
В 2017 году мы написали пост о том, как храним миллиарды сообщений [перевод на Хабре]. В нём мы рассказали о том, как начали с использования MongoDB, но потом выполнили миграцию данных в Cassandra, потому что искали надёжную, устойчивую к сбоям базу данных, имеющую относительно низкую стоимость обслуживания. Мы знали, что будем расти, так и произошло!
Нам нужна была база данных, способная расти вместе с нами, но чтобы стоимость обслуживания не росла вместе с объёмом хранимых данных. К сожалению, оказалось, что это не так — кластер Cassandra демонстрировал серьёзные проблемы с производительностью, поэтому нам требовалось всё больше усилий, чтобы просто поддерживать его, не говоря уже о совершенствовании.
Спустя почти шесть лет мы многое изменили; изменился и способ хранения сообщений.
Наши проблемы с Cassandra
Мы хранили сообщения в базе данных под названием cassandra-messages. Как понятно из имени, в ней работала Cassandra и хранились сообщения. В 2017 году у нас работало 12 узлов Cassandra, хранящих миллиарды сообщений.
В начале 2022 года база данных имела 177 узлов с триллионами сообщений. К нашей досаде, она требовала огромных усилий — наша дежурная команда инженеров часто фиксировала проблемы с базой данных, задержки оказывались непредсказуемыми и нам пришлось сократить операции по обслуживанию, которые были слишком экономически затратными.
Что вызывало эти проблемы? Во-первых, давайте взглянем на сообщение.
CREATE TABLE messages ( channel_id bigint, bucket int, message_id bigint, author_id bigint, content text, PRIMARY KEY ((channel_id, bucket), message_id) ) WITH CLUSTERING ORDER BY (message_id DESC);
Показанная выше конструкция CQL — это минимальная версия схемы сообщений. Каждый используемый нами ID — это Snowflake, что позволяет сортировать их хронологически. Мы разделяем сообщения по каналу их передачи вместе с bucket (статическим окном времени). Такое разделение означает, что в Cassandra все сообщения для заданного канала и bucket будут храниться вместе и реплицироваться в трёх узлах (или в количестве, заданном коэффициентом репликации).
В этом разделении и таится потенциальная проблема производительности: сервер, на котором сидит небольшая группа друзей, обычно отправляет объём сообщений на порядки меньший, чем у сервера с сотнями тысяч людей.
В Cassandra операции считывания более затратны, чем операции записи. Операции записи добавляются в лог коммитов и записываются в структуру памяти под названием memtable, которая время от времени сбрасывается на диск. С другой стороны, для операций чтения требуется выполнение запроса к memtable и потенциально к нескольким SSTable (файлам на диске), то есть эта операция более затратна. Множество одновременных операций чтения в процессе взаимодействия пользователей с серверами могут сделать раздел «горячим». Из-за большого размера нашего датасета и этих паттернов доступа у кластера возникали проблемы.
Когда возникал «горячий» раздел, это часто влияло на задержки во всём кластере базы данных. Одна пара канала и bucket получала большой объём трафика, задержка в узле могла увеличиваться, поскольку узлу всё сложнее было обрабатывать трафик и он всё больше начинал отставать.
Если узел не справлялся, это влияло и на другие запросы к этому узлу. Так как мы выполняем чтение и записи с уровнем согласованности кворума, все запросы к узлу, обслуживающие «горячий» раздел, страдали от повышения задержек, что влияло на всё большее количество пользователей.
Часто вызывали проблемы и задачи по обслуживанию кластера. Мы были подвержены отставаниям при сжатии: Cassandra сжимала SSTable на диск для повышения эффективности чтения. Наши операции чтения не только были более затратными, мы наблюдали и каскадное повышение задержек, пока узел пытался выполнить сжатие.
Мы часто выполняли операцию, которую называли «танец с переменой партнёров»: один узел выводился из ротации, чтобы он смог выполнить сжатие без получения трафика, после чего возвращался в строй и получал подсказки от Cassandra и повторял процесс до исчерпания бэклога сжатия. Также мы тратили много времени на настройку сборщика мусора JVM и параметры кучи, потому что паузы GC вызывали существенные всплески задержек.
Изменение архитектуры
Кластер сообщений не был нашей единственной базой данных Cassandra. У нас было множество других кластеров, и каждый из них демонстрировал такие же сбои (только, возможно, не столь же серьёзные).
В предыдущей итерации этого поста мы говорили, что нас заинтриговала ScyllaDB, совместимая с Cassandra база данных, написанная на C++. Её разработчики обещают повышенную производительность, более быстрый ремонт, усиленную изоляцию рабочих нагрузок благодаря архитектуре «шард на ядро» и работу без сборки мусора.
И хотя ScyllaDB почти точно имеет свои проблемы, в ней нет сборщика мусора, потому что она написана на C++, а не на Java. Раньше наша команда сталкивалась со множеством проблем со сборщиком мусора Cassandra, от пауз GC, влияющих на задержку, и вплоть до сверхдолгих последовательных пауз GC, которые становились настолько ужасными, что оператору приходилось вручную перезагружать и самостоятельно возвращать узел к жизни. Эти проблемы стали источником большой нагрузки на дежурную команду и первопричиной многих проблем со стабильностью в кластере сообщений.
Поэкспериментировав со ScyllaDB и выявив при тестировании улучшения, мы приняли решение выполнить миграцию всех наших баз данных. Хотя такое решение само по себе может быть темой для целого поста, вкратце расскажу, что к 2020 году мы завершили миграцию всех баз данных, кроме одной, на ScyllaDB.
Что же это за последняя база? Наша старая подруга, cassandra-messages.
Почему мы всё-таки не провели её миграцию? Стоит начать с того, что это большой кластер. Учитывая наличие триллионов сообщений и примерно двухсот узлов, любая миграция стала бы сложной задачей. Кроме того, мы стремились гарантировать. что наша новая база станет лучшей, поэтому работали над тонкой настройкой её показателей. Также мы хотели обрести больше опыта работы с ScyllaDB в продакшене и освоить все её недостатки.
Также мы работали над повышением производительности ScyllaDB в наших сценариях использования. При тестировании выяснилось, что показатели обратных запросов недостаточны для наших потребностей. Мы выполняем обратный запрос, когда пытаемся выполнить сканирование базы данных в порядке, противоположном сортировке таблицы, например, когда мы сканируем сообщения по возрастанию. Самый высокий приоритет команда ScyllaDB отдала внесению улучшений и повышению производительности обратных запросов, устранив последнее препятствие нашего плана миграции.
Мы подозревали, что просто запихнув новую базу данных в свою систему, не сделаем волшебным образом всё лучше. «Горячие» разделы могли существовать и в ScyllaDB; кроме того, мы хотели вложиться в совершенствование систем в апстриме от базы данных, чтобы обеспечить улучшение производительности базы данных и облегчить его.
Сервисы данных
При работе с Cassandra мы испытывали проблемы с «горячими» разделами. Большой объём трафика к одному разделу приводил к неограниченной одновременной нагрузке, вызывавшей каскадное увеличение задержек, при которых продолжали расти задержки последующих запросов. Если бы смогли контролировать объём одновременного трафика к «горячим» разделам, то защитили бы базу данных от перегруза.
Чтобы выполнить эту задачу, мы написали так называемые сервисы данных — промежуточные сервисы, находящиеся между нашим монолитом API и кластерами баз данных. При написании сервисов данных мы выбрали язык, которым всё больше и больше пользуемся в Discord: Rust! Раньше мы использовали его для нескольких проектов, и он оправдал связанный с ним ажиотаж. Он обеспечивал высокие скорости, свойственные C/C++, без ущерба для безопасности.
Одно из главных восхваляемых преимуществ Rust заключается в беспроблемной concurrency — язык должен позволить разработчикам писать безопасный код с параллельным исполнением. Кроме того, его библиотеки отлично подходили для того, чего мы хотели добиться. Экосистема Tokio — это великолепный фундамент для создания системы с асинхронным вводом-выводом, а сам язык имеет поддержку драйверов для Cassandra и ScyllaDB.
Также мы получали настоящее удовольствие от кодинга на нём: компилятор предоставляет помощь, сообщения об ошибках чётки и понятны, конструкции языка удобны, а сам язык делает упор на безопасность. Нам очень понравилось, что после компиляции кода он чаще всего работал, как нужно. Однако самое важное заключалось в том, что мы могли теперь хвастаться, что переписали кодовую базу на Rust (бахвалиться ведь очень важно).
Наши сервисы данных находятся между API и кластерами ScyllaDB. Они содержат приблизительно по одной конечной точке gRPC на один запрос базы данных и специально не содержат никакой бизнес-логики. Важная особенность сервисов данных заключается в объединении запросов. Если несколько пользователей одновременно запрашивают одну строку, мы выполняем только один запрос к базе данных. Первый пользователь, делающий запрос, заставляет задачу воркера запустить сервис. Последующие запросы проверяют наличие этой задачи и подписываются на неё. Эта задача воркера будет выполнять запросы к базе данных и возвращать строку всем подписчикам.
В этом и заключается мощь Rust: он упростил написание безопасного кода для параллельного выполнения.
Представьте важное объявление на крупном сервере, уведомляющее всех (everyone) пользователей на нём: пользователи запустят приложение и прочитают сообщение, отправляя огромный объём трафика базе данных. Раньше это могло привести к возникновению «горячего» раздела и потенциальному вызову дежурной команды для помощи в восстановлении системы. Благодаря наличию сервисов данных мы смогли существенно снизить всплески трафика к базе данных.
Вторая часть волшебства — это апстрим наших сервисов данных. Мы реализовали согласованную маршрутизацию на основе хэшей к нашим сервисам данных для обеспечения более эффективного объединения запросов. На каждый запрос к сервису данных мы предоставляем ключ маршрутизации. Для сообщений это ID канала, поэтому все запросы к одному каналу передаются на один и тот же инстанс сервиса. Такая маршрутизация ещё больше снижает нагрузку на базу данных.

Эти улучшения существенно помогли, но не решили всех наших проблем. Мы всё равно сталкивались с «горячими» разделами и повышением задержек в кластере Cassandra, только не так часто. Это позволило нам выиграть время на подготовку нового оптимального кластера ScyllaDB и выполнение миграции.
Очень большая миграция
Наши требования к миграции были достаточно просты: нам необходимо было без даунтайма выполнить перенос триллионов сообщений, и сделать это быстро, потому что хотя ситуация с Cassandra немного улучшилась, на самом деле нам часто приходилось «тушить пожары».
Первый этап прост: мы создаём новый кластер ScyllaDB при помощи нашей супердисковой топологии хранения. Благодаря использованию локальных SSD для обеспечения скорости и применению RAID для зеркалирования данных в постоянное хранилище, мы обеспечили скорость локальных дисков вместе с надёжностью постоянного хранилища. Подготовив кластер, мы могли начать миграцию данных на него.
Первый черновик плана миграции подразумевал быстрое получение выигрыша. Мы бы начали применять новенький блестящий кластер ScyllaDB для новых данных во время переключения, а затем выполнить миграцию исторических данных. Это повышает сложность, но ведь каждому крупному проекту нужна дополнительная сложность, не так ли?
Мы начали выполнять двойную запись новых данных в Cassandra и ScyllaDB и одновременно реализовывать мигратор Spark ScyllaDB. Это потребовало много тонкой настройки и после того, как нам удалось её завершить, мы получили примерную оценку времени до завершения: три месяца.
Такие временные рамки нас не обрадовали, и мы предпочли ускорить процесс. Мы собрали совещание с командой и путём мозгового штурма пытались придумать, как нам ускорить работу, пока не вспомнили, что написали быструю и производительную библиотеку базы данных, которую потенциально можно расширить. Мы решили воспользоваться силой мемов и переписать мигратор данных на Rust.
За один день мы расширили библиотеку сервисов данных так, чтобы она позволяла выполнять крупномасштабные миграции данных. Она считывает диапазоны токенов из базы данных, выполняет их локальные чекпоинты при помощи SQLite, а затем засовывает их в ScyllaDB. Мы подключили наш улучшенный мигратор и получили новую оценку времени: девять дней! Если мы окажемся способны выполнить миграцию данных так быстро, то сможем забыть наш сложный пошаговый план миграции и переключить рубильник одновременно для всего кластера.
Мы включили мигратор, и он начал работать, выполняя миграцию со скоростями до 3,2 миллиона сообщений в секунду. Несколько дней спустя мы собрались, чтобы смотреть, как индикатор прогресса достигнет 100%, но увидели, что он застрял на 99,9999%! Наш мигратор прекратил работу по таймауту при чтении последних нескольких токенов данных, потому что они содержали огромные диапазоны удалённых записей, которые так никогда и не были сжаты в Cassandra. Мы сжали этот диапазон токенов и считанные секунды спустя миграция была завершена!
Мы выполнили автоматическую валидацию данных, отправив небольшой процент операций чтения обеим базам данных и сравнив результаты. Всё выглядело отлично! Кластер хорошо справлялся с полномасштабным трафиком продакшена, в то время как Cassandra сильно страдала от всё более частых проблем с задержками. Мы собрались всей командой, символически переключили рубильник, сделав ScyllaDB основной базой данных, и съели праздничный торт!
Несколько месяцев спустя…
Мы выполнили перенос базы данных сообщений в мае 2022 года, так как же она проявляет себя с тех пор?
Это тихая, благопристойная база данных. Нам теперь не приходится «тушить пожары» все выходные и жонглировать узлами в кластере в попытках сохранить аптайм. Это гораздо более эффективная база данных: 177 узлов Cassandra свелись к 72 узлам ScyllaDB. Каждый узел ScyllaDB имеет 9 ТБ дискового пространства по сравнению со средними 4 ТБ узла Cassandra.
Хвостовые задержки тоже существенно снизились. Например, p99 получения исторических сообщений составлял на Cassandra примерно 40-125 мс, а ScyllaDB имеет приятную задержку p99 в 15 мс; p99 скорости вставки сообщений снизился с 5-70 мс на Cassandra, до стабильных 5 мс на ScyllaDB. Благодаря вышеупомянутым улучшениям производительности мы обрели уверенность в базе данных сообщений, и поэтому смогли выявить новые сценарии применения продукта.
В конце 2022 года люди во всём мире следили за Кубком мира. Мы быстро заметили, что забитые голы проявляются на наших графиках мониторинга. Это было очень круто: мы не только смогли наблюдать реакцию наших систем на события реального мира, это ещё и позволило команде без угрызений совести смотреть футбол во время совещаний. Мы не «смотрели футбол во время совещаний», а «проактивно мониторили производительность систем».
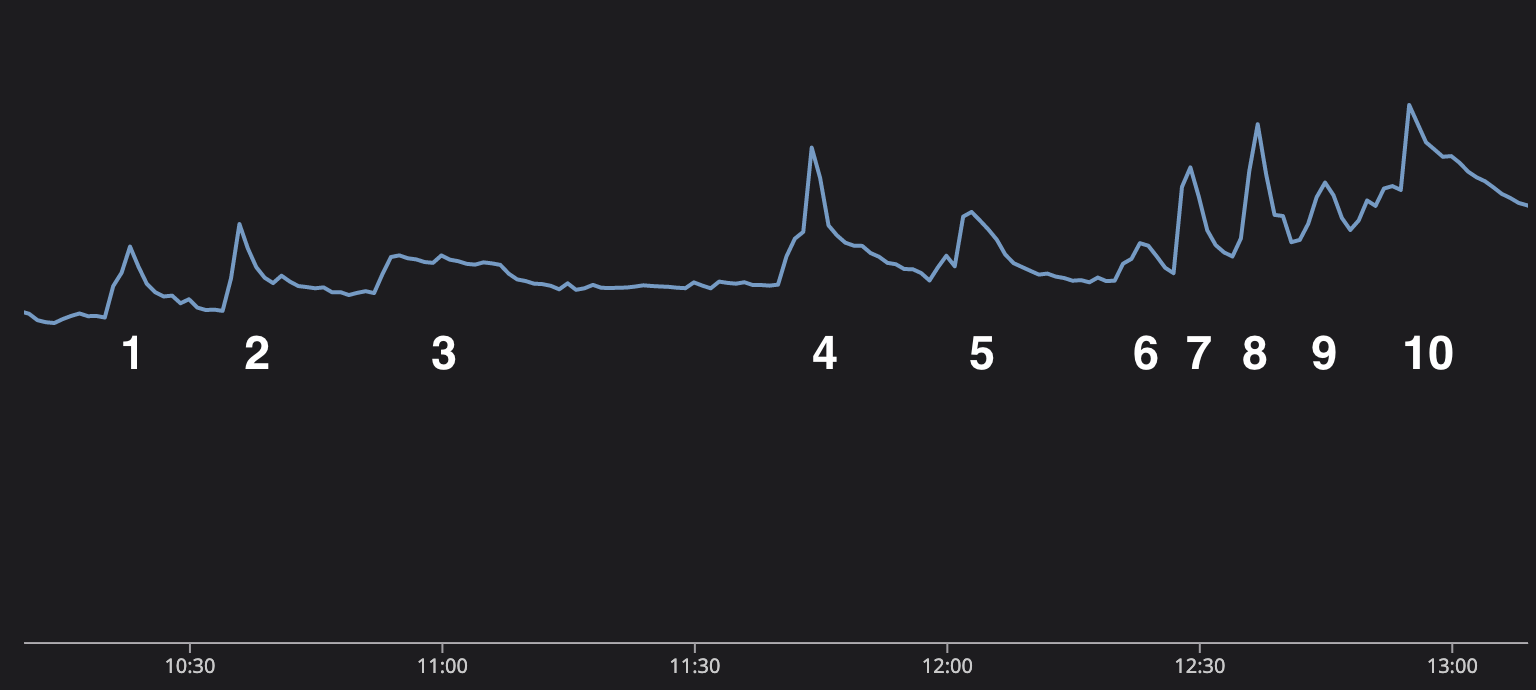
Мы даже можем рассказать историю финала Кубка мира по графику отправляемых сообщений. Матч был потрясающим. Лионель Месси пытался достичь пика своей карьеры и подтвердить заявление о том, что он величайший футболист всех времён, приведя Аргентину к чемпионскому титулу, однако на его пути встали талантливый Киллиан Мбаппе и Франция.
Каждый из десяти всплесков на этом графике соответствует важному событию матча.
- Месси пробивает пенальти, и Аргентина начинает вести 1-0.
- Аргентина снова забивает, счёт становится 2-0.
- Перерыв между таймами. Устойчивое пятнадцатиминутное плато, во время которого пользователи обсуждают матч.
- Огромный скачок, потому что Мбаппе забивает и спустя 90 секунд забивает снова. Ничья!
- Конец основного времени, дополнительное время.
- В первой части дополнительного времени не происходит ничего особо интересного, но мы добрались до перерыва и пользователи общаются.
- Месси снова забивает, и Аргентина захватывает лидерство!
- Мбаппе наносит ответный удар, приводя к ничьей!
- Конец дополнительного времени, подготовка к пенальти!
- Во время «перестрелки» восторг и стресс нарастают, Франция промахивается, а Аргентина пользуется этим! Аргентина побеждает!
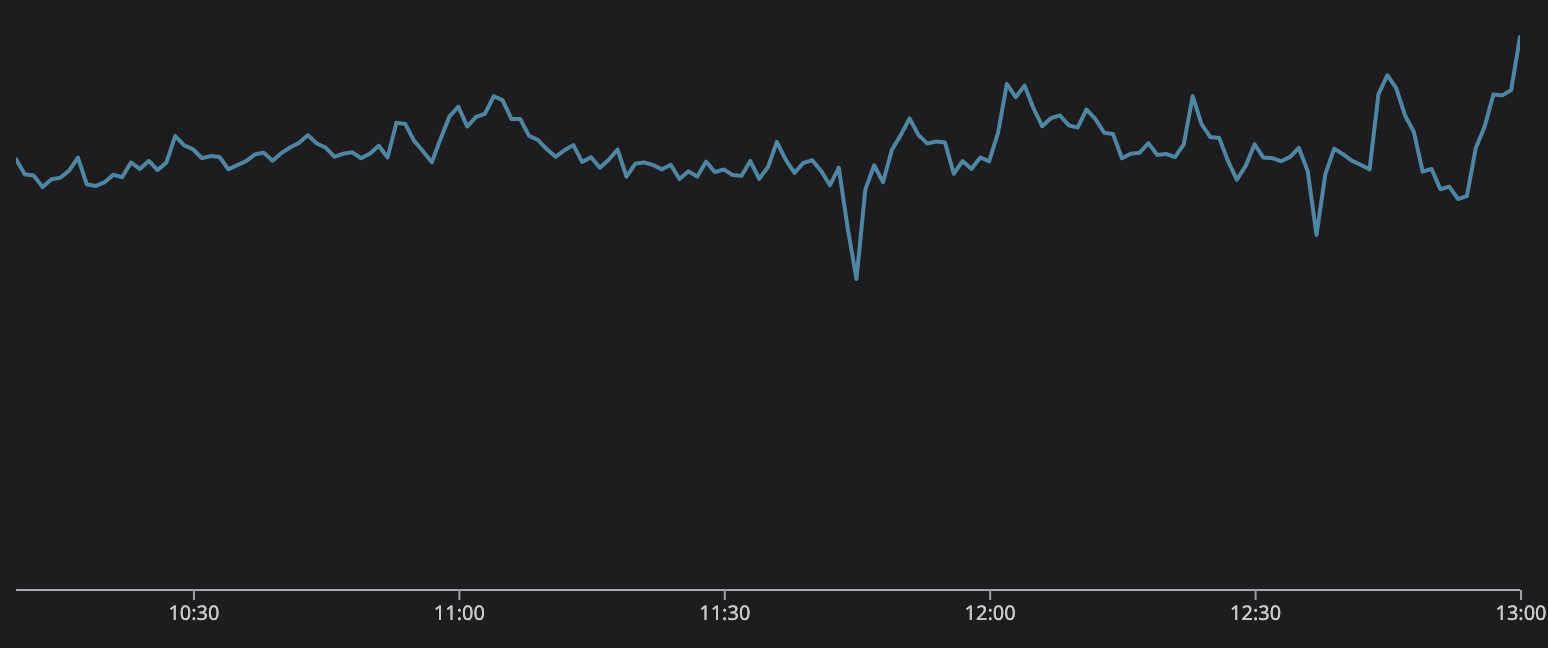
Количество объединённых сообщений в секунду
Люди по всему миру с напряжением наблюдали за потрясающим матчем, но тем временем Discord и база данных сообщений не испытывала ни малейших проблем. Мы замечательно справлялись с отправкой и обработкой сообщений. Благодаря написанным на Rust сервисам данных и ScyllaDB мы смогли осилить этот трафик и предоставить нашим пользователям платформу для общения.

