В прошлый раз получился простой генератор парсера PEG. Сейчас же я покажу, что на самом деле делает сгенерированный парсер при разборе программы. Я погрузился в ретро-мир ASCII-арта, в частности, библиотеку с именем «curses», которая доступна в стандартной поставке Python для Linux и Mac, а также как дополнение для Windows.

<В конце статьи под спойлером приводится gif. Мне он показался более понятным, нежели статичная картинка>
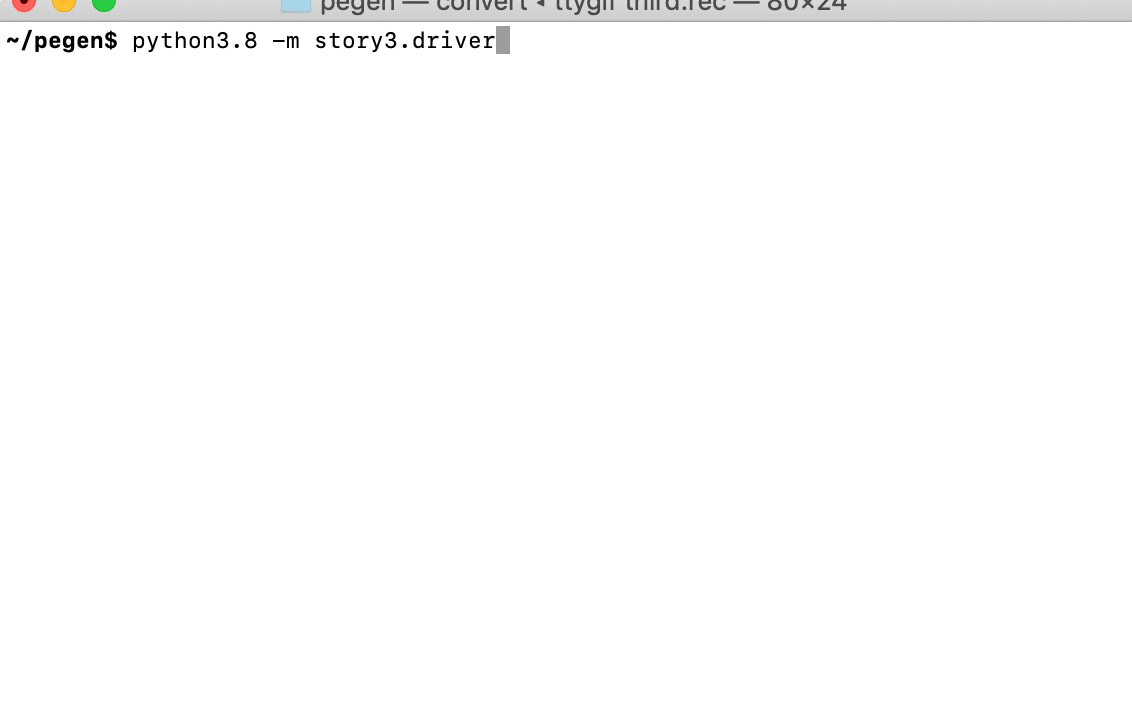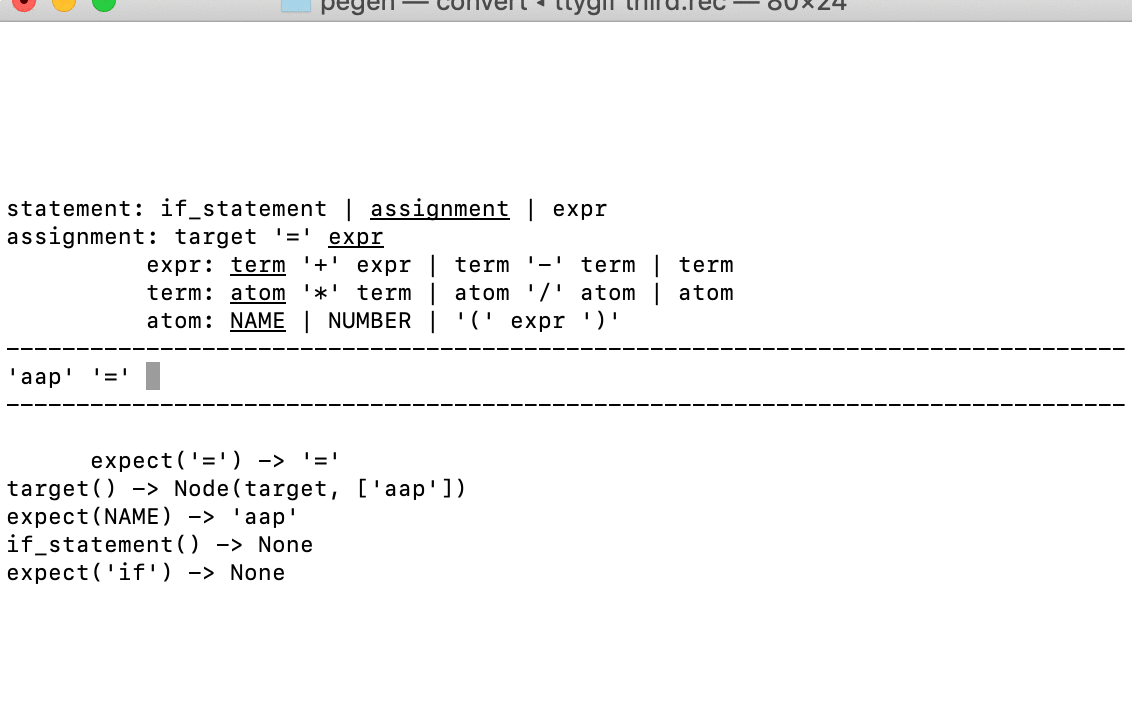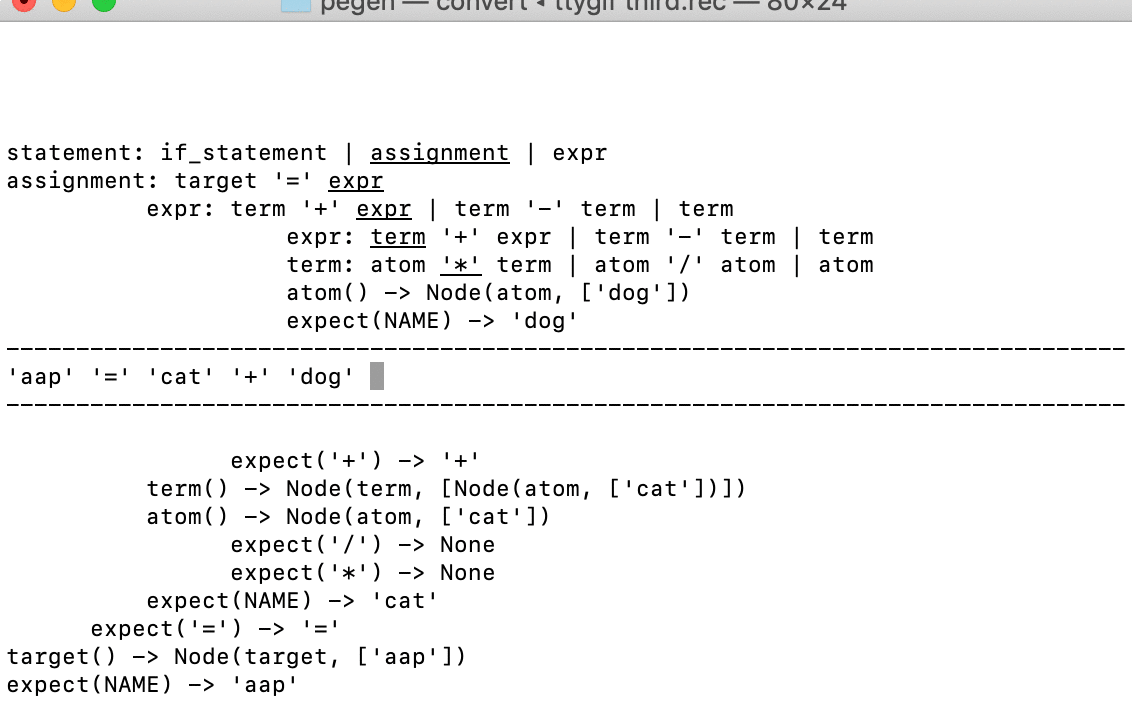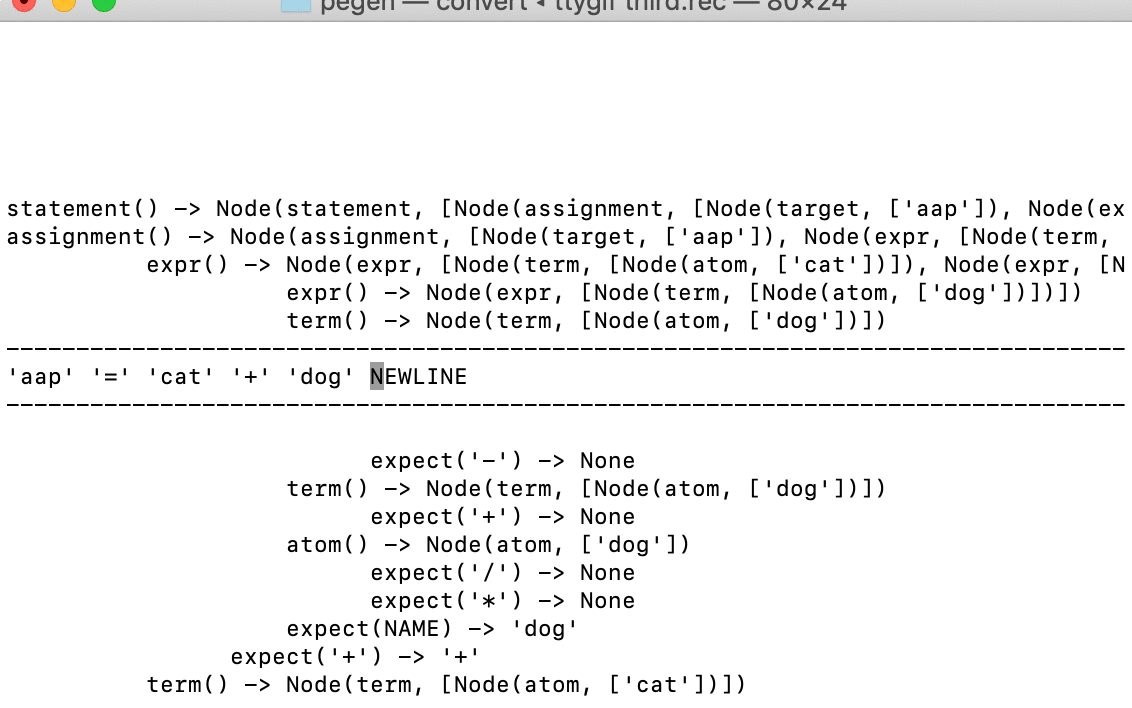
Давайте посмотрим на визуализацию. Экран разделён на три части, как это и принято в ASCII, линией дефисов:
- В верхней части показан стек вызовов синтаксического анализатора, который, как вы помните, является анализатором рекурсивного спуска с неограниченным возвратом. Чуть ниже я объясню более подробно.
- Однострочный раздел в середине показывает содержимое буфера токенов с курсором, указывающим на токен, который будет анализироваться следующим.
- Внизу мы визуализируем кэш-память, используемую алгоритмом packrat-парсера. Запись его элементов несколько похожа на некоторые элементы стека парсера (с результатами).
Главное, что нужно знать, чтобы понимать эту визуализацию, это то, что отступы строк в верхней и нижней частях соответствуют буферу токенов.
