Реверс-инжиниринг неизвестного бинарного формата файла – задачка нечастая, но, на мой взгляд, вкусная. Самое то, чтобы в пятницу с утра отвлечься от организационной текучки, техподдержки, бизнес-планов, заполнения восьмёрок в системах отчётности, и поиграть в Шерлока Холмса. В этой статье я расскажу об опыте изучения бинарного файла с временными данными технологических параметров и о небольшой фишке чтения хитрым способом сохранённых строк из другого формата. Файлы несложные, времени на анализ потребовалось немного, но мне было интересно, и вам, я надеюсь, тоже будет интересно.
На хабре есть несколько статей про приёмы исследования содержимого различных бинарных файлов, например (раз, два, три). Мне больше всего нравится обстоятельное и системное описание в переводной статье, кто хочет научиться большей части приёмов – рекомендую ознакомиться именно с ней.
Мы занимаемся разработкой инженерного ПО, как описано вот тут, и делаем это на связке Python и С++. По-английски это софт типа CAD/CAE, а по сути – это программы для физического моделирования технологических операций: они должны, например, провести расчёт того, как будут спускать в скважину гибкую трубу, и сказать, не застрянет ли она при этом где-нибудь, не порвётся ли при вытаскивании и так далее. Сама операция проводится оборудованием, более или менее обвешанным датчиками, эти датчики ведут записи, а после работы запись всех показаний сохраняется, передаётся во всякие информационные системы и отображается в виде красивых графиков, например, таких:
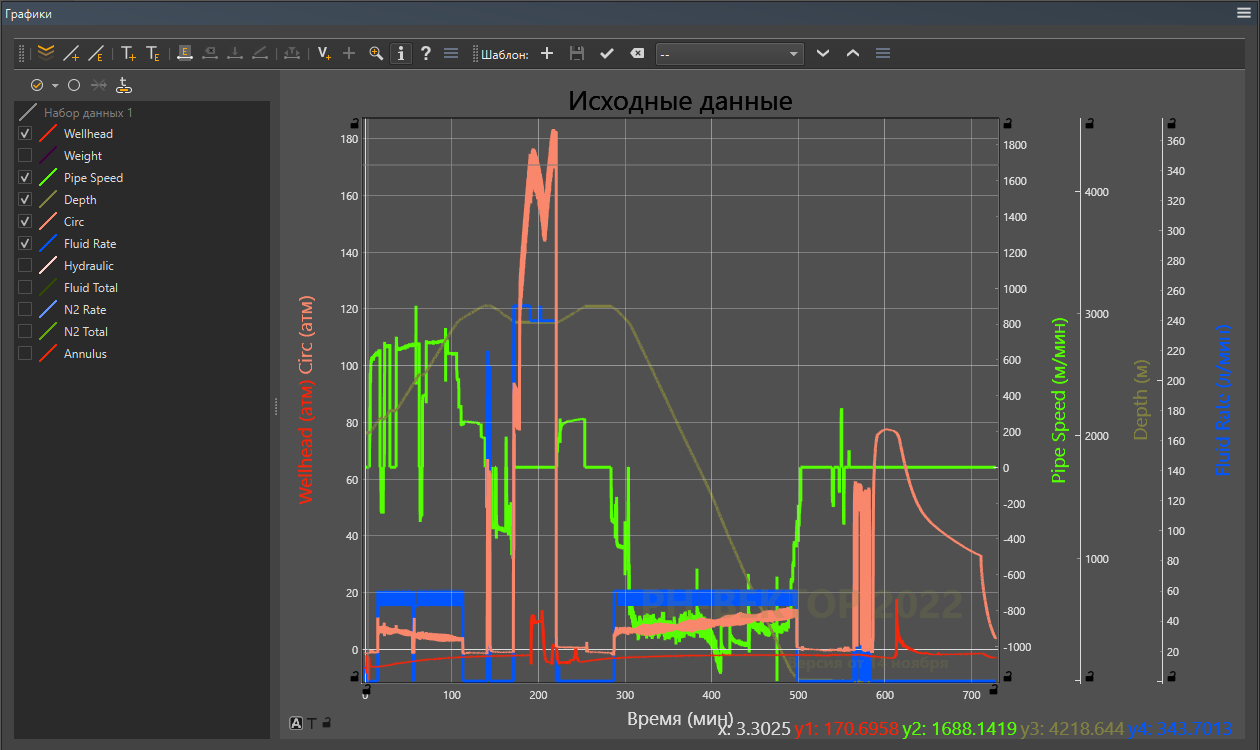
Данные бывают в десятках разных форматов, причём как текстовых, так и бинарных. С текстовыми форматами всё понятно: кто хоть раз пользовался в Excel функцией «текст по столбцам», тот понимает, что там просто разбор текстовых табличных данных с заданием разделителей. А вот с бинарными форматами всё хитрее.
Зачем они вообще нужны, эти бинарные форматы? Во-первых, они компактнее. Если какой-нибудь типовой бинарный файл с длительной записью может занимать 50 МБ, то он же в текстовом виде может занимать 250 МБ и больше, в зависимости от детальности десятичного представления. Во-вторых, они загружаются быстрее. Разбор того же текстового файла 250 МБ в моноширинном виде может подвиснуть на минуту, но те же самые данные из бинарных 50 МБ загрузятся за 5 секунд. В-третьих, бинарные файлы часто пишет оборудование: какой-нибудь погружной датчик пишет два месяца данных на свою флешку и даже привет нам передать не может с глубины в 3 км. Потом его поднимут, данные с флешки загрузят, откроют в ПО от производителя, вырежут, сгладят, подрисуют, и сохранят в csv для передачи заказчику. А грамотный заказчик любит свежачок, неисправленный исходник, в который никто поправки не внёс – а он, стало быть, бинарный.
Бинарных форматов много, и каждый производитель использует свой: одни используют какой-то стандарт, другие нет. Иногда с производителем можно пообщаться, но иногда никакого контакта нет или производитель уже не существует как организация, и тогда приходится выяснять, как именно хранятся данные. Было бы в наличии ПО от производителя - можно было бы с его помощью узнать, что именно хранится в файле. Но в большинстве случаев на практике приходится гадать только по двоичному содержимому файла.
Понятно, что в общем случае эта проблема трудноразрешима. Если производитель сделал всё, чтобы затруднить реверс-инжиниринг, сделал обфускацию или шифрование, то дело – дрянь. Но чаще всего такое не делается и в приведённом ниже примере, в частности, ничего такого нет.
