Однажды мы размышляли о рейтинге знаков зодиака среди Великих людей. Задачу выполнили и представляю результаты на ваш суд.
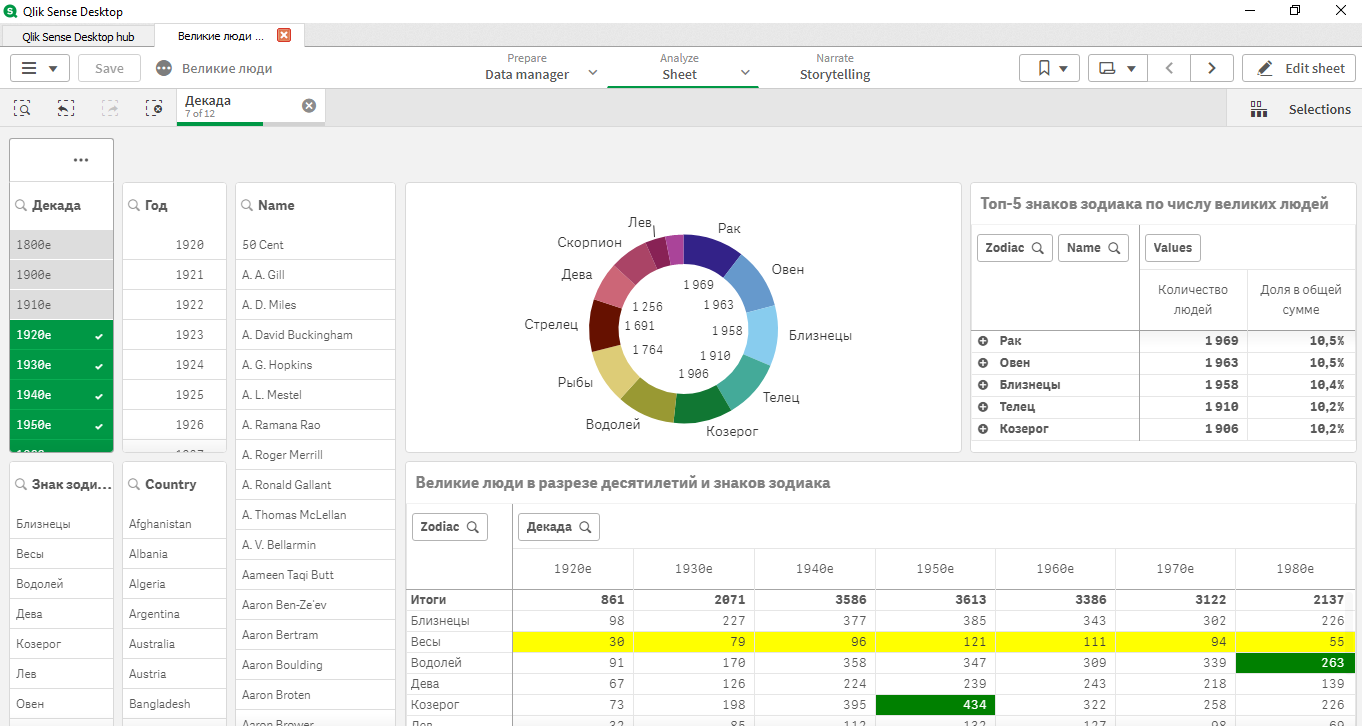
Со скорбью замечу, что Весы (ЭТО Я!) на последнем месте… Хотя что-то по данным мне кажется, что есть аномалии. Как-то подозрительно мало Весов!

Wikipedia List of lists of lists
на выходе нужна база с ФИО + дата рождения + (если есть любые другие признаки — например м/ж, страна и т.д.) есть API.
Данный сайт получилось поскрапить (харвестинг / получение / экстракт (извлечение) / сбор данных полученных с web-ресурсов) сайт при помощи Python библиотеки Scrapy.
Подробная инструкция
сначала получаются ссылки (листы с людьми с Википедии, а потом уже данные).
В других случаях парсили успешно вот так.
Результат: файл BD wiki.zip
Многие сталкиваются со сложностью обработки входных данных. Так в данной задаче нужно было вытащить из более 42 тысяч статей данные о рождении и по возможности определить страну рождения. С одной стороны, это – простая алгоритмическая задача, с другой стороны, средства Excel & BI систем не позволяют это выполнить «в лоб».
В такой момент на помощь приходят языки программирования (Python, R), запуск которых предусмотрен в большинстве BI систем. Стоит отметить, что, например, в Power BI существует лимит в 30 минут на выполнение скрипта (программы) на языке Python. Поэтому многие «тяжелые» обработки делают до запуска BI систем, например, в озере данных.
Первое, что сделал после загрузки и проверки на некорректные значения, было превратить каждую статью в список слов.
В этой задаче, мне повезло с языком, английским. Этот язык характеризует жесткая форма построения предложения, что значительно облегчило поиск даты рождения. Ключевое слово здесь «born», затем смотрится и анализируется что находится после него.
С другой стороны, все статьи были взяты из одного источника, что тоже облегчило задачу. Все статьи имели примерно одинаковую структуру и обороты.
Далее, все года имели длину в 4 символа, все даты имели длину 1-2 символа, месяцы имели текстовое представление. Было всего 3-4 возможных вариации написания даты рождения, что решалось простой логикой. Также можно было бы анализировать через регулярные выражения.
Настоящий код неоптимизирован (такой задачи не ставилось, может быть есть огрехи в наименованиях переменных).
По предсказанию страны, мне повезло найти таблицу соответствия стран и национальностей. Обычно в статьях описывается не страна, а принадлежность к ней. Например, Russia – russian. Поэтому производился поиск вхождений национальностей, но в виду, что в одной статье, могло быть более 5 разных национальностей, то я сделал гипотезу¸что нужное слово будет самым ближайшим из всех возможных к ключевому слову «born». Таким образом, критерий был – минимальное индексное расстояние между нужными словами в статье. Потом одной строкой делалось переименование из национальности в страну.
В статьях многие слова имели мусор, то есть к слову было соединено какой-то отрывок коды или два слова были слиты воедино. Поэтому проверка вероятности нахождения искомых значений в таких словах не производилась. Можно произвести очистку таких слов по алгоритмам степени похожести.
Не анализировались сущности, к которым относится ключевое слово «born». Были несколько примеров, когда ключевое слово относилось к рождению родственников. Этих примеров было ничтожно мало. Эти примеры можно отследить по факту, что ключевое слово находится далеко от начала статьи. Можно вычислить ��ерцентили нахождения ключевого слова и определить критерий отсечения.
Есть банальные случаи, когда мы можем точно предположить, что должно быть на месте пропусков. Но есть случаи, например, есть пропуски по гендерному признаку покупателя магазина и есть данные о его покупках. Стандартных приемов по решению этой задачи не существует в системах BI, но в тоже время, на уровне препроцессинга можно создать «легкую» модель и посмотреть различные варианты заполнения пропусков. Существуют варианты заполнения, основанные на простых алгоритмах машинного обучения. И это стоит использовать. Это не трудно.
Исходный код (Python) доступен по ссылке
Результат: файл out_data_fin.xls
Станислав Костенков / Компания «Си-Би-Эс Консалтинг» (Ижевск, Россия) staskostenkov@gmail.com
Дальше было сделано классическое приложение, где и выявились некие аномалии с датасетом:
Все данные (дата-сет, исходные данные, полученное приложение Qlik Sense для анализа данных) лежат по ссылке.
Скачать Qlik Sense можно по ссылке.
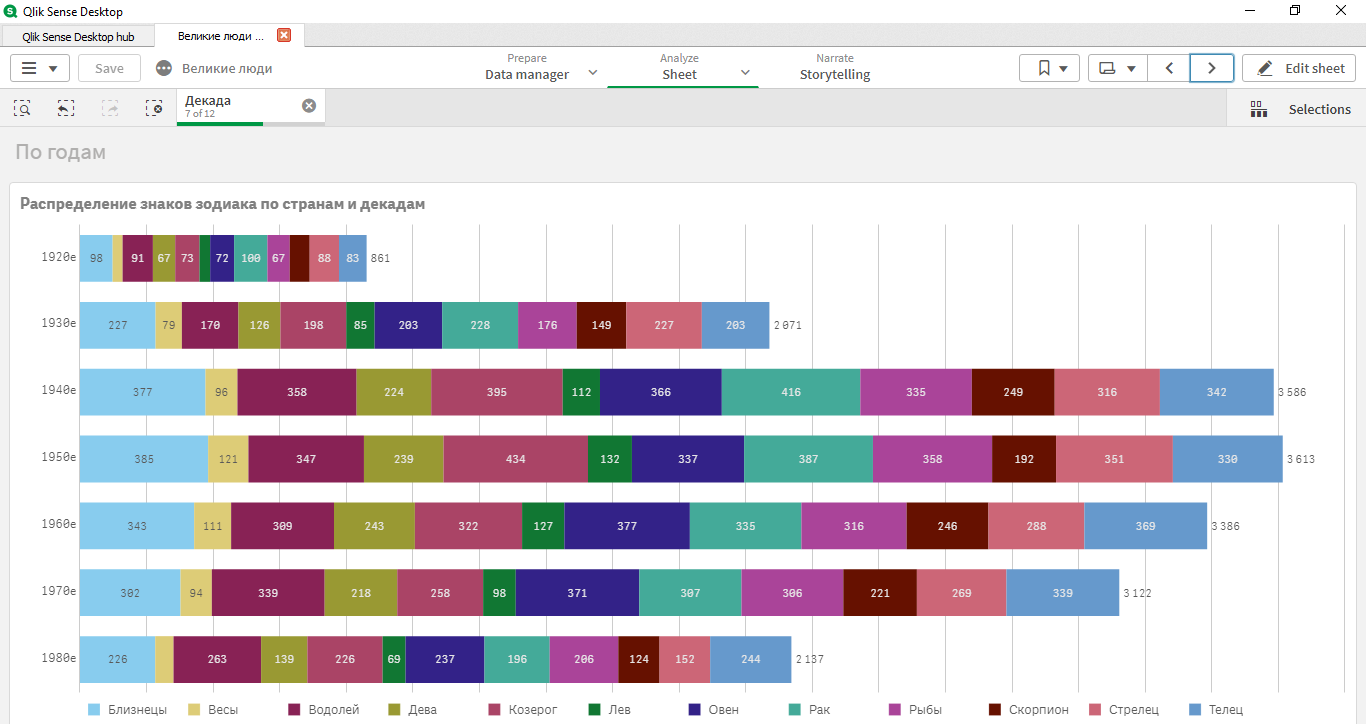
Со скорбью замечу, что Весы (ЭТО Я!) на последнем месте… Хотя что-то по данным мне кажется, что есть аномалии. Как-то подозрительно мало Весов!