- Первые две строки (начинающиеся с
statementиassignment) показывают вызовы соответствующих методов парсера, которые проводят анализ прямо сейчас. Они были вызваны, когда указатель токенизатора был перед первым токеном ('aap'). - Следующие две строки (начинающиеся с
exprиterm) выровнены с началом токена'cat', где были вызваны соответствующие методы парсера. - Пятая и последняя строка визуализации стека показывает вызов
expect('/'), который возвращаетNone. Он вызвался в позиции токена'+'.
Отступы элементов в кэше также соответствуют позиции в буфере токенов. Например, внизу есть отрицательные записи в кэше, они были получены при поиске токена 'if' и правила if_statement в начале буфера токенов. Мы также находим и успешные записи в кэше для токена '=' и для NAME (в частности, 'cat'), соответствующих дальнейшим позициям ввода.
Как в блоке стека анализатора, так и в блоке кэша возвращённые вызовы отображаются как function(args) -> result. Иногда в стеке парсера отображается несколько возвращаемых методов — я сделал это, чтобы уменьшить дрожание текста от частой смены содержимого.
(Говоря о дрожании, верхние строки стека анализатора перемещаются вверх, когда в стек добавляется вызов, и опускаются, когда он извлекается из стека. Т.е. каждый новый вызов вставляется в самый низ блока визуализации стека, сдвигая существующие строки вверх. Мне кажется, что наблюдать за этой частью экрана особых проблем не составляет, ну по крайней мере для меня. Вероятно, значительная часть нашего мозга посвящена отслеживанию движущихся объектов. :-)
Кэш визуализируется как LRU, с часто используемыми элементами в верхней части; более редкие опускаются вниз экрана. (Прототип packrat-парсера, который я показал в предыдущих статьях, не использует LRU, но, вероятно, будет хорошей идеей оптимизировать потребление памяти.)
Давайте посмотрим на некоторые детали при визуализации стека синтаксического анализа. Верхние четыре записи соответствуют методам парсера, которые ещё в обработке, каждая строка представляет собой строку из грамматики. Подчеркнутый пункт — тот, который породил следующий вызов.
Т.е. судя по скриншоту, мы находимся на второй альтернативе для statement, а именно на assignment. В этом правиле мы находимся на третьем пункте, а именно на expr. В правиле expr мы находимся только в первом пункте первой альтернативы (term '+' expr); и в правиле для term мы находимся в последней альтернативе (atom).
Ниже мы видим результат, который привел к сбою второй альтернативы (atom '/' term): expect('/') -> None отступ с токеном '+'. На следующем шаге, мы увидим, как она попадает в кэш.
Но наверняка вы бы предпочли сами увидеть всю анимацию!

Вы также можете поиграть с уже готовым кодом, но учтите, что это не спортивно.
Когда вы просматриваете записанный GIF, может показаться несколько странным, что иногда следующий токен не отображается (например, в самом начале стек увеличивается на несколько записей до того, как обнаруживается токен 'aap'). Это именно то, что анализатор видит: буфер токенов заполняется лениво. Токены не сканируются, пока синтаксический анализатор не запросит их, вызвав функцию expect(). Как только токен попадает в буфер, он же там и остаётся, даже если анализатор отматывает последовательность токенов назад. Обратный трекинг показывается в буфере токенов курсором, который прыгает влево; на записи много таких ситуаций. Вы также можете наблюдать за заполнением кэша, когда анализатор не делает дополнительных рекурсивных вызовов. (Я должен выделить, когда это происходит, но у меня не хватило времени.)
На следующей неделе я буду развивать синтаксический анализатор, возможно, добавив свой взгляд на левые правила рекурсивной грамматики. (Они великолепны!)
Благодарности: для записи я использовал ttygif от Ильи Чоли и ttyrec от Мэтью Йординга.
Лицензия на эту статью и приведенный код: CC BY-NC-SA 4.0


{kind=link}