Модели трансформеров на данный момент являются state-of-the-art решениями в мире обработки естественного языка. Новые, более крупные и качественные модели появляются почти каждый месяц, устанавливая новые критерии производительности по широкому кругу задач. В данной статье мы будем использовать модель трансформера для бинарной классификации текста.

Для работы с текстом существует большое количество решений. Самая простая и популярная связка – TF-IDF + линейная модель. Данный подход позволяет обрабатывать и решать языковые задачи без особых затрат вычислительных ресурсов. Однако процесс использования такой связки требует дополнительных операций: чистка, лемматизация. В случае с BERT можно (даже нужно) опустить препроцессинг и сразу перейти к токенизации и обучению. Помимо дополнительных шагов, линейные модели часто выдают некорректные результат, так как не учитывают контекст слов. Понимание контекста является главным преимуществом трансформеров.
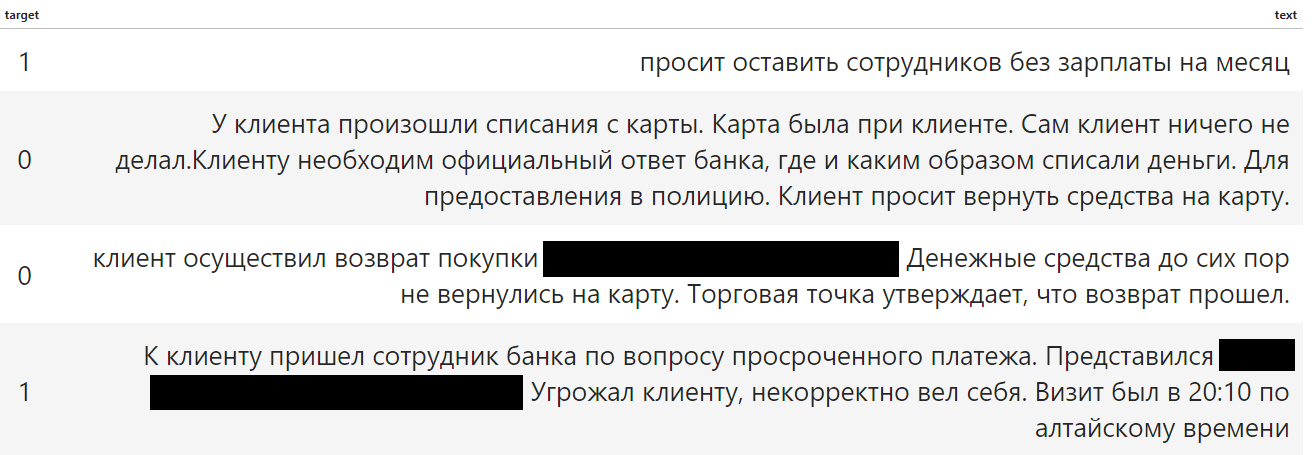
На входе имеются обращения пользователей на различные темы. Необходимо обучить модель находить обращения с жалобой на сотрудника или другими словами – бинарная классификация:
Для решения описанной задачи используется модель от DeepPavlov rubert-base-cased-sentence. Эта регистрозависимая модель, которую обучали на русском тексте.
Для начала импортируем необходимые для работы библиотеки и зададим начальные переменные:
import re import numpy as np import pandas as pd from tqdm import tqdm from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report, f1_score import torch import transformers import torch.nn as nn from transformers import AutoModel, BertTokenizer, BertForSequenceClassification from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler tqdm.pandas() device = torch.device('cuda')
Далее импортируем предобученную модель.
bert = AutoModel.from_pretrained('rubert_base_cased_sentence/') tokenizer = BertTokenizer.from_pretrained('rubert_base_cased_sentence/')
Для Bert не нужно проводить препроцессинг, поскольку он обучался на таких же грязных данных. Мои данные я заранее разбил на train / val / test выборки в пропорциях 60/20/20. Разобьем выборки на текст и таргет:
train_text = train_df['text'].astype('str') train_labels = train_df['target'] val_text = val_df['text'].astype('str') val_labels = val_df['target'] test_text = test_df['text'].astype('str') test_labels = test_df['target']
Следующий код выведет график длин предложений. Он поможет определить оптимальную длину последовательности токенов, чтобы избежать разреженных векторов.