Часть 1. Парсинг и получение исходных данных
Wikipedia List of lists of lists
на выходе нужна база с ФИО + дата рождения + (если есть любые другие признаки — например м/ж, страна и т.д.) есть API.
Данный сайт получилось поскрапить (харвестинг / получение / экстракт (извлечение) / сбор данных полученных с web-ресурсов) сайт при помощи Python библиотеки Scrapy.
Подробная инструкция
сначала получаются ссылки (листы с людьми с Википедии, а потом уже данные).
В других случаях парсили успешно вот так.
Результат: файл BD wiki.zip
Часть 2. О препроцессинге (выполнил Станислав Костенков — контакты ниже)
Многие сталкиваются со сложностью обработки входных данных. Так в данной задаче нужно было вытащить из более 42 тысяч статей данные о рождении и по возможности определить страну рождения. С одной стороны, это – простая алгоритмическая задача, с другой стороны, средства Excel & BI систем не позволяют это выполнить «в лоб».
В такой момент на помощь приходят языки программирования (Python, R), запуск которых предусмотрен в большинстве BI систем. Стоит отметить, что, например, в Power BI существует лимит в 30 минут на выполнение скрипта (программы) на языке Python. Поэтому многие «тяжелые» обработки делают до запуска BI систем, например, в озере данных.
Как решалась задача
Первое, что сделал после загрузки и проверки на некорректные значения, было превратить каждую статью в список слов.
В этой задаче, мне повезло с языком, английским. Этот язык характеризует жесткая форма построения предложения, что значительно облегчило поиск даты рождения. Ключевое слово здесь «born», затем смотрится и анализируется что находится после него.
С другой стороны, все статьи были взяты из одного источника, что тоже облегчило задачу. Все статьи имели примерно одинаковую структуру и обороты.
Далее, все года имели длину в 4 символа, все даты имели длину 1-2 символа, месяцы имели текстовое представление. Было всего 3-4 возможных вариации написания даты рождения, что решалось простой логикой. Также можно было бы анализировать через регулярные выражения.
Настоящий код неоптимизирован (такой задачи не ставилось, может быть есть огрехи в наименованиях переменных).
По предсказанию страны, мне повезло найти таблицу соответствия стран и национальностей. Обычно в статьях описывается не страна, а принадлежность к ней. Например, Russia – russian. Поэтому производился поиск вхождений национальностей, но в виду, что в одной статье, могло быть более 5 разных национальностей, то я сделал гипотезу¸что нужное слово будет самым ближайшим из всех возможных к ключевому слову «born». Таким образом, критерий был – минимальное индексное расстояние между нужными словами в статье. Потом одной строкой делалось переименование из национальности в страну.
Что не делалось
В статьях многие слова имели мусор, то есть к слову было соединено какой-то отрывок коды или два слова были слиты воедино. Поэтому проверка вероятности нахождения искомых значений в таких словах не производилась. Можно произвести очистку таких слов по алгоритмам степени похожести.
Не анализировались сущности, к которым относится ключевое слово «born». Были несколько примеров, когда ключевое слово относилось к рождению родственников. Этих примеров было ничтожно мало. Эти примеры можно отследить по факту, что ключевое слово находится далеко от начала статьи. Можно вычислить ��ерцентили нахождения ключевого слова и определить критерий отсечения.