Итак, вот файл, который будем грузить: это бинарный файл с расширением WTF. По словам инженера, он должен содержать временные данные о технологической операции, но больше никакой информации о формате файла нет. Открывать его, понятно дело, надо в каком-нибудь редакторе в hex-режиме (ура-ура-ура, NPP перестал крашиться с плагином HEX – последний довод отказаться от UltraEdit):

Можно воспользоваться каким-нибудь онлайн-инструментом для разбора бинарников, например, ide.kaitai.io (инструмент на самом деле не совсем для того, или совсем не для того, но и для того – тоже):
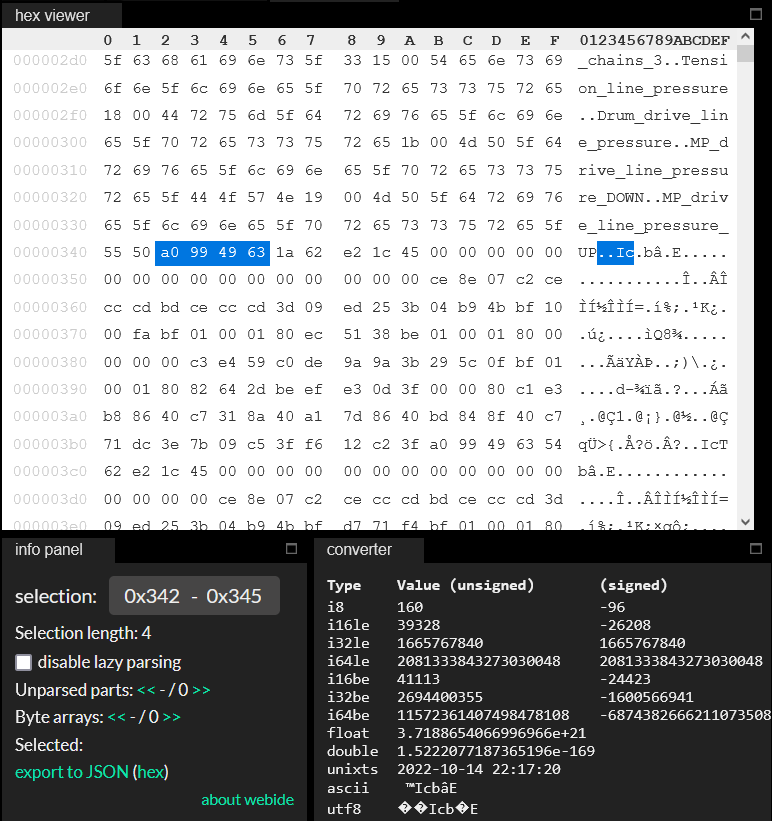
Что мы видим, применяя, как учили в школе, метод пристального взгляда?
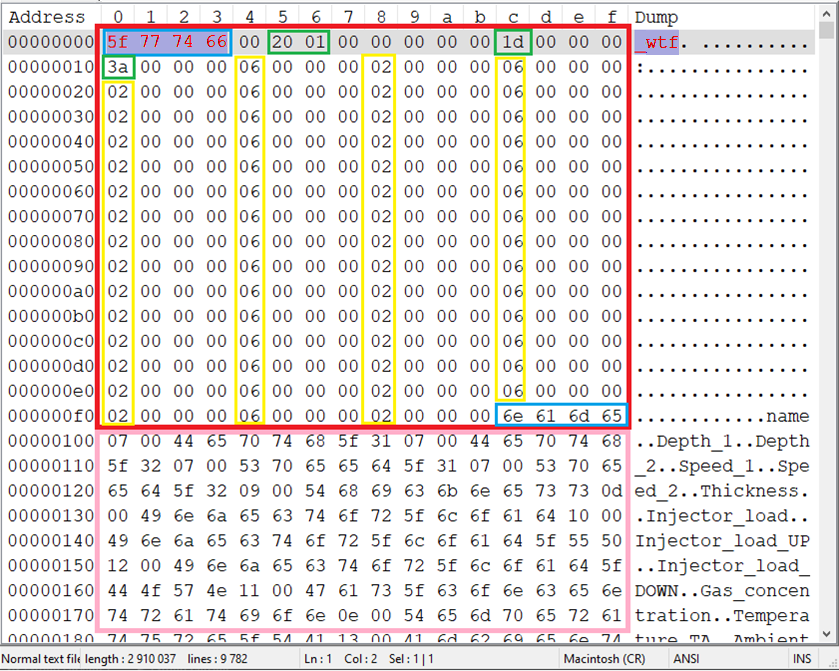
Во-первых, видно первый блок в файле, размером 256 байт, который заканчивается текстом «name». В этом блоке бросается в глаза сигнатура в начале файла, самые первые 4 байта: «_wtf», которая нам подтверждает, что это wtf файл, как ни странно. Дальше идут пока не понятные нам значения, из которых пока никакой информации не вытащить.
Дальше идёт блок, в котором, как будто, описываются имена хранящихся в файле кривых:

Как будто это обычные строки в самой обычной однобайтовой кодировке, но почему-то они заканчиваются символом x07 таблицы ASCII (это BELL), за которым следует нулевой байт. С чего бы? По ком звонит колокол? Продолжая смотреть, мы видим, что это вовсе не всегда x07: иногда x09, иногда x10 и так далее. Может показаться, что это какой-нибудь номер – но начинается он не с нуля. И вообще, первое такое вхождение пары x07, x00 идёт до первой строки, а не после.
Вообще, строки в файлах чаще всего бывают только трёх видов:
фиксированной длины (это явно не наш случай: мы бы увидели в файле, что после каждой строки идут нули или пробелы, добивая её длину до какого-то постоянного значения);
переменной длины с нулём в конце для сигнализации окончания строки (это, как будто, похоже на наш случай, потому что разделяющий строки ноль есть, но перед ним есть ещё один посторонний символ и, что ещё хуже, этот символ рядом с нулём – нечитаемый);
последнее как раз намекает нам на третий вариант: строки переменной длины, где длина строки задаётся двумя байтами перед ней – разбив байты по-другому, это становится очевидно:
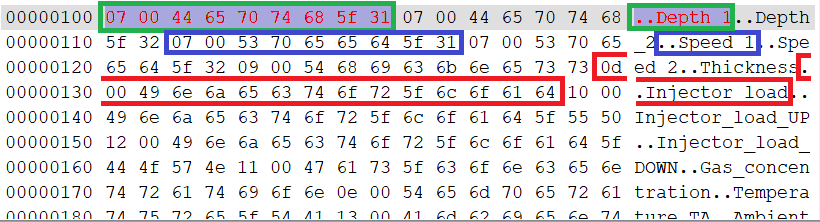
Нас пытались обмануть, намекая на zero-terminated-строки, но мы не поддались! Это строки задаваемой переменной длины, причём двухбайтная длина (младший байт идёт первым, это little-endian формат записи чего-то многобайтного) строки идёт перед ней, что логично: прежде, чем читать строку, надо бы узнать, сколько байт читать.
Итак, мы обнаружили блок описания кривых, в которых перед каждой кривой идёт её длина, а перед всем этим – 256-байтный заголовок. Вроде бы всё пока получается красиво, 256 байт – очень правильный размер для заголовка! Пора, наконец, начать писать код, который этот файл будет читать. Для экспериментов будем использовать, конечно же, Jupyter. Напоминаю, мы занимаемся исследованием файла, поэтому это не продакшен-код (хотя кого я обманываю – все понимают, что это универсальная отговорка):

В питоне мы открываем файл для чтения в бинарном режиме, читаем заголовок 256 байт и с помощью модуля struct разбираем его на те три части, которые пока понимаем: 4 байта в строку, потом 248 байт непонятных, потом снова 4 байта в строку.
Теперь у нас идёт блок со строками. Сколько их будет, мы не знаем, поэтому будем читать всё:
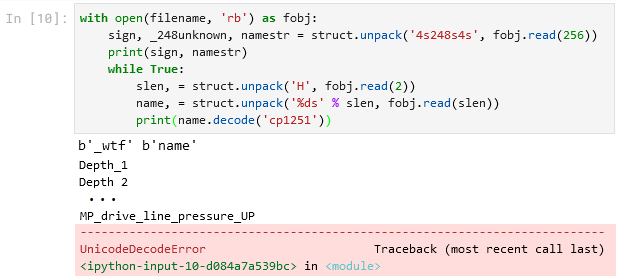
В цикле мы читаем 2 байта, разбираем их как целое беззнаковое двухбайтное число slen, потом читаем slen байтов дальше и разбираем их как строку заданной длины. В результате получаем тип bytes, который надо ещё раскодировать с заданной кодировкой. У нас нет особых предпочтений, поэтому предположим, что это cp1251, потому что других букв мы там в строке не видим. Что в результате?
Куча имён кривых нормально прочиталась, а потом всё упало, потому что питон не смог очередную строку раскодировать. Если посмотреть в файл, становится понятно, что после строки MP_drive_line_pressure_UP явно строки заканчиваются и начинается что-то другое:

Итого мы насчитали 29 прочитанных названий кривых. Можно сделать смелое предположение о том, что в нашем файле пишется 29 кривых данных. Число 29 в шестнадцатеричном виде – это x1D. Наверное можно ждать, что где-то перед самими именами кривых в заголовке это число должно быть записано. Возвращаемся к заголовку, и действительно, находим там x1D:
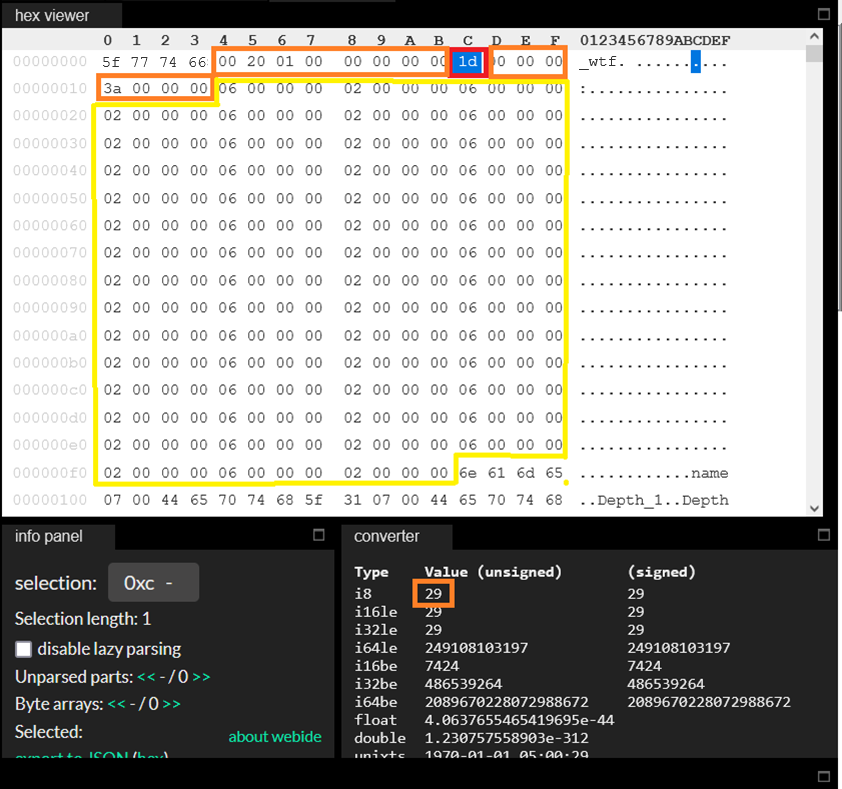
Что за байты перед x1D – пока не ясно. Что за байты после x1D – тоже не ясно, но их там три байта после x1D, а потом ещё четыре байта до первой регулярной шестёрки. Возможно, число кривых – это однобайтное целое, может быть двухбайтное, а может даже и четырёхбайтное – пока мы не знаем. Но потом начинается снова какой-то регулярный блок, где последовательности x06 x00 x00 x00 сменяются последовательностями x02 x00 x00 x00, и происходит это ровно 29 раз! Напрашивается мысль, что это 29 раз описанные какие-то флаги про наши 29 кривых, и заголовок круглым размером 256 байт – это просто совпадение! Самое время переписать чтение того, что мы уже распознали:
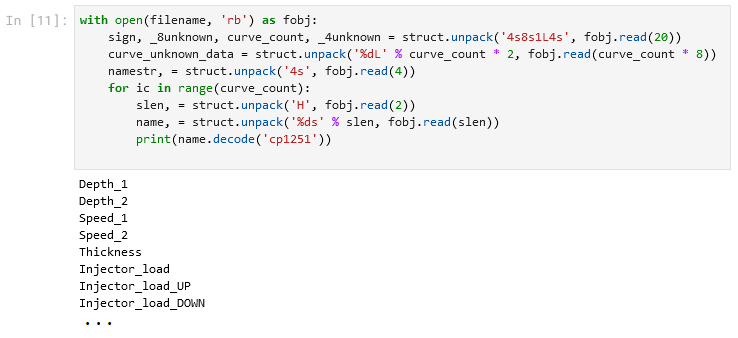
Итак, сначала читаем 20 байт и распаковываем (форматом 4s8s1L4s) их в строку 4 байт, строку 8 байт, одно длинное четырёхбайтное целое и снова строку 4 байт.
Потом массив из 29 (по числу кривых) последовательностей x06 x00 x00 x00 x02 x00 x00 x00, где хранится непонятно что (но интерпретируемое пока как длинные беззнаковые четырёхбайтовые целые), и ещё 4 байта строки.
Ну и дальше в цикле 29 раз (по числу кривых) читаем 2 байта длины строки-названия кривой, потом читаем нужно количество байт самого названия, раскодируем их из bytes в str и печатаем (ну или складываем в массив).
Всё, заголовок прочитан (пусть и не весь понят), и можно переходить к основному содержимому. А сколько там этого содержимого осталось?

Какое некрасивое число! Нутром чую – не нравится оно мне! Может, оно делится на 29? Нет. На 30? Нет. На 31? Тоже нет. Разложим на множители? 2909203 = 11 * 11 * 24043. Ух ты! Похоже это черно-белое видео с 24043 кадрами размера 11 на 11 пикселов! По крайней мере, если бы я был Элеонор Эрроуэй, я бы однозначно в этом видео нашёл бы Подпись Творца, которую искал. Но мы будем проще, её суперкомпьютера у нас нет (на самом деле есть, это просто мне его не дают), и мы снова будем применять метод пристального взгляда. Вот какие обнаруживаются регулярности:
В kaitai уже хуже, но тоже видны эти регулярности, начинающиеся после 25 байт, выделенных жёлтым:
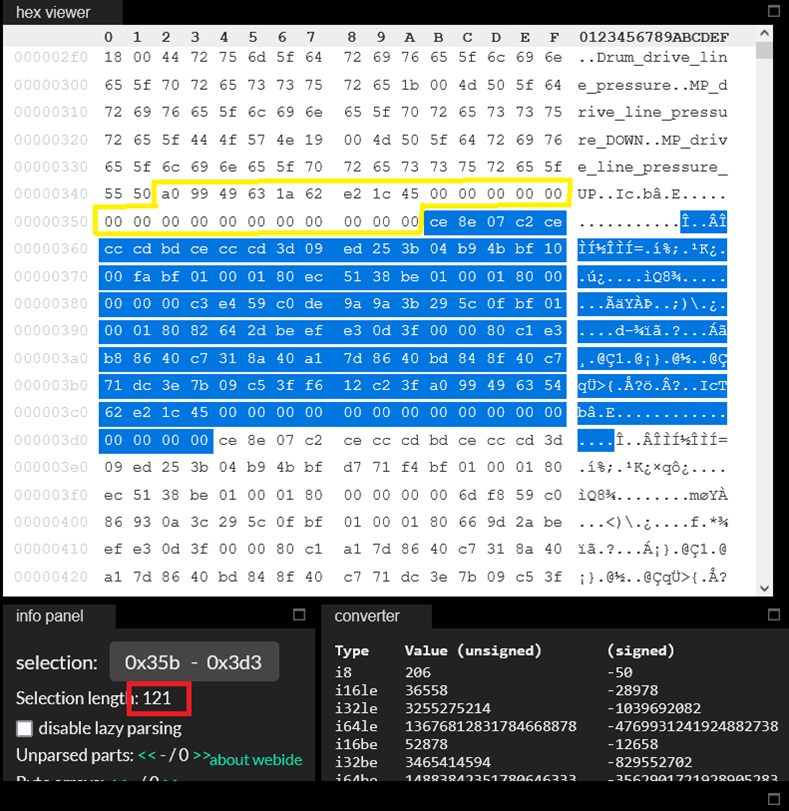
Важно, что длина этих регулярностей равна 121 байт. А наше магическое число 2909203 как раз на 121 делится. Получается, что весь наш файл, кроме заголовка 256 байт, состоит из 24043 «блоков» длиной 121 байт! Причём мы регулярность заметили с того, что нам просто бросилось в глаза, но ровное деление 2909203 на 121 намекает нам на то, что на рисунке выше выделено не начало «блока», а на самом деле блок начинается именно сразу после заголовка. Зная теперь его длину в 121 байт, мы можем выделить первый блок и посмотреть на него, а также убедиться, что следующий за ним блок имеет то же самое начало:
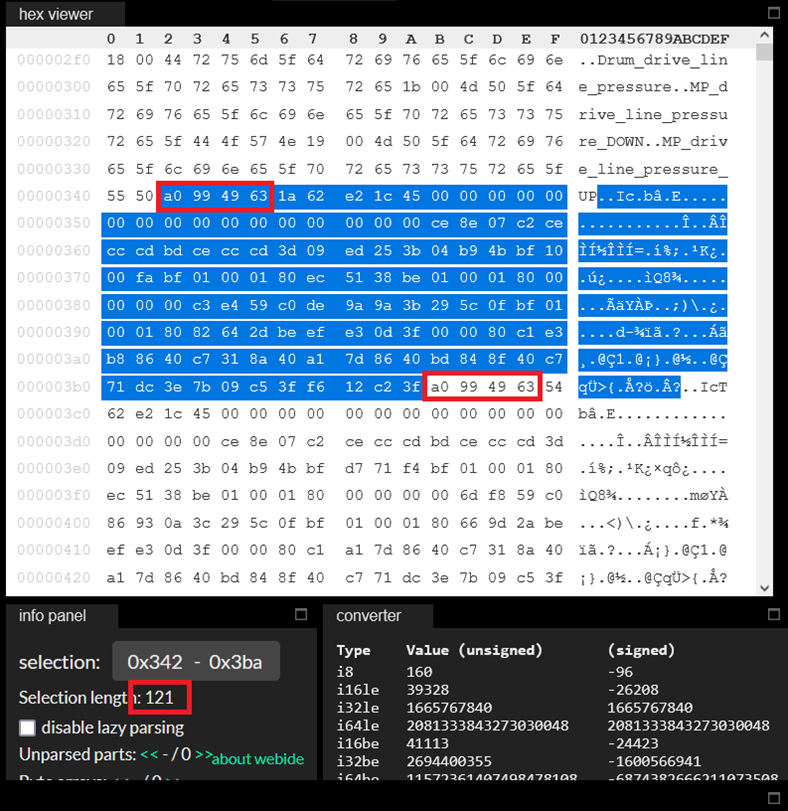
Жаль, значит, мультиков не будет. Но теперь мы наконец-то можем прочитать сразу весь файл, разбив его на «блоки», и у нас не останется никаких «лишних» байт. Теперь будем пытаться понять, что же есть в каждом блоке. Возьмём первые 10 блоков и посмотрим на первые 50 байт каждого:
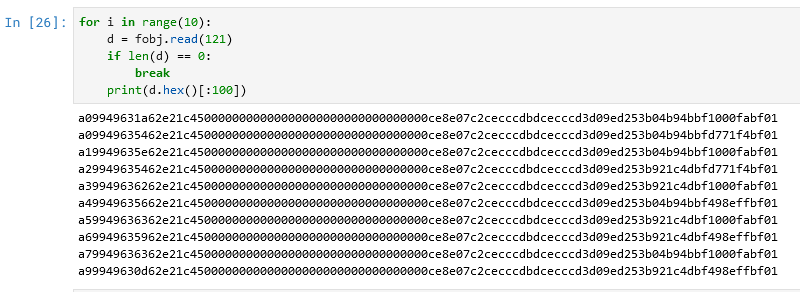
Посмотрим на выводимое содержимое внимательнее:

Красным выделен первый байт блока, он:
меняется почти всегда (но не всегда – в первых двух строках он одинаковый)
меняется достаточно регулярно, почти всегда на единицу (но не всегда, в последних двух строках – на двойку)
Жёлтым выделены три байта, которые в этих 10 строках не меняются. Зелёным выделен байт, который изменяется, а голубым выделены идущие за ним байты, которые в этих 10 строках тоже не меняются. И что нам с этим делать?
Что у нас может и даже обязано с такой завидной регулярностью меняться на единицу? Это файл временных технологических данных, что там должно регулярно изменяться? Время!
В каком виде может встречаться время в подобных файлах? Вариантов много: это может быть относительное время в часах или минутах или секундах, стартующее с нуля (а может и не с нуля), тут может быть очень разное количество байт. А может это быть и время в формате OLE datetime, в float дней с 1 января 1900 (вариант – с 30 декабря 1899), тогда это, как правило, 4 байта. Наконец, часто это бывает unix timestamp как количество секунд с того момента, как Jeff Dean в возрасте 12 минут запрограммировал и запустил свой первый счётчик времени в 1970 году, тогда это тоже 4 байта.
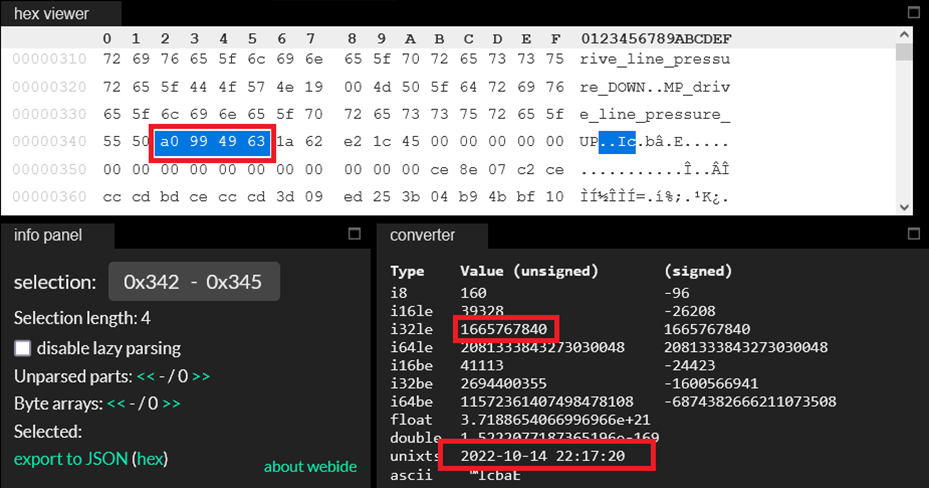
На самом деле, намётанный взгляд, как увидит большое число, начинающееся с 16657… или типа того, сразу понимает, что речь идёт о unix timestamp примерно нашего времени. Kaitai этому намётанному взгляду сразу помогает, переводя его в строку, и мы понимаем, что угадали: это действительно unix-время в секундах, и мы ожидаемо получаем что-то не очень давнее – потому что данные, с которыми мы работаем, были записаны не очень давно. Итак, первые четыре байта разгаданы: это время unix timestamp в секундах!
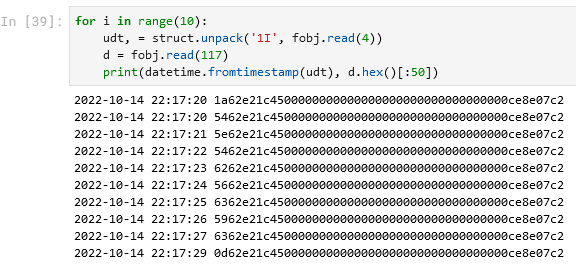
Но прежде, чем пытаться разгадать оставшиеся 117 байт, надо разрешить неприятный факт. Мы ожидали, что каждая запись будет с уникальным временем, а мы сразу видим две записи подряд с одинаковым временем, но с разными данными, которые записаны после. С этим надо будет что-то делать.
Теперь дальше: что это за 117 байт? Почему нечётное число? Это очень неприятно! А вообще, что мы хотели бы дальше увидеть в каждом блоке? Наверное, раз у нас 29 каналов с данными, то мы хотели бы увидеть 29 значений. И тут ближе всего вот такой финт: 117 = 116 + 1 = 29 * 4 + 1. То есть как будто бы в 117 байтах можно найти как раз 29 чисел (возможно целых четырёхбайтовых, возможно вещественных float, которые занимают столько же) и один какой-то лишний байт. Что это? Разметка? Выравнивание? Какой-нибудь флаг? И где этот байт? Можно снова применять метод пристального взгляда, а можно попробовать разные варианты. Например, что в этих 117 байтах сначала идёт 29 float-ов, а потом этот байт:
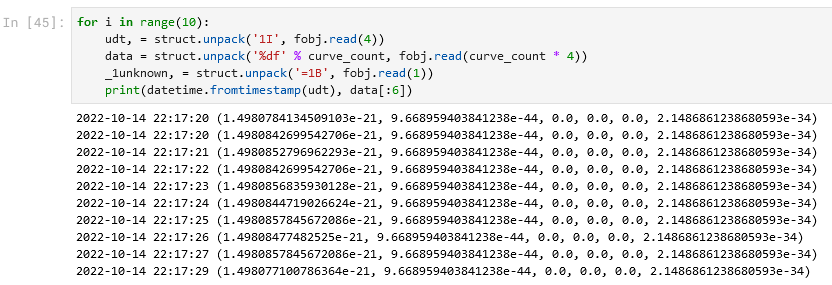
Как-то не очень. Мы, конечно, морально готовы увидеть и большие, и маленькие значения (потому что мы готовы увидеть и давление в паскалях, и проницаемость не в миллидарси, а в м2), но значения порядка 1e-21 и 1e-44 – это, пожалуй, перебор.
Может быть, это вообще не float, а целочисленные значения? На самом деле глазами уже видно, что это не целочисленные значения, но надо убедиться (при этом в формате использована буква «l», а не «L», потому что мы пишем показания приборов, а они бывают и отрицательные – но, по-хорошему, надо проверять все варианты):
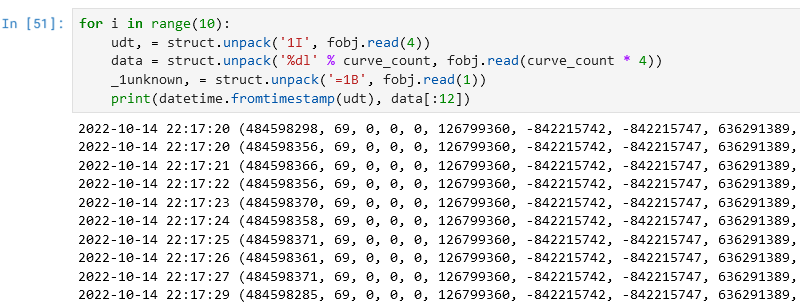
Не очень многообещающе. Тогда может, сначала 1 байт, а потом 29 целых четырёхбайтовых знаковых?
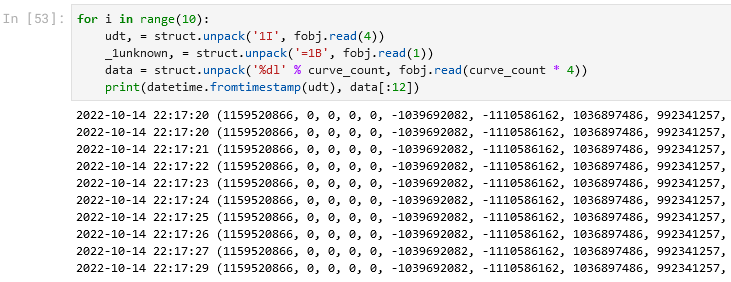
Снова явно не то. Тогда попробуем сначала 1 байт, а потом 29 float-ов? Кстати, формат для чтения байта тут везде начинается с '=' для того, чтобы отключить выравнивающее дополнение этого байта до двухбайтного слова:
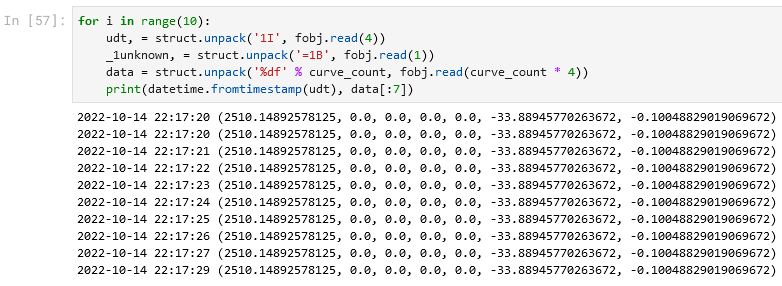
Ура! Вероятность того, что float, полученный из случайной последовательности байтов будет иметь размерность близкую к нулю – сама по себе достаточно мала, поэтому такие «красивые» числа – признак правильного разбора. А если мы вспомним строковые названия кривых, то первой кривой там была Depth_1, а мы, нефтяники, как раз и имеем дело с глубинами порядка 2000-2500 метров. Так что, похоже, мы угадали. Осталось только понять, что с этим «лишним» байтом:
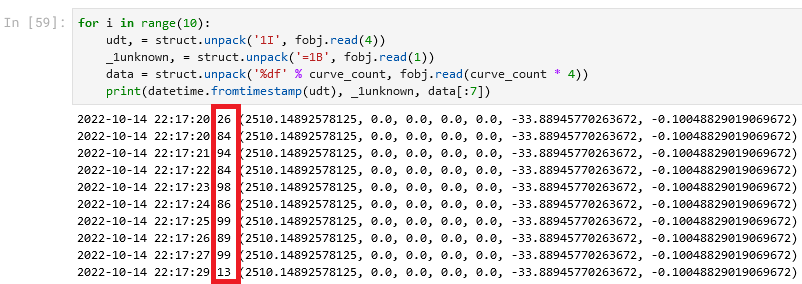
Байт, как известно, хранит числа от 0 до 255, а у нас 10 чисел – и все меньше 100. Неужели…? Надо срочно проверить его пределы!

Действительно, этот байт хранит только числа до 100. У меня нет другой гипотезы, кроме той, что он хранит миллисекунды! Чтобы подтвердить эту гипотезу, можно проверить, что для тех строк, где основная unix timestamp одинаковая, этот байт содержит строго возрастающие значения, но мне уже лень, я верю в свою догадку.
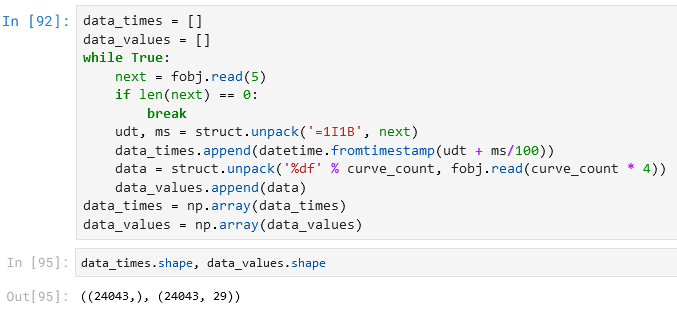
Всё, мы научились загружать эти данные из файла. Осталась мелочь – формат вместе с функцией его чтения обернуть во что-нибудь и засунуть в нашу программную платформу, на которой мы пишем инженерное ПО (то есть обернуть всякими обёртками, фабриками декораторов и итераторами команд), запустить новую сборку, загрузить этот файл и посмотреть на графики:

Ну и последнее, что ещё тут стоит проверить: мы читали файл до конца, пока получается читать. В итоге получилось 24043 записи. В hex это x5DEB. Надо бы посмотреть снова наш заголовок, есть ли там эти магические байты? Я не нашёл, но, может, у вас получится? А что означают те магические 29 двоек и 29 шестёрок в заголовке? Узнаем ли мы это когда-нибудь?
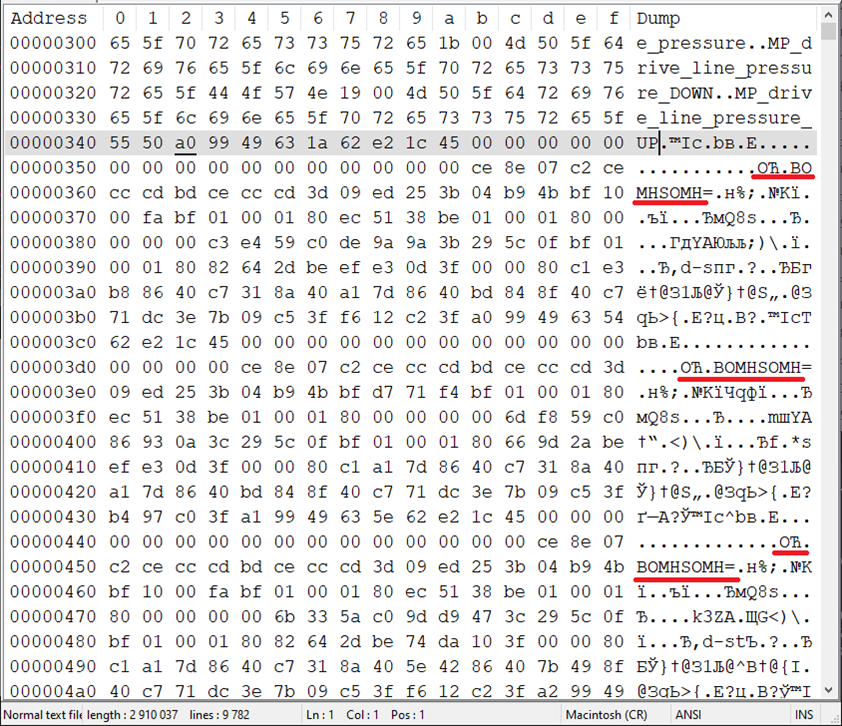
Ещё одна небольшая история, которую я хотел бы рассказать, связана с разгадыванием шифра пляшущих человечков чтением строк. Как-то приходилось читать всё те же технологические данные из файла текстового, но названия каналов в котором хранились очень странным способом, дублируясь в верхнем и нижнем блоках:
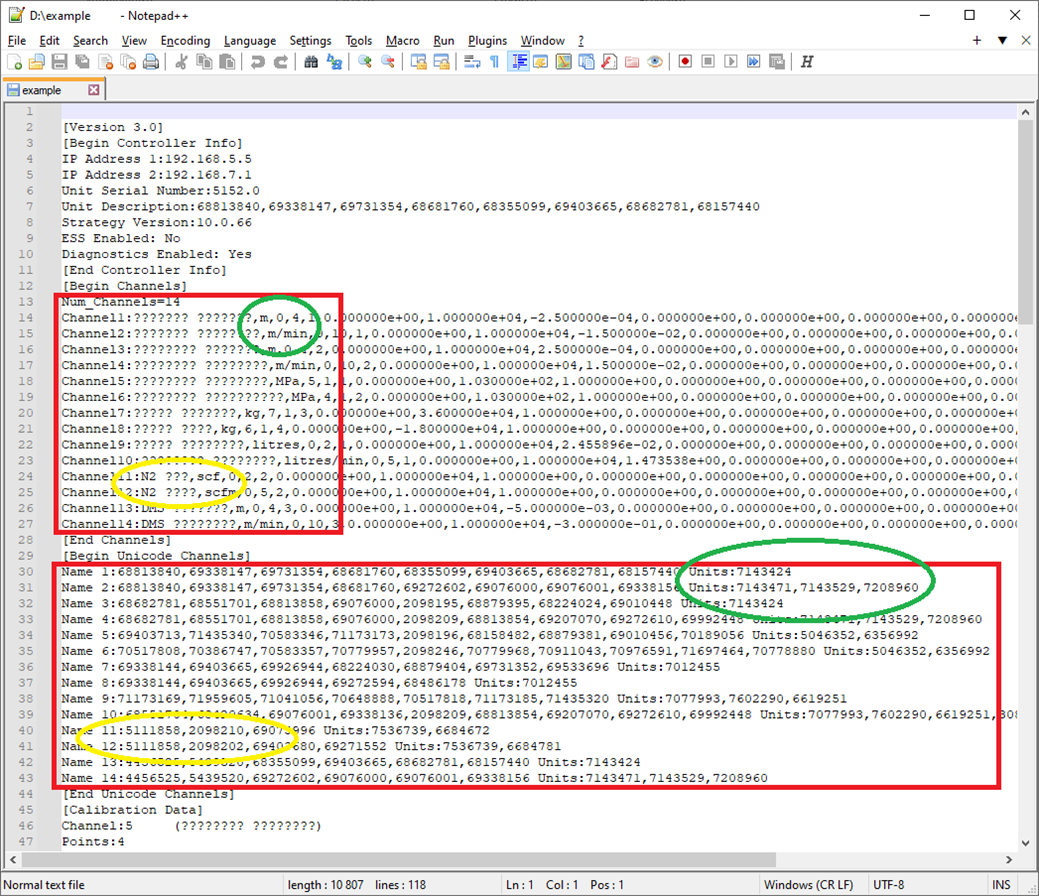
В верхнем блоке должны быть написаны имена каналов, но там вопросики, причём честные вопросики, то есть символы с кодом x3F прямо в файле, так что это не кривой шрифт выбран и не ошибочная кодировка для отображения используется. Остаётся надежда, что в нижнем блоке эти же самые строки закодированы в другом виде, и мы сможем в нём разобраться.
Нам могут помочь те строки, которые содержат единицы измерения в верхней, неюникодной части, потому что мы можем найти им соответствие в нижней, юникодной и закодированной части.
Там, где единицы измерения в верхней части – «m», в нижней части – «7143424», а строка «m/min» сверху соответствует кодовой строке «7143471,7143529,7208960» снизу. Очень похоже на то, что буква m соответствует то ли 71434, то ли 7143, то ли 714? Но при этом в строке «m/min» целых 4 буквы и 1 символ, а в строке «7143471,7143529,7208960» - всего 3 числа, так что придётся оставить гипотезу о том, что каждой букве соответствует одно число.
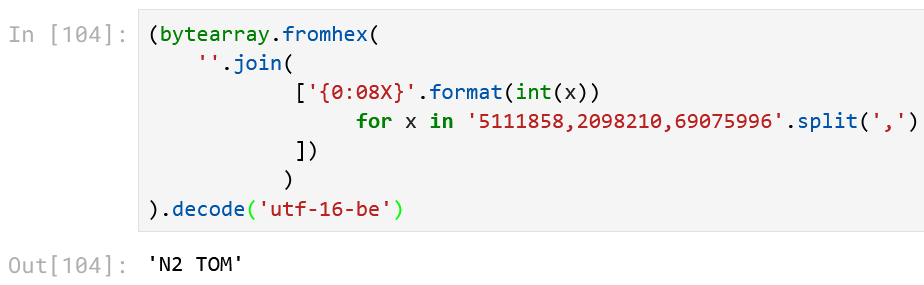
Тогда посмотрим на выделенные жёлтым цветом области. Попробуем в «5111858,2098210,69075996» поискать что-то начинающееся с «N2 » (буква, цифра и пробел). Первое, что приходит в голову – числа перевести в hex и посмотреть на их коды:

Похоже, что мы на правильном пути: x4E – это код буквы «N», x32 – код цифры «2», x20 – код пробела « », но проблема в появившихся нулях между ними. Нули намекают на двухбайтовую кодировку строк. Известно, что в utf-16 как раз – два байта у каждого символа, и у английских символов и цифр один из байтов будет нулевым, поэтому ноль после x4E понятен, но после x32, как и после x20, нулей почему-то нет, а должны быть. Кроме этого, «41E041C» вообще нечётное число символов содержит, и это ни с какой нашей рабочей гипотезой не совместимо.
Но кодировок utf-16 есть, на самом деле, минимум две, они как раз и определяют, с какой стороны оказываются нули:

Попробуем добавлять нули к каждому кусочку, дополняя его до ровных 4 байтов? Только куда, в начало – или в конец? Попытка добавить нули в конце ни к чему не приводит (добавленные нули показаны жёлтым), хотя N2 в начале выводит:

А вот добавка нулей до 4 байтов к началу каждого обрывка – приводит к нужному результату:

Ура, теперь всё без иероглифов!
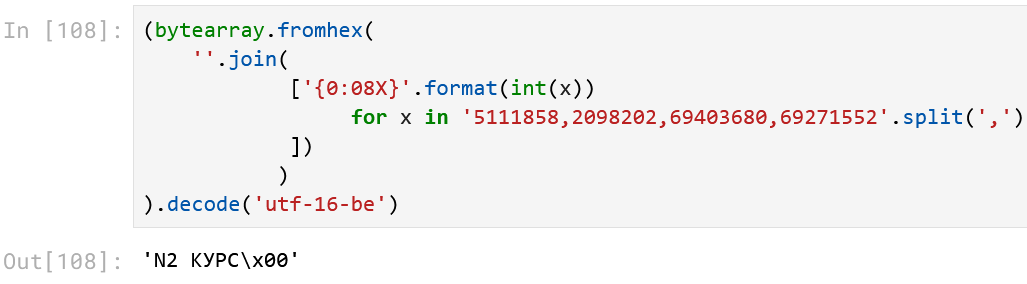
Получается, что сделали создатели этого формата? Они взяли строку, записали её в utf-16-be, потом разбили на отрезки по 4 байта, эти отрезки интерпретировали как целые числа, и числа распечатали в файл через запятую. Ну что тут скажешь? Ребята с фантазией!
Значит, нам нужно выполнить обратную операцию. Сначала каждое число переводим в hex, причём строго с дополнением нулей в начале до 8 шестнадцатеричных символов (то есть до 4 байтов):

Полученную последовательность байтов сливаем вместе и декодируем как utf-16-be:
Ну да, ещё strip нужен (а вообще, какой-то LISP получается, вам не кажется?):


Пожалуй, на этом всё. Сложность любого формата бинарника определяется тем, какое число у вас в итоге получится на последнем скриншоте в строке In [X] или Out[Y]. Это были не самые сложные задачки, но для пятницы сойдёт.
Подведём итоги. Какие уроки может для себя из этой истории извлечь читатель, которому ещё не приходилось задумчиво глядеть на шестнадцатеричные дампы?
Держите в уме размеры типов данных, выравнивание и endianness многобайтовых данных.
Знайте размеры и внешний вид типовых форматов хранения самых популярных типов данных: целых чисел, вещественных чисел, дат и строк (однобайтовых, многобайтовых, разные виды utf).
Умение видеть повторы там, где они в дампах есть - вовсе не признак психического заболевания, Рассел Кроу не даст соврать!
Нумерология – зло, совпадения чисел ничего не значат, но не в этом случае: 121 байт – это действительно 30 float-ов и ещё один байтик, верьте в совпадения!
Не верьте в совпадения! Иногда заголовок в 256 байт – это просто случайность, и на самом деле он имеет переменную длину!
Помните о том, с какими данными вы имеете дело. Чем больше правильных предположений о том, что нужно ждать, вы сделаете, тем быстрее вы сможете разобраться с форматом.
Узнавайте, на чём писалось ПО, выгрузившее ваши данные: язык часто идёт вместе с форматом хранения данных.
Всем добра и хорошей пятницы!
P.S. Если вы вдруг пользуетесь NPP с плагином HEX, не слишком ему доверяйте. Этот негодяй в HEX-режиме не показывает байты, как есть в файле, а изменяет их в соответствии с кодировкой! Можно попробовать это исправить, отключив 'Autodetect character encoding' в настройках Preferences/MISC и вручную выбрать кодировкой ANSI или типа того. Но надо переходить на другой редактор (или плагин), конечно. Тому, который может переврать в HEX-режиме содержимое файла, доверия нет и никогда не будет. Посоветуйте, какой лучше? Может что-то типа Hex Editor Neo?
