
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Забавно, что иногда такие задачи в ИТ встречаются: например, как на лету прочитать дамп ffmpeg vstats при условии, что он пишется исключительно в файл (в стандартный выхлоп не умеет).
И первой мыслью в ответе на вопрос статьи у меня было "никак" (довольно сложно совершить переход от неприятия идиотизма задачи к первому решению, хотя дальше уже ход мысли понятен).
И да, в других сферах жизнидеятельности вряд ли найдется человек, который удалит гланды с помощью разложения синуса суммы углов)
Если вы не можете придумать реальную задачу
Если ваша реальная задача сводится к тому, чтобы заниматься таким вот извращением, возможно вам стоит отойти на шаг подальше, и понять где именно вы свернули не туда
На объяснение «реальной задачи» может уйти 10 минут. И если я уже знаю, что «реальная задача» сводится к «найти наибольший элемент в массиве без использования оператора сравнения» — то я сэкономлю 10 минут и дам сразу задачу в сжатом виде.Способность декомпозировать задачу до уровня простых алгоритмов так явно не проверить. Джунов имеет смысл так проверять, но только их, кмк.
Способность декомпозировать задачу до уровня простых алгоритмов так явно не проверить. Джунов имеет смысл так проверять, но только их, кмк.
Из решений "в лоб" — присваивать каждому значению элемент массива с индексом его значения и выводить "последний элемент", но с кучей ограничений — как минимум, значения целочисленные, а интепретатор языка располагает элементы массива в порядке возрастания индекса (оба упомянутых ограничения — весьма трудновыполнимы, в общем случае).
Ну вообще-то, такая программа как tail именно это и делает, читает в свой stdout всё что валится в файл.
в стандартный выхлоп не умеет
fmpeg -i input.mp3 2>&1Так что по факту это просто ИБД
К сожалению, даже я, практически не имеющий опыта "боевой" разработки, сталкивался с ситуациями, когда кандидату нельзя показывать боевые примеры кодинга. Безопасность через неясность — всё ещё популярный механизм. Увы.
Мне кажется, в данном случае проверялось, нет ли у собеседуемого склонности к решению задач "на отвали" через максимально формальную трактовку ТЗ.
Если 5 разных способов на самом деле разные, то ок.
Если 5 способов это почти копии одного (5 вычислений через минусы со сменой знака в конце, например), то не ок.
Ну и промежуточные вариации.
Правильный ответ на вопрос "как?" не может быть дан при неимении ответа на вопрос "зачем?".
"Задача - удалить гланды. Условие - через рот нельзя."
Сложить два целых числа (от 1 до 99) без использования оператора 'плюс'
Правильный ответ - после первого вопроса встать и уйти. Не дай Б-г еще возьмут на саппорт уже написанного в этом духе.
a = 15
b = 24
for bv in range(200, 0, -1):
if bv-a == b:
break
print(bv)
3. табличное сложение — предварительно в коде размещаем таблицу 99x99 — где каждый элемент является сложением индеска.
Можно отсортировать аргументы (if (a > b) swap(a, b);) и оптимизировать таблицу.
«Сложить два целых числа (от 1 до 99) без использования оператора 'плюс'. Дайте пять разных ответов»
if a<>b then
writeln((a*a-b*b) div (a-b))
else
writeln(a*2);writeln(a*2 - (a-b));Ну так неинтересно. Вот если бы у вас не было ADD/SUB в доступном подмножестве ассемблера...
Есть такие задачки, до сих пор помню code challenge 15-летней давности, который меня выбил на неделю
язык: asm
набор инструкций: I 386**
цель: написать DOS программу (.com), которая принимает на стандартный вход 1 байт (число 0-255) и выводит в стандартный вывод N знаков $, где N - число на входе, после чего завершается с кодом 0
критерий оценивания: побеждает программа минимального размера
** ну, и маленький нюанс: нельзя использовать команды условного перехода (jz, je, jne и т.п.), нельзя использовать арифметику (add, sub, inc, dec, mul, div), в том числе адресную арифметику (lea, dword ptr [eax + 4] и т.п.)
Победила программа размером (кажется) 19 байт
Ну да, предыдущий программист грепнул исходники предпредыдущего и сказал, что слишком много плюсов, вот код так плохо и работает.
Правда за полгода так и не смог наладить, мы его уволили.
auto start = now();
sleep(a);
sleep(b);
return now() - start;Вот вам задачка для собеседования:
Попробуйте объяснить с точки зрения здравого смысла, почему разработчик системы поставил ограничение на длину пароля сверху:
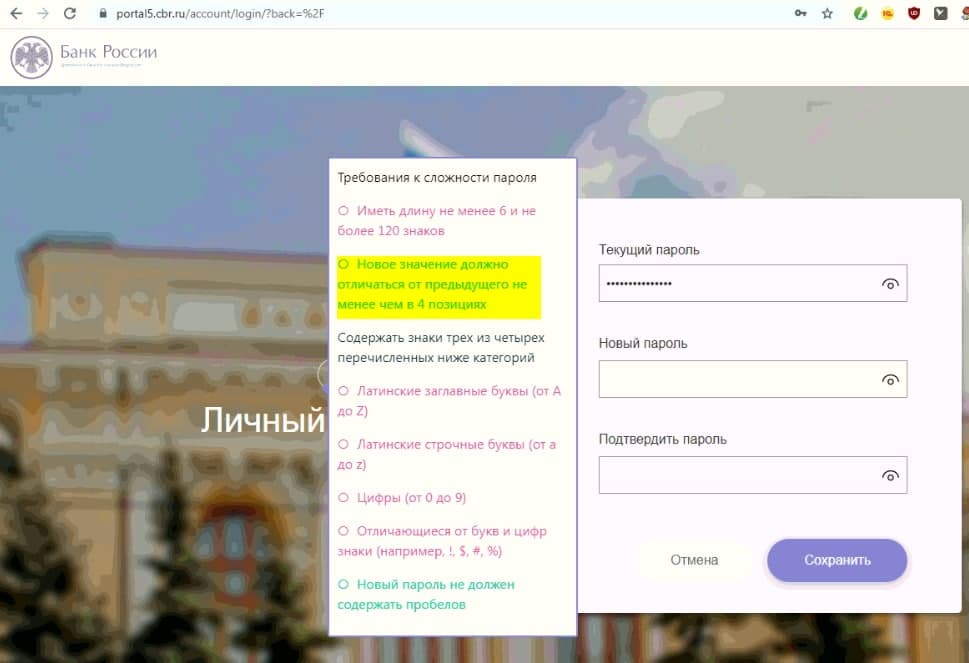
почему разработчик системы поставил ограничение на длину пароля сверху
Длина СМС?
Попробуйте объяснить с точки зрения здравого смысла, почему разработчик системы поставил ограничение на длину пароля сверху:
Аккуратнее в выражениях, времена нынче такие, что Вас легко могут привлечь по статье "Разжигание профессиональной розни к социальной группе 'Разработчики-родственники чиновников госструктур'".
Причём по этапу пойдёте и Вы, как комментатор, и я, как parent-комментатор, и автор поста.
Да и вообще все, кто открыл эту страницу.
Боится SQL injection :D с учетом "не пихайте пробелы в пароль"
Про 120 не знаю, знаю про 72 из своего дивного доисторического опыта в php :) Blowfish и bcrypt игнорируют остальные символы. Может что-то подобное и про 120 есть.
Кажется, на польском тикетмастере, ограничение на длину пароля при регистрации - 20 символов, но на самом деле запоминает он только 16. Об этом он тебе любезно сообщает аж на странице смены пароля, когда ты его сбросишь, потому что не можешь залогиниться с _только что_ заведённым аккаунтом. Очень увлекательный UX
Универсальное правило для подобных головоломок и собеседований:
В любой непонятной ситуации говори: «lookup-таблица»! (И начинай думать, как её применить).
