Что такое нейросеть? В базовом понимании, нейросеть – это совокупность связанных нейронных блоков, выполняющих обработку информации.
Обучение
До 1-го года:
Свыше 1-го года:
Онлайн-бакалавриат: Data Science & Machine Learning: Российская академия народного хозяйства и государственной службы при Президенте РФ занимает 9-е место в российском рейтинге Forbes и 2-е место в рейтинге самых влиятельных вузов страны, по версии рейтингового агентства RAEX.
Московский Физико-Технический Институт (МФТИ): Один из ведущих российских университетов в области естественных наук и технологий. У них есть несколько курсов по нейросетям и искусственному интеллекту.
Санкт-Петербургский государственный университет (СПбГУ): Они также предлагают различные курсы по машинному обучению и нейросетям.
Высшая Школа Экономики (ВШЭ): Их факультет компьютерных наук предлагает несколько программ, связанных с искусственным интеллектом и машинным обучением.
Университет Иннополис: Иннополис – это технологический университет в России, который также предлагает программы по искусственному интеллекту.
I. Основы нейросетей
В поисковых системах ежедневно растет количество запросов, что такое нейросеть (далее — НС). Прежде всего это связано с растущим интересом к технологиям на базе искусственного интеллекта (далее — ИИ). Многие из нас даже не подозревают, что мы практически ежедневно используем модели глубокого обучения. Запросы Siri или взаимодействие с чат-ботами в мессенджерах — один из ярких примеров использования НС.

Мало кто из нас знает, что нейронки существуют уже 80 лет. Первая НС была представлена в 1943 году Уорреном Маккалоу и Уолтером Питтсом. В ее основе лежала пороговая логика для построения вычислительных моделей. Но с годами подходы к реализации нейронных сетей изменились, как и технологии, которые используются для их разработки. Углубимся в основы НС и разберемся с ключевыми вопросами.
Сегодня это неотъемлемая часть искусственного интеллекта (далее — ИИ) и в области глубокого обучения. В фундаментальном виде НС обладают нелинейными свойствами, которые могут быть применены как для контролируемого, так и для неконтролируемого обучения. Более того, нейронные сети можно рассматривать как совокупность алгоритмов, основанных на функционировании человеческого мозга и предназначенных для выявления закономерностей.
Таким образом, нейронки базируются на алгоритмах глубокого обучения и сегодня они широко используются в решении многих задач: от классификации данных, обработки изображений до распознавания речи. Сегодня существует большое разнообразие НЧ, включая сверточные и рекуррентные структуры. При этом, их разработка представляет собой достаточно сложный процесс, но благодаря прогрессу технологий и наличию готовых фреймворков, создание и использование таких моделей стало более доступным даже для обычных пользователей.
A. Основные типы нейросетей
Существует множество типов нейронок, которые классифицируются в зависимости от структуры, потока данных, используемых нейронов и их плотности, слоев и их фильтров активации глубины и прочее.
Перцептрон
Персептрон — это алгоритм обучения с учителем, который классифицирует данные по двум категориям, поэтому он является бинарным классификатором. Концепция персептрона была впервые введена Фрэнком Розенблаттом в 1957 году. В основе лежит искусственный нейрон с регулируемыми весами и порогом. Персептрон разделяет входное пространство на две категории с помощью гиперплоскости, представленной следующим уравнением:

Персептроны могут реализовывать логические элементы, такие как И, ИЛИ или НЕ-И. Но их проблема в том, что они могут изучать только линейно разделимые задачи, такие как логическая задача И. А для нелинейных задач, таких как логическое XOR, это не работает.
Сверточные нейросети (CNN)
Эта концепция содержит трехмерное расположение нейронов вместо стандартного двумерного массива. Первый слой называется свёрточным. Каждый нейрон в сверточном слое обрабатывает информацию только из небольшой части поля. Входные функции берутся в пакетном режиме как фильтр. Архитектура искусственных НС, предложенная Яном Лекуном в 1988 году используется для эффективного распознавания образов. В этом случае сеть понимает образ частично и может выполнять операции несколько раз, чтобы завершить полную обработку.
Эта модель НС используется для разработки следующих типов приложений:
обработка изображений;
компьютерное зрение;
распознавание речи;
машинный перевод.
Например, в программах обработки происходит преобразование изображения из шкалы RGB или HSI в шкалу серого. Дальнейшие изменения значения пикселя помогут обнаружить края, и изображения можно будет классифицировать по разным категориям. Эта модель используется для глубокого обучения с несколькими параметрами, которых меньше, чем в случае с полносвязным слоем. Но есть пару недостатков этого типа НС, которые связаны со сложностью проектирования и обслуживания, а также с невысокой скоростью обработки.
Рекуррентные нейросети (RNN)
Стоит обратить внимание на еще одну достаточно распространенную архитектуру, которая нашла свое применение в обработке естественного языка (NLP). Принцип работы рекуррентной нейросети основан на оценивании произвольных предложений на основании того, как часто они встречались в текстах. Такой подход дает представление о грамматической и семантической корректности. Данная модель используется в машинном переводе и для генерации новых текстов. То есть, обучаясь, например, на произведениях Ремарка, нейронка сможет генерировать новый текст, похожий на Ремарка. Исходя из этого, мы пониманием, что в этой архитектуре используются прошлые выходные данные в качестве входных, имея при этом скрытые состояния.

Recurrent Neural Networks используются для решения целого ряда задач:
Обработка текста, например, проверка грамматики.
Преобразование текста в речь.
Анализ настроений.
Преимущества такой архитектуры в модели последовательных данных, в которой можно предположить, что каждая выборка зависит от исторических данных. Но обучать такую НС крайне сложно.
Генеративно-состязательные нейросети (GAN)
А это уже подход к генеративному моделированию, который генерирует новый набор данных на основе данных для обучения. У GAN есть 2 основных блока — генератор и дискриминатор, которые конкурируют друг с другом и могут захватывать, копировать и анализировать вариации в наборе данных. Чтобы лучше понять, что собой представляет GAN, стоит разбить этот термин на три отдельные части:
Генеративная — для изучения генеративной модели, которая описывает, как генерируются данные с точки зрения вероятностной модели. Простыми словами, в этой части объясняется, как данные генерируются визуально.
Состязательная — обучение модели проводится в состязательной обстановке.
Сеть — для обучения используются глубокие нейронные сети.
B. Принципы работы нейросетей
Алгоритм работы НС следующий:
1. На входной слой поступают данные.
2. Синапсы передают данные на следующий слой. Каждому синапсу присвоен определенный коэффициент веса и у каждого последующего нейрона может быть несколько входных синапсов.
3. Данные, которые передаются следующему нейрону — это сумма всех данных в нейронке, умноженных на соответствующие коэффициенты веса.
4. Полученные значения подставляются в функцию активации, что приводит к формированию выходных данных.
5. Передача данных будет продолжаться, пока она не достигнет конечного выхода.
Известно, что при первом запуске нейронной сети результаты могут быть неточными, так как сеть еще не обучена. Для обучения нейронки и последующей обработки данных потребуются тренировочные сеты.
Процесс обучения
Одной из особенностей нейронок является способность к обучению и совершенствованию. Для этого используется среднеквадратичная ошибка потерь. Небольшое напоминание, что такое потеря: это когда вы находите способ количественно оценить усилия НС и пытаетесь ее улучшить.

В приведенной выше формуле:
N - количество входов
Y - переменная, используемая для прогноза
Y_true — истинное значение переменной-предиктора.
Y_pred — прогнозируемое значение переменной или выходных данных.
Здесь (y_true - y_pred)^2 — квадрат ошибки. Общий квадрат ошибки можно получить с помощью функции потерь. Стоит рассматривать потери как функцию веса и чем лучше прогноз, тем меньше потери. Таким образом, цель состоит в обучении сети для минимизации потерь. Теперь у вас есть возможность изменить веса сети, чтобы повлиять на прогнозы. Отметьте каждый вес в сети, а затем запишите потери как многомерную функцию.
В свою очередь, стохастический градиентный спуск показывает, как изменить веса, чтобы минимизировать потери. Это представлено в виде уравнения:

η — это константа, известная как скорость обучения, определяющая насколько быстро вы тренируетесь. Вычтем η ∂w1/∂L из w1:
Когда ∂L/∂w1 положительна, w1 будет уменьшаться, что приведет к уменьшению L.
Когда он отрицателен, w1 будет увеличиваться, а L уменьшаться.
Выполнение этого уравнения для каждого веса в сети уменьшит потери и улучшит сеть. В таком случае важно иметь правильный тренировочный процесс, такой как:
Выбор одного образца из набора данных, чтобы сделать его стохастическим градиентным спуском, работая только с одним образцом в определенное время.
Вычисление всех производных потерь по весам.
Использование уравнения обновления для обновления каждого веса.
Возвращаемся к шагу 1 и движемся вперед.
Когда все описанные процессы завершены, вы готовы реализовать полную НС. Упомянутые шаги приводят к неуклонному снижению потерь и повышению точности.
Функции активации
Функция активации представляет собой нелинейное преобразование, которое поэлементно используется к входным данным. В данном контексте предполагается, что она добавляется к искусственной нейронной сети, чтобы помочь сети изучить сложные закономерности в данных. При сравнении с моделью, основанной на нейронах, которая находится в нашем мозгу, функция активации в конечном итоге решает, что должно быть запущено для следующего нейрона.
Стоит отметить, что есть несколько типов функций активации:
Линейная функция активации или функция активации идентичности.
Двоичная ступенчатая функция или функция активации бинарного шага.
Нелинейные функции активации.
Рассмотрим каждый тип по отдельности.
Линейная функция. Ее диапазон от -∞ до ∞ и принцип работы заключается в том, что при выполнении суммируется взвешенная сумма входных данных и возвращается результат. Ниже вы можете ознакомиться с графиком линейной функции активации:

Математически это можно представить следующим образом:

Стоит отметить, что это не бинарная функция и она ограничена диапазоном активаций. Но она подразумевает объединение нескольких нейронов вместе, чтобы вычислить максимальное значение при наличии нескольких активаций. Производная этой функции является постоянной величиной, которая не зависит от входного значения x.
Следующей функцией является бинарный шаг, для выполнения которого важно пороговое значение. Он позволяет определить, активировать нейрон или нет. Нейрон активируется в том случае, если входное значение превышает пороговое. Но если он не активирован, то его выходные данные не передаются на следующий или скрытый слой. Ниже приведен график, иллюстрирующий функцию активации бинарного шага:

Математически бинарную функцию активации можно представить в виде:

Важно отметить, что представленная возможность не способна генерировать разнообразные выходные данные с несколькими значениями. Например, она не может использоваться для классификации в рамках множества классов. Градиент ступенчатой функции равен нулю, что создает некоторые трудности при обратном распространении.
Нелинейные функция активации – это самый распространенный тип, позволяющий нейронным сетям легко приспосабливаться к различным данным и разделять выходные значения. Более того, нелинейные функции активации позволяют добавлять несколько слоев нейронов, поскольку выходные данные становятся нелинейной комбинацией входных данных, проходящих через различные слои.
Функции потерь
Функции потерь в глубоком обучении используются, чтобы измерить то, насколько хорошо работает модель НС. Дело в том, что внутри НС происходят 2 возможные математические операции – прямое и обратное распространение с градиентным спуском. Процесс прямого распространения является вычислительной процедурой, направленной на прогнозирование выходных данных для заданного входного вектора x. С другой стороны, обратное распространение и градиентный спуск представляют собой методы, описывающие процесс улучшения весов и смещений в нейронной сети, с целью достижения более точных прогнозов.
Например, есть вектор x, для которого нейронная сеть предсказывает выход, называемый вектором предсказания y.

Улучшение функции потерь в нейронных сетях является ключевым аспектом для достижения высокой эффективности при выполнении различных задач, таких как регрессия или классификация. Оценка качества модели нейронной сети основывается на том, насколько точно она выполняет поставленную задачу. В процессе обратного распространения необходимо стремиться к минимизации значения функции потерь, поскольку это позволяет улучшить производительность и эффективность нейронной сети. Результаты обратного распространения будут оптимальными при минимальном значении функции потерь.
Оптимизация и методы обратного распространения ошибки (Backpropagation)
Обратное распространение представляет собой процесс обучения НС, при котором частота ошибок передается обратно через нейронку для достижения более высокой точности. Обратное распространение — это процесс обучения НС, который включает в себя получение частоты ошибок прямого распространения и передачу этой потери назад через слои нейронной сети для более точной настройки весов.
II. Создание своей нейросети
По мере развития технологий, все больше людей интересуются глубоким обучением. Это один из революционных подходов, который развивается семимильными шагами и позволяет более эффективно компьютеру учиться на собственном опыте и понимать мир. Подход к обучению изменил представление о том, как можно использовать наши компьютеры, и сегодня ИИ быстро проникает практически во все аспекты нашей жизни. Трудно представить, каким был бы мир без глубокого обучения, но еще труднее представить, каким он будет в 2023 году и через 5 лет.
Если вы заинтересованы в изучении нейронок, стоит подробно рассмотреть вопросы, которые помогут создать свою первую НС. Начнем с самого главного – подбора инструментов и фреймворков.
A. Выбор инструментов и фреймворков
TensorFlow
Фреймворк TensorFlow пользуется широкой популярностью среди разработчиков, прежде всего благодаря активному сообществу поддержки, обширному набору встроенных функций и гибкой структуре, которую можно легко настроить под свои нужды. TensorFlow используется в Google Translate для обработки диалектов, упорядочивания, краткого изложения контента, прогнозирования и маркировки. Этот высокоэффективный фреймворк базируется на языке программирования Python и активно поддерживается компанией Google. Он также предоставляет точную документацию и пошаговые инструкции, что облегчает процесс его освоения и использования.
Keras
Этот фреймворк машинного обучения с открытым исходным кодом является популярным инструментом, основанным на TensorFlow. Он способен масштабироваться для работы с большими кластерами графических процессоров или даже целыми модулями таймерного процессора TPU. Данный инструмент обладает хорошей гибкостью и позволяет воплощать самые разнообразные исследовательские идеи, и предлагает также высокоуровневые функции для ускорения экспериментальных циклов.
PyTorch
К вашему вниманию еще одна популярная среда глубокого обучения, которая широко используется для построения нейронных сетей. Инструмент основан на научной вычислительной среде с широкой поддержкой алгоритмов машинного обучения – Torch. PyTorch является хорошей заменой базовому движку Torch на основе Python с ускорением на графическом процессоре. Это ПО с открытым исходным кодом, которое было выпущено под лицензией Apache 2.0.
Как правило, PyTorch подходит для моделей глубокого обучения, включая модели последовательностей, обучения с подкреплением и реляционных моделей. Он похож на другие фреймворки глубокого обучения, такие как Tensorflow и Caffe и сейчас это один из лучших вариантов для выполнения целого ряда задач из-за его гибкости и простоты использования. Дополнительно это хороший выбор из-за доступной документации и большого сообщества. Этот фреймворк используется многими крупными компаниями, в том числе Facebook, Uber, Twitter, Snap.
B. Определение задачи и подготовка данных
Одним из ключевых этапов перед началом разработки собственной НС является определение задачи и подготовка данных. Вы можете рассмотреть несколько вариантов, например, создать нейронку для решения задач классификации изображений, распознавания речи, предсказания временных рядов и прочее. Как только определитесь с задачей, вам предстоит подготовить данные для обучения. Они должны быть представлены в формате, понятном для нейросети.
На основе этого вы можете определить архитектуру НС, которая будет понимать, как будут обрабатываться данные и какие слои и функции активации будут использоваться. Стоит учитывать, что выбор правильной архитектуры является важным этапом, который влияет на точность и скорость обучения нейросети.
Разделение данных на обучающую, валидационную и тестовую выборки
При обучении и оценке точности нейронки необходимо разделить данные на три выборки: обучающую, валидационную и тестовую. Обучающая выборка, как следует из названия, используется для обучения нейросети, валидационная – для настройки параметров модели и контроля переобучения, а тестовая – для оценки качества модели.
Предобработка данных и аугментация
Для некоторых данных нужна предварительная обработка, например, приведения к единому формату или масштабирование. Помимо этого, важна аргументация данных, чтобы более эффективно обучать нейронку. Это возможно, например, путем случайного изменения яркости, поворота или изменения размера изображений.
C. Создание архитектуры нейросети
Теперь стоит более углубленно рассмотреть создание архитектуры нейросети. Одной из важных составляющих этого этапа является выбор того типа нейронки, которая будет соответствовать вашим задачам.
Выбор типа нейросети в зависимости от задачи
Прежде чем приступить к созданию НС определите, какие именно задачи вы хотите решить: классификация, регрессия, обработка естественного языка и прочее. Для каждого конкретного случая предусмотрены различные типы НС. Так, например, для классификации подходят нейронки прямого распространения (Feedforward Neural Network), а в случае с обработкой естественного языка – рекуррентная нейронная сеть (Recurrent Neural Network). Что касается решения задач для компьютерного зрения, то в этом случае подходит сверточная НС (Convolutional Neural Network).
Определение количества слоев и нейронов
Когда тип нейронки выбран, следует определить количество слоев и нейронов на основании этого и сложности задачи. Обычно для небольших задач достаточно нескольких слоев и нейронов, но в случае с более сложными задачами может потребоваться множество слоев и нейронов. Однако стоит понимать, что чем больше слоев и нейронов, тем больше шансов, что вам придется переобучить модель. Поэтому следует производить тонкую настройку параметров.
Выбор функций активации и функции потерь
Функция активации определяет то, как именно нейрон будет реагировать на входные данные и активироваться. Различные функции активации могут использоваться в зависимости от выбранного типа НС. Например, функция ReLU (Rectified Linear Unit) часто используется в сверточных нейронных сетях. А функция потерь, в свою очередь, определяет как модель оценивает точность прогнозирования. Функции потерь применяются в зависимости от типа задачи. Так, в случае с задачами классификации может использоваться кросс-энтропийная функция потерь.
Помните, что выбор функций активации и потерь существенно влияет на производительность и точность модели, поэтому необходимо тщательно их выбирать и настраивать.
Обучение и оценка нейросети
Нейронки обучаются посредством обработки нескольких больших наборов размеченных или неразмеченных данных. Это позволяет сетям более точно обрабатывать неизвестные входные данные. Стоит отметить, что в зависимости от типа модели и ее структуры мы получаем разные прогнозные данные. В этом случае первоочередными являются задачи обучения и тестирования модели.
Настройка гиперпараметров
Для начала нужно определить ее гиперпараметры – это параметры, которые определяют структуру и поведение модели. К ним относятся: количество слоев, размер каждого слоя, скорость обучения, коэффициенты регуляризации и прочее. Настройка гиперпараметров может происходить методом проб и ошибок или с помощью оптимизационных алгоритмов. К таким алгоритмам относится случайный поиск, генетические алгоритмы или оптимизация градиентом. Оптимальные гиперпараметры помогут достичь лучших результатов.
Обучение модели
Этот этап заключается в настройке весов и параметров на основе входных данных и правильных ответов. Это делается путем минимизации функции потерь, определяющей то, насколько хорошо модель предсказывает правильные ответы. Обычно используется метод обратного распространения ошибки, который рассчитывает градиент функции потерь по весам модели и использует его для обновления весов с целью минимизации функции потерь. Обучение может происходить в несколько этапов, когда модель проходит через весь набор данных несколько раз.
Оценка производительности и точности модели
После обучения модели необходимо оценить ее производительность и точность на тестовых данных, которые не использовались в процессе обучения. Это поможет правильно оценить то, насколько хорошо модель может обобщать данные и делать предсказания на новых данных. Оценка включает вычисление метрик, таких как точность, F1-мера, AUC-ROC и прочее. Это помогает оценить качество модели.
Визуализация результатов и анализ ошибок
Чтобы лучше понимать работу модели и ее ошибок, можно визуализировать результаты. Например, для этого можно построить графики, которые отображают изменение функции потерь и точности на обучающем и тестовом наборах данных в зависимости от количества эпох обучения. Кроме того, можно провести анализ ошибок модели, например, построить матрицу или график распределения ошибок по классам. Таким образом, вы сможете определить проблемные области и улучшить работу модели в будущем.
E. Улучшение и оптимизация нейросети
Одним из заключительных этапов является улучшение и оптимизация нейронки, и он заключается на настройке параметров для повышения производительности.
Регуляризация и методы борьбы с переобучением
Переобучение считается одной из проблем, с которой сталкиваются нейросети. Но благодаря регуляризации можно уменьшить последствия от переобучения модели. Стоит отметить, что есть несколько методов регуляризации: L1 и L2-регуляризация, и Dropout.
L1-регуляризация подразумевает добавление штрафа к функции потерь, который зависит от суммы абсолютных значений весов модели. Этот подход приводит к уменьшению весов, что позволяет удалить несущественные функции из модели.
L2-регуляризация основывается на добавлении штрафа к функции потерь, который зависит от суммы квадратов весов модели. Это уменьшает весы, что приводит к уменьшению чувствительности модели к шуму и выбросам.
Dropout - это метод, который случайным образом отключает некоторые нейроны во время обучения. Это позволяет избежать переобучения и улучшить обобщающую способность модели.
Подбор гиперпараметров и использование сетки поиска (Grid Search)
Гиперпараметры следует задать еще до того, как начнется обучение нейронки. Это позволит определить архитектуру модели, параметры оптимизации и другие настройки. Но стоит понимать, что подбор гиперпараметров не такая простая задача и поэтому приходится прибегать к использованию сетки поиска. Сетка поиска, в свою очередь, делает перебор всех возможных комбинаций, чтобы подобрать самые оптимальные параметры. В каждой комбинации модель обучается и оценивается на проверочном наборе данных. Затем выбирает ту комбинацию, которая гарантирует наилучший результат.
Перенос обучения (Transfer Learning)
Суть заключается в повторном использовании предварительно обученной модели для решения новых задач. Такой подход подразумевает использование знаний, которые были получены в ходе предыдущего задания. Например, если вы обучили простой классификатор распознавать определенные объекты на изображениях, то вы можете использовать данные этой модели для идентификации других объектов.
III. Примеры применения нейросетей
Рассмотрим самые распространенные примеры использования НС и как они решают свои задачи.
A. Распознавание изображений
Сегодня нейросети нашли широкое применение в распознавании объектов на изображениях, классификации изображений, определении границ объектов, обнаружении лиц и для других задачах. Это открывает перед нами новые перспективы и возможности, которые позволяют, например, обучить компьютер идентифицировать объекты на цифровых изображениях. Такие технологии широко используются для обеспечения безопасности или улучшения алгоритмов поисковых систем. Также нейросети используются для распознавания номерных знаков на автомобилях или определения сортов фруктов на фотографиях.
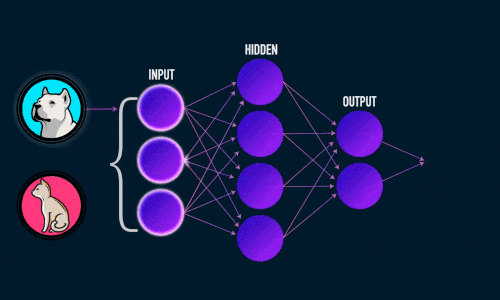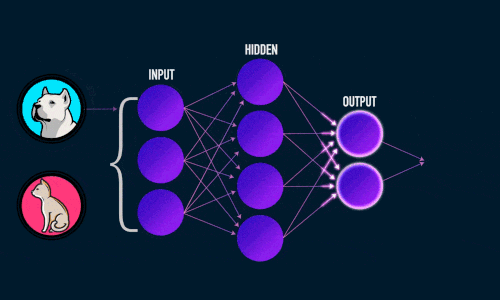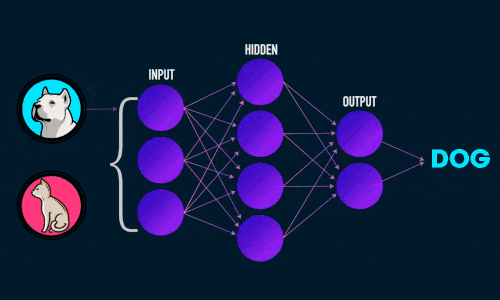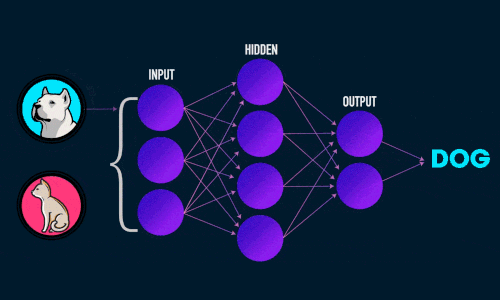
Для решения задач в области распознавания лиц и объектов используются глубокие нейронные сети. Стоит рассматривать их как жизнеспособные решения для задач по классификации изображений. И сегодня они являются достаточно точными благодаря новым алгоритмам и методов машинного обучения.
B. Обработка естественного языка (NLP)
Нейросети могут быть использованы для решения задач NLP. Речь о решениях для распознавания речи, машинного перевода, анализа тональности текста, суммаризации текста и прочее. Ярким примером являются голосовые помощники или программы для анализа тональности отзывов на продукты или для автоматического перевода текста на другие языки. В целом, NLP стало частью повседневной жизни и по мере развития технологий все больше используется в разных областях, в том числе таких как: розничная торговля для разработки чат-ботов обслуживания клиентов или в медицине для интерпретации или обобщения электронных медкарт.
Ярким примером использования NLP являются разговорные агенты, такие как Alexa от Amazon и Siri от Apple. Данная технология используется для прослушивания запросов пользователей и поиска ответов. А самые сложные из таких агентов, например, ChatGPT, который был открыт не так давно, способен даже генерировать целые поэмы на разные темы или использоваться в качестве чат-бота, способного поддерживать связные разговоры. В свою очередь, Google использует NLP для улучшения результатов своей поисковой системы, а социальные сети, такие как Facebook, используют его для обнаружения и фильтрации комментариев или публикаций с ненормативной лексикой.
Но стоит отметить, что нынешние системы НЛП достаточно изощренные и еще есть над чем поработать. Например, существующие системы несколько предвзяты и непоследовательны, а иногда ведут себя и вовсе хаотично. Но инженеры по машинному обучению ищут новые способы для улучшения технологий НЛП.
C. Генерация контента
Сегодня нейронку совершенствовали до такой степени, что ее можно использовать для генерации контента и речь не только о тексте, но также об изображениях и музыке. Например, НС сейчас все активнее используется для создания новых музыкальных композиций на основе существующих, генерации описаний товаров для интернет-магазинов или для создания новых изображений на основе существующих.
Фишка нейросетей — в генерации того, чего не существует, но за основу берутся старые данные. Только с каждым днем НС все лучше справляются с этим и сейчас появляется все больше сервисов для генерации контента, разработанные на базе нейросетей. Они решают массу задач: от обработки изображений и оптимизации видео, до создания презентаций и генерации музыки. Для этого используются разные типы НС, например, рекуррентные нейронные сети (RNN) широко используется для решения задач создания текстового контента: новостей, статей, рецензий, аналитических обзоров. Такие нейросети способны обучаться на огромной базе данных, чтобы создавать контент на основе изученного. Одним из ярких примеров, опять же, является ChatGPT, который за последние полгода просто изменил представление о генерации контента. Но в этом случае есть одна проблема – ограниченная база, в которой хранятся данные только до 2021 года. То есть, чтобы ChatGPT смог генерировать актуальную информацию, он нуждается в постоянном обновлении данных.
В свою очередь, генеративно-состязательные нейронные сети (GAN) также могут использоваться для создания контента, включая изображения и видео. НС такого плана состоят из 2-х частей: генератора и дискриминатора. Генератор создает изображения, а дискриминатор оценивает, насколько эти изображения выглядят реалистично. Нейросеть рисует все более реалистичные изображения по мере обучения.
В интернете полно онлайн-решений для генерации изображений. Одним из таких вариантов является нейросеть Midjourney, которая имеет несколько преимуществ, как инструмент ИИ для преобразования текста в картинку. Например, это решение известно созданием хорошо структурированных, четких и реалистичных изображений. Не говоря уже про высокое разрешение и точную настройку команд и параметров.
Также существуют автоэнкодеры, которые могут использоваться для генерации контента, основанного на изображениях, видео и звуковых файлах. Такие нейронки обучаются на большом количестве данных, чтобы создавать новый контент на основе того, что они видели или слышали. Но насколько бы хорошо не обучались нейронные сети, они полностью не заменят творческую работу человека, а лишь помогут в создании контента. Помимо этого, автоматически сгенерированный контент может быть не всегда высокого качества и требовать дополнительной обработки и редактирования.
D. Рекомендательные системы
Еще одно направление, в котором используются нейронные сети – это создание рекомендательных систем. Это тот тип систем, которые предлагают пользователям контент на основе их предпочтений и поведения. Так, например, НС могут использоваться для рекомендации фильмов, музыки или товаров в интернет-магазинах. Рекомендательные системы представляют собой модели, которые предсказывают предпочтения пользователей в отношении нескольких продуктов. И в последние годы – это одно из наиболее распространенных решений для различных онлайн-сервисов.
Одним из ярких примеров рекомендательной системы является стриминговый сервис Netflix (Нетфликс). Это известный во всем мире сервис, предлагающий модель обслуживания по подписке, которая предлагает персональные рекомендации, чтобы помочь найти пользователям интересующие шоу и фильмы. В основе сервиса есть собственная комплексная система рекомендаций. При получении доступа к сервису Netflix система рекомендаций стремится помочь пользователям найти шоу или фильм с минимальными усилиями на основе ряда факторов, в том числе:
взаимодействие с сервисом (например, история просмотров и оценки);
другие участники с похожими вкусами и предпочтениями;
информация о названиях, жанрах, категориях, актерах, годе выпуска и т.д.

Чтобы лучше персонализировать данные, рекомендательная система Нетфликс обращает внимание на такие вещи, как:
Время, в которое используется сервис.
Какое устройство использовалось для доступа к сервису.
Продолжительность использования.
Фрагменты этих данных используются в качестве входных данных, которые обрабатываются в алгоритме Нетфликс. Система рекомендаций не включает демографическую информацию (такую как возраст или пол) как часть процесса принятия решения. Также рекомендации составляются на основе оценок и предпочтений пользователя к контенту.

Похожий принцип работы и у сервиса Hulu. Например, в конце 2020 года Hulu даже изменил дизайн, чтобы использовать макет, более похожий на Netflix: с горизонтальными прокручивающимися строками. Редизайн привнес и изменения в систему рекомендаций, чтобы персонализировать строки с выбором пользователей. Hulu фокусируется на алгоритмах своей поисковой системы и общих рекомендациях, а также на человеческом курировании трендовых областей. Платформа, кажется, выбрала золотую середину, когда искала баланс между человеческим и алгоритмическим управлением.
IV. Заключение
Нейронные сети созданы, чтобы сделать мир более персонализированным. Каждый из нас уже может пользоваться преимуществами машинного обучения, получая рекомендации из блюд, музыки, фильмов или литературы. Кроме того, искусственный интеллект уже начал выполнять некоторые человеческие задачи, хотя еще не способны полностью заменить людей. Прежде всего, чтобы эффективно использовать НС, необходимо выполнить несколько ключевых требований:
Набор данных должен быть достаточно большим, чтобы нейронка получила достаточно информации для обучения. Чем разнообразнее и репрезентативнее данные, тем лучше будет работать сеть.
Для обучения с учителем данные должны быть хорошо размечены и организованы, чтобы нейронка могла точно идентифицировать закономерности.
Данные должны быть высокого качества, не иметь отклонений, выбросов или ошибок.
В зависимости от типа НС должна быть разработана соответствующая архитектура, с необходимым количеством слоев и узлов в них.
Алгоритм обучения должен быть подходящим, включая стохастический градиентный спуск или обратное распространение, соответствующий выбор гиперпараметров, включая скорость обучения, размер партии и прочее.
Нейронке должно быть предоставлено достаточно времени для обучения на данных, прежде чем она будет развернута. Это также зависит от вычислительных ресурсов (память, вычислительная мощность и т. д.), используемых для обучения.
B. Перспективы развития нейросетей и искусственного интеллекта
Можно найти бесконечное множество вариантов использования искусственного интеллекта и наряду с такими технологиями, как машинное обучение и глубокая нейронная сеть, решения на базе ИИ можно использовать в разных отраслях. К тому же, темпы развития ИИ последние несколько лет впечатляют. С помощью современных технологий можно значительно сократить расходы и препятствия и послужить развитию инновационных бизнес-моделей, которые могут превзойти традиционные модели.
Сегодня нейросеть генерирует картинки, пишет тексты, улучшает качество видео и многие опасаются, что они вытеснят специалистов в этих областях. И многие отрасли уже используют решения на базе НС для решения своих серьезных сложных проблем или для оценки своих новых бизнес-моделей, методов предоставления услуг и повышения своей конкурентоспособности на рынке. Но стоит понимать, что у нейросетей и искусственного интеллекта все еще есть определенные недостатки. Например, они могут давать неверные прогнозы, если они обучены на предвзятых данных. Также стоит отметить, что НС часто становятся слишком специализированными, поскольку подстраиваются под обучающие данные и из-за этого плохо работают с новой информацией.
Своим постоянным развитием НС и другие формы ИИ приходят к возможности преобразовать и перевернуть ситуацию во многих отраслях и профессиях. В некоторых случаях ИИ системы могут эффективнее и точнее выполнять различные задачи по сравнению с человеком, что вызывает определенные опасения в связи с возможными увольнениями и увеличением безработицы. Однако полное замещение человека ИИ потребует продолжительного времени и значительного прогресса в развитии нейронных сетей. В настоящий момент ограничения связаны с данными, на основе которых обучаются ИИ системы, а также с ограниченной способностью их "понимать" обрабатываемые концепции. В результате системы на базе машинного обучения вряд ли смогут полностью заменить человека во всех сферах деятельности.

