Современные процессоры суперскалярны, то есть способны выполнять несколько инструкций одновременно. Например, некоторые процессоры могут обрабатывать за цикл от четырёх до шести инструкций. Более того, многие такие процессоры способны инициировать команды не по порядку: они могут начать работать с командами, расположенными в коде намного позже.
В то же время, код часто содержит ветвления (операторы
if–then). Такие ветвления часто реализуются как «переходы», при которых процессор или переходит к выполнению инструкции ниже по коду, или продолжает текущий путь.При суперскалярном выполнении команд вне порядка с ветвлениями справляться сложно. Для этого у процессоров имеются изощрённые блоки предсказания ветвления. То есть процессор пытается предсказать будущее. Когда он видит ветвление, а значит, переход, то пытается догадаться, каким путём пойдёт программа.
Очень часто это работает достаточно хорошо. Например, большинство циклов реализовано как ветвления. В конце каждой итерации цикла процессор должен предсказывать, будет ли выполняться следующая итерация. Часто для процессора безопаснее предсказать, что цикл будет продолжаться (вечно). В таком случае процессор ошибочно предскажет только одно ветвление на цикл.
Существуют и другие распространённые примеры. Если вы выполняете доступ к содержимому массива, то многие языки программирования перед совершением доступа к значению массива добавляют «контроль границ» (bound checking) — скрытую проверку правильности индекса. Если индекс неверен, то генерируется ошибка, в противном случае код продолжает выполняться обычным образом. Проверки границ предсказуемы, потому что в обычной ситуации все операции доступа должны быть правильными. Следовательно, большинство процессоров должно почти идеально предсказывать результат.
Что происходит, если ветвление сложно предсказать?
Внутри процессора все инструкции, которые были выполнены, но находятся на неверно предсказанном ветвлении, должны быть отменены, и вычисления необходимо начинать заново. Следует ожидать, что за каждую ошибку предсказания ветвления мы расплачиваемся более чем 10 циклами. Из-за этого время выполнения программы может возрасти в разы.
Давайте рассмотрим простой код, в котором мы записываем случайные целые числа в выходной массив:
while (howmany != 0) { out[index] = random(); index += 1; howmany--; }
Мы можем генерировать подходящее случайное число в среднем за 3 цикла. То есть общая задержка генератора случайных чисел может быть равна 10 циклам. Но наш процессор является суперскалярным, то есть мы можем выполнять одновременно несколько вычислений случайных чисел. Следовательно, мы сможем генерировать новое случайное число примерно каждые 3 цикла.
Давайте немного изменим функцию, чтобы в массив записывались только нечётные числа:
while (howmany != 0) { val = random(); if( val is an odd integer ) { out[index] = val; index += 1; } howmany--; }
Можно наивно подумать, что эта новая функция может быть быстрее. И в самом деле, ведь нам нужно в среднем записывать только одно из двух целых чисел. В коде есть ветвление, но для проверки чётности целого числа достаточно проверить один бит.
Я провёл бенчмарк этих двух функций на C++ на процессоре Skylake:
| Запись всех случайных чисел | 3,3 цикла на integer |
| Запись только нечётных случайных чисел | 15 циклов на integer |
Вторая функция работает примерно в пять раз дольше!
Можно ли тут что-нибудь исправить? Да, мы можем просто устранить ветвление. Нечётное целое число можно характерировать таким образом, что это побитовое логическое И со значением 1, равным единице. Хитрость в том, чтобы выполнять инкремент индекса массива на единицу, только если случайное значение нечётно.
while (howmany != 0) { val = random(); out[index] = val; index += (val bitand 1); howmany--; }
В этой новой версии мы всегда записываем случайное значение в выходной массив, даже если это не требуется. На первый взгляд, это пустая трата ресурсов. Однако она избавляет нас от ошибочно предсказанных ветвлений. На практике производительность оказывается почти такой же, как у первоначального кода, и намного лучше, чем у версии с ветвлениями:
| Запись всех случайных чисел | 3,3 цикла на integer |
| запись только нечётных случайных чисел | 15 циклов на integer |
| с устранённым ветвлением | 3,8 цикла на integer |
Мог ли компилятор решить эту проблему самостоятельно? В общем случае ответ отрицательный. Иногда у компиляторов есть опции полного исключения ветвлений, даже если в исходном коде есть оператор
if-then. Например, ветвления иногда можно заменить «условными перемещениями» (conditional move) или другими арифметическими трюками. Однако такие трюки небезопасны для использования в компиляторах.Важный вывод: ошибочно предсказанное ветвление — это не малозначительная проблема, оно имеет большое влияние.