Немного слов о полезности препроцессинга при очистке данных
Есть банальные случаи, когда мы можем точно предположить, что должно быть на месте пропусков. Но есть случаи, например, есть пропуски по гендерному признаку покупателя магазина и есть данные о его покупках. Стандартных приемов по решению этой задачи не существует в системах BI, но в тоже время, на уровне препроцессинга можно создать «легкую» модель и посмотреть различные варианты заполнения пропусков. Существуют варианты заполнения, основанные на простых алгоритмах машинного обучения. И это стоит использовать. Это не трудно.
Исходный код (Python) доступен по ссылке
Результат: файл out_data_fin.xls
Станислав Костенков / Компания «Си-Би-Эс Консалтинг» (Ижевск, Россия) staskostenkov@gmail.com
Часть 3. Приложение Qlik Sense
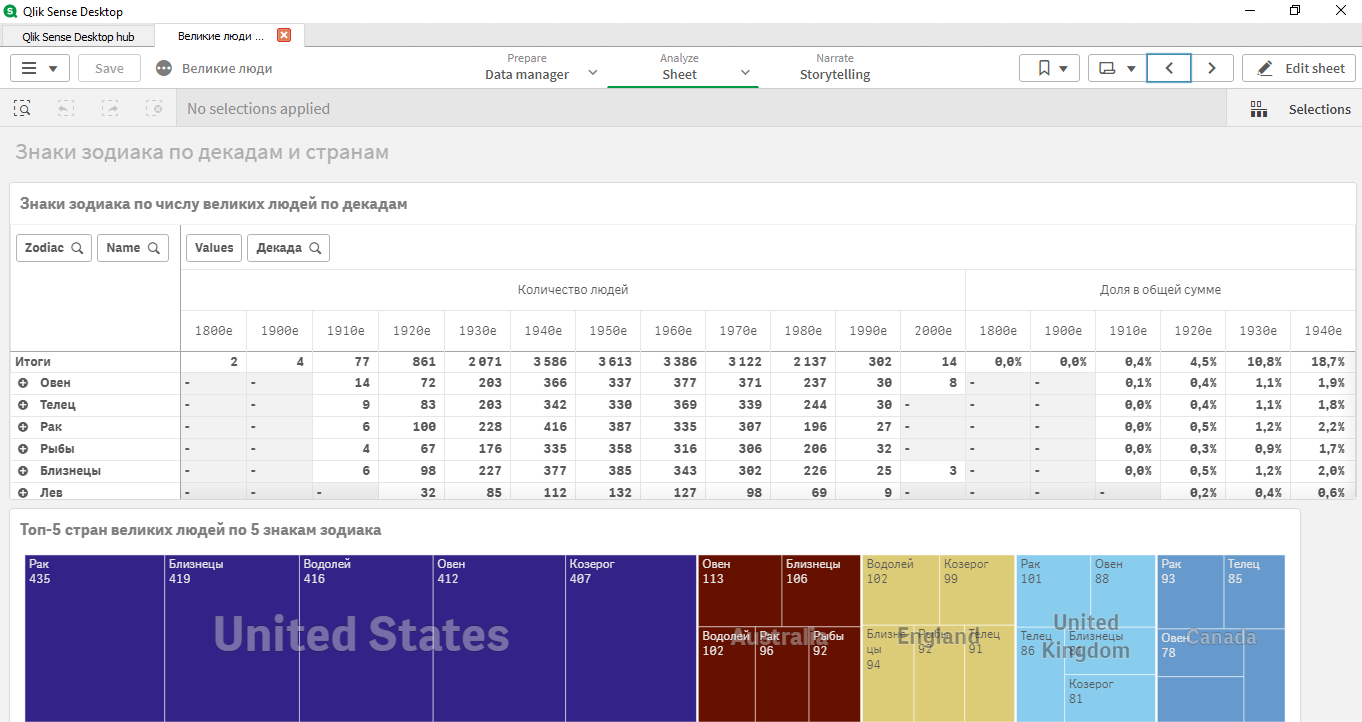
Дальше было сделано классическое приложение, где и выявились некие аномалии с датасетом:
- имело смысл выбирать только декады с 1920-1980;
- в разных странах были разные лидеры по знакам гороскопа;
- топ знаков: Рак, Овен, Близнецы, Телец, Козерог.
Все данные (дата-сет, исходные данные, полученное приложение Qlik Sense для анализа данных) лежат по ссылке.
Скачать Qlik Sense можно по ссылке.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Рейтинг знаков зодиака среди читателей habr
9.65%Овен58
7.65%Телец46
9.82%Близнецы59
11.15%Рак67
9.65%Лев58
4.99%Дева30
8.15%Весы49
8.49%Скорпион51
5.49%Стрелец33
7.82%Козерог47
9.65%Водолей58
7.49%Рыбы45
Проголосовал 601 пользователь. Воздержались 69 пользователей.

