
Привет Хабр!
Сегодня на связи Портнов Клим, участник профессионального сообщества NTA.
В этом посте расскажу о простом для понимания, но в то же время достаточно эффективном алгоритме — дереве решений, а также его расширенной модификацией — случайных лесах решений, и их реализации с помощью PySpark MLib.
Навигация по посту
Сначала расскажу о подготовке данных для обучения в PySpark MLib и построю наивную модель дерева решений.
Затем буду увеличивать точность модели путем подбора гиперпараметров.
В конце засею целый лес решений, и не забуду про сравнение полученных моделей.
Что такое дерево решений?
Данный раздел предназначен для первопроходцев. Если вы знакомы с данным алгоритмом, то смело переходите к следующей части поста.
Деревья решений
Деревья решений представляют собой семейство алгоритмов, которые естественным образом могут обрабатывать как категориальные, так и числовые функции.
Главные преимущества алгоритма:
устойчивость к выбросам в данных;
возможность использования данных разных типов и в разных масштабах без предварительной обработки или нормализации;
и главное — доступность для понимания.
На самом деле используются одни и те же рассуждения, воплощенные в деревьях решений, неявно в повседневной жизни. Например, серия решений «да/нет», которые приводят к прогнозу будет ли тренировка на улице или нет.
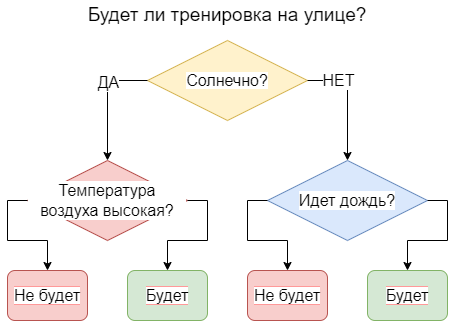
Модель дерева решений сама «придумывает» эти развилки. Чем больше развилок, тем точнее модель будет работать на тренировочных данных, но на тестовых значениях она начнет чаще ошибаться. Необходим некоторый баланс, чтобы избежать этого явления, известного как переобучение.
Случайные леса решений
Деревья решений обобщаются в более мощный алгоритм, называемый случайные леса. Случайные леса объединяют множество деревьев решений, чтобы снизить риск переоснащения и обучения деревьев решений отдельно. Объединение прогнозов уменьшает дисперсию прогнозов, делает результирующую модель более обобщенной и повышает производительность на тестовых данных.
Более подробно об алгоритме случайных деревьев можно почитать тут.
Подготовка данных
Для того, чтобы обучить модель в PySpark MLib надо всегда держать в голове, что предложенный набор данных необходимо перевести в числовой вектор. И неважно, какой у вас набор признаков (числовой, категориальный, смешанный).
Датасет
Для примера возьму общедоступный набор данных Bank Marketing. Данные получены по результатам звонков португальской маркетинговой компании (2008 — 2010 годах) и прекрасно подходят для решения задачи классификации: сделает ли клиент term deposit (срочный вклад) или нет.
Входные данные (features):
age (numeric);
job: type of job (categorical: "admin", "unknown", "unemployed", "management", "housemaid", "entrepreneur", "student", "blue-collar", "self-employed", "retired", "technician", "services");
marital: marital status (categorical: "married", "divorced", "single"; note: "divorced" means divorced or widowed);
education: (categorical: "unknown", "secondary", "primary", "tertiary");
default: has credit in default? (binary: "yes", "no");
balance: average yearly balance, in euros (numeric);
housing: has housing loan? (binary: "yes", "no");
loan: has personal loan? (binary: "yes", "no");
contact: contact communication type (categorical: "unknown", "telephone", "cellular");
day: last contact day of the month (numeric);
month: last contact month of year (categorical: "jan", "feb", "mar", ..., "nov", "dec");
duration: last contact duration, in seconds (numeric);
campaign: number of contacts performed during this campaign and for this client (numeric, includes last contact);
pdays: number of days that passed by after the client was last contacted from a previous campaign (numeric, -1 means client was not previously contacted);
previous: number of contacts performed before this campaign and for this client (numeric);
poutcome: outcome of the previous marketing campaign (categorical: "unknown", "other", "failure", "success").
Выходные данные (target): y - has the client subscribed a term deposit? (binary: "yes", "no")
С датасетом определился, перехожу к практической части.
Чтение данных
Запускаю spark сессию:
from pyspark.sql import functions as F import pyspark.sql.types as T import pandas as pd # Создаем спарк сессию spark = SparkSession \ .builder \ .config("spark.ui.enabled", "true") \ .config("spark.driver.memory", "8g") \ .config("spark.executor.instances", "4") \ .config("spark.executor.cores", "4") \ .config("spark.executor.memory", "6g") \ .config("spark.executor.memoryOverhead", "200m") \ .config("spark.dynamicAllocation.enabled", "true") \ .config("spark.dynamicAllocation.shuffleTracking.enabled", "true") \ .config("spark.sql.parquet.compression.codec", "snappy") \ .config("spark.sql.execution.arrow.pyspark.enabled", "true") \ .getOrCreate()
Считываю данные в pyspark.Dataframe():
data_raw = spark.read.option("inferSchema", "true").csv("bank-full.csv", sep=';',encoding = "UTF-8", header = True) data_raw.printSchema()
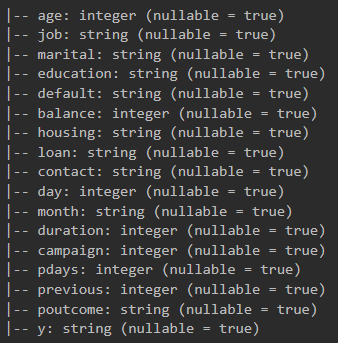
Для начала нужно избавиться от type string. Нет, не подумайте, что я вырежу все переменные этого типа, хотя было бы славно избавиться от target (шутка). Напоминаю, что target в моем датасете — это столбец «y».
Существует несколько подходов для перехода от string к integer, я рассмотрю парочку.
Первый: используем udf функции
Использование таких функций позволяет работать с sparkDataframe, как с pandasDataframe, но без использования toPandas(), что позволяет сэкономить кучу времени и нервных клеток.
# Перевод двух столбцов (month и y) из типа string в тип integer # Создаем udf функции с правилами перевода """Transforms yes/no to digit 1/0""" @F.pandas_udf(T.IntegerType()) def y_to_digit(y: pd.Series) -> pd.Series: return (y == 'yes') """Transforms months to digit""" @F.pandas_udf(T.IntegerType()) def month_to_digit(month: pd.Series) -> pd.Series: months = {'jan': 1, 'feb': 2, 'mar': 3, 'apr': 4, 'may': 5, 'jun': 6, 'jul': 7, 'aug': 8, 'sep': 9, 'oct': 10, 'nov': 11, 'dec': 12} return month.map(months) # Трансформируем столбцы по правилам перевода data_after_udf = data_raw.withColumn('y', y_to_digit(F.col('y'))).withColumn('month', month_to_digit(F.col('month'))) data_after_udf.show(20)

Второй: OneHotEncoder или преобразование в бинарные вектора
Для последовательного преобразования данных, а затем и для обучения модели буду использовать pipeline. Я формирую некое расписание в списке stages, а затем pipeline их последовательно исполняет.
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler # Для построения будем использовать контейнер pipeline # stages последовательность действий в контейнере stages = []
Преобразую все категориальные признаки в бинарные вектора:
# Преобразование категориальных колонок в бинарные вектора categoricalColumns = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'poutcome'] for categoricalCol in categoricalColumns: stringIndexer = StringIndexer(inputCol = categoricalCol, outputCol = categoricalCol + 'Index', handleInvalid = 'keep') encoder = OneHotEncoder(inputCol = stringIndexer.getOutputCol(), outputCol = categoricalCol + "classVec") stages += [stringIndexer, encoder]
Соберу все признаки в один вектор, необходимые для обучения моделей в PySpark MLib.
# Cбор всех признаков в один вектор assembler numericCols = ['age', 'balance', 'day', 'month', 'duration', 'campaign', 'pdays', 'previous'] assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols assembler = VectorAssembler(inputCols = assemblerInputs, outputCol = "features") stages += [assembler]
Посмотрю, что произойдет с данными после преобразования. Я создаю контейнер pipeline, но не добавляю в него никакую модель. Метод fit преобразует данные полученные после применений udf функций.
Для работы модели повторять эту часть необязательно, она наглядно показывает, как преобразуются данные.
# Что происходит с данными (доп. раздел) from pyspark.ml import Pipeline pipeline = Pipeline(stages=stages) model = pipeline.fit(data_after_udf) how_transform_data = model.transform(data_after_udf) how_transform_data.select(F.col('job'), F.col('jobclassVec'), F.col('features')).show(10, truncate = False)

Все категориальные признаки превратятся в sparse вектора. (Например, job → jobclassVec).
Конечный вектор признаков (features) → sparse vector с размерностью 40.
Делим данные на train и test
# Делим данные на обучающую и тестовую выборки (train_data, test_data) = data_after_udf.randomSplit([0.9, 0.1])
Наше первое дерево
После подготовки данных перехожу к построению модели.
Создание модели классификатора:
# Импорт модели классификатора from pyspark.ml.classification import DecisionTreeClassifier # labelCol – target, featuresCol – признаки, predictionCol – название колонки с результатом classifier_tree = DecisionTreeClassifier(seed = 1234, labelCol="y", featuresCol="features", predictionCol="prediction") stages += [classifier_tree]
Создание контейнера pipeline и тренировка модели:
# Создаем контейнер со стадиями stages from pyspark.ml import Pipeline pipeline_first_tree = Pipeline(stages = stages) # Тренируем модель model_first_tree = pipeline_first_tree.fit(train_data) # Делаем предсказания на тестовой выборке predictions_first_tree = model_first_tree.transform(test_data)
Оценю качество модели.
MulticlassClassificationEvaluator позволяет определять различные метрики модели. Я буду оценивать точность модели (accuracy).
# Оценка качества модели from pyspark.ml.evaluation import MulticlassClassificationEvaluator # setMetricName – тип метрики (в данном примере – "точность") multiclassEval = MulticlassClassificationEvaluator(). \ setLabelCol("y"). \ setPredictionCol("prediction"). \ setMetricName("accuracy") # Точность нашей первой модели multiclassEval.evaluate(predictions_first_tree) # 0.703
Оптимизация деревьев решений
Повысить метрику можно изменив её гиперпараметры. Для этого я выясню, какие гиперпараметры есть у дерева решений, а также рассмотрю инструмент для их автоматического перебора.
Гиперпараметры дерева решений
Все гиперпараметры дерева решений можно посмотреть тут.
Я рассмотрю наиболее важные гиперпараметры:
Максимальная глубина (maxDepth) — это максимальное количество связанных решений, которые классификатор примет для классификации примера. Это необходимо, чтобы избежать переобучения.
Максимальное количество бинов (развилок) в дереве (maxBins).
Мера примеси (impurity) — хорошие правила делят целевые значения обучающих данных на относительно однородные или «чистые» подмножества. Выбор наилучшего правила означает минимизацию нечистоты двух подмножеств, которые оно вызывает. В основном используются две меры примеси: gini и entropy.
Минимальный информационный прирост (minInfoGain) — это гиперпараметр, который определяет минимальный информационный прирост или уменьшение примесей для правил принятия решений‑кандидатов.
Реализация
Для начала необходимо создать стандартный контейнер аналогично разделу «Наше первое дерево»:
# Аналогично предыдущему разделу создаём pipeline pipeline_with_optimization = pipeline_first_tree
Затем в ParamGridBuilder определю возможные варианты интересующих меня гиперпараметров:
# Определяю гиперпараметры from pyspark.ml.tuning import ParamGridBuilder paramGrid_with_optimization = ParamGridBuilder(). \ addGrid(classifier_tree.impurity, ["gini", "entropy"]). \ addGrid(classifier_tree.maxDepth, [8, 10]). \ addGrid(classifier_tree.maxBins, [20, 30]). \ addGrid(classifier_tree.minInfoGain, [0.0]). \ build() # impurity - Присмесь # maxDepth - Максимальная глубина дерева # maxBins - Максимальное количество бинов (розвилок) в дереве # minInfoGain- Минимальный прирост информации
Далее передам в TrainValidationSplit правила построения модели (pipeline_with_optimization), метрику сравнения моделей (multiclassEval), возможные варианты гиперпараметров (paramGrid_with_optimization) и соотношение, на которое разобьётся train (trainRatio), т. е. dataset train во время обучения поделится на две выборки: на одной модели будут обучаться, а с помощью второй модели будут сравниваться между собой.
# Построение модели (которая будет искать самый оптимальный вариант) from pyspark.ml.tuning import TrainValidationSplit # estimator - контейнер с логичкой построения модели # evaluator - по какой метрике мы будем сравнивать модели # estimatorParamMaps - гиперпараметры, которые будем варьировать # trainRatio - с каким соотношением разобьёться train выборка во время обучения validator = TrainValidationSplit(seed=1234, estimator=pipeline_with_optimization, evaluator=multiclassEval, estimatorParamMaps=paramGrid_with_optimization, trainRatio=0.9) validator_with_optimization = validator.fit(train_data)
Есть возможность посмотреть результаты работы каждой модели, также их гиперпараметры.
metrics = validator_with_optimization.validationMetrics #оценки params = validator_with_optimization.getEstimatorParamMaps() #гиперпараметры metrics_and_params = list(zip(metrics, params)) metrics_and_params.sort(key=lambda x: x[0], reverse=True) metrics_and_params
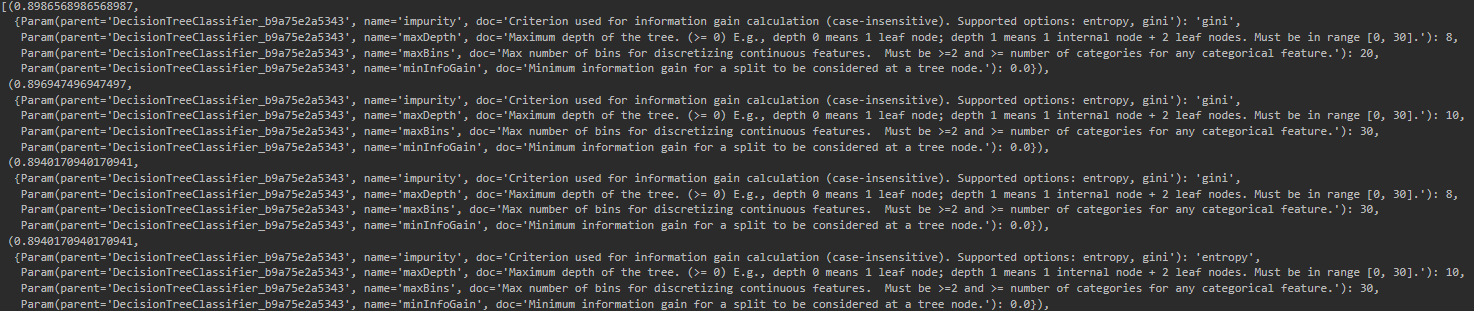
С помощью метода bestModel «вытаскиваю» лучшую модель из набора.
# Результат лучшей модели на тестовой выборке best_model = validator_with_optimization.bestModel multiclassEval.evaluate(best_model.transform(test_data)) # 0.899
Случайные леса решений
Было бы здорово иметь не одно дерево, а много деревьев, каждое из которых дает разумные, но разные и независимые оценки правильного целевого значения. Их коллективный средний прогноз должен быть близок к истинному ответу больше, чем прогноз любого отдельного дерева. Это есть алгоритм случайного леса.
Предсказание случайного леса — это просто средневзвешенное значение предсказаний деревьев. Для категориальной цели это может быть большинство голосов или наиболее вероятное значение, основанное на среднем значении вероятностей, полученных деревьями. Случайные леса, как и деревья решений, также поддерживают регрессию, и прогноз леса в этом случае представляет собой среднее число, предсказанное каждым деревом.
Хотя случайные леса являются более мощным и сложным методом классификации, хорошая новость заключается в том, что разработка модели практически ничем не отличается от разработки дерева.
Первым делом заменим в stages модель дерева на модель случайного леса:
from pyspark.ml.classification import RandomForestClassifier # Поменяем модель с дерева на лес classifier_forest = RandomForestClassifier().setLabelCol("y").setFeaturesCol("features").setPredictionCol("prediction") stages_new = stages stages_new.pop(-1) # Кикаем дерево stages_new += [classifier_forest] pipeline_forest = Pipeline(stages = stages_new)
Добавлю еще один гиперпараметр: numTrees – количество деревьев в лесе:
# Новый гиперпараметр numTrees – количество деревьев paramGrid_forest = ParamGridBuilder(). \ addGrid(classifier_forest.impurity, ["gini"]). \ addGrid(classifier_forest.maxDepth, [8]). \ addGrid(classifier_forest.maxBins, [20]). \ addGrid(classifier_forest.minInfoGain, [0.0]). \ addGrid(classifier_forest.numTrees, [2, 4, 6]). \ build()
Аналогично предыдущему разделу тренирую модели и извлекаю наилучшую:
# Построение модели (которая будет искать самый оптимальный вариант) validator = TrainValidationSplit(seed=1234, estimator=pipeline_forest, evaluator=multiclassEval, estimatorParamMaps=paramGrid_forest, trainRatio=0.9) validator_forest = validator.fit(train_data) # Извлекаю RandomForestClassifier() из PipelineModel best_model_forest = validator_forest.bestModel multiclassEval.evaluate(best_model_forest.transform(test_data)) #0.9501
Сравнение моделей
Перед сравнением моделей создам модель randomizer, которая случайно будет выбирать класс. Буду считать, что данная модель обладает наихудшей точностью.
from pyspark.sql import DataFrame from pyspark.sql.functions import col def class_probabilities(data): total = data.count() return data.groupBy("y").count().orderBy("y").select(col("count").cast(T.DoubleType())).\ withColumn("count_proportion", col("count")/total).\ select("count_proportion").collect() train_prior_probabilities = class_probabilities(train_data) #доля каждого target в total test_prior_probabilities = class_probabilities(test_data) train_prior_probabilities = [p[0] for p in train_prior_probabilities] test_prior_probabilities = [p[0] for p in test_prior_probabilities] print(sum([train_p * cv_p for train_p, cv_p in zip(train_prior_probabilities, test_prior_probabilities)])) #0.3796

Вывод
Для повышения метрик дерева решений в PySpark можно использовать параметрическую оптимизацию. Следует обратить внимание на то, что каждая модель требует индивидуального подбора гиперепараметров.
Случайный лес в основном показывает более точные результаты, но требует большего количества ресурсов.
P. S. На написании поста меня вдохновила книга издательства O'Reilly «Advanced Analytics with PySpark».

