Привет, Хабр!
Мониторинг сегодня – фактически обязательная «часть программы» для компании любых размеров. В данной статье мы попробуем разобраться в многообразии программного обеспечения для мониторинга и рассмотрим подробнее одно из популярных решений – систему на основе Prometheus и Grafana
История и определение
На заре появления компьютерных сетей в конце 1970х – начале 1980х гг. главной задачей мониторинга была проверка связности и доступности серверов. В 1981 году появился протокол ICMP, на основе которого в декабре 1983 года написана утилита ping, а позднее и traceroute, которые используются для диагностики сетевых неполадок и по сей день. Следующим этапом стало создание в 1988 году протокола SNMP, что привело к рождению MRTG – одной из первых программ для мониторинга и измерения нагрузки трафика на сетевые каналы. Параллельно с середины 1980х гг. стало активно разрабатываться программное обеспечение для мониторинга потребления ресурсов компьютерами, такое как top, vmstat, nmon, Task Manager и др. К середине 1990х годов в связи с ростом ИТ инфраструктуры многие компании стали испытывать потребность в комплексной и централизованной системе мониторинга, что послужило спусковым крючком для синхронного начала разработки нескольких прототипов. В 1999-2002 гг. на свет появились решения, предопределившие развитие отрасли на годы вперед и развивающиеся до сих пор – Cacti, Nagios и Zabbix.
Мониторинг в ИТ сегодня – это система, которая позволяет в режиме реального времени выявлять проблемы в ИТ инфраструктуре, а также оценивать тренды использования ресурсов. Как правило состоит из нескольких базовых компонентов – сбора сырых данных, обработки данных с целью их анализа, рассылки уведомлений и пользовательского интерфейса для просмотра графиков и отчетов. В настоящее время существует большое количество систем для мониторинга различных категорий – сети, серверной инфраструктуры, производительности приложений (APM), реального пользователя (RUM), безопасности и др. Таким образом, мониторить можно все – от сетевой доступности узлов в огромной корпорации до значений датчика температуры в спальне в «умном» доме.
Читать подробнее:
Обзор систем мониторинга
Для цельности картины рассмотрим несколько примеров систем мониторинга:
PingInfoView, SolarWinds pingdom и др.
Ping – наиболее известный способ проверки доступности узлов в сети. Программы, умеющие с определенным интервалом пинговать набор сетевых узлов и отражающие в режиме реального времени графики доступности, по сути есть зародыш системы мониторинга. Выручат, если полноценной системы мониторинга еще нетZabbix
Поддерживает сбор данных из различных источников – как с помощью агентов (реализованы под большинство распространенных платформ), так и без них (agent-less) посредством SNMP и IPMI, ODBC, ICMP и TCP проверок, HTTP запросов и т.д., а также собственных скриптов. Имеются инструменты для преобразования и анализа данных, подсистема рассылки уведомлений и веб-интерфейс. Свободно распространяется по лицензии GNU GPL v2 (бесплатно)PRTG
Поддерживает сбор данных без агентов посредством преднастроенных сенсоров SNMP, WMI, Database, ICMP и TCP проверок, HTTP запросов и т.д., а также собственных скриптов. Имеются инструменты для анализа данных, удобная подсистема рассылки уведомлений и веб-интерфейс. Является коммерческим продуктом, лицензируется по количеству сенсоров. PRTG Network Monitor с количеством сенсоров не более 100 доступен для использования бесплатноNagios Core / Nagios XI
Поддерживает сбор данных с помощью агентов (реализованы под большинство распространенных платформ) и без них посредством SNMP и WMI, а также расширений и собственных скриптов. Имеются инструменты для анализа данных, подсистема рассылки уведомлений и веб-интерфейс. Nagios Core свободно распространяется по лицензии GNU GPL v2 (бесплатно), Nagios XI является коммерческим продуктом. Подробнее о различиях между Nagios Core и Nagios XI можно почитать в статье Nagios Core vs. Nagios XI: 4 Key DifferencesIcinga
Появилась как форк Nagios. Поддерживает сбор данных с помощью агентов, а также расширений и собственных скриптов. Имеются инструменты для анализа данных, подсистема рассылки уведомлений и веб-интерфейс. Свободно распространяется по лицензии GNU GPL v2 (бесплатно)Prometheus
Ядро – БД временных рядов (Time series database, TSDB). Поддерживает сбор данных из различных источников посредством экспортеров и шлюза PushGateway. Имеются инструменты для анализа данных, подсистема уведомлений и простой веб-интерфейс. Для визуализации рекомендуется использовать Grafana. Свободно распространяется по лицензии Apache License 2.0 (бесплатно)VictoriaMetrics
Ядро – БД временных рядов (TSDB). Поддерживает сбор данных из различных источников посредством экспортеров (совместимых с Prometheus), интеграции с внешними системами (например, Prometheus) и прямых запросов на вставку. Имеются инструменты для анализа данных, подсистема уведомлений и простой веб-интерфейс. Для визуализации рекомендуется использовать Grafana. Свободно распространяется по лицензии Apache License 2.0 (бесплатно)Grafana
Не является системой мониторинга, однако не упомянуть ее в контексте статьи просто нельзя. Является прекрасной системой визуализации и анализа информации, которая позволяет «из коробки» работать с широким спектром источников данных (data source) – Elasticsearch, Loki, MS SQL, MySQL, PostgreSQL, Prometheus и др. При необходимости также интегрируется с Zabbix, PRTG и др. системами. Свободно распространяется по лицензии GNU AGPL v3 (бесплатно)
Читать подробнее:
Работа с Prometheus и Grafana
Рассмотрим подробнее схему взаимодействия компонентов системы мониторинга на основе Prometheus. Базовая конфигурация состоит из трех компонентов экосистемы:
Экспортеры (exporters)
Экспортер собирает данные и возвращает их в виде набора метрик. Экспортеры делятся на официальные (написанные командой Prometheus) и неофициальные (написанные разработчиками различного программного обеспечения для интеграции с Prometheus). При необходимости есть возможность писать свои экспортеры и расширять существующие дополнительными метрикамиPrometheus
Получает метрики от экспортеров и сохраняет их в БД временных рядов. Поддерживает мощный язык запросов PromQL (Prometheus Query Language) для выборки и аггрегации метрик. Позволяет строить простые графики и формировать правила уведомлений (alerts) на основе выражений PromQL для отправки через AlertmanagerAlertmanager
Обрабатывает уведомления от Prometheus и рассылает их. С помощью механизма приемников (receivers) реализована интеграция с почтой (SMTP), Telegram, Slack и др. системами, а также отправка сообщений в собственный API посредством вебхуков (webhook)
Таким образом, базовая конфигурация позволяет собирать данные, писать сложные запросы и отправлять уведомления на их основе. Однако по-настоящему потенциал Prometheus раскрывается при добавлении двух дополнительных компонентов (или как минимум одного – Grafana):
VictoriaMetrics
Получает метрики из Prometheus посредством remote write. Поддерживает язык запросов MetricsQL, синтаксис которого совместим с PromQL. Предоставляет оптимизированное по потреблению ресурсов хранение данных и высокопроизводительное выполнение запросов. Идеально подходит для долговременного хранения большого количества метрикGrafana
Предоставляет средства визуализации и дополнительного анализа информации из Prometheus и VictoriaMetrics. Есть примеры дашбордов практически под любые задачи, которые при необходимости можно легко доработать. Создание собственных дашбордов также интуитивно (разумеется, за исключением некоторых тонкостей) – достаточно знать основы PromQL / MetricsQL
Де-факто использование Grafana вместе с Prometheus уже стало стандартом, в то время как добавление в конфигурацию VictoriaMetrics безусловно опционально и необходимо скорее для высоконагруженных систем.

Практика
Итак, система мониторинга на основе Prometheus – PAVG (Prometheus, Alertmanager, VictoriaMetrics, Grafana) – предоставляет широкий спектр возможностей. Рассмотрим ее практическое применение. Для упрощения предположим, что основные компоненты будут развернуты на одном сервере мониторинга с применением docker и systemd, а также вынесем требования безопасности за рамки данной статьи.
Важное примечание
Все ниженаписанное является лишь иллюстрацией, которая призвана помочь ознакомиться с рассматриваемой системой
Развертывание экспортеров
Экспортеры могут быть развернуты на сервере мониторинга (например blackbox), на целевых серверах (kafka, mongodb, jmx и др.) или на всех серверах (node, cadvisor и др.). Как правило не требовательны к аппаратным ресурсам. В качестве примера возьмем три экспортера – node (сбор данных по ЦПУ, ОЗУ, дисковой подсистеме и сети), cadvisor (сбор информации о контейнерах) и blackbox (проверка точек входа TCP, HTTP/HTTPS и др.). Для развертывания необходимо:
Создать /etc/systemd/system/node-exporter.service
node-exporter.service
[Unit] Description=node exporter Requires=docker.service After=docker.service [Service] Restart=always ExecStartPre=-/usr/bin/docker rm node-exporter ExecStart=/usr/bin/docker run \ --rm \ --publish=9100:9100 \ --memory=64m \ --volume="/proc:/host/proc:ro" \ --volume="/sys:/host/sys:ro" \ --volume="/:/rootfs:ro" \ --name=node-exporter \ prom/node-exporter:v1.1.2 ExecStop=/usr/bin/docker stop -t 10 node-exporter [Install] WantedBy=multi-user.targetСоздать /etc/systemd/system/cadvisor.service
cadvisor.service
[Unit] Description=cadvisor Requires=docker.service After=docker.service [Service] Restart=always ExecStartPre=-/usr/bin/docker rm cadvisor ExecStart=/usr/bin/docker run \ --rm \ --publish=8080:8080 \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:ro \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --volume=/dev/disk/:/dev/disk:ro \ --privileged=true \ --name=cadvisor \ gcr.io/cadvisor/cadvisor:v0.44.0 ExecStop=/usr/bin/docker stop -t 10 cadvisor [Install] WantedBy=multi-user.targetСоздать /etc/systemd/system/blackbox-exporter.service
blackbox-exporter.service
[Unit] Description=blackbox exporter Requires=docker.service After=docker.service [Service] Restart=always ExecStartPre=-/usr/bin/docker rm blackbox-exporter ExecStart=/usr/bin/docker run \ --rm \ --publish=9115:9115 \ --memory=64m \ --name=blackbox-exporter \ prom/blackbox-exporter:v0.22.0 ExecStop=/usr/bin/docker stop -t 10 blackbox-exporter [Install] WantedBy=multi-user.targetЗапустить сервисы
sudo systemctl daemon-reload sudo systemctl start node-exporter cadvisor blackbox-exporter sudo systemctl status node-exporter cadvisor blackbox-exporter sudo systemctl enable node-exporter cadvisor blackbox-exporterПроверить работу (здесь <hostname> – DNS запись или IP адрес вашего сервера)
http://<hostname>:9100/metrics (node)
http://<hostname>:8080/metrics (cadvisor)
http://<hostname>:9115/metrics (blackbox)
http://<hostname>:9115/probe?target=github.com&module=http_2xx
http://<hostname>:9115/probe?target=github.com:443&module=tcp_connect
Экспортеры реализованы практически под все распространенное программное обеспечение, причем зачастую от нескольких разработчиков с разным набором метрик. Поиск не составляет труда – достаточно дать запрос на GitHub, DockerHub или в любимой поисковой системе. Однако в случае необходимости можно написать свой экспортер – например на Go или Python.
Развертывание Alertmanager
Как правило не требователен к аппаратным ресурсам. Для развертывания необходимо:
Подготовить каталог для конфигурационного файла
sudo mkdir /etc/alertmanagerСоздать /etc/alertmanager/alertmanager.yml
alertmanager.yml
global: resolve_timeout: 10s # mail configuration smtp_smarthost: "<smtp_server_address>:25" smtp_from: "<smtp_from>" smtp_auth_username: "<smtp_username>" smtp_auth_password: "<smtp_password>" route: # default receiver receiver: "webhook_alert" group_wait: 20s group_interval: 1m group_by: [service] repeat_interval: 3h # receiver tree routes: - receiver: "mail" match_re: severity: warning|error|critical continue: true - receiver: "webhook_alert" match_re: severity: warning|error|critical continue: true - receiver: "webhook_report" match_re: severity: info # receiver settings receivers: - name: "mail" email_configs: - to: <mail_to> - name: "webhook_alert" webhook_configs: - send_resolved: true # api endpoint for webhook url: http://webhook_api_url/alert - name: "webhook_report" webhook_configs: - send_resolved: false # api endpoint for webhook url: http://webhook_api_url/reportВ рассматриваемом примере уведомления рассылаются на почту и две дополнительные точки входа API – для срочных уведомлений (warning|error|critical) и отчетов (info). Подробнее о подготовке конфигурации можно почитать в статье Alerting Configuration
Создать /etc/systemd/system/alertmanager.service
alertmanager.service
[Unit] Description=alertmanager Requires=docker.service After=docker.service [Service] Restart=always ExecStartPre=-/usr/bin/docker rm alertmanager ExecStart=/usr/bin/docker run \ --rm \ --publish=9093:9093 \ --memory=512m \ --volume=/etc/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml:ro \ --name=alertmanager \ prom/alertmanager:v0.23.0 \ --config.file=/etc/alertmanager/alertmanager.yml ExecStop=/usr/bin/docker stop -t 10 alertmanager [Install] WantedBy=multi-user.targetЗапустить сервис
sudo systemctl daemon-reload sudo systemctl start alertmanager sudo systemctl status alertmanager sudo systemctl enable alertmanagerПроверить работу (здесь <hostname> – DNS запись или IP адрес вашего сервера)
http://<hostname>:9093
http://<hostname>:9093/#/alerts
http://<hostname>:9093/#/status
Для обеспечения высокой доступности Alertmanager поддерживает развертывание в кластерной конфигурации. Подробнее о создании кластера можно почитать в статье Alerting High Availability.
Развертывание VictoriaMetrics
Потребление ресурсов VictoriaMetrics зависит от количества опрашиваемых экспортеров и собираемых метрик, нагрузки запросами на чтение, глубины хранения данных и др. факторов. Вывести средние значения для старта достаточно сложно, однако для небольшой инсталляции достаточно 1 ядра ЦПУ, 2 ГБ ОЗУ и 20 ГБ дискового пространства. Для развертывания необходимо:
Подготовить каталог для хранения данных
sudo mkdir -p /data/victoriametricsСоздать /etc/systemd/system/victoriametrics.service
victoriametrics.service
[Unit] Description=victoriametrics Requires=docker.service After=docker.service [Service] Restart=always ExecStartPre=-/usr/bin/docker rm victoriametrics ExecStart=/usr/bin/docker run \ --rm \ --publish=8428:8428 \ --volume=/data/victoriametrics:/victoria-metrics-data \ --name=victoriametrics \ victoriametrics/victoria-metrics:v1.55.1 \ -dedup.minScrapeInterval=60s \ -retentionPeriod=2 ExecStop=/usr/bin/docker stop -t 10 victoriametrics [Install] WantedBy=multi-user.targetУказано хранение метрик в течение 2 месяцев
Запустить сервис
sudo systemctl daemon-reload sudo systemctl start victoriametrics sudo systemctl status victoriametrics sudo systemctl enable victoriametricsПроверить работу (здесь <hostname> – DNS запись или IP адрес вашего сервера):
http://<hostname>:8428
Развертывание Prometheus
Потребление ресурсов Prometheus зависит от количества опрашиваемых экспортеров и собираемых метрик, нагрузки запросами на чтение, глубины хранения данных и др. факторов. Вывести средние значения для старта достаточно сложно, однако для небольшой инсталляции достаточно 1 ядра ЦПУ, 2 ГБ ОЗУ и 20 ГБ дискового пространства. Для развертывания необходимо:
Создать пользователя и подготовить каталоги для конфигурационных файлов и хранения данных
sudo useradd -M -u 1101 -s /bin/false prometheus sudo mkdir -p /etc/prometheus/rule_files # каталог конфигурации sudo mkdir -p /data/prometheus # каталог данных sudo chown -R prometheus /etc/prometheus /data/prometheusОбязательно убедиться, что на раздел с каталогом для хранения данных выделено достаточно дискового пространства
Создать конфигурационный файл /etc/prometheus/prometheus.yml (здесь <hostname> – DNS запись или IP адрес вашего сервера)
prometheus.yml
global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 30s # alerting settings alerting: alertmanagers: - follow_redirects: true timeout: 10s static_configs: - targets: - <hostname>:9093 # alert rule files rule_files: - /etc/prometheus/rule_files/*.yml # remote write to victoriametrics remote_write: - url: http://<hostname>:8428/api/v1/write remote_timeout: 30s # scrape exporter jobs scrape_configs: - job_name: 'prometheus' static_configs: - targets: - <hostname>:9090 - job_name: 'node' metrics_path: /metrics static_configs: - targets: - <hostname>:9100 - job_name: 'cadvisor' metrics_path: /metrics static_configs: - targets: - <hostname>:8080 - job_name: 'blackbox' metrics_path: /metrics static_configs: - targets: - <hostname>:9115 - job_name: 'blackbox-tcp' metrics_path: /probe params: module: [tcp_connect] static_configs: - targets: - github.com:443 relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: <hostname>:9115 - job_name: 'blackbox-http' metrics_path: /probe params: module: [http_2xx] static_configs: - targets: - https://github.com relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [__param_target] target_label: instance - target_label: __address__ replacement: <hostname>:9115Создать правила уведомлений /etc/prometheus/rule_files/main.yml
rule_files/main.yml
groups: - name: target rules: - alert: target_down expr: up == 0 for: 1m labels: service: target severity: critical annotations: summary: 'Target down! Failed to scrape {{ $labels.job }} on {{ $labels.instance }}' - name: probe rules: - alert: probe_down expr: probe_success == 0 for: 1m labels: service: probe severity: error annotations: summary: 'Probe {{ $labels.instance }} down' - name: hardware rules: - alert: hardware_cpu expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[1m])) * 100) > 75 for: 3m labels: service: hardware severity: warning annotations: summary: 'High CPU load on {{ $labels.instance }} - {{ $value | printf "%.2f" }}%' - alert: hardware_memory expr: 100 - ((node_memory_MemAvailable_bytes * 100) / node_memory_MemTotal_bytes) > 85 for: 3m labels: service: hardware severity: warning annotations: summary: 'High memory utilization on {{ $labels.instance }} - {{ $value | printf "%.2f" }}%' - alert: hardware_disk expr: (node_filesystem_free_bytes / node_filesystem_size_bytes * 100) < 25 for: 3m labels: service: hardware severity: error annotations: summary: 'Low free space on {{ $labels.instance }} device {{ $labels.device }} mounted on {{ $labels.mountpoint }} - {{ $value | printf "%.2f" }}%' - name: container rules: - alert: container_down expr: (time() - container_last_seen) > 60 for: 1m labels: service: container severity: error annotations: summary: 'Container down! Last seen {{ $labels.name }} on {{ $labels.instance }} - {{ $value | printf "%.2f" }}s ago'В данном случае для примера мы добавили только один файл c несколькими группами правил, однако в больших инсталляциях для удобства группы распределены по различным файлам – application, container, hardware, kubernetes, mongodb, elasticsearch и т.д.
Создать /etc/systemd/system/prometheus.service
prometheus.service
[Unit] Description=prometheus Requires=docker.service After=docker.service [Service] Restart=always ExecStartPre=-/usr/bin/docker rm prometheus ExecStart=/usr/bin/docker run \ --rm \ --user=1101 \ --publish=9090:9090 \ --memory=2048m \ --volume=/etc/prometheus/:/etc/prometheus/ \ --volume=/data/prometheus/:/prometheus/ \ --name=prometheus \ prom/prometheus:v2.30.3 \ --config.file=/etc/prometheus/prometheus.yml \ --storage.tsdb.path=/prometheus \ --storage.tsdb.retention.time=14d ExecStop=/usr/bin/docker stop -t 10 prometheus [Install] WantedBy=multi-user.targetУказано хранение метрик в течение 14 суток
Запустить сервис
sudo systemctl daemon-reload sudo systemctl start prometheus sudo systemctl status prometheus sudo systemctl enable prometheusПроверить работу (здесь <hostname> – DNS запись или IP адрес вашего сервера)
http://<hostname>:9090
Status → Configuration, Status → Rules, Status → Targets
Для обеспечения высокой доступности Prometheus может быть развернут в нескольких экземплярах, каждый из которых будет опрашивать экспортеры и сохранять данные в локальную БД.
Развертывание Grafana
Grafana не слишком требовательна к потреблению ресурсов – для небольшой инсталляции достаточно 1 ядра ЦПУ и 1 ГБ ОЗУ (хотя, конечно, есть нюанс...). Для развертывания необходимо:
Создать пользователя и подготовить каталоги для конфигурационных файлов и хранения данных
sudo useradd -M -u 1102 -s /bin/false grafana sudo mkdir -p /etc/grafana/provisioning/datasources # каталог декларативного описания источников данных sudo mkdir /etc/grafana/provisioning/dashboards # каталог декларативного описания дашбордов sudo mkdir -p /data/grafana/dashboards # каталог данных sudo chown -R grafana /etc/grafana/ /data/grafanaСоздать файл декларативного описания источников данных /etc/grafana/provisioning/datasources/main.yml (здесь <hostname> – DNS запись или IP адрес вашего сервера)
datasources/main.yml
apiVersion: 1 datasources: - name: Prometheus type: prometheus version: 1 access: proxy orgId: 1 basicAuth: false editable: false url: http://<hostname>:9090 - name: VictoriaMetrics type: prometheus version: 1 access: proxy orgId: 1 basicAuth: false editable: false url: http://<hostname>:8428Создать файл декларативного описания дашбордов /etc/grafana/provisioning/dashboards/main.yml
dashboards/main.yml
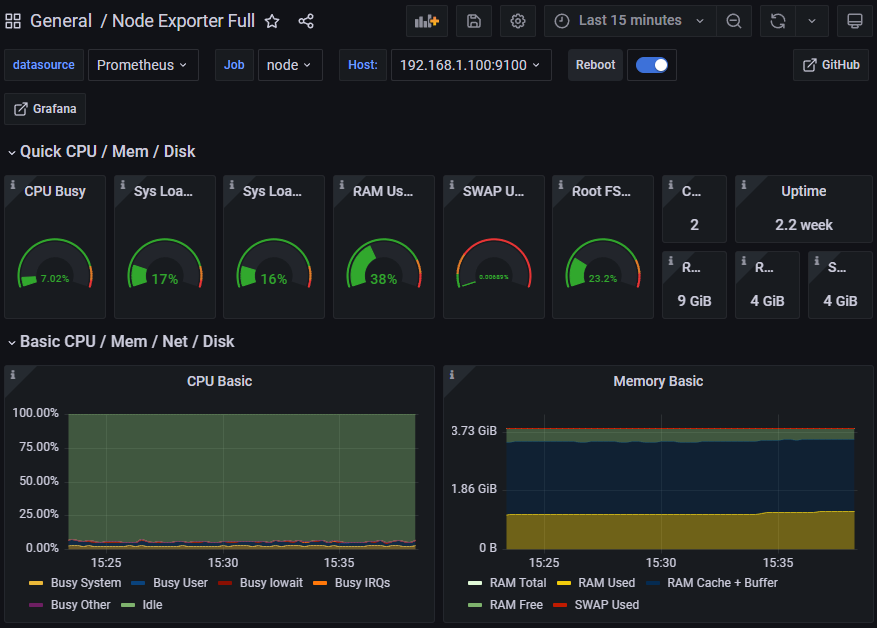
apiVersion: 1 providers: - name: 'main' orgId: 1 folder: '' type: file disableDeletion: false editable: True options: path: /var/lib/grafana/dashboardsДобавить дашборд Node Exporter Full в каталог /data/grafana/dashboards
cd ~/ && git clone https://github.com/rfmoz/grafana-dashboards sudo cp grafana-dashboards/prometheus/node-exporter-full.json /data/grafana/dashboards/Репозиторий и его содержимое актуальны на начало 2023 года
Создать /etc/systemd/system/grafana.service
grafana.service
[Unit] Description=grafana Requires=docker.service After=docker.service [Service] Restart=always ExecStartPre=-/usr/bin/docker rm grafana ExecStart=/usr/bin/docker run \ --rm \ --user=1102 \ --publish=3000:3000 \ --memory=1024m \ --volume=/etc/grafana/provisioning:/etc/grafana/provisioning \ --volume=/data/grafana:/var/lib/grafana \ --name=grafana \ grafana/grafana:9.2.8 ExecStop=/usr/bin/docker stop -t 10 grafana [Install] WantedBy=multi-user.targetЗапустить сервис
sudo systemctl daemon-reload sudo systemctl start grafana sudo systemctl status grafana sudo systemctl enable grafanaПроверить работу (здесь <hostname> – DNS запись или IP адрес вашего сервера)
http://<hostname>:3000 (учетные данные по умолчанию – admin/admin, желательно сразу изменить пароль)
Configuration → Data sources
Explore → Metric → up → Run query
Dashboards → Browse → General → Node Exporter Full
Подсказки
На практике могут быть полезны следующие простые советы:
Ищите проверенные экспортеры под свои потребности. В этом может помочь статья Топ-10 экспортеров для Prometheus 2023
Обязательно изучите PromQL Cheat Sheet
Почаще исследуйте метрики в «сыром» виде (от экспортеров)
Система мониторинга на основе Prometheus описывается декларативно. Храните конфигурации в git и используйте ansible для автоматизации
За помощь в подготовке статьи автор выражает благодарность @novikov0805, @Eviil и @KoPashka
Все статьи серии:

