
В user-generated проектах часто приходится бороться с дубликатами, а для нас это особенно актуально, так как основной контент мобильного приложения, которое я разрабатываю, — это изображения, которые постятся десятками тысяч ежедневно. Для поиска повторов мы написали отдельную систему, чтобы облегчить процесс и сэкономить море времени.
Под катом рассмотрим используемые инструменты, а потом перейдём к примеру реализации.
Свёрточная нейронная сеть (СNN)
Существует огромное количество различных алгоритмов поисков дубликатов, каждый со своими плюсами и минусами. Один из таких — поиск наиболее похожих (близких) векторов, полученных с помощью CNN-сетей.
После классификации изображения через CNN-сеть на выходе получается вектор «того, что увидела сеть на изображении». В теории такой способ должен быть менее чувствительным к кропу, но ложных похожих изображений будет больше в сравнении с более точными методами.
Есть и другой недостаток. На выходе классификации получается большой вектор (2048 float для resnet152), который где-то нужно хранить и иметь возможность за разумный промежуток времени найти все N похожих векторов для искомого — что само по себе уже непросто.
FAISS
Поиск наиболее близких векторов — частая задача, для решения которой уже есть отличные инструменты. Здесь лидером считается библиотека FAISS от Facebook. Она использует эффективную кластеризацию векторов, позволяя организовывать поиск даже для векторов, которые не помещаются в RAM.
Но с FAISS напрямую работать не очень удобно. Это не база данных, нельзя туда просто сохранить вектор и запросить похожий (к тому же, после создания индекса его можно только пересоздать). Поэтому для промышленной эксплуатации нужно строить свою обвязку вокруг системы индексации.
Milvus
Для этого есть весьма перспективный проект Milvus, который по дизайну сильно напоминает Elasticsearch. Отличие только в том, что Elasticsearch построен вокруг индекса lucene, а в Milvus вся архитектура выстроена вокруг индекса FAISS.
Структура коллекций тоже схожа:
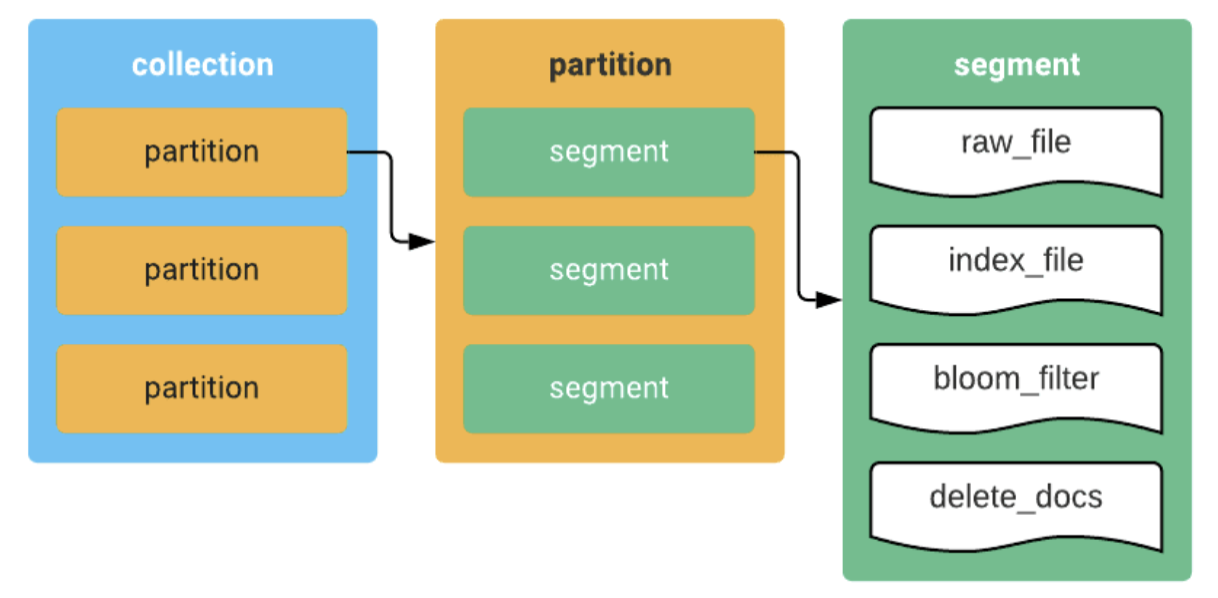
Для каждой коллекции можно создать несколько партиций, по которым потом будет ограничиваться поиск. Партиция состоит из сегментов, которые представляют из себя простой набор файлов с id, исходными индексами и служебными данными.
Информация о коллекциях, партициях и сегментах хранится в отдельной SQL-базе. Для standalone-запуска используется встроенный SQLite, а ещё есть возможность использовать внешнюю MySQL-базу.

Проект Milvus находится в активной разработке (текущая версия 0.11.0). Пока что в нём нет репликации данных, как и возможности использовать другие SQL (или NoSQL) базы в качестве хранилища метаинформации. Поэтому пока для HA-решений можно использовать только схему с двумя экземплярами с общим хранилищем: один будет запущен, а другой — «спать». Для масштабирования можно будет использовать Mishards, но в 0.11.0 он сломан.
Кроме того, в 0.11.0 появилась возможность вместе с самим вектором и id сохранять в коллекцию дополнительные данные. Правда, пока без дополнительных индексов для них, но с возможностью поиска.
С точки зрения использования, Milvus выглядит как обычная внешняя база данных. Есть API (gRPC-клиент и набор http-методов) для сохранения и поиска вектора, управления коллекциями и индексами, а также для получения информации обо всех сущностях.
При создании коллекции можно указать максимальное количество записей в сегменте (segment_row_limit). Если превысить этот лимит, то Milvus начнёт строить индекс FAISS. С этим связана одна из особенностей Milvus: для всех добавляемых векторов, по которым ещё не создан индекс, поиск будет работать на основе полного перебора. Поэтому при больших значениях segment_row_limit будет много записей, для которых индекс ещё не построен (он также влияет ещё и на то, сколько будет созданных сегментов для коллекции). Для поиска похожих векторов в коллекции необходимо сделать поиск в каждом сегменте — и чем их больше, тем дольше поиск.
Обратите внимание, новый созданный сегмент не набивается до лимита при добавлении новых записей. Вместо этого происходит постепенное объединение сегментов по принципу игры 2048 (до тех пор пока размер не превысит лимит). Поэтому при указании большего значения segment_row_limit может оказаться много меньших сегментов, для которых нет индекса, а значит поиск по ним будет медленным.
Несмотря на все особенности, поиск по векторам работает быстро. Архитектура индексов FAISS и самого Milvus позволяет за раз искать одновременно значения по нескольким векторам. И на практике последовательный поиск двух векторов будет существенно медленнее поиска обоих векторов за раз.
Реализация поиска дубликатов
Milvus можно запускать как в CPU-версии, так и в GPU. Первую лучше всего использовать на процессорах, которые поддерживают инструкцию AVX512. Для этого достаточно просто запустить контейнер:
docker run -d --rm --name milvusdb -p 19530:19530 -p 19121:19121 \ milvusdb/milvus:0.11.0-cpu-d101620-4c44c0
В данном случае 19530 будет портом для gRPC-клиента, а 19121 — для http API.
В качестве CNN-сети можно взять любую из предобученных (или обучить самому) — результаты могут немного отличаться. В данном примере будем использовать предобученный resnet152:
model = models.resnet152(pretrained=True)
Вектор будем снимать со слоя `avgpool`:
layer = model._modules.get('avgpool')
А сам вектор получать с помощью hook:
vector = torch.zeros(2048) def copy_data(m, i, o): vector.copy_(torch.reshape(o.data, (1, 2048))[0]) hook = layer.register_forward_hook(copy_data) model(prepared_image) hook.remove()
Полный код получения вектора выглядит так:
import numpy as np import torch import torchvision.models as models import torchvision.transforms as transforms from torch.autograd import Variable from PIL import Image model = models.resnet152(pretrained=True) layer = model._modules.get('avgpool') model.eval() pipeline = [ transforms.Resize(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ] def _prepare_Image(img: Image) -> Variable: raw = img for action in pipeline: raw = action(raw) return Variable(raw.unsqueeze(0)) def image_vectorization(image_path: str) -> np.ndarray: img = Image.open(image_path) prepared_image = _prepare_Image(img) vector = torch.zeros(2048) def copy_data(m, i, o): vector.copy_(torch.reshape(o.data, (1, 2048))[0]) hook = layer.register_forward_hook(copy_data) model(prepared_image) hook.remove() # vector normalization norm_vector = vector / torch.norm(vector) return np.array(norm_vector)
Теперь понадобится клиент для работы с Milvus. Можно взять любой из поддерживаемых (Python, Java, Go, Rest, C++). Возьмём Java-клиент и напишем пример на Kotlin. Почему? А почему бы и нет.
Подключаем Milvus SDK:
implementation("io.milvus:milvus-sdk-java:0.9.0")
Создаём подключение к Milvus:
val connectParam = ConnectParam.Builder() .withHost("localhost") .withPort(19530) .build() val client = MilvusGrpcClient(connectParam)
Создаём коллекцию под 2048 вектор:
val collectionMapping = CollectionMapping.create(collectionName) .addVectorField("float_vec", DataType.VECTOR_FLOAT, 2048) //выключаем автосоздание id .setParamsInJson(JsonBuilder() .param("auto_id", false) .param("segment_row_limit", segmentRowLimit) .build() ) client.createCollection(collectionMapping)
Создаём IVF_SQ8 индекс:
Index.create(collectionName, "float_vec") .setIndexType(IndexType.IVF_SQ8) .setMetricType(MetricType.L2) .setParamsInJson(JsonBuilder() .param("nlist", 16384) .build() ) client.createIndex(index)
Сохраняем несколько векторов в коллекцию:
InsertParam.create(collectionName) .setEntityIds(listOf(1L, 2L)) .addVectorField("float_vec", DataType.VECTOR_FLOAT, listOf(vector1, vector2)) client.insert(insertParam) client.flush(collectionName) // чтобы сразу можно было найти вектор
Ищем ранее сохранённый вектор:
val dsl = JsonBuilder().param( "bool", mapOf( "must" to listOf( mapOf( "vector" to mapOf( "float_vec" to mapOf( "topk" to 10, "metric_type" to MetricType.L2, "type" to "float", "query" to listOf(vector1), "params" to mapOf("nprobe" to 50) ) ) ) ) ) ).build() val searchParam = SearchParam.create(collectionName) .setDsl(dsl) val result = client.search(searchParam) println(result.queryResultsList[0].map { it.entityId to it.distance })
Если всё работает и правильно настроено, то вернётся похожий результат:
[(1, 0.0), (2, 0.2)]
Для первого вектора расстояние L2 с самим собой будет 0, а с другим вектором — больше 0.
Всё вышеприведённое, конечно, только наброски, но этого достаточно, чтобы попробовать создать Python-сервис для классификации и получения вектора. И либо для него накрутить API для сохранения и поиска векторов, либо сделать в отдельном сервисе (например, на Kotlin), который будет получать вектор и сохранять его уже в Milvus самостоятельно.
Спасибо всем, кто дочитал до конца, надеюсь, вы нашли для себя что-то новое. А если вас заинтересовал проект Milvus, то можете поддержать его на Github.

