Хочу вам признаться: я довольно тревожный человек, и это качество не заканчивается личной жизнью, а перетекает на работу. От того, что я очень тревожный человек, мне все время хочется проверить, что все идет хорошо, что я нахожусь в конкретной точке, что впереди меня не ждет очень серьезная проблема, из которой будет сложно выбраться.

Поэтому я люблю метрики — они помогают убедиться в том, что все идет хорошо. О метриках отношений микросервисов и будет этот пост. Меня зовут Алексей Лашнев, я продуктовый разработчик в QIWI.
Метрики
Начнем с метрик кодовой базы. Как мы мы можем измерить качество кода? Для этого у нас есть инструменты вида SonarQube, по которым мы можем понять степень покрытия тестами нашего кода, какие-то code smells’ы — процент дублирования кода, уязвимости или баги. На основе этого принять решение — пора ли рефакторить наш код или нет.

В плане приложений мы можем посмотреть, например, CPU, вывести в Grafana процент занятой памяти, время ответа нашего сервиса и прочие полезности. Все это тоже даст нам возможность понять, что впереди намечается какая-то проблема и пора что-то делать. Например, если заканчивается оперативная память в приложении, то мы задумываемся о том, что приложение пора скейлить, и начинаем думать о том, можно ли вообще заскейлить приложение.

Но на этом метрики для приложений не заканчиваются. Мы можем вывести в Kibana количество ошибок и посмотреть, сколько их было, скажем, год назад, когда мы только написали сервис, и сколько их сейчас. Кроме этого, можно определить, что количество ошибок стало слишком большим, что невозможно вычленить какие-то серьезные оши��ки, или их в принципе стало очень много, и этот сервис тоже пора отрефакторить.
Вот ещё штуки, которые помогают нам оценивать качество кода и приложений.
Во-первых, практики по типу SOLID, The Twelve-Factor Applications — практики разработки кода через тестирование, соблюдая которые, мы можем добиться достаточно качественного кода и приложения. Во-вторых, шаблоны и принципы проектирования (DDD, чистая архитектура), применяя которые, мы можем писать понятные приложения и решать какие-то стандартные проблемы.

Однако большинство из всех нас работает в крупных компаниях, а там enterprise-приложения, которые редко бывают монолитными. Чаще всего для простоты их разбивают на модули. Вот и наши приложения разбиваются на модули — мы работаем с микросервисами.

Такая архитектура порождает вопросы.
Что мы можем сказать по поводу качества этих отношений между модулями? Как они связаны? Не превратилось ли это в паутину? Можно ли разобраться в вашей системе, состоящей из модулей? Если прийти к разработчику, который работает в этом продукте, с вопросом: “Все ли хорошо?”, он обычно скажет: “Никаких проблем нет, давайте пилить модули и сервисы дальше”.
Но чаще всего люди не замечают проблем, пока они не становятся очень серьезными. Вот как это бывает. Ты разработчик, тебе говорят, что нужно что-то поправить в каком-то legacy или старом сервисе. Ты залезаешь в этот сервис, ужасаешься и видишь, что там полная лапша, в нем невозможно что-то исправить. Ты говоришь: “Надо взять и переписать этот модуль с нуля”. Сделать это очень дорого для бизнеса с точки зрения упущенной выгоды и с точки зрения потраченного времени разработчиков.
Кстати, дорого это и для самих разработчиков: во-первых, потому что повторять функционал, который у вас уже был, неинтересно, во-вторых, потому что это демотивирует. Ведь получается, что ты, твоя команда и твой продукт недостаточно компетентны, что привело к тому, что твое приложение превратилось в спагетти, которое нужно взять и выкинуть.
Поэтому дальше мы будем говорить о качестве в модульных системах и как их измерить.
Я не зря упомянул выше принципы SOLID, их сформулировал известный разработчик дядя Боб или Боб Мартин. Я его поклонник и вырос как разработчик, смотря его лекции и вообще наблюдая за ним. Однажды я смотрел серию его лекций под названием “SOLID for components”, конкретно лекция называется “Component coupling”. В них дядя Боб формулирует принципы, по которым должны быть связаны ваши модули или сервисы.
Матчасть
Так как мы будем говорить о компонентах, сначала надо дать определение этому термину. Дядя Боб дает две характеристики для компонента в системе: независимая разработка и независимый deploy.

Это может быть DLL-файл, JAR-архив или, например, микросервис. Последний удовлетворяет этим требованиям, и дальше, когда я буду говорить о модуле, я буду иметь в виду микросервис, потому что мы в QIWI работаем с микросервисами.
Теперь надо уточнить, как вообще построить эти связи между приложениями. У нас в компании, так как мы работаем с микросервисами, есть Kubernetes, большинство приложений развернуто им. В Kubernetes есть ресурс под названием Network Policy Definition. Это конкретный файл yml, который лежит в коде самого приложения, где мы как разработчики прописываем, куда наше приложение должно ходить (в какой-то соседний модуль или в какую-то базу данных).

Соответственно, мы (разра��отчики) сами определяем, куда сервис может ходить. Также у нас есть внутренний инструмент под названием OpenSpace, который может построить связи между вашими приложениями, такой граф зависимостей. У вас, скорее всего, не так — у вас нет OpenSpace, раз вы не QIWI, поэтому я могу вам порекомендовать библиотеку Zipkin Dependency, которая строит аналогичные граф-зависимости между вашими приложениями на основе трассировки.

Итак, теперь у нас есть данные для анализа связей наших приложений, можно перейти к трем принципам и к тому, почему их надо соблюдать
Принципы
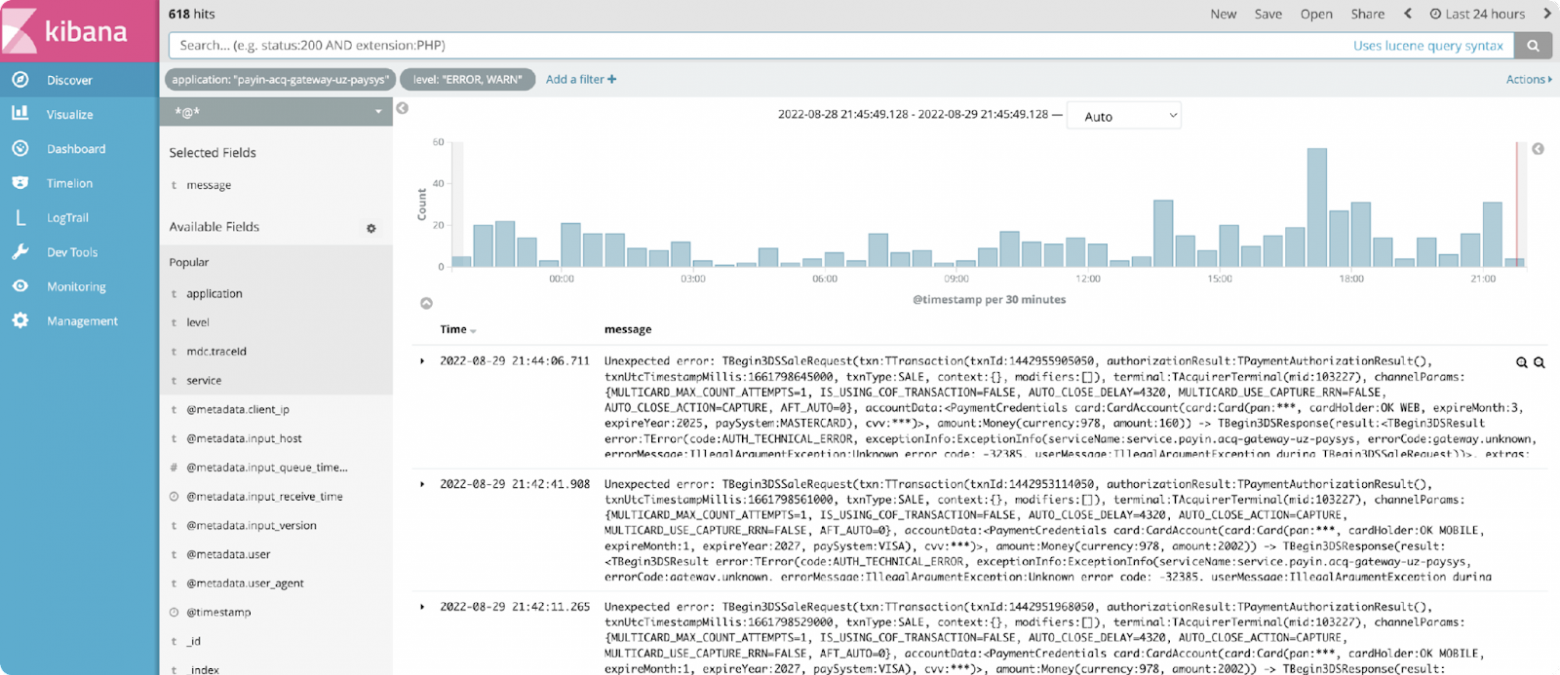
Первый принцип называется Acyclic Dependencies Principle, или принцип ациклической зависимости. Он звучит так: вся система должна быть ациклическим графом, где, выйдя из одного модуля, ты не можешь вернуться в него же.

А вот пример нарушения этого принципа.
Мы можем выйти из модуля api-gateway, прийти в модуль sbp, а затем через него вернуться в api-gateway, то есть у нас появляется циклический граф.
Почему плохо иметь граф зависимостей, содержащий циклы? Потому что тогда наше приложение начинает падать по каким-то неведомым причинам. Например, у нас падает приложение currencies, от него падает приложение api-gateway, и по цепочке от него может упасть приложение sbp. То есть, казалось бы, sbp не использует никакой функциональности currencies, но онo (приложение) транзитивно падает от того, что падает не связанное с ним приложение.
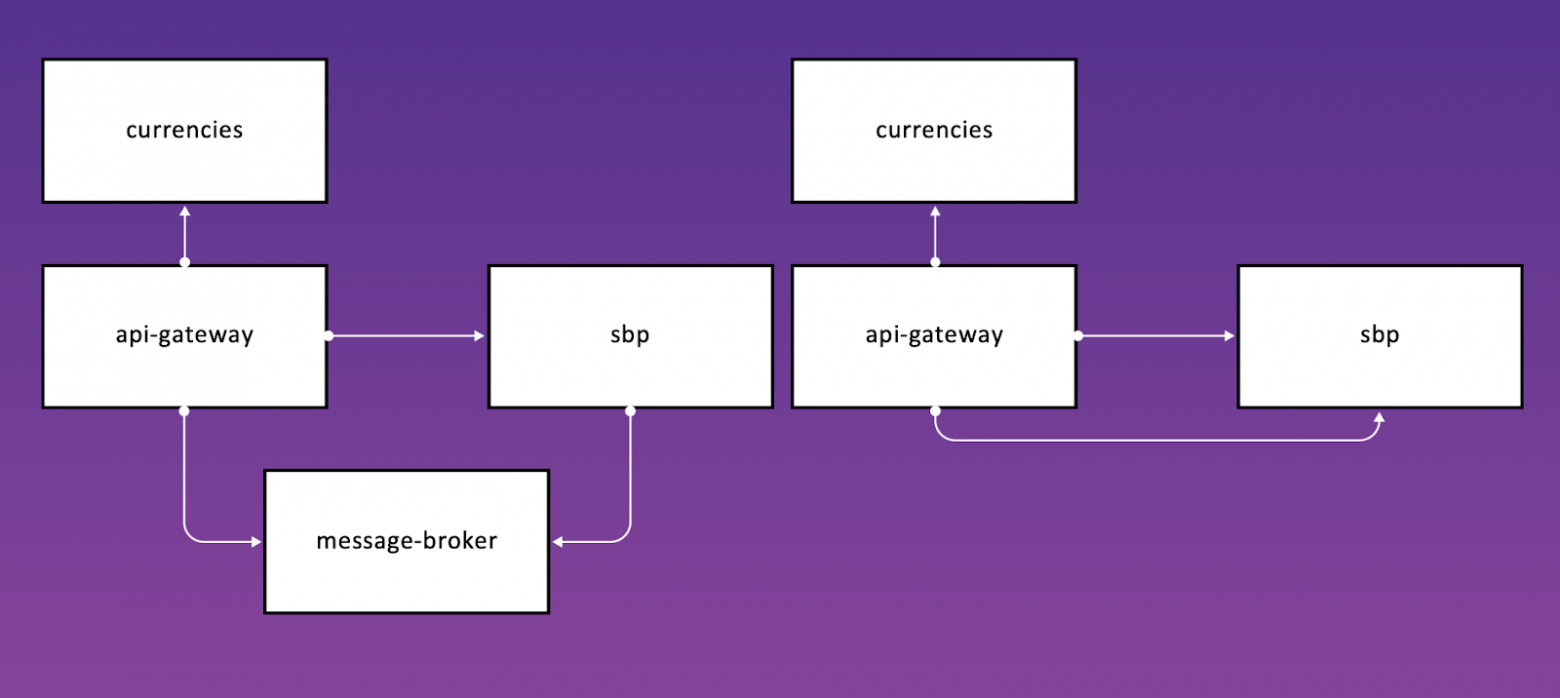
Что делать, если вы уже нарушаете этот принцип? Для решения есть два варианта: ввести дополнительный модуль, например, какой-нибудь message broker по типу Kafka, или же инвертировать зависимость и сделать api-gateway, например, подписанным на какие-то изменения в sbp.
Второй принцип — Stable Dependencies Principle, или принцип стабильных зависимостей.
Этот принцип говорит про стабильность компонентов, поэтому нужно сначала дать определение — что такое стабильный компонент. Стабильным компонентом называется компонент, который редко меняется в силу своей зрелости, и по этой же причине многие модули системы зависят от этого компонента, а он в свою очередь почти не зависит от кого-то еще. Чаще всего такие компоненты находятся в ядре вашей системы и разработаны очень давно, вокруг них строятся другие приложения, использующие их в своих целях.

Например, у нас это приложение card-info, к которому большинство продуктов ходит для того, чтобы по номеру карты получить данные о том, в какой стране и каким банком выпущена карта, и другую информацию по карте. Такой компонент называется стабильным.
Соответственно, нестабильным компонентом называется компонент, бизнес-логика которого еще не состоялась, он стоит на краю системы, часто релизится и часто меняется.
Для того чтобы дальше говорить про этот принцип, нам нужно ввести переменную I, которая называется “нестабильность”. Она считается от 0 до 1 как результат деления количества исходящих зависимостей на общее число зависимостей.
I = Fan-out ÷ (Fan-in + Fan-out), где Fan-in (число входов): количество входящих зависимостей и Fan-out (число выходов)

Суть принципа звучит так: более стабильные компоненты не должны зависеть от менее стабильных компонентов. Например, у нас тут есть очень стабильный компонент card-info, про который я уже говорил, и есть какой-то нестабильный компонент module-1. Мы не должны проводить связь, не должны завязывать модуль card-info на module-1. Это плохо из-за того, что нестабильные компоненты по типу module-1 очень часто релизятся. Из-за этого они могут задеть компонент card-info, а, как мы помним, от него зависят чуть ли не все продукты компании. Если падает какой-то сторонний или на краю стоящий компонент module-1, то падает card-info, а из-за этого падают платежи, падает кошелек, падают выплаты, падает контакт.
Какие варианты для решения? Аналогично первому принципу, это dependency inversion – разворачивание зависимостей и введение дополнительного модуля.
Только что я вам рассказал, что есть какие-то очень стабильные компоненты, которые стоят в ядре системы по типу card-info и которые очень редко меняются. Значит ли это, что в такие компоненты вообще невозможно внести какие-то изменения, из-за того, что от них зависят все продукты компании?
На самом деле — нет.
Чтобы иметь возможность безболезненно изменять такие компоненты, они должны соблюдать букву O в SOLID – это принцип открытости / закрытости. Такой компонент должен быть закрыт для изменения, но открыт для расширения. Это означает, что в этом компоненте должно быть большое количество абстракций, чтобы его поведение можно было легко поменять, не нарушив при этом работу старого функционала.
Теперь как звучит третий принцип — Stable Abstraction Principal, или принцип стабильных абстракций: чем более стабильный компонент, тем более абстрактным он должен быть. Соответственно, нам нужно ввести какое-то отношение между абстрактностью и стабильностью компонента.

Для этого нам нужно ввести переменную A, которая называется “Стабильность”. Она изменяется от 0 до 1 и вычисляется как результат деления количества абстрактных классов на общее количество классов.
A = Na ÷ Nc, где Na — это количество абстрактных классов, а Nc — общее количество классов.
Также мы помним переменную I из второго принципа (нестабильность), и еще нам нужно ввести переменную D, которая называется “Удаленность от главной последовательности”. Она также изменяется от 0 до 1, считается по следующей формуле: абстрактность плюс нестабильности минус один по модулю.
D = |A + I - 1|, где A — это абстрактность компонента, I — это его нестабильность.
На графике это будет выглядеть вот так, по вертикальной оси у нас абстрактность, по горизонтальной – нестабильность. Нам еще нужно провести линию, которая называется главной последовательностью.

Наши модули на этой схеме обозначены точками, и принцип говорит о том, что удаленность от главной последовательности не должна быть очень большой. Дядя Боб в своих лекциях не рассказывает, какой она должна быть, он говорит, что для себя он использует параметр, примерно равный 0,3 (или два квадратичных отклонения), но для своего продукта вы можете сами определить этот параметр.

Что будет, если нарушить этот третий принцип? Можно рассмотреть две характерные зоны: зона бесполезности и зона боли.
В первую очень редко попадают какие-то модули, потому что редко бывает, когда абстрактность компонента равна единице. Это значит, что у вас в самом компоненте много абстрактных классов, интерфейсов и каких-то нереализованных возможностей, то есть это скорее всего какое-то приложение-болванка, которое вообще не приносит пользу.
Гораздо интереснее зона боли. В нее попадают компоненты, которые находятся в ядре и сильно стабильны, при этом у них малая абстрактность, мало интерфейсов, компоненты очень больно менять, поэтому она и называется зоной боли. Но что делать, если ваш компонент находится очень далеко от главной последовательности?
Единственное решение – рефакторить его.
Расскажу о нашем собственном примере нарушения третьего принципа. Месяца три назад к нам в команду пришла задача — сделать так, чтобы card-info смог resolve’ить не только стандартные карты Visa, MasterCard и Мир, но и новые платежные системы UzCard и Humo – это узбекские платежные системы, которые мы тоже хотим эквайрить.
Мы оценили эту задачу примерно в один спринт, потому что казалось, что это достаточно легкая задача, не так много менять. Компонент было сложно изменить, мы не уложились ни в один спринт, ни даже в два спринта, то есть релизили мы с переходом на третий спринт. Провалили все сроки, которые планировали, и оказалось, что переменная D для этого компонента была 0.815, то есть наш компонент попадал в зону боли, его было очень сложно изменить.
Значения переменных до взятия задачи в спринт
I = 0,1
A1 = 0,085
A2 = 0,196
У нас не было ни спринта, ни какого-то отдельно выделенного времени на то, чтобы рефакторить этот модуль, но это было в рамках продуктовой задачи. Мы его чуть-чуть подрефакторили и улучшили значение D, которое теперь составляет 0.704. Недавно пришла новость о том, что платежная система Мир интегрируется с индийской платежной системой RuPay на оплату. Я предполагаю, что в ближайшем будущем к нам придет задача на то, чтобы добавить в card-info платежные карты RuPay. Думаю, что это будет сильно легче.
Значения переменных после спринта
D1 = 0,815
D2 = 0,704
Что в итоге
А в итоге у нас есть написанный внутренний инструмент, который, во-первых, анализирует дерево зависимостей и смотрит, нет ли там циклических графов. Во-вторых, анализирует нестабильность компонента и всех его соседей. В-третьих, выкачивает проект из Git’а, строит AST-дерево из классов, анализирует абстрактность компонента и сравнивает его с нестабильностью.
В результате всего этого он выдает предупреждения в наш OpenSpace (я уже упоминал о нем ранее). Он позволяет посмотреть не только связи, но и какую-то конкретную информацию по конкретному модулю.

Что это вообще дает нам полезного на практике?
Для разработчиков мы получаем повышение инженерной культуры, они видят, что уже есть какое-то нарушение, могут почитать какую-то дополнительную информацию об этих принципах и не нарушать их — это очень похоже на предупреждения в компиляторе. Бизнесу это дает метрику, по которой он может оценивать сложность системы.
Что это дает лично мне? Я спокойно сплю.
А для тревожного человека это очень и очень большой
Проверить свои компоненты можете моим сервисом