seq_len = [len(str(i).split()) for i in train_text] pd.Series(seq_len).hist(bins = 50)
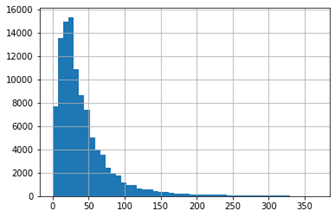
«На глазок» 50 токенов хватит. Токенизируем текста, передадим в тензоры и загрузим в функцию DataLoader, которая будет по частям подавать наши данные для обучения и валидации в модель:
tokens_train = tokenizer.batch_encode_plus( train_text.values, max_length = 50, padding = 'max_length', truncation = True ) tokens_val = tokenizer.batch_encode_plus( val_text.values, max_length = 50, padding = 'max_length', truncation = True ) tokens_test = tokenizer.batch_encode_plus( test_text.values, max_length = 50, padding = 'max_length', truncation = True ) train_seq = torch.tensor(tokens_train['input_ids']) train_mask = torch.tensor(tokens_train['attention_mask']) train_y = torch.tensor(train_labels.values) val_seq = torch.tensor(tokens_val['input_ids']) val_mask = torch.tensor(tokens_val['attention_mask']) val_y = torch.tensor(val_labels.values) test_seq = torch.tensor(tokens_test['input_ids']) test_mask = torch.tensor(tokens_test['attention_mask']) test_y = torch.tensor(test_labels.values) batch_size = 8 train_data = TensorDataset(train_seq, train_mask, train_y) train_sampler = RandomSampler(train_data) train_dataloader = DataLoader(train_data, sampler = train_sampler, batch_size = batch_size) val_data = TensorDataset(val_seq, val_mask, val_y) val_sampler = SequentialSampler(val_data) val_dataloader = DataLoader(val_data, sampler = val_sampler, batch_size = batch_size)
Сам BERT обучать не будем. Допишем к его выходу свои слои, которые и будем обучать на классификацию.
for param in bert.parameters(): param.requires_grad = False class BERT_Arch(nn.Module): def __init__(self, bert): super(BERT_Arch, self).__init__() self.bert = bert self.dropout = nn.Dropout(0.1) self.relu = nn.ReLU() self.fc1 = nn.Linear(768,512) self.fc2 = nn.Linear(512,2) self.softmax = nn.LogSoftmax(dim = 1) def forward(self, sent_id, mask): _, cls_hs = self.bert(sent_id, attention_mask = mask, return_dict = False) x = self.fc1(cls_hs) x = self.relu(x) x = self.dropout(x) x = self.fc2(x) x = self.softmax(x) return x
Объявим модель, загрузим ее в GPU. Импортируем оптимизатор.
model = BERT_Arch(bert) model = model.to(device) from transformers import AdamW optimizer = AdamW(model.parameters(), lr= 1e-3)
Для борьбы с дисбалансом классов используем следующий подход:
from sklearn.utils.class_weight import compute_class_weight class_weights = compute_class_weight('balanced', np.unique(train_labels), train_labels) print(class_weights) [0.8086199 1.31005794] weights = torch.tensor(class_weights, dtype = torch.float) weights = weights.to(device) cross_entropy = nn.CrossEntropyLoss() epochs = 20
Функция для обучения модели:
def train(): model.train() total_loss, total_accuracy = 0, 0 total_preds = [] for step, batch in tqdm(enumerate(train_dataloader), total = len(train_dataloader)): batch = [r.to(device) for r in batch] sent_id,mask,labels = batch model.zero_grad() preds = model(sent_id, mask) loss = cross_entropy(preds, labels) total_loss += loss.item() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() preds = preds.detach().cpu().numpy() total_preds.append(preds) avg_loss = total_loss / len(train_dataloader) total_preds = np.concatenate(total_preds, axis = 0) return avg_loss, total_preds
Функция валидации:
def evaluate(): model.eval() total_loss, total_accuracy = 0,0 total_preds = [] for step, batch in tqdm(enumerate(val_dataloader), total = len(val_dataloader)): batch = [t.to(device) for t in batch] sent_id, mask, labels = batch with torch.no_grad(): preds = model(sent_id, mask) loss = cross_entropy(preds, labels) total_loss = total_loss + loss.item() preds = preds.detach().cpu().numpy() total_preds.append(preds) avg_loss = total_loss / len(val_dataloader) total_preds = np.concatenate(total_preds, axis = 0)
Обучаем. Для лучшей метрики на валидации сохраняем веса:
best_valid_loss = float('inf') train_losses = [] valid_losses = [] for epoch in range(epochs): print('\n Epoch{:} / {:}'.format(epoch+1, epochs)) train_loss, _ = train() valid_loss, _ = evaluate() if valid_loss < best_valid_loss: best_valid_loss = valid_loss torch.save(model.state_dict(), 'saved_weights.pt') train_losses.append(train_loss) valid_losses.append(valid_loss) print(f'\nTraining loss: {train_loss:.3f}') print(f'Validation loss: {valid_loss:.3f}')
На данном этапе мы обучили модель и сохранили ее результат. Далее идет проверка на тестовой выборке и использование на боевых данных.
Загрузим лучшие веса для модели:
path = 'saved_weights.pt' model.load_state_dict(torch.load(path))
Видеопамяти не хватает для хранения всего что в нее передано, поэтому используем костыль. Разобьем тестовые данные на части и будем отправлять на предсказание по частям
import gc gc.collect() torch.cuda.empty_cache() list_seq = np.array_split(test_seq, 50) list_mask = np.array_split(test_mask, 50) predictions = [] for num, elem in enumerate(list_seq): with torch.no_grad(): preds = model(elem.to(device), list_mask[num].to(device)) predictions.append(preds.detach().cpu().numpy())
Преобразуем полученные предсказания в один список, нормализуем данные и запишем в новый столбик датафрейма.
flat_preds = [item[1] for sublist in predictions for item in sublist] flat_preds = (flat_preds - min(flat_preds)) / (max(flat_preds) - min(flat_preds)) test_df['confidence'] = flat_preds
На выходе мы получили значение с плавающей точкой от 0 до 1. Теперь меняя порог, мы сможем предсказать финальный класс:
test_df['pred'] = test_df['confidence'].apply(lambda x: 1 if x>0.92 else 0) print(classification_report(test_df['target'], test_df['pred'])) precision recall f1-score support 0 0.91 0.91 0.91 21831 1 0.85 0.85 0.85 13460 accuracy 0.89 35291 macro avg 0.88 0.88 0.88 35291 weighted avg 0.89 0.89 0.89 35291
На выходе мы получаем метрику f1 = 0.91 Посмотрим, как модель классифицировала данные показанные в начале статьи.
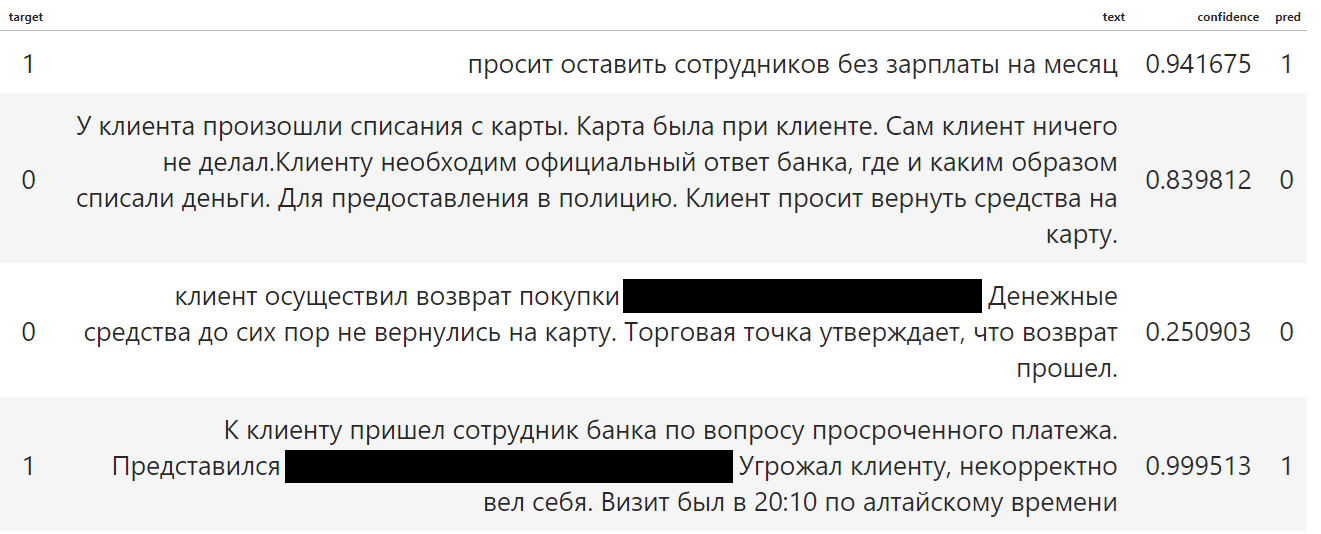
Модель корректно классифицировала случайно взятые примеры.
Вывод:
Обученные модели можно найти на сайтах HuggingFace и DeepPavlov. Сейчас популярно обучать трансформеры для решения сразу большого спектра задач. Пользователю остается лишь взять предобученную модель и доработать для своей конкретной проблемы.
В данной статье мы воспользовались моделью для работы с целыми предложениями и доработали ее для бинарной классификации. Помимо бинарной классификации указанную модель можно использовать для обычной классификации, изменив количество выходов, а также нахождения косинусного сходства между текстами. Обученный трансформер прекрасно обрабатывает смысл не просто предложений, а целых текстов.

