Введение
Настоящий хреновый программист всегда находится на гребне волны новых технологий. Зачем ему это? Чтобы при случае можно было повыделываться багажом своих знаний, и заработать немного очков уважения в окружении своих менее осведомлённых коллег. Stay toxic, brothers. Я с вами.
Когда-то давно мне нужно было обработать чуть больше тысячи жирнейших excel-таблиц и сделать это нужно было быстро. Буквально за час я вкатился в Python и Pandas, а за второй час выполнил все необходимые манипуляции. Так я и познакомился с этими двумя. С тех самых пор приходилось выполнять самые разные задачи по анализу данных и всё бы ничего, но хотелось бы, чтобы Pandas работал побыстрее. Оказывается хотелось не одному мне, а целой команде разработчиков, на Rust.
Как и полагается, всё что на Rust то Blazingly-Fast, и Polars не стала исключением. За счёт чего Polars быстрее Pandas? Что это за библиотека и стоит ли на неё переходить? Давайте попробуем разобраться в этой статье.
Что такое Polars?
Одна из ключевых особенностей Polars заключается в том, что он полностью написан на Rust, но вам не нужно знать Rust, чтобы его использовать, потому что у него есть пакет Python, который предлагает интерфейс, аналогичный Pandas.
Прежде чем двигаться дальше, давайте взглянем на бенчмарки с официального сайта Polars.
")
Небольшое пояснение к бенчмарку выше. Чтение паркета — это процесс извлечения данных, хранящихся в формате файла паркета. Parquet — это формат столбцового хранения, который широко используется в экосистеме Hadoop для эффективного хранения больших объемов данных. Он особенно популярен для хранения данных в формате Apache Parquet, поскольку он оптимизирован для быстрого чтения и записи и используется многими системами обработки данных, включая Apache Spark, Apache Flink и Apache Impala. Когда вы читаете паркет, вы извлекаете данные из файла паркета и загружаете их в программу или систему для дальнейшей обработки или анализа.
")
Как мы видим, разница в скорости невероятная. Важно понимать, что сам по себе Rust не является причиной прироста производительности. Всё дело в том, что Polars использует все ядра компьютера, и это реализовано на системном уровне. Pandas работает в однопоточном режиме, чтобы распараллелить процессинг датафреймов в этом случае, придётся использоваться Dask.
На этом отличия не заканчиваются. Polars предлагает на выбор два API: eager и lazy. Eager такое же как у Pandas, т.е. код выполняется незамедлительно. Напротив, lazy выполнение не запускается до тех пор, пока этого не потребуется, что делает код эффективнее, поскольку позволяет избежать исполнения ненужных инструкций, что как следствие повышает производительность.
Установка и использование
Для установки необходимо выполнить команду в терминале:
pip install polars
Проверяем что Polars точно установлен, выведем версию. Для дальнейших демонстраций я буду использовать JupyterLab.
import polars as pl print(pl.__version__)

Прочтём датафрейм с помощью Polars. Синтаксис очень похож на Pandas.
df = pl.read_csv("https://j.mp/iriscsv")

Датафрейм прочтён, разобран по колонкам и типам данных, точно также, как если бы мы использовали Pandas. Давайте попробуем отфильровать эти данные. Для этого необходимо вызвать методdf.filter(), который является аналогом query()в Pandas. Отфильтруем только те записи, у которых значение sepal_length > 5:
df.filter(pl.col("sepal_length") > 5)

Отлично, а теперь попробуем сгруппировать и агрегировать записи:
filtered = (df.filter(pl.col("sepal_length") > 5) .groupby('species', maintain_order=True) .agg(pl.all().sum()) ) print(filtered)

Для сравнения, давайте посмотрим как будет выглядеть код, если написать такой же фильтр с помощью Pandas:
import pandas as pd df = pd.read_csv("https://j.mp/iriscsv") df.query('sepal_length > 5') \ .groupby('species').sum()

Как мы видим, синтаксис немного отличается, конечно, это субъективщина, но мне больше нравится синтаксис Polars. Самое главное, что мы получили одинаковый результат. Давайте взглянем на Lazy API. Попробуем переписать этот фильтр.
(pl.read_csv("https://j.mp/iriscsv") .lazy() .filter(pl.col('sepal_length') > 5) .groupby('species', maintain_order=True) .agg(pl.all().sum()) .collect() )

Что ж с Lazy API тоже всё понятно, главное не забыть вызвать метод collect() в конце запроса иначе вы увидите вот такую картину:
")
С Polars мы можем оперировать теми же сущностями, с которыми привыкли работать с Pandas: series и dataframe.

Лично я редко пользуюсь этими блоками. Чаще всего мне приходится работать с файлами.

Например, попробуем прочесть parquet-файл:
sample_parquet = pl.read_parquet('https://github.com/kaysush/sample-parquet-files/blob/main/part-00000-a9e77425-5fb4-456f-ba52-f821123bd193-c000.snappy.parquet?raw=true')

Polars предлагает большой набор методов для работы с этим датафреймом, например:
# describe() покажет нам всю информацию о каждом столбце sample_parquet.describe()
")
# sample(3) покажет нам 3 случайные записи sample_parquet.sample(3)
")
# Мы можем выбрать определённый набор столбцов sample_parquet.select(pl.col(['id', 'first_name', 'last_name']))

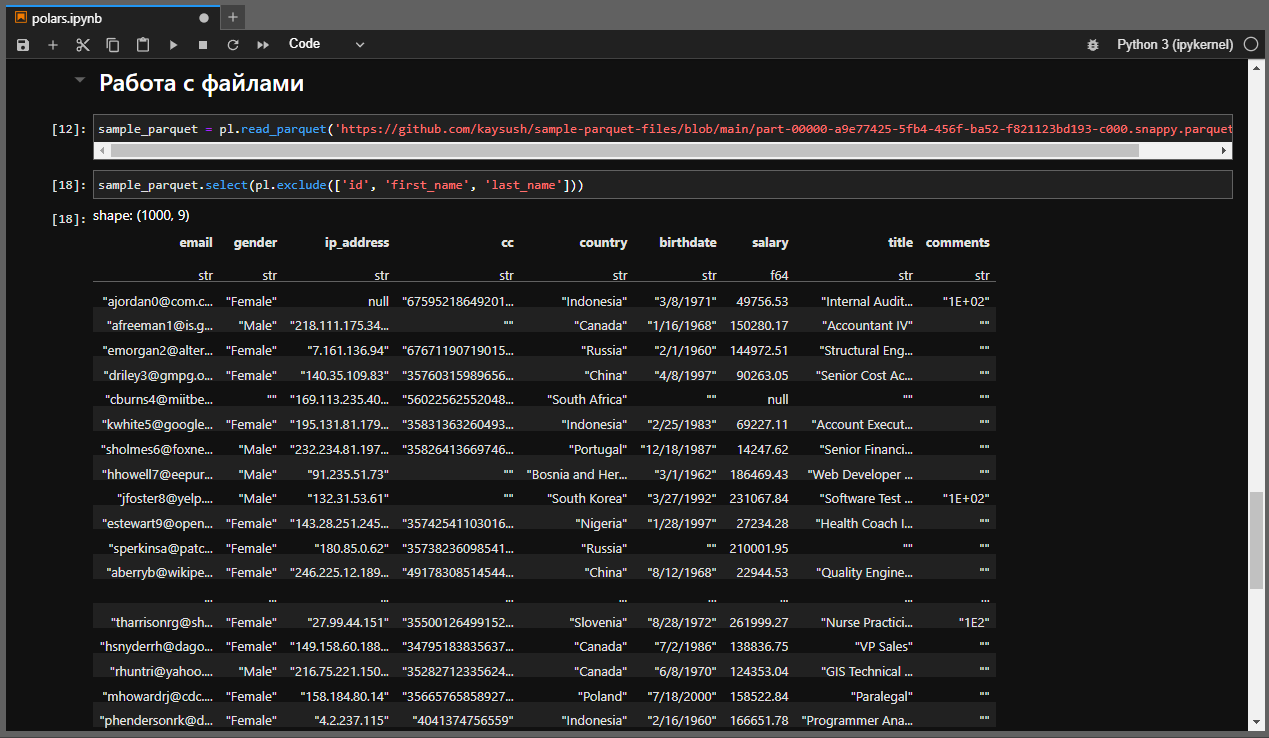
# Или наоборот исключить определённые столбцы sample_parquet.select(pl.exclude(['id', 'first_name', 'last_name']))
Фильтрация
Для примера давайте напишем фильтр, который будет фильтровать пользователей по зарплате:
sample_parquet.filter( pl.col('salary').is_between(100000.0, 150000.0) )

Мы также можем написать фильтр для нескольких столбцов:
sample_parquet.filter( (pl.col('salary').is_between(100000.0, 150000.0)) & (pl.col('country') == "Russia") )

Добавление новых столбцов
Добавление новых столбцов в Polars немного отличается от того, что вы привыкли видеть в Pandas:
sample_parquet.with_columns([ ((pl.col('gender') == "Female") & (pl.col('country') == "Russia")).alias('russian_female') ])
В данном случае, мы добавили новый столбец с типом данных boolean, в котором храним признак того, что пользователь удовлетворяет условию (pl.col('gender') == "Female") & (pl.col('country') == "Russia")

Группирование
Мы также можем сгруппировать нужные нам данные и получить совершенно иной датафрейм. Например, давайте попробуем вывести таблицу со всеми странами и их средней зарплатой:
print(sample_parquet.groupby('country', maintain_order=True).agg([ pl.col('salary').mean().alias('average_salary') ]))

Объединение датафреймов
Также как и в Pandas, где вы можете объединять фреймы с помощью pd.concat() и pd.merge(), вы можете использовать следующие методы в Polars.
Создадим датафреймы, которые хотим мержить:
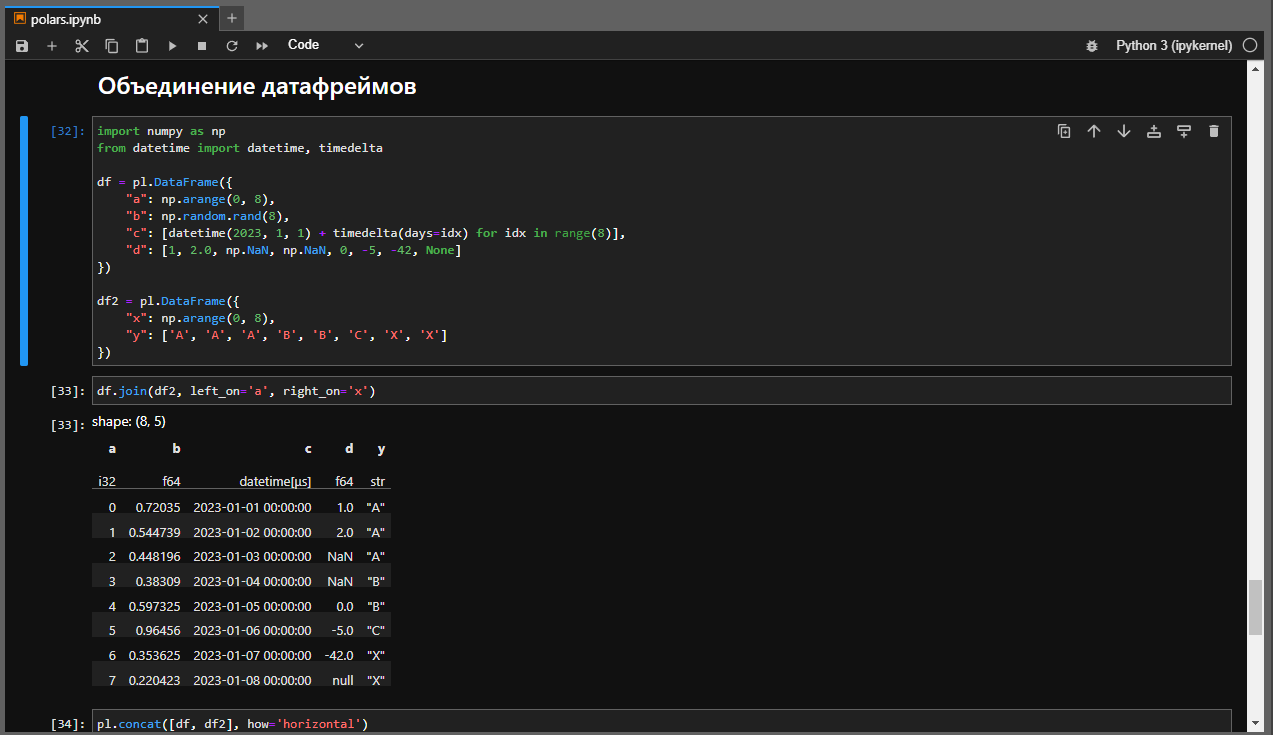
import numpy as np from datetime import datetime, timedelta df = pl.DataFrame({ "a": np.arange(0, 8), "b": np.random.rand(8), "c": [datetime(2023, 1, 1) + timedelta(days=idx) for idx in range(8)], "d": [1, 2.0, np.NaN, np.NaN, 0, -5, -42, None] }) df2 = pl.DataFrame({ "x": np.arange(0, 8), "y": ['A', 'A', 'A', 'B', 'B', 'C', 'X', 'X'] })
Для объединения датафреймов достаточно вызвать метод join()
df.join(df2, left_on='a', right_on='x')
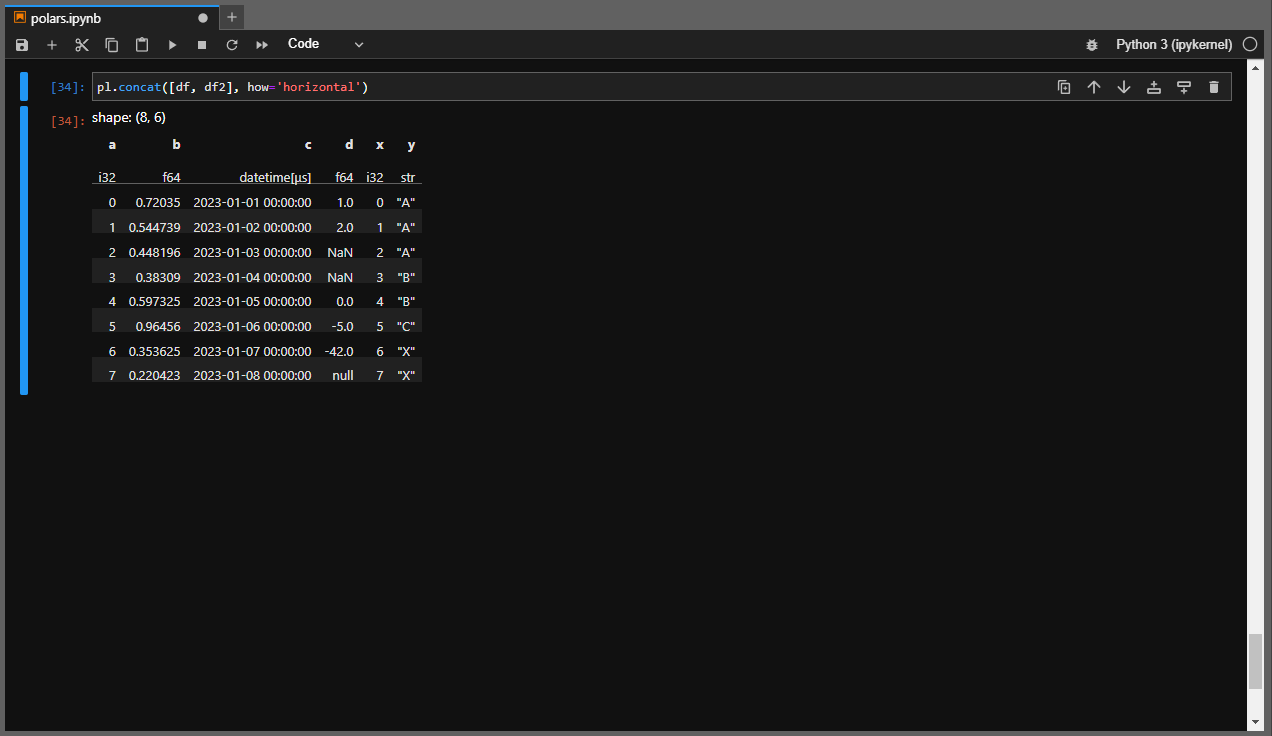
Ну а если мы хотим объединить датафреймы, но в стиле стака, то достаточно вызвать метод concat():
# how='horizontal' аналог axis из Pandas pl.concat([df, df2], how='horizontal')
Многопоточность
Многопоточная обработка табличных данных возможна благодаря подходу "split-apply-combine". Этот набор операций лежит в основе реализации группирования данных, благодаря чему растёт скорость исполнения. Если говорить точнее, то только фазы "split" и "apply" исполняются в многопоточном режиме.

Диаграмма сверху показывает как будет происходить группирование результатов для абстрактного датафрейма. Сначала данные будут разделены на группы (split) , а затем значения каждой группы будут агрегированы в параллельном режиме (apply). Что означает, что чем больше у вас ядер, тем быстрее произойдёт эта операция.
В первом приближении реализация многопоточности в Polars выглядит именно так. Более подробно можно прочитать в документации на официальном сайта. А мы пойдём дальше к тесту производительности.
Тест производительности
Для тестирования скорости работы библиотек попробуем сгруппировать данные по двум столбцам:

Как мы видим замер с помощью %%timeit показывает разницу больше чем в 5 раз. Внушительно...
Заключение
На этом я бы закончить свой обзор библиотеки Polars. Из всех альтернатив Pandas с которыми мне приходилось иметь дело, Polars произвёл на меня наибольшее впечатление. Не думаю, что кто-то будет переписывать на него уже имеющуюся кодовую базу, но приятно знать что где-то там есть более быстрый инструмент, который можно использовать в случае необходимости.
Не подписывайся на нас в телеграмм, ни в коем случае, чтобы мы не стали очередным каналом, в который ты никогда не заходишь. Там мы постим несмешные мемы, неинтересные новости из мира программирования, делимся своим не очень важным мнением и немногое другое.