Мой исходный код на Github.
Создание бенчмарков — сложная задача: процессоры учатся предсказывать ветвления
[Прим. пер.: эта часть была у автора отдельной статьёй, но я объединил её с предыдущей, потому что они имеют общую тему.]
В предыдущей части я показал, что большая часть времени выполнения программы может быть вызвана неверным предсказанием ветвлений. Мой бенчмарк заключался в записи 64 миллионов случайных целочисленных значений в массив. Когда я попробовал записывать только нечётные случайные числа, производительность из-за ошибочных предсказаний сильно снизилась.
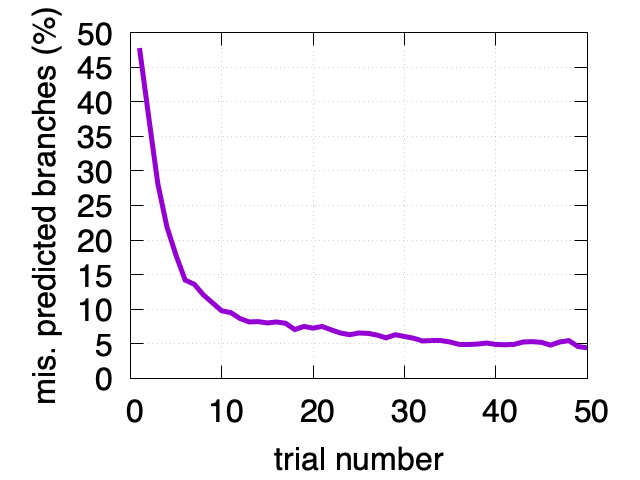
Почему я использовал 64 миллиона целых чисел, а не, допустим, 2000? Если выполнить всего один тест, то это не будет иметь значения. Однако что будет, если мы выполним множество попыток? Количество ошибочно предсказанных ветвлений быстро снизится до нуля. Показатели процессора Intel Skylake говорят сами за себя:
| Количество тестов | Неверно предсказанные ветвления (Intel Skylake) |
|---|---|
| 1 | 48% |
| 2 | 38% |
| 3 | 28% |
| 4 | 22% |
| 5 | 14% |
Как видно из показанных ниже графиков, «обучение» продолжается и дальше. Постепенно доля ошибочно предсказанных ветвлений падает примерно до 2%.
То есть если продолжить измерения времени, занимаемого одной и той же задачей, то оно становится всё меньше и меньше, потому что процессор учится лучше предсказывать результат. Качество «обучения» зависит от конкретной модели процессора, но стоит ожидать, что более новые процессоры должны учиться лучше.
Новейшие серверные процессоры AMD учатся почти идеально предсказывать ветвление (в пределах 0,1%) менее, чем за 10 попыток.
| Количество тестов | Неверно предсказанные ветвления (AMD Rome) |
|---|---|
| 1 | 52% |
| 2 | 18% |
| 3 | 6% |
| 4 | 2% |
| 5 | 1% |
| 6 | 0,3% |
| 7 | 0,15% |
| 8 | 0,15% |
| 9 | 0,1% |
Это идеальное предсказание на AMD Rome исчезает, если увеличить в задаче число значений с 2000 до 10 000: наилучшее предсказание меняется с доли ошибок в 0,1% до 33%.
Вероятно, стоит избегать бенчмаркинга кода с ветвлением на малых задачах.
Мой код на Github.
Благодарность: значения по AMD Rome предоставлены Велу Эрваном.
Дополнительное чтение: A case for (partially) TAgged GEometric history length branch prediction (Seznec et al.)

