Добрый день! Меня зовут Михаил Емельянов, недавно я опубликовал на «Хабре» небольшую статью с примерным путеводителем начинающего Python-разработчика. Пользуясь этим материалом как своего рода оглавлением книги, я написал первые четыре главы мини-учебника «Ядро планеты Python», где постарался коротко, но достаточно ёмко раскрыть специфику, удобство, красоту и силу этого прекрасного языка.
Оригинал учебника лежит на GitHub, вы вольны сколько угодно дополнять и переделывать его. Самое главное — учебник написан на Jupiter Notebook, а это значит, что вы можете интерактивно редактировать код, мгновенно добавляя новые сущности или проясняя непонятные моменты.

Погружаясь в Python, не забывайте про прекрасную официальную документацию docs.python.org. Изучив её, хотя бы по диагонали, и постепенно углубляясь в нужные разделы, вы сможете убедиться, что многие «хаки», «открытия» и прочие неочевидные вещи уже давно разжеваны, описаны и имеют подробные примеры применения.
Также я бы рекомендовал для изучения базового синтаксиса Python на полную катушку использовать leetcode.com. Если отфильтровать задачи по уровню «Easy», а потом добавить дополнительную сортировку по столбцу «Acceptance», то перед вами предстанет не волчий оскал соревновательной платформы, а ванильный букварь с плавно нарастающим уровнем задачек.
1. Структуры данных
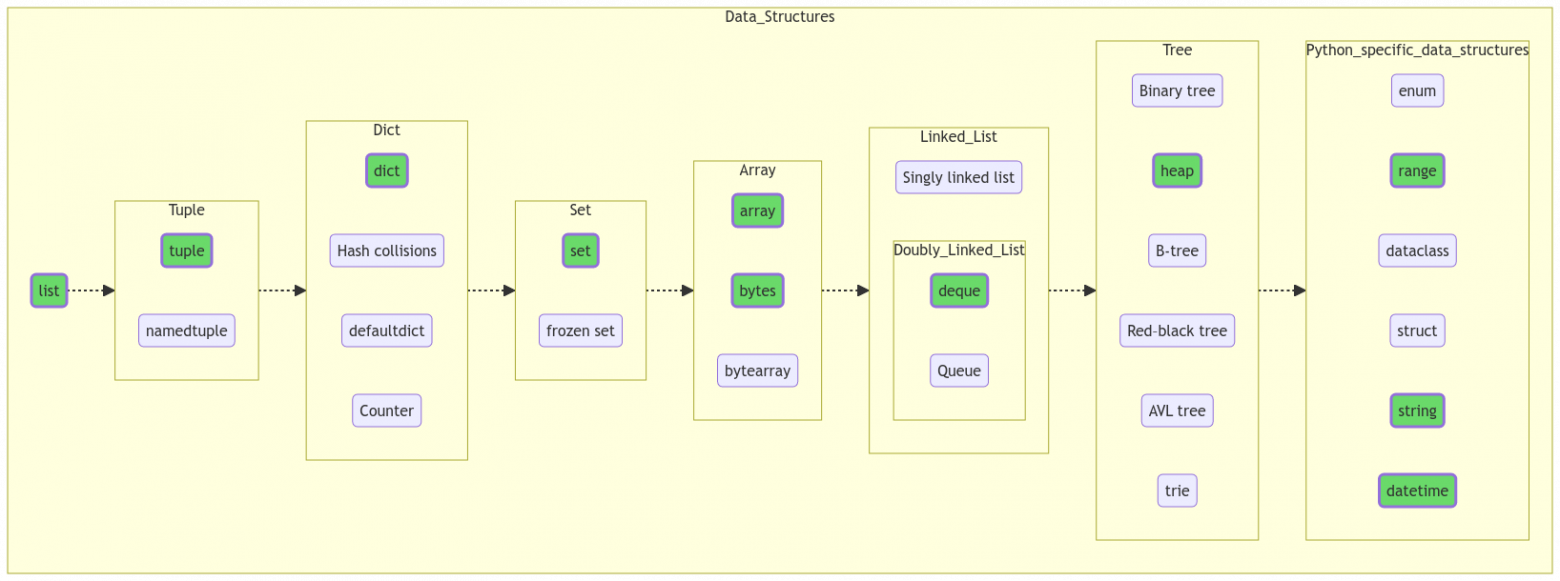
Как известно, программирование = структуры данных + алгоритмы (у Никлауса Вирта даже книжка такая есть). Начнем с данных, а потом плавненько перейдем к методам их обработки.
Список (list)
Список — самая универсальная и популярная структура данных в Python. Если вы пока точно не определились, какая структура понадобится в вашем проекте, просто возьмите список, с него достаточно просто мигрировать на что-нибудь более специализированное.
Список представляет собой упорядоченную изменяемую коллекцию объектов произвольных типов. Внутреннее строение списка — массив (точнее, vector) указателей, т. е. список является динамическим массивом.
a = [] # Создаем пустой список a: list[int] = [10, 20] b: list[int] = [30, 40] a.append(50) # Добавляем значение в конец списка b.insert(2, 60) # Вставляем значение по определенному индексу print(a, b) a += b print(f"Add: {a}") a.reverse() b = list(reversed(a)) # reversed() возвращает итератор, а не список print(f"Reverse: {a}, {b}") b = sorted(a) # Возвращает новый отсортированный список a.sort() # Модифицирует исходный список и не возвращает ничего print(f"Sort: {a}, {b}") s: str = "A whole string" list_of_chars: list = list(s) print(list_of_chars) list_of_words: list = s.split() print(list_of_words) i: int = list_of_chars.index("w") # Возвращает индекс первого вхождения искомого элемента или вызывает исключение ValueError print(i) list_of_chars.remove("w") # Удаляет первое вхождение искомого элемента или вызывает исключение ValueError e = list_of_chars.pop(9) # Удаляет и возвращает значение, расположенное по индексу. pop() (без аргумента) удалит и вернет последний элемент списка print(list_of_chars, e) a.clear() # Очистка списка
[10, 20, 50] [30, 40, 60] Add: [10, 20, 50, 30, 40, 60] Reverse: [60, 40, 30, 50, 20, 10], [10, 20, 50, 30, 40, 60] Sort: [10, 20, 30, 40, 50, 60], [10, 20, 30, 40, 50, 60] ['A', ' ', 'w', 'h', 'o', 'l', 'e', ' ', 's', 't', 'r', 'i', 'n', 'g'] ['A', 'whole', 'string'] 2 ['A', ' ', 'h', 'o', 'l', 'e', ' ', 's', 't', 'i', 'n', 'g'] r
Кортеж (tuple)
Кортеж — тоже список, только неизменяемый (immutable) и хэшируемый (hashable). Кортеж, содержащий те же данные, что и список, занимает меньше места:
a = [2, 3, "Boson", "Higgs", 1.56e-22] b = (2, 3, "Boson", "Higgs", 1.56e-22) print(f"List: {a.__sizeof__()} bytes") print(f"Tuple: {b.__sizeof__()} bytes")
List: 104 bytes Tuple: 64 bytes
Именованный кортеж (named tuple)
В соответствии с названием, имеет именованные поля. Удобно!
from collections import namedtuple rectangle = namedtuple('rectangle', 'length width') r = rectangle(length = 1, width = 2) print(r) print(r.length) print(r.width) print(r._fields)
rectangle(length=1, width=2) 1 2 ('length', 'width')
Словарь (dict)
Словарь — вторая по частоте использования структура данных в Python. dict — реализация хеш-таблицы, поэтому в качестве ключа нельзя брать нехешируемый объект, например, список (тут-то нам и может пригодиться кортеж). Ключом словаря может быть любой неизменяемый объект: число, строка, datetime и даже функция. Такие объекты имеют метод __hash__(), который однозначно сопоставляет объект с некоторым числом. По этому числу словарь ищет значение для ключа.
Списки, словари и множества (которые мы рассмотрим чуть ниже) изменяемы и не имеют метода хеширования, при попытке подставить их в словарь возникнет ошибка.
d = {} # Создаем пустой словарь d: dict[str, str] = {"Italy": "Pizza", "US": "Hot-Dog", "China": "Dim Sum"} # Непосредственное создание словаря k = ["Italy", "US", "China"] v = ["Pizza", "Hot-Dog", "Dim Sum"] d = dict(zip(k, v)) # Создание словаря из двух коллекций при помощи zip k = d.keys() # Коллекция ключей. Отражает изменения в основном словаре v = d.values() # Коллекция значений. Тоже отражает изменения в основном словаре k_v = d.items() # Кортежи ключ-значение, которые тоже отражают изменения в основном словаре print(d) print(k) print(v) print(k_v) print(f"Mapping: {k.mapping['Italy']}") d.update({"China": "Dumplings"}) # Добавление значение. При совпадении ключа старое значение будет перезаписано print(f"Replace item: {d}") c = d["China"] # Читаем значение print(f"Read item: {c}") try: v = d.pop("Spain") # Удаляет значение или вызывает исключение KeyError except KeyError: print("Dictionary key doesn't exist") # Примеры dict comprehension (более подробно comprehension будет рассмотрено ниже) b = {k: v for k, v in d.items() if "a" in k} # Вернет новый словарь, отфильтрованный по значению ключа print(b) c = {k: v for k, v in d.items() if len(v) >= 7} # Вернет новый словарь, отфильтрованный по длине значений print(c) d.clear() # Очистка словаря
{'Italy': 'Pizza', 'US': 'Hot-Dog', 'China': 'Dim Sum'} dict_keys(['Italy', 'US', 'China']) dict_values(['Pizza', 'Hot-Dog', 'Dim Sum']) dict_items([('Italy', 'Pizza'), ('US', 'Hot-Dog'), ('China', 'Dim Sum')]) Mapping: Pizza Replace item: {'Italy': 'Pizza', 'US': 'Hot-Dog', 'China': 'Dumplings'} Read item: Dumplings Dictionary key doesn't exist {'Italy': 'Pizza', 'China': 'Dumplings'} {'US': 'Hot-Dog', 'China': 'Dumplings'}
Решение проблемы вычисления хеша при работе со словарем
Любая хеш-таблица, в том числе и питоновский словарь, должна уметь решать проблему вычисления хеша. Для этого используются техники open addressing или chaining. Python использует open addressing.
Новый словарь инициализируется с 8 пустыми слотами.
Интерпретатор сначала пытается добавить новую запись по адресу, зависящему от хеша ключа.
addr = hash(key) & mask,
где
mask = PyDictMINSIZE - 1
Если этот адрес занят, то интерпретатор проверяет (при помощи ==) хеш и ключ. Если оба совпадают, то, значит, запись уже существует. Тогда начинается зондирование свободных слотов, которое идет в псевдослучайном порядке (порядок зависит от значения ключа). Новая запись будет добавлена по первому свободному адресу.
Чтение из словаря происходит аналогично, интерпретатор начинает поиск с позиции addr и идет по тому же псевдослучайному пути, пока не прочитает нужную запись.
Defaultdict
Если попытаться прочитать из обычного словаря значение ключа, которого там нет, то будет выброшено исключение KeyError (исключения будут рассмотрены ниже). Defaultdict позволяет не писать обработчик исключений, а просто воспринимает чтение несуществующего ключа как команду записать в этот ключ и вернуть значение по умолчанию; например, defaultdict(int) вернет 0.
from collections import defaultdict dd = defaultdict(int) print(dd[10]) # Печать int, будет выведен ноль, значение по умолчанию dd = {} # "Обычный" пустой словарь # print(dd[10]) # вызовет исключение KeyError
0
Счетчик (counter)
Счетчик подсчитывает передаваемые ему объекты. Иногда очень удобно просто бухнуть в счетчик какой-нибудь список и сразу получить структуру данных с подсчитанными элементами.
from collections import Counter shirts_colors = ["red", "white", "blue", "white", "white", "black", "black"] c = Counter(shirts_colors) print(c) c["blue"] += 1 print(f"After shopping: {c}")
Counter({'white': 3, 'black': 2, 'red': 1, 'blue': 1}) After shopping: Counter({'white': 3, 'blue': 2, 'black': 2, 'red': 1})
Объяснение работы Counter() при помощи defaultdict():
from collections import defaultdict shirts_colors = ["red", "white", "blue", "white", "white", "black", "black"] d = defaultdict(int) for shirt in shirts_colors: d[shirt] += 1 print(d)
defaultdict(<class 'int'>, {'red': 1, 'white': 3, 'blue': 1, 'black': 2})
Множество (set)
Третья по распространенности питоновская структура данных. Когда-то, когда Python был молод, множества представляли собой несколько редуцированные словари, но со временем их судьбы (и реализации) стали расходиться. Однако, множество всё-таки является хеш-таблицей с соответствующим быстродействием на разных типах операций.
big_cities: set["str"] = {"New-York", "Los Angeles", "Ottawa"} american_cities: set["str"] = {"Chicago", "New-York", "Los Angeles"} big_cities |= {"Sydney"} # Добавить значение (или add()) american_cities |= {"Salt Lake City", "Seattle"} # Сложить множества (или update()) print(big_cities, american_cities) union_cities: set["str"] = big_cities | american_cities # Или union() intersected_cities: set["str"] = big_cities & american_cities # Или intersection() dif_cities: set["str"] = big_cities - american_cities # Или difference() symdif_cities: set["str"] = big_cities ^ american_cities # Или symmetric_difference() issub: bool = big_cities <= union_cities # Или issubset() issuper: bool = american_cities >= dif_cities # Или issuperset() print(union_cities) print(intersected_cities) print(dif_cities) print(symdif_cities) print(issub, issuper) big_cities.add("London") big_cities.remove("Ottawa") # Удаляет значение, если оно имеется или выбрасывает KeyError big_cities.discard("Los Angeles") # Удаляет значение без выбрасывания KeyError big_cities.pop() # Возвращает и удаляет случайное значение (порядок в set неопределен) или выбрасывает KeyError big_cities.clear() # Очищает множество
{'New-York', 'Los Angeles', 'Sydney', 'Ottawa'} {'New-York', 'Seattle', 'Chicago', 'Los Angeles', 'Salt Lake City'} {'Ottawa', 'Salt Lake City', 'Chicago', 'New-York', 'Seattle', 'Sydney', 'Los Angeles'} {'New-York', 'Los Angeles'} {'Ottawa', 'Sydney'} {'Seattle', 'Ottawa', 'Chicago', 'Salt Lake City', 'Sydney'} True False
Иммутабельное множество (frozen set)
Frozen set — то же множество, только иммутабельное и хешируемое. Напоминает разницу между списком и кортежем, не правда ли?
a = frozenset({"New-York", "Los Angeles", "Ottawa"})
Массив (array, bytes, bytearray)
Я перешел на Python с языков, более приближенных к «железу» (C, C#, даже на ассемблере когда-то писал за деньги :) и сначала немного удивлялся, что обычный массив, в котором всё так удобно лежит на своих местах, используется относительно редко. Массив в Python не является структурой данных, выбираемой по умолчанию и используется только в случаях, когда решающую роль начинают играть размер структуры и скорость её обработки. Но, с другой стороны, если вы смотрите в сторону NumPy и Pandas (немного затронуты ниже), то массивы — ваше всё.
Массив хранит переменные определенного типа, поэтому, в отличие от списка, не требует создания нового объекта для каждой новой переменной и выигрывает у списка в размерах и скорости доступа. Можно сказать, что это тонкая обёртка над Си-массивами.
Следует различать array («просто» массив), bytes (иммутабельный массив, содержащий только байты, наследие str из Python 2) и bytearray (мутабельный байтовый массив).
from array import array a1 = array("l", [1, 2, 3, -4]) a2 = array("b", b"1234567890") b = bytes(a2) print(a1) print(a2[0]) print(b) print(a1.index(-4)) # Возвращает индекс элементы или выбрасывает ValueError
array('l', [1, 2, 3, -4]) 49 b'1234567890' 3
# Создание b1 = bytes([1, 2, 3, 4]) # Целые числа должны быть в диапазоне от 0 to 255 b2 = "The String".encode('utf-8') b3 = (-1024).to_bytes(4, byteorder='big', signed=True) # byteorder = "big"/"little"/"sys.byteorder", signed = False/True b4 = bytes.fromhex('FEADCA') # Для большей читаемости hex-значения могут быть разделены пробелами b5 = bytes(range(10,30,2)) print(b1, b2, b3, b4, b5) # Преобразование c: list = list(b"\xfc\x00\x00\x00\x00\x01") s: str = b'The String'.decode("utf-8") b: int = int.from_bytes(b"\xfc\x00", byteorder='big', signed=False) # byteorder = "big"/"little"/"sys.byteorder", signed = False/True s2: str = b"\xfc\x00\x00\x00\x00\x01".hex(" ") print(c, s, b, s2) with open("1.bin", "wb") as file: # Байтовая запись в файл file.write(b1) with open("1.bin", "rb") as file: # Чтение из файла b6 = file.read() print(b6)
b'\x01\x02\x03\x04' b'The String' b'\xff\xff\xfc\x00' b'\xfe\xad\xca' b'\n\x0c\x0e\x10\x12\x14\x16\x18\x1a\x1c' [252, 0, 0, 0, 0, 1] The String 64512 fc 00 00 00 00 01 b'\x01\x02\x03\x04'
Односвязный список
Односвязный список представляет набор связанных узлов, каждый из которых хранит собственные данные и ссылку на следующий узел. В практике применим редко, но его любят использовать интервьюеры на собеседованиях, чтобы кандидат мог блеснуть своими алгоритмическими знаниями. В Python встроенной реализации не имеет, можно или использовать deque (в основе которого лежит двусвязный список), или написать свою реализацию.
Двусвязный список (Deque)
Ссылки в каждом узле двусвязного списка указывают на предыдущий и на последующий узел в списке. Можно или использовать deque, или написать свою реализацию.
from collections import deque d = deque([1, 2, 3, 4], maxlen=1000) d.append(5) # Add element to the right side of the deque d.appendleft(0) # Add element to the left side of the deque by appending elements from iterable d.extend([6, 7]) # Extend the right side of the deque d.extendleft([-1, -2]) # Extend the left side of the deque print(d) a = d.pop() # Remove and return an element from the right side of the deque. Can raise an IndexError b = d.popleft() # Remove and return an element from the left side of the deque. Can raise an IndexError print(a, b) print(d)
deque([-2, -1, 0, 1, 2, 3, 4, 5, 6, 7], maxlen=1000) 7 -2 deque([-1, 0, 1, 2, 3, 4, 5, 6], maxlen=1000)
Queue
Queue реализует FIFO со множественными поставщиками данных и множественными потребителями. Может быть особенно полезен при многопоточности, позволяя корректно обмениваться информацией между потоками. Также существуют LifoQueue для реализации LIFO и PriorityQueue для реализации очереди с приоритетом.
from queue import Queue q = Queue(maxsize=1000) q.put("eat", block=True, timeout=10) q.put("sleep") # По умолчанию block=True, timeout=None q.put("code") q.put_nowait("repeat") # Эквивалент put("repeat", block=False). Если свободный слот не будет предоставлен немедленно, будет вызвано исключение queue.Full print(q.queue) a = q.get(block=True, timeout=10) # Удалить и возвратить элемент из FIFO b = q.get() # По умолчанию block=True, timeout=None c = q.get_nowait() # Эквивалент get(False) print(a, b, c, q.queue)
deque(['eat', 'sleep', 'code', 'repeat']) eat sleep code deque(['repeat'])
Бинарное дерево (binary tree)
Иерархическая структура данных, в которой каждый узел имеет не более двух потомков. Встроенной реализации не имеет, нужно писать свою. Как правило, используются деревья с дополнительными свойствами, рассмотренные ниже.
Куча (heap)
Бинарное дерево, удовлетворяющее свойство кучи: если B является узлом-потомком узла A, то ключ(A) ≥ ключ(B). Куча является максимально эффективной реализацией абстрактного типа данных, который называется очередью с приоритетом и поддерживающего две обязательные операции — добавить элемент и извлечь минимум (или максимум, в зависимости от реализации).
В Python min-куча (наименьшее значение всегда лежит в корне) реализована на базе списка при помощи встроенного модуля heapq. Если вам нужна max-куча, с максимальным значением в корне, можете воспользоваться советами со Stackoverflow.
import heapq h = [211, 1, 43, 79, 12, 5, -10, 0] heapq.heapify(h) # Превращаем список в кучу print(h) heapq.heappush(h, 2) # Добавляем элемент print(h) m = heapq.heappop(h) # Извлекаем минимальный элемент print(h, m)
[-10, 0, 5, 1, 12, 211, 43, 79] [-10, 0, 5, 1, 12, 211, 43, 79, 2] [0, 1, 5, 2, 12, 211, 43, 79] -10
Пробежимся коротенько по остальным структурам данных, которые в Python не имеют встроенной реализации, но, тем не менее, могут весьма пригодиться в реальном проекте.
Би-дерево (B-tree)
Сбалансированное дерево, оптимизированное для доступа к относительно медленным элементам памяти (например, дисковым структурам или индексам баз данных); как ветви, так и листья представляют собой списки (для того, чтобы можно было считать такой список в один проход для дальнейшего быстрого разбора в ОЗУ). Нужно писать свою реализацию. Либо — воспользоваться встроенной в Python поддержкой базы данных sqlite3, эта БД как раз реализована на би-дереве.
Красно-черное дерево
Самобалансирующееся двоичное дерево поиска, позволяющее быстро выполнять основные операции: добавление, удаление и поиск узла. Сбалансированность достигается за счёт введения дополнительного признака узла дерева — «цвета». Этот атрибут может принимать одно из двух возможных значений — «чёрный» или «красный». Листовые узлы КЧ деревьев не содержат данных, поэтому не требуют выделения памяти — достаточно просто записать в узле-предке нулевой указатель на потомка. Нужно писать свою реализацию.
Возможно, вы читали о том, что при собеседовании в FAANG претендентов «заставляют крутить красно-черное дерево на доске». Это «кружение» и есть балансировка, после операции вставки или удаления элемента дерево нужно отбалансировать, с примерным объемом кода вы можете ознакомиться здесь или здесь.
АВЛ-дерево
В АВЛ-деревьях операции вставки и удаления работают медленнее, чем в красно-черных деревьях (при том же количестве листьев красно-чёрное дерево может быть выше АВЛ-дерева, но не более чем в 1,388 раза). Поиск же в АВЛ-дереве выполняется быстрее (максимальная разница в скорости поиска составляет 39 %). Нужно писать свою реализацию.
Префиксное дерево
Префиксное дерево (или trie) — структура данных, позволяющая хранить ассоциативный массив, ключами которого являются строки. Нужно писать свою реализацию.
Таблица выбора структуры данных
В квадратных скобках показан худший случай.
| Структура | Реализация | Применение | Индексация | Поиск | Вставка | Удаление | Память |
|---|---|---|---|---|---|---|---|
| Динамический массив | list | 1 | n | n | n | n | |
| Хэш таблица | dict, set | 1 [n] |
1 [n] |
1 [n] |
n | ||
| Массив | array, bytes, bytearray | Для хранения однотипных данных | 1 | n | n | n | n |
| Односвязный список | — (~deque) | n | n | 1 | 1 | n | |
| Двусвязный список | deque | FIFO, LIFO | n | n | 1 | 1 | n |
| Бинарное дерево | - | logn [n] |
logn [n] |
logn [n] |
logn [n] |
n | |
| Куча | heapq | Очередь с приоритетом | 1 (find min) |
logn | logn (del min) |
n | |
| B-tree (Би-дерево) | ~sqlite | Для памяти с медленным доступом | logn | logn | logn | logn | n |
| КЧ дерево | - | logn | logn | logn | logn | n | |
| АВЛ дерево | - | logn | logn | logn | logn | n | |
| Префиксное дерево | - | T9, алгоритм Ахо–Корасик, алгоритм LZW |
key | key | key |
Перечисление (Enum, IntEnum)
Удобные конструкции для определения заранее известных перечислений.
from enum import Enum, auto import random class Currency(Enum): euro = 1 us_dollar = 2 yuan = auto() local_currency = Currency.us_dollar print(local_currency) local_currency = Currency["us_dollar"] # Может вызвать исключение KeyError print(local_currency) local_currency = Currency(2) # Может вызвать исключение ValueError print(local_currency) print(local_currency.name) print(local_currency.value) list_of_members = list(Currency) member_names = [e.name for e in Currency] member_values = [e.value for e in Currency] random_member = random.choice(list(Currency)) print(list_of_members, "\n", member_names, "\n", member_values, "\n", random_member)
Currency.us_dollar Currency.us_dollar Currency.us_dollar us_dollar 2 [<Currency.euro: 1>, <Currency.us_dollar: 2>, <Currency.yuan: 3>] ['euro', 'us_dollar', 'yuan'] [1, 2, 3] Currency.euro
Целочисленный диапазон (range)
range() возвращает иммутабельную последовательность чисел, которая часто используется как задатчик диапазона для цикла for.
r1: range = range(11) # Возвращает последовательность чисел от 0 до 10 r2: range = range(5, 21) # Возвращает последовательность чисел от 5 до 20 r3: range = range(20, 9, -2) # Возвращает последовательность чисел от 20 до 10 с шагом 2 print("To exclusive: ", end="") for i in r1: print(f"{i} ", end="") print("\nFrom inclusive to exclusive: ", end="") for i in r2: print(f"{i} ", end="") print("\nFrom inclusive to exclusive with step: ", end="") for i in r3: print(f"{i} ", end="") print(f"\nFrom = {r3.start}") print(f"To = {r3.stop}")
To exclusive: 0 1 2 3 4 5 6 7 8 9 10 From inclusive to exclusive: 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 From inclusive to exclusive with step: 20 18 16 14 12 10 From = 20 To = 9
Классы данных (dataclass)
Декоратор, автоматически создающий методы init(), repr() и eq(). Нужен для создания классов, главной задачей которых является хранение данных. Аннотации типов обязательны. Существует более продвинутая альтернатива под названием attrs.
from dataclasses import dataclass from decimal import * from datetime import datetime @dataclass class Transaction: value: Decimal issuer: str = "Default Bank" dt: datetime = datetime.now() t1 = Transaction(value=1000_000, issuer="Deutsche Bank", dt = datetime(2022, 1, 1, 12)) t2 = Transaction(1000) print(t1) print(t2)
Transaction(value=1000000, issuer='Deutsche Bank', dt=datetime.datetime(2022, 1, 1, 12, 0)) Transaction(value=1000, issuer='Default Bank', dt=datetime.datetime(2022, 9, 6, 17, 50, 36, 162897))
Dataclass может быть сделан иммутабельным с директивой frozen=True.
from dataclasses import dataclass @dataclass(frozen=True) class User: name: str account: int
Бинарная запаковка (struct)
Запаковка (и распаковка, разумеется) данных в байтовые последовательности с предопределенными размерами каждого элемента данных, их порядка в структуре, а также порядка байт для многобайтовых типов данных. Позволяет превращать Python-овский int в, например, short int или long int (подробности про систему типов языка Си).
При работе со структурами вам нужно будет знать, что такое little-endian и big-endian, а также не забывать, что размер типа данных в Си бывает разным.
from struct import pack, unpack, iter_unpack b = pack(">hhll", 1, 2, 3, 4) print(b) t = unpack(">hhll", b) print(t) i = pack("ii", 1, 2) * 5 print(i) print(list(iter_unpack('ii', i)))
b'\x00\x01\x00\x02\x00\x00\x00\x03\x00\x00\x00\x04' (1, 2, 3, 4) b'\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00' [(1, 2), (1, 2), (1, 2), (1, 2), (1, 2)]
Строка (string)
Строки в Python 3 — иммутабельные последовательности, использующие кодировку Unicode.
se: str = "" # Пустая строка si: str = str(12345) # Создает строку из числа sj: str = " ".join(["Follow", "the", "white", "rabbit"]) # Собирает строку из кусочков, используя указанный сепаратор print(f"Joined string: {sj}") is_contains: bool = "rabbit" in sj # Проверка наличия подстроки is_startswith = sj.startswith("Foll") is_endswith = sj.endswith("bbit") print(f"is_contains = {is_contains}, is_startswith = {is_startswith}, is_endswith = {is_endswith}") sr: str = sj.replace("rabbit", "sheep") # Замена подстроки. Можно указать количество замен: sr: str = sj.replace("rabbit", "sheep", times) print(f"After replace: {sr}") i1 = sr.find("rabbit") # Возвращает стартовый индекс первого вхождения или -1. Есть еще rfind(), начинающий искать с конца строки i2 = sr.index("sheep") # Возвращает стартовый индекс первого вхождения или выкидывает ValueError. Есть еще rindex(), начинающий искать с конца строки print(f"Start index of 'rabbit' is {i1}, start index of 'sheep' is {i2}") d = str.maketrans({"a" : "x", "b" : "y", "c" : "z"}) st = "abc".translate(d) print(f"Translate string: {st}") sr = sj[::-1] # Реверс через slice с отрицательным шагом print(f"Reverse string: {sr}")
Joined string: Follow the white rabbit is_contains = True, is_startswith = True, is_endswith = True After replace: Follow the white sheep Start index of 'rabbit' is -1, start index of 'sheep' is 17 Translate string: xyz Reverse string: tibbar etihw eht wolloF
Datetime
Для работы с датами и временем в datetime есть типы date, time, datetime и timedelta. Все они хешируемы и иммутабельны.
Конструкторы
from datetime import date, time, datetime, timedelta d: date = date(year=1964, month=9, day=2) t: time = time(hour=12, minute=30, second=0, microsecond=0, tzinfo=None, fold=0) dt: datetime = datetime(year=1964, month=9, day=2, hour=10, minute=30, second=0) td: timedelta = timedelta(weeks=1, days=1, hours=12, minutes=13, seconds=14) print (f"{d}\n {t}\n {dt}\n {td}")
1964-09-02 12:30:00 1964-09-02 10:30:00 8 days, 12:13:14
Now
Получение текущей даты или даты/времени.
from datetime import date, datetime import pytz import time d: date = date.today() dt1: datetime = datetime.today() dt2: datetime = datetime.utcnow() dt3: datetime = datetime.now(pytz.timezone('US/Pacific')) t1 = time.time() # Эпоха Unix t2 = time.ctime() print (f"{d}\n {dt1}\n {dt2}\n {dt3}\n {t1}\n {t2}")
2022-09-27 2022-09-27 09:47:02.430474 2022-09-27 04:47:02.430474 2022-09-26 21:47:02.430474-07:00 1664254022.4304743 Tue Sep 27 09:47:02 2022
Timezone
Часовые пояса.
from datetime import date, time, datetime, timedelta, tzinfo from dateutil.tz import UTC, tzlocal, gettz, datetime_exists, resolve_imaginary tz1: tzinfo = UTC # Часовой пояс UTC tz2: tzinfo = tzlocal() # Местный часовой пояс tz3: tzinfo = gettz() # Местный часовой пояс tz4: tzinfo = gettz("America/Chicago") # Или, например, "Asia/Kolkata". Полный список: en.wikipedia.org/wiki/List_of_tz_database_time_zones local_dt = datetime.today() utc_dt = local_dt.astimezone(UTC) # Конвертация местного часового пояса в часовой пояс UTC print (f"{tz1}\n {tz2}\n {tz3}\n {tz4}\n {local_dt}\n {utc_dt}")
tzutc() tzlocal() tzlocal() tzfile('US/Central') 2022-09-27 09:19:35.399362 2022-09-27 04:19:35.399362+00:00
2. Обработка данных
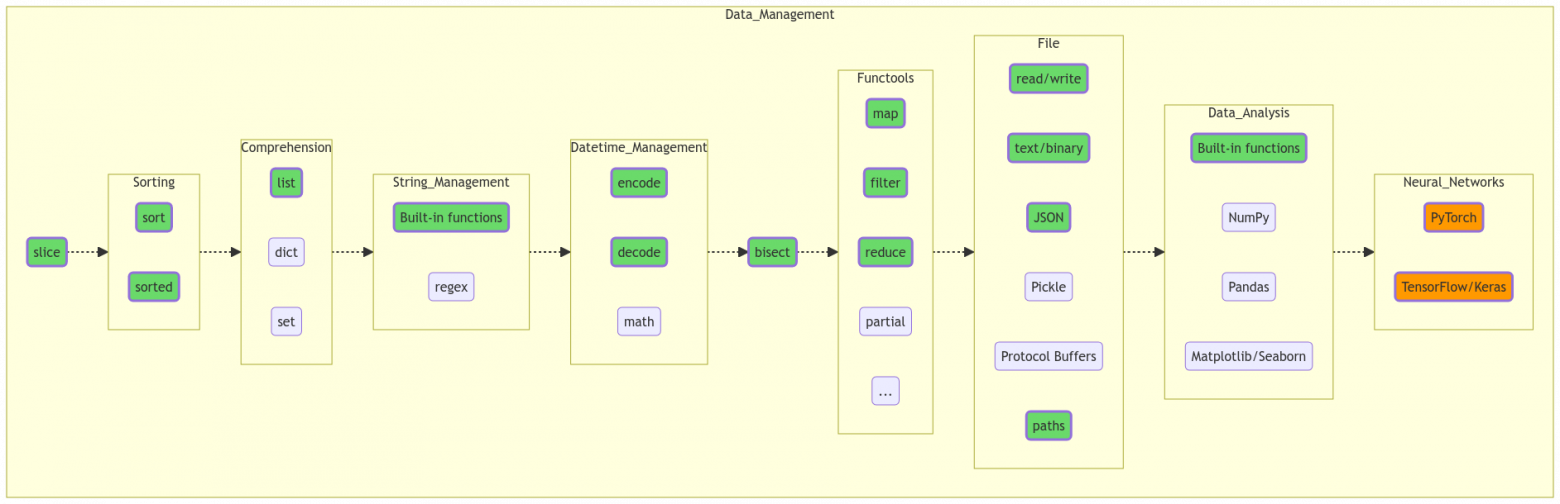
Срез (slice)
Самый простой метод обработки данных, просто возвращает ту часть данных, местоположение которой (индексы) удовлетворяет определенным условиям.
a:str = "Pack my box with five dozen liquor jugs" start, stop = 8, 21 b:str = a[start:stop] # Значения от start до stop-1 c:str = a[start:] # Значения от start до конца структуры d:str = a[:stop] # Значения от начала до stop-1 e:str = a[:] # Полная копия структуры print(b, "\n", c, "\n", d, "\n", e, "\n")
box with five box with five dozen liquor jugs Pack my box with five Pack my box with five dozen liquor jugs
Значения start и stop могут быть отрицательными, это будет означать, что отсчет ведется от конца структуры. Можно также использовать значение step, чтобы на выход среза попали не все подряд данные из входной структуры.
a:str = "Step on no pets" b:str = a[-4:] # «Хвостик» c:str = a[::-1] # Реверс входной строки d:str = a[4::-1] # Первые четыре значения, реверсированы e:str = a[::2] # Каждый второй символ print(b, "\n", c, "\n", d, "\n", e, "\n")
pets step on no petS petS Se nn es
Сортировка (sort, sorted)
В сортировке всё самое интересное спрятано под капотом (мы ненадолго вернемся к этой теме чуть ниже, в разделе «Алгоритмы»), пока рассмотрим только Python-специфичный синтаксис.
Надо различать методы sort() и sorted(), первый сортирует данные in-place, второй порождает новую структуру.
a: list = [5, 2, 3, 1, 4] b: list = sorted(a) print(a, b) a.sort() print(a)
[5, 2, 3, 1, 4] [1, 2, 3, 4, 5] [1, 2, 3, 4, 5]
И sort(), и sorted() имеют параметр key для указания функции, которая будет вызываться на каждом элементе. Если вам больше по нраву сортировка при помощи функции, принимающей два аргумента (или вы привыкли к cmp в Python 2), присмотритесь к functools.cmp_to_key().
# Регистрозависимое сравнение строк dinos: str = "Dinosaurs were Big and small" a = sorted(dinos.split()) print(a) # Регистронезависимое сравнение строк dinos: str = "Dinosaurs were Big and small" b = sorted(dinos.split(), key=str.lower) print(b)
['Big', 'Dinosaurs', 'and', 'small', 'were'] ['and', 'Big', 'Dinosaurs', 'small', 'were']
Сложносочиненные структуры данных можно сортировать по key=lambda el: el[1] или даже, например по key=lambda el: (el[1], el[0]).
Comprehension
Comprehension, которое переводится то как включение в список, то как абстракция списков (Википедия), то вообще никак не переводится — способ компактного описания операций обработки списков (а применительно к Python — еще и словарей, и множеств).
Проще говоря, если вам нужно получить из списка другой список, включающий только те значения, которые удовлетворяют какому-то определенному условию, или вычисляемые из первого списка по каким-то определенным правилам, то comprehension — претендент на решение этой задачи № 1.
# Примеры Comprehension a = [i+1 for i in range(10)] # list b = {i for i in range(10) if i > 5} # set c = (2*i+5 for i in range(10)) # iter d = {i: i**2 for i in range(10)} # dict print(a,"\n", b, "\n", list(c), "\n", d)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] {8, 9, 6, 7} [5, 7, 9, 11, 13, 15, 17, 19, 21, 23] {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
Тут главное не перегнуть палку. Если запись comprehension становится слишком сложной и нечитаемой, возможно, стоит развернуть логику в «нормальный» цикл или в другой более удобочитаемый алгоритм. Comprehension соблазняет записывать «однострочниками» достаточно сложные выражения, но не забывайте, что программист примерно 90 % времени читает код, и только 10 % пишет, так что если выражение будет плохочитаемым, вы усложните жизнь и себе, и свои коллегам.
Есть более-менее удачные «однострочники», есть быстрые, но плохочитаемые, написанные из спортивного интереса (это ссылки на решенные мной задачки на leetcode), желательно использовать comprehension в меру; лучше написать понятный развернутый алгоритм, чем непонятный, но обложенный пояснениями (если нет особых требований к производительности, само собой).
Еще немного про list comprehension:
# new_list = [expression for member in iterable (if conditional)] fruits: list = ["Lemon", "Apple", "Banana", "Kiwi", "Watermelon", "Pear"] e_fruits = [fruit for fruit in fruits if "e" in fruit] # ☝ условие print(e_fruits) upper_fruits = [fruit.upper() for fruit in fruits] # ☝ выражение print(upper_fruits) # Пример разбиения списка на фрагменты одинаковой длины chunk_len = 2 chunk_fruits = [fruits[i:i + chunk_len] for i in range(0, len(fruits), chunk_len)] print(chunk_fruits)
['Lemon', 'Apple', 'Watermelon', 'Pear'] ['LEMON', 'APPLE', 'BANANA', 'KIWI', 'WATERMELON', 'PEAR'] [['Lemon', 'Apple'], ['Banana', 'Kiwi'], ['Watermelon', 'Pear']]
Dict comprehension, включение в словарь:
# new_dict = {expression for member in iterable (if conditional)} d: dict = {"Italy": "Pizza", "US": "Hot-Dog", "China": "Dim Sum", "South Korea": "Kimchi"} print(d) a: dict = {k: v for k, v in d.items() if "i" in v} # Вернет новый словарь, отфильтрованный по значению print(a) b: dict = {k: v for k, v in d.items() if "i" in k} # Вернет новый словарь, отфильтрованный по ключу print(b) c: dict = {k: v for k, v in d.items() if len(v) >= 7} # Вернет новый словарь, отфильтрованный по длине значений print(c)
{'Italy': 'Pizza', 'US': 'Hot-Dog', 'China': 'Dim Sum', 'South Korea': 'Kimchi'} {'Italy': 'Pizza', 'China': 'Dim Sum', 'South Korea': 'Kimchi'} {'China': 'Dim Sum'} {'US': 'Hot-Dog', 'China': 'Dim Sum'}
Попробуйте самостоятельно поиграться с set comprehension. Не забывайте, что set «переваривает» только уникальные значения, поэтому в результате вы можете получить не совсем то, на что рассчитывали.
Попробуйте также освоить nested (вложенный) comprehension, используя конструкции вида [[func(y) for y in x] for x in n]. Для примера создайте двумерный массив, содержащий случайные значения, среднее значение которых плавно нарастает ближе к правому нижнему углу (если не получится, готовый пример есть чуть ниже, в коде, иллюстрирующем применение matplotlib).
Операции над строками. lower(), upper(), capitalize() и title()
s: str = "camelCase string" print(s.lower()) print(s.upper()) print(s.capitalize()) print(s.title())
camelcase string CAMELCASE STRING Camelcase string Camelcase String
strip()
s: str = " ~~##A big blahblahblah##~~ " s = s.strip() # Strips all whitespace characters from both ends print(s) s = s.strip("~#") # Strips all passed characters from both ends print(s) s = s.lstrip(" A") # Strips all passed characters from left end print(s) s = s.rstrip("habl") # Strips all passed characters from right end print(s)
~~##A big blahblahblah##~~ A big blahblahblah big blahblahblah big
split()
s1: str = "Follow the white rabbit, Neo" c1 = s1.split() # Splits on one or more whitespace characters print(c1) c2 = s1.split(sep=", ", maxsplit=1) # Splits on "sep" str at most "maxsplit" times print(c2) s2: str = "Beware the Jabberwock, my son!\n The jaws that bite, the claws that catch!" c3 = s2.splitlines(keepends=False) # On [\n\r\f\v\x1c-\x1e\x85\u2028\u2029] and \r\n. print(c3) # split() vs rsplit() c4 = s2.split(maxsplit=2) c5 = s2.rsplit(maxsplit=2) print(c4, c5)
['Follow', 'the', 'white', 'rabbit,', 'Neo'] ['Follow the white rabbit', 'Neo'] ['Beware the Jabberwock, my son!', ' The jaws that bite, the claws that catch!'] ['Beware', 'the', 'Jabberwock, my son!\n The jaws that bite, the claws that catch!'] ['Beware the Jabberwock, my son!\n The jaws that bite, the claws', 'that', 'catch!']
ord(), chr()
s1: str = "abcABC!" for ch in s1: print(f"{ch} -> {ord(ch)}") # Returns an integer representing the Unicode character nums = [72, 101, 108, 108, 111, 33] for num in nums: print(f"{num} -> {chr(num)}")
a -> 97 b -> 98 c -> 99 A -> 65 B -> 66 C -> 67 ! -> 33 72 -> H 101 -> e 108 -> l 108 -> l 111 -> o 33 -> !
Regex
Регулярные выражения — отдельная область знаний, и весьма-весьма непростая область. Тут, пожалуй, самое время для бородатой шутки про то, что если вы решили свою проблему при помощи регулярных выражений — теперь у вас две проблемы.
Регулярки похожи на вхождение в воду на пляже острова Гуам в сторону Марианской впадины — даже когда вы думаете, что погрузились реально глубоко, то, скорее всего, вы просто не видите впередилежащей бездны. Но — знать регулярные выражения, хотя бы на начальном уровне, необходимо для решения целого класса задач, а то, что вёрткие регулярки периодически поворачиваются к вам своими, кхм… новыми гранями, придется простить, переварить и принять.
Вот здесь есть грамотное и методически выдержанное введение в тему, пока же окинем взглядом основные возможности регулярных выражений:
import re s1: str = "123 abc ABC 456" m1 = re.search("[aA]", s1) # Ищет первое вхождение паттерна, при неудаче возвращает None print(m1, m1.group(0)) m2 = re.fullmatch("[aA]", s1) # Проверка, подходит ли строка под шаблон print(m2) c1: list = re.findall("[aA]", s1) # Найти в строке все непересекающиеся шаблоны print(c1) def replacer(s): return chr(ord(s[0]) + 1) # Следующий символ из алфавита s2 = re.sub("\w", replacer, s1) # Вы можете использовать функцию вместо шаблона print(s2) c2 = re.split("\d", s1) print(c2) iter = re.finditer("\D", s1) # Итератор по непересекающимся шаблонам for ch in iter: print(ch.group(0), end= "")
<re.Match object; span=(4, 5), match='a'> a None ['a', 'A'] 234 bcd BCD 567 ['', '', '', ' abc ABC ', '', '', ''] abc ABC
Match Object
import re m3 = re.match(r"(\w+) (\w+)", "John Connor, leader of the Resistance") s3: str = m3.group(0) # Возвращает полное совпадение s4: str = m3.group(1) # Возвращает часть в первых скобках t1: tuple = m3.groups() start: int = m3.start() # Возвращает начальный индекс совпадения end: int = m3.end() # Возвращает конечный индекс совпадения t2: tuple[int, int] = m3.span() # Кортеж (start, end) print (f"{s3}\n {s4}\n {t1}\n {start}\n {end}\n {t2}\n")
John Connor John ('John', 'Connor') 0 11 (0, 11)
Создание переменных datetime
Python использует Unix Epoch: "1970-01-01 00:00 UTC"
from datetime import datetime from dateutil.tz import tzlocal dt1: datetime = datetime.fromisoformat("2021-10-04 00:05:23.555+00:00") # Может вызвать ValueError dt2: datetime = datetime.strptime("21/10/04 17:30", "%d/%m/%y %H:%M") # Подробнее про форматы - https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes dt3: datetime = datetime.fromordinal(100_000) # 100000-й день от 1.1.0001 dt4: datetime = datetime.fromtimestamp(20_000_000.01) # Время в секундах с начала Unix Epoch tz = tzlocal() dt5: datetime = datetime.fromtimestamp(20_000_000.01, tz) # С учетом часового пояса print (f"{dt1}\n {dt2}\n {dt3}\n {dt4}\n {dt5}")
2021-10-04 00:05:23.555000+00:00 2004-10-21 17:30:00 0274-10-16 00:00:00 1970-08-20 16:33:20.010000 1970-08-20 16:33:20.010000+05:00
Преобразование переменных datetime
from datetime import datetime dt1: datetime = datetime.today() s1: str = dt1.isoformat() s2: str = dt1.strftime("%d/%m/%y %H:%M") # https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes i: int = dt1.toordinal() a: float = dt1.timestamp() # Секунды с начала Unix Epoch print (f"{dt1}\n {s1}\n {s2}\n {i}\n {a}")
2022-09-06 17:50:38.041159 2022-09-06T17:50:38.041159 06/09/22 17:50 738404 1662468638.041159
Арифметика datetime
from datetime import date, time, datetime, timedelta from dateutil.tz import UTC, tzlocal, gettz, datetime_exists, resolve_imaginary d: date = date.today() dt1: datetime = datetime.today() dt2: datetime = datetime(year=1981, month=12, day=2) td1: timedelta = timedelta(days=5) td2: timedelta = timedelta(days=1) d = d + td1 # date = date ± timedelta dt3 = dt1 - td1 # datetime = datetime ± timedelta td3 = dt1 - dt2 # timedelta = datetime - datetime td4 = 10 * td1 # timedelta = const * timedelta c: float = td1/td2 # timedelta/timedelta print (f"{d}\n {dt3}\n {td3}\n {td4}\n {c}")
2022-09-11 2022-09-01 17:50:38.132916 14888 days, 17:50:38.132916 50 days, 0:00:00 5.0
bisect и бинарный поиск
Бинарный поиск существенно быстрее, чем обычный (см. раздел «Алгоритмы»), но требует предварительной сортировки коллекции, по которой осуществляется поиск.
import bisect a: list[int] = [12, 6, 8, 19, 1, 33] a.sort() print(f"Sorted: {a}") print(bisect.bisect(a, 20)) # Найти индекс для потенциальной вставки bisect.insort(a, 15) # Вставка значения в отсортированную последовательность print(a) # Бинарный поиск def binary_search(a, x, lo=0, hi=None): if hi is None: hi = len(a) pos = bisect.bisect_left(a, x, lo, hi) return pos if pos != hi and a[pos] == x else -1 print(binary_search(a, 15))
Sorted: [1, 6, 8, 12, 19, 33] 5 [1, 6, 8, 12, 15, 19, 33] 4
Функциональное программирование (Map, Filter, Reduce, Partial)
На случай, если начиная с этого момента и до конца текущего жизненного цикла вы собираетесь к месту и не месту использовать приёмы функционального программирования, чтобы сделать свой код «воистину крутым», просто процитирую вам Джоэля Граса, автора книги «Data Science: Наука о данных с нуля»: «В первом издании этой книги были представлены функции partial, map, reduce и filter языка Python. На своем пути к просветлению я понял, что этих функций лучше избегать, и их использование в книге было заменено включениями в список, циклами и другими, более Python'овскими конструкциями». Такие дела…
import functools # Преобразует все входящие значения при помощи указанной функции iter1 = map(lambda x: x + 1, range(10)) print(list(iter1)) # Передает в выходной итератор только значения, удовлетворяющие условию iter2 = filter(lambda x: x > 5, range(10)) print(list(iter2)) # Применяет указанную функцию ко всей последовательности входных данных, сводя их к единственному значению a = functools.reduce(lambda out, x: out + x, range(10)) print(a)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] [6, 7, 8, 9] 45
import functools def sum(a,b): return a + b add_const = functools.partial(sum, 10) print(add_const(5))
15
Если вам не сразу станет понятно, как работает функция partial (и зачем она нужна), не расстраивайтесь, вы не одиноки :). Вот, пожалуйста, тема на Stackoverflow: «I am not able to get my head on how the partial works». Там, кстати, есть совет, как partial могут быть полезны при организации pipe с включением функций, имеющих разное количество аргументов.
Any, All
any() вернет True, если хотя бы один элемент итерируемой коллекции истинен, all() вернет True только в случае истинности всех элементов коллекции.
animals = ["Squirrel", "Beaver", "Fox"] sentence = "Bison likes squirrels and beavers" any_animal: bool = any(animal.lower() in sentence.lower() for animal in animals) print(any_animal) all_animal: bool = all(animal.lower() in sentence.lower() for animal in animals) print(all_animal)
True False
Файлы
Файловые операции стоят немного особняком от остальных методов обработки данных, как подразумевающие не сиюминутную торопливую обработку информации, а взаимодействие с неким постоянным энергонезависимым хранилищем данных. Так что если вам нужно сохранить данные на завтра, или, наоборот, нужно прочитать данные, которые вам предоставили неделю назад, то вам, очевидно, нужно будет работать с файлами. В файлах же осядет информация, которую мы передаем базам данных, но эту тему мы рассмотри ниже.
f = open("f.txt", mode='r', encoding="utf-8", newline=None) print(f.read())
Hello from file!
На всякий случай, если вы испытываете программистский зуд даже небольшой степени выраженности, напоминаю — обязательно прогоняйте в IDE все непонятные куски кода, не надо на них смотреть, их надо видоизменять, корректировать, дорабатывать; только когда концы свяжутся, только когда вы поймете, как функционирует этот кусочек кода, только тогда промелькнёт маленькая искорка и ваша квалификация как программиста немного подрастёт.
Режимы (mode):
"r" — чтение (поведение по умолчанию)
"w" — запись (информация, ранее присутствующая в файле, будет стёрта)
"x" — эксклюзивное создание и запись; если файл уже существует, будет выброшено исключение FileExistsError
"a" — открытие с последующим добавлением в конец файла
"w+" — чтение и запись
"r+" — чтение и запись с начала файла
"a+" — чтение и запись с конца файла
"t" — текстовый режим ("rt", "wt" и т. д.; поведение по умолчанию)
"b" — двоичный режим ("rb", "wb", "xb" и т. д.)
encoding=None — будет использована кодировка по умолчанию (зависит от системы, см. getpreferredencoding()). Если нет специальных требований, просто используйте везде encoding="utf-8"; без этого, например, русский текст запишется в текстовый файл в виде человеконечитаемой последовательности.
newline=None — при чтении системные символы конца строки будут конвертированы в "\n"; при записи, наоборот, "\n" будут конвертированы в системные символы конца строки.
Возможные исключения при работе с файлами:
FileNotFoundError при чтении в режиме "r" или "r+".
FileExistsError при записи в режиме "x".
IsADirectoryError, PermissionError — в любом режиме.
Чтение из файла
Открывает файл и возвращает файловый объект.
Для работы с файлами лучше использовать менеджеры контекста (рассмотрены ниже), т. е. конструкции вида "with open...". Даже если что-то пойдет не так, как задумано (например, вы не обработаете исключение во время работы с файлом), менеджер контекста «зачистит хвосты», и ваша оплошность не отразится, например, на файловой системе.
with open("f.txt", encoding="utf-8") as f: chars = f.read(5) # Reads chars/bytes or until EOF print(chars) f.seek(0) # Moves to the start of the file. Also seek(offset) and seek(±offset, anchor), where anchor is 0 for start, 1 for current position and 2 for end lines: list[str] = f.readlines() # Also readline() print(lines)
Hello ['Hello from file!']
Запись в файл
with open("f.txt", "w", encoding="utf-8") as f: f.write("Hello from file!") # Или f.writelines(<collection>)
JSON
Человекочитаемый формат для хранения и передачи данных.
import json d: dict = {1: "Lemon", 2: "Apple", 3: "Banana!"} object_as_string: str = json.dumps(d, indent=2) print(object_as_string) restored_object = json.loads(object_as_string) # Write object to JSON file with open("1.json", 'w', encoding='utf-8') as file: json.dump(d, file, indent=2) # Read object from JSON file with open("1.json", encoding='utf-8') as file: restored_from_file = json.load(file) print(restored_from_file)
{ "1": "Lemon", "2": "Apple", "3": "Banana!" } {'1': 'Lemon', '2': 'Apple', '3': 'Banana!'}
Pickle
Бинарный формат для хранения и передачи данных.
import pickle d: dict = {1: "Lemon", 2: "Apple", 3: "Banana!"} # Запись объекта в бинарный файл with open("1.bin", "wb") as file: pickle.dump(d, file) # Чтение объекта из файла with open("1.bin", "rb") as file: restored_from_file = pickle.load(file) print(restored_from_file)
{1: 'Lemon', 2: 'Apple', 3: 'Banana!'}
Protocol Buffers
Если вы хотите передавать и хранить данные, используя универсальную структуру, одинаково хорошо понимаемую всеми языками программирования (как JSON) и занимающую мало места (как Pickle), то можно посмотреть в сторону Protocol Buffers (Wikipedia, примеры для Python). Есть еще альтернативы, например, FlatBuffers, Apache Avro или Thrift.
Пути (Paths)
При работе с файлами не обойтись без манипулирования файловыми путями.
from os import getcwd, path, listdir from pathlib import Path s1: str = getcwd() # Возвращает текущую рабочую директорию print(s1) s2: str = path.abspath("f.txt") # Возвращает полный путь print(s2) s3: str = path.basename(s2) # Возвращает имя файла s4: str = path.dirname(s2) # Возвращает путь без файла t1: tuple = path.splitext(s2) # Возвращает кортеж из пути и имени файла print(s3, s4, t1) p = Path(s2) st = p.stat() print(st) b1: bool = p.exists() b2: bool = p.is_file() b3: bool = p.is_dir() print(b1, b2, b3) c: list = listdir(path=s1) # Возвращает список имен файлов, находящихся по указанному пути print(c) s5: str = p.stem # Возвращает имя файла без расширения s6: str = p.suffix # Возвращает расширение файла t2: tuple = p.parts # Возвращает все элементы пути как отдельные строки print(s5, s6, t2)
c:\Works\amaargiru\pycore c:\Works\amaargiru\pycore\f.txt f.txt c:\Works\amaargiru\pycore ('c:\\Works\\amaargiru\\pycore\\f', '.txt') os.stat_result(st_mode=33206, st_ino=2251799814917120, st_dev=3628794147, st_nlink=1, st_uid=0, st_gid=0, st_size=16, st_atime=1662468638, st_mtime=1662468638, st_ctime=1661089564) True True False ['.git', '.gitignore', '.pytest_cache', '01_python.ipynb', '01_python.md', '02_postgre.md', '03_architecture.md', '04_algorithms.ipynb', '04_algorithms.md', '05_admin_devops.md', '06_pytest_mock.ipynb', '06_pytest_mock.md', '07_fastapi.md', '08_flask.md', '1.bin', '1.json', 'compose_readme.bat', 'coupling_vs_cohesion.svg', 'f.txt', 'gitflow.svg', 'graph_for_dfs.jpg', 'pycallgraph3.png', 'readme.md'] f .txt ('c:\\', 'Works', 'amaargiru', 'pycore', 'f.txt')
Простейшие вычисления — Sum, Count, Min, Max
a: list[int] = [1, 2, 3, 4, 5, 2, 2] s = sum(a) print(s) c = a.count(2) # Вернет количество вхождений print(c) mn = min(a) print(mn) mx = max(a) print(mx)
19 3 1 5
Присмотритесь к встроенным функциям, там есть еще кое-что, касающееся элементарной математики.
Базовая математика
from math import pi a: float = pi ** 2 # Or pow(pi, 2) print(f"Power: {a}") b: float = round(pi, 2) print(f"Round: {b}") c: int = round(256, -2) print(f"Int round: {c}") d: float = abs(-pi) print(f"Abs: {d}") e: float = abs(10+10j) # Or e: float = abs(complex(real=10, imag=10)) print(f"Complex abs: {e}")
Power: 9.869604401089358 Round: 3.14 Int round: 300 Abs: 3.141592653589793 Complex abs: 14.142135623730951
Побитовые операции
a: int = 0b01010101 b: int = 0b10101010 print(f"And: 0b{a&b:08b}") print(f"Or: 0b{a|b:08b}") print(f"Xor: 0b{a^b:08b}") print(f"Left shift: 0b{a << 4:08b}") print(f"Right shift: 0b{b >> 4:08b}") print(f"Not: 0b{~a:08b}")
And: 0b00000000 Or: 0b11111111 Xor: 0b11111111 Left shift: 0b10101010000 Right shift: 0b00001010 Not: 0b-1010110
Подсчет битов
a: int = 4242 print(f"{a} in binary format: 0b{a:b}") c = a.bit_count() # Returns the number of ones in the binary representation of the absolute value of the integer print(f"Bit count: {c}")
4242 in binary format: 0b1000010010010 Bit count: 4
Fractions
from fractions import Fraction f = Fraction("0.2").as_integer_ratio() print(f)
(1, 5)
Евклидово расстояние между двумя точками
import math p1 = (0.22, 1, 12) p2 = (-0.12, 3, 7) print(math.dist(p1, p2))
5.39588732276722
NumPy
Мини-язык для манипулирования массивами. На удачных сценариях работает в сотни раз быстрее встроенных функций. Еще более быстрая альтернатива работает на GPU, называется CuPy и опять-таки обещает стократный прирост производительности, только уже по сравнению с NumPy. Так что если вам нужен какой-нибудь быстрый FFT или еще какой числогрыз, то вы знаете, что делать. Если вы дружите с английским, то изучайте официальный мануал, если нет — на «Хабре» есть перевод (как всегда, читайте комментарии, там немало полезного).
Небольшое отступление.
Во-первых, тут мы переходим границу между встроенной функциональность языка и внешними библиотеками. Надо понимать, что успех Python во многом основан именно на богатстве его экосистемы (хотя, впрочем, то же самое можно сказать и про JavaScript, и про C#); сам язык предоставляет богатую, но всё же ограниченную функциональность, в то время как функционал внешних библиотек практически безграничен; это как бесконечно разнообразные кубики Лего. Соответственно, очень часто для решения задачи не нужно реализовывать алгоритм с нуля на чистом Python'е, достаточно подобрать нужную библиотеку.
Во-вторых, популярность разных библиотек Python (в том числе и конкурирующих) сильно разнится. Например, NumPy — очень популярная библиотека, но в мире существуют буквально миллионы Python-разработчиков, которые никогда не работали с NumPy, просто в силу своего круга функциональных обязанностей.
Для начинающего разработчика это представляет собой довольно нешуточную проблему — как конкретно двигаться вперед, какие библиотеки изучать, ведь знания чистого Python, как правило, недостаточно для формирования актуального резюме.
Дам вам небольшой совет. Ежегодно компания JetBrains (делающая среди прочего очень классную IDE PyCharm) проводит всемирный опрос Python-разработчиков, а потом выкладывает полученные результаты в виде так называемого Python Developers Survey Results. Например, если вы почитаете результаты последнего исследования, то найдете там довольно чёткие ориентиры: скажем, в разделе «Data science frameworks and libraries» в топе находятся NumPy, Pandas (рассмотрен ниже) и Matplotlib; в тестировании с большим отрывом лидирует pytest (смотри ниже), в других областях вперед вырываются Flask (Django на втором месте с крошечным отрывом), SQLAlchemy (vs Django ORM) и PostgreSQL (vs SQLite), про них мы тоже еще поговорим. Так что в целом, общее направление развития определить можно.
Однако, вернемся к NumPy. Не забывайте, что в основе NumPy лежат массивы, а все данные в массиве должны быть одинакового типа (просто на случай, если вы уже познали пр-р-рел-л-лесть списков Python). Создание массивов:
import numpy as np a1 = np.array([1, 2, 3, 4, 5], float) # Получение массива из списка print(a1[0:2]) a2 = np.zeros(5) # Массив, заполненный нулями print(a2) a3 = np.arange(0, 6, 1) # Использование диапазона, np.arange(from_inclusive, to_exclusive, step_size) print(a3) a4 = np.random.randint(6, size=10) # Создание массива, содержащего случайные значения, np.random.randint(low_inclusive, high_exclusive=None, size=None, dtype=int) print(a4) a5 = np.random.randint(6, size=(2, 5)) # Создание многомерного массива, содержащего случайные значения print(a5) print(a5.shape) # Число строк и столбцов в массиве print(a5.dtype) # Тип переменных print(1 in a5) # Проверка наличия элемента
[1. 2.] [0. 0. 0. 0. 0.] [0 1 2 3 4 5] [2 2 4 0 0 0 0 4 0 5] [[1 0 3 5 0] [3 1 4 2 2]] (2, 5) int32 True
Базовые математические операции (полный список):
import numpy as np a1 = np.array([1, 2, 3, 4, 5]) a2 = np.array([6, 7, 8, 9, 10]) a3 = a1 + 1 print(a3) a4 = a1 + a2 print(a4) a5 = a1 ** 3 print(a5) a6 = a1 ** a2 print(a6)
[2 3 4 5 6] [ 7 9 11 13 15] [ 1 8 27 64 125] [ 1 128 6561 262144 9765625]
Вообще, можно сказать, что быстрые математические операции над многомерными массивами — это главная «фишка» NumPy. Вы просто говорите: возьми такие-то массивы и проделай над ними такую-то операцию. Далее все эти данные «проваливаются» в высокоскоростное ядро NumPy, где к ним уже можно применить всю мощь вашего процессора, которая раньше была вам недоступна (ну, или доступна не полностью) из-за ограничений Python-интерпретатора. Так что, если вы пытаетесь в цикле итерировать массив NumPy, по факту передавая данные на нижний уровень небольшими порциями (например, объектами row), то имейте в виду, что тем самым используете возможности NumPy недостаточно эффективно; попробуйте решить задачу без итерирования.
Sum, Min, Max
import numpy as np a1 = np.random.randint(6, size=(2, 10)) # NumPy поддерживает несколько десятков видов распределений, например, Пуассона и Стьюдента print(a1) s = np.sum(a1) # Сумма всех элементов print(s) mn = a1.min(axis=0) # Наименьшие числа в каждом столбце print(mn) mx = a1.max(axis=1) # Наибольшие числа в каждой строке print(mx) amin = a1.argmin(axis=0) # Индексы минимальных элементов в каждом столбце print(amin) amax = a1.argmax(axis=1) # Индексы максимальных элементов в каждой строке print(amax) uniq = np.unique(a1) # Извлечение уникальных элементов print(uniq)
[[3 0 4 1 0 5 4 0 1 3] [0 3 4 0 0 1 4 0 5 4]] 42 [0 0 4 0 0 1 4 0 1 3] [5 5] [1 0 0 1 0 1 0 0 0 0] [5 8] [0 1 3 4 5]
В качестве домашнего задания попробуйте самостоятельно применить prod(), mean(), var(), std(), median(), cov() и corrcoef().
Форматирование массивов:
import numpy as np a = np.random.randint(6, size=(3, 5)) print(a) a1 = a.reshape((5, 3)) # Форматирование. Если есть возможность, создается новый view на те же самые данные print(a1) a.shape = (5, 3) # Форматирование in-place print(a) print(a.shape) a = a[:, :, np.newaxis] # Увеличение размерности массива с 2 до 3 print(a) print(a.shape) a = a.flatten() # Конвертация в одномерный массив print(a) print(a.shape)
[[5 5 5 1 1] [0 2 0 5 5] [0 2 5 4 5]] [[5 5 5] [1 1 0] [2 0 5] [5 0 2] [5 4 5]] [[5 5 5] [1 1 0] [2 0 5] [5 0 2] [5 4 5]] (5, 3) [[[5] [5] [5]] [[1] [1] [0]] [[2] [0] [5]] [[5] [0] [2]] [[5] [4] [5]]] (5, 3, 1) [5 5 5 1 1 0 2 0 5 5 0 2 5 4 5] (15,)
Копирование массивов:
import numpy as np import copy a = np.random.randint(10, size=(4, 4)) print(a) # Неглубокая (shallow) копия a1 = np.copy(a) # Глубокая (deep) копия a2 = copy.deepcopy(a) # Копирование ссылки a3 = a a[0, 0] = 10 print(a[0, 0] == a1[0, 0]) print(a[0, 0] == a2[0, 0]) print(a[0, 0] == a3[0, 0])
[[5 3 1 4] [0 8 7 0] [1 7 4 7] [5 3 5 2]] False False True
NumPy очень мощный инструмент, не зря же он стоит на первом месте в списке «Data science frameworks and libraries» обзора, который мы упоминали чуть выше. Но углубляться в эту тему очень уж глубоко в рамках нашего достаточно поверхностного очерка, пожалуй, не стоит; вряд ли прямо сейчас вам кровь из носу нужно освоить скалярное, тензорное и внешнее произведение матриц или познать (вспомнить?) специфику линейной алгебры. Думаю, даже если мы сейчас начнем описывать транспонирование или выбор оси, по которой будет произведена конкатенация массивов, то это уже будет, что называется, «не в коня корм».
К тому же, изучая тонкости употребления NumPy, начинает появляться соблазн упоминания SciPy, предоставляющего еще более широкий функционал, а после первого "import scipy" у нас начнётся уже полное непотребство. Давайте пока пройдем мимо этой кроличьей норы, для первого знакомства она слишком глубока.
Единственное, что еще можно освоить в конце ознакомительного курса NumPy — взаимодействие с внешним миром. Изучите для начала load/save/savez (бинарники) и loadtxt/savetxt (человекочитаемый формат).
Pandas
Библиотека обработки и анализа данных. Работа с данными строится поверх библиотеки NumPy.
В первом, грубом приближении pandas можно воспринимать как связку «Excel + VisualBasic-скрипты», только более гибкую и удобную. Библиотека создает своеобразный мостик между профессиями Python-программиста, дата-сайентиста и аналитика, позволяя сосредоточиться в большей степени именно на очистке и анализе данных, на читабельности отчетов, а не на программировании. Pandas также поддерживает широкий спектр «красивостей» при выводе информации, позволяя, например, добавлять в выводимые данные градиентную подсветку (heatmap) или визуализировать отклонение от среднего (bar chart).
Для того чтобы как следует «распробовать» pandas, по-хорошему надо загрузить какой-нибудь развесистый набор данных, но мы, пожалуй, не будем погружаться в глубины глубин, просто поиграем небольшим самодельным датасетом.
import pandas as pd s = pd.Series([0, 1, 4, 7, 8, 10, 12]) print(s) print(s[2])
0 0 1 1 2 4 3 7 4 8 5 10 6 12 dtype: int64 4
Series — базовая структура данных pandas. Вы можете воспринимать её как упорядоченный словарь или как строку Excel, смотря по тому, какая аналогия вам ближе.
import pandas as pd s = pd.Series([0, 1, 4, 7, 8, 10, 12], index=["a", "b", "c", "d", "x", "y", "z"]) # Индексы Series можно задавать вручную print(s) print(s["x"]) print(s[["x", "y", "z"]]) # Выборка print(s[s > 5]) # Фильтрация print(s.max()) # Математика, примерно как в NumPy print(s.sum())
a 0 b 1 c 4 d 7 x 8 y 10 z 12 dtype: int64 8 x 8 y 10 z 12 dtype: int64 d 7 x 8 y 10 z 12 dtype: int64 12 42
При объединении нескольких Series получается DataFrame, вторая базовая структура данных pandas, которую в первом приближении можно рассматривать как лист Excel.
import pandas as pd from pandas import DataFrame s1 = pd.Series([0, 1, 4, 7, 8, 10, 12]) s2 = pd.Series([0, 100, 200, 300, 600, 900, 1200]) df = pd.DataFrame([s1, s2]) print(df) print(df[1]) print(df[2][0]) print(df.iloc[0][2:4])
0 1 2 3 4 5 6 0 0 1 4 7 8 10 12 1 0 100 200 300 600 900 1200 0 1 1 100 Name: 1, dtype: int64 4 2 4 3 7 Name: 0, dtype: int64
Давайте сделаем что-то более похожее на реальный анализ данных. При помощи формулы ИМТ выясним, кто из знаменитостей не следит за собой и обзавелся лишним весом:
from pandas import DataFrame import matplotlib.pyplot as plt def bmi(row): return row["weight"] / row["height"] ** 2 if __name__ == '__main__': celebs: dict = {"Britney Spears": {"height": 1.63, "weight": 57}, "Melanie Griffith": {"height": 1.73, "weight": 63}, "Kylie Minogue": {"height": 1.52, "weight": 46}, "Hulk Hogan": {"height": 1.98, "weight": 137}} df = DataFrame(celebs) # Создаем DataFrame df.loc["bmi"] = df.apply(lambda row: bmi(row), axis=0) # Добавлем новую строку с ИМТ df = df.sort_values(by="bmi", ascending=True, axis=1) # Сортируем print(df) df.loc["bmi"].plot.bar() # Визуализация plt.show()
Kylie Minogue Melanie Griffith Britney Spears Hulk Hogan height 1.520000 1.730000 1.630000 1.980000 weight 46.000000 63.000000 57.000000 137.000000 bmi 19.909972 21.049818 21.453574 34.945414

На самом деле Халк, конечно, не толстяк, а профессиональный спортсмен, к которым формула ИМТ малоприменима, но крошка Кайли действительно вырывается вперед, даже с учетом своего небольшого роста.
Matplotlib/Seaborn
Библиотеку визуализации matplotlib мы уже слегка задействовали в примере выше. Прямо здесь и прямо сейчас глубоко погружаться в разбор возможностей matplotlib/seaborn, наверное, особого смысла не имеет; все вы видели примеры иллюстраций в научной и бизнес-литературе и, разумеется, все эти графики и иллюстрации можно повторить при помощи рассматриваемых библиотек.
Давайте просто для затравки нарисуем пару симпатичных визуализаций, чтобы наглядно показать полезность качественного оформления результатов проделанной работы.
Тепловая карта (heatmap), наглядно показывающая достижения отдельных членов команды:
from random import randrange import numpy as np import matplotlib.pyplot as plt import uuid targets = ["authorities", "humans", "parrots", "cars", "motorcycles", "buildings", "warehouses"] robots = ["Terminator #" + str(uuid.uuid4())[:5] for _ in range(7)] harvest = np.array([[randrange(i * j) for i in range(10, 80, 10)] for j in range(1, 8)]) fig, ax = plt.subplots() im = ax.imshow(harvest) ax.set_xticks(np.arange(len(robots)), labels=robots) ax.set_yticks(np.arange(len(targets)), labels=targets) plt.setp(ax.get_xticklabels(), rotation=60, ha="right", rotation_mode="anchor") for i in range(len(targets)): for j in range(len(robots)): text = ax.text(j, i, harvest[i, j], ha="center", va="center", color="w") ax.set_title("Targets destroyed") fig.tight_layout() plt.rcParams['figure.figsize'] = [4, 4] plt.rcParams['figure.dpi'] = 200 plt.show()

Аналогичная тепловая карта, визуализированная при помощи seaborn:
from random import randrange import numpy as np import matplotlib.pyplot as plt import uuid import seaborn as sns sns.set_theme() targets = ["authorities", "humans", "parrots", "cars", "motorcycles", "buildings", "warehouses"] robots = ["Terminator #" + str(uuid.uuid4())[:5] for _ in range(7)] harvest = np.array([[randrange(i * j) for i in range(10, 80, 10)] for j in range(1, 8)]) fig, ax = plt.subplots() im = ax.imshow(harvest) ax.set_title("Targets destroyed") plt.rcParams['figure.figsize'] = [4, 4] sns.heatmap(harvest, annot=True, fmt="d", linewidths=.5, ax=ax, xticklabels=robots, yticklabels=targets) plt.setp(ax.get_xticklabels(), rotation=60, ha="right", rotation_mode="anchor") plt.xticks(rotation=60) plt.show()

А вот так будет выглядеть «Доска почёта» при отрисовке в 3D:
import uuid from random import randrange import matplotlib.cm as cm import matplotlib.colors as colors import matplotlib.pyplot as plt import numpy as np targets = ["authorities", "humans", "parrots", "cars", "motorcycles", "buildings", "warehouses"] robots = ["Terminator #" + str(uuid.uuid4())[:5] for _ in range(7)] harvest = np.array([[randrange(i * j) for i in range(10, 80, 10)] for j in range(1, 8)]) fig = plt.figure(figsize=(5, 5)) ax = fig.add_subplot(projection='3d') ax.set_xticks(np.arange(len(robots)), labels=robots) ax.set_yticks(np.arange(len(targets)), labels=targets) plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor") plt.setp(ax.get_yticklabels(), ha="left", rotation_mode="anchor") ax.set_title("Our team") xx, yy = np.meshgrid(range(len(targets)), range(len(robots))) x1d, y1d = xx.ravel(), yy.ravel() harvest1d = harvest.ravel() # Setup color scheme offset = harvest1d + np.abs(harvest1d.min()) fracs = offset.astype(float) / offset.max() norm = colors.Normalize(fracs.min(), fracs.max()) colors = cm.jet(norm(fracs)) ax.bar3d(x1d, y1d, np.zeros_like(x1d + y1d), 0.7, 0.7, harvest1d, color=colors) plt.show()

Нейронные сети
Углубиться достаточно глубоко в тематику глубокого обучения в рамках нашего несколько неглубокого формата, конечно, не получится (каким-нибудь томом «Введение в Deep Learning» вполне можно нанести себе существенные травмы, если неудачно уронить со стола), так что скользнём буквально по верхушкам, рассмотрев основные понятия.
Глубинная нейронная сеть (deep neural network) — это, формально выражаясь, многослойная искусственная нейронная сеть, использующая алгоритмы машинного обучения для моделирования высокоуровневых абстракций с применением нелинейных преобразований. В ходу есть еще такие термины, как «поверхностное машинное обучение», «слабый ИИ», «сильный ИИ»; существует классификация понятий «глубокое обучение», «машинное обучение» и «искусственный интеллект» (вот, например, вариант от Microsoft, такую же структуру-матрёшку демонстрирует Франсуа Шолле в своей книге «Глубокое обучение на Python»), но сейчас, по крайней мере при неформальном общении, всё чаще ставится знак равенства между «машинным обучением» и «искусственным интеллектом»; причём в работе, как правило, используется «машинное обучение», а при подготовке презентаций — «искусственный интеллект» :) Дело, по всей видимости, в том, что глубокое обучение стало самой многообещающей и динамично развивающейся областью машинного обучения, а искусственным интеллектом уже давно именовали всю эту область знаний как популяризаторы науки, так и журналисты.
В общем, при первоначальном знакомстве с TensorFlow или PyTorch можете смело всем говорить, что занимаетесь AI, а если захотите углубиться — уж терминологией-то овладеете.
Что касается сути работы нейронных сетей, то здесь можно выделить следующие основные понятия:
Датасет — маркированные данные, используемые для обучения сети и для последующей проверки качества этого обучения. Вариант простого датасета — коллекция изображений одинакового размера с рукописными цифрами и буквами, где про каждое изображение точно известно, какай именно символ в нём содержится; такой датасет нужен для разработки систем распознавания рукописного текста (handwritten text recognition, HTR). Создание качественных датасетов — большая, тяжелая работа, поэтому сейчас идет активная работа по созданию моделей, способных работать с большими объёмами немаркированных данных. Как правило, датасет разбивается на две части — для обучения сети и для проверки качества проведенного обучения.
Искусственная нейронная сеть — программный или аппаратный аналог биологической нейронной сети; в самом простом варианте, в сети прямого распространения, это последовательно соединенные слои нейронов. Первые реализации нейронных сетей получили практическое воплощение еще в 60-х годах XX века, хотя существенный прогресс и практическое внедрение приходятся примерно на последние лет пятнадцать.
Архитектура искусственной нейронной сети — определяет общие принципы её построения, вот здесь есть хорошее введение в тему, наглядно показано, чем, например, GAN отличается от LSTM.
Обучение нейронной сети — если в двух словах, то это нахождение коэффициентов связи между нейронами. Применительно к машинному обучению заменяет процесс собственно программирования. Когда мы говорим о DALL-E 2, способном создавать изображения по текстовым описаниям или об AlphaGo, обыгрывающем профессиональных игроков в го — мы говорим в первую очередь об обученных нейронных сетях, создатели которых проявили бездну изобретательности, чтобы все коэффициенты связи были на своём месте. Дообучение — частичная корректировка коэффициентов связи между нейронами при модификации старого или добавлении нового функционала.
Зачем нужно машинное обучение? Сильный ИИ, который будет (скрестим пальцы) решать все наши проблемы в режиме реального времени, еще за горизонтом, а прямо сейчас нейронные сети решают задачи, которые не по зубам классическим алгоритмам. Можно ли при помощи «обычного» программирования решить, например, задачу распознавания отсканированного текста или перевода с одного языка на другой? Да, можно, и такие небезуспешные попытки неоднократно предпринимались. Но, учитывая прорыв в развитии математической базы машинного обучения, наметившийся в последние 10-15 лет, помноженный на гигантский прирост производительности даже обычных повседневных вычислительных устройств, вроде смартфонов, фактически и распознавание, и перевод сейчас реализуют только при помощи машинного обучения. Для некоторых же классов задач, таких как распознавание изображений и видео с последующей классификацией объектов или беспилотная транспортировка, решения на базе классических алгоритмов никогда не заходили дальше вялотекущих концептов.
Мало-помалу машинное обучение делает нашу жизнь лучше. Со временем, надеюсь, каждый из нас сможет воспользоваться плодами работы искусственного интеллекта, хоть мы и величаем его «слабым». И речь идет не только о громких проектах, вроде автопилота «Теслы» (хотя и это крайне немаловажно), но в первую очередь о постоянном сканировании эксабайтных потоков информации, порождаемых современной цифровой цивилизацией — видео с уличных камер, сканов МРТ и КТ, телеметрии с фитнес-браслетов, отчетов об исследовании лекарственных средств и пищевых добавок. И если всё это пройдет перед, может быть, пока не очень умными, но зато неустанными глазами предварительно должным образом обученной нейронной сети, то кратно уменьшится неверных диагнозов, людей, умерших от инсультов или замерзших на улицах, а также лекарств с тяжелыми побочными эффектами.
Но помните, однако — даже если вы полны энтузиазма и готовы хоть прямо сейчас нырнуть во все эти модные, интересные и актуальные сущности вроде бигдаты или ИИ — чем дальше вы будете углубляться в эту тематику, тем меньше в вас будет программиста, тем больше исследователя, учёного, математика. Где-то в самом конце этого длинного-предлинного коридора сидит вовсе не Нео из «Матрицы», а эдакий себе Григорий Перельман, уставший человек с ручкой и листом бумаги, иногда этой ручкой на этой бумаге пишущий вещи, которые потом приходится два года разжевывать лучшим математикам мира. Крепко подумайте, как глубоко вы хотите и можете зайти, взвесьте свои силы.
3. Потоки данных
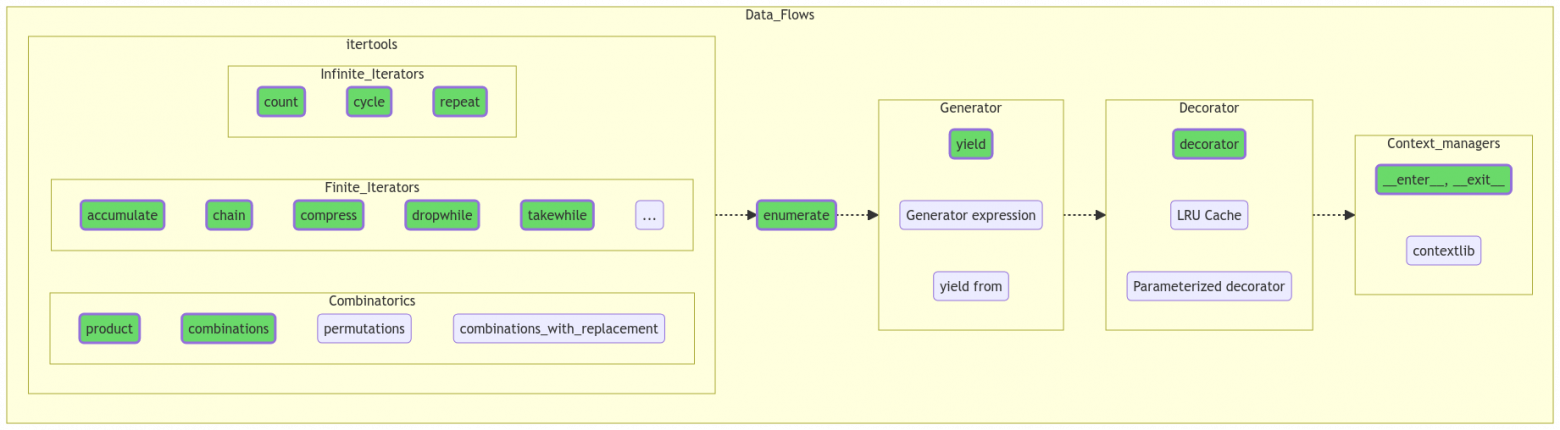
Itertools
Методы модуля itertools возвращают итераторы.
Итератор — механизм поэлементного обхода данных, который использует метод next() для получения следующего значения последовательности. Подробнее создание итераторов будет рассмотрено ниже, в разделе «ООП / Утиная типизация». В «нормальные» данные итераторы перегоняются при помощи for, next или list().
Itertools содержит множество готовых итераторов, которые могут быть бесконечными (порождаются при помощи count, cycle или repeat), конечными (accumulate, chain, takewhile и другие) и комбинаторными (product, combinations, combinations_with_replacement, permutations). Лучше изучить их все, хотя бы поверхностно, потому что даже относительно редко употребляемый метод, например, какой-нибудь zip_longest(), иногда весьма и весьма пригождается, идеально ложась на поставленную задачу.
Пример работы с бесконечными итераторами:
from itertools import count, repeat, cycle # Итератор, возвращающий равномерно распределенные значения i1 = count(start=0, step=.1) print(next(i1)) print(next(i1)) print(next(i1)) # Итератор, циклично и бесконечно возвращающий элементы итерируемого объекта i2 = cycle([1, 2]) print(next(i2)) print(next(i2)) print(next(i2)) # Итератор, возвращающий один и тот же объект бесконечно, если не указано значение аргумента times i3 = repeat("Wow!", times=3) print(list(i3))
0 0.1 0.2 1 2 1 ['Wow!', 'Wow!', 'Wow!']
Применение некоторых конечных итераторов:
from itertools import accumulate, chain, compress, dropwhile, takewhile, pairwise import operator # Итератор, возвращающий накопленный результат выполнения указанной функции (по умолчанию — сложение) i1 = accumulate([1, 2, 3, 4]) i2 = accumulate([1, 2, 3, 4], initial=10) print(list(i1), list(i2)) i3 = accumulate([ -3, -2, -1, 1, 2, 3, 4], operator.mul) print(list(i3)) # Можно использовать свою функцию def myfunc(accumulated, current): return accumulated + 2 * current i4 = accumulate([1, 2, 3, 4], func=myfunc) print(list(i4)) # Можно использовать лямбду (подробнее рассмотрены ниже) i5 = accumulate([1, 2, 3, 4], lambda accumulated, current: accumulated + 2 * current) print(list(i5)) # Итератор, возвращающий только те элементы входной последовательности, # которые имеют соответствующий элемент, равный True или 1 в последовательности selectors i6 = compress("ABCDEF", [1, 1, 1, 0, 0, 1]) print(list(i6)) # Итератор, отбрасывающий элементы входной последовательности, если результат выполнения функции равен True. # Как только предикат становится False, то отбрасывание прекращается (предикат больше не применяется) i7 = dropwhile(lambda x: x<5, [1, 4, 6, 4, 1, 1, 1, 0]) print(list(i7)) # takewhile, в отличие от dropwhile, наоборот, возвращает элементы входной последовательности, # если результат выполнения функции равен True i8 = takewhile(lambda x: x<5, [1, 4, 6, 0, 4, 1, 2, 1]) print(list(i8)) # Итератор, формирующий из нескольких входных последовательностей одну общую i2 = chain(["A", "B", "C"],["D", "E", "F"],["G", "H", "I"]) print(list(i2)) # Кстати, такой же трюк можно провернуть при помощи обычной sum(), задав ей начальный параметр [] (т. е. пустой список) a = sum([["A", "B", "C"],["D", "E", "F"],["G", "H", "I"]], []) print(a) # Возвращает элементы входной коллекции попарно i6 = pairwise([1, 2, 3, 4, 5]) print(list(i6))
[1, 3, 6, 10] [10, 11, 13, 16, 20] [-3, 6, -6, -6, -12, -36, -144] [1, 5, 11, 19] [1, 5, 11, 19] ['A', 'B', 'C', 'F'] [6, 4, 1, 1, 1, 0] [1, 4] ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'] ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'] [(1, 2), (2, 3), (3, 4), (4, 5)]
Комбинаторика
from itertools import product, combinations, combinations_with_replacement, permutations # Создает множество, содержащее все упорядоченные пары элементов из входных множеств a = product("abc", "xyz") print(list(a)) b = product([0, 1], repeat=3) print(list(b)) # Возвращает подпоследовательности длины r из элементов входного итерируемого объекта, повторяющиеся элементы не допускаются c = combinations("abc", r=2) print(list(c)) # Выдает перестановки элементов итерируемого объекта d = permutations("abc", r=2) print(list(d)) # Возвращает подпоследовательности длины r из элементов входного итерируемого объекта, повторяющиеся элементы допустимы e = combinations_with_replacement("abc", r=2) print(list(e))
[('a', 'x'), ('a', 'y'), ('a', 'z'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'x'), ('c', 'y'), ('c', 'z')] [(0, 0, 0), (0, 0, 1), (0, 1, 0), (0, 1, 1), (1, 0, 0), (1, 0, 1), (1, 1, 0), (1, 1, 1)] [('a', 'b'), ('a', 'c'), ('b', 'c')] [('a', 'b'), ('a', 'c'), ('b', 'a'), ('b', 'c'), ('c', 'a'), ('c', 'b')] [('a', 'a'), ('a', 'b'), ('a', 'c'), ('b', 'b'), ('b', 'c'), ('c', 'c')]
Enumerate
Иногда, при переборе объектов в цикле for, нужно получить не только сам объект, но и его порядковый номер. Разумеется, это можно сделать, создав дополнительную переменную, которая будет инкрементироваться на каждом шаге цикла. Однако, гораздо удобнее это делать с помощью итератора enumerate, введенным в PEP-279. Enumerate — синтаксический сахар («introduces… to simplify a commonly used looping idiom»), позволяющий проще и нагляднее работать с объектами, поддерживающими итерацию. Метод __next__() enumerate возвращает кортеж, содержащий значение индекса и соответствующее этому индексу значение.
В документации работа enumerate упрощенно объясняется через генератор:
def enumerate(sequence, start=0): n = start for elem in sequence: yield n, elem n += 1
На самом деле enumerate — не генератор, а итератор:
import collections import types e = enumerate("abcdef") print(isinstance(e, enumerate)) print(isinstance(e, collections.Iterable)) print(isinstance(e, collections.Iterator)) print(isinstance(e, types.GeneratorType))
True True True False
Enumerate реализован не на Python, а на C, и в его исходном коде, разумеется, нет ключевого слова yield.
Примеры использования enumerate:
values = ["a", "b", "c", "d"] for count, value in enumerate(values): print(count, value) print("\n") for count, value in enumerate(values, start=10 ): print(count, value)
0 a 1 b 2 c 3 d 10 a 11 b 12 c 13 d
Генератор (generator)
Любая функция, содержащая ключевое слово yield, вернет генератор. Генератор не хранит в памяти все необходимые элементы, а просто содержит метод для вычисления очередного элемента; результат может создаваться на основе математического алгоритма или брать элементы из другого источника данных (коллекция, файл, сетевое подключение и т. д.), при необходимости модифицируя их.
Пройти генератор в цикле можно только один раз, на каждом шаге возможно вычислить только следующий элемент, но не предыдущий. Элемент генератора нельзя извлечь по индексу, будет выброшена ошибка, т. к. генератор не поддерживает метод __getitem__().
Бесконечный генератор:
def count(start, step): current = start while True: yield current current += step c = count(100, 10) print(next(c)) print(next(c)) print(next(c))
100 110 120
Конечный генератор.
Также, как и конечный итератор, конечный генератор можно превратить в список при помощи list() (вы можете попробовать превратить в list и бесконечный генератор, но процесс рискует несколько затянуться :):
def count(start, stop, step): current = start while current <= stop: yield current current += step c = count(100, 200, 10) print(next(c)) print(next(c)) print(next(c)) print(list(c))
100 110 120 [130, 140, 150, 160, 170, 180, 190, 200]
Следует разделять итераторы и генераторы. Итератор — объект, который использует метод __next__() для получения следующего значения последовательности. Генератор — функция, которая позволяет отложено создавать результат при итерации.
Объявление генератора
Объявить генератор можно несколькими методами. Первый метод — объявить функцию с yield, как было показано выше.
Второй метод — использовать генераторное выражение (generator expression):
r = range(1, 11) squares = (n**2 for n in r) print(list(squares))
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
Можно объединить генераторы или делегировать часть функционала генератора другому генератору при помощи конструкции yield from:
def subg(): yield 'World' def generator(): yield 'Hello' yield from subg() yield '!' for i in generator(): print(i, end = ' ')
Hello World !
До широкого распространения asyncio конструкция yield from использовалась для создания корутин на базе генераторов.
Декораторы
Что такое декораторы?
Декоратор в широком смысле – паттерн проектирования, когда один объект изменяет поведение другого. Декораторы — это, по сути, своеобразные «обёртки», которые дают нам возможность делать что-либо до или после того, что сделает декорируемая функция, не изменяя её. Можно сказать, что декоратор является просто синтаксическим сахаром для конструкции вида:
my_function = my_decorator(my_function)
def makebold(fn): def wrapped(): return "<b>" + fn() + "</b>" return wrapped def makeitalic(fn): def wrapped(): return "<i>" + fn() + "</i>" return wrapped # Разумеется, при последовательном применении нескольких декораторов играет роль порядок декорирования. @makebold @makeitalic def hello(): return "Hello, world!" print(hello())
<b><i>Hello, world!</i></b>
Декоратор, подсчитывающий время работы оборачиваемой функции:
import time def perf_counter(function): def counted(*args): start_time = time.perf_counter_ns() res = function(*args) print(f"{time.perf_counter_ns() - start_time} ns") return res return counted @perf_counter def slow_sum(x, y): time.sleep(1) return x + y print(slow_sum(1, 2))
1002478400 ns 3
LRU Cache
Декоратор, кеширующий значения, возвращаемые функцией. Все аргументы функции должны быть хэшируемы.
import functools def recursion_sum(n): if n == 1: return n print(n, end=" ") return n + recursion_sum(n - 1) recursion_sum(5) print("\n") recursion_sum(9) print("\n") @functools.lru_cache def recursion_sum2(n): if n == 1: return n print(n, end=" ") return n + recursion_sum2(n - 1) recursion_sum2(5) print("\n") recursion_sum2(9)
5 4 3 2 9 8 7 6 5 4 3 2 5 4 3 2 9 8 7 6 45
Размер кеша по умолчанию 128 значений. Ограничение можно отменить при помощи 'maxsize=None'.
Пока мы не ушли далеко от тема кеша, погуглите заодно модуль weakref и WeakValueDictionary, позволяющие организовать более гибкую работу с кешем.
Параметризованный декоратор
В декоратор можно передать и позиционные, и именованные аргументы — args и kwargs соответственно. Синтаксис декораторов с аргументами немного отличается — декоратор с аргументами должен возвращать функцию, которая принимает функцию и возвращает другую функцию:
def text_wrapper(wrap_text): def wrapped(function): def wrapper(*args, **kwargs): result = function(*args, **kwargs) return f"{wrap_text}\n{result}\n{wrap_text}" return wrapper return wrapped @text_wrapper('============') def my_decorated_function(text): return text print(my_decorated_function('Hello, world!'))
============ Hello, world! ============
Контекстный менеджер
Код, размещенный внутри оператора with выполняется с особенностью: как до, так и после срабатывают события входа в блок with и выхода из него. Объект, который определяет логику событий, называется контекстным менеджером.
На уровне класса события определены методами __enter__ и __exit__.
__enter__ срабатывает в тот момент, когда ход исполнения программы переходит внутрь with. Метод может вернуть значение. Оно будет доступно расположенному внутри блока with коду.
__exit__ срабатывает в момент выхода блока, в т.ч. и в случае исключения. В этом случае в метод будет передана тройка значений (exc_class, exc_instance, traceback).
Самый распространённый контекстный менеджер – класс, порожденный функцией open. Он гарантирует, что файл будет закрыт даже в том случае, если внутри блока возникнет ошибка.
Желательно побыстрее выходить из контекстного менеджера, освобождая контекст и ресурсы.
with open('file.txt') as f: data = f.read() process_data(data)
В примере выше мы вышли из блока with сразу же после прочтения файла. Обработка данных происходит в основном блоке программы.
Контекстные менеджеры можно использовать для временной замены параметров, переменных окружения, транзакций БД.
Напишем свой контекстный менеджер для подключения к БД SQLite:
import sqlite3 class db_conn: def __init__(self, db_name): self.db_name = db_name # Открываем подключение к БД def __enter__(self): self.conn = sqlite3.connect(self.db_name) return self.conn # Закрываем подключение к БД def __exit__(self, exc_type, exc_value, exc_traceback): self.conn.close() if exc_value: raise if __name__ == "__main__": db = "test_context_connect.db" with db_conn(db) as conn: cursor = conn.cursor()
Контекстный менеджер на базе contextlib
Перепишем наш контекстный менеджер для подключения к БД SQLite при помощи contextlib:
import sqlite3 from contextlib import contextmanager # Схема конструирования следующая: всё, что написано до оператора yield - вызывается в рамках функции __enter__, # всё что после – в рамках __exit__. @contextmanager def db_conn(db_name): # Открываем подключение к БД conn = sqlite3.connect(db_name) yield conn # Закрываем подключение к БД conn.close() if __name__ == "__main__": db = "test_contextlib_connect.db" with db_conn(db) as conn: cursor = conn.cursor()
4. ООП

Классы и объекты
Тут, конечно, было бы к месту кратенькое, минут на сорок, введеньице в тему классов и объектов, но в наш текущий формат такая мощная врезка не совсем укладывается. Объясню максимально просто, на доступных примерах из киновселенной «Чужих»:
объект — это один конкретный ксеноморф;
класс — это Королева ксеноморфов. Класс либо рожает ксеноморфа, либо может вступить в бой сам (@staticmethod);
метапрограммирование — это такая Супер-Королева, размером с «Сулако», которая рожает других Королев;
наследование — это ксеноморф из «Воскрешения», помните, миленький такой, взявший лучшее и от собственной генетической программы и от генов Рипли.
Мы попробуем вернуться к теме объектов с чуть более серьезным настроением позже, в главе «Архитектура», но, вообще, в объектно-ориентированном программировании нет ничего особо сложного; просто до него лучше дойти, предварительно немного погрязнув в поддержке обычного процедурного подхода, когда зачастую стоит выбор — попробовать подлечить этот кусок кода или уже усыпить и переписать всё по новой? Когда-то давно, когда я писал относительно несложные программы на ассемблере для микроконтроллеров, то читая Страуструпа, слегка недоумевал — зачем всё это? Чтобы осознать потребность в обуви, надо походить босиком.
Магические методы
Специальные (называемые также magic или dunder) методы класса — перегрузка, позволяющая классам определять собственное поведение по отношению к операторам языка.
Магические они потому, что почти никогда не вызываются явно. Их вызывают встроенные функции или синтаксические конструкции. Например, функция len() вызывает метод __len__() переданного объекта. Метод __add__(self, other) вызывается автоматически при сложении оператором +.
Примеры магических методы:
__init__: конструктор класса
__add__: сложение с другим объектом
__eq__: проверка на равенство с другим объектом
__cmp__: сравнение (больше, меньше, равно)
__iter__: при подстановке объекта в цикл
print(dir(int), "\n") class A: # An empty class ... a = A() print(dir(a), "\n") print(repr(a), "\n") print(str(a))
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'as_integer_ratio', 'bit_count', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes'] ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__'] <__main__.A object at 0x000001A1FFF3AF20> <__main__.A object at 0x000001A1FFF3AF20>
Особенностью метода __init__ является то, что он не должен ничего возвращать. При попытке возврата данных будет сгенерировано исключение.
__repr__ (representation) возвращает более-менее машино-читаемое представление объекта, полезное для отладки.
Иногда repr может содержать достаточно информации для восстановления объекта.
__str__ возвращает человеко-читаемое сообщение. Если __str__ не определён, то str использует repr.
class Person: # A simple class with init, repr and str methods def __init__(self, name: str): self.name: str = name def __repr__(self): return f"Person '{self.name}'" def __str__(self): return f"{self.name}" def say_hi(self): print("Hi, my name is", self.name) p = Person("Charlie") p.say_hi() print(repr(p)) print(str(p))
Hi, my name is Charlie Person 'Charlie' Charlie
@property
Декоратор @property используется для определения методов, доступных как поля. Таким образом операции чтения/записи поля можно обрамить дополнительной логикой, например, проверкой допустимых значений входного аргумента.
import math class Circle: def __init__(self, radius, max_radius): self._radius = radius self.max_radius = max_radius @property def radius(self): return self._radius @radius.setter def radius(self, value): if value <= self.max_radius: self._radius = value else: raise ValueError @property def area(self): return 2 * self.radius * math.pi circle = Circle(10, 100) circle.radius = 20 # OK # circle.radius = 101 # Raises ValueError print(circle.area)
125.66370614359172
@staticmethod
Обычный метод (т. е. не помеченный декораторами @staticmethod или @classmethod) имеет доступ к свойствам конкретного экземпляра класса.
@staticmethod — метод, принадлежащий классу, а не экземпляру класса. Можно вызывать без создания экземпляра, т. к. метод не имеет доступа к свойствам экземпляра. При помощи @staticmethod помечают функционал, логически связанный с классом, но не требующий доступа к свойствам экземпляра.
@classmethod, cls, self
Если метод не должен иметь доступа к свойствам конкретного экземпляра класса (как @staticmethod), но должен иметь доступ к другим методам и переменным класса, то следует использовать @classmethod.
class B(object): def foo(self, x): print(f"Run foo({self}, {x})") @classmethod def class_foo(cls, x): print(f"Run class_foo({cls}, {x})") @staticmethod def static_foo(x): print(f"Run static_foo({x})") b = B() b.foo(1) b.class_foo(1) b.static_foo(1)
Run foo(<__main__.B object at 0x000001A1FFF3A980>, 1) Run class_foo(<class '__main__.B'>, 1) Run static_foo(1)
У @classmethod первым параметром должен быть cls (класс), а у обычного метода — self (экземпляр класса).
Для @staticmethod не требуется ни cls, ни self.
__dict__
Каждый класс и каждый объект имеет атрибут __dict__. Это «системный», определённый интерпретатором атрибут, его не нужно создавать вручную. __dict__ — словарь, который хранит пользовательские атрибуты, и в котором ключом является имя атрибута, значением, соответственно, значение атрибута.
class Supercriminal: publisher = 'DC Comics' Riddler = Supercriminal() print(Supercriminal.__dict__) print(Riddler.__dict__) Riddler.name = 'Edward Nygma' print(Riddler.__dict__) # Values from object __dict__ print(Riddler.publisher) # Value from class __dict__
{'__module__': '__main__', 'publisher': 'DC Comics', '__dict__': <attribute '__dict__' of 'Supercriminal' objects>, '__weakref__': <attribute '__weakref__' of 'Supercriminal' objects>, '__doc__': None} {} {'name': 'Edward Nygma'} DC Comics
Каждый раз при запросе пользовательского атрибута Python последовательно обыскивает сам объект, класс объекта и классы, от которых унасаледован класс объекта.
__slots__
Если вы припомните разницу между списком и кортежем, а также между множеством и иимутабельным множеством, то заметите, что создатели Python пытаются предоставлять разработчикам выбор между удобством и скоростью (тут Си с ассемблерными вставками слегка напрягается, но потом опадает, как будто хотел что-то сказать, но благоразумно передумал). К списку таких же особенностей языка, заточенных на увеличение производительности и уменьшение занимаемой памяти, относится и __slots__.
Вот официальная документация по __slots__, а вот дополнительные разъяснения от одного из разработчиков официальной документации. При выборе «slots или не slots» не забывайте также про существование PEP 412 – Key-Sharing Dictionary, который внёс некоторый раздрай в некогда однозначное отношение к __slots__.
__dict__, рассмотренный чуть выше – изменяемая структура, и вы можете на лету добавлять и удалять поля из класса, что удобно, но порой медленно. Вы можете разменять удобство на скорость и размер занимаемой памяти, создав __slots__ — жестко заданный список предопределенных атрибутов, резервирующий память, создание которого запрещает дальнейшее создание __dict__ и __weakref__. Слоты можно использовать, когда у класса может быть очень много полей, например, в ORM, либо когда критична производительность, потому что доступ к списку работает быстрее, чем поиск в словаре.
class Clan: __slots__ = ["first", "second"] clan = Clan() clan.first = "Joker" clan.second = "Lex Luthor" # clan.third = "Green Goblin" # Raises AttributeError # print(clan.__dict__) # Raises AttributeError
Слоты используются, скажем, в библиотеках requests (например, __slots__ = ["url", "netloc", "simple_url", "pypi_url", "file_storagedomain"]) или ORM peewee (__slots_\ = ('stack', '_sql', '_values', 'alias_manager', 'state')).
Наследование __slots__ имеет определенную специфику и будет рассмотрено ниже.
Чтобы было понятно, о каком приросте производительности и снижении потребления памяти идёт речь, сделаем простое сравнение:
import timeit import pympler.asizeof # В нашем случае sys.getsizeof - не лучший вариант, берем стороннее решение class NotSlotted(): pass class Slotted(): __slots__ = 'foo' not_slotted = NotSlotted() slotted = Slotted() def get_set_delete_fn(obj): def get_set_delete(): obj.foo = "Never Ending Song of Love" del obj.foo return get_set_delete ns = min(timeit.repeat(get_set_delete_fn(not_slotted))) s = min((timeit.repeat(get_set_delete_fn(slotted)))) print(ns, s, f'{(ns - s) / s * 100} %') print(pympler.asizeof.asizeof(not_slotted), 'bytes') print(pympler.asizeof.asizeof(slotted), 'bytes')
0.10838449979200959 0.08712740009650588 24.39772066187959 % 280 bytes 40 bytes
Я в Python 3.10 в Windows вижу 24 % разницы.
На всякий случай напоминаю еще раз — прогняйте все непонятные примеры кода в IDE, их можно и нужно анализировать, корректировать и видоизменять. Попробуйте, например, самостоятельно посмотреть потребление памяти объектов с __dict__ и __slots__. А заодно на практике испытайте давно напрашивающийся, и наконец появившийся в Python 3.10 симбиоз между __slots__ и dataclass.
Утиная типизация
Утиная типизация (duck types) — постулирование реализации интерфейса классом не через явное объявление, а через реализацию методов интерфейса. Так, каждый класс, реализующий методы __next__() и __iter__(), автоматически становится итератором, несмотря на отсутствие явного объявления (что-нибудь вроде iterator) или, скажем, наследования от класса Iterator.
Iterator
Итератор — класс, реализующий методы __next__() и __iter__().
Метод __next__() должен возвращать следующее значение итератора или выкидывать исключение StopIteration, чтобы сигнализировать о том, что итератор исчерпал доступные значения.
Метод __iter__() должен возвращать "self".
class LimitCounter: def __init__(self, max_value: int): self.count = 0 self.max_value = max_value def __next__(self): self.count += 1 if self.count <= self.max_value: return self.count else: raise StopIteration def __iter__(self): return self limit_counter = LimitCounter(2) print(next(limit_counter)) print(next(limit_counter)) # print(next(limit_counter)) # Raises StopIteration
1 2
Comparable
Начиная с Python 3.4, для того, чтобы экземпляры метода можно было сравнивать между собой, достаточно определить методы __lt__ (меньше) и __eq__ (равно), а также задействовать декоратор @functools.total_ordering.
from functools import total_ordering @total_ordering class Person: def __init__(self, firstname: str, lastname: str): self.firstname: str = firstname self.lastname: str = lastname def _is_valid_operand(self, other): return hasattr(other, "lastname") and hasattr(other, "firstname") def __eq__(self, other): if not self._is_valid_operand(other): return NotImplemented return (self.lastname, self.firstname) == (other.lastname, other.firstname) def __lt__(self, other): if not self._is_valid_operand(other): return NotImplemented return (self.lastname, self.firstname) < (other.lastname, other.firstname) Finn = Person("Finn", "the Human") Jake = Person("Jake", "the Dog") print(Finn != Jake)
True
Hashable
Хешируемые объекты должны реализовывать методы __hash__() и __eq__(). Хеш объекта должен быть неизменен в течении всего жизненного цикла. Хешируемые объекты можно использовать как ключи в словарях и как элементы множеств, так как эти структуры используют хеш-таблицу для внутреннего представления данных.
Hashable objects that compare equal must have the same hash value, meaning default hash() that returns 'id(self)' will not do. That is why Python automatically makes classes unhashable if you only implement eq().
class Hero: def __init__(self, name: str, level: int): self.name: str = name self.level: int = level def _is_valid_operand(self, other): return hasattr(other, "name") and hasattr(other, "level") def __eq__(self, other): if not self._is_valid_operand(other): return NotImplemented return (self.name, self.level) == (other.name, other.level) def __hash__(self): return hash((self.name, self.level)) Finn = Hero("Finn the Human", 10_000) Jake = Hero("Jake the Dog", 10_000) print(hash(Finn)) print(hash(Jake))
-8707075988359731747 -2276052447712954388
Sortable
Для возможности применения к последовательностям объектов таких методов как sort() или max() необходимо, как и в случае Comparable, определить методы __lt__ (меньше) и __eq__ (равно), а также задействовать декоратор @functools.total_ordering.
Для более предсказумого поведения объекта в условиях различного контекста вы можете определить полное множество функций сравнения (__lt()__, __gt()__, __le__() и __ge__()).
Для примера создадим класс студентов, которых можно будет сортировать не по имени, а по среднему баллу.
from functools import total_ordering from statistics import mean @total_ordering class Student: def __init__(self, name: str, grades: list[int]): self.name: str = name self.grades: list[int] = grades def _is_valid_operand(self, other): return hasattr(other, "name") and hasattr(other, "grades") def __eq__(self, other): if not self._is_valid_operand(other): return NotImplemented return mean(self.grades) == mean(other.grades) def __lt__(self, other): if not self._is_valid_operand(other): return NotImplemented return mean(self.grades) < mean(other.grades) # определим str для человеко-читаемой репрезентации объекта def __str__(self): return self.name + " " + str(mean(self.grades)) Melissa = Student("Melissa Andrew", [4, 3, 4, 5, 4]) Peter = Student("Peter Shining Jr.", [3, 3, 4, 5, 3]) Joe = Student("Just Joe", [5, 5, 4, 5, 5]) print([str(stud) for stud in sorted([Peter, Melissa, Joe], reverse=True)])
['Just Joe 4.8', 'Melissa Andrew 4', 'Peter Shining Jr. 3.6']
Callable
Для возможности вызова объекта в качестве функции необходимо реализовать метод __call__. Типы, поддерживающие возможность их вызова в качестве функции, могут принимать набор аргументов.
class Counter: def __init__(self): self.i = 0 def __call__(self): self.i += 1 return self.i counter = Counter() print(counter()) print(counter()) print(counter())
1 2 3
@classmethod нельзя вызывать в качестве функции:
class Check(): @classmethod def class_method(cls): pass @staticmethod def static_method(): pass def instance_method(self): pass for attr, val in vars(Check).items(): if not attr.startswith("__"): print (attr, f"{'is' if callable(val) else 'is NOT'} callable")
class_method is NOT callable static_method is callable instance_method is callable
Контекстные менеджеры, описанные в предыдущей главе, тоже, как мы теперь видим, определяются через утиную типизацию при помощи методов __enter__ и __exit__.
Утиная типизация итерируемых объектов
Iterable
Iterable — объект, который для предоставления возможности поочерёдного прохода по всем своим элементам должен реализовывать метод __iter__(), возвращающий итератор. У каждого объекта с методом __iter__() автоматически начинает работать метод __contains__().
class MyIterable: def __init__(self, *args): self.a = list(args) def __iter__(self): return iter(self.a) mi = MyIterable(1, 2, 3, 4) print([el for el in mi]) print(1 in mi) # __contains__()
[1, 2, 3, 4] True
Collection
Collection — объект, предоставляющий возможность поочерёдного прохода по всем своим элементам и обладающий конечным размером.
В дополнение к iter() должен быть реализован метод len(), возвращающий размер коллекции.
class MyCollection: def __init__(self, *args): self.a = list(args) def __iter__(self): return iter(self.a) def __len__(self): return len(self.a) mc = MyCollection(1, 2, 3, 4) print([el for el in mc]) print(1 in mc) print(len(mc))
[1, 2, 3, 4] True 4
Sequence
Требует методы len() and getitem(). getitem() должен отдавать элемент с требуемым индексом или вызывать исключение IndexError.
Автоматически будут порождены методы iter(), reversed() и contains().
class MySequence: def __init__(self, a): self.a = a def __len__(self): return len(self.a) def __getitem__(self, i): return self.a[i]
ABC Sequence
Коллекция Sequence из Abstract Base Classes for Containers предоставляет расширенный интерфейс по сравнению с обычной Sequence.
Всё так же требуя __getitem__ и __len__, предоставляет __contains_, __iter__, __reversed_\, index и count.
from collections import abc class MyAbcSequence(abc.Sequence): def __init__(self, a): self.a = a def __len__(self): return len(self.a) def __getitem__(self, i): return self.a[i]
Таблица требуемых и доступных методов:
+------------+------------+------------+------------+--------------+ | | Iterable | Collection | Sequence | ABC Sequence | +------------+------------+------------+------------+--------------+ | iter() | нужен | нужен | + | + | | contains() | + | + | + | + | | len() | | нужен | нужен | нужен | | getitem() | | | нужен | нужен | | reversed() | | | + | + | | index() | | | | + | | count() | | | | + | +------------+------------+------------+------------+--------------+
И вообще, потщательнее присмотритесь с collections.abc, там есть множество заготовок, которые помогут вам сэкономить немало времени. Например, если к упомянутым относительно ABC Sequence __getitem__ и __len__ добавить __setitem__, __delitem__ и insert, то в ответ вы получите коллекцию MutableSequence, которая, кроме возможностей Sequence, имеет еще методы append, reverse, extend, pop, remove и __iadd__.
Копирование объектов
В Python оператор присваивания (=) не копирует объекты. Вместо этого он создает связь между существующим объектом и именем целевой переменной. Чтобы создать копии объекта в Python, необходимо использовать модуль copy. Более того, существует два способа создания копий для данного объекта с помощью модуля copy.
Shallow Copy – это побитовая копия объекта. Созданный скопированный объект имеет точную копию значений в исходном объекте. Если одно из значений является ссылкой на другие объекты, копируются только адреса ссылок на них.
Deep Copy – рекурсивно копирует все значения от исходного объекта к целевому, т. е. дублирует даже объекты, на которые ссылается исходный объект.
from copy import copy, deepcopy class A: def __init__(self, val: list): self.val = val def change_val(self, val: list): self.val = val a = A(list("one")) # Просто копирование ссылки на объект b = a # Assignment # Создание нового объекта и копирование ссылок на объекты, найденные в изначальном объекте c = copy(a) # Shallow copy # Создание нового объекта с последующим рекурсивным копированием содержащихся внутри объектов d = deepcopy(a) # Deep Copy b.change_val(list("two")) c.change_val(list("three")) d.change_val(list("four")) print(a.val, b.val, c.val, d.val) print(id(a), id(b), id(c), id(d)) print(id(a.val[1]), id(c.val[1]))
['t', 'w', 'o'] ['t', 'w', 'o'] ['t', 'h', 'r', 'e', 'e'] ['f', 'o', 'u', 'r'] 1795295519472 1795295519472 1793149281968 1793149273808 1795217224688 1795217321264
Наследование
class Person: def __init__(self, name, age): self.name = name self.age = age class Employee(Person): def __init__(self, name, age, staff_num, email): super().__init__(name, age) self.staff_num = staff_num self.email = email
Множественное наследование
При множественном наследовании порядок разрешения методов (method resolution order, MRO) позволяет Питону выяснить, из какого класса-предка нужно вызывать метод, если он не обнаружен непосредственно в классе-потомке.
class PrivateStaffData: def __init__(self, private_email): self.private_email = private_email class PublicStaffData: def __init__(self, work_email): self.work_email = work_email class StaffData(PrivateStaffData, PublicStaffData): def __init__(self, private_email, work_email): super().__init__() print(StaffData.mro())
[<class '__main__.StaffData'>, <class '__main__.PrivateStaffData'>, <class '__main__.PublicStaffData'>, <class 'object'>]
MRO строит иерархию наследования таким образом, чтобы более специфичные методы класса-потомка перекрывали менее специфичные методы класса-предка. MRO строит упорядоченный список классов, в которых будет производиться поиск метода слева направо (линеаризация класса).
Для решения проблемы ромбовидной структуры (которая неявно присутствует даже в простейшем случае, так как все классы наследуются от object) линеаризация должна быть монотонной. Монотонность — свойство, которое требует соблюдения в линеаризации класса-потомка того же порядка следования классов-прародителей, что и в линеаризации класса-родителя. Линеаризация по сути является топологической сортировкой. В ранних версиях Python использовался алгоритм DLR, сейчас в ходу C3-линеаризация.
Если после удовлетворения свойства монотонности остаётся больше одного варианта линеаризации, то применяется порядок локального старшинства (local precedence ordering), т. е. порядок соблюдения для классов-родителей в линеаризации класса-потомка того же порядка, что и при его объявлении. Например, если класс объявлен как D(A, B, C), то в линеаризации D класс A должен стоять раньше B, а класс B — раньше C.
Если разрешение всех конфликтов при линеаризации невозможно, то остается три пути:
1 — переменой мест классов-предков в объявлении класса-потомка (но это помогает далеко не всегда);
2 — пересмотр иерархии наследования;
3 — определение своей собственной линеаризации через метаклассы при помощи метода mro(cls). Но при данном подходе надо быть готовым к тому, что будет использован менее специфичный метод класса-родителя вместо более специфичного метода класса-потомка.
При задании своей собственной линеаризации Python отключает встроенные проверки.
Наследование классов со __slots__
При одиночном наследовании __slots__ нормально наследуется, но это не предотвращает создание __dict__:
class SlotsClass: __slots__ = 'foo', 'bar' class ChildSlotsClass(SlotsClass): ... obj = ChildSlotsClass() print(obj.__slots__) obj.something_new = "underwater stones" print(obj.__dict__)
('foo', 'bar') {'something_new': 'underwater stones'}
Для ограничения дочернего класса слотами нужно в нём снова присвоить значение атрибуту __slots__, родительские поля дублировать не нужно.
class SlotsClass: __slots__ = 'foo', 'bar' class ChildSlotsClass(SlotsClass): __slots__ = 'baz' obj = ChildSlotsClass() # obj.something_new = "underwater stones" # Raises AttributeError: 'ChildSlotsClass' object has no attribute 'something_new'
Множественное же наследование классов с непустыми __slots__ невозможно.
Метапрограммирование
Что такое класс? Это, в принципе, просто кусок кода, описывающий, как создать объект. Но в Python класс — это нечто большее, классы также являются объектами; как только используется ключевое слово class, Python исполняет команду и создаёт объект:
class A: ...
В памяти будет создан объект с именем A.
Классы, как и другие объекты, можно создавать на ходу:
def custom_class(name): if name == "foo": class Foo: ... return Foo # Возвращает именно класс, а не экземпляр else: class Bar: ... return Bar MyClass = custom_class("foo") print(MyClass) # Функция возвращает класс, а не экземпляр print(my_class := MyClass()) # Можно создать экземпляр класса
<class '__main__.custom_class.<locals>.Foo'> <__main__.custom_class.<locals>.Foo object at 0x000001F0ECF97610>
Но это не очень удобно, так как нам до сих пор приходится писать весь код класса.
Основная цель метаклассов — автоматически изменять класс в момент создания, генерируя классы в соответствии с текущим контекстом.
Сами по себе метаклассы достаточно просты и работают примерно следующим образом:
перехватывают создание класса,
изменяют класс,
возвращают модифицированный класс.
Но обычно логику работы метаклассов насыщают вещами вроде интроспекции или манипуляцией наследованием, поэтому конечный код выглядит достаточно громоздко.
Здесь неплохо было бы добавить еще пару страниц про ньюансы создания и работы метаклассов, но позвольте переадресовать вас на вот эту прекрасную статью.
При помощи метаклассов хорошо решаются задачи, например, генерации классов для ORM. Скажем, для
class Person(models.Model): name = models.CharField(max_length=30) age = models.IntegerField()
код
keanu = Person(name="Keanu Reeves", age=58) print(keanu.age)
распечатает число, взятое из БД, потому что models.Model определяет __metaclass__, который сотворит некоторую магию и превратит класс Person, который мы только что определили достаточно простым выражением, в сложную привязку к базе данных.
Если вы всё еще ломаете голову, где бы вам пришить метапрограммирование в своём текущем проекте, чтобы потом упомянуть об этом в резюме, то вот вам на 147 % уместная цитата из Тима Питерса: «[Metaclasses] are deeper magic than 99% of users should ever worry about. If you wonder whether you need them, you don’t (the people who actually need them know with certainty that they need them, and don’t need an explanation about why)», что в вольном переводе означает «Метаклассы нужны только уверенным в себе людям, которые точно знают, чего хотят от жизни, а вовсе не тебе».
@abstractmethod
Абстрактный класс в Python — аналог интерфейса в других языках (например, в C#) — класс, содержащий только сигнатуры методов, без реализации. Реализация методов переложена на классы-потомки. Задача абстрактного класса соответствует задаче интерфейса — обязать классы-потомки реализовывать все методы, заложенные в классе-родителе.
import abc class AbstractClass(metaclass=abc.ABCMeta): @abc.abstractmethod def return_anything(self): return class ConcreteClass(AbstractClass): def return_anything(self): return 42 c = ConcreteClass() print(c.return_anything())
42
Если не специфицировать return_anything() в ConcreteClass, при попытке вызвать c.return_anything() будет выброшено исключение TypeError: Can't instantiate abstract class ConcreteClass with abstract method return_anything.
Источники
Официальная документация Python docs.python.org, включающая The Python Standard Library.
Весьма подробное руководство (совсем уж базовый синтаксис не включен): Comprehensive Python Cheatsheet.
Руководство с включением базового синтаксиса: Python Cheatsheet. Включает практические Jupiter Notebooks.
Сипсок библиотек и фреймворков: Awesome Python.
Около-питоновские практические советы (pip, virtualenv, pyInstaller и т. д.): "The Hitchhiker’s Guide to Python".
Мануал для начинающих дата-сайентистов: Joel Grus, "Data Science from Scratch".
Руководство для начинающих: "Python Notes for Professionals".
Руководство для опытных программистов: "Python 3 Patterns, Recipes and Idioms".
Архитектурные паттерны: Harry Percival & Bob Gregory, "Architecture Patterns with Python".

