
Недавние достижения в области генерации изображений на основе искусственного интеллекта, возглавляемые диффузионными моделями, такими как Glide, Dalle-2, Imagen и Stable Diffusion, взяли мир “искусственного интеллекта” штурмом. Создание высококачественных изображений на основе текстовых описаний - сложная задача. Это требует глубокого понимания основного значения текста и способности генерировать изображение, соответствующее этому значению.В последние годы диффузионные модели стали мощным инструментом для решения этой проблемы.
Эти модели позволяют невероятно легко создавать высококачественные изображения в различных стилях, используя всего несколько слов. Например, мы создали изображение ниже, просто предоставив подсказку:
“дом в лесу, темная ночь, листья в воздухе, флуоресцентные грибы, четкий фокус, очень четкая, очень подробная, контрастная, яркая, цифровая живопись”


В этой статье рассмотрим следующие темы в понятной и простой форме, понятной для любого новичка в захватывающем мире диффузионных моделей для генерации изображений.
Кратко обсудим пространство моделей генерации изображений на основе глубокого обучения, а также плюсы и минусы различных используемых методов.
Объясним в простых терминах, что такое “диффузия” и как работают диффузионные модели.
Представим высокоуровневый обзор четырех наиболее популярных диффузионных моделей:
Dall-E 2 от OpenAI
Imagen от Google
StabilityAI’s Stable Diffusion
Midjourney
Наконец, обсудим некоторые приложения и веб-сайты, которые предоставляют услуги, связанные с диффузионными моделями, или используют диффузионные модели в качестве сервиса.
Содержание
Что такое генеративные модели?
Большинство задач машинного обучения и глубокого обучения, которые вы решаете, концептуализируются из Генеративных и дискриминационных модели. Проще говоря, “генеративные модели” - это статистические модели, предназначенные для “генерации / синтеза данных”. Их задача состоит в том, чтобы “преобразовать шум в репрезентативную выборку данных”.
На протяжении многих лет мы видели много творческих применений генеративных моделей. Одним из конкретных приложений, которое большинство из нас помнит, была реклама Cadbury, в которой использовались Генерация звука и синхронизация по губам составить карту выражения лица и речи различных знаменитостей. Его можно использовать для создания персонализированной рекламы знаменитостей.
Четыре хорошо известные модели генерации изображений, основанные на глубоком обучении::
Вариационные автоэнкодеры (VAE)
Flow-based models
Генеративные состязательные сети (GAN).
Diffusion (недавняя тенденция)

Эти модели сначала обучаются, чтобы научиться моделировать “распределение данных” (обучающих данных). После обучения модель знает, как аппроксимировать исходное распределение данных, и может использовать его для генерации новых данных (изображений) по желанию.
Предшественником понимания “Variational Autoencoders” являются “Autoencoders”. Основной задачей автоэнкодеров является сжатие данных. Архитектура автоэнкодеров довольно проста. Оно содержит три компонента:
Кодировщик
Узкое место (ответственное за сжатие)
Декодер
Дополнительным преимуществом этой конструкции является то, что мы можем использовать Автоэнкодеры для шумоподавления изображения.
В автоэнкодерах распределение сжатых данных / скрытых данных “без ограничений”. Данные сжимаются таким образом, что ошибка восстановления минимальна. Это приводит к серьезному недостатку, т.е. потому, что у нас нет представления / информации о распределении скрытого, поэтому генерировать новые выборки (используя только декодер) сложно.
В вариационных автоэнкодерах это больше не проблема. К уровню узких мест добавляется ограничение, поэтому сжатые данные кодера должны максимально точно имитировать (простое, подобранное вручную) распределение вероятностей (обычно стандартное гауссово). Чтобы сгенерировать новые выборки, мы можем просто выбрать точку из выбранного распределения вероятностей и передать ее в декодер.
На момент написания статьи мы все еще не определились с единой моделью для всех задач, связанных с генеративным моделированием, и это справедливо. В каждой области применения есть свои проблемы, и люди обычно используют различные методы для их решения. Все четыре вышеперечисленные модели имеют проблемы, которые хорошо иллюстрируются на gif ниже.

Подводя итог:
VAE | Поток | GAN | Диффузия | |
Плюсы | Высокая частота дискретизации. Генерация разнообразных образцов | Высокая частота дискретизации. Генерация разнообразных образцов | Высокая частота дискретизации.Высокое качество генерации образцов. | Высокое качество генерации образцов.Генерация разнообразных образцов |
Минусы | Низкое качество генерации выборки | Требуется специализированная архитектура,низкое качество генерации выборки | Нестабильное обучение,низкое разнообразие генерации выборки(коллапс режима) | Низкая частота дискретизации |
Созданные в 14 году Иэном Гудфеллоу генеративные состязательные сети (GAN) были в значительной степени нормой для генерации образцов изображений.
Было создано множество вариаций оригинального GAN, таких как:
Условный GAN (cGAN): управление классом / категорией генерируемых изображений.
Глубокая сверточная GAN (DCGAN): архитектура значительно улучшает качество GAN с использованием сверточных слоев.
Преобразование изображения в изображение с помощью Pix2Pix: преобразование изображений из одного домена в другой путем изучения сопоставления между входом и выходом.
Сейчас, в эпоху диффузионных моделей, исследователи обязательно используют знания, накопленные за годы работы над GaN. Это одна из основных причин такого быстрого прогресса в диффузионных моделях за такой короткий промежуток времени.
Что такое диффузия?
Прежде чем мы разберемся с диффузионными моделями, давайте быстро разберемся в значении термина “диффузия”. Диффузия (или диффузионный процесс) является хорошо известной и изученной областью неравновесной статистической физики.
В неравновесной статистической физике процесс диффузии относится к:
“Перемещение частиц или молекул из области высокой концентрации в область низкой концентрации, обусловленное градиентом концентрации”.

Процесс диффузии обусловлен случайным движением частиц или молекул, описываемым законами термодинамики и статистической механики.
Что такое диффузионные модели?
В простых терминах – “Диффузионные модели представляют собой класс вероятностных генеративных моделей, которые превращают шум в репрезентативную выборку данных”.
Используя диффузионные модели, мы можем генерировать изображения как условно, так и безоговорочно.
Безусловная генерация изображений просто означает, что модель преобразует шум в любую “случайную репрезентативную выборку данных”. Процесс генерации не контролируется и не управляется, и модель может генерировать изображение любого характера.
Условная генерация изображений - это когда модели предоставляется дополнительная информация с помощью текста (text2img) или меток классов (как в CGANs). Это случай управляемой или управляемой генерации изображений. Предоставляя дополнительную информацию, мы ожидаем, что модель будет генерировать определенные наборы изображений. Например, вы можете обратиться к двум изображениям в начале сообщения.
В этом разделе мы сосредоточимся на процессе “безусловной генерации изображений”.

Немного истории…
Диффузионные модели в глубоком обучении были впервые представлены Соул-Дикштейном и др. в оригинальной статье 2015 года “Глубокое неконтролируемое обучение с использованием неравновесной термодинамики”. К сожалению, это оставалось за кулисами некоторое время.
Но в 2019 году Сонг и др. опубликовал статью “Генеративное моделирование путем оценки градиентов распределения данных”, использующую тот же принцип, но другой подход. В 2020 году Хо и др. опубликовал популярную в настоящее время статью “Вероятностные модели рассеяния шума” (сокращенно DDPM).
После 2020 года исследования в области диффузионных моделей начались 🚀. За относительно короткое время был достигнут значительный прогресс в создании, обучении и улучшении генеративного моделирования на основе диффузии.
Как работают диффузионные модели генерации изображений?
Общий принцип работы диффузионных моделей действительно прост для понимания.
Метод диффузии можно резюмировать следующим образом:
... систематически и медленно разрушать структуру в распределении данных посредством итеративного процесса прямого распространения. Затем мы изучаем процесс обратной диффузии, который восстанавливает структуру данных, создавая очень гибкую и послушную генеративную модель данных. Этот подход позволяет нам быстро изучать, отбирать и оценивать вероятности в глубоких генеративных моделях …
– Глубокое неконтролируемое обучение с использованием неравновесной термодинамики, 2015
Давайте сделаем шаг назад и посмотрим на GIF-изображение газовой диффузии выше. Когда банку открывают, молекулы зеленого газа быстро выходят из банки и попадают в окружающую среду. По сути, это диффузия. С течением времени концентрация молекул зеленого газа внутри и снаружи сосуда выравнивается.Распределение молекул газа полностью изменилось по сравнению с тем, как банка была открыта. Обратить вспять этот процесс - непростая задача; именно здесь на сцену выходит неравновесная статистическая физика.
Идея, используемая в неравновесной статистической физике, заключается в том, что мы можем постепенно преобразовывать одно распределение в другое.В 2015 году Sohl-Dicktein и др., вдохновленные этим, создали “Диффузионные вероятностные модели” или, короче говоря, “диффузионные модели”, основываясь на этой важной идее.
Они строят “генеративную цепочку Маркова, которая преобразует простое известное распределение (например, гауссово) в целевое (данные) распределение с использованием процесса диффузии”.
Цепочка Маркова просто означает, что состояние объекта / объекта в любой точке цепочки зависит исключительно от предыдущего объекта / объекта.
Теперь мы можем сделать это двумя способами, т. Е. Мы также можем преобразовать (неизвестное) распределение наших обучающих данных в другое распределение. И, чтобы добавить вишенку на вершине, оба (преобразование данных в шум и преобразование шума в данные) могут быть смоделированы с использованием одной и той же функциональной формы. Это именно то, что делается в диффузионных моделях.
Авторы описывают, что –
“Наша цель - определить прямой (или логический) процесс распространения, который преобразует любое сложное распределение данных в простое, понятное распределение, а затем изучить обращение этого процесса распространения за конечное время, которое определяет наше генеративное распределение модели”.
– Глубокое неконтролируемое обучение с использованием неравновесной термодинамики, 2015
Структура (распределение) исходного изображения постепенно разрушается путем добавления шума, а затем с использованием модели нейронной сети для восстановления изображения, т. Е. Удаления шума на каждом шаге. Выполняя это достаточное количество раз и с хорошими данными, модель в конечном итоге научится оценивать базовое (исходное) распределение данных. Затем мы можем просто начать с простого шума и использовать обученную нейронную сеть для создания нового изображения, представляющего исходный обучающий набор данных.

Мы только что описали два основных процесса / этапа, выполняемых каждой диффузионной моделью. Не вдаваясь в математические подробности, давайте рассмотрим их немного подробнее и воспользуемся приведенным выше изображением в качестве ссылки.
Прямое распространение:
Исходное изображение (x 0) медленно итеративно искажается (цепочка Маркова) путем добавления (масштабированного гауссова) шума.
Этот процесс выполняется для некоторых временных шагов T, т.Е. x T.
Изображение на временном шаге t создается: xt-1 + εt-1 (шум) → xt
На этом этапе модель не задействована.
В конце этапа прямой диффузии Xt, из-за итеративного добавления шума, мы остаемся с (чистым) зашумленным изображением, представляющим “изотропный гауссовский”. Это просто математический способ сказать, что у нас есть стандартное нормальное распределение, и дисперсия распределения одинакова по всем измерениям. Мы преобразовали распределение данных в гауссово распределение.
Обратная / Обратная диффузия:
На этом этапе мы отменяем процесс пересылки. Задача состоит в том, чтобы удалить шум, добавленный в прямом процессе, снова итеративным способом (цепочка Маркова). Это делается с использованием модели нейронной сети.
Задача модели заключается в следующем: учитывая временной интервал t и зашумленное изображение xt, спрогнозируйте шум (έ), добавленный к изображению на шаге t-1.
xt → Модель → έ (прогнозируемый шум). Модель предсказывает (аппроксимирует) шум, добавленный к x t-1 при прямом проходе.
Сравнение с GaN:
Из-за итеративного характера процесса распространения процесс обучения и генерации, как правило, более стабилен, чем GAN.
В GaN модель генератора должна перейти от чистого шума к изображению за один шаг Xt → x0, что является одним из источников нестабильного обучения.
В отличие от GAN, где для обучения требуются две модели, в диффузиях требуется только одна модель.
Одно из наблюдений из приведенного выше изображения заключается в том, что “размер изображения остается неизменным” на протяжении всего процесса, в отличие от GaN, где скрытый тензор может иметь разные размеры. Это может быть проблемой при создании высококачественных изображений из-за ограниченной памяти графического процессора. Однако авторы “Стабильной диффузии” (точнее, “скрытой диффузии”) обходят эту проблему, используя вариационный автоэнкодер.
Некоторые моменты, на которые следует обратить внимание в процессе диффузии:
Еще одним преимуществом итеративного характера является то, что мы проводим контролируемое обучение на каждом временном шаге.
В диффузионных моделях популярной архитектурой выбора является UNet (с вниманием), который обучается с использованием функции потерь MSE контролируемым образом.
На каждом временном шаге шум, добавляемый к изображению, контролируется с помощью “планировщика дисперсий” или просто “планировщика”. Задача планировщиков - определить, сколько шума следует добавить, чтобы во время прямого процесса изображение в конце xt было изотропным гауссовым.
В документе DDPM авторы использовали “линейный планировщик”. Это означает, что добавляемый шум при каждом временном шаге линейно увеличивался.
Количество временных шагов T было установлено равным T=1000. Итак, учитывая гауссовский шум, модели потребуется 1000 итераций для получения результата. Это проблема низкой частоты дискретизации, упомянутая в предыдущем разделе. Но в недавних работах, благодаря внедрению новых методов и различных планировщиков, исследователи могут создавать художественные изображения всего за T = 4 временных шага.
Хорошо известные диффузионные модели для генерации изображений

Давайте рассмотрим некоторые модели генерации изображений на основе диффузии, которые стали известными за последние несколько месяцев. Поскольку в настоящее время в этой области используются сотни диффузионных моделей и их вариаций, мы сделаем небольшую выборку из наших собственных и рассмотрим более известные. К ним относятся:
Dall-E 2 by OpenAI
Imagen by Google
Stable Diffusion by StabilityAI
Midjourney
Здесь мы не будем углубляться в вышеупомянутые архитектуры. Вместо этого мы рассмотрим обзор каждой модели и создадим специальный пост в будущем. Мы также ознакомимся с несколькими подсказками и изображениями, созданными Dall-E 2 и Stable Diffusion.
DALL-E 2
Dall-E 2 был опубликован OpenAI в апреле 2022 года. Оно основано на предыдущих новаторских работах OpenAI по GLIDE, CLIP и Dall-E. Хотя Dall-E 2 является превосходным преемником Dall-E, первый содержит 3,5 миллиарда параметров по сравнению с 12 миллиардами параметров в Dall-E.
Не вдаваясь в слишком много архитектурных деталей, Dall-E 2 представляет собой комбинацию трех разных моделей:
CLIP
Предшествующая нейронная сеть
Нейронная сеть декодера
На данный момент достаточно знать, что сеть декодера генерирует изображения во время вывода. Доступ к веб-интерфейсу Dall-E 2 можно получить, отправив запрос на официальном веб-сайте OpenAI.
Вот несколько подсказок и соответствующие им изображения, созданные Dall-E 2.

Imagen
После Dall-E 2, всего через месяц, в апреле 2022 года, Google выпустила свой алгоритм генерации изображений на основе диффузии. Они удачно назвали его Imagen (для генерации изображений).
Он построен поверх больших языковых моделей на основе transformer. Для своей публикации авторы Imagen выбрали языковую модель T5-XXL transformer. После него Imagen состоит из еще трех диффузионных моделей генерации изображений:
Диффузионная модель для создания изображения с разрешением 64 × 64.
Затем следует диффузионная модель с высоким разрешением для увеличения дискретизации изображения до разрешения 256 × 256.
И одна заключительная модель со сверхразрешением, которая увеличивает дискретизацию изображения до разрешения 1024 × 1024.
В настоящее время Imagen от Google недоступен для широкой публики и доступен только по приглашению.

Stable Diffusion
Создано StabilityAI. Stable Diffusion основывается на работе по синтезу изображений с высоким разрешением с использованием моделей скрытой диффузии Ромбаха и др. Это единственная модель генерации изображений на основе диффузии в этом списке, которая полностью с открытым исходным кодом.
На момент написания этой статьи версия Stable Diffusion v2.1 доступна в официальном репозитории StabilityAI.
Мало того, сообщество разработчиков с открытым исходным кодом было очень активным с момента его выпуска. За короткий промежуток времени сообщество выпустило несколько стабильных диффузионных моделей с открытым исходным кодом, доработанных для различных наборов данных, стилизованных под художественные. Можно свободно использовать эти модели и создавать новые изображения, используя эти стили.
Они могут варьироваться от японского аниме и футуристических роботов до киберпанковских миров. Просто чтобы заинтриговать ваше воображение, вот несколько примеров из стабильных диффузионных моделей.

Полная архитектура стабильной диффузии состоит из трех моделей:
Кодировщик текста, который принимает текстовое приглашение.
Преобразование текстовых подсказок в машиночитаемые векторы.
U-Net
Это диффузионная модель, отвечающая за генерацию изображений.
Вариационный автоэнкодер, состоящий из модели кодера и декодера.
Кодировщик используется для уменьшения размеров изображения. Диффузионная модель UNet работает в этом меньшем измерении.
Затем декодер отвечает за улучшение / восстановление изображения, сгенерированного диффузионной моделью, до его первоначального размера.
Можно легко получить доступ к стабильным диффузионным моделям, используя их платформу DreamStudio. Создание учетной записи первоначально предоставит вам 200 кредитов, которые вы можете использовать для игры с подсказками и создания изображений по выбору.
Кроме того, если у вас есть вычислительные ресурсы, вы также можете настроить стабильную диффузию для запуска в вашей системе, следуя документации в их репозитории.
Midjourney
Midjourney - это еще одна диффузионная модель генерации изображений, разработанная одноименной компанией. Midjourney стал доступен для широких масс в марте 2020 года. Он быстро завоевал большое количество поклонников благодаря своему выразительному стилю и тому факту, что он стал общедоступным до DALLE и Stable Diffusion.
На данный момент это полностью закрытый исходный код, и у него нет соответствующей статьи. Тем не менее, можно получить доступ к возможностям Midjourney по созданию изображений с помощью их официального бота Discord. Недавно компания объявила о начале этапа альфа-тестирования v4 model.

Популярные варианты стабильной диффузионной модели
Открытый исходный код Stable Diffusion позволяет разработчикам по всему миру тренироваться в определенном стиле и создавать вариации Stable Diffusion. Мы можем найти множество примеров в Интернете, включая стабильные диффузионные модели, которые генерируют персонажей Диснея, персонажей аниме и даже стили других диффузионных моделей.
Почти все модели и примеры, которым мы будем следовать здесь, доступны через HuggingFace hub. Итак, если вы хотите их опробовать, не стесняйтесь запускать код самостоятельно.
Вот несколько примеров:
Anything V3
Anything V3 - это вариация стабильной диффузии, которая генерирует изображения в стиле персонажей аниме.

Robo Diffusion
Модель, которая генерирует роботов на основе объекта и символов, которые мы вводим в нашем приглашении.

Open Journey
Созданная сообществом репликация MidJourney с открытым исходным кодом, которая генерирует изображения в стиле, аналогичном тому, что генерирует Midjourney. Open Journey - это разновидность стабильной диффузии, которая была обучена на изображениях, сгенерированных Midjourney.

Arcane Diffusion
Arcan Diffusion - это стабильная диффузионная модель, которая была настроена на стили изображений из телешоу Arcane.

Mo-Di Fusion
Эта версия стабильной диффузии создавала персонажей в стиле Pixar.

Применение диффузионных моделей
В вышеприведенных разделах мы рассмотрели несколько хорошо известных диффузионных моделей, и среди них свободно доступны только стабильная диффузия и ее варианты. В результате того, что кодовая база является открытым исходным кодом, сообщество разработчиков и исследователей придумало разумные способы использования стабильной диффузии. В этом разделе мы рассмотрим некоторые известные приложения и способы использования диффузионных моделей.
Самый простой способ использовать стабильные диффузионные модели генерации изображений из текста в изображение - это Стабильная диффузия 2-1 – объемное пространство лица от stabilityai. Просто добавьте текстовое описание и нажмите “Создать изображение”.
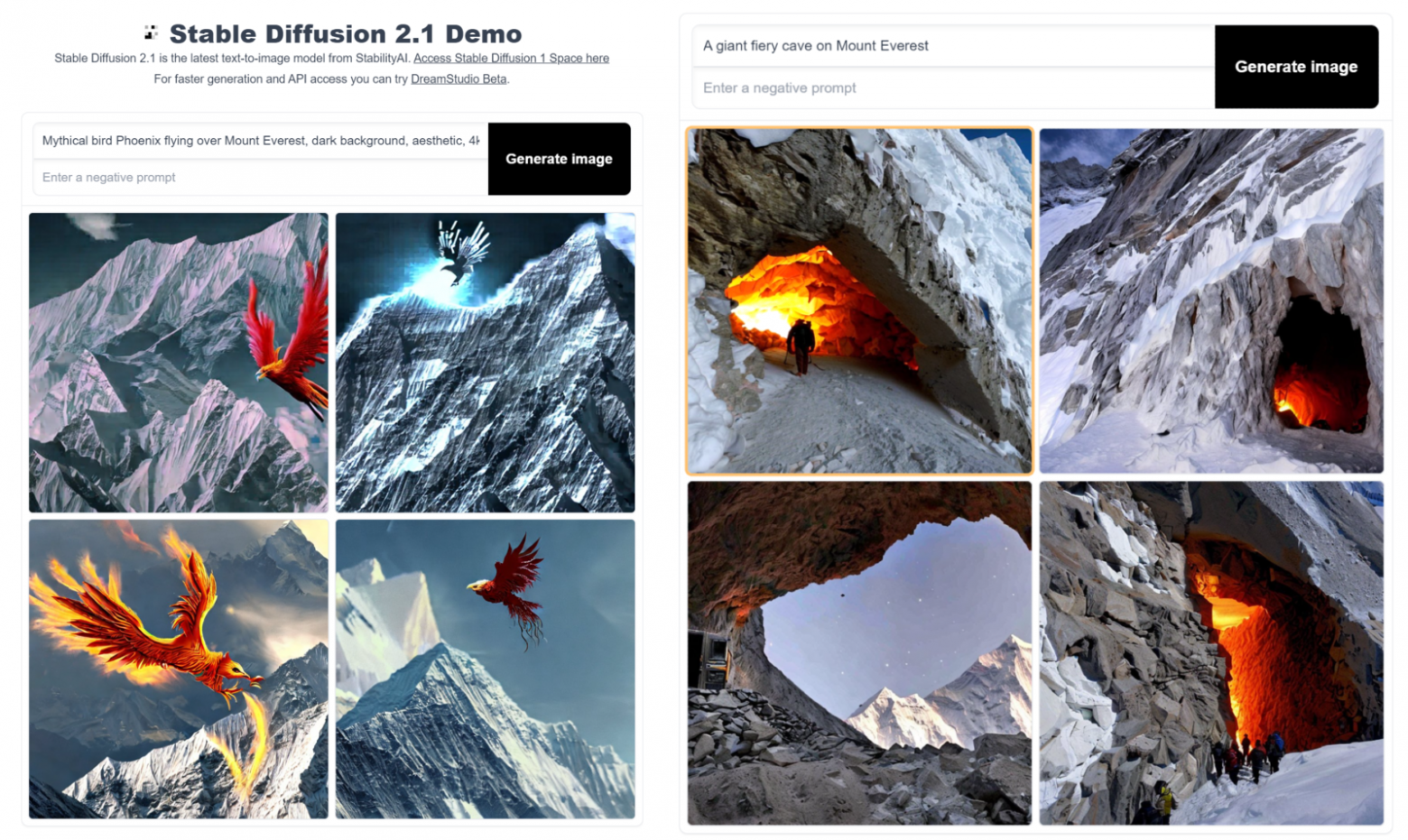
Недостатки использования свободно размещенного сервиса заключаются в том, что у него может быть большая очередь, поэтому вам, возможно, придется ждать создания вашего изображения, и нет доступных опций настройки или элементов управления.
Чтобы решить эту проблему, мы можем загружать и запускать стабильные диффузионные модели локально. Можно использовать два подхода:
Установите готовое к использованию приложение, созданное сообществом, которое мы можем установить локально или использовать в Google Colab.
Непосредственно работайте с открытым исходным кодом и используйте его по своему усмотрению. Для этого мы предоставляем нашим читателям записную книжку jupyter.
Единственным недостатком этого подхода является то, что нам нужен локальный графический процессор. На процессорах процесс будет намного медленнее. Мы перечислили области и инструменты, которые мы использовали для публикации, в разделе “Инструменты” внизу.
Итак, давайте начнем.
Текстовая инверсия
Используя текстовую инверсию, мы можем точно настроить диффузионную модель для создания изображений с использованием личных объектов или художественных стилей, используя всего 10 изображений. Это не приложение само по себе, а хитрый трюк для обучения диффузионных моделей, которые можно использовать для создания более персонализированных изображений.
От авторов статьи о текстовой инверсии:
“Мы учимся генерировать конкретные концепции, такие как личные объекты или художественные стили, описывая их с помощью новых “слов” в пространстве встраивания предварительно подготовленных моделей преобразования текста в изображение. Их можно использовать в новых предложениях, как и любое другое слово. ”
– Изображение стоит одного слова, 2022

С помощью textual inversion мы сгенерировали несколько изображений с использованием приложения Lensa для iOS.

Если вы не ищете ничего слишком личного и хотите создавать изображения, используя некоторые известные стили, вы можете попробовать Stable Diffusion Conceptualizer space. Здесь вы найдете коллекцию диффузионных моделей, обученных различным художественным стилям. Вы можете выбрать любую модель по своему вкусу и начать генерировать без каких-либо проблем.
Например, мы создали изображение ниже, используя “стиль midjourney” Гэндальфа Серого на черной горе.

Text To Videos
Как следует из названия, мы можем использовать диффузионные модели для непосредственного создания видео с помощью текстовых подсказок. Распространяя концепцию, используемую в преобразовании текста в изображение, на видео, можно использовать диффузионные модели для создания видео из рассказов, песен, стихотворений и т. Д.
“a beautiful forest by Asher Brown Durand, trending on Artstation“
Source: Example from deforum stable diffusion – Animating prompts with stable diffusion
“a cat | a dog | a horse”
Source: Example from “Stable Diffusion Videos” on Replicate – Generate videos by interpolating the latent space of Stable Diffusion
Существуют другие (возможно, лучшие) модели диффузии текста в видео, такие как Google Imagen Video, Phenaki, Meta's Make-A-Video. Но, к сожалению, код в настоящее время не доступен для общественности.
Text To 3D
Это приложение было продемонстрировано в статье “Dreamfusion”, где авторы с помощью “NeRFs” могли использовать обученную 2D-модель диффузии текста в изображение для выполнения синтеза текста в 3D.
“Полученную 3D-модель заданного текста можно рассматривать под любым углом, повторно освещать произвольным освещением или комбинировать в любой 3D-среде. Наш подход не требует данных 3D-обучения и никаких модификаций модели диффузии изображений, демонстрируя эффективность предварительно подготовленных моделей диффузии изображений в качестве априорных ”.
– DreamFusion: преобразование текста в 3D с использованием 2D-диффузии, 2022

Text To Motion
Это еще одно новое и захватывающее приложение, в котором диффузионные модели (наряду с другими методами) используются для создания простых движений человека. В частности, мы имеем в виду “Диффузионная модель движения человека”.
“Естественное и выразительное воспроизведение движений человека - это святой грааль компьютерной анимации. Это сложная задача из-за разнообразия возможных движений, чувствительности человеческого восприятия к ним и сложности их точного описания .... Мы показываем, что наша модель обучается с использованием небольших ресурсов и при этом достигает самых современных результатов в ведущих тестах для преобразования текста в движение и преобразования действия в движение.
– MDM: модель диффузии движения человека, 2022
“Человек идет вперед, наклоняется, чтобы поднять что-то с земли.“
Источник: https://guytevet.github.io/mdm-page/
Image To Image
Преобразование изображения в изображение (сокращенно Img2Img) - это метод, который мы можем использовать для изменения существующих изображений. Это метод преобразования существующего изображения в целевой домен с помощью текстовой подсказки. Проще говоря, мы можем создать новое изображение с тем же содержимым, что и существующее изображение, но с некоторыми преобразованиями. Мы можем предоставить текстовое описание преобразования, которое мы хотим.
Например, в приведенной ниже таблице левое изображение представляет собой “фестиваль воздушных шаров”, сначала созданный с помощью “text2img”, а затем переданный в img2img для преобразования его в графическое изображение в стиле Disney Pixar.

Пользователь предоставляет входное изображение в качестве ориентира / отправной точки и может изменять его, предоставляя инструкции модели с помощью подсказки. Диффузионная модель сгенерирует новое изображение с тем же цветом и композицией, что и входное изображение, с новыми изменениями.
Используя img2img, вы также можете преобразуйте свои портреты в изображения в стиле Pixar.


Еще один интересный пример использования Img2Img a для преобразования грубых нарисованных от руки или незаконченных изображений в красивые картинки с тем же содержанием. Как показано в примере ниже.
В качестве эксперимента: Я преобразовал свой “плохой рисунок природы” в “картину маслом”, и результаты выдающиеся.
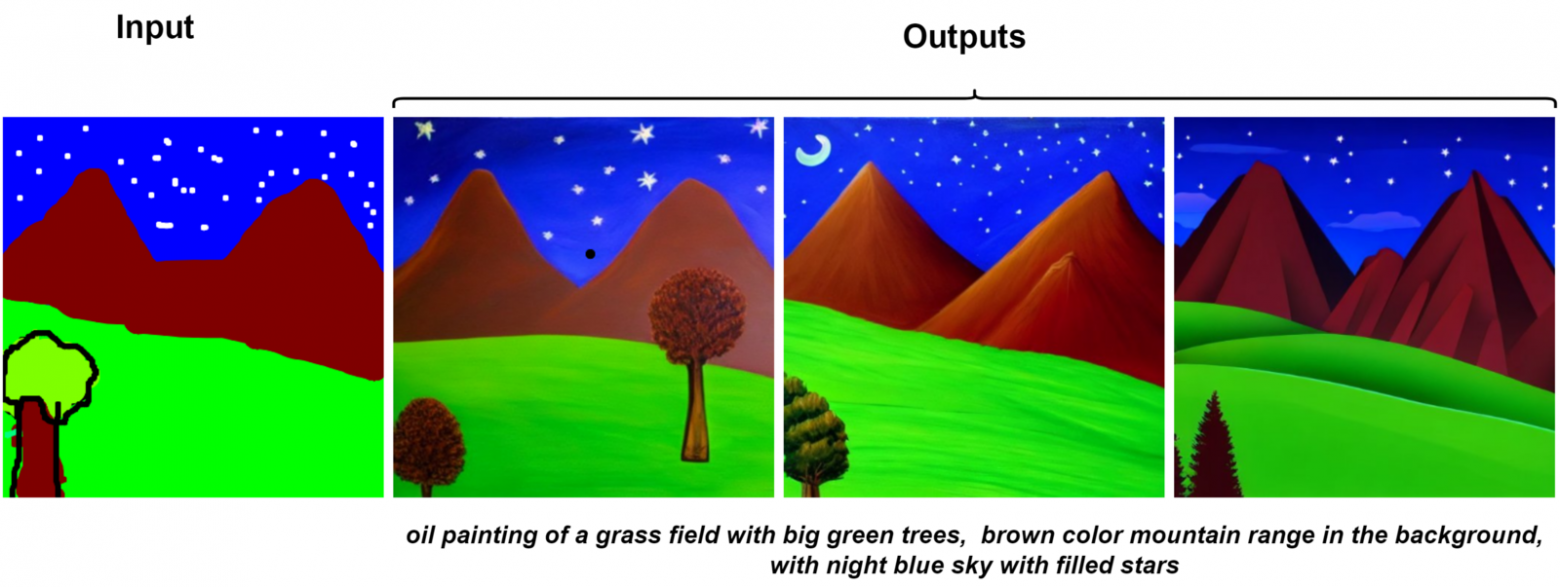
Примером использования Img2Img является передача стиля. При передаче стиля мы берем два изображения: одно для контента и одно для ссылки на стиль. Создается новое изображение, представляющее собой смесь обоих: содержание первого в чужом стиле.
Передача стиля - захватывающая и интересная тема для изучения. В одном из наших недавних постов мы использовали передачу стиля и создали приложение для передача стиля в реальном времени при вызовах масштабирования.

Image Inpainting
Закрашивание изображения - это метод восстановления изображения, позволяющий удалить ненужные объекты на изображении или полностью заменить их каким-либо другим объектом / текстурой / дизайном. Для выполнения рисования изображения пользователь сначала рисует маску вокруг объекта или пикселей, которые необходимо изменить. После создания маски пользователь может указать модели, как она должна изменять замаскированные пиксели.
Некоторые примеры:




Image Outpainting
Раскрашивание или бесконечное рисование - это процесс, при котором диффузионная модель добавляет детали за пределы / за пределы исходного изображения. Мы можем расширить наше исходное изображение, либо используя части исходного изображения (или вновь созданные пиксели) в качестве эталонных пикселей, либо добавляя новые текстуры и концепции с помощью текстовой подсказки.

Infinite Zoom In & Zoom Out
A. Бесконечное увеличение

Это можно считать разумным способом использования рисования изображений для создания фрактальных шаблонов проектирования.
Процесс, используемый для создания “Infine zoom in”, заключается в следующем:
Создайте изображение, используя стабильную диффузионную модель.
Уменьшите изображение и скопируйте и вставьте его в центр.
Замаскируйте границу за пределами уменьшенной копии.
Используйте стабильную диффузионную раскраску для заполнения замаскированной части.
Другой пример Бесконечное увеличение от пользователя Twitter @hardmaru, исследователя Stability.ai .
Бесконечный зум с высоким разрешением в научно-фантастическом Ренессансе эпохи Эдо
Когда рисование зависит от измененных размеров предыдущих изображений, на которых появилась перспектива, оно, как правило, создает внутренние помещения или коридоры, которые соответствуют перспективному виду, не запрашивая их.#StableDiffusion2 #AIArt pic.twitter.com/uWP4He1cia
— hardmaru (@hardmaru) 9 января 2023 г.
B. Бесконечное уменьшение масштаба
Методы, используемые для создания “Infine Zoom Out”, довольно просты для понимания. Это можно рассматривать как расширение “outpainting”. В отличие от вывода изображения, размер изображения остается постоянным на протяжении всего процесса.

Размер изображения, созданного с помощью начальной подсказки, постепенно уменьшается. Это создает пустое пространство между границей изображения и измененным размером изображения. Дополнительное пространство заполняется с использованием диффузионной модели, обусловленной тем же запросом, с новым изображением (содержащим пустое пространство и исходное изображение) в качестве начальной точки. Мы можем сгенерировать видео, продолжив этот процесс в течение нескольких итераций, как показано в примерах выше.
Image Search & Reverse Image Search
Эти две утилиты созданы для поиска изображений, которые были созданы с использованием стабильной диффузии или выполнения обратного поиска изображений.
Lexica – Это стабильная поисковая система диффузии. В нем содержится более ~ 5 миллионов сгенерированных изображений, и запрос генерирует изображение.
Ternaus – Ternaus отличается тем, что объединяет поиск изображений (изображение в изображение) и обратный поиск изображений (изображение в текст) в одном запросе. Основное внимание уделяется поиску сгенерированных изображений, свободных от лицензионных ограничений.
Инструменты
В этом разделе мы перечисляем известные и новые инструменты и онлайн-сервисы, созданные сообществом, которые наши пользователи могут изучить и использовать для своих задач.
Для локальной и Colab установки
Самые популярные – AUTOMATIC1111: Стабильный диффузионный веб-интерфейс
Запуск в Google Colab быстрые и стабильные-диффузионные ноутбуки Colab, AUTOMATIC1111
InvokeAI: InvokeAI является ведущим творческим движком для стабильной диффузионной модели.
cmdr2: простая установка стабильного распространения в 1 клик
Для онлайн-тестирования
Craiyon – Craiyon - это модель искусственного интеллекта, которая может рисовать изображения из любой текстовой подсказки!
Нанесение на взлетно–посадочную полосу - объемное пространство для лица
Стабильная диффузионная окраска – объемное пространство для лица
Stablediffusion Infinity – перерисовка со стабильной диффузией на бесконечном холсте.
Краткие сведения
Диффузионные модели остаются здесь навсегда!
Диффузионные модели могут значительно расширить мир творческой работы и создания контента в целом. За последние несколько месяцев они уже доказали свою эффективность. Количество диффузионных моделей растет с каждым днем, а старые версии быстро устаревают. На самом деле, существует очень высокая вероятность того, что к тому времени, когда вы прочтете эту статью, некоторые из упомянутых выше моделей будут иметь свои более новые версии.
В любом случае, создателям и компаниям пора начать использовать диффузионные модели для создания изображений и контента. Даже если они не являются конечным продуктом, диффузионные модели могут служить средством вдохновения для мира творческих работников.
В этой статье📜 мы рассмотрели полный список связанных тем. Резюмировать:
Мы начали с изучения места диффузионных моделей в генеративных моделях, основанных на глубоком обучении.
Мы предоставили высокоуровневый обзор диффузионных и диффузионных моделей и того, как они работают.
Мы обсудили некоторые из наиболее эффективных и популярных диффузионных моделей и их варианты, созданные сообществом.
Наконец, мы закончили, обсудив различные интересные и забавные приложения диффузионных моделей, а также различные инструменты и сервисы, которые можно использовать для работы с диффузионными моделями.
P.S. В этом репозитории содержатся ноутбуки для стабильной работы Diffusion