Сделать список из чисел от 1 до 189 и итерироваться по нему b раз, начиная с позиции а :)
(типа сложение по аксиомам Пеано)
Вот мои решения, несколько из которых, правда, есть здесь.
def add0(a, b):
return a - (-b)
# =======================================
def add1(a, b):
return a.__add__(b) # a.__radd__(b)
# =======================================
def add2(a, b):
def inc(a):
return -(a ^ (-1))
bin_a, bin_b = bin(a)[:1:-1], bin(b)[:1:-1]
res_len = inc(max(len(bin_a), len(bin_b)))
res = '0' * res_len
bin_a = f'{bin_a}{"0" * (res_len - len(bin_a))}'
bin_b = f'{bin_b}{"0" * (res_len - len(bin_b))}'
zz, zos, oo = ('0', '0'), [('1', '0'), ('0', '1')], ('1', '1')
for (i, (ba, bb)) in enumerate(zip(bin_a, bin_b)):
if (ba, bb) == zz:
continue
elif (ba, bb) in zos:
if res[i] == '0':
res = f'{res[:i]}1{res[inc(i):]}'
else:
res = f'{res[:i]}01{res[inc(inc(i)):]}'
elif (ba, bb) == oo:
res = f'{res[:inc(i)]}1{res[inc(inc(i)):]}'
res = res[::-1]
return int(res, 2)
# =======================================
def add3(a, b):
if a == b:
return 2 * a
m = max(a, b)
for z in range(m ** 2):
if z - a - b == 0:
return z
# =======================================
def add4(a, b):
if a == b:
return a * 2
import math
a, b = min(a, b), max(a, b)
c2 = round((b / math.cos(math.atan(a/b)))**2)
a2b2 = c2 - 2 * a**2
return a2b2 // (b - a)
# =======================================
def add5(a, b):
# Свернул для комментария, для ответа развернуть в
# {(1, 1): 2, (1, 2): 3, (1, 3): 4, (1, 4): 5, (1, 5): 6, ...}
all_results = {(a, b): a + b for a in range(1, 100) for b in range(1, 100)}
return all_results[(a, b)]
def test(f):
test_flag = True
for a in range(1, 100):
for b in range(1, 100):
if f(a, b) != a + b:
test_flag = False
print('error in ', a, b, f.__qualname__)
return test_flag
for f in [add0, add1, add2, add3, add4]:
if test(f):
print(f.__qualname__, 'is good')
@sukhe Круто было бы на GitHub сделать репозиторий и в нем папочки для разных языков. И принимать туда pr)
range(max(a,b),a*b*2)[min(a,b)]from time import sleep, time
left, right = map(int, (input(), input()))
now = time()
sleep(left)
sleep(right)
new = time()
print(int(new - now))
Второй вариант, думаю, очевиден
Зря вы так все человечество под математиков подписали )
Подумал про три варианта, один - через побитовые операции автор описал, спасибо, + а ведь ещё есть
Модулярная арифметика, вангую, что можно через деление.
И еще регулярные выражения суть разложить число на цифры и собрать новое число. В принципе это можно сделать и без регулярное, токо много if или case будет
while (a--) b-=-1;
Есть мнение, что при всей своей долбанутости, данный вопрос всё же может оказаться полезным на собеседовании. Из того, как именно соискатель организует свой процесс поиска решения, можно сделать предположения о его профессиональных навыках.
Может я что упустил, но все предложенные решения так или иначе можно отнести к одной из групп, коих набирается как раз пять:
1. Математические. Эти решения не специфичны для Пайтона и для ЯП вообще. Сводятся к поиску выражения, не содержащего в себе знака "плюс", но дающего сумму аргументов на выходе. Здесь вычитание отрицательного числа, логарифм от произведения степеней и прочие варианты из комментариев.
2. Lookup-таблица с вычисленными заранее результатами.
3. Сокрытие вызова. Здесь мы на самом деле вызываем всё тот же add что и при использовании оператора "плюс", но делаем это без использования оператора. Решений также несколько, все они сильно зависят от конкретного ЯП.
4. Реализация сумматора. Сюда относятся решения со счётчиками, реализация двоичного сложения и прочее. Императивный подход, реализуемый на любом Тьюринг-полном ЯП, не завязан конкретно на Пайтон.
5. Использование внешнего источника. Реализация нужной операции берётся из среды выполнения — окружения или библиотек.
Бонусная шестая категория — "Индусский метод". Использование сайд-эффекта некой операции, слабо связанной с предметной областью, но в итоге дающей верный результат. По сути здесь будут решения из двух предыдущих категорий, но через подход "почесать правое ухо левой пяткой" — например суммирование чисел через запись в файл и получения длины файла.
Разные разработчики могут более уверенно себя чувствовать в одной категории решений, но плавать в другой. Плохое понимание математики помешает в первом случае, плохое знание Пайтона в третьем, неумение алгоритмически решать задачи — в четвёртом.
Теперь заменяем сложение на другую, более сложную операцию, которой и в самом деле нет в Пайтоне. Например, вычисление специфичное для предметной области приложения. Теперь задача превратилась в реальную — такую, которая действительно может встретиться в работе и иметь несколько вариантов решения. Можно было бы конечно сразу дать реальную задачу, но это потребовало бы нескольких часов для введения в предметную область, а лишнего времени на собеседовании нет. Поэтому соискателю предлагают простую альтернативу. Из того, какие решения разработчик выбирает с простым примером, можно предположить, что именно он будет делать со сложным.
plus = lambda a,b: (a==b) and 2*a or int((a**2-b**2)/(a-b))Вероятно "правильными" вариантами являются "минус на минус", сложение степеней, sum и, например, operator или eval, хотя мне больше нравится по длине строки. Это натолкнуло на ещё один простой ответ - цикл по b и a += 1, ведь это же другой оператор?
А если так, то можно и ещё проще: a += b
Видишь ошибку? Она здесь есть. И на интервью её заметят. Но не будем пока отвлекаться — в конце объясню.Это тестирование кратковременной памяти, или будет вторая статья в цикле?
Без плюса? Ха! Можно сложение сделать даже без самих чисел! :)
Правда, придётся написать функции, которые конвертируют числа в эти самые псевдочисла и обратно. Но в них можно обойтись без арифметических операций и числовых литералов.
Навскидку:
# Вспомогательная функция
rec = lambda f: f(f)
# Определение «числа»
zero = lambda: None
succ = lambda x: lambda: x
# Сложение «чисел»
add_num = rec(lambda r: lambda x, y: x if not y() else r(r)(succ(x), y()))
# Преобразование в «число»
to_num = lambda n: (lambda l: rec(lambda r: lambda a: succ(a) if not next(l) else r(r)(succ(a))))(iter(reversed(range(n))))(zero)
# Преобразование из «числа»
ln = lambda i: next(iter(next(iter(reversed(list(enumerate(i)))))))
from_num = lambda num: ln(rec(lambda r: lambda n, l: l if not n() else r(r)(n(), [*l, []]))(num, [[]]))
# Сложение
add = lambda x, y: from_num(add_num(to_num(x), to_num(y)))
# Проверяем
add(5, 3) # выведет 8Интересно, тот работодатель взял бы меня писать код в продакшен? :)
Сходу вспомнилось
abs(-a-b)
~(-a-b)+1
a = 7
b = 9
while a:
a = ~-a
b = -~b
print(b)
# 16«Три точки в первой строке — это Ellipsis?»
Да. Объект-заполнитель, который здесь используется вместо pass. Появился в последних версиях.
Точно версию не скажу, но в Python 2.7 многоточие уже было, но можно было использовать только при индексирования. Начиная с Python 3.0 (декабрь 2008 года) многоточие уже можно использовать как самостоятельный объект.
Ну и стоит добавить, конечно, что многоточие (объект) конечно же не является заменой pass (элемент синтаксиса) и вводился совсем для других целей.
Если у вас нету плюсов - пишите на чистом Си. Ну или собирайте компилятор плюсов самостоятельно)
Если у вас нет плюсов