с завтипами и тотальностью вы можете запретить воткнуть композицию с const "" перед unParser если только специально не будете "ловить" именно этот случай.
Проще просто хоть немного понимать что в коде происходит, а не только на типы смотреть.
А завтипы разве как-то позволяют вывести это свойство для стандартного Functor?
Я вот смотрю на файл Functor.idr и не вижу никаких хитрых проверок. Да там, в отличии от Хаскеля, даже в комментарии подобная аксиома не упомянута.
Я думаю вы немного не туда смотрите :) https://github.com/idris-lang/Idris-dev/blob/master/libs/contrib/Interfaces/Verified.idr#L21
Читаем запись практически дословноДля этого нужно понимать каждую функцию в строке (количество, плюс, возможно – тип аргументов). А в умеренном количестве скобок ничего страшного нет, плюс:
QJsonValue v = ...; // некоторое значение
if(v.isArray()) {
for(QJsonValue v2 : v.asArray())
doSomething(v2);
}Console.WriteLine( Add(10, Add5(3 . Sqr)).AsString )var ArgumentIdentifier = (id) => Argument(IdentifierName(id));
// Тогда получается не так страшно местами
something.AddArgumentListArguments(
ArgumentIdentifier(web3Identifier),
ArgumentIdentifier(abiIdentifier),
ArgumentIdentifier(binIdentifier),
ArgumentIdentifier(gasIdentifier),
...
);
SingletonList(
AttributeList(
SingletonSeparatedList(
Attribute(
IdentifierName("FunctionOutputAttribute")))))
// =>
AttributeIdentifier("FunctionOutputAttribute")
.AsSingletonSeparatedList()
.AsAttributeList()
.AsAttributeList()
Ну пишите скобки, если хотите, никто же не заставляет так писать.Это работает до первой встречи с чужим кодом; если самому не понять, как это работает – то потом нельзя будет быть уверенным, что при возникновении проблем ответ на свой вопрос по хасскелю на том же stackoverflow удастся разобрать и понять :) Не всё же бездумно копипастить.
Как-то я пропустил ваш комментарий, вчера температура 39 была, поэтому видимо не заметил.
После чего дальше примеры выглядят ещё более жутко – вроде как общий смысл виден, но больше похоже на магию всё равно.
Честно говорю, вопрос привычки же :) Если вам нужно, можете выносить в локальные переменные:
main = do
let print = putStrLn . show
let printAdd10 = print . add 10
let pritnAdd10Add5 = printAdd10 . add 5
pritnAdd10Add5 $ sqr 3Новички в сишарпе тоже LINQ считают магией и выносят каждый шаг обработки в локальные переменные, но более знакомые с технологией не стесняются по 5-10 вызовов в чейне сделать. Просто потому что так обычно удобнее.
Для этого нужно понимать каждую функцию в строке (количество, плюс, возможно – тип аргументов). А в умеренном количестве скобок ничего страшного нет
Так просто не пишут, потому что так удобнее. Как например флюент апи в сишарпе никто не выносит в переменные. Знай просто читай как оно написано и все.
IDE может подсветичивать парные скобки, помогая уложить в голове выражение (при такой записи в хасскеле это невозможно);
Так а зачем вам скобки? допустим у нас есть функция add 10 . add 5 $ sqr 3. Смотрим на сигнатуру add, видим Int -> Int -> Int, смотрим, что передали в неё Int, значит осталось Int -> Int. Ок, теперь смотрим что справа от точки. add 5 $ sqr 3, тут все вроде понятно. Ну и вспоминая Int -> Int и то, что справа у нас получился Int, получаем результат выражения Int.
Если все расписывать, кажется, что это сложно, но это не так. Я вам честно говорю, если вы хотя бы пару часов на хаскелле попишете вы оцените удобство.
Не хватает только возможности делать свойства расширений – при желании можно было бы писать так:
Ну скоро добавят extension everything, но сахара имхо в сишарпе давно хватает. А вот полезных фич добавляется не так много, к сожалению.
И немного offtopic по вашему коду
Вы совершенно правы, но тут вся суть в том, что я этот код весь написал за ~2 рабочих дня, и у меня просто не было времени рефакторить. Я по сути написал кодогенератор на рослине сам для себя, забрав 2 дня из текущей задачи на работе. Потом конечно он мне эти 2 дня легко сэкономил и я выправился, но сидеть и улучшать код времени не было. Работает, и хорошо :) Но вообще конечно надо бы все эти лесенки убрать.
Но даже с вашими советами количество )))))))) будет большим, если только не дробить всё очень мелко.
main = do
putStrLn . show . add 10 . add5 $ sqr 3
putStrLn . show $ add 10 . add5 $ sqr 3
putStrLn . show $ add 10 $ add5 $ sqr 3
putStrLn . show $ add 10 . add5 . sqr 3
putStrLn . show $ add 10 ( add5 . sqr 3 )putStrLn . show $ add 10 ( add5 . sqr 3 )( add5 . sqr 3 )смотрите, точка между функциями означает композицию. f . g === x => f(g(x)). Теперь сморим на эту запись:
add5 . sqr 3sqr 3 это не функция, а значение. Нельзя скомпозировать функцию и значение. Поэтому оно и не собирается, у вас по стрелкам не сходится. Композиция работает так: (a -> b) . (b -> c) => a -> c. А у вас слева add5 :: Int -> Int, а справа sqr3 :: () -> Int. Поэтому и не компилируется :)
Поэтому если вы напишете так:
putStrLn . show $ add 10 (( add5 . sqr) 3 )То стрелки сойдутся и все заработает
Впрочем, вижу вы это и дописали, а я проглядел.
Уточнение: sqr 3 имеет тип Int, а не () -> Int.
Тип () -> Int могла бы иметь конструкция const $ sqr 3
Они изоморфны, потому что стрелки между категориями всегда отображаются на значения множества 1-1 :)

Собственно вы и показали способ это сделать. В обратную сторону так же тривиально :)
Хотя если подходить строго с точки зрения хаскельного компилятора, для него это конечно разные вещи. Но иногда удобно смотреть на значения как на функции без аргументов.
Тольуко у композиции функций немного другая сигнатура:
GHCi>:t (.)
(.) :: (b -> c) -> (a -> b) -> a -> cTL;DR Вообще проблема с тем, что это работает автомагически — она характерна для всей индустрии. Историю с left-pad помните, надеюсь? Вот и везде так — берут готовые библиотеки, не вдаваясь в суть того, что у них под капотом.
Во первых, это подтверждает очевидную истину — не зная в деталях объект приложения усилий, можно нагородить ерунду. Поэтому здесь ничего удивительного нет, кроме одного момента — почему вы удивляетесь, что не можете понять смысл целого, когда не знаете деталей?
Вопрос в емерджентности: проблема возникает не принадлежит какой-то конкретной строчке кода, а возникает лишь из их совокупности.
Во вторых, разбираясь с хаскелем, в голове не заучившего наизусть все приоритеты и все библиотечные функции программиста, происходит тот же самый комбинаторный взрыв.
О каких приоритетах идет речь? Выполнение идет всегда справа налево, как и во всех остальных языках — f(g(h(x))), сначала h, потом g, потом f. Знать все библиотечные функции не обязательно, достаточно уметь сформулировать вопрос в гугл. А то и в хугл.
Вообще, когда я не понимаю, что происходит при выполнении программы, меня это напрягает. Я оказываюсь в ситуации, когда должен полагаться на волю случая — а вдруг там внутри всё само как-то правильно сложится?
Суть как раз в том, чтобы знать что что-то работает нужно иметь возможность судить об этом по интерфейсу, а не по реализации. Как только вы пошли в реализацию смотреть, что там написано, вы потеряли главный плюс программирования — возможность абстрагировать сложность. "А вдруг оно там сломается" — в этом ведь и смысл, чтобы если скомпилировалось, значит ничего не сломается. Это как писать тесты за формально верифицированным кодом, просто карго культ языков с более слабыми системами типов.
Без зазубривания же вы не сможет понять чужой код.
Я не настоящий хаскеллист, но судя по тому что я слышал от людей чтобы понять чужой код достаточно посмотреть какие типы у функции + название. Учить их не надо, чтобы понимать. Точно так же как если вы приходите в новый проект на C#/Java/Go и там есть функция SendEmail с параметрами урла и текстом уведомления, вам не надо "учить" эту функцию. Ну ок, она есть.
А вот хугл это очень крутая штука, я тут потыкал недавно. Например, у вас есть массив, и вы хотите его отсортировать. Достаточно просто сделать поиск по сигнатуре (a -> Bool) -> [a] -> [a], и почти наверняка найдете пару функций сортировки. Выбирайте любую. То есть у вас ситуация, что у вас есть некоторые типы на входе, а функция возвращает какой-то другой. Вы не знаете, что сделать, чтобы все отработало. Вбиваете сигнатуры в хугл и он вам подсказывает, какие есть библиотеки и с какими функциями. Из-за того, что сигнатура на 100% описывает что происходит внутри это и становится возможно. С императивными функциями () -> () так не выйдет, увы.
Вот в этом и проблема хаскеля — он не предназначен для тех, кому нужен простой и быстрый результат. А это как раз все те индусы.
Если человек потратил время чтобы изучить его возможности он напишет так же быстро, как и на го. Если человека устраивает вечно сидеть на уровне миддла и его не разочаровывает то, как он тратит свой талант, что ж, его право.
Я уже не раз говорил, что я предпочту потратить день на изучение фичи, которая будет мне экономить одну минуту каждый день до конца жизни. Просто потому, что это выгодно по объективным математическим соображениям.
Потому что там сразу ясно, что происходит. Ну а комбинаторная сложность комплексных явлений, будь то текст программы или что угодно ещё, всегда высокая. И в хаскеле с ней бороться невозможно без понимания всех функций, типов, приоритетов.
Все еще не понимаю, про какие функции и приоритеты речь. У вас есть ну пусть сотня стандартных функций, аналог BCL любого языка. Ну и ладно, не так уж сложно. Насчет комбинаторной сложности — меня вот всегда бесила геометрия, заучивать формулы 100500 фигур. А потом я узнал, что все эти формулы можно было бы заменить одинарным-двойным интегралом. Я просто потратил год школьный на то, чтобы выучить кучу бесполезных формул, тогда как на протяжении всего этого года нам могли бы объяснить принцип, и мы бы для любых фигур могли бы считать, а не только для "одобренных минобром".
Хотя да, можно полагаться на удачу — запустил и оно как-то само всё сделало. Но это не наш метод.
Поймите, что вся суть в том, чтобы компилятор ловил ошибки. Собралось, значит все правильно и отработает ожидаемым образом. Именно за эту безопасность приходится платить всеми этими "сложностями". Но сложность привносимая инструментом должна быть ниже чем побежденной проблемы. Экскаватор сложнее лопаты, и если вы хотите перекопать грядку то он излишен. Но глупо спорить, что он хуже лопаты в задачах выкапывания колодцев. Я по работе в основном занимаюсь именно колодцами, а не простыми грядками. Поэтому я и рад такому инструменту.
Если вы в курсе, что такое дженерики, то всё вы легко поймёте. На крайний случай — есть просто тип Object, плюс интроспекция — вот вам и рецепт для повторения. То есть при минимальном желании библиотеку написать вполне возможно. Ну а возражения других участников о якобы невозможности такого чуда — оставим на их совести.
Ниже объяснялось, почему не получится это сделать в го. Ни без генериков, ни с ними.
Опять — вам кажется. В одну строку можно вытянуть выражения почти на любом языке, но понятней от этого не становится. Та же обработка в циклах на императивных языках часто гораздо нагляднее, нежели то же самое, но с рекурсивными вызовами, без которых в принципе нельзя сделать что-то вменяемое на функциональных языках. И да, в императиве при этом строк будет больше. Но понятность-то будет лучше!
Спросите у сишарпистов, что понятнее, императивный код на циклах или декларативный на LINQ.
Вопрос не в возможности изучения, а в скорости. Индус будет изучать лет 5 (может утрирую, но не сильно). А го изучит параллельно с работой, даже не заметит. Есть разница?
Мне кажется вы очень переоцениваете сложность. Я думаю, что разница в несколько раз. Если для го приличный код можно выдавать через месяц, то на хаскелле через 2-3. На примере того же Rust я слышал именно такую статистику. Вопрос в том, что у вас нет ограничения на потолок. Условно говоря, профессиональный гошник напишет программу за день, а начинающий — за 2 недели. При это начинающий хаскеллист будет писать 2 месяца, а профессиональный — за час. Я стремлюсь именно к последней цифре.
Проблема не в самооценке, а в объективно существующей потребности. Потребность простая — надо много и быстро. А индусы на хаскеле — не способны ни много, ни быстро. И как бы вы не решали, кем хотите быть, проблема от этого никуда не денется.
Ну мне жаль индусов, я выбираю язык для себя. Я не буду выбирать плохой инструмент только потому, что он модный. 95% веб-сайтов это вордпресс сайты-визитки, но при этом люди как-то продлжают заниматься бекендом на этих ваших джавах и нодах.
И да, разработчики, которые ценят своё время, как раз очень озабочены затратами этого самого времени на зазубривание хаскеля хотя бы на уровне стандартного синтаксиса и Prelude. То есть если времени девать некуда — ну тогда ОК, можно заниматься хаскелем. А если есть актуальные задачи?
Времени вообще никогда не хватает

Вопрос только в желании вечно оставаться на подхвате, и писать руками то, что могла бы сгенерировать машина.
Вообще, пришла в голову простая мысль — сторонники функционального подхода реально не знают, что такое требования жизни.
Мы недавно переписали сервис с джавы на хаскель, и выиграли в 5 раз по памяти и в 10 по производительности. Но да, раз этот язык не заставляет дебажить ночами прод значит он не продакшн реди.
В целом я бы повозился с тем же хаскелем побольше, но вот реально — а что толку? Куда я его прикручу с его неудобными ORM-ами и прочим? Народ давно попробовал и сделал вывод — для enterprise разработки оно реально неудобно.
Могу спросить в хаскельном чате что у них с орм, но по словам одного моего знакомого по крайней мере с постгресом никаких проблем нет.
Что касается экосистемы, то всегда есть Scala, в которой кода столько же сколько и в хаскелле, зато доступны все прелести джавовой экосистемы и 100500 фреймворков на любой вкус.
Ну и да, если я вас не убедил — ваше право остаться при своем. Я не загоняю людей в секту, а просто делюсь своими наблюдениями.
Есть, например, SQL (более распространённый аналог LINQ). И никто в здравом уме не пишет в императивных языках всё то, что можно сделать на SQL.
Зато почему-то продолжают писать всё то, что можно сделать на LINQ. Видимо, или язык плохой достался, или всё же не аналог.
Вот вы в своём коде использовали значок $, а почему? Знаете?
Чтобы не писать скобочки. Вот вы в своем языке знаете, у чего больше приоритет: у плюсика, скобочек или знака умножения?
Эффективно использовать инструмент, постоянно ползая по интернету — невозможно.
Ну то есть я в полтора раза быстрее чем на го, неэффективно используя язык. Что же будет когда я его хорошо изучу. Небось в разы быстрее писать начну.
Во первых, интерфейсы есть почти во всех императивных языках. Чем в этом плане лучше хаскель?
То что вы не разделяете интерфейс как элемент ООП и интерфейс как набор публичных АПИ о многом говорит.
Почему не выйдет с императивом? Например: (int[]) -> (int[]). Но интересно, а если функция просто переставляет пару значений в массиве, то как вы её отличите от сортировки?
Потому что я могу написать такую функцию на сишарпе:
int[] Foo(int[] a)
{
Console.WriteLine("Hello!");
ElasticSearch.Push(new LogMessage("Processing a"));
return a.Shuffle();
}А вот в хаскелле не получится (да, это плюс).
Потому что в хаскелле если я увижу сигнатуру foo :: [a] -> a я точно знаю, что результатом выполнения будет либо какой-то из элементов списка.
теперь посмотрим на шарп:
T Foo(T[] a)
{
return (T) Activator.CreateInstance(T); // упс
}Упс.
Но он так же потратит меньше времени на изучение го, значит суммарные затраты времени меньше.
Если вы планируете разработкой заниматься хотя бы еще 10 лет, то нет, не меньше.
Это хорошая максима, но исключительно для тех, у кого времени — вагон. В реальной жизни (если время всё-таки ограничено), приходится находить компромисс. И вот сообщество функциональных программистов здесь склоняется к максимизации времени на долговременно полезные затраты, а в реальной жизни с такой ориентацией быстро становишься неконкурентоспособен.
Это какой-то призыв "спервадобейся" и "ктотытакойчтобымнеговорить". Я не буду тут раскидывать пальцы и говорить, какой я конкурентноспособный или нет, просто рекомендую сделать небольшую переоценку такого утверждения.
Я же говорил — будь у меня куча лишнего времени, я бы обязательно много чего поизучал бы. Но даже когда вдруг время появляется, то оказывается, то «много чего» за раз не получается, приходится расставлять приоритеты, а потом находить способ не затягивать с первым выбранным предметом
Так для того и статья :) Вместо того, чтобы изучать 101ую библиотеу для того чтобы делать то же самое, что и другие 100, но теперь с модной финтифлюшкой, можно попробовать решить проблему принципиально.
У меня как-то получается и математику почитывать, и на работе работать, и на предыдущей проект доводить до конца, и с женой время не забываю провести, да в игрушки еще поигрываю. Ах да, еще и 30 часов чистого времени на статью где-то откопал. Ну вот как так)
Ну здесь же вы опять в сторону индусов уходите, хотя их образ действий критикуете.
Да, я критикую образ индусов. Делать втупую то, что может сделать машина — пустая трата времени. Вся суть программирования в автоматизации. Если бы всем было в кайф все руками делать (например, вместо экселя на калькуляторе считать или вместо автоматического пробрасывания через ExceptT писать if err != nil) то эти инструменты никогда не появились бы.
И если вы предпочитаете получить работающий способ здесь и сейчас, то вы идёте строго по пути индусов.
Верно, только это не работает дальше одноразовых скриптов до пятисот строк.
Поймите, что уровень, когда вся сложность ограничивается тем, что может компилятор, совершенно недостаточен для вменяемой разработки ПО. Такой подход люди тупо заменяют генерацией кода.
Что если я вам скажу, что компилятор при желании может проверить все ошибки в вашей программе, включая логические?
То есть вы поверили, что некий алгоритм в принципе не реализуем на языке, реализующем машину Тьюринга, но при этом отлично реализуем на другом языке, который тоже реализует машину Тьюринга?
Ну если вы хотите на го написать интерпретатор хаскелля то милости просим, теоретически это конечно возможно. Есть желающие?
Вы путаете ниши. Есть, например, SQL (более распространённый аналог LINQ). И никто в здравом уме не пишет в императивных языках всё то, что можно сделать на SQL. Поэтому ваш пример абсолютно некорректен.
Вообще не понял этот момент. Вообще-то мы говорили Linq2Objects, там вообще никаким SQL не пахнет. Вы же сказали про императивные циклы, вот я привел пример того, как языке вместо них пишут запросы. Вы, это, сжудения не подменяйте.
Ограничивает не язык, а умение придумать правильный алгоритм. Ну а инструмент — он и в африке инструмент.
Вот я придумал сделать сортировку, которая не зависит от типа объектов (только чтобы он сравниваться умел), а язык, собака, мне не дает его написать. Я конечно понимаю, что путь индуса для трех разных типов в программе где эта функция используется накопипастить 3 раза (чай не 10 же), но все же?
Хаскель как раз — модный. То есть продуктивность в реальной жизни он не обеспечивает, но создаёт иллюзию «последнего писка технологичности».
Это про хаскель из каждого утюга вещают и запросы в гугл подменяют? Вот не знал.
Но про компромисс и при её создании забыли.
Так ваш компромисс это исключительно "хуяк хуяк и впродакшн". Такой себе компромисс, должен сказать.
Значит писали сервис индусы. Если переписать сервис с хаскеля на Java, но не по индуйски, то вы ещё больше сэкономите.
Да, есть. Но всё же пока востребован императив, поэтому я на «тёмной стороне» силы. Вот победит функциональщина, докажет продуктивность в массовой разработке — я к вам обязательно присоединюсь :)
Да я не возражаю, мне больше заплатят же :) Только за индустрию немного обидно.
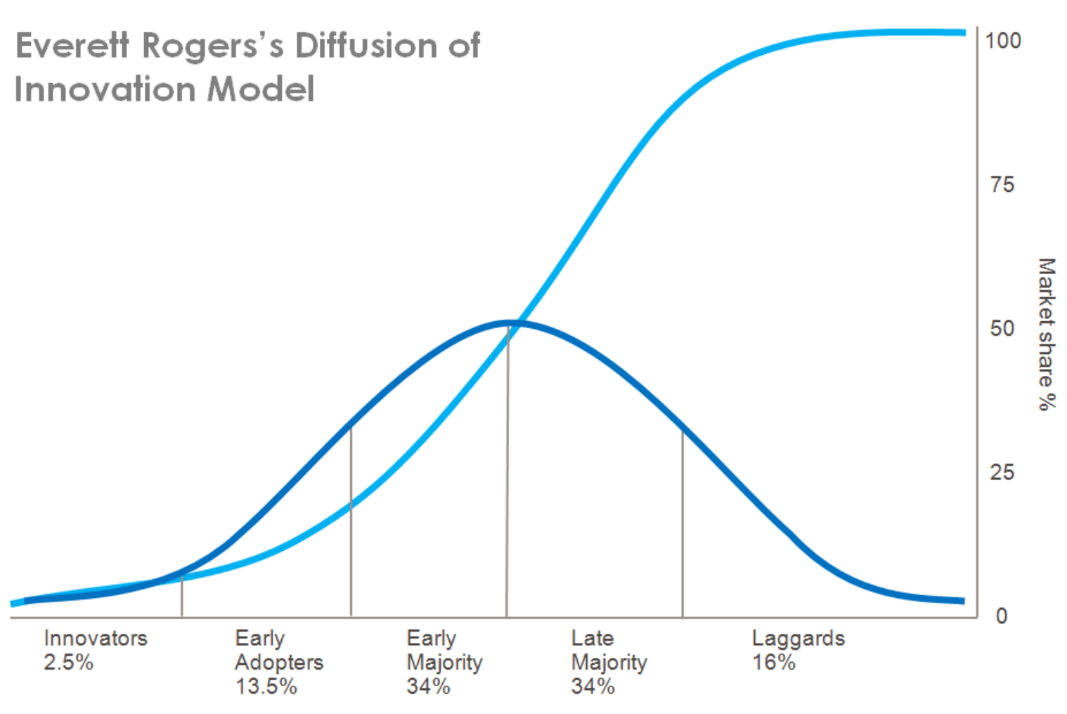
Только в последнем сегменте в основном боль и страдания..
Если посмотреть на график, то вещи вроде паттерн матчинга, лямбд, query-language в языках и асинк-авейт это Early majority, а то что я тут рассказываю — Early adopters. А у человека с опытом всегда преимущество.
Опять не совсем правильный подход. Эволюция ведь, как ни странно, всё ещё работает, то есть отбирает наиболее адаптированных к условиям обитания. Поэтому возникает интересный вопрос — а почему в нынешних условиях процветают индусы? А функциональные языки задвинуты куда-то в академии.
А где это они процветают? Среднестатистический индус очень несчастный человек.
Я читаю текст, который комментирую. А вы читаете? В моём сообщении было про неверно интерпретируемое название. И заметьте — это ещё цветочки. То есть что для полноты понимания вам стоит отказаться от всей документации и попробовать понимать чужой код по сигнатурам.
У меня есть знакомые которые так и делают. И очень успешно этим пользуются. По крайней мере были моменты, когда была либа с хренвой документацией (а я привык по ней работать), а они норм, по сигнатуркам поняли апи и погнали делать.
Для справки — aws lambda работает с разными языками, поэтому выделение из них исключительно функциональных говорит о вашей исключительной предвзятости.
То, что вы не поняли о чем идет речь не делает вам чести.
А решает, например, лёгкость освоения языка, ибо нужно много программистов, а где их взять?
Мне как программисту много программистов ни к чему. А возможность использовать удобный инструмент, чтобы не подгорать от использования неудобного инструмента, важна.
Наивно полагать, что, наняв программиста, его не придётся ничему учить.
Именно поэтому гуглы и придумали го, ибо им нужны миллионы индусов, которые задёшево и быстро освоят новый язык. Представьте себе, сколько времени займёт освоение хаскеля обычным индусом (из тех самых миллионов). Представили? Вот поэтому го идёт в массы, а хаскель тихо курит бамбук в академической среде.
А потом получим write-only код. Который выполняет заданную задачу. Но потом дешевле — его выкинуть и написать заново под новые условия, потому что индусы дешевые — пускай работают.
Ну, есть же state-of-the-art. Какое-то удовольствие от работ, помимо финансового, а еще и от технических решений (хороших). А с индусами все просто… Надо их нанимать, ставить им задачи, получать результат и жить на дельту (все так делают — чем мы хуже?)
Так не начну, в этом-то и суть :) Пока индусу "некогда" я подучу функторы, монадки, и напишу за день то, за что он запросил месяц. Вот и вся история.
Их просто больше. При этом как зарплата, так и продуктивность среднестатистического индуса на порядок ниже.
Ответьте на вопрос, вы себя считаете индусом в таком случае? Потому как я слышу явный посыл "го все как индусы, я создал"?
И при этом все эти необъятные орды конкурируют и с хаскелистами и со всеми остальными
Это ведь аргумент не в вашу пользу :) Необъятные орды конкурируют да все выиграть никак не могут, хаскельные проекты как были, так и есть. Только в этом треде несколько человек отметились с этим, я еще общался с чуваками из biocad и bank of america — чет они не торопятся переписывать на гошечку всё.
Я предполагаю, что Вы специально нарывались и вели себя… ну, эм, некорректно с переходом на личности. Собственно, и бросая тень на эти 99% народа. А теперь удивляетесь результату. Ну, ок. Что сказать.
На том мои комментарии на сегодня закончены, ибо угрюмые аутисты опустили мне карму ниже плинтуса
Как говорится, дело было не в бобине, да?..
Но я объективно смотрю на реальность и вижу в ней очень простой факт — миллионы индусов реально (и некоторые — много) зарабатывают на жизнь программированием.
Тут бы надо уточнить, что подразумевается под "индусами". Если кодеры с низкой квалификацией, то зарабатывают они не сказать чтобы много. И если дело дошло до конкуренции с ними, то надо что-то менять. И мне кажется, что браться за направление, которое успешно окучивает данная категория и при этом брать с них пример — не очень хорошая стратегия. Надо чем-то выделяться.
А то мне кажется, что ты это понятие как-то непонятно расширяешь. Если речь просто о мейнстримном направлении, то внутри него будут свои индусы, "элита" и что-то посредине. Возьмём, например, джаву: можно фигачить посредственный код пользуясь фреймворками и не особо разбираясь как оно внутри. А можно разбираться хорошо или даже писать эти фреймворки. Людей из последней категории я ну никак не могу отнести к "индусам", а хорошо зарабатывать будут как раз они.
Наличие библиотеки было бы недостатком сравнения если бы не одно но: вовсе не случайно в Хаскеле она есть, а в Go её нет. В Go подобная библиотека просто невозможна, вот в чём проблема этого языка.
Если кратко, то там используется библиотечная функция traverse, сигнатура которой невыразима в системе типов Go.
Если подробнее, то посмотрим как устроена функция traverse, используемая библиотекой:
class (Functor t, Foldable t) => Traversable t where
traverse :: Applicative f => (a -> f b) -> t a -> f (t b)Попробуем перенести на Go хотя бы некоторые из её зависимостей.
Вот есть Functor:
class Functor f where
fmap :: (a -> b) -> f a -> f bТут из типов данных видно, что функция принимает обобщенную структуру данных, функцию-обработчик и возвращает другой вариант той же структуры данных.
То есть на Go это могло бы выглядеть как-то так:
type FunctorIntString interface {
fmap(fn func(int) string) []string
}
func fmap(input []int) (fn func(int) string) []string {
output := make([]string, len(input))
for i, v := range input {
output[i] = f(v)
}
return output
}Только вместо int и string должны быть доступны любые типы данных. Без дженериков из go2 тут не обойтись.
Зачем такое необходимо? Ну вот возьмём простейшую реализацию traverse (только не надо приводить этот пример как пример сложности языка — это вообще-то часть стандартной библиотеки и прикладной программист никогда не будет писать подобный код):
instance Traversable [] where
traverse f = List.foldr cons_f (pure [])
where cons_f x ys = liftA2 (:) (f x) ys
...
liftA2 g y = (<*>) (fmap g y)Здесь x — это очередной элемент исходного списка. Над ним вызывается пользовательская функция f, после чего результат (являющийся любой структурой данных по выбору пользователя!) поэлементно прогоняется через функцию (:) (это конструктор списка).
Зачем пользователю нужна возможность самому выбирать структуру данных? Ну вот, например, чтобы этой структурой данных как раз и оказался тип Concurrently из библиотеки async. Если нельзя выбрать свою структуру данных, значит, нельзя подставить туда Concurrently, а тогда и библиотеки не будет.
Но на самом деле всё ещё хуже, и даже дженерики из go2 тут не помогут. Чтобы понять почему, смотрим дальше и замечаем конструкцию pure []. Какой у неё тип? Если принять тип f за Applicative F => a -> F b, то у pure [] тип будет F [b]. И если мы взглянем на сигнатуру pure...
class Functor f => Applicative f where
pure :: a -> f aто мы вообще не увидим f среди входных параметров.
То есть элементарная реализация traverse первым делом пытается построить выбранную пользователем структуру данных для одного элемента, причём в этой структуре будет храниться не выбранный пользователем тип данных, а другой! А у нас ещё даже нет ни одного экземпляра, у которого можно было бы через интерфейс вызвать хоть один метод.
Нет, нельзя, потому что она сама в себе всем рулит. Если вы хотите настраивать количество воркеров, то берете вместо этого расширение библиотеки async-pool, и там настраиваете всё, что надо.
Но разве мы постоянно меняем структуры в программе?
Думаю, если бы менять структуры было бы легко — вы бы делали это куда чаще.
Хаскель осмысленно стремится НЕ быть индустриальным языком, а оставаться языком академическим. Если вы хотите покататься на типосёрборде по типоволне, и при этом остаться с индустриальным (пригодным к продакшену) языком — используйте Rust.
А в чем эта академичность заключается, можно узнать? Я часто это слышал про хаскель, но вот на примере этой задачи (да и по отзывам знакомых) я не заметил каких-то проблем. Ну библиотек не 100 разных под каждую задачу на любой вкус и цвет, а только одна-две, то есть экосистема в этом плане бедновата, но всё, что нужно, вроде есть: жсоны парстить можно, в постгресы/монги ходить можно, веб-серверы поднимать можно, сваггер.жсон генерируется. Что еще нужно?
Если вы хотите покататься на типосёрборде по типоволне, и при этом остаться с индустриальным (пригодным к продакшену) языком — используйте Rust.
Раст в этом плане намного слабее. Когда завезут Const generics/GAT тогда еще что-то можно будет говорить. Но пока — увы.
Если вы говорите про "vs Java", то да, у хаскеля есть много (но не так много как у индустриальных языков, преимущественно в районе библиотек). Если вы говорите "vs C++/C", то ответ очевидный — GC и runtime. Я с трудом себе представляю программирование микроконтроллера на haskell, но вполне представляю — на Rust (речь не про extreme embedded, когда память в байтах считается, но про что-то умеренное, с сотнями кб).
С точки зрения же "vs Java" есть ещё одно "но" — иммутабельность. Да, можно встать на уши и написать без мутабельности, но на практике мутабельность полезна и удобна (особенно, если кто-то удерживает шаловливые ручки от комбинации мутабельности и sharing, привет ownership/borrow).
Понятно, что всегда можно откопать фичу, которой нет в языке и говорить, что без этого жизнь невозможна. Я, вон, до сих пор страдаю, что, казалось, бы, в таком богатом языке как Rust, и до сих пор нет питонового yield для конструирования замыканий. В реальности, для защиты проекта от глупых ошибок и принуждения программиста к clarity того, что он пытается написать, Rust более чем хорош. Особенно, если компилятор бъёт по ручкам и не позволяет сделать Странное из-за нарушения lifetimes.
Если вы говорите про "vs Java", то да, у хаскеля есть много (но не так много как у индустриальных языков, преимущественно в районе библиотек). Если вы говорите "vs C++/C", то ответ очевидный — GC и runtime. Я с трудом себе представляю программирование микроконтроллера на haskell, но вполне представляю — на Rust (речь не про extreme embedded, когда память в байтах считается, но про что-то умеренное, с сотнями кб).
Про микроконтроллеры речи не идет. Я про обычные прикладные задачи: жсончик распарсить, в монгу слазить, собственно вариация от того, что в статье показано. Понятное дело, что в случае реального приложения у нас куча контроллеров, разные апи, возможная персистентность на уровне приложения, кэши всякие, но принципиально суть остается той же.
Для МК конечно же никакие языки с ГЦ не годятся, берите раст, скорее всего не ошибетесь.
С точки зрения же "vs Java" есть ещё одно "но" — иммутабельность. Да, можно встать на уши и написать без мутабельности, но на практике мутабельность полезна и удобна (особенно, если кто-то удерживает шаловливые ручки от комбинации мутабельности и sharing, привет ownership/borrow).
А можно привести пример где шаред мутабельность это благо? А в случе не-шаред в том же хаскелле одно от другого не отличается (если компилятор увидит, что старая копия не используется, он может мутацию инплейс, для простых случаев хорошо работает).
Понятно, что всегда можно откопать фичу, которой нет в языке и говорить, что без этого жизнь невозможна.
Ну, мне очень не хватает асинк-авейтов (я попробовал ночную альфа-верси гипера, и по документацию построить рабочий пример не очень получилось), да и копи-паста в той же стандартной библиотеке расстраивает. Реализуй они do-нотацию изначально (хотя бы Ad-hoc, как в C#), то ушла бы куча копипасты из стд реализаций Option/Result/Iterator/Future/..., не нужно было бы делать отдельно ?, async/await и так далее.
Раст прекрасный язык, если вам нужна производительность или ограниченные ресурсы системы. Когда у вас 4 гига оперативки и нужно пользователям лайки апдейтить то есть варианты поинтереснее в плане простоты и качестве разработки.
База данных, кеш — это разделяемая мутабельность. Пока приложение может делегировать всю разделяемую мутабельность в удаленную базу данных и использовать для кеширования только удаленные сервисы типа Memcached/Redis, все хорошо. Но иногда надо подтянуть изменяемое состояние прямо в память приложения.
Распространенность (и оправданность) этого "иногда", скорее всего, сужается, с распространением микросервисов, serverless, и быстрых in-memory баз данных.
С другой стороны, разделяемая мутабельность в Haskell есть, но, возможно, с достаточно плохой конкурентностью. Впрочем, то же самое можно было сказать про Go вплоть до версии 1.9, и не то что бы люди очень сильно страдали без этого инструмента. Класс задач, где хорошая конкурентность разделяемой мутабельности критична, очень узок.
Спасибо за замечание. Я сейчас понял что stm-containers использует hash trie, это решение действительно должно хорошо скалироваться.
Но это не та же разделяемая мутабельность, что, условно, в тех же плюсах (или в Go, насколько я могу сделать вывод из исходного поста и всей этой дискуссии). У вас нет способа одновременно из двух потоков что-то там поменять.
А должна быть?) Поменять одну и ту жу ячейку памяти из двух потоков одновременно это чистая гонка.
Ну, мне очень не хватает асинк-авейтов (я попробовал ночную альфа-верси гипера, и по документацию построить рабочий пример не очень получилось), да и копи-паста в той же стандартной библиотеке расстраивает. Реализуй они do-нотацию изначально (хотя бы Ad-hoc, как в C#), то ушла бы куча копипасты из стд реализаций Option/Result/Iterator/Future/..., не нужно было бы делать отдельно ?, async/await и так далее.
async/await, Option, Iteration — звучат как фичи которые хорошо сделаны в Kotlin. Смотрели в сторону Kotlin/Native?
Котлин мне совсем не интересен, потому что это просто Better Java. Он уменьшает всякий бойлерплейт всяким сахаром, но принципиально ничего не меняет, сахара мне и в C# хватает, неделю назад еще чутка подсыпали :). Вот Scala другое дело. У меня в планах использовать Haskell для изучения концепций ФП и потом тащить скалу в прод. Но это пока так, прикидки на будущее.
"Числодробильность" задачи это не бинарное свойство, а градиент. Есть задачи которые можно назвать числодробилками и с которыми справятся и Rust, и Java, со скоростью не ниже чем С/С++ (в отдельных случаях — выше).
Есть еще одна подобласть — написание баз данных. Как раз-таки не попадает ни туда, ни сюда. Я думаю, сейчас Rust — это наиболее оптимальный выбор, особенно когда туда завезут рантайм-кодогенерацию.
А чем микроконтроллеры не угодили? =) занимаемся как раз этим на хаскеле, хард реалттайм, экстрим эмбедед (памяти чуть больше байтов)
Во первых, хаскель осмысленно стремится не жертвовать чистотой ради кратковременной выгоды, не более. Во вторых, во всём, что касается типов, хаскель нынче уже давно не на острие прогресса.
Язык — это не только bnf и лямбды, но и ещё масса lore. Из простейшего — нет поддержки приватных репозиториев артефактов (приватного hackage), нормального offline-режима (даже gradle разродился!). Библиотеки тоже не совсем enterprise-grade, особенно по мере приближения к SOAP'у. Я сходу ткнулся — gtk всё ещё на второй версии только.
Нет блокировки вендореных версий (Cargo.lock), про удовольствие от TH можете сами рассказать.
Хорошие замечания, спасибо.
>Какой язык показал себя лучше?По моему вывод из этой статьи — C# — он позволяет писать и ФП, как показано, и
Я взял задачу, которая мне показалось одновременно достаточно простой, но при этом интересной, и затрагивающий сильные стороны одной парадигмы (работа с деревьями) и другой (удобная асинхронность и гринтреды). И мне результат не был очевиден. Я думал я получу 100 строк на го раза в 2 быстрее, чем на хаскелле, и написал бы "ну, тут 100 строк кода, но зато смотрите как быстро. При изменении требований можно выкинуть и за еще 10 минут получить 100 новых строк с нужными правками", а вышло немного по-другому.
По моему вывод из этой статьи — C# — он позволяет писать и ФП, как показано, и императивно, и быстро и беспроблемно. Можно бы добавить в голосовалку.
