
После запуска моделей на прод рано или поздно приходит понимание того, что Ваши сервисы популярны и что KPI растут. Вместе с популярностью приходят тормоза и нестабильность. В этой статье речь пойдет о прикладном аспекте оптимизации быстродействия алгоритмов/моделей на примере движка распознавания автомобильных номеров “Nomeroff Net”. Буду делиться опытом, полученным на протяжении 2-х летней разработки. Если коротко: нам удалось ускорить время распознавания 1 фото более чем в 10 раз.
“Чел догадался в свой сервер вставить RTX 3090” подумаете Вы… Приблизительно так и было, только если взять замеры до установки GPU то все ускорили в 100+ раз :).
Не будет детального описания архитектуры моделей (они давно известны в узких кругах), хочу поделиться важными моментами, на которые стоит обратить внимание при оптимизации ваших ML-сервисов.
Коротко о проекте
Я работаю в компании RIA.com. Самым большим проектом компании является онлайн классифайд AUTO.RIA.com. В день мы анализируем до 200 000 фото, на которых, в том числе, находим и считываем номерной(ые) знак(и). В 2018-2019 годах мы не нашли хорошего opensource-решения по распознаванию номеров, которое умело справляться с этой задачей. Основные проблемы, которые плохо решаются: чтение exUSSR-номеров с кириллицей, чтение номеров, которые сфотографированы “под наклоном” или с “перспективными искажениями”, чтение многострочных номеров (часто используются на спецтехнике, (мото/квадро)циклах, тракторах и так далее. В результате мы запилили небольшой движок под названием Nomeroff Net, с помощью которого научились полностью или частично вышеописанные проблемы решать. Протестировать как это работает можно прямо сейчас (сразу оговорюсь, что многострочные номера пока что читаются неважно)
Коротко об авторах
Сейчас основными разработчиками проекта являются Дмитрий Пробачай (
dimabendera ) и я (apelsyn), кроме того после публикации кода в opensorce на github нам оказали неоценимую помощь многие хабралюди: присылали датасеты, находили баги, писали отзывы и пожелания. Мы все читаем и стараемся на все отвечать. С радостью поможем вам натренировать датасет для Вашей страны, если в списке OCR-ок ее пока что нет.
Где обычно тормозит
Если говорить о железе, то узким горлышком является передача данных из RAM в GPU, и обратно.

При разработке “тяжелых” моделей мы часто наблюдали картину, при которой мы не могли загрузить GPU “на все деньги” по причине медленной передачи данных в видеопамять. Для более глубокого понимания проблемы рекомендую прочитать статью Dmitriy Vatolin 3Dvideo “Аппаратное ускорение глубоких нейросетей: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP и другие буквы”. Неожиданным тормозом может стать устройство хранения, на которое поступает контент для инференса. Обязательно обращайте внимание на iowait системы, где происходит загрузка/предпроцессинг фото, иначе может случиться так, что ваше приложение будет пребывать в бездействии, вызванном ожиданием операций ввода/вывода больше чем, собственно, сам инференс! Очень часто это неочевидно. Рядом с запущенными инстансами инференса в контейнерах или виртуалках может находиться контейнер с БД, которая утилизирует все ресурсы дисковой системы. Не будем погружаться в тему быстродействия железа, так как вижу что некоторые из вас начинают засыпать.
Предположим, что все «железячные» проблемы в вашей системе решены и мы приступаем к оптимизации приложения.
С чего мы стартовали
Первая версия-прототип показывала скорость детекции в районе 7s/фото (Без GPU и на весьма средненьком железе), поэтому этот замер не учитываем, начнем c того что пошло в продакшн на раннем этапе 840ms/фото. А хотелось меньше 100ms.
Ускоряем загрузку фото
Казалось бы, загрузка фото — это ж милисекунды, что тут оптимизировать? Не спешим с выводами, посмотрим на примере популярной библиотеки Pillow. Пробуем загрузить фото и получить матрицу для дальнейшей обработки нашей потенциальной моделью — пишем как-то так:
from PIL import Image im = Image.open('image.jpg') img = np.asarray(im)
По нашим замерам такая загрузка (в среднем) на тестовом наборе изображений показывает 59ms/фото. Получается в планируемых 100 ms большая часть времени будет потрачена на загрузку изображения в память приложения. Есть ли что-то получше? Ну конечно! OpenCV однозначно быстрее, в нашем тесте он выдает 50ms/фото, но суровые датасаентисты предпочитают TurboJPEG, в нашем случае средняя скорость загрузки изменилась до 23ms/фото (ускорение в 2.5 раза)
from turbojpeg import TurboJPEG jpeg = TurboJPEG() with open('image.jpg', 'rb') as in_file: img = jpeg.decode(in_file.read())
Ускоряем ресайзинг фото
Ну ресайзинг же точно не может тормозить, эти алгоритмы, наверное, писала еще Ада Лавлейс. Дело в том, что число анализируемых точек большое и ресайзинг может выполняться за время, сравнимое с инференсом. Не поверите, в некоторых случаях загрузка с ресайзингом осуществяется даже быстрее чем просто загрузка этого же фото (например, если надо грузить большое фото с уменьшением в 2, 4 или 8 раз).
from turbojpeg import TurboJPEG jpeg = TurboJPEG() with open('image.jpg', 'rb') as in_file: img = jpeg.decode(in_file.read()) # Only for scaling_factor (13, 8), (7, 4), (3, 8), (1, 2), (2, 1), (15, 8), (3, 4), (5, 8), (5, 4), (1, 1), (1, 8), (1, 4), (9, 8), (3, 2), (7, 8), (11, 8) img = jpeg.decode(in_file.read(), scaling_factor=(1, 2))
Но это частный случай для наших тестовых данных (да и уверен, что для ваших) наилучший результат дает комбинация в связке TurboJPEG+OpenCV.
from turbojpeg import TurboJPEG import cv2 jpeg = TurboJPEG() with open('image.jpg', 'rb') as in_file: img = jpeg.decode(in_file.read()) (width, height) = (img.shape[1] // 2, img.shape[0] // 2) img = cv2.resize(img, [width, height], interpolation = cv2.INTER_AREA)
Результаты замеров на наших данных
| Бибилотека | Среднее время загрузки + ресайзинг |
|---|---|
| Pillow | 86ms |
| OpenCV | 49ms |
| TurboJPEG+OpenCV | 23ms |
| TurboJPEG with resizing | 18ms |
UPD: В коментах excentro спрашивал об ускоренной версии Pillow — Pillow-SIMD, я добавил прогон тестов и с этой библиотекой. Она быстее чем OpenCV, но в 1.5 раза медленнее чем TurboJPEG.
Ускоряем поисковую модель
Итак, в предыдущих статьях (Часть 1, Часть 2), я уже писал как изначально предполагалось находить зону с номером: ищем бинарную маску, которая обрамляет контур номерного знака, потом с помощью инструментария OpenCV интерполируем, выравниваем и получаем 4 точки, которые описывают четырехугольник с номером.
В первой версии библиотеки мы попробовали несколько моделей, которые решают задачу Instance Segmentation (нахождение маску(и)), наиболее точный результат показала сеть Mask R-CNN.
Работает это приблизительно так:

Мы взяли реализацию Mask R-CNN на Tensorflow v1, размер картинки для детекции маски, которая поступала на вход сети, 1000x1000. Это работало, но общая средняя скорость детекции оставляла желать лучшего, в среднем 840ms/фото.
Так уж сложилось исторически, что основные успехи в ускорении движка у нас проходили небольшими иттерациями, которые будем называть «этапы».
Оптимизация: Этап 1
Первая мысль по оптимизации — уменьшить размер изображения, который поступает на вход сети, мы пожертвуем детекцией номеров на заднем плане, что для наших данных не принципиально, так как пользователи сайта выкладывают фото авто, как правило, на переднем плане. Экспериментально остановились на размере 800x800.

Оптимизация: Этап 2
Mask R-CNN это не самая быстрая реализация для задачи Instance segmentation, кроме того, она написана на устаревшем tensorflow v1, поэтому мы начали искать альтернативу, остановились на малоизвестной “CenterMask 2” на PyTorch, с размером изображения 800x800. Мы ускорились приблизительно в 3 раза до 230ms/фото, это был определенно прорыв! Уменьшилось не только время детекции номера, но и потребление видеопамяти.
Оптимизация: Этап 3
На момент перехода на CenterMask 2 у проприетарных решений от конкурентов средняя скорость детекции была около 100-200ms/фото и это означало, что наше решение все еще было достаточно “жирное”. Снижая размер изображения до 640x640, начинало страдать качество нахождения маски. Cмена бэкенда, эксперименты с другими фреймворками для нахождения маски существенно ситуацию не улучшили. Приложение оставалось жирным и неповоротливым, надо было что-то менять в архитектуре.
Рецепт в такой ситуации простой: берем самые бредовые идеи и не стесняясь пробуем. В конце то концов, отрицательный результат — тоже результат! Одной из таких идей был отказ от поиска маски в пользу нахождения bounding box-а (рамки) с номерным знаком, эта операция проходит в разы быстрее и имеет множество шикарных реализаций.
Остановились на YOLOv5, натренированная модель находит bounding box довольно быстро, осталось научиться внутри рамки правильно оценивать как расположен текст, чтоб его нормализовать и передать OCR-ке. Для этого был использован фреймворк CRAFT с небольшими доработками системы интерпретации результатов модели.
Также оказалось, что для нахождения bounding box-а можно было еще уменьшить размер изображения до 640x640 без заметной потери качества.
Эта идея, в конечном итоге, дала самый большой прирост производительности и мы вышли на среднее время < 100ms/фото.

OCR-модели на Nomeroff Net
Когда изображение с номерным знаком найдено и нормализовано, нам нужно его “прочитать”. В самой первой версии мы с этим не заморачивались и задействовали tesseract. Tesseract на выходе давал достаточно посредственное качество, это как у окулиста: читаешь нижнюю строчку, вроде все буквы увидел, но по факту половину не угадал.
Задумали написать свое, на начальном этапе идею подсмотрели в статье на сайте hackernoon.com, с приблизительно такой архитектурой
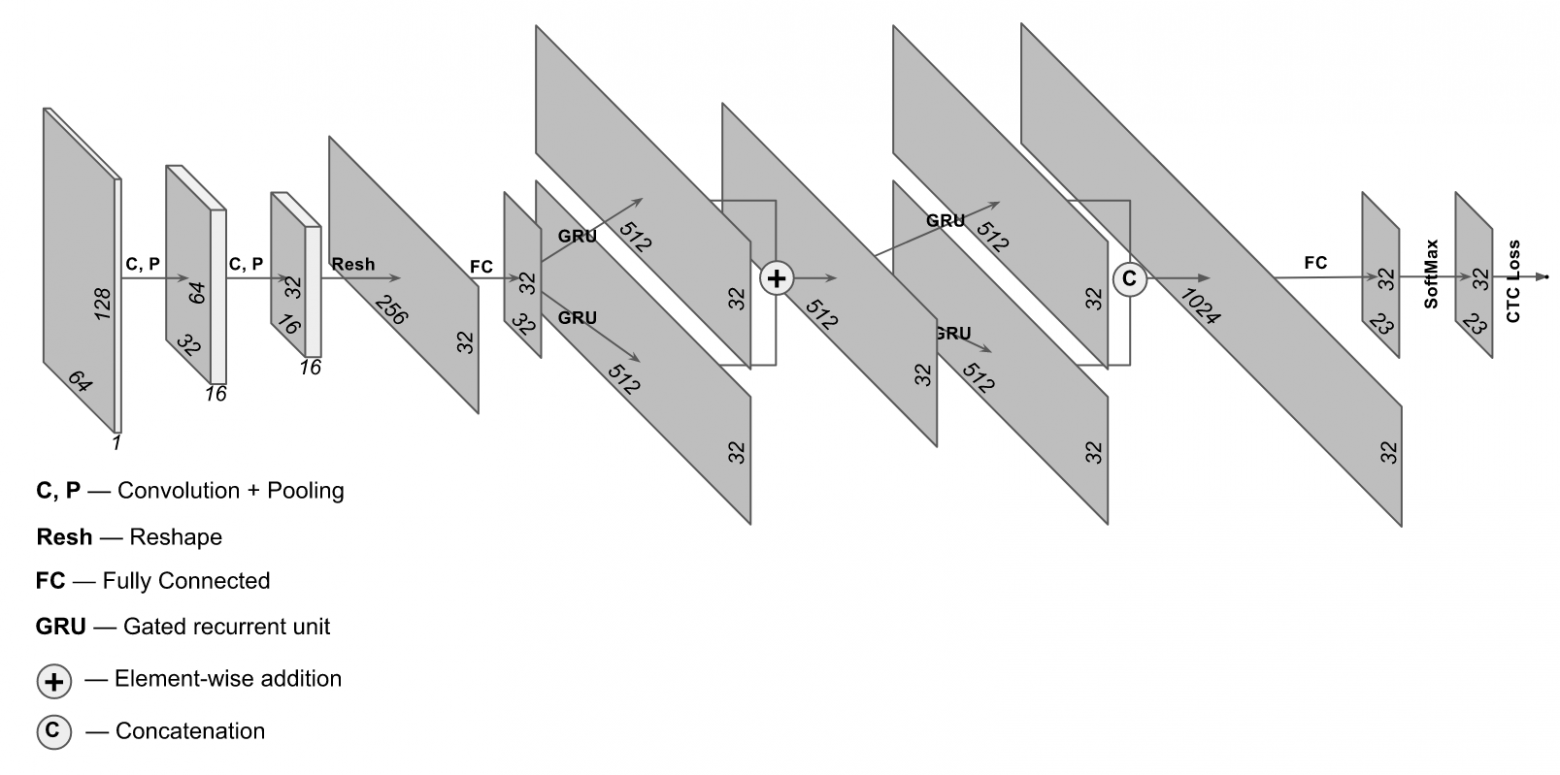
Первая реализация была tensorflow v1, потом tensorflow v2, сейчас все работает на pytorch. Модель работает быстро, речь идет о нескольких милисекундах, тут усилия были направлены на улучшение качества, которое для большинства моделей составляет 99%.
Классификатор номеров
Если номера могут быть нескольких типов (например, транзитные, exUSSR с кириллицей, европейские, ...) то это влечет за собой использование разных OCR для разных типов номеров. Перед OCR-кой для таких случаев мы поставили классификатор, сейчас это небольшая сверточная сеть на архитектуре resnet18. В качестве ускорения пробовали простую кастомную сеть на 4 свертки, но она давала немного хуже точность 98,5% против 96,6%. В результате решили пожертвовать 2 милисекундами и выбрали resnet18. Но если у вас Jetson Nano или Raspberry Pi 4, то я бы задумался над таким вариантом.

Прикручиваем TensorRT от NVIDIA
На разных этапах работы над Nomeroff Net мы пробовали задействовать TensorRT для оптимизации моделей. Например, инференс TensorRT-модели для YOLOv5 проходит быстрее и сама модель потребляет меньше видеопамяти, особенно это заметно на устройствах с небольшим числом CUDA-ядер (например на тестируемом Jetson Xavier прирост составил в среднем 10ms/фото). Были эксперименты и с конвертацией моделей в ONNX-формат, запуск через ONNX Runtime c бэкендом на TensorRT, но там прирост был малозаметен на наших моделях. Но попробовать под свои задачи однозначно рекомендуем.
Что еще бы помогло
Уверен, что есть еще несколько направлений, по которым можно продолжить оптимизацию. О некоторых хочу написать.
- YOLOv5: Мы выбрали среднюю по производительности модель (YOLOv5s), в угоду качеству и точности. Но если говорить о запуске распознавания на компактных устройствах, то можно попробовать менее точную, но зато более производительную версию YOLOv5n
- CRAFT: Это лучшее решение задачи line detection из тех, что мы протестировали, но не идеальное, как по качеству, так и по скорости. Возможно, попробуем перетренировать модель на ствоих данных.
- Определенное ускорение можно получить, обрабатывая фото батчами по n-фото, такой сценарий возможен, например, в случае получение фото с нескольких источников. Это могут быть камеры видеонаблюдения, с которых данные получаем в режиме онлайн или когда на систему распознавания номеров идет большой поток фото, которые можно сгрупировать на батчи. Мы планируем имплементровать этот подход в новой версии 3.0
Каков результат
На момент написания статьи (текущая версия Nomeroff Net 2.5) среднее время детекции 1 фото на наших данных на железе Intel® Core(TM) i9-9900K CPU @ 3.60GHz + NVIDIA RTX 3090 51,4ms/фото, также неплохие результаты получили на Jetson Xavier 284,7ms/фото, с TensorRT для YOLOv5 272ms/фото.
| Показатель | Intel® Core(TM) i9-9900K CPU @ 3.60GHz + NVIDIA RTX 3090 | Jetson Xavier | Jetson Xavier + TensorRT |
|---|---|---|---|
| One photo process | 51,4 ms | 284,7ms | 272ms |
| Image load | 19,5ms | 45,3ms | 44,7ms |
| YOLO detect bounding box | 9,3ms | 55,1ms | 44,5ms |
| Craft detection | 12,7ms | 125ms | 121,9ms |
| Perspective align | 1,9ms | 13,8ms | 13,9ms |
| Classification | 2,6ms | 23,4ms | 24,2ms |
| OCR detection | 3,3ms | 22,8ms | 22,5ms |
Нам удалось ускориться больше, чем на порядок, обратите внимание, что самая продолжительная операция по времени (около 20ms или 40% всей детекции) — загрузка фото, без TuboJPEG эти показатели были бы значительно хуже!
На втором месте по продолжительности выполнения находится применение модели CRAFT (около 12ms), мы уверены, что эту часть можно также ускорить. И если у нас получится это сделать, обязательно добавлю сюда результаты.
Спасибо за внимание, буду рад ответить на вопросы в комментариях.