Я шарп хорошо знаю, а два других языка — нет, поэтому мне показалось, что это будет несправедливо по отношению к ним.
Так. Работа с деревьями удобна в ФП. Конкурентность и параллельность — это тоже удобно в ФП. А для чего же тогда удобно ИП, кроме того, чтобы быструю сортировку написать?
Вычислительная математика (перемножения матриц, решения СЛАУ), игры, компьютерная графика, обработка сигналов, вычисления в ограниченной памяти.
Тут всё же надо признать, что мутабельность важна, но с точки зрения заблаговременной защиты от ошибок, мутабельность не должна быть по умолчанию. (Вот как в современных языках, вроде Раста или Хаскеля)
Вы шутите? Вы перечислили именно те области, где голанг отсутствует и никогда не выстрелит.
Его удел — это тулинги и сетевые сервисы. Все. Никто не будет на нем писать большие проекты вроде комп. игр, тем более, что там есть свои уже устоявшиеся подходы и фреймворки. Голангу также заказана дорога в ускорение на гпу.
Я уж не говорю, что Golang — пример фреймворков с GC. Поэтому это точно не про быстродействие (по крайней мере, не больше — чем java).
Перечитывал комментарии, и решил подчеркнуть один момент:
Автор тяготеет к ФП, имеет опыт с Хаскелем и C# и в первый раз видит 100% императивный Go. Результат очевиден.
Мой опыт ФП ограничивается написанием LINQ-запросов в шарпе и реализации некоторых задачек из книжки по теории категорий. Хаскель, как и го, я видел первый раз в жизни (хотя и слышал о них разную априорую информацию вроде строго компилятора Haskell и неконфигурируемого gofmt), и считаю что они были в достаточно равных условиях. Особенно, если учесть, что на го мы писали уже имея на руках решение на Haskell, и немного лучше представляя себе пространство решений.
Да и решается задача скорее фронтенда, в то время как Го — бекэндный язык
Давайте еще задачи бить на фронтовые и бекендовые? Что это значит в Вашем понимании? Сервис, который отдает данные в виде единого блоба на клиент — тоже вполне себе бекенд. Ну, и сила Java/Haskell etc. в том, что они вполне позволяют ваять stand-alone приложение (но это тоже вне разделения на front / back).
В моем окружении, по крайней мере, в применении к веб-разработке — фронт — это то, что у пользователя в браузере выполняется на JS...
ну, если так рассуждать, то Java, python anything else на "фронте" — т.е. то что выполняется на сервере, но отдает данные юзеру (или приложению у юзера — будь то веб-приложение в браузере, андроид или мак). И в таком ключе Java, python anything else тоже прекрасно работают ) Вы сами-то на чем программируете?
Ну насколько я помню по комментариям, достаточно устойчивый интерес к Хаскелю подразумевает предварительную, возможно только теоретическую, подготовку.
Подготовку какого плана? Ну знаю я то такое функтор, это в рамках раста вот такой вот трейт
pub trait Functor<_> {
fn map<T, U, F>(self: Self<T>, map: F) -> Self<U>
where F: FnOnce(T) -> U;
}и реализуем его например для типа Option:
impl Functor<_> for Option<_> {
fn map<T, U, F>(self: Self<T>, map: F) -> Self<U>
where F: FnOnce(T) -> U {
match self {
Some(x) => Some(map(x)),
None => None
}
}
}Ну так эта функция в рамках стд либы живет, просто к трейту не привязана, и теперь и вы тоже знаете, что это. А теперь скажите, насколько оно релевантно статье и какие преимущества это дало? Насколько я помню по статье, вопросы в гугл, там ничего не было "как работать с функторами в хаскелле", там было "смаппить одно дерево на другое", и попытка взять первое решение со stackoverflow, а работа с map на массивах/слайсах/… у любого разработчика включая даже низкоуровневые типа С++ в крови. Мне кажется, это не самая сложная задача для умных людей, которыми программисты ИМХО являются.
В чем подготовка заключается можно узнать? В том что я чуть-чуть в математике разбирался (топологический раздел алгебры по сути)?
Вот только непонятно, чего же барину не хватает в С#? Хаскель, Раст и Го ему не замена.
В знании синтаксиса и понятий Хаскеля.
Так я их и не знал.
И в стремлении использовать ФП куда надо и куда не надо.
А куда не надо?
А ответ на вопрос таки будет?
map2 (+) Just 5 Just 10 и получить Just 15. В сишарпе мне придется писать a.HasValue && b.HasValue ? a.Value + b.Value : null. Это часто неудобно. Любые не-инстанс методы через null-propagation прокинуть нельзя. В примере это оператор +, но примеров намного большеМне не хватает гибкости решений, в частности интерфейсы не могут содержать статических членов. Нахрена это нужно? Ну например для такого случая
interface IParseable<T>
{
static T Parse(string value)
}
T ReadFromConsole<T>() where T : Parseable<T> => T.Parse(Console.ReadLine();Array<T> наследуется от IList<T>, но каждый второй метод бросает NotSupportedException, это вообще что такое?), а из-за того как работают интерфейсы в ООП это не исправить. С тайпклассами старую иерархию можно было бы задеприкейтить и сделать новую, не сломав никакого кода....
Я могу продолжать еще долго. Вам хватит причин, или нужны еще?
Ну, нулы занимают всё же не так много места. Как правило, операции над ними всё равно сводятся либо к арифметическим, либо к вызовам методов.
Да и исключения тоже не проблема. В любом нетотальном языке есть возможность не вернуть никакого значения из функции, и Раст с Хаскелем — не исключения.
Вот пунктов 3 и 5 правда порой не хватает.
Ну, нулы занимают всё же не так много места. Как правило, операции над ними всё равно сводятся либо к арифметическим, либо к вызовам методов.
Да ладно вам. Вот я щас открыл случайный микросервис и нашел там такое
var state = route == null
? null
: new RoutePointActorState(route.HubInfo.HubId);или вот
if (createdOn.HasValue)
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(
"CreatedOn",
createdOn.Value.ToString("yyyy-MM-ddTHH\\:mm\\:ss.fffffffZ"));И таких случаев очень много, учитывая, что конструктор нельзя как method group использовать, что вывод типов на нем не работает, и тд и тп.
Да и исключения тоже не проблема. В любом нетотальном языке есть возможность не вернуть никакого значения из функции, и Раст с Хаскелем — не исключения.
Вопрос в идеологии языка. В хаскелле я могу условно линтер настроить или на ревью не пропустить код который плохо себя ведет. В сишарпе же я бы хотел, но не могу, потому что все библиотеки так работают. О чем говорить, когда отмена таски в языке реализуется через проброс эксепшна) А потом лови, то ли TaskCancelledException, то ли OperationCancelledException, то ли AggregateException ex when (ex.InnerException is TaskCancelledException),… Ну это же ужас просто.
Да ладно вам. Вот я щас открыл случайный микросервис и нашел там такое
Это один раз встречается или в каждом микросервисе / в каждом методе? В первом случае пофиг, во втором случае надо просто метод-расширение сделать.
А потом лови, то ли TaskCancelledException, то ли OperationCancelledException, то ли AggregateException
Ловить надо, конечно же, OperationCanceledException — ведь TaskCancelledException его наследник. А внутри AggregateException никакого TaskCancelledException оказываться не должно, если оно там вдруг есть — это уже где-то в коде баг.
Это один раз встречается или в каждом микросервисе / в каждом методе? В первом случае пофиг, во втором случае надо просто метод-расширение сделать.
Ну я не берусь судить, но я думаю на 500-1000 строк кода оно встречается хотя бы раз. Выносить в метод смысла нет, потому что каждый раз используется в единственном месте, где-то RoutePointActorState, а где-то какой-нибудь RoutePointsState
Ловить надо, конечно же, OperationCanceledException — ведь TaskCancelledException его наследник. А внутри AggregateException никакого TaskCancelledException оказываться не должно, если оно там вдруг есть — это уже где-то в коде баг.
Принимаю. Но на практике я встречал кучу либ, которые в AggregateException, всякие TimeoutException и пр. В общем, для меня это проблема. И еще хуже, что изменение чистой функции которая была тотальной на частичную с эксепшнами не является ошибкой компиляции.
думаю на 500-1000 строк кода оно встречается хотя бы раз
Так это совсем не напрягает. Я же всё-таки не с телефона программу пишу...
Нет, мне нравится когда Option/Maybe получает общеязыковую поддержку монад. Но именно как побочный эффект существования этой самой поддержки, в качестве основной причины существования монад в языке Option/Maybe не подходит никак.
И еще хуже, что изменение чистой функции которая была тотальной на частичную с эксепшнами не является ошибкой компиляции.
Но тут только Идрис поможет.
Так это совсем не напрягает. Я же всё-таки не с телефона программу пишу...
Ну, я не говорю что это киллерфича. Просто неудобство. Киллерфича это расширяемость снаружи, хкт и вот это все.
Но тут только Идрис поможет.
Да не обязательно, в расте T -> Result<T> это ломающее изменение.
Так и в C# возвращаемый тип поменять — ломающее изменение. Но прямой аналог исключения — паника. Добавление паники в метод — не ломающее изменение.
Ну я об этом и говорю. Ошибки которые производит функция не являются частью сигнатуры (результата) метода. шарпы не разделяют по сути ошибки и паники, и то и то работает через эксепшны. Я не встречал распространенных библиотек которые бы использовали что-то кроме исключений для обработки ошибок, даже ожидаемых. Пример с OperationCancelledException показателен. Никому в расте в голову бы не пришло делать это паникой. Поэтому если мы раньше не могли отменять, а теперь отменяем, то это ломает код и мы должны прокинуть обработку отмены. А в сишарпе найти все места где нужно было бы обрабатывать это намного более нетривиально.
Лучше го вспомните. Как я понимаю, там либо паника (и приплыли), либо передача кодов ошибок по всему стеку вызова (а-ля как было в Си и раннем С++). Лучше уж эксепшены — ей Богу.
Ну так и в расте то же самое. Но у раста есть два больших преимущества:
?.В итоге у вас действительно значение передается по всему стеку, но это не плохо, а хорошо. Теперь замена функции с ошибочной на чистую позволит вам убрать все лишние проверки, которые захламляют код. А обратная замена заставит проверить там, где теперь значения может и не оказаться.
Вот, можно поиграться с примером: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=46b43cd318ffb17f0b6b92f3132123cc. В данном случае ошибка (в нашем примере, число больше десяти) прокидывается по всему стеку вызовов main -> d -> c -> b -> a, но это не накладывает никаких неудобств.
Ну например вот так
На самом деле в реальности даже так так никто не будет делать. Вы сделаете свою ошибку AppError, и будете просто в неё конвертировать автоматически. Например вот.
С макросами рутину всегда легко автоматизировать. И протестировать вещи до того, как они попадают в язык. Удобный отстойник + возможность реализовать то, что в языке еще нет (например, в статье про раст мы за 5 минут реализовали шарповый nameof)
В Rust любая функция может запаниковать, с другой стороны.
(синхрон)
int ?a = null;
int ?b = 4;
var x = a + b;
Console.WriteLine("Hello World {0}", x);
if (!x.HasValue) Console.WriteLine("Hello Null World {0}", x);
Вы правы, не знал, что они арифметику реализовали. Ну давайте возьмем вот такой случай:
long? ticks = ...;
var timespan = ticks != null ? TimeSpan.FromTicks(ticks) : null;при этом в расте
let ticks = ...;
let timespan = ticks.map(TimeSpan::FromTicks);С одной стороны мелочь. А с другой раздражает очень)
Еще прикольная штука в расте, условная реализация. Например:
struct Option<T>;
impl Ord<T: Ord> for Option<T> {...}
impl Eq<T: Eq> for Option<T> { ... }То есть мы определяем равенство и сортировку для типа, если его внутренний тип тоже определяет этот трейт.
теперь возьмем шарп:
class Option<T> : IComparable<T>, IEquitable<T> {}Если мы напишем так, то не сможем создать Option<object> например, потому что он не реализует эти трейты. А сделать сортировку на них хотелось бы...
В случае этих интерфейсов большинство функций выполняющих сортировку принимают IEqualityComparer/IComparer, но для кастомных интерфейсов их может и не оказаться.
Во-первых, раздражение при наборе пары лишних букв это не повод претензий к языку. Читаемость и надежность не страдают.
Страдают, особенно если у вас 2-3 аргумента нуллябельных.
Да я и признался, что это не киллер-фича, а небольшое неудобство. Можете его проигнорировать.
Во-вторых я не понимаю, Раст не тема статьи и не тема обсуждения в этой ветке. Какого х вы на него постоянно съезжаете??? Что там проблемного с этим (nullable/ADT) в Го и Хаскеле?
Ну вот что вы так сразу, нормально же общались.
Проблем с АДТ в хаскелле нет, а в го просто их нет. Собственно, и в шарпах нет.
В третьих, при разворачивании нуля в расте получим панику, что еще хуже, чем исключение в С№. Или пишем аналогичные лесенки матчей. Прикольно, но не более.
Покажите лесенки матчей в примере выше, пожалуйста? Result можно заменить на Option без изменения кода.
В С№ есть нормальное наследование т.ч. с интерфейсами и методы расширения. Не хватает?
Я вроде бы уже говорил, что не хватает, и даже по пунктам перечислил, чего конкретно.
Если вы краулите интернет то у вас нет возможности получить всё. Как пример задачки, у вас на входе список урлов, а на выходе HTML каждой страницы.
Может быть куча причин, почему нужно делать N+1 запрос. Если это ваша апишка и дергается много данных то офк надо агрегировать. Но это не всегда кейс.
Но менее известно, что в высокоуровневых языках это Haskell. В Scala/F#/Idris/Elm/Elexir/… тусовках если не знаешь, на чем пишет твой визави — пиши на хаскелле, не ошибешься.
Честно говоря, я не вижу особых преимуществ F# над C#, а проблем с компилятором и коммьюнити у него хватает. Одни только АДТ не повод мигрировать с одного языка на другой, тем более что с новым паттерн матчингом можно их достаточно удобно эмулировать на шарпах. Коммьюнити же у F# на любые фич реквесты говорит "не нужно". Ну как так что хкт не нужно в фп языке? А они в это верят.
Отличная статья, буду на неё теперь ссылки давать. Мне бы терпения не хватило с Go мучаться.
Спасибо, как раз ваша задача и вопрос стали причиной появления этой статьи. Чуть больше 30 часов чистого времени и 80 ревизий (согласно гиту), но результатом я очень доволен.
Хаскель мне очень понравился. Нужно изучать его дальше, наверняка еще какие-то чудеса обнаружу.
Нет, он правда долго качает и собирается. Скорее всего он тупил потому что у меня было запущено 2 студии и 3 идеи, которые дрались за CPU, но вообще он нетороплив.
С другой стороны есть вероятность что это у хаскелля репозиторий тупил и медленно отдавал зависимости. Хотя какая разница, если результат один?
Я поэтому и указал на эти моменты, потому что я старался быть максимально объективным. Долгая первоначальная компиляция — имеет место быть, если тащить это в какой-то реальный прод то надо подходить к кэшированию зависимостей на CI с умом.
Все правильно написано. Очень четко пояснена проблема программ на голанге — вроде бы все красиво, вроде все должно работать, а в рантайме ломается. Чертова конкурентность )
Do not communicate by sharing memory; instead, share memory by communicating.Я бы, наверное, описанную задачу решал так: не запускал горутину на каждую запись, а создал пул воркеров с входными и выходными каналами, во входной пихал айдишники, с выходного сваливал результаты в мап, потом закрыл входной чтоб воркеры закончились, а из мапа по-новой построил дерево. Никаких блокировок или гонок.
Код напишете, чтобы мы восхитились Вашим владением голанга? Было бы очень здорово — это позволило нам привить себе правильные привычки написания многопоточных программ.
Но тут вы создаете по дополнительному каналу на каждом узле. Вряд ли это даст какое-то улучшение...
func loadComments(root intTree) map[int]comment {
var wg sync.WaitGroup
result := make(map[int]comment)
in := make(chan int)
out := make(chan comment)
nWorkers := 2
for i := 0; i < nWorkers; i++ {
go func() {
for id := range in {
out <- getCommentById(id)
}
}()
}
var loadCommentsInner func(node intTree)
loadCommentsInner = func(node intTree) {
for _, c := range node.children {
loadCommentsInner(c)
}
wg.Add(1)
in <- node.id
}
go func() {
for c := range out {
result[c.Id] = c
wg.Done()
}
}()
loadCommentsInner(root)
close(in)
wg.Wait()
close(out)
return result
}
А, ну это ж нечестно, вы сделали мапу :) Хотя бы код собирания дерева обратно если бы добавили то стало бы понятнее. Красота траверсабла в том и заключается, что он позволяет автомагически собрать оригинальную структуру, ничего априорно про неё не зная. Полагаю, это одна из причин, почему 0xd34df00d придумал именно эту задачу.
type Futurer interface {
Await() interface{}
}
type future struct {
await func() interface{}
}
func (f future) Await() interface{} {
return f.await()
}
func WhenAll(f func(intTree) commentTree, v []intTree ) Futurer {
l := len(v)
var result = make([]commentTree, l)
var wg sync.WaitGroup
wg.Add(l)
for i := 0; i < l; i++ {
i := i
go func() {
result[i] = f(v[i])
wg.Done()
}()
}
return future{
await: func() interface{} {
wg.Wait()
return result
},
}
}
func GetCommentsTree(tree intTree) commentTree {
children := WhenAll(GetCommentsTree, tree.children)
var value = getCommentById(tree.id)
var childrenResults = children.Await().([]commentTree)
return commentTree{ value, childrenResults }
}
Но это же снова создание горотины из другой горотины! Ровно то, от чего пришлось отказаться автору, потому что планировщику кирдык наступал...
Ну так просто замените intTree на interface{} и всё. Ничего умнее без дженериков сделать всё равно не получится.
func WhenAll(f interface{}, s interface{} ) Futurer {
v := reflect.ValueOf(s)
fn := reflect.ValueOf(f)
if reflect.TypeOf(s).Kind() != reflect.Slice {
panic("not slice")
}
if reflect.TypeOf(f).Kind() != reflect.Func {
panic("not func")
}
if reflect.TypeOf(f).In(0) != v.Type().Elem() {
panic("wrong arg type")
}
l := v.Len()
var result = reflect.MakeSlice(reflect.SliceOf(reflect.TypeOf(f).Out(0)), l, l)
var wg sync.WaitGroup
wg.Add(l)
for i := 0; i < l; i++ {
i := i
go func() {
in := []reflect.Value{v.Index(i)}
result.Index(i).Set(fn.Call(in)[0])
wg.Done()
}()
}
return future{
await: func() interface{} {
wg.Wait()
return result.Interface()
},
}
}
А что там со скоростью такого кода?
Как хорошо, что существуют языки кроме Go обладающие такой же фишкой. Например хаскель, в котором гринтреды в отличии от Go умудряются нормально сосуществовать с FFI.
type Comment struct {
ID int // задано
Contents string // заполняем сами
Children []*Comment // задано
}
func loadComments(root *Comment) {
var wg sync.WaitGroup
loadCommentsInner(&wg, root)
wg.Wait()
}
func loadCommentsInner(wg *sync.WaitGroup, node *Comment) {
wg.Add(1)
go func() {
// не факт, что можно просто так заполнять поля произвольной структуры
// из любой горутины, но вроде можно
node.Contents = loadCommentContentsByID(node.ID)
wg.Done()
}()
for _, c := range node.Children {
loadCommentsInner(wg, c)
}
}
Странно, что вы не взяли мой вариант из комментария, который упомянули в начале статьи
Ой, прошу прощения, я изначально не помню, почему не взял ваш вариант сразу, а потом совершенно вылетело из головы. Скорее всего потому, что я изначально хотел строить дерево в каждом узле отдельно + хранить дерево айдишек от дерева комментариев раздельно.
Если теперь вам нужно будет ограничить конкурентность, например (совершенно точно нужно будет, если будете делать что-то похожее в продакшене), то уже становится интереснее с тем, как это будет выглядеть в Хаскеле.
Очень интересный вопрос, пожалуй сегодня вечером посмотрю, как это может выглядеть. В идеале если это будет отдельный комбинатор типа limit . mapConcurrent getCommentById tree, но скорее всего вместо mapConcurrent должна быть другая функция, принимающая целочисленный аргумент ограничения.
Если нужна обработка ошибок (она всегда нужна), то код тоже усложняется.
Отличный вопрос, и ответ на него — монадический трансформер ExceptT. К сожалению я кроме названия не знаю, как оно работает, но могу постараться почитать документацию.
Плюс нужно логирование
монадический трансформер WriterT
Плюс нужно логирование, плюс походы в RPC, и т.д., и неожиданно получается, что код на Go не такой уж и сложный по сравнению с другими языками, хотя и да, Go не пытается сделать работу с конкуретностью полностью тривиальной.
Ну так, давайте я допишу свой пример с использованием этих штук, вы свой, и сравним. В го же я тоже сделал panic на ошибке ;)
Ну и, самое главное — автор комментария пример явно выбрал не случайно
Ну, я подумал, что в данном случае будет паритет по фишкам: абстрактные структуры данных (дерево в haskell) против удобной асинхронности (горутины в го).
В любом случае, ваш опыт интересен, спасибо за статью :).
Рад, что вам понравилось.
Кстати, вспоминая статью "Какого цвета ваша функция", в го тоже функции разных цветов. Вот эта — синяя: func loadComments(node intTree) commentTree
А вот эта — красная: func loadComments(resNode *commentTree, node intTree, wg *sync.WaitGroup)
--
Ну вот, пока писал за меня уже все ответили...
Кстати, вспоминая статью «Какого цвета ваша функция», в го тоже функции разных цветов. Вот эта — синяя: func loadComments(node intTree) commentTree
А вот эта — красная: func loadComments(resNode *commentTree, node intTree, wg *sync.WaitGroup)
Необходимо построить новое дерево, аналогичное исходному, узлами которого вместо идентификаторов являются десериализованные структуры соответствующего API, и вывести его на экран. Важно, что мы хотим грузить все узлы параллельно, потому что у нас каждая для каждой ноды выполняется медленное IO и естественно их делать одновременно.
Действительно, в такой постановке задача тяжело решается на Go, где мутировать состояние более привычно, чем выражать алгоритм через иммутабельные преобразования.
Если разрешить мутировать изначальное дерево (что бы сделали большинство разработчиков на этом языке), то получается немного проще:
type Tree struct {
ID int `json:"-"`
Comment string `json:"comment"`
Childs []*Tree `json:"-"`
}
func (t *Tree) Traverse(fetchers chan<- *Tree) {
fetchers <- t
for _, tt := range t.Childs {
tt.Traverse(fetchers)
}
}
func (t *Tree) Fetch() {
resp, err := http.Get("http://jsonplaceholder.typicode.com/todos/" + strconv.Itoa(t.ID))
if err != nil {
panic(err)
}
defer resp.Body.Close()
if err = json.NewDecoder(resp.Body).Decode(t); err != nil {
panic(err)
}
}
func fetchAll(t *Tree, concurrency int) {
trees := make(chan *Tree)
go func() {
t.Traverse(trees)
close(trees)
}()
wg := new(sync.WaitGroup)
wg.Add(concurrency)
for i := 0; i < concurrency; i++ {
go func() {
defer wg.Done()
for f := range trees {
f.Fetch()
}
}()
}
wg.Wait()
}У меня сложилось впечатление, что автор статьи был изначально несколько предвзят к Go, как и автор постановки задачи. В ответ я бы предложил дополнить постановку задачи следующим образом:
Мое решение на го я выложил на гитхаб: ernado/traverse. Получилось 167 SLOC с тестами, но я особо их не пытался экономить, и заодно реализовал задачу как cli утилиту:
$ ./traverse -j 1 --timeout 30ms
Failed: Get http://jsonplaceholder.typicode.com/todos/3: context deadline exceeded
1=delectus aut autem
2=quis ut nam facilis et officia qui
3=
4=
5=По ^C как раз происходит отмена в соответствии с п.3., опция j отвечает за ограничение параллельных запросов, а timeout указывает глобальный таймаут.
UPD: Забыл про п. 6, дополнил п. 5 комментарием
Не получается, так как дерево ID'шников и дерево комментариев — это вообще разные типы. И смешивать их (как в вашем примере) — плохая идея, потому что теперь компилятор не даст мне по рукам, если я случайно полезу доставать текст комментария в дереве, которое не было «материализовано».
В го стараются работать с данными, а не типами, и большинство решений — ad-hoc, поэтому и такой подход. Возможно с вводом контрактов (aka дженерики) это частично исправится.
В смысле, что именно протестировать?
Ну у нас есть кусок кода, который загружает дерево комментариев. Хочется, чтобы рядом был тест, который его запускает, но вместо сети ходит в мок. У меня в репозитории есть пример.
Вот это — единственное, что потребует не совсем тривиальных изменений исходного кода. Будет дерево с узлами типа Maybe Comment вместо Comment в STM + набор потоков, которые в него пишут.
Круто. Мне действительно интересно, как это будет выглядеть в реальном коде на Haskell и C#.
Сейчас мой вариант на Go относительно прост, но там есть спорные места — ограничение на макс. глубину дерева (из-за отсутсвия TCO, впрочем, мб можно убрать рекурсию) и потенциальный data race (всё же мутировать дерево во время обхода по нему — тот еще веселый аттракцион).
. А вот если бы эта зависимость, которую нужно внедрять, была бы чуть менее тривиальна, и одной-двумя функциями не ограничивалась, то можно было бы просто добавить ещё один уровень в монадный стек — теперь у нас бы была монада для делания запросов.
Что-то мне это напоминает… А! Точно! Заборы декораторов из питона.
Ну так это же не что-то хорошее. По крайней мере, я бы даже на плюсах как минимум хранил бы дерево с узлами из std::variant<Id, CommentBody>, как максимум оно точно так же было бы параметризованное.
Эх, опередили. Я тоже хотел упомянуть про С и С++ именно в этом ключе. А потом плакаться про рефлексию в рантайме. Этого в голанге нет и не нужно туда это тащить — взращивать очередного монстра.
Ну так это же не что-то хорошее. По крайней мере, я бы даже на плюсах как минимум хранил бы дерево с узлами из std::variant<Id, CommentBody>, как максимум оно точно так же было бы параметризованное.
А я бы и не сказал, что это однозначно плохо :)
А, ну можно совершенно аналогично передавать функцию для запрашивания комментов
У меня можно подменить HTTP клиент, т.е. запрос -> ответ. Но смысл я понял, спасибо.
Вот за это мы STM и гарантии компилятора и любим.
Очевидно, что у всего есть цена. А еще было бы замечательно, если бы STM реализовали на уровне железа. В итоге приходим к тому, что у го есть свои трейдоффы, как и у всех ЯП.
На мой взгляд топикстартеру просто "повезло" начать с задачи, оказавшейся нетривиальной для новичка в го.
Вы абсолютно правы про тесты. На голанге действительно тесты являются неотъемлемым этапом написания кода и сам язык это Форсит.
PsyHaSTe, Вы сравнивали именно, что не сам язык, а все в пакете — включая экосистему языка? Может в ней то самое, что вытягивает голанг на невиданные высоты? Или нет ?
Круто. Мне действительно интересно, как это будет выглядеть в реальном коде на Haskell и C#.
Сейчас мой вариант на Go относительно прост, но там есть спорные места — ограничение на макс. глубину дерева (из-за отсутсвия TCO, впрочем, мб можно убрать рекурсию) и потенциальный data race (всё же мутировать дерево во время обхода по нему — тот еще веселый аттракцион).
К сожалению, я не настолько крут, чтобы забацать решение на хаскелле, как и было выше написано, мой опыт работы с языком пара часов. Я знаю только то, что для решения проблемы моков в функциональных языках используют MTL парадигму, тогда вместо любой монады которая у вас используется (например, ходит в сеть) вы используете Id-монаду (которая ничего не делает, просто контейнер с константным значением), и это и будет ваш мок.
В случае сишарпа чтобы добавить мок достаточно отнаследовать HTTP хандлер и передать в конструктор:
class TestHandler : HttpClientHandler
{
// мокаете ответ как хотите. Например, вставляем исскуственную задержку для третьего случая, но можно делать в общем случае что угодно
protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
if (request.RequestUri.PathAndQuery.EndsWith('3'))
{
await Task.Delay(5000, cancellationToken);
}
return await base.SendAsync(request, cancellationToken);
}
}
...
private HttpClient HttpClient = new HttpClient(new TestHandler());Ну а для отмены достаточно зарегистрировать обработчик, который отменит задачу, ну и сделать возвращаемый тип опциональным, чтобы показать, что значения может и не быть:
private static async Task Main()
{
var timeout = TimeSpan.FromMilliseconds(500);
HttpClient = new HttpClient(new TestHandler());
var cancellationTokenSource = new CancellationTokenSource(timeout);
cancellationTokenSource.Token.Register(() => HttpClient.CancelPendingRequests());
var tree = Tr(1, new[] { Tr(2), Tr(3, new[] { Tr(4), Tr(5) }) });
PrintTree(tree);
var comment_tree = await GetCommentsTree(tree);
PrintTree(comment_tree);
}Скомбинировав оба варианта, получим, что №3 никогда не загрузится:
1
2
3
4
5
1 - delectus aut autem
2 - quis ut nam facilis et officia qui
4 - et porro tempora
5 - laboriosam mollitia et enim quasi adipisci quia provident illum
C:\Program Files\dotnet\dotnet.exe (process 16704) exited with code 0.https://gist.github.com/Pzixel/e882d6653937843b4fd412053bb69489
По пунктам:
Без аллокации нового дерева
Как было сказано, дерево загруженное и незагруженное отличаются кардинально, поэтому они обязаны быть различными на уровне типов чтобы исключить ошибку. Сколько раз я ловил NullReferenceException потому что "ну значение точно должно быть" не берусь даже считать. Второй по частоте KeyNotFoundException "ну этот ключ в мапе ну точно должен быть".
Возможность контроля количества параллельных запросов
var handler = new TestHandler(){MaxConnectionsPerServer = 5}
Возможность отмены обхода по дереву в любой момент, но с сохранением уже полученных данных (т.е. частичный ответ)
Написал в ветке выше + Console.CancelKeyPress += (sender, e) => cancellationTokenSource.Cancel();
Глобальный таймаут на обход, после которого он заверашется с ошибкой
Написал в ветке выше
Возможность протестировать взаимодействие по HTTP (т.е. "замокать" поход в сеть, оставив всё остальное)
Написал в ветке выше
Отмена обхода после первой ошибки загрузки/десериализации данных (такая же, как в п.3)
Вместо AggregateException в примере выше указать типы исключений, которые хотим ловить.
Всё это касается сишарпа который я знаю. За Haskell надеюсь кто-то разбирающийся в теме напишет, желательно не египетскими иероглифами a <$> b ^. c >>= d.
del
Попытался решить задачу на питоне и наконец-то вроде даже понял, как работает asyncio.
Исходные структуры данных:
from dataclasses import dataclass
@dataclass
class IdNode:
"""tree for IDs"""
id: int
children: list
@dataclass
class MsgNode:
"""tree for messages"""
message: str
children: list
# initial tree with IDs
tree = IdNode(1, [
IdNode(2, []),
IdNode(3, [
IdNode(4, []),
IdNode(5, [])
])
])
print(tree)Удаленная база сообщений (обращаюсь к ней через typicode, как и автор статьи) :
{
"messages": [
{
"id": 1,
"message": "1:Оригинальный комментарий"
},
{
"id": 2,
"message": "2:Ответ на комментарий 1"
},
{
"id": 3,
"message": "3:Ответ на комментарий 2"
},
{
"id": 4,
"message": "4:Ответ на ответ 1"
},
{
"id": 5,
"message": "5:Ответ на ответ 2"
}
],
"profile": {
"name": "typicode"
}
}Синхронное решение задачи:
#!/usr/bin/env python
import requests
from data_structures import IdNode, MsgNode, tree
api_url = "https://my-json-server.typicode.com/AcckiyGerman/demo/messages/"
def get_comment_by_id(x):
url = api_url + str(x)
r = requests.get(url).json()
return r["message"]
def map_tree(node):
return MsgNode(
message=get_comment_by_id(node.id),
children=[map_tree(child) for child in node.children]
)
message_tree = map_tree(tree)
print(message_tree)Асинхронное решение задачи:
#!/usr/bin/env python
import aiohttp
import asyncio
from data_structures import IdNode, MsgNode, tree
api_url = "https://my-json-server.typicode.com/AcckiyGerman/demo/messages/"
messages = {}
tasks = []
async def get_comment_by_id(x, session):
global messages
url = api_url + str(x)
r = await session.get(url)
data = await r.json()
messages[x] = data['message']
print(f"request {x} finished")
def initiate_tasks(node, session):
""" starts a task for each message id in the tree, but not await for result """
global tasks
tasks.append(get_comment_by_id(node.id, session))
for child in node.children:
initiate_tasks(child, session)
def map_tree(node):
global messages
return MsgNode(
message=messages[node.id],
children=[map_tree(child) for child in node.children]
)
async def main():
async with aiohttp.ClientSession() as session:
initiate_tasks(node=tree, session=session)
await asyncio.gather(*tasks)
message_tree = map_tree(tree)
print(message_tree)
if __name__ == "__main__":
asyncio.run(main())Результаты:
$ time ./sync_fetch.py
IdNode(id=1, children=[IdNode(id=2, children=[]), IdNode(id=3, children=[IdNode(id=4, children=[]), IdNode(id=5, children=[])])])
MsgNode(message='1:Оригинальный комментарий', children=[MsgNode(message='2:Ответ на комментарий 1', children=[]), MsgNode(message='3:Ответ на комментарий 2', children=[MsgNode(message='4:Ответ на ответ 1', children=[]), MsgNode(message='5:Ответ на ответ 2', children=[])])])
real 0m1,762s
user 0m0,181s
sys 0m0,012s
$ time ./async_fetch.py
IdNode(id=1, children=[IdNode(id=2, children=[]), IdNode(id=3, children=[IdNode(id=4, children=[]), IdNode(id=5, children=[])])])
request 2 finished
request 3 finished
request 1 finished
request 5 finished
request 4 finished
MsgNode(message='1:Оригинальный комментарий', children=[MsgNode(message='2:Ответ на комментарий 1', children=[]), MsgNode(message='3:Ответ на комментарий 2', children=[MsgNode(message='4:Ответ на ответ 1', children=[]), MsgNode(message='5:Ответ на ответ 2', children=[])])])
real 0m0,473s
user 0m0,137s
sys 0m0,020sВыводы — асинхронный питон довольно сложен даже для такой простой задачи.
Я потратил около 3-х часов времени, чтобы написать правильное асинхронное решение, и мне не очень нравится результат. Рекурсивного обхода не получилось из-за необходимости собрать асинхронные обращения к удаленному серверу в одном месте, так что пришлось вводить еще две глобальные структуры messages и tasks
Синхронное решение заняло 10 минут. Правда я никогда в работе с асинхронным питоном не работал.
Может кто-либо подскажет, как можно короче написать.
Спасибо за потраченное время. Синхронный код действительно выглядит достаточно простым.
Любопытно, можно ли как-то упростить второй случай..
А зачем вы собирали задачи в одном месте? Разве нельзя было сделать вот так:
async def map_tree(node):
message, children = await asyncio.gather(
get_comment_by_id(node),
asyncio.gather(*[map_tree(child) for child in node.children])
)
return MsgNode(
message=message,
children=children
)С опозданием на десять дней, но проверил — действительно asyncio.gather корректно собирает задачи из вложенного asyncio.gather и все просто работает асинхронно.
Вот полный код:
#!/usr/bin/env python
from dataclasses import dataclass, field
import aiohttp
import asyncio
@dataclass
class IdNode:
id: int
children: list = field(default_factory=list)
@dataclass
class MsgNode:
message: str
children: list
def __str__(self, indentation=""): # из комментария @Senpos ниже
message = f"{indentation}{self.message}"
children_messages = [child.__str__(indentation + '\t') for child in self.children]
return '\n'.join([message, *children_messages])
async def get_comment_by_id(x, session):
r = await session.get(f"https://jsonplaceholder.typicode.com/todos/{x}")
data = await r.json()
print('request', x, 'finished')
return data['title']
async def map_tree(node, session):
message, children = await asyncio.gather(
get_comment_by_id(node.id, session),
asyncio.gather(*[map_tree(child, session) for child in node.children])
)
return MsgNode(message, children)
async def main():
async with aiohttp.ClientSession() as session:
message_tree = await map_tree(
node=IdNode(1, [IdNode(2), IdNode(3, [IdNode(4), IdNode(5)])]),
session=session
)
print('\n', message_tree)
asyncio.run(main())Вот так решение выглядит уже почти идеальным и сравнимо по читаемости с синхронной версией. Можно еще сделать ClientSession синглтоном, чтобы не прокидывать сессию через все функции, но это мелочи.
Но вы считерили ведь.
@dataclass
class MsgNode:
message: str
children: listЭто совсем не
class Comment
{
public int Id { get; set; }
public string Title { get; set; }
}Исходная задача:
Допустим у нас есть дерево идентификаторов комментариев
Я описал узел дерева, который сразу же в себе содержит ID комментария И дочерние узлы.
class IdNode:
id: int
children: listДалее:
Необходимо построить новое дерево, аналогичное исходному, узлами которого вместо идентификаторов являются десериализованные структуры (т.е. сами комментарии, если я правильно понял)
class MsgNode:
message: str # вместо ID - комментарий
children: listТот факт, что вы для решения задачи построили другие структуры данных (дерево отдельно, сообщения отдельно), не делает это решение неправильным.
P.S. хотя меня было цапарающее чувство, что одно дерево с разной нагрузкой это лучше чем два разных, так что ваше решение пожалуй правильнее, но я фокусировался тогда на асинхронности.
Тот факт, что вы для решения задачи построили другие структуры данных (дерево отдельно, сообщения отдельно), не делает это решение неправильным.
Просто комментарий это ведь не только текст, но еще как минимум id. Там есть еще и другие поля, просто я для простоты не стал их указывать. Но у нас конечно не же просто строчки.
Что касается хранения комментария отдельно от дерева, как я выше уже говорил, это совершенно разные вещи. Разделение на разные типы в данном случае следствие принципа SRP — хранение данных о комментарии — одна ответственность, а сохранение иерархии — совсем другая. В частности перевод из дерева в массив (или хэшмапу) и назад это обычная операция, в коде на го этим люди и пользовались, к слову.
А в чём чит-то заключается? Подобная замена структуры данных не делает задачу ни проще, ни сложнее.
Ну будет вместо return MsgNode(message, children) написано return TreeNode(Comment(node.id, message), children) — что от этого принципиально поменяется?
from dataclasses import dataclass, field
from typing import Any, Callable, Awaitable, List
import aiohttp
import asyncio
class TreeMapper:
def __init__(
self,
create: Callable[[Any], Awaitable[Any]],
get_children: Callable[[Any], List[Any]],
set_children: Callable[[Any, List[Any]], None],
):
self.create = create
self.get_children = get_children
self.set_children = set_children
async def map(self, node):
new_node, new_children = await asyncio.gather(
self.create(node),
asyncio.gather(*[
self.map(child)
for child in self.get_children(node)
]),
)
self.set_children(new_node, new_children)
return new_node
@dataclass
class IdNode:
id: int
children: list = field(default_factory=list)
@dataclass
class TitleNode:
title: str
children: list = field(default_factory=list)
def __str__(self, indentation=""):
title = f"{indentation}{self.title}"
children = [
child.__str__(indentation + '\t') for child in self.children
]
return '\n'.join([title, *children])
async def get_title_by_id(node: IdNode, session):
response = await session.get(
f"https://jsonplaceholder.typicode.com/todos/{node.id}"
)
data = await response.json()
return TitleNode(title=data['title'])
async def main():
async with aiohttp.ClientSession() as session:
message_tree = await TreeMapper(
lambda node: get_title_by_id(node, session),
lambda node: node.children,
lambda node, children: node.children.extend(children),
).map(
IdNode(1, [IdNode(2), IdNode(3, [IdNode(4), IdNode(5)])]),
)
print('\n', message_tree)
if __name__ == '__main__':
asyncio.run(main())
from dataclasses import dataclass, field
import aiohttp
import asyncio
@dataclass
class IdNode:
id: int
children: list = field(default_factory=list)
async def get_data_by_id(node: IdNode, session):
response = await session.get(
f"https://jsonplaceholder.typicode.com/todos/{node.id}"
)
data = await response.json()
return data
def tree_iter(node, get_children, lvl=0):
yield node, lvl
for child in get_children(node):
yield from tree_iter(child, get_children, lvl + 1)
async def main():
async with aiohttp.ClientSession() as session:
id_tree = (
IdNode(1, [
IdNode(2),
IdNode(3, [
IdNode(4),
IdNode(5)
])
])
)
nodes, lvls = zip(*tree_iter(id_tree, lambda node: node.children))
nodes = await asyncio.gather(*[
get_data_by_id(node, session)
for node in nodes
])
for node, lvl in zip(nodes, lvls):
print('{}{}'.format('\t'*lvl, node['title']))
if __name__ == '__main__':
asyncio.run(main())
Перенес C# реализацию автора на Python 3.7+:
from __future__ import annotations
import asyncio
from dataclasses import dataclass, field
from typing import Generic, Sequence, TypeVar
from aiohttp import ClientSession
T = TypeVar("T")
@dataclass
class Comment:
id: int
title: str
def __repr__(self):
return f"{self.id} - {self.title}"
@dataclass
class Tree(Generic[T]):
value: T
children: Sequence[Tree] = field(default_factory=list)
def print(self, indentation: str = "") -> None:
print(f"{indentation}{self.value}")
for child in self.children:
child.print(indentation + "\t")
async def get_comment(client: ClientSession, id: int) -> Comment:
async with client.get(f"https://jsonplaceholder.typicode.com/todos/{id}") as resp:
raw_comment = await resp.json()
return Comment(id=raw_comment["id"], title=raw_comment["title"])
async def get_comments_tree(client: ClientSession, tree: Tree[int]):
children = [get_comments_tree(client, child) for child in tree.children]
value = await get_comment(client, tree.value)
chilren_results = await asyncio.gather(*children)
return Tree[Comment](value, chilren_results)
async def main():
async with ClientSession() as client:
tree = Tree(1, children=[Tree(2), Tree(3, children=[Tree(4), Tree(5)])])
tree.print()
comment_tree = await get_comments_tree(client, tree)
comment_tree.print()
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(main())pyright даже умеет за дженериками следить. А вот mypy и PyCharm почему-то не смогли меня наругать, когда при создании дерева я попытался одной из нод передать в качестве children НЕ Sequence[Tree].
Если кто знает как обучить другие тайпчекеры понимать дженерики — поделитесь, пожалуйста. :)
Попробовать можно на этом:
tree = Tree(1, children=[Tree(2), Tree(3, children=[Tree(4), Tree(5, children='i am not a sequence of trees')])])Я добавил печать результатов в get_comment :
...
raw_comment = await resp.json()
print(f"request {id} finished: {raw_comment['title']}")и в выводе сразу видно, что код не совсем асинхронный, вызовы к back-end асинхронны только для детей одного узла, но не всех узлов одновременно:
request 1 finished: delectus aut autem
request 2 finished: quis ut nam facilis et officia qui
request 3 finished: fugiat veniam minus
request 5 finished: laboriosam mollitia et enim quasi adipisci quia provident illum
request 4 finished: et porro tempora(последние два вызова могут поменятся местами по времени, но 1..3 — никогда и это будет видно более ясно, если сделать дерево побольше)
Потому что там перенос сделан некорректно. Вызов asyncio.gather должен до первого await идти.
Всегда было приятно почитать твои комментарии, они обычно очень обстоятельные. А статья получилась тем более обстоятельной.
Работаю с Go года четыре, и в целом полностью согласен с выводами, сделанными за четыре часа знакомства. Go Community крайне токсичный, берет плохой пример с Rob'а Pike'а, и не берет хороший пример с Russ'а Cox'а.
под низкоуровневыми языками я имею ввиду языки С/С++/..., а под среднеуровневыми — C++/C#/Java/Kotlin/Swift/...
Извините, а топик всё ещё жив?
После небольшой практики в Haskell эта задача мне видится не совсем честной. Она как раз показывает чуть ли не best case для Haskell.
Вот другая задача (готов поспорить, что она более "честная"):
Есть:
- корневой комментарий
- API для получения всех непосредственных потомков комментария (да это латентное IO -- соответственно хотим распараллелить)
Требуется:
- нарисовать дерево комментариев начиная с заданного коммента.
Здесь баланс сложности резко сместится Haskell будет всё ещё проще но не настолько.
ПС.
А вот в следующей задаче вообще Haskell похоже даст худшее решение:
- исходная структура данных представляет собой граф (например File System со ссылками на директории).
Добрый день, у меня собственно вопрос а в чем тут будет отличие? По сути у нас всего 2 изменения:
Полагаю самым простым способом будет просто мемоизировать вызов getChil
Мемоизация же нужна только в задаче из "ПС"?
Но мемоизация "в лоб" разрушает параллельность на такой задаче.
Соответственно вам нужно будет делать какое-то инженерное решение:
- параллельные запросы
- последовательное добавление полученных данных в нашу структуру
эдакий последовательно-параллельный BFS получается.
Но само такое апи кажется немного странным, кажется так не делают.
Ну в FS то ровно так.
Тут более широкий вопрос в том, что есть:
- "математичные" (термин не очень чёткий, но надеюсь понятный) задачи - они прям чудо как удобно решаются на Haskell
- "нематематичные" задачи - кажется, что для их решения на Haskell из-за ограничений надо потратить больше времени, чем на императивном ЯП.
Так вот в туториалах и статьях на Haskell любят решать задачи "математичные", а в реальном Software Engineering мы встречаемся с нематематичными.
Да не разрушает. Будет выглядеть как-то так:
g :: IO (Tree Data)
g = join <$> forM tree \id -> do
datas <- get id
pure (Fork (Leaf <$> datas))Где get это наша функция возврата инфы по непосредственным детям по айди комментария. Линк
Ну в FS то ровно так.
При чем тут ФС. Вот вы бы если бы апи для форума проектировали стали бы делать апи такого вида? Тут вопрос не к ФС, а к вопросами типа REST. Потому что в ресте у вас как раз будет
comment/ids с айдишками и comment/1, comment/2 с деталями.
Что в статье и показано.
Так вот в туториалах и статьях на Haskell любят решать задачи "математичные", а в реальном Software Engineering мы встречаемся с нематематичными.
В качестве примера я взял васмделишное апи которое устроено по базовому рестовому принципу (пресловутый jsonplaceholder.typicode.com). Он дофига математичный? Можете показать пример где АПИ сделано так как вы предлагаете выше?
to del
Поскольку комментарий большой, сначала краткий абстракт:
1. Мне нравится Хаскель (он прививает хорошие практики программирования).
2. Хаскель разгромно выигрывает в интернет-статьях и точно так же разгромно проигрывает в широте использования написанного на нём ПО.
3. Ваша реакция на неудобный комментарий "let tree = ..." в жизни тоже надо получать и тут Хаскель уже не будет так разгромно выигрывать: "я взял реальный АПИ, он что дофига математичный?".
Так вот проблема описанная в п.2 - во многом результат вот такой вот реакции (кто говорит о Хаскель недостаточно восторженно - тот враг и ату его).
==================================================
Q: Мемоизация же нужна только в задаче из "ПС" (с графом) и в той задаче разрушает параллелизм?
A: Да нет не разрушает. И вы приводите код для задачи с деревом.
У нас с вами какой-то misunderstanding, о причинах которого я могу только догадываться. Чтобы избежат недоразумений хочу вас заверить что у меня нет цели "атаковать" Хаскель - это хороший язык со своим балансом плюсов и минусов.
Хаскель мне реально понравился, после знакомства с ним я прямо заметил места, в которых я стал делать лучшие инженерные решения.
Но такие статьи не только воодушевляют на знакомство с Хаскелем, но и порождают нереализованные ожидания после первых десятков часов опробывания.
у меня собственно вопрос а в чем тут будет отличие?
Была 1 строка.
Стало 5 строк которые я, (junior в Haskell) читаю не без труда.
Я бы написал в 10-15 строк в более простом, менее семантически-насыщенном виде.
И после этого вся магия "Хаскелю нужна 1 строка там, где Go 15" исчезла бы.
В качестве примера я взял васмделишное апи которое устроено по базовому рестовому принципу (пресловутый jsonplaceholder.typicode.com). Он дофига математичный? Можете показать пример где АПИ сделано так как вы предлагаете выше?
Задача показать дерево комментариев состоит из 2 частей:
1. Получить структуру дедева комментариев (предложен АПИ 1-к-1 соответствующий: SELECT * FROM xxx WHERE parent_id = *** )
2. Подставить текст комментариев в структуру (взят API гугла для одноранговых комментов).
Вы упорно пытаетесь решить только задачу №2 (при этом если решить только её, то по-моему соотношение трудозатрат несколько приукрашивается в пользу Haskell).
- Мне нравится Хаскель (он прививает хорошие практики программирования).
В принцие любой язык стоящий особняком прививает хорошие практики. Хаскель, Си, Лисп — каждый привносит что-то свое. Языки которые привносят плохие навыки обычно редки, и го кстати я пожалуй отнес бы к таким.
- Хаскель разгромно выигрывает в интернет-статьях и точно так же разгромно проигрывает в широте использования написанного на нём ПО.
Если так судить то лучшая платформа для программированич это excel. не шучу, на их макросах больше кода написано чем на всех остальных языках вместе взятых. Точно так же как сайты-визитк на вордпрессе куда более распрострнанены чем любые экспрессы/джанги/мвц/… 80% если я правильно помню статистику от вордпресса.
- Ваша реакция на неудобный комментарий "let tree = ..." в жизни тоже надо получать и тут Хаскель уже не будет так разгромно выигрывать: "я взял реальный АПИ, он что дофига математичный?".
Тут не хватает глагола "что моя реакция". Я просто объяснил, что я взял пример АПИ с которыми я работаю последние лет 10 — есть способ получить список айдишек, есть способ по айдишке получить детали. Иногда сверху добавляется какой-нибудь GQL где можно фильтры произвольные писать, но для простоты это опустили. И вот ни разу никогда я не видел апи "по айди достаем инфу по детям". Поэтому и говорить про "математичность" такого апи кажется сильным лукавством. Вот и вся реакция.
Но такие статьи не только воодушевляют на знакомство с Хаскелем, но и порождают нереализованные ожидания после первых десятков часов опробывания.
Я описал по сути собственное знакомство с хаскеллем. Как я с ним знакомился, так и писал. YMMV, кому-то может не подойти.
Была 1 строка.
Стало 5 строк которые я, (junior в Haskell) читаю не без труда.
Я бы написал в 10-15 строк в более простом, менее семантически-насыщенном виде.
И после этого вся магия "Хаскелю нужна 1 строка там, где Go 15" исчезла бы.
Во-первых там 3 строки, 4 включая сигнатуру
Во-вторых читать что написано научиться можно легко, а писать простыни кода без ошибок — не очень. Поэтому я больше доверяю семантически насыщенному коду, где нужно просто клеить функции из библиотек чтобы получить свое решение, а не писать фор фор канал канал и потом ловить проблемы (мои мучения я +- описал).
Вы упорно пытаетесь решить только задачу №2 (при этом если решить только её, то по-моему соотношение трудозатрат несколько приукрашивается в пользу Haskell).
Задача №1 решается примерно так:
getComments :: Int -> IO (Tree Id)
getComments i = do
response <- get $ "www.mysite.com/commentsTree"
let comment = decode (response ^. responseBody) :: Maybe (Tree Id)
return $ fromJust commentПоэтоу мне показалось не сильно интересным это рассматривать. Или вы предлагаете руками писать десериализацию дерева и сравнить с такой же ручной десериализацией в го?
> Хаскель разгромно выигрывает в интернет-статьях и точно так же разгромно проигрывает в широте использования написанного на нём ПО.
Если так судить то лучшая платформа для программированич это excel. не шучу, на их макросах больше кода написано чем на всех остальных языках вместе взятых. Точно так же как сайты-визитк на вордпрессе куда более распрострнанены чем любые экспрессы/джанги/мвц/… 80% если я правильно помню статистику от вордпресса.
Во-первых вы пропустили ключевое "по широте использования написанного на нём ПО".
Ну и да кто ж сказал, что excel (встроенные макросы или VisualBasic?) плохой? Если люди реально пользуются - значит good enough (ну и эффект первого застолбившего поляну, конечно).
Но в целом при такой разнице конечных подходов обсуждать локальный подход в статье малоосмысленно. Я просто вижу, что практически каждый аргумент интерпретируется нами по-разному и каждый остаётся при своём мнении.
Для меня - крайне мало задач, для которых Хаскель был бы удобен, поэтому вкладывать и дальше своё время в изучение малоосмысленно. У вас вероятно ситуация другая.
======================================
Не заню стоит ли отвечать, но пусть будет для истории.
Тут не хватает глагола "что моя реакция".
Ваша реакция процитирована. Она как минимум раздражённая, как максимум - подберите эпитет сами. Мне даже пришлось дисклеймер, что "не атакую Хаскель" написать, т.к. ситуация грозила скатиться в срачик.
Во-первых там 3 строки, 4 включая сигнатуру
А если с empty-line, перед ф-ией то 5. Что даст вклад 5 в:
wc -l *.hs
Во-вторых читать что написано научиться можно легко, а писать простыни кода без ошибок — не очень.
Хаскель довольно хорошо страхует от ошибок в семантически-разряженном коде. Поэтому какой код писать на Хаскеле - дело вкуса и привычек коммюнити.
По мне привычки писать замысловатый код - плохие практики для целей... (впрочем про разность целей написано выше).
Задача №1 решается примерно так:
Вы постулировали удобный для Haskell АПИ и у вас всё хорошо. Имеете право. Можете повторить это ещё и ещё.
Но в моей практике технология: "мы делаем на ней только удобное, если что-то не удобно - скидываем головную боль на соседний отдел", - нужна в сложном проекте только в каких-то совсем экзотических условиях (скажем SQL - пример такой технологии, да).
Но в целом при такой разнице конечных подходов обсуждать локальный подход в статье малоосмысленно. Я просто вижу, что практически каждый аргумент интерпретируется нами по-разному и каждый остаётся при своём мнении.
Для меня — крайне мало задач, для которых Хаскель был бы удобен, поэтому вкладывать и дальше своё время в изучение малоосмысленно. У вас вероятно ситуация другая.
Для меня хаскель удобен для всех задач, когда я имею возможность взять язык с ГЦ. Ну там вместо джавки или сишарпа. С поправкой на басфактор, поиск людей на проект и набор библиотек — какой-нибудь блокчейн дапп куда проще на тайпскрпте вероятно написать.
Ваша реакция процитирована. Она как минимум раздражённая, как максимум — подберите эпитет сами. Мне даже пришлось дисклеймер, что "не атакую Хаскель" написать, т.к. ситуация грозила скатиться в срачик.
Вам кажется. Я вообще редко ругаюсь, тем более из-за языков. Каждый берет что ему комфортнее.
А если с empty-line, перед ф-ией то 5. Что даст вклад 5 в:
wc -l *.hs
Ну офигеть :)
Хаскель довольно хорошо страхует от ошибок в семантически-разряженном коде. Поэтому какой код писать на Хаскеле — дело вкуса и привычек коммюнити.
По мне привычки писать замысловатый код — плохие практики для целей… (впрочем про разность целей написано выше).
Замысловатый код — плохой и так делать не надо. Но в примере выше ничего сильно замысловатого и нет. Вопрос привычки, опять-же, я и на ЖС иногда пишу код вида
const [maxPrice, sumPrice] = foo
.items
.map(x => BigNumber.from(x.price || constants.Zero))
.reduce(([max, sum], x) => [max.gt(x) ? max : x, sum.add(x)],
[BigNumber.from(0), BigNumber.from(0)]);Что вероятно может отпугнуть джунов-жсеров. Но что поделать — для сениоров тут коротко и понятно написано происходящее.
Но в моей практике технология: "мы делаем на ней только удобное, если что-то не удобно — скидываем головную боль на соседний отдел", — нужна в сложном проекте только в каких-то совсем экзотических условиях (скажем SQL — пример такой технологии, да).
Действительно говорим о разном. Можете ткнуть конкретно на кого что тут спихнуто. Провайдеры апишки возвращают жсоном дерево — их обязанность. Библиотека деревьев умеет парситься из/в жсона — её обязанность. Тут нет никакой кастомизации и рокет саенса — просто базовая структура данных, может быть чуть более редка чем массив. Вас же не удивляет возможность преобразовать массив чисел в жсон и наоброт в 1 строку в любом языке? И это кажется не считаетс перекладыванием боли на соседний отдел.
В общем, я в растерянности от такой постановки честно говоря
Действительно говорим о разном. Можете ткнуть конкретно на кого что тут спихнуто.
Я говорю вот о чём:
Все статьи которые я вижу - в них по счастливому стечению обстоятельств формулировка задачи и внешние API удобны для Haskell (в данном случае у вас презумпция: если получать структуру комментов - сразу всё дерево, а не пошагово, разумеется парсить DOM-дерево на Хаскель будет удобнее чем на Го).
Мой Pet-project для изучения Haskell. Прям с ходу влетаю в то, что мне нужен двусвязный список, с полноценными вставкой \ удалением. Далее мысли:
1. Возможно 2 Map (в прямом обратном направлении, потом всё это в data instance functor && traverse).
2. Погуглить что есть. Ничего лучше не нашёл. Т.е. у того, что я видел под капотом что-то похожее по ассимптотической сложности.
3. Долго думал.
4. Решение: разделить проходы в прямом и обратном направлении (благо задача почти игрушечная, позволяла). Использовать односвязный список, иногда его переворачивать. Использовать разные newtype для прямого и обратного списков для типобезопасности.
То есть когда я пишу программы вселенная мне не предоставляет "удобные для Хаскеля" интерфейсы. И я бы что-то хотя бы отдалённо похожее хотел бы видеть в статьях про Хаскель.
Но в основном это success stories - идущие вразрез с тем опытом, который получил я.
Для меня хаскель удобен для всех задач,
Ровно одна боевая задача - генерация примеров для тестирования нашего DSL. Потому, что Haskell
а) чудо как хорош с Parsec,
б) заставляет делать другую реализацию интерпретатора, что предотвращает "тянуть ошибки на автомате из проекта в его верификатор".
Замысловатый код — плохой и так делать не надо.
Я вот совсем не знаю JavaScript (1 раз писал для себя расширение кое-что посчитать в GoogleSpreadSheets). Т.е. опыт в Haskell раз в 50 больше чем в JS =)
Написанное вами не выглядит страшно, хотя может где-то под капотом являться, слышал в JS любят неявные побочные эффекты. Просто надо помнить что что делает.
Написанное на Haskell выглядит.
Мне кажется нетипичный синтаксис и любовь коммюнити к наворотам - действительно одина из проблем языка (если ставить целью его проход в массы)
Мой Pet-project для изучения Haskell. Прям с ходу влетаю в то, что мне нужен двусвязный список, с полноценными вставкой \ удалением.
Что за задача-то?
Маленький компилятор DSL-языка (но поскольку там нужны IR-оптимизации, пусть и неполноценные, то надо хранить состояние, лазить по операциям туда-сюда и оптимизировать их).
Маленький - в смысле без циклов.
Простите за некропост, но по описанию звучит как что-то, что очень хорошо ложится на list zipper.
Все статьи которые я вижу — в них по счастливому стечению обстоятельств формулировка задачи и внешние API удобны для Haskell (в данном случае у вас презумпция: если получать структуру комментов — сразу всё дерево, а не пошагово, разумеется парсить DOM-дерево на Хаскель будет удобнее чем на Го).
Я сначала взял задачу, а потом подумал что неплохо бы на её примере обучиться азам хаскеля/го. А не наоборот. Если так совпало — ну что поделать, я описал свой опыт.
Мой Pet-project для изучения Haskell. Прям с ходу влетаю в то, что мне нужен двусвязный список, с полноценными вставкой \ удалением.
Двусвязный список это такая структура данных, которая часто прохоидится в универе и почти никогда не используется на практике. Возможно для вашей задачи есть более подходящие структуры данных.
Мне кажется нетипичный синтаксис и любовь коммюнити к наворотам — действительно одина из проблем языка (если ставить целью его проход в массы)
МЛ в целом кажется более супериор синтаксисом откровенно говоря. Это особенно начинаешь замечать когда начинаешь часто пихать туда/сюда функции, например на акторных фреймворках это заметно.
А так да, умение читать разные синтаксисы в целом полезно и неплохо расширяет кругозор.
Это особенно начинаешь замечать когда начинаешь часто пихать туда/сюда функции, например на акторных фреймворках это заметно.
Akka была изначально написана на Scala, а не более "взрослом", тогда точно, Хаскель, ИМХО ровно потому, что её изначально пытались сделать для людей, а не "кому не нравится тот сам не прав".
Я как раз основной мой поинт в том, что такой подход более рабочий.
Двусвязный список это такая структура данных, которая часто прохоидится в универе и почти никогда не используется на практике.
cd linux_***
grep -r "struct list" *.h | wc -l
Ваши ставки?
И да вы же не пытаетесь сказать, что: "ценность двусвязного списка переоценена" => "ценность двусвязного списка 0"?
МЛ в целом кажется более супериор синтаксисом откровенно говоря... А так да, умение читать разные синтаксисы в целом полезно и неплохо расширяет кругозор
Мы прыгаем с пункта на пункт, в целом все звучат так:
1. семантическая насыщенность фрагмента на Haskell выше чем на JavaScript
2. Синтаксис хаскеля странен и в нём есть как ошибки, так и помарки
*) a.map(f1).filter(f2).map(f3) >> map f3 $ filter f2 $ map f3 a
**) странные отступы в while при записи на той же строке или громоздкий $ для доступа к полям data
3. Люди действительно знают C-syntax лучше чем Haskell. И пытаться принуждать к неудобству людей заради их же блага работает только если морковка НУ ОЧЕНЬ вкусная.
Ну и независимо от этого с какой-то точки "новая концепция", познакомится с которой несомненно хорошо, становится вещью в себе не добавляя никакой ценности вокруг.
Не важно знание это 150го паттерна проектирования, обход C-types "по улитке" или умение на автомате парсить сложную Haskell-запись.
И да вы же не пытаетесь сказать, что: "ценность двусвязного списка переоценена" => "ценность двусвязного списка 0"?
Нет, не буду. Тем не менее, это такая же редкость как скажем структура данных "минмакс куча". В задачках на литкоде бывает, в реальном коде где-то там наверное тоже.
- Синтаксис хаскеля странен и в нём есть как ошибки, так и помарки
*) a.map(f1).filter(f2).map(f3) >> map f3 $ filter f2 $ map f3 a
Что вам мешает написать ровно так же?
a
.map(f1)
.filter(f2)
.map(f3)->
a
& map f1
& filter f2
& map f3
- Люди действительно знают C-syntax лучше чем Haskell. И пытаться принуждать к неудобству людей заради их же блага работает только если морковка НУ ОЧЕНЬ вкусная.
Ну давайте теперь 300 лет тащить си-синтаксис, потому что в середине 20 века АЛГОЛ стал популярным.
When you're designing a new language, don't slavishly follow the bizarre conventions of predecessor languages
When you're designing a new language, don't slavishly follow the bizarre conventions of predecessor languages
Вы правы абсолютно по всем позициям.
И вот мы в самом начале беседы:
Хаскель пректасный язык для обучения студентов и написания грамотных комментариев (без шуток - моя ремарка о "хороших прктиках" была не просто так).
Но если при таких достоинствах его вклад в индустрию ПО близок к о-малому, значит недостатки in real world всё-таки есть и существенны. И на них не следует закрывать глаза.
И вот ни разу никогда я не видел апи "по айди достаем инфу по детям".
Вообще-то это самый частый случай. Есть CRUD, а всё что сверху — отложено в неопределённое будущее.
del
Сложность простоты